
卷积神经网络 (CNN) 基本原理和公式
卷积神经网络(CNN)基本原理和公式推导卷积神经网络是一种前馈型神经网络, 受生物自然视觉认知机制启发而来的. 现在, CNN 已经成为众多科学领域的研究热点之一, 特别是在模式分类领域, 由于该网络避免了对图像的复杂前期预处理, 可以直接输入原始图像, 因而得到了更为广泛的应用. 可应用于图像分类, 目标识别, 目标检测, 语义分割等等. 本文介绍可用于图像分类的卷积神经网络的基本结构.深度..
卷积神经网络是一种前馈型神经网络, 受生物自然视觉认知机制启发而来的. 现在, CNN 已经成为众多科学领域的研究热点之一, 特别是在模式分类领域, 由于该网络避免了对图像的复杂前期预处理, 可以直接输入原始图像, 因而得到了更为广泛的应用. 可应用于图像分类, 目标识别, 目标检测, 语义分割等等. 本文介绍可用于图像分类的卷积神经网络的基本结构.
深度学习是一种特殊的机器学习,通过学习将世界使用嵌套的概念层次来表示并实现巨大的功能和灵活性,其中每个概念都定义为与简单概念相关联,而更为抽象的表示则以较不抽象的方式来计算。
1. CNN 结构介绍

上面是一个简单的 CNN 结构图, 第一层输入图片, 进行卷积(Convolution)操作, 得到第二层深度为 3 的特征图(Feature Map). 对第二层的特征图进行池化(Pooling)操作, 得到第三层深度为 3 的特征图. 重复上述操作得到第五层深度为 5 的特征图, 最后将这 5 个特征图, 也就是 5 个矩阵, 按行展开连接成向量, 传入全连接(Fully Connected)层, 全连接层就是一个 BP 神经网络. 图中的每个特征图都可以看成是排列成矩阵形式的神经元, 与 BP神经网络中的神经元大同小异. 下面是卷积和池化的计算过程.
卷积
对于一张输入图片, 将其转化为矩阵, 矩阵的元素为对应的像素值. 假设有一个 5 × 5 5 \times 5 5×5 的图像,使用一个 3 × 3 3 \times 3 3×3 的卷积核进行卷积,可得到一个 3 × 3 3 \times 3 3×3 的特征图. 卷积核也称为滤波器(Filter).
具体的操作过程如下图所示:
黄色的区域表示卷积核在输入矩阵中滑动, 每滑动到一个位置, 将对应数字相乘并求和, 得到一个特征图矩阵的元素. 注意到, 动图中卷积核每次滑动了一个单位, 实际上滑动的幅度可以根据需要进行调整. 如果滑动步幅大于 1, 则卷积核有可能无法恰好滑到边缘, 针对这种情况, 可在矩阵最外层补零, 补一层零后的矩阵如下图所示: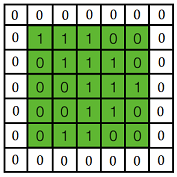
可根据需要设定补零的层数. 补零层称为 Zero Padding, 是一个可以设置的超参数, 但要根据卷积核的大小, 步幅, 输入矩阵的大小进行调整, 以使得卷积核恰好滑动到边缘.
一般情况下, 输入的图片矩阵以及后面的卷积核, 特征图矩阵都是方阵, 这里设输入矩阵大小为 w w w, 卷积核大小为 k k k, 步幅为 s s s, 补零层数为 p p p, 则卷积后产生的特征图大小计算公式为:
w ′ = ( w + 2 p − k ) s + 1 w^{\prime}=\frac{(w+2p-k)}{s}+1 w′=s(w+2p−k)+1
上图是对一个特征图采用一个卷积核卷积的过程, 为了提取更多的特征, 可以采用多个卷积核分别进行卷积, 这样便可以得到多个特征图. 有时, 对于一张三通道彩色图片, 或者如第三层特征图所示, 输入的是一组矩阵, 这时卷积核也不再是一层的, 而要变成相应的深度.
上图中, 最左边是输入的特征图矩阵, 深度为 3, 补零(Zero Padding)层数为 1, 每次滑动的步幅为 2. 中间两列粉色的矩阵分别是两组卷积核, 一组有三个, 三个矩阵分别对应着卷积左侧三个输入矩阵, 每一次滑动卷积会得到三个数, 这三个数的和作为卷积的输出. 最右侧两个绿色的矩阵分别是两组卷积核得到的特征图.
池化
池化又叫下采样(Dwon sampling), 与之相对的是上采样(Up sampling). 卷积得到的特征图一般需要一个池化层以降低数据量. 池化的操作如下图所示: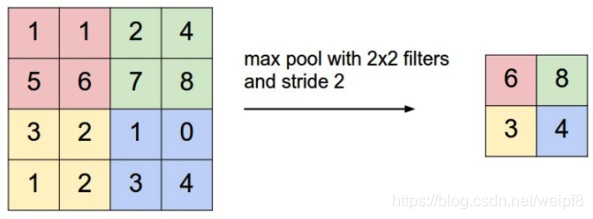
和卷积一样, 池化也有一个滑动的核, 可以称之为滑动窗口, 上图中滑动窗口的大小为 2 × 2 2\times 2 2×2, 步幅为 2 2 2, 每滑动到一个区域, 则取最大值作为输出, 这样的操作称为 Max Pooling. 还可以采用输出均值的方式, 称为 Mean Pooling.
全连接
经过若干层的卷积, 池化操作后, 将得到的特征图依次按行展开, 连接成向量, 输入全连接网络.
2. 公式
输入
V = conv2 ( W , X , "valid" ) + b V=\text{conv2}(W,X,\text{"valid"})+b V=conv2(W,X,"valid")+b
输出
Y = φ ( V ) Y=\varphi{(V)} Y=φ(V)
上面的输入输出公式是对每一个卷积层而言的, 每一个卷积层都有一个不同的权重矩阵 W W W, 并且 W , X , Y W,X,Y W,X,Y 是矩阵形式.对于最后一层全连接层, 设为第 L L L 层, 输出是向量形式的 y L y^L yL, 期望输出是 d d d, 则有总误差公式
总误差
E = 1 2 ∣ ∣ d − y L ∣ ∣ 2 2 E=\frac{1}{2}||d-y^L||_2^2 E=21∣∣d−yL∣∣22
conv2() 是 Matlab 中卷积运算的函数, 第三个参数 valid 指明卷积运算的类型, 前面介绍的卷积方式就是 valid 型. W W W 是卷积核矩阵, X X X 是输入矩阵, b b b 是偏置, φ ( x ) \varphi(x) φ(x) 是激活函数. 总误差中的 d d d, y y y 分别是期望输出和网络输出的向量. ∣ ∣ x ∣ ∣ 2 ||x||_2 ∣∣x∣∣2 表示向量 x x x 的 2-范数, 计算表达式为 ∣ ∣ x ∣ ∣ 2 = ( ∑ x i 2 ) 1 2 ||x||_2=(\sum x_i^2)^{\frac{1}{2}} ∣∣x∣∣2=(∑xi2)21. 全连接层神经元的输入输出计算公式与 BP网络完全相同.
3. 梯度下降和反向传播算法
与 BP神经网络一样, CNN 也是通过梯度下降和反向传播算法进行训练的, 则全连接层的梯度公式与 BP网络完全一样, 这里就不重复了. 下面介绍卷积层和池化层的梯度公式.
∂ E ∂ w i j = ∂ E ∂ v i j ∂ v i j ∂ w i j = δ i j ∂ v i j ∂ w i j \frac{\partial E}{\partial w_{i j}}=\frac{\partial E}{\partial v_{i j}} \frac{\partial v_{i j}}{\partial w_{i j}}=\delta_{i j} \frac{\partial v_{i j}}{\partial w_{i j}} ∂wij∂E=∂vij∂E∂wij∂vij=δij∂wij∂vij
现在的目标是求出 δ i j \delta_{ij} δij 和 ∂ v i j ∂ w i j \frac{\partial v_{i j}}{\partial w_{i j}} ∂wij∂vij的表达式. 首先求 δ i j \delta_{ij} δij, 从一个简单情况开始.
设输入是 3 × 3 3\times3 3×3 的矩阵, 卷积核是 2 × 2 2\times2 2×2 的矩阵.
(1) 当步长为 1 时, 则可得到 2 × 2 2\times 2 2×2 的特征图矩阵. 如下图所示: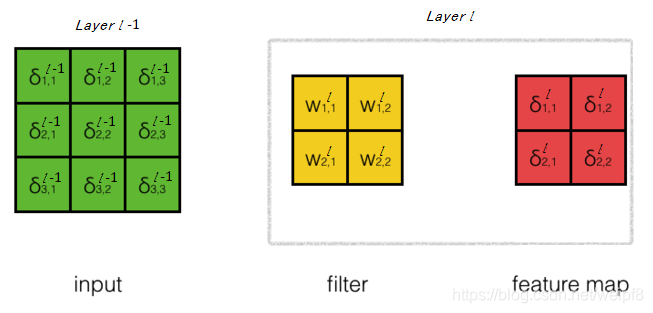
绿色矩阵是第 l − 1 l-1 l−1 层神经元, 红色的是第 l l l 层, 黄色的是第 l l l 层的卷积核, 图中省略掉了第 l − 1 l-1 l−1 层的卷积核. 每个矩阵的元素可以看成一个神经元, 于是和 BP网络一样, 可以对每个神经元定义局部梯度, 为了看着清楚, 把矩阵的元素换成 δ \delta δ. 神经网络中数值的传递也可以看成导数的传递. 假设已经求出了 δ l \delta^l δl, 则 δ l − 1 \delta^{l-1} δl−1 的计算公式为
δ l − 1 = conv2 ( rot180 ( W l ) , δ l , ’full’ ) φ ′ ( v l − 1 ) \delta^{l-1}=\text{conv2}(\text{rot180}(W^l),\delta^l,\text{'full'})\varphi^{\prime}(v^{l-1}) δl−1=conv2(rot180(Wl),δl,’full’)φ′(vl−1)
这是一个递归公式. δ \delta δ, w w w, v v v 是矩阵形式, 公式中 rot180() 函数表示将矩阵逆时针旋转 180 度, 参数 full 表示进行的完全的卷积运算, 这种运算形象的解释如下: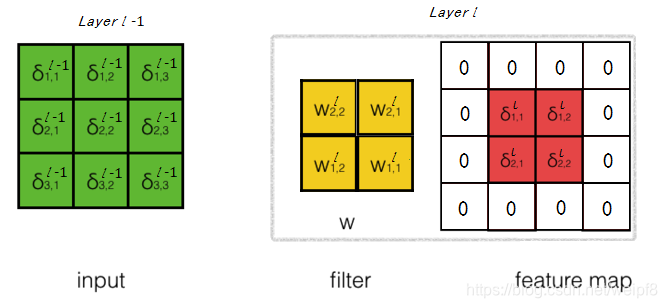
首先将特征图矩阵补一圈零, 然后用权重矩阵对补零后的特征图矩阵进行 vaild 型卷积运算. 这里补零的层数等于卷积核矩阵的大小减去 1 1 1, full 型卷积的内涵在于使卷积从边缘开始, 即先计算 w 11 l δ 11 l w_{11}^l \delta_{11}^l w11lδ11l, 然后是 w 12 l δ 11 l + w 11 l δ 12 l w_{12}^l \delta_{11}^l+w_{11}^l \delta_{12}^l w12lδ11l+w11lδ12l, 以此类推. 关于 δ \delta δ 递归公式的推导, 请看文末补充的内容.
(2) 当滑动步幅大于 1 时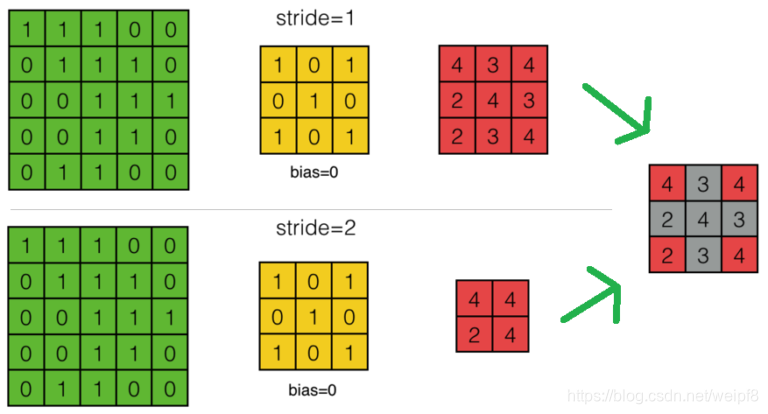
上图分别是步长为 1, 2 时的卷积过程, 可以发现步长为 1 是一个比较完全的卷积, 当步长增大时, 会跳过某些区域, 因此可以通过对特征图补零的方式将步幅为 2 时生成的特征图转换为步幅 1 的特征图, 然后直接利用前面推导的公式即可求出 δ l − 1 \delta^{l-1} δl−1. 补零如下图所示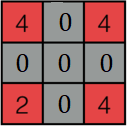
(3) 当卷积核数目为 N N N 时, 与 BP 网络隐藏层神经元局部梯度计算类似, 每一个权重的改变, 都会影响到下一层每一个神经元输入的改变, 所以误差的反响传递需要把误差之和传到前一层, 则公式可简单地修改为
δ l − 1 = ∑ i = 0 N conv2 ( rot180 ( W i l ) , δ i l , ’full’ ) φ ′ ( v l − 1 ) \delta^{l-1}=\sum_{i=0}^N \text{conv2}(\text{rot180}(W_i^l),\delta_i^l, \text{'full'}) \varphi^{\prime}(v^{l-1}) δl−1=i=0∑Nconv2(rot180(Wil),δil,’full’)φ′(vl−1)
(4) 对于池化层的梯度传递, 情况就简单了一些, 下面以 Max Pooling 为例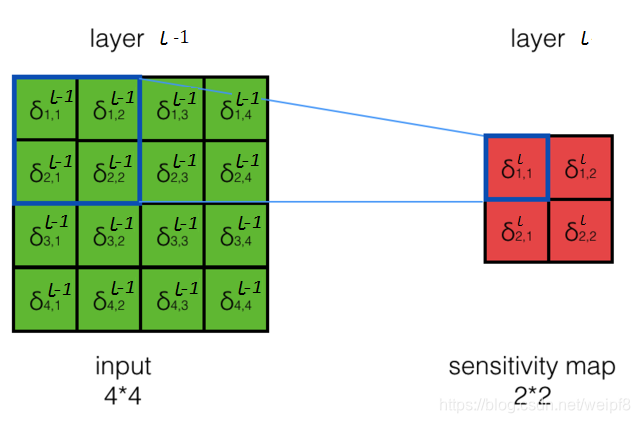
图中滑动窗口大小为 2 × 2 2\times2 2×2, 步幅为 2, 则得到一个 2 × 2 2\times2 2×2的特征图, Max Pooling 方法是选择最大的数值作为输出, 由于过程中没有任何运算, 不存在梯度的变化, 所以误差可以直接由第 l l l 层传递到第 l − 1 l-1 l−1 层, 如下图所示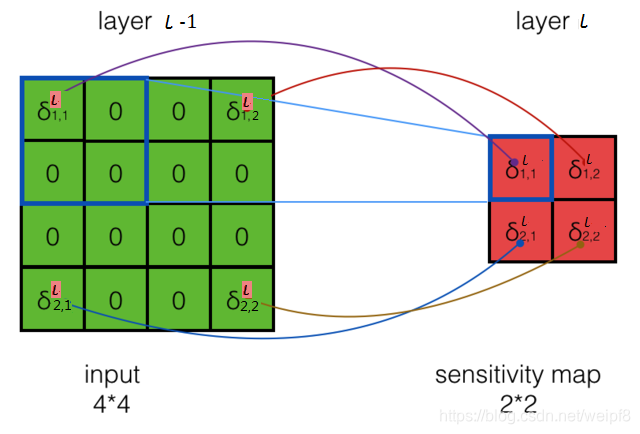
图中假设四个角上的元素值最大, 则对应位置的局部梯度可直接反向传递, 其它位置由于没有连接, 则梯度设为 0.
如果池化类型是 Mean Pooling, 即取滑动窗口内的均值作为输出, 则将 l l l 层的梯度的 1 4 \frac{1}{4} 41 倍反向传递到 l − 1 l-1 l−1 层, 如下图所示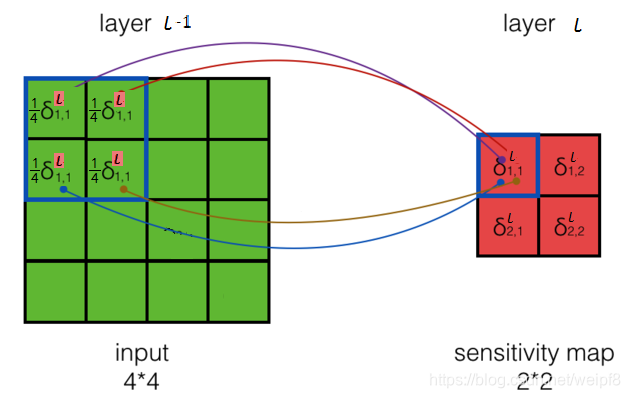
到此为止已经推导出了不同情况下的 d e l t a delta delta 的递归公式, 下面推导 ∂ v i j ∂ w i j \frac{\partial v_{ij}}{\partial w_{ij}} ∂wij∂vij 的表达式. 下图所示, 为了表达清楚, 将符号做一些替换, 相对于第 l l l 层, 第 l − 1 l-1 l−1 层的输出变量符号可由 y y y 变为 x x x.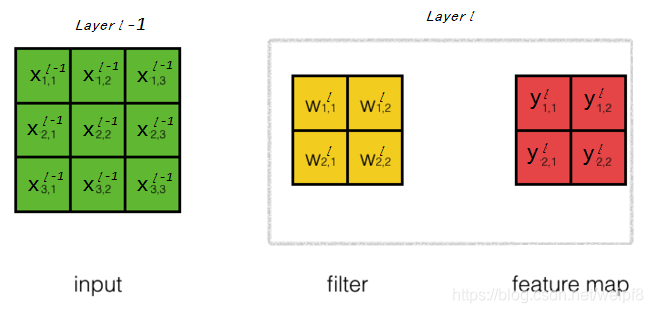
根据卷积的原理, 可以得到
y 11 l = w 11 l x 11 l − 1 + w 12 l x 12 l − 1 + w 21 l x 21 l − 1 + w 22 l x 22 l − 1 y 12 l = w 11 l x 12 l − 1 + w 12 l x 13 l − 1 + w 21 l x 22 l − 1 + w 22 l x 23 l − 1 y 21 l = w 11 l x 21 l − 1 + w 12 l x 22 l − 1 + w 21 l x 31 l − 1 + w 22 l x 32 l − 1 y 22 l = w 11 l x 22 l − 1 + w 12 l x 23 l − 1 + w 21 l x 32 l − 1 + w 22 l x 33 l − 1 \begin{aligned} y_{11}^{l} &=w_{11}^{l} x_{11}^{l-1}+w_{12}^{l} x_{12}^{l-1}+w_{21}^{l} x_{21}^{l-1}+w_{22}^{l} x_{22}^{l-1} \\ y_{12}^{l} &=w_{11}^{l} x_{12}^{l-1}+w_{12}^{l} x_{13}^{l-1}+w_{21}^{l} x_{22}^{l-1}+w_{22}^{l} x_{23}^{l-1} \\ y_{21}^{l} &=w_{11}^{l} x_{21}^{l-1}+w_{12}^{l} x_{22}^{l-1}+w_{21}^{l} x_{31}^{l-1}+w_{22}^{l} x_{32}^{l-1} \\ y_{22}^{l} &=w_{11}^{l} x_{22}^{l-1}+w_{12}^{l} x_{23}^{l-1}+w_{21}^{l} x_{32}^{l-1}+w_{22}^{l} x_{33}^{l-1} \end{aligned} y11ly12ly21ly22l=w11lx11l−1+w12lx12l−1+w21lx21l−1+w22lx22l−1=w11lx12l−1+w12lx13l−1+w21lx22l−1+w22lx23l−1=w11lx21l−1+w12lx22l−1+w21lx31l−1+w22lx32l−1=w11lx22l−1+w12lx23l−1+w21lx32l−1+w22lx33l−1
可以发现, 由于共享权重, 一个权重 w i j w_{ij} wij 的改变, 会影响所有的 y y y. 因而对某一个权重求梯度时, 需要运用全微分公式. 现在以 ∂ E ∂ w 11 l \frac{\partial E}{\partial w_{11}^{l}} ∂w11l∂E为例, 求得表达式
∂ E ∂ w 11 l = ∂ E ∂ y 11 l ∂ y 11 l ∂ w 11 l + ∂ E ∂ y 12 l ∂ y 12 l ∂ w 12 l + ∂ E ∂ y 21 l ∂ y 21 l ∂ w 21 l + ∂ E ∂ y 22 l ∂ y 22 l ∂ w 22 l = δ 11 l x 11 l − 1 + δ 12 l x 12 l − 1 + δ 21 l x 21 l − 1 + δ 22 l x 22 l − 1 \begin{array}{l}{\frac{\partial E}{\partial w_{11}^{l}}=\frac{\partial E}{\partial y_{11}^{l}} \frac{\partial y_{11}^{l}}{\partial w_{11}^{l}}+\frac{\partial E}{\partial y_{12}^{l}} \frac{\partial y_{12}^{l}}{\partial w_{12}^{l}}+\frac{\partial E}{\partial y_{21}^{l}} \frac{\partial y_{21}^{l}}{\partial w_{21}^{l}}+\frac{\partial E}{\partial y_{22}^{l}} \frac{\partial y_{22}^{l}}{\partial w_{22}^{l}}} \\ {=\delta_{11}^{l} x_{11}^{l-1}+\delta_{12}^{l} x_{12}^{l-1}+\delta_{21}^{l} x_{21}^{l-1}+\delta_{22}^{l} x_{22}^{l-1}}\end{array} ∂w11l∂E=∂y11l∂E∂w11l∂y11l+∂y12l∂E∂w12l∂y12l+∂y21l∂E∂w21l∂y21l+∂y22l∂E∂w22l∂y22l=δ11lx11l−1+δ12lx12l−1+δ21lx21l−1+δ22lx22l−1
同理可得
∂ E ∂ w 12 ′ = δ 11 l x 12 l − 1 + δ 12 l x 13 l − 1 + δ 21 l x 22 l − 1 + δ 22 l x 23 l − 1 ∂ E ∂ w 21 l = δ 11 l x 21 l − 1 + δ 12 l x 22 l − 1 + δ 21 l x 31 l − 1 + δ 22 l x 32 l − 1 ∂ E ∂ u 2 l = δ 11 l x 22 l − 1 + δ 12 l x 23 l − 1 + δ 21 l x 32 l − 1 + δ 22 l x 33 l − 1 \begin{array}{l}{\frac{\partial E}{\partial w_{12}^{\prime}}=\delta_{11}^{l} x_{12}^{l-1}+\delta_{12}^{l} x_{13}^{l-1}+\delta_{21}^{l} x_{22}^{l-1}+\delta_{22}^{l} x_{23}^{l-1}} \\ {\frac{\partial E}{\partial w_{21}^{l}}=\delta_{11}^{l} x_{21}^{l-1}+\delta_{12}^{l} x_{22}^{l-1}+\delta_{21}^{l} x_{31}^{l-1}+\delta_{22}^{l} x_{32}^{l-1}} \\ {\frac{\partial E}{\partial u_{2}^{l}}=\delta_{11}^{l} x_{22}^{l-1}+\delta_{12}^{l} x_{23}^{l-1}+\delta_{21}^{l} x_{32}^{l-1}+\delta_{22}^{l} x_{33}^{l-1}}\end{array} ∂w12′∂E=δ11lx12l−1+δ12lx13l−1+δ21lx22l−1+δ22lx23l−1∂w21l∂E=δ11lx21l−1+δ12lx22l−1+δ21lx31l−1+δ22lx32l−1∂u2l∂E=δ11lx22l−1+δ12lx23l−1+δ21lx32l−1+δ22lx33l−1
根据得到的结果, 可以发现计算 ∂ E ∂ w i j l \frac{\partial E}{\partial w_{ij}^{l}} ∂wijl∂E 的规律:
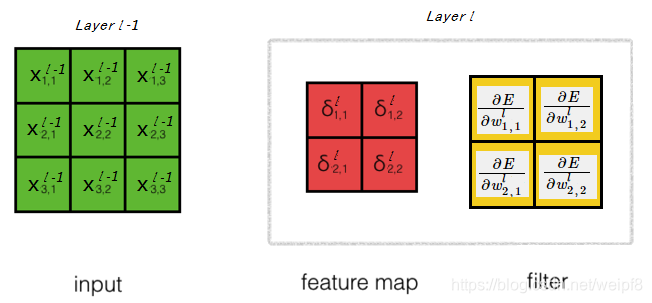
首先将前面的图中卷积核和特征图调换一下位置, 将特征图矩阵的元素替换为 δ \delta δ, 将卷积核矩阵的元素替换为 E E E 对 w w w 的偏导. 根据前面得到的偏导公式, 可以发现特征图对输入矩阵卷积可得到右边黄色的偏导矩阵. 即
∂ E ∂ w l = conv2 ( δ l , x l − 1 , ’valid’ ) \frac{\partial E}{\partial w^l}=\text{conv2}(\delta^l,x^{l-1},\text{'valid'}) ∂wl∂E=conv2(δl,xl−1,’valid’)
公式中 w w w, δ \delta δ, x x x 是以矩阵形式表达的. 同时, 可得到
∂ E ∂ b l = ∂ E ∂ v 11 l ∂ v 11 l ∂ b l + ∂ E ∂ v 12 l ∂ v 12 l ∂ b l + ∂ E ∂ v 21 l ∂ v 21 l ∂ b l + ∂ E ∂ v 22 l ∂ v 22 l ∂ b l = δ 11 l + δ 12 l + δ 21 l + δ 22 l = ∑ i ∑ j δ i j l \begin{array}{l}{\frac{\partial E}{\partial b^{l}}=\frac{\partial E}{\partial v_{11}^{l}} \frac{\partial v_{11}^{l}}{\partial b^{l}}+\frac{\partial E}{\partial v_{12}^{l}} \frac{\partial v_{12}^{l}}{\partial b^{l}}+\frac{\partial E}{\partial v_{21}^{l}} \frac{\partial v_{21}^{l}}{\partial b^{l}}+\frac{\partial E}{\partial v_{22}^{l}} \frac{\partial v_{22}^{l}}{\partial b^{l}}} \\ {=\delta_{11}^{l}+\delta_{12}^{l}+\delta_{21}^{l}+\delta_{22}^{l}} \\ {=\sum_{i} \sum_{j} \delta_{i j}^{l}}\end{array} ∂bl∂E=∂v11l∂E∂bl∂v11l+∂v12l∂E∂bl∂v12l+∂v21l∂E∂bl∂v21l+∂v22l∂E∂bl∂v22l=δ11l+δ12l+δ21l+δ22l=∑i∑jδijl
4. CNN 的特点
一个 CNN 是为了识别二维形状而特殊设计的多层感知器, 对二维形状的缩放, 倾斜或其它形式的变形具有高度不变性. 每一个神经元从上一层的局部区域得到输入, 这迫使神经元提取局部特征. 一旦一个特征被提取出来, 它相对于其它特征的位置被近似保留下来, 而忽略掉精确的位置. 每个卷积层后面跟着一个池化, 使得特征图的分辨率降低, 而有利于降低对二维图形的平移或其他形式的敏感度.
权值共享是 CNN 的一大特点, 每一个卷积核滑遍整个输入矩阵, 而参数的数目等于卷积核矩阵元素的数目加上一个偏置, 相对于 BP 网络大大减少了训练的参数. 例如对于一张 300 × 300 300\times300 300×300 的彩色图片, 如果第一层网络有25个神经元, 使用 BP网络, 参数的数目可达 675万个( 300 × 300 × 3 × 25 + 1 300\times300\times 3\times 25+1 300×300×3×25+1), 而卷积网络只有76个( 25 × 3 + 1 25\times 3+1 25×3+1).
下图是将卷积核可视化的结果
每一个卷积核就是一个特征提取器, 可以提取出输入图片或特征图中形状, 颜色等特征. 当卷积核滑动到具有这种特征的位置时, 便会产生较大的输出值, 从而达到激活的状态.
δ \delta δ 递归公式的推导
CNN 是一种前馈型神经网络, 每一个神经元只与前一层神经元相连, 接受前一层的输出, 经过运算后输出给下一层, 各层之间没有反馈. 因此对于计算局部梯度, 可以根据后一层神经元的梯度, 递归地向前传递. 首先根据前面演示过的一张图
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-I927KbbM-1578583101586)(assets/cnn-delta.png)]](https://i-blog.csdnimg.cn/blog_migrate/72f8be6853529f66947c45d8aff412e2.png)
局部梯度的定义公式
δ i j l − 1 = ∂ E ∂ v i j l − 1 = ∂ E ∂ y i j l − 1 ∂ y i j l − 1 ∂ v i j l − 1 = ∂ E ∂ y i j l − 1 φ ( v i j l − 1 ) \delta_{i j}^{l-1}=\frac{\partial E}{\partial v_{i j}^{l-1}}=\frac{\partial E}{\partial y_{i j}^{l-1}} \frac{\partial y_{i j}^{l-1}}{\partial v_{i j}^{l-1}}=\frac{\partial E}{\partial y_{i j}^{l-1}} \varphi\left(v_{i j}^{l-1}\right) δijl−1=∂vijl−1∂E=∂yijl−1∂E∂vijl−1∂yijl−1=∂yijl−1∂Eφ(vijl−1)
现在我们求出几项 ∂ E ∂ v i j l − 1 \frac{\partial E}{\partial v_{ij}^{l-1}} ∂vijl−1∂E 来寻找规律, 首先假设图中第 l l l 层中的 δ \delta δ 已知, 根据卷积运算的原理可得
v 11 l = w 11 l x 11 l − 1 + w 12 l x 12 l − 1 + w 21 l x 21 l − 1 + w 22 l x 22 l − 1 + b ∂ E ∂ y 11 l = ∂ E ∂ v 11 l ∂ v 11 l ∂ y 11 l = δ 11 l w 11 l \begin{array}{l}{v_{11}^{l}=w_{11}^{l} x_{11}^{l-1}+w_{12}^{l} x_{12}^{l-1}+w_{21}^{l} x_{21}^{l-1}+w_{22}^{l} x_{22}^{l-1}+b} \\ {\frac{\partial E}{\partial y_{11}^{l}}=\frac{\partial E}{\partial v_{11}^{l}} \frac{\partial v_{11}^{l}}{\partial y_{11}^{l}}=\delta_{11}^{l} w_{11}^{l}}\end{array} v11l=w11lx11l−1+w12lx12l−1+w21lx21l−1+w22lx22l−1+b∂y11l∂E=∂v11l∂E∂y11l∂v11l=δ11lw11l
同理可得
∂ E ∂ y 12 1 = δ 11 l w 12 l + δ 12 l w 11 l ∂ E ∂ y 22 l = δ 11 l w 22 l + δ 12 l w 21 l + δ 21 l w 12 l + δ 22 l w 11 l \begin{array}{l}{\frac{\partial E}{\partial y_{12}^{1}}=\delta_{11}^{l} w_{12}^{l}+\delta_{12}^{l} w_{11}^{l}} \\ {\frac{\partial E}{\partial y_{22}^{l}}=\delta_{11}^{l} w_{22}^{l}+\delta_{12}^{l} w_{21}^{l}+\delta_{21}^{l} w_{12}^{l}+\delta_{22}^{l} w_{11}^{l}}\end{array} ∂y121∂E=δ11lw12l+δ12lw11l∂y22l∂E=δ11lw22l+δ12lw21l+δ21lw12l+δ22lw11l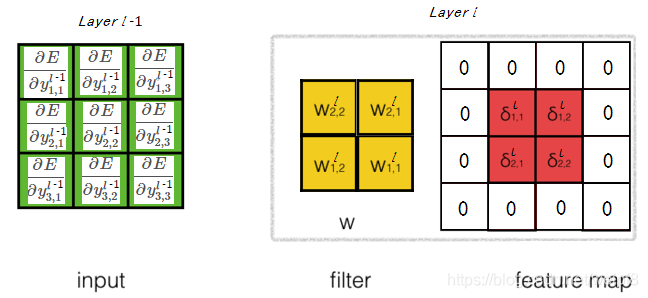
则可以发现 ∂ E ∂ y i j l − 1 \frac{\partial E}{\partial y_{ij}^{l-1}} ∂yijl−1∂E 的计算公式可以表达为上图中黄色卷积核在补零后的特征图卷积, 步幅为 1.
∂ E ∂ y l − 1 = conv2 ( rot 180 ( w l ) , δ l , ’full’ ) \frac{\partial E}{\partial y^{l-1}}=\operatorname{conv2}\left(\operatorname{rot} 180\left(w^{l}\right), \delta^{l}, \text { 'full' }\right) ∂yl−1∂E=conv2(rot180(wl),δl, ’full’ )
代入局部梯度公式得
δ l − 1 = conv2 ( rot 180 ( w l ) , δ l , ’full’ ) φ ′ ( v l − 1 ) \delta^{l-1}=\operatorname{conv2}\left(\operatorname{rot} 180\left(w^{l}\right), \delta^{l}, \text { 'full' }\right)\varphi^{\prime}(v^{l-1}) δl−1=conv2(rot180(wl),δl, ’full’ )φ′(vl−1)

学大模型,用大模型上飞桨星河社区!每天8点V100G算力免费领!免费领取ERNIE 4.0 100w Token >>>
更多推荐



 218
218 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)