
mask-rcnn解读
文章目录原理解读简介总体架构架构分解backboneFPN(Feature Pyramid Networks)FPN解决了什么问题?自下而上的路径自上而下的路径和横向连接应用RPN中的特征金字塔网络Fast R-CNN 中的特征金字塔网络总结ROIAlignROI PoolingROI Pooling局限性ROIAlignFCN**1.卷积化(convolutionalization)****2.
原理解读
如果不了解Faster-RCNN 的,灰常有必要先搞懂Faster-RCNN
https://blog.csdn.net/u010901792/article/details/100041135
简介

图1 Mask R-CNN整体架构
Mask R-CNN是一个实例分割(Instance segmentation)算法,可以用来做“目标检测”、“目标实例分割”、“目标关键点检测”。
- 实例分割(Instance segmentation)和语义分割(Semantic segmentation)的区别与联系
联系:语义分割和实例分割都是目标分割中的两个小的领域,都是用来对输入的图片做分割处理;
区别:

图2 实例分割与语义分割区别
- 通常意义上的目标分割指的是语义分割,语义分割已经有很长的发展历史,已经取得了很好地进展,目前有很多的学者在做这方面的研究;然而实例分割是一个从目标分割领域独立出来的一个小领域,是最近几年才发展起来的,与前者相比,后者更加复杂,当前研究的学者也比较少,是一个有研究空间的热门领域,如图3所示,这是一个正在探索中的领域;

图3 实例分割与语义分割区别
- 观察图3中的c和d图,c图是对a图进行语义分割的结果,d图是对a图进行实例分割的结果。两者最大的区别就是图中的"cube对象",在语义分割中给了它们相同的颜色,而在实例分割中却给了不同的颜色。即实例分割需要在语义分割的基础上对同类物体进行更精细的分割。
Mask R-CNN是一个非常灵活的框架,可以增加不同的分支完成不同的任务,可以完成目标分类、目标检测、语义分割、实例分割、人体姿势识别等多种任务。
总体架构
Mask-RCNN 大体框架还是 Faster-RCNN 的框架,可以说在基础特征网络之后又加入了全连接的分割子网,由原来的两个任务(分类+回归)变为了三个任务(分类+回归+分割)。Mask R-CNN 采用和Faster R-CNN相同的两个阶段:
第一个阶段具有相同的第一层(即RPN),扫描图像并生成提议(proposals,即有可能包含一个目标的区域);
第二阶段,除了预测种类和bbox回归,并添加了一个全卷积网络的分支,对每个RoI预测了对应的二值掩膜(binary mask),以说明给定像素是否是目标的一部分。所谓二进制mask,就是当像素属于目标的所有位置上时标识为1,其它位置标识为 0。示意图如下:

这样做可以将整个任务简化为mulit-stage pipeline,解耦了多个子任务的关系,现阶段来看,这样做好处颇多。
总体流程如下:

-
首先,输入一幅你想处理的图片,然后进行对应的预处理操作,或者预处理后的图片;
-
然后,将其输入到一个预训练好的神经网络中(ResNet等)获得对应的feature map;
-
接着,对这个feature map中的每一点设定预定个的ROI,从而获得多个候选ROI;
-
接着,将这些候选的ROI送入RPN网络进行二值分类(前景或背景)和BB回归,过滤掉一部分候选的ROI;
-
接着,对这些剩下的ROI进行ROIAlign操作(即先将原图和feature map的pixel对应起来,然后将feature map和固定的feature对应起来);
-
最后,对这些ROI进行分类(N类别分类)、BB回归和MASK生成(在每一个ROI里面进行FCN操作)。

其中 黑色部分为原来的 Faster-RCNN,红色部分为在 Faster网络上的修改:
与faster RCNN的区别:
-
ResNet+FPN
作者替换了在faster rcnn中使用的vgg网络,转而使用特征表达能力更强的残差网络。
另外为了挖掘多尺度信息,作者还使用了FPN网络。
-
将 Roi Pooling 层替换成了 RoiAlign;
解决Misalignment 的问题,说白了就是对 feature map 的插值。直接的ROIPooling的那种量化操作会使得得到的mask与实际物体位置有一个微小偏移;
-
添加并列的 FCN层(mask层);
FCN全卷积神经网络(semantic segmentation语义分割)
架构分解
各大部件原理讲解
backbone
backbone是一系列的卷积层用于提取图像的feature maps,比如可以是VGG16,VGG19,GooLeNet,ResNet50,ResNet101等,这里主要讲解的是ResNet101的结构。
ResNet(深度残差网络)实际上就是为了能够训练更加深层的网络提供了有利的思路,毕竟之前一段时间里面一直相信深度学习中网络越深得到的效果会更加的好,但是在构建了太深层之后又会使得网络退化。ResNet使用了跨层连接,使得训练更加容易。

网络试图让一个block的输出为f(x) + x,其中的f(x)为残差,当网络特别深的时候残差f(x)会趋近于0,从而f(x) + x就等于了x,即实现了恒等变换,不管训练多深性能起码不会变差。
在网络中只存在两种类型的block,在构建ResNet中一直是这两种block在交替或者循环的使用,所有接下来介绍一下这两种类型的block(indetity block, conv block):

跳过三个卷积的identity block
图中可以看出该block中直接把开端的x接入到第三个卷积层的输出,所以该x也被称为shortcut,相当于捷径似得。注意主路上第三个卷积层使用激活层,在相加之后才进行了ReLU的激活。

跳过三个卷积并在shortcut上存在的卷积的conv block
与identity block其实是差不多的,只是在shortcut上加了一个卷积层再进行相加。注意主路上的第三个卷积层和shortcut上的卷积层都没激活,而是先相加再进行激活的。
其实在作者的代码中,主路中的第一个和第三个卷积都是1*1的卷积(改变的只有feature maps的通道大小,不改变长和宽),为了降维从而实现卷积运算的加速;注意需要保持shortcut和主路最后一个卷积层的channel要相同才能够进行相加。
下面展示一下ResNet101的整体框架:

ResNet101整体架构
从图中可以得知ResNet分为了5个stage,C1-C5分别为每个Stage的输出,这些输出在后面的FPN中会使用到。你可以数数,看看是不是总共101层,数的时候除去BatchNorm层。注:stage4中是由一个conv_block和22个identity_block,如果要改成ResNet50网络的话只需要调整为5个identity_block.
FPN(Feature Pyramid Networks)
FPN解决了什么问题?
答:FPN的提出是为了实现更好的feature maps融合,一般的网络都是直接使用最后一层的feature maps,虽然最后一层的feature maps 语义强,但是位置和分辨率都比较低,容易检测不到比较小的物体。FPN的功能就是融合了底层到高层的feature maps ,从而充分的利用了提取到的各个阶段的特征(ResNet中的C2-C5 )。
简单来说,就是把底层的特征和高层的特征进行融合,便于细致检测
下面来看一下相似的网络:

FPN是为了自然地利用CNN层级特征的金字塔形式,同时生成在所有尺度上都具有强语义信息的特征金字塔。所以FPN的结构设计了top-down结构和横向连接,以此融合具有高分辨率的浅层layer和具有丰富语义信息的深层layer。这样就实现了从单尺度的单张输入图像,快速构建在所有尺度上都具有强语义信息的特征金字塔,同时不产生明显的代价。
上面一个带有skip connection的网络结构在预测的时候是在finest level(自顶向下的最后一层)进行的,简单讲就是经过多次上采样并融合特征到最后一步,拿最后一步生成的特征做预测。
而FPN网络结构和上面的类似,区别在于预测是在每一层中独立进行的。后面的实验证明finest level的效果不如FPN好,原因在于FPN网络是一个窗口大小固定的滑动窗口检测器,因此在金字塔的不同层滑动可以增加其对尺度变化的鲁棒性。另外虽然finest level有更多的anchor,但仍然效果不如FPN好,说明增加anchor的数量并不能有效提高准确率。

FPN特征融合图
自下而上的路径
CNN的前馈计算就是自下而上的路径,特征图经过卷积核计算,通常是越变越小的,也有一些特征层的输出和原来大小一样,称为“相同网络阶段”(same network stage )。对于本文的特征金字塔,作者为每个阶段定义一个金字塔级别, 然后选择每个阶段的最后一层的输出作为特征图的参考集。 这种选择是很自然的,因为每个阶段的最深层应该具有最强的特征。具体来说,对于ResNets,作者使用了每个阶段的最后一个残差结构的特征激活输出。将这些残差模块输出表示为{C2, C3, C4, C5},对应于conv2,conv3,conv4和conv5的输出,并且注意它们相对于输入图像具有{4, 8, 16, 32}像素的步长(也就是感受野)。考虑到内存占用,没有将conv1包含在金字塔中。
自上而下的路径和横向连接
自上而下的路径(the top-down pathway )是如何去结合低层高分辨率的特征呢?方法就是,把更抽象,语义更强的高层特征图进行上取样,然后把该特征横向连接(lateral connections )至前一层特征,因此高层特征得到加强。值得注意的是,横向连接的两层特征在空间尺寸上要相同。这样做应该主要是为了利用底层的定位细节信息。
下图显示连接细节。把高层特征做2倍上采样(最邻近上采样法,可以参考反卷积),然后将其和对应的前一层特征结合(前一层要经过1 * 1的卷积核才能用,目的是改变channels,应该是要和后一层的channels相同),结合方式就是做像素间的加法。重复迭代该过程,直至生成最精细的特征图。迭代开始阶段,作者在C5层后面加了一个1 * 1的卷积核来产生最粗略的特征图,最后,作者用3 * 3的卷积核去处理已经融合的特征图(为了消除上采样的混叠效应),以生成最后需要的特征图。为了后面的应用能够在所有层级共享分类层,这里作者固定了3*3卷积后的输出通道为d,这里设为256.因此所有额外的卷积层(比如P2)具有256通道输出。这些额外层没有用非线性。
{C2, C3, C4, C5}层对应的融合特征层为{P2, P3, P4, P5},对应的层空间尺寸是相通的。


从图中可以看出+的意义为:左边的底层特征层通过1*1的卷积得到与上一层特征层相同的通道数;上层的特征层通过上采样得到与下一层特征层一样的长和宽再进行相加,从而得到了一个融合好的新的特征层。举个例子说就是:C4层经过1*1卷积得到与P5相同的通道,P5经过上采样后得到与C4相同的长和宽,最终两者进行相加,得到了融合层P4,其他的以此类推。
注:P2-P5是将来用于预测物体的bbox,box-regression,mask的,而P2-P6是用于训练RPN的,即P6只用于RPN网络中。
应用
Faster R-CNN+Resnet-101
要想明白FPN如何应用在RPN和Fast R-CNN(合起来就是Faster R-CNN),首先要明白Faster R-CNN+Resnet-101的结构,直接理解就是把Faster-RCNN中原有的VGG网络换成ResNet-101,ResNet-101结构如下图:

Faster-RCNN利用conv1到conv4-x的91层为共享卷积层,然后从conv4-x的输出开始分叉,一路经过RPN网络进行区域选择,另一路直接连一个ROI Pooling层,把RPN的结果输入ROI Pooling层,映射成7 * 7的特征。然后所有输出经过conv5-x的计算,这里conv5-x起到原来全连接层(fc)的作用。最后再经分类器和边框回归得到最终结果。整体框架用下图表示:

RPN中的特征金字塔网络
RPN是Faster R-CNN中用于区域选择的子网络,RPN是在一个13 * 13 * 256的特征图上应用9种不同尺度的anchor,本篇论文另辟蹊径,把特征图弄成多尺度的,然后固定每种特征图对应的anchor尺寸,很有意思。也就是说,作者在每一个金字塔层级应用了单尺度的anchor,{P2, P3, P4, P5, P6}分别对应的anchor尺度为{32^2, 64^2, 128^2, 256^2, 512^2 },当然目标不可能都是正方形,本文仍然使用三种比例{1:2, 1:1, 2:1},所以金字塔结构中共有15种anchors。RPN结构:

从图上看出各阶层共享后面的分类网络。这也是强调为什么各阶层输出的channel必须一致的原因,这样才能使用相同的参数,达到共享的目的。
注意上面的p6,根据论文中所指添加:

正负样本的界定和Faster RCNN差不多:如果某个anchor和一个给定的ground truth有最高的IOU或者和任意一个Ground truth的IOU都大于0.7,则是正样本。如果一个anchor和任意一个ground truth的IOU都小于0.3,则为负样本。
Fast R-CNN 中的特征金字塔网络
Fast R-CNN 中很重要的是ROI Pooling层,需要对不同层级的金字塔制定不同尺度的ROI。
ROI Pooling层使用region proposal的结果和中间的某一特征图作为输入,得到的结果经过分解后分别用于分类结果和边框回归。
然后作者想的是,不同尺度的ROI使用不同特征层作为ROI pooling层的输入,大尺度ROI就用后面一些的金字塔层,比如P5;小尺度ROI就用前面一点的特征层,比如P4。那怎么判断ROI该用那个层的输出呢?这里作者定义了一个系数Pk,其定义为:
224是ImageNet的标准输入,k0是基准值,设置为5,代表P5层的输出(原图大小就用P5层),w和h是ROI区域的长和宽,假设ROI是112 * 112的大小,那么k = k0-1 = 5-1 = 4,意味着该ROI应该使用P4的特征层。k值应该会做取整处理,防止结果不是整数。
然后,因为作者把conv5也作为了金字塔结构的一部分,那么从前全连接层的那个作用怎么办呢?这里采取的方法是增加两个1024维的轻量级全连接层,然后再跟上分类器和边框回归,认为这样还能使速度更快一些。
总结
作者提出的FPN(Feature Pyramid Network)算法同时利用低层特征高分辨率和高层特征的高语义信息,通过融合这些不同层的特征达到预测的效果。并且预测是在每个融合后的特征层上单独进行的,这和常规的特征融合方式不同。
ROIAlign
ROI Pooling和ROIAlign最大的区别是:
前者使用了两次量化操作,对于roi pooling,经历了两个量化的过程:
-
从roi proposal到feature map的映射过程。如[x/16],这里x是原始roi的坐标值,而方框代表四舍五入。
-
从feature map划分成7*7的bin,每个bin使用max pooling。
而后者并没有采用量化操作,使用了线性插值算法,具体的解释如下所示。
ROI Pooling
在faster rcnn中,anchors经过proposal layer升级为proposal,需要经过ROI Pooling进行size的归一化后才能进入全连接网络,也就是说ROI Pooling的主要作用是将proposal调整到统一大小。步骤如下:
- 将proposal映射到feature map对应位置
- 将映射后的区域划分为相同大小的sections
- 对每个sections进行max pooling/avg pooling操作
举例说明:
[外链图片转存失败(img-2TLQogVd-1566556125150)(C:\F\notebook\mask-rcnn\11.png)]
考虑一个8*8大小的feature map,经过一个ROI Pooling,以及输出大小为2*2.
1)输入的固定大小的feature map (图一)
2)region proposal 投影之后位置(左上角,右下角坐标):(0,4),(4,4)(图二)
3)将其划分为(2*2)个sections(因为输出大小为2*2),我们可以得到(图三) ,不整除时错位对齐(Fast RCNN)
4)对每个section做max pooling,可以得到(图四)
ROI Pooling局限性
在常见的两级检测框架(比如Fast-RCNN,Faster-RCNN,RFCN)中,ROI Pooling 的作用是根据预选框的位置坐标在特征图中将相应区域池化为固定尺寸的特征图,以便进行后续的分类和包围框回归操作。由于预选框的位置通常是由模型回归得到的,一般来讲是浮点数,而池化后的特征图要求尺寸固定。故ROI Pooling这一操作存在两次量化的过程。
将候选框边界量化为整数点坐标值。从roi proposal到feature map的映射时,取[x/16],这里x是原始roi的坐标值,而方框代表四舍五入。 将量化后的边界区域平均分割成 k x k 个单元(bin), 对每一个单元的边界进行量化,每个bin使用max pooling。事实上,经过上述两次量化,此时的候选框已经和最开始回归出来的位置有一定的偏差,这个偏差会影响检测或者分割的准确度。在论文里,作者把它总结为“不匹配问题(misalignment)。
下面我们用直观的例子具体分析一下上述区域不匹配问题。

ROI Pooling技术
如图所示,为了得到固定大小(7X7)的feature map,我们需要做两次量化操作:
1)图像坐标 — feature map坐标,
2)feature map坐标 — ROI feature坐标。
我们来说一下具体的细节,如图我们输入的是一张800x800的图像,在图像中有两个目标(猫和狗),狗的BB大小为665x665,经过VGG16网络后,我们可以获得对应的feature map,如果我们对卷积层进行Padding操作,我们的图片经过卷积层后保持原来的大小,但是由于池化层的存在,我们最终获得feature map 会比原图缩小一定的比例,这和Pooling层的个数和大小有关。在该VGG16中,我们使用了5个池化操作,每个池化操作都是2Pooling,因此我们最终获得feature map的大小为800/32 x 800/32 = 25x25(是整数),但是将狗的BB对应到feature map上面,我们得到的结果是665/32 x 665/32 = 20.78 x 20.78,结果是浮点数,含有小数,但是我们的像素值可没有小数,那么作者就对其进行了量化操作(即取整操作),即其结果变为20 x 20,在这里引入了第一次的量化误差;然而我们的feature map中有不同大小的ROI,但是我们后面的网络却要求我们有固定的输入,因此,我们需要将不同大小的ROI转化为固定的ROI feature,在这里使用的是7x7的ROI feature,那么我们需要将20 x 20的ROI映射成7 x 7的ROI feature,其结果是 20 /7 x 20/7 = 2.86 x 2.86,同样是浮点数,含有小数点,我们采取同样的操作对其进行取整吧,在这里引入了第二次量化误差。其实,这里引入的误差会导致图像中的像素和特征中的像素的偏差,即将feature空间的ROI对应到原图上面会出现很大的偏差。原因如下:比如用我们第二次引入的误差来分析,本来是2.86,我们将其量化为2,这期间引入了0.86的误差,看起来是一个很小的误差呀,但是你要记得这是在feature空间,我们的feature空间和图像空间是有比例关系的,在这里是1:32,那么对应到原图上面的差距就是0.86 x 32 = 27.52。这个差距不小吧,这还是仅仅考虑了第二次的量化误差。这会大大影响整个检测算法的性能,因此是一个严重的问题。
简而言之:
做segment是pixel级别的,但是faster rcnn中roi pooling有2次量化操作导致了没有对齐 .
ROIAlign

为了解决ROI Pooling的上述缺点,作者提出了ROI Align这一改进的方法(如上图)。ROI Align的思路很简单:取消量化操作,使用双线性插值的方法获得坐标为浮点数的像素点上的图像数值,从而将整个特征聚集过程转化为一个连续的操作。如下图所示:
蓝色的虚线框表示卷积后获得的feature map,黑色实线框表示ROI feature,最后需要输出的大小是2x2,那么我们就利用双线性插值来估计这些蓝点(虚拟坐标点,又称双线性插值的网格点)处所对应的像素值,最后得到相应的输出。这些蓝点是2x2Cell中的随机采样的普通点,作者指出,这些采样点的个数和位置不会对性能产生很大的影响,你也可以用其它的方法获得。然后在每一个橘红色的区域里面进行max pooling或者average pooling操作,获得最终2x2的输出结果。我们的整个过程中没有用到量化操作,没有引入误差,即原图中的像素和feature map中的像素是完全对齐的,没有偏差,这不仅会提高检测的精度,同时也会有利于实例分割。

双线性插值
-
遍历每一个候选区域,保持浮点数边界不做量化。
-
将候选区域分割成k x k个单元,每个单元的边界也不做量化。
-
在每个单元中计算固定四个坐标位置,用双线性内插的方法计算出这四个位置的值,然后进行最大池化操作。
这里对上述步骤的第三点作一些说明:这个固定位置是指在每一个矩形单元(bin)中按照固定规则确定的位置。比如,如果采样点数是1,那么就是这个单元的中心点。如果采样点数是4,那么就是把这个单元平均分割成四个小方块以后它们分别的中心点。显然这些采样点的坐标通常是浮点数,所以需要使用插值的方法得到它的像素值。在相关实验中,作者发现将采样点设为4会获得最佳性能,甚至直接设为1在性能上也相差无几。
事实上,ROI Align 在遍历取样点的数量上没有ROIPooling那么多,但却可以获得更好的性能,这主要归功于解决了misalignment的问题。值得一提的是,我在实验时发现,ROI Align在VOC2007数据集上的提升效果并不如在COCO上明显。经过分析,造成这种区别的原因是COCO上小目标的数量更多,而小目标受misalignment问题的影响更大(比如,同样是0.5个像素点的偏差,对于较大的目标而言显得微不足道,但是对于小目标,误差的影响就要高很多)。

ROIAlign技术
如图所示,为了得到为了得到固定大小(7X7)的feature map,ROIAlign技术并没有使用量化操作,即我们不想引入量化误差,比如665 / 32 = 20.78,我们就用20.78,不用什么20来替代它,比如20.78 / 7 = 2.97,我们就用2.97,而不用2来代替它。这就是ROIAlign的初衷。那么我们如何处理这些浮点数呢,我们的解决思路是使用“双线性插值”算法。双线性插值是一种比较好的图像缩放算法,它充分的利用了原图中虚拟点(比如20.56这个浮点数,像素位置都是整数值,没有浮点值)四周的四个真实存在的像素值来共同决定目标图中的一个像素值,即可以将20.56这个虚拟的位置点对应的像素值估计出来。
roi-align总结:
对于每个roi,映射之后坐标保持浮点数,在此基础上再平均切分成k*k个bin,这个时候也保持浮点数。再把每个bin平均分成4个小的空间(bin中更小的bin),然后计算每个更小的bin的中心点的像素点对应的概率值。这个像素点大概率是一个浮点数,实际上图像的浮点是没有像素值的,但这里假设这个浮点数的位置存储一个概率值,这个值由相邻最近的整数像素点存储的概率值经过双线性插值得到,其实也就是根据这个中心点所在的像素值找到所在的大bin对应的4个整数像素存储的值,然后乘以多个参数进行插值。这些参数其实就是那4个整数像素点和中心点的位置距离关系构成参数。最后再在每个大bin中对4个中心点进行max或者mean的pooling。

其实就是对每个格子再次划分四个格子,进行四次采样,每次采样的位置都是四个格子的中心点,由于我知道了它的位置,但是不知道这个中心点位置的具体像素值是多少,所以采用双线性插值法求这个中心点位置的具体像素(利用它周围位置的像素点求),然后对着四个位置的像素值取最大值,得到这个大格子的输出。
补充:
- 双线性差值
1.线性插值法
这里讲解线性插值法的推导为了给双线性插值公式做铺垫。
线性插值法是指使用连接两个已知量的直线来确定在这个两个已知量之间的一个未知量的值的方法。

- 双线性插值
双线性插值是插值算法中的一种,是线性插值的扩展。利用原图像中目标点四周的四个真实存在的像素值来共同决定目标图中的一个像素值,其核心思想是在两个方向分别进行一次线性插值。

FCN
Fully Convolutional Networks 全卷积网络是CNN在语义分割领域一次重大的突破,图像语义分割,简而言之就是对一张图片上的所有像素点进行分类。
下面我们重点看一下FCN所用到的三种技术:
- 不含全连接层(fc)的全卷积(fully conv)网络。可适应任意尺寸输入。
- 增大数据尺寸的反卷积(deconv)层。能够输出精细的结果。
- 结合不同深度层结果的跳级(skip)结构。同时确保鲁棒性和精确性
1.卷积化(convolutionalization)
分类所使用的网络通常会在最后连接全连接层,它会将原来二维的矩阵(图片)压缩成一维的,从而丢失了空间信息,最后训练输出一个标量,这就是我们的分类标签。
而图像语义分割的输出则需要是个分割图,且不论尺寸大小,但是至少是二维的。所以,我们丢弃全连接层,换上卷积层,而这就是所谓的卷积化了。

这幅图显示了卷积化的过程,图中显示的是AlexNet的结构,简单来说卷积化就是将其最后三层全连接层全部替换成卷积层。
全连接层转换为卷积层:
在两种变换中,将全连接层转化为卷积层在实际运用中更加有用。假设一个卷积神经网络的输入是 224x224x3 的图像,一系列的卷积层和下采样层将图像数据变为尺寸为 7x7x512 的激活数据体。AlexNet使用了两个尺寸为4096的全连接层,最后一个有1000个神经元的全连接层用于计算分类评分。我们可以将这3个全连接层中的任意一个转化为卷积层:
针对第一个连接区域是[7x7x512]的全连接层,令其滤波器尺寸为F=7,这样输出数据体就为[1x1x4096]了。
针对第二个全连接层,令其滤波器尺寸为F=1,这样输出数据体为[1x1x4096]。
对最后一个全连接层也做类似的,令其F=1,最终输出为[1x1x1000]
2.上采样(Upsampling)
实际上,上采样(upsampling)一般包括2种方式:
- Resize,如双线性插值直接缩放,类似于图像缩放(这种方法在原文中提到)
- Deconvolution,也叫Transposed Convolution。
传统的网络是subsampling的,对应的输出尺寸会降低;upsampling的意义在于将小尺寸的高维度feature map恢复回去,以便做pixelwise prediction,获得每个点的分类信息。
转置卷积
卷积矩阵
我们可以将一个卷积操作用一个矩阵表示。这个表示很简单,无非就是将卷积核重新排列到我们可以用普通的矩阵乘法进行矩阵卷积操作。如下图就是原始的卷积核:




简单来说,这个卷积矩阵除了重新排列卷积核的权重之外就没有啥了,然后卷积操作可以通过表示为卷积矩阵和输入矩阵的列向量形式的矩阵乘积形式进行表达。
重点就在于这个卷积矩阵,你可以从16(4×4 )到4(2×2 )因为这个卷积矩阵尺寸正是4×16 ,然后,如果你有一个16×4的矩阵,你就可以从4(2×2)到16(4×4 )了,这不就是一个上采样的操作吗?
转置卷积矩阵:
我们想要从4(2×2)到16(4×4),因此我们使用了一个16×4的矩阵,但是还有一件事情需要注意,我们是想要维护一个1到9的映射关系。
假设我们转置这个卷积矩阵C (4×16)变为C.T (16×4)。我们可以对C用一个列向量(4×1)进行矩阵乘法,从而生成一个16×1 的输出矩阵。这个转置矩阵正是将一个元素映射到了9个元素。

详解:
从矩阵计算的角度来看卷积。比如下面这个简单的卷积计算,卷积参数(kernal=3,stride=1,padding=0),输入尺寸为 4,输出尺寸为 (4-3)/1+1=2。

对于上述卷积运算,我们把上图所示的 3*3 卷积核在整个矩阵上的计算过程展成一个如下所示的 [4,16] 的稀疏矩阵 , 其中非 0 元素 wi,j 表示卷积核的第 i行和第j列。

再把 4*4的输入特征展成16*1 的矩阵X,那么由 Y=AX得到一个 [4,1] 的输出特征矩阵,把它重新排列成2*2 的输出特征就得到最终的结果,从上述分析中可以看出卷积层的计算是可以转换成矩阵计算的。
在反向传播时,我们已知更深层返回的损失

所以,卷积计算中前向传播就是把输入左乘卷积矩阵A ,反向传播就是把梯度左乘卷积矩阵的转置 A T A^T AT 。
反卷积与卷积恰好相反,前向传播就是把输入左乘卷积矩阵的转置 A T A^T AT,反向传播就是把梯度左乘卷积矩阵A 。因此,反卷积又可以称为转置卷积。
“反卷积”(the transpose of conv) 可以理解为upsample conv.
卷积核为:3x3; no padding , strides=1

那看下strides=2的时候。
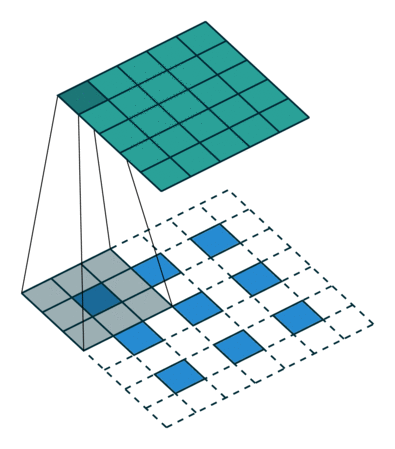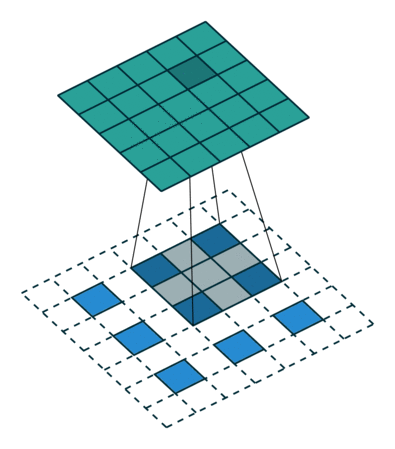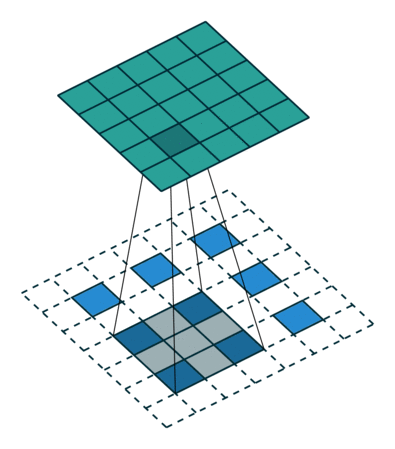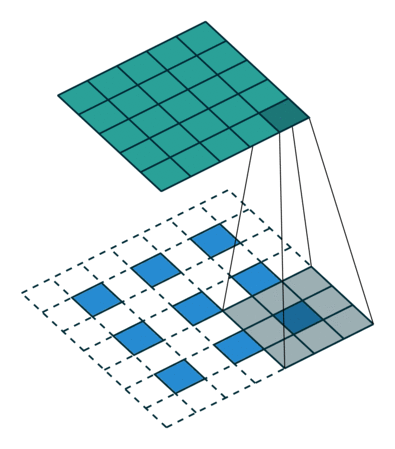
在实际计算过程中,我们要转化为矩阵的乘积的形式,将卷积核转化为Toeplitz matrix,将输入reshape为列矩阵。
举个简单的例子
比如 input= [4,4],Reshape之后,为X=[16,1]
A(可以理解为滤波器)=[4,16]
那么A*X=Y=[4,1]。Reshape Y=[2,2]
所以,通过A卷积,我们从shape=[4,4]变成了shape=[2,2]
反过来。
输入X=[2,2],reshape之后为[4,1]
A的转置为[16,4]
那么 A T ∗ X = Y A^T*X=Y AT∗X=Y=[16,1],reshape为[4,4]
所以,通过A的转置 - “反卷积”,我们从shape=[2,2]得到了shape=[4,4]
也就是输入feature map X=[3,3]经过了卷积滤波A=[3,3] 输出为 [2,2] ,所以padding=0,stride=1
反卷积则是
输入feature map X=[2,2],经过了反卷积滤波A=[3,3].输出为[3,3].padding=0,stride=1
那么[3,3]的卷积核(滤波器)是怎么转化为[4,16]或者[16,4]的呢?
通过Toeplitz matrix,不清楚自己百度下~
重点来了:对于卷积操作很了解,这里不多说。我们梳理一下反卷积的操作:
首先看stride=1时候的反卷积:这里写的是no padding,但是其实这对应的是正常卷积操作的no padding,然而实际意义上卷积操作是no padding,那么反卷积就是full padding;同时带来一个新的问题,那么padding到底是多少呢?这里我目前理解的是添加的padding值等于(kernel_size - stride),像此处就是padding = kernel_size - stride = 3 - 1 = 2,那么padding添加为2。同样对于下面stride=2的时候,padding = 3 - 2 = 1。
但是当stride>1的时候,需要在原输入中插入0像素值,如上图stride=2的时候,填充padding其实是进行了两个步骤:
-
其一是根据步长stride来填充,即在原输入矩阵中间插入(stride-1)= 2 - 1 = 1个像素值为0的值;
-
其二再根据padding来填充,padding = kernel_size - stride = 3 - 2 = 1,所以需要在输入外围填充1个像素值为0的值。
另外要说明一点反卷积和转置卷积的真正区别:
反卷积在数学含义上是可以还原输入信号的;但是转置卷积只能还原到原来输入的shape,其value值是不一样的。
借用一个反池化的图简单说明一下转置卷积是可以恢复到原来输入的shape,但是其value值是不一样的。
我们知道,池化是不可逆的过程,然而我们可以通过记录池化过程中,最大激活值得坐标位置。然后在反池化的时候,只把池化过程中最大激活值所在的位置坐标的值激活,其它的值置为0,当然这个过程只是一种近似,因为我们在池化的过程中,除了最大值所在的位置,其它的值也是不为0的。
3.跳跃结构(Skip Architecture)
其实直接使用前两种结构就已经可以得到结果了,但是直接将全卷积后的结果上采样后得到的结果通常是很粗糙的。所以这一结构主要是用来优化最终结果的,思路就是将不同池化层的结果进行上采样,然后结合这些结果来优化输出,具体结构如下:
对第5层做32倍反卷积(deconvolution),得到的结果不太精确。于是将第 4 层和第 3 层的输出也依次反卷积

**FCN例子:**输入可为任意尺寸图像彩色图像;输出与输入尺寸相同,深度为:20类目标+背景=21,模型基于AlexNet

-
蓝色:卷积层
-
绿色:Max Pooling层
-
黄色: 求和运算, 使用逐数据相加,把三个不同深度的预测结果进行融合:
较浅的结果更为精细,较深的结果更为鲁棒 -
灰色: 裁剪, 在融合之前,使用裁剪层统一两者大小, 最后裁剪成和输入相同尺寸输出
-
对于不同尺寸的输入图像,各层数据的尺寸(height,width)相应变化,深度(channel)不变
-
全卷积层部分进行特征提取, 提取卷积层(3个蓝色层)的输出来作为预测21个类别的特征
-
图中虚线内是反卷积层的运算, 反卷积层(3个橙色层)可以把输入数据尺寸放大。和卷积层一样,升采样的具体参数经过训练确定
1.以经典的AlexNet分类网络为初始化。最后两级是全连接(红色),参数弃去不用

2.从特征小图(16∗16∗4096)预测分割小图(16∗16∗21),之后直接升采样为大图。

反卷积(橙色)的步长为32,这个网络称为FCN-32s。
3.升采样分为两次完成(橙色×2), 在第二次升采样前,把第4个pooling层(绿色)的预测结果(蓝色)融合进来。使用跳级结构提升精确性

第二次反卷积步长为16,这个网络称为FCN-16s。
4.升采样分为三次完成(橙色×3), 进一步融合了第3个pooling层的预测结果

第三次反卷积步长为8,记为FCN-8s。
较浅层的预测结果包含了更多细节信息。比较2,3,4阶段可以看出,跳级结构利用浅层信息辅助逐步升采样,有更精细的结果

FCN的有点和不足
FCN 的优势在于:
- 可以接受任意大小的输入图像(没有全连接层)
- 更加高效,避免了使用邻域带来的重复计算和空间浪费的问题
其不足也很突出:
- 得到的结果还不够精细
- 没有充分考虑像素之间的关系,缺乏空间一致性
Loss计算与分析
由于增加了mask分支,每个ROI的Loss函数如下所示:
L = L c l s + L b o x + L m a s k L=L_{cls}+L_{box}+L_{mask} L=Lcls+Lbox+Lmask
其中Lcls和Lbox和Faster r-cnn中定义的相同。对于每一个ROI,mask分支有Km*m维度的输出,其对K个大小为m*m的mask进行编码,即K个分辨率为m*m的二值的掩膜。依据预测类别分支预测的类型i,只将第i的二值掩膜输出记为Lmask.
掩膜分支的损失计算如下示意图:
1.mask branch 预测K个种类的m×m二值掩膜输出
2.依据种类预测分支(Faster R-CNN部分)预测结果:当前RoI的物体种类为i
3.第i个二值掩膜输出就是该RoI的损失Lmask
对于预测的二值掩膜输出,我们对每个像素点应用sigmoid函数,整体损失定义为平均二值交叉损失熵。
引入预测K个输出的机制,允许每个类都生成独立的掩膜,避免类间竞争。这样做解耦了掩膜和种类预测。不像是FCN的方法,在每个像素点上应用softmax函数,整体采用的多任务交叉熵,这样会导致类间竞争,最终导致分割效果差。
代码解读
整体流程:

创建模型对象:
model = modellib.MaskRCNN(mode="training", config=config,
model_dir=MODEL_DIR)
搭建backbone网络
搭建特征提取网络用于图片的特征的提取,maskrcnn使用了金字塔(FPN)的网络方式进行特征的提取,使用的网络是resnet101
# 生成金字塔网络,并在每层提取特征
_, C2, C3, C4, C5 = resnet_graph(input_image, config.BACKBONE,
stage5=True, train_bn=config.TRAIN_BN)
FPN特征提取
构建RPN需要的Feature maps 和 Mask所需要的Feature maps(需要网络计算).

#构造FPN金字塔特征
# Top-down Layers
# TODO: add assert to varify feature map sizes match what's in config
P5 = KL.Conv2D(config.TOP_DOWN_PYRAMID_SIZE, (1, 1), name='fpn_c5p5')(C5)
P4 = KL.Add(name="fpn_p4add")([
KL.UpSampling2D(size=(2, 2), name="fpn_p5upsampled")(P5),
KL.Conv2D(config.TOP_DOWN_PYRAMID_SIZE, (1, 1), name='fpn_c4p4')(C4)])
P3 = KL.Add(name="fpn_p3add")([
KL.UpSampling2D(size=(2, 2), name="fpn_p4upsampled")(P4),
KL.Conv2D(config.TOP_DOWN_PYRAMID_SIZE, (1, 1), name='fpn_c3p3')(C3)])
P2 = KL.Add(name="fpn_p2add")([
KL.UpSampling2D(size=(2, 2), name="fpn_p3upsampled")(P3),
KL.Conv2D(config.TOP_DOWN_PYRAMID_SIZE, (1, 1), name='fpn_c2p2')(C2)])
# Attach 3x3 conv to all P layers to get the final feature maps.
#3*3卷积消除上采样带来的混叠效应
P2 = KL.Conv2D(config.TOP_DOWN_PYRAMID_SIZE, (3, 3), padding="SAME", name="fpn_p2")(P2)
P3 = KL.Conv2D(config.TOP_DOWN_PYRAMID_SIZE, (3, 3), padding="SAME", name="fpn_p3")(P3)
P4 = KL.Conv2D(config.TOP_DOWN_PYRAMID_SIZE, (3, 3), padding="SAME", name="fpn_p4")(P4)
P5 = KL.Conv2D(config.TOP_DOWN_PYRAMID_SIZE, (3, 3), padding="SAME", name="fpn_p5")(P5)
# P6 is used for the 5th anchor scale in RPN. Generated by
# subsampling from P5 with stride of 2.
P6 = KL.MaxPooling2D(pool_size=(1, 1), strides=2, name="fpn_p6")(P5)
# Note that P6 is used in RPN, but not in the classifier heads.
rpn_feature_maps = [P2, P3, P4, P5, P6]
mrcnn_feature_maps = [P2, P3, P4, P5]
RPN网络(需要网络计算)

这步的特点:
(1) 对于RPN的是用的同样卷积filter参数对不同的feature map进行卷积。
(2) RPN在对原始的feature map进行卷积的时候是不改变原始feature map的大小,这样的话,原始的feature map就具有cell的概念。
(3) 生成的261888个 box数据是对于anchor部分的delta数据
#有了FPN生成的这些特征图,就可以用这些特征图生成anchor
# Anchors 如果是训练情况,就在金字塔的特征图上生成anchor,如果是inference,则anchor就是输入的anchor
if mode == "training":
#获取金字塔层面上所有的anchor,是在原始图的大小上生成的anchor
#在金字塔的特征图上以每个像素为中心,以配置文件的anchor大小为宽高,生成anchor,
#并根据特征图相对原图缩小的比例,还原到原始的输入的图片上,
#也就是说,这些生成的anchor是在原始的图片上的坐标
anchors = self.get_anchors(config.IMAGE_SHAPE)
# Duplicate across the batch dimension because Keras requires it
# TODO: can this be optimized to avoid duplicating the anchors?
anchors = np.broadcast_to(anchors, (config.BATCH_SIZE,) + anchors.shape)
# A hack to get around Keras's bad support for constants
anchors = KL.Lambda(lambda x: tf.Variable(anchors), name="anchors")(input_image)
else:
anchors = input_anchors
#搭建rpn网络,将得到的金字塔特征分别输入到rpn网络中,得到网络的分类和回归值
# RPN Model 返回的是keras的Module对象, 注意keras中的Module对象是可call的
rpn = build_rpn_model(config.RPN_ANCHOR_STRIDE,
len(config.RPN_ANCHOR_RATIOS),config.TOP_DOWN_PYRAMID_SIZE)
....
#rpn网络的输出值
rpn_class_logits, rpn_class, rpn_bbox = outputs
rpn_logits: [batch, H, W, 2] Anchor classifier logits (before softmax)
rpn_probs: [batch, W, W, 2] Anchor classifier probabilities.
rpn_bbox: [batch, H, W, (dy, dx, log(dh), log(dw))] Deltas to be applied to anchors.
ProposalLayer(不需要网络计算)
这部分的特点
(1) 把第二步的box delta数据和anchor数据结合,生成最后的RPN box数据, 这里的anchor是像素尺度的值
(2) 然后对score从大到小做NMS,保留前面的1000 or 2000个
(3) 这部分不需要网络计算,相对于是对网络计算的结果进行了部分的筛选

#ProposalLayer的作用主要:
#1.根据rpn网络,获取score靠前的前n个anchor
#2.利用rpn_bbox对anchors进行修正
#3.舍弃修正后边框超过图片大小的anchor,由于我们的anchor的坐标大小是归一化的,只要坐标不超过0-1即可
#4.利用非极大抑制的方法获得最后的anchor
rpn_rois = ProposalLayer(
proposal_count=proposal_count,
nms_threshold=config.RPN_NMS_THRESHOLD,
name="ROI",
config=config)([rpn_class, rpn_bbox, anchors])
DetectionTargetLayer
DetectionTargetLayer的输入包含了:
target_rois, input_gt_class_ids, gt_boxes, input_gt_masks。其中target_rois是ProposalLayer输出的结果。
首先,计算target_rois中的每一个rois和哪一个真实的框gt_boxes iou值,如果最大的iou大于0.5,则被认为是正样本,负样本是是iou小于0.5并且和crowd box相交不大的anchor,选择出了正负样本,还要保证样本的均衡性,具体可以才配置文件中进行配置。最后计算了正样本中的anchor和哪一个真实的框最接近,用真实的框和anchor计算出偏移值,并且将mask的大小resize成28*28的(我猜测利用的是双线性差值的方式,因为mask的值不是0就是1,0是背景,一是前景)这些都是后面的分类和mask网络要用到的真实的值。
下面是该层的主要代码:
#获取的就是每个rois和哪个真实的框最接近,计算出和真实框的距离,以及要预测的mask,这些信息都会在网络的头的#classify和mask网络所使用
def detection_targets_graph(proposals, gt_class_ids, gt_boxes, gt_masks, config):
"""Generates detection targets for one image. Subsamples proposals and
generates target class IDs, bounding box deltas, and masks for each.
Inputs:
proposals: [N, (y1, x1, y2, x2)] in normalized coordinates. Might
be zero padded if there are not enough proposals.
gt_class_ids: [MAX_GT_INSTANCES] int class IDs
gt_boxes: [MAX_GT_INSTANCES, (y1, x1, y2, x2)] in normalized coordinates.
gt_masks: [height, width, MAX_GT_INSTANCES] of boolean type.
Returns: Target ROIs and corresponding class IDs, bounding box shifts,
and masks.
rois: [TRAIN_ROIS_PER_IMAGE, (y1, x1, y2, x2)] in normalized coordinates
class_ids: [TRAIN_ROIS_PER_IMAGE]. Integer class IDs. Zero padded.
deltas: [TRAIN_ROIS_PER_IMAGE, NUM_CLASSES, (dy, dx, log(dh), log(dw))]
Class-specific bbox refinements.
masks: [TRAIN_ROIS_PER_IMAGE, height, width). Masks cropped to bbox
boundaries and resized to neural network output size.
Note: Returned arrays might be zero padded if not enough target ROIs.
"""
# Assertions
asserts = [
tf.Assert(tf.greater(tf.shape(proposals)[0], 0), [proposals],
name="roi_assertion"),
]
with tf.control_dependencies(asserts):
proposals = tf.identity(proposals)
# Remove zero padding
proposals, _ = trim_zeros_graph(proposals, name="trim_proposals")
#去除非零的真实的框,也就是只留下真实存在的有意义的框
gt_boxes, non_zeros = trim_zeros_graph(gt_boxes, name="trim_gt_boxes")
gt_class_ids = tf.boolean_mask(gt_class_ids, non_zeros,
name="trim_gt_class_ids")
gt_masks = tf.gather(gt_masks, tf.where(non_zeros)[:, 0], axis=2,
name="trim_gt_masks")
# Handle COCO crowds
# A crowd box in COCO is a bounding box around several instances. Exclude
# them from training. A crowd box is given a negative class ID.
#在coco数据集中,有的框会标注很多的物体,在训练中,去掉这些框
crowd_ix = tf.where(gt_class_ids < 0)[:, 0]
non_crowd_ix = tf.where(gt_class_ids > 0)[:, 0]
crowd_boxes = tf.gather(gt_boxes, crowd_ix)
crowd_masks = tf.gather(gt_masks, crowd_ix, axis=2)
#下面就是一张图片中真实存在的物体用于训练
gt_class_ids = tf.gather(gt_class_ids, non_crowd_ix)
gt_boxes = tf.gather(gt_boxes, non_crowd_ix)
gt_masks = tf.gather(gt_masks, non_crowd_ix, axis=2)
# Compute overlaps matrix [proposals, gt_boxes]
#计算iou的值
overlaps = overlaps_graph(proposals, gt_boxes)
# Compute overlaps with crowd boxes [anchors, crowds]
crowd_overlaps = overlaps_graph(proposals, crowd_boxes)
crowd_iou_max = tf.reduce_max(crowd_overlaps, axis=1)
no_crowd_bool = (crowd_iou_max < 0.001)
# Determine positive and negative ROIs
roi_iou_max = tf.reduce_max(overlaps, axis=1)
# 1. Positive ROIs are those with >= 0.5 IoU with a GT box
#和真实的框的iou值大于0.5时,被认为是正样本
positive_roi_bool = (roi_iou_max >= 0.5)
positive_indices = tf.where(positive_roi_bool)[:, 0]
# 2. Negative ROIs are those with < 0.5 with every GT box. Skip crowds.
#负样本是是iou小于0.5并且和crowd box相交不大的anchor
negative_indices = tf.where(tf.logical_and(roi_iou_max < 0.5, no_crowd_bool))[:, 0]
# Subsample ROIs. Aim for 33% positive
# Positive ROIs
positive_count = int(config.TRAIN_ROIS_PER_IMAGE *
config.ROI_POSITIVE_RATIO)
positive_indices = tf.random_shuffle(positive_indices)[:positive_count]
positive_count = tf.shape(positive_indices)[0]
# Negative ROIs. Add enough to maintain positive:negative ratio.
r = 1.0 / config.ROI_POSITIVE_RATIO
negative_count = tf.cast(r * tf.cast(positive_count, tf.float32), tf.int32) - positive_count
negative_indices = tf.random_shuffle(negative_indices)[:negative_count]
# Gather selected ROIs
#选择出正负样本
positive_rois = tf.gather(proposals, positive_indices)
negative_rois = tf.gather(proposals, negative_indices)
# Assign positive ROIs to GT boxes.
#计算正样本和哪个真实的框最接近
positive_overlaps = tf.gather(overlaps, positive_indices)
roi_gt_box_assignment = tf.cond(
tf.greater(tf.shape(positive_overlaps)[1], 0),
true_fn = lambda: tf.argmax(positive_overlaps, axis=1),
false_fn = lambda: tf.cast(tf.constant([]),tf.int64)
)
roi_gt_boxes = tf.gather(gt_boxes, roi_gt_box_assignment)
roi_gt_class_ids = tf.gather(gt_class_ids, roi_gt_box_assignment)
# Compute bbox refinement for positive ROIs
#用最接近的真实框修正rpn网络预测的框
deltas = utils.box_refinement_graph(positive_rois, roi_gt_boxes)
deltas /= config.BBOX_STD_DEV
# Assign positive ROIs to GT masks
# Permute masks to [N, height, width, 1]
transposed_masks = tf.expand_dims(tf.transpose(gt_masks, [2, 0, 1]), -1)
# Pick the right mask for each ROI
# 计算和每一个rois最接近的框的mask
roi_masks = tf.gather(transposed_masks, roi_gt_box_assignment)
# Compute mask targets
boxes = positive_rois
if config.USE_MINI_MASK:
# Transform ROI coordinates from normalized image space
# to normalized mini-mask space.
y1, x1, y2, x2 = tf.split(positive_rois, 4, axis=1)
gt_y1, gt_x1, gt_y2, gt_x2 = tf.split(roi_gt_boxes, 4, axis=1)
gt_h = gt_y2 - gt_y1
gt_w = gt_x2 - gt_x1
y1 = (y1 - gt_y1) / gt_h
x1 = (x1 - gt_x1) / gt_w
y2 = (y2 - gt_y1) / gt_h
x2 = (x2 - gt_x1) / gt_w
boxes = tf.concat([y1, x1, y2, x2], 1)
box_ids = tf.range(0, tf.shape(roi_masks)[0])
# crop_and_resize相当于roipolling的操作
masks = tf.image.crop_and_resize(tf.cast(roi_masks, tf.float32), boxes,
box_ids,
config.MASK_SHAPE)
# Remove the extra dimension from masks.
masks = tf.squeeze(masks, axis=3)
# Threshold mask pixels at 0.5 to have GT masks be 0 or 1 to use with
# binary cross entropy loss.
masks = tf.round(masks)
# Append negative ROIs and pad bbox deltas and masks that
# are not used for negative ROIs with zeros.
rois = tf.concat([positive_rois, negative_rois], axis=0)
N = tf.shape(negative_rois)[0]
P = tf.maximum(config.TRAIN_ROIS_PER_IMAGE - tf.shape(rois)[0], 0)
rois = tf.pad(rois, [(0, P), (0, 0)])
roi_gt_boxes = tf.pad(roi_gt_boxes, [(0, N + P), (0, 0)])
roi_gt_class_ids = tf.pad(roi_gt_class_ids, [(0, N + P)])
deltas = tf.pad(deltas, [(0, N + P), (0, 0)])
masks = tf.pad(masks, [[0, N + P], (0, 0), (0, 0)])
return rois, roi_gt_class_ids, deltas, masks
最后返回的是:
rois: [TRAIN_ROIS_PER_IMAGE, (y1, x1, y2, x2)] in normalized coordinates
class_ids: [TRAIN_ROIS_PER_IMAGE]. Integer class IDs. Zero padded.
deltas: [TRAIN_ROIS_PER_IMAGE, NUM_CLASSES, (dy, dx, log(dh), log(dw))]
Class-specific bbox refinements.
masks: [TRAIN_ROIS_PER_IMAGE, height, width). Masks cropped to bbox
boundaries and resized to neural network output size.
通过rpn网络得到的anchor,选择出来正负样本,并计算出正样本和真实框的差距,以及要预测的mask的值,这些都是在后面的网络中计算损失函数需要的真实值。
Feature Pyramid Network Heads(fpn_classifier_graph)

该网络是maskrcnn的最后一层,与之并行的还有一个mask分支,在这里先介绍一下这个分类网络。
由上面得到的roi的大小并不一样,因此,需要一个网络类似于fasterrcnn中的roipooling,将rois转换成大小一样的特征图。maskrcnn中使用的是PyramidROIAlign。PyramidROIAlign首先根据下面的公司计算每一个roi来自于金字塔特征的P2到P5的哪一层的特征:
# Assign each ROI to a level in the pyramid based on the ROI area.
y1, x1, y2, x2 = tf.split(boxes, 4, axis=2)
h = y2 - y1
w = x2 - x1
# Use shape of first image. Images in a batch must have the same size.
image_shape = parse_image_meta_graph(image_meta)['image_shape'][0]
# Equation 1 in the Feature Pyramid Networks paper. Account for
# the fact that our coordinates are normalized here.
# e.g. a 224x224 ROI (in pixels) maps to P4
#计算每个roi映射到哪一层的金字塔特征的输出上
image_area = tf.cast(image_shape[0] * image_shape[1], tf.float32)
roi_level = log2_graph(tf.sqrt(h * w) / (224.0 / tf.sqrt(image_area)))
roi_level = tf.minimum(5, tf.maximum(
2, 4 + tf.cast(tf.round(roi_level), tf.int32)))
roi_level = tf.squeeze(roi_level, 2)
然后从对应的特征图中取出坐标对应的区域,利用双线性插值的方式进行pooling操作。PyramidROIAlign会返回resize成相同大小的rois。
将得到的特征块输入到fpn_classifier_graph网络中,得到分类和回归值。
下面是fpn_classifier_graph网络的定义,
def fpn_classifier_graph(rois, feature_maps, image_meta,
pool_size, num_classes, train_bn=True,
fc_layers_size=1024):
"""Builds the computation graph of the feature pyramid network classifier
and regressor heads.
rois: [batch, num_rois, (y1, x1, y2, x2)] Proposal boxes in normalized
coordinates.
feature_maps: List of feature maps from different layers of the pyramid,
[P2, P3, P4, P5]. Each has a different resolution.
- image_meta: [batch, (meta data)] Image details. See compose_image_meta()
pool_size: The width of the square feature map generated from ROI Pooling.
num_classes: number of classes, which determines the depth of the results
train_bn: Boolean. Train or freeze Batch Norm layers
fc_layers_size: Size of the 2 FC layers
Returns:
logits: [N, NUM_CLASSES] classifier logits (before softmax)
probs: [N, NUM_CLASSES] classifier probabilities
bbox_deltas: [N, (dy, dx, log(dh), log(dw))] Deltas to apply to
proposal boxes
"""
# ROI Pooling
# Shape: [batch, num_boxes, pool_height, pool_width, channels]
x = PyramidROIAlign([pool_size, pool_size],
name="roi_align_classifier")([rois, image_meta] + feature_maps)
# Two 1024 FC layers (implemented with Conv2D for consistency)
x = KL.TimeDistributed(KL.Conv2D(fc_layers_size, (pool_size, pool_size), padding="valid"),
name="mrcnn_class_conv1")(x)
x = KL.TimeDistributed(BatchNorm(), name='mrcnn_class_bn1')(x, training=train_bn)
x = KL.Activation('relu')(x)
x = KL.TimeDistributed(KL.Conv2D(fc_layers_size, (1, 1)),
name="mrcnn_class_conv2")(x)
x = KL.TimeDistributed(BatchNorm(), name='mrcnn_class_bn2')(x, training=train_bn)
x = KL.Activation('relu')(x)
shared = KL.Lambda(lambda x: K.squeeze(K.squeeze(x, 3), 2),
name="pool_squeeze")(x)
# Classifier head
mrcnn_class_logits = KL.TimeDistributed(KL.Dense(num_classes),
name='mrcnn_class_logits')(shared)
mrcnn_probs = KL.TimeDistributed(KL.Activation("softmax"),
name="mrcnn_class")(mrcnn_class_logits)
# BBox head
# [batch, boxes, num_classes * (dy, dx, log(dh), log(dw))]
x = KL.TimeDistributed(KL.Dense(num_classes * 4, activation='linear'),
name='mrcnn_bbox_fc')(shared)
# Reshape to [batch, boxes, num_classes, (dy, dx, log(dh), log(dw))]
s = K.int_shape(x)
mrcnn_bbox = KL.Reshape((s[1], num_classes, 4), name="mrcnn_bbox")(x)
return mrcnn_class_logits, mrcnn_probs, mrcnn_bbox
返回值为:
Returns:
logits: [N, NUM_CLASSES] classifier logits (before softmax)
probs: [N, NUM_CLASSES] classifier probabilities
bbox_deltas: [N, (dy, dx, log(dh), log(dw))] Deltas to apply to
proposal boxes
MASk部分(build_fpn_mask_graph)
大的逻辑是:
输入:
-
mrcnn_feature_maps = [p2_out, p3_out, p4_out, p5_out] (1,256,256,256) (1,256,128,128)(1,256,64,64)(1,256,32,32)
-
detection_boxes = (16,4)
需要完成:
- 对每个box,做一个分割,求出物体所在的区域,这里需要对于输入的box,回到原来的feature maps上再做一次ROI aligin然后算出固定大小的mask
输出:
- mrcnn_mask (16,81,28,28) — 代表的每个类别mask的score value的sigmoid以后的值
主要是调用了一个ROI align生成 14x14大小的feature map然后,做一个deconv把feature map变大到(28x28),每个类别取sigmoid.
流程图如下

mask网络的输入和1.6网络的输入值是一样的,也会经过PyramidROIAlign(这个地方可以进行一个提取,放在最后的网络之前)
#创建mask的分类头
def build_fpn_mask_graph(rois, feature_maps, image_meta,
pool_size, num_classes, train_bn=True):
"""Builds the computation graph of the mask head of Feature Pyramid Network.
rois: [batch, num_rois, (y1, x1, y2, x2)] Proposal boxes in normalized
coordinates.
feature_maps: List of feature maps from different layers of the pyramid,
[P2, P3, P4, P5]. Each has a different resolution.
image_meta: [batch, (meta data)] Image details. See compose_image_meta()
pool_size: The width of the square feature map generated from ROI Pooling.
num_classes: number of classes, which determines the depth of the results
train_bn: Boolean. Train or freeze Batch Norm layers
Returns: Masks [batch, roi_count, height, width, num_classes]
"""
# ROI Pooling
# Shape: [batch, boxes, pool_height, pool_width, channels]
x = PyramidROIAlign([pool_size, pool_size],
name="roi_align_mask")([rois, image_meta] + feature_maps)
# Conv layers
x = KL.TimeDistributed(KL.Conv2D(256, (3, 3), padding="same"),
name="mrcnn_mask_conv1")(x)
x = KL.TimeDistributed(BatchNorm(),
name='mrcnn_mask_bn1')(x, training=train_bn)
x = KL.Activation('relu')(x)
x = KL.TimeDistributed(KL.Conv2D(256, (3, 3), padding="same"),
name="mrcnn_mask_conv2")(x)
x = KL.TimeDistributed(BatchNorm(),
name='mrcnn_mask_bn2')(x, training=train_bn)
x = KL.Activation('relu')(x)
x = KL.TimeDistributed(KL.Conv2D(256, (3, 3), padding="same"),
name="mrcnn_mask_conv3")(x)
x = KL.TimeDistributed(BatchNorm(),
name='mrcnn_mask_bn3')(x, training=train_bn)
x = KL.Activation('relu')(x)
x = KL.TimeDistributed(KL.Conv2D(256, (3, 3), padding="same"),
name="mrcnn_mask_conv4")(x)
x = KL.TimeDistributed(BatchNorm(),
name='mrcnn_mask_bn4')(x, training=train_bn)
x = KL.Activation('relu')(x)
x = KL.TimeDistributed(KL.Conv2DTranspose(256, (2, 2), strides=2, activation="relu"),
name="mrcnn_mask_deconv")(x)
x = KL.TimeDistributed(KL.Conv2D(num_classes, (1, 1), strides=1, activation="sigmoid"),
name="mrcnn_mask")(x)
return x
有一个细节需要注意的就是1.6经过PyramidROIAlign得到的特征图是7*7大小的,二1.7经过PyramidROIAlign得到的特征图大小是14*14
最后的返回值是:
Returns: Masks [batch, roi_count, height, width, num_classes]
损失函数
maskrcnn中总共有五个损失函数,分别是rpn网络的两个损失,分类的两个损失,以及mask分支的损失函数。前四个损失函数与fasterrcnn的损失函数一样,最后的mask损失函数的采用的是mask分支对于每个RoI有Km2 维度的输出。K个(类别数)分辨率为m*m的二值mask。
因此作者利用了a per-pixel sigmoid,并且定义 Lmask 为平均二值交叉熵损失(the average binary cross-entropy loss).
对于一个属于第k个类别的RoI, Lmask 仅仅考虑第k个mask(其他的掩模输入不会贡献到损失函数中)。这样的定义会允许对每个类别都会生成掩模,并且不会存在类间竞争。
# Losses
rpn_class_loss = KL.Lambda(lambda x: rpn_class_loss_graph(*x), name="rpn_class_loss")(
[input_rpn_match, rpn_class_logits])
rpn_bbox_loss = KL.Lambda(lambda x: rpn_bbox_loss_graph(config, *x), name="rpn_bbox_loss")(
[input_rpn_bbox, input_rpn_match, rpn_bbox])
class_loss = KL.Lambda(lambda x: mrcnn_class_loss_graph(*x), name="mrcnn_class_loss")(
[target_class_ids, mrcnn_class_logits, active_class_ids])
bbox_loss = KL.Lambda(lambda x: mrcnn_bbox_loss_graph(*x), name="mrcnn_bbox_loss")(
[target_bbox, target_class_ids, mrcnn_bbox])
mask_loss = KL.Lambda(lambda x: mrcnn_mask_loss_graph(*x), name="mrcnn_mask_loss")(
[target_mask, target_class_ids, mrcnn_mask])
总的模型
上面只是介绍了模型的每一步,要把各个模型串联起来,才可以形成一个整体的网络,网络的整体定义如下:
# Model
inputs = [input_image, input_image_meta,
input_rpn_match, input_rpn_bbox, input_gt_class_ids, input_gt_boxes, input_gt_masks]
if not config.USE_RPN_ROIS:
inputs.append(input_rois)
outputs = [rpn_class_logits, rpn_class, rpn_bbox,
mrcnn_class_logits, mrcnn_class, mrcnn_bbox, mrcnn_mask,
rpn_rois, output_rois,
rpn_class_loss, rpn_bbox_loss, class_loss, bbox_loss, mask_loss]
model = KM.Model(inputs, outputs, name='mask_rcnn')
以上整体总结:

两次Score排序,两次roi align, 两次box delta (一次是anchor+region proposal= rois, 一次是rois+回归误差 = detections)
或者是对feature map访问了3次,第一次做RPN;第二次,ROI align进行坐标的回归调整和类别判断;第三次,ROI align计算mask
1: 首先是在网络创建的时候生成所有的anchor
2: 然后是函数rpn对不同的feature map生成region proposal — region proposal 的意义是在anchor上的delta
3: (这里score第一次排序–从261888-1000)函数proposal_layer内排序,结合所有的(anchor和RPN生成ROI),并且排序取前1000个ROI 得到1000个roi box
4-1: 然后是函数classifier,对有1000个roi进行(ROI algin,第一次), 生成每个roi的物体类别(1000,81)的输出和对于ROI的坐标偏移(1000,81,4)的输出
4-2: 在对81个类别取最大(score排序第二次排序—从1000-16),认为类别最大所对应的score和Box delta,就是roi的score和detla,这样就可以对每个ROI的score赋值,(同时调整box的delta)
5: 在获得detection (16,6)的结果以后,在回到原来的feature map list上做(ROI algin,第二次),然后生成各个类别的mask
另外凡是和坐标相关的数据,比如RPN的输出,回归调整坐标的输出,ROI align的输入,涉及到网络输出的坐标数据肯定是小数,另外需要把坐标值作为输入的也是小数
关于box deltas的地方有一个比较搞的地方是 [dy,dx,log(dh),log(dw)] 这里的dy,dx,log(dh),log(dw)都是相对于传入box的高度和宽度来计算,传入box的坐标值也可以为像素意义,也可以为归一化的意义
参考:
https://blog.csdn.net/WZZ18191171661/article/details/79453780
https://blog.csdn.net/xiamentingtao/article/details/78598511
https://blog.csdn.net/qinghuaci666/article/details/80900882
https://blog.csdn.net/qinghuaci666/article/details/80920202
https://zhuanlan.zhihu.com/p/22976342

学大模型,用大模型上飞桨星河社区!每天8点V100G算力免费领!免费领取ERNIE 4.0 100w Token >>>
更多推荐



 231
231 2
2- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)