
卡尔曼滤波详解
Kalman Filter简单介绍主要讲解基本的卡尔曼滤波算法,有时候也说是离散或者线性卡尔曼滤波。首先来看一个数学公式,这部分仅仅是给定一个思路,和最后实际算法无关。目前考虑到要估计当前系统的状态,而且有两个已知量,一个上一个状态的估计值以及当前状态的测量值,这两个都有一定的噪声,需要做的就是把这两个结合起来,很简单的思路就是按照比例相加得到当前状态的估计值:X^k=Kk⋅Zk+(1−K...
这篇主要介绍卡尔曼滤波公式详细推导,使用示例参考卡尔曼滤波示例。
Kalman Filter
简单介绍
主要讲解基本的卡尔曼滤波算法,有时候也说是离散或者线性卡尔曼滤波。
首先来看一个数学公式,这部分仅仅是给定一个思路,和最后实际算法无关。目前考虑到要估计当前系统的状态,而且有两个已知量,一个上一个状态的估计值以及当前状态的测量值,这两个都有一定的噪声,需要做的就是把这两个结合起来,很简单的思路就是按照比例相加得到当前状态的估计值:
X
^
k
=
K
k
⋅
Z
k
+
(
1
−
K
k
)
⋅
X
^
k
−
1
\hat{X}_k = K_k \cdot Z_k + (1 - K_k) \cdot \hat{X}_{k-1}
X^k=Kk⋅Zk+(1−Kk)⋅X^k−1
k k k 表示离散的状态量,可以把它简单的理解为离散的时间间隔。k=1 表示1ms,k=2 表示2ms;
X ^ k \hat{X}_k X^k 是对当前状态的估计值,希望利用上面的公式对每一个 k 都能得到一个较为准确的 X 的值;
Z k Z_k Zk 是对当前状态的测量值,当然这个值并不是绝对准确的,会有一定的误差噪声(如果绝对准确,直接用就可以了,也就没必要搞这个卡尔曼滤波算法了);
X ^ k − 1 \hat{X}_{k-1} X^k−1 是对上一状态的估计值,利用这个以及测量值对当前状态进行估计;
K k K_k Kk 是卡尔曼增益(kalman gain),在这里唯一未知的就是这个值,也是需要去求的值。当然可以直接设置值为0.5,但是这样比较暴力。最好的方式就是根据每一时刻的状态求一个当前状态最好的增益值,这样的话更好利用以前状态的估计值以及当前测量值来估计一个最优的当前值。
后面卡尔曼滤波算法就是按照上面思路利用上一状态以及测量值去估计当前状态,只不过模型要更加复杂。
基本模型
卡尔曼滤波的状态方程,利用线性随机差分方程(Linear Stochastic Difference equation)利用上一个系统状态估计当前系统状态(这里假设上一状态与下一一状态有某种线性关系,比如恒温环境的温度,匀速运动的速度等,但是因为现实环境的复杂,这种线性关系不是完全平滑的,也就是会有一些扰动):
x
k
=
A
x
k
−
1
+
B
u
k
−
1
+
w
x_k = Ax_{k-1} + Bu_{k-1}+w
xk=Axk−1+Buk−1+w
使用时一般忽略
u
u
u 控制输入,得到:
x
k
=
A
x
k
−
1
+
w
(
1.1
)
x_k = Ax_{k-1} + w \qquad {(1.1)}
xk=Axk−1+w(1.1)
加上对于当前状态的测量方程(简单来说就是测量值和状态值的线性函数):
z
k
=
H
x
k
+
v
(
1.2
)
z_k = Hx_k + v \qquad {(1.2)}
zk=Hxk+v(1.2)
k − 1 k-1 k−1 和 k k k 分别表示上一状态和当前状态;
x ∈ R n x \in R^n x∈Rn 表示要估计的状态;
A ∈ R n × n A \in R^{n \times n} A∈Rn×n 表示上一状态到当前状态的转换矩阵;
u ∈ R l u \in R^l u∈Rl 表示可选的控制输入,一般在实际使用中忽略;
B ∈ R n × l B \in R^{n \times l} B∈Rn×l 表示控制输入到当前状态的转换矩阵;
z ∈ R m z \in R^m z∈Rm 表示测量值;
H ∈ R m × n H \in R^{m \times n} H∈Rm×n 表示当前状态到测量的转换矩阵;
w ∈ R n w \in R^n w∈Rn 表示过程噪声,主要是从上一状态进入到当前状态时,会有许多外界因素的干扰;
v ∈ R m v \in R^m v∈Rm 表示测量噪声,主要是任何测量仪器都会有一定的误差;
在上面转换矩阵 A A A B B B H H H w w w v v v 是随着状态变化的,在这里没有添加下标,假设是不变的。
上面提到的过程噪声
w
w
w 和测量噪声
v
v
v 假设是相互独立的(之间没有关系,无相互影响),且是高斯白噪声,意思是这些噪声在离散的状态上是没有关系的(互相独立的, 每个时刻的噪声都是独立的)且 服从高斯分布:
p
(
w
)
∼
N
(
0
,
Q
)
(
1.3
)
p
(
v
)
∼
N
(
0
,
R
)
(
1.4
)
Q
=
w
w
T
R
=
v
v
T
E
(
w
)
=
0
E
(
v
)
=
0
\begin{aligned} p(w) & \sim N(0, Q) \qquad {(1.3)} \\ p(v) & \sim N(0, R) \qquad {(1.4)} \\ Q & = ww^T \\ R & = vv^T \\ E(w) & = 0 \\ E(v) & = 0 \end{aligned}
p(w)p(v)QRE(w)E(v)∼N(0,Q)(1.3)∼N(0,R)(1.4)=wwT=vvT=0=0
Q ∈ R n × n Q \in R^{n \times n} Q∈Rn×n 表示过程噪声 w w w 的协方差矩阵,表示 w w w 向量元素之间的相关关系;
R ∈ R m × m R \in R^{m \times m} R∈Rm×m 表示测量噪声 v v v 的协方差矩阵,表示 v v v 向量元素之间的相关关系;
在上面协方差矩阵 Q Q Q R R R 是随着状态变化的,在这里假设是不变的。
推导过程
上面是给出了卡尔曼滤波的整体思路和基本模型,在这里一步步分解来看卡尔曼滤波的推导过程。首先确定了卡尔曼滤波的基本模型,那么下一步是怎样根据这个模型来不断求取后面的状态。
首先定义几个变量:
x ^ k ˉ \bar{\hat{x}_k} x^kˉ 加了一个负号上标,表示仅仅利用过程先验知识求出的当前状态的先验状态估计(a priori state estimate),不考虑过程噪声的情况下;
x ^ k \hat{x}_k x^k 表示利用测量值 z k z_k zk 求出的当前状态的后验状态估计(a posteriori state estimate),也是最终求得的状态;
需要注意的是,卡尔曼滤波的最终目标是求 x ^ k \hat{x}_k x^k ,这是对当前状态的最优估计。
根据上面的定义忽略过程噪声可以得到:
x
^
k
ˉ
=
A
x
^
k
−
1
+
B
u
k
−
1
\bar{\hat{x}_k} = A\hat{x}_{k-1} + Bu_{k-1}
x^kˉ=Ax^k−1+Buk−1
通常都是忽略
u
u
u 这个可选的控制输入(以后加入该变量的话也是非常方便的):
x
^
k
ˉ
=
A
x
^
k
−
1
(
2.1
)
\bar{\hat{x}_k} = A\hat{x}_{k-1} \qquad {(2.1)}
x^kˉ=Ax^k−1(2.1)
然后同理忽略测量噪声可以得到:
z
k
ˉ
=
H
x
^
k
ˉ
\begin{aligned} \bar{z_k} & = H\bar{\hat{x}_k} \end{aligned}
zkˉ=Hx^kˉ
z k ˉ \bar{z_k} zkˉ 表示忽略测量噪声根据当前先验状态得到的无噪声测量值。
那么很简单的可以用实际得到的测量值减去无噪声由上一状态预测的测量值:
z
k
˙
=
z
k
−
z
k
ˉ
=
z
k
−
H
x
^
k
ˉ
\begin{aligned} \dot{z_k} & = z_k - \bar{z_k} \\ & = z_k - H\bar{\hat{x}_k} \end{aligned}
zk˙=zk−zkˉ=zk−Hx^kˉ
z k ˙ \dot{z_k} zk˙ 表示实际测量值(包含了上面提到的各种干扰即过程噪声以及测量噪声)减去无噪声测量值,一般被叫做measurement innovation 或者是 residual,表示预测的测量值和实际测量值的差异。实际得到是过程噪声和测量噪声对当前测量值的影响(当然也会影响当前状态),也就是包含了 w w w 和 v v v 的情况。
现在得到了一个无噪声的状态的估计
x
^
k
ˉ
\bar{\hat{x}_k}
x^kˉ,以及一个噪声变量
z
k
˙
\dot{z_k}
zk˙。根据经验来说把这两个值按照一定的方式整合起来就可以得到后验状态估计。卡尔曼滤波中采用按照比例组合的方式(其实对于下面的公式在数学上有严格的证明过程,但是仅仅是使用卡尔曼滤波就不去深究了):
x
^
k
=
x
^
k
ˉ
+
K
k
z
k
˙
=
x
^
k
ˉ
+
K
k
(
z
k
−
H
x
^
k
ˉ
)
(
2.2
)
\begin{aligned} \hat{x}_k & = \bar{\hat{x}_k} + K_k\dot{z_k} \\ & = \bar{\hat{x}_k} + K_k(z_k - H\bar{\hat{x}_k}) \qquad {(2.2)} \end{aligned}
x^k=x^kˉ+Kkzk˙=x^kˉ+Kk(zk−Hx^kˉ)(2.2)
K k ∈ R n × m K_k \in R^{n \times m} Kk∈Rn×m 表示卡尔曼增益(gain)或者均化系数(blending factor)。
到这里,有了上面的公式(2.2),为了得到
x
^
k
\hat{x}_k
x^k,其他参数都是已知的,目前需要把每个状态的
K
k
K_k
Kk 求出来,这里定义先验和后验估计误差:
e
k
ˉ
≡
x
k
−
x
^
k
ˉ
e
k
≡
x
k
−
x
^
k
\bar{e_k} \equiv x_k - \bar{\hat{x}_k} \\ e_k \equiv x_k - \hat{x}_k
ekˉ≡xk−x^kˉek≡xk−x^k
对应的误差协方差矩阵为:
P
k
ˉ
=
E
[
e
k
ˉ
e
ˉ
k
T
]
P
k
=
E
[
e
k
e
k
T
]
\bar{P_k} = E[\bar{e_k}\bar{e}_{k}^T] \\ P_k = E[e_ke_{k}^T]
Pkˉ=E[ekˉeˉkT]Pk=E[ekekT]
然后为了使后验状态估计
x
^
k
\hat{x}_k
x^k 最优,那么目标就是最小化后验状态估计的误差协方差矩阵
P
k
P_k
Pk 值。
后验误差
根据公式(1.1),(2.2),(1.2),(2.1)可以得到:
e
k
=
x
k
−
x
^
k
=
x
k
−
(
x
^
k
ˉ
+
K
k
(
z
k
−
H
x
^
k
ˉ
)
)
=
x
k
−
(
x
^
k
ˉ
+
K
k
(
(
H
x
k
+
v
)
−
H
x
^
k
ˉ
)
)
=
x
k
−
x
^
k
ˉ
−
K
k
H
x
k
−
K
k
v
+
K
k
H
x
^
k
ˉ
=
(
I
−
K
k
H
)
(
x
k
−
x
^
k
ˉ
)
−
K
k
v
=
(
I
−
K
k
H
)
e
k
ˉ
−
K
k
v
\begin{aligned} e_k & = x_k - \hat{x}_k \\ & = x_k - (\bar{\hat{x}_k} + K_k(z_k - H\bar{\hat{x}_k})) \\ & = x_k - (\bar{\hat{x}_k} + K_k((Hx_k + v) - H\bar{\hat{x}_k})) \\ & = x_k - \bar{\hat{x}_k} - K_kHx_k - K_kv + K_kH\bar{\hat{x}_k} \\ & = (I - K_kH)(x_k-\bar{\hat{x}_k}) - K_kv \\ & = (I - K_kH)\bar{e_k} - K_kv \end{aligned}
ek=xk−x^k=xk−(x^kˉ+Kk(zk−Hx^kˉ))=xk−(x^kˉ+Kk((Hxk+v)−Hx^kˉ))=xk−x^kˉ−KkHxk−Kkv+KkHx^kˉ=(I−KkH)(xk−x^kˉ)−Kkv=(I−KkH)ekˉ−Kkv
所以带入展开可得:
e
k
e
k
T
=
[
(
I
−
K
k
H
)
e
k
ˉ
−
K
k
v
]
[
(
I
−
K
k
H
)
e
k
ˉ
−
K
k
v
]
T
=
(
I
−
K
k
H
)
e
k
ˉ
e
k
ˉ
T
(
I
−
K
k
H
)
T
−
K
k
v
e
k
ˉ
T
(
I
−
K
k
H
)
T
−
(
I
−
K
k
H
)
e
k
ˉ
v
T
K
k
T
+
K
k
v
v
T
K
k
T
\begin{aligned} e_ke_{k}^T & = \left[ (I - K_kH)\bar{e_k} - K_kv \right]\left[ (I - K_kH)\bar{e_k} - K_kv \right]^T \\ & = (I - K_kH)\bar{e_k}\bar{e_k}^T(I - K_kH)^T - K_kv\bar{e_k}^T(I - K_kH)^T - (I - K_kH)\bar{e_k}v^TK_k^T + K_kvv^TK_k^T \end{aligned}
ekekT=[(I−KkH)ekˉ−Kkv][(I−KkH)ekˉ−Kkv]T=(I−KkH)ekˉekˉT(I−KkH)T−KkvekˉT(I−KkH)T−(I−KkH)ekˉvTKkT+KkvvTKkT
又
e
k
ˉ
\bar{e_k}
ekˉ 是
z
1
,
⋯
,
z
k
−
1
z_{1} , \cdots , z_{k - 1}
z1,⋯,zk−1 的线性函数,和当前
z
k
z_k
zk 无关,所以:
E ( e k ˉ v T ) = 0 E ( v e k ˉ T ) = 0 E(\bar{e_k}v^T) = 0 \\ E(v\bar{e_k}^T) = 0 E(ekˉvT)=0E(vekˉT)=0
带入整理得到:
P
k
=
E
[
e
k
e
k
T
]
=
(
I
−
K
k
H
)
P
k
ˉ
(
I
−
K
k
H
)
T
+
K
k
R
K
k
T
=
P
k
ˉ
−
K
k
H
P
k
ˉ
−
P
k
ˉ
H
T
K
k
T
+
K
k
H
P
k
ˉ
H
T
K
k
T
+
K
k
R
K
k
T
\begin{aligned} P_k = E[e_ke_{k}^T] & = (I-K_kH)\bar{P_k}(I - K_kH)^T + K_kRK_k^T \\ & = \bar{P_k} - K_kH\bar{P_k} - \bar{P_k}H^TK_k^T + K_kH\bar{P_k}H^TK_k^T + K_kRK_k^T \end{aligned}
Pk=E[ekekT]=(I−KkH)Pkˉ(I−KkH)T+KkRKkT=Pkˉ−KkHPkˉ−PkˉHTKkT+KkHPkˉHTKkT+KkRKkT
合并
K
k
K_k
Kk 项目:
P
k
=
P
k
ˉ
−
P
k
ˉ
H
T
(
H
P
k
ˉ
H
T
+
R
)
−
1
H
P
k
ˉ
+
[
K
k
−
P
k
ˉ
H
T
(
H
P
k
ˉ
H
T
+
R
)
−
1
]
(
H
P
k
ˉ
H
T
+
R
)
[
K
k
−
P
k
ˉ
H
T
(
H
P
k
ˉ
H
T
+
R
)
−
1
]
T
\begin{aligned} P_k & = \bar{P_k} - \bar{P_k}H^T(H\bar{P_k}H^T + R)^{-1}H\bar{P_k} \\ & + \left[ K_k - \bar{P_k}H^T(H\bar{P_k}H^T + R)^{-1}\right ](H\bar{P_k}H^T + R)\left[K_k - \bar{P_k}H^T(H\bar{P_k}H^T + R)^{-1} \right ]^T \end{aligned}
Pk=Pkˉ−PkˉHT(HPkˉHT+R)−1HPkˉ+[Kk−PkˉHT(HPkˉHT+R)−1](HPkˉHT+R)[Kk−PkˉHT(HPkˉHT+R)−1]T
具体合并的过程其实利用最基本的矩阵运算就可以解决,这里主要是矩阵运算可能不那么直观,如果把它想象成正常的以 K k K_k Kk
为未知数的一元二次方程,可能就很好理解了。首先我们目标是合并 K k K_k Kk 项,先考虑二次项部分: K k H P k ˉ H T K k T + K k R K k T = K k ( H P k ˉ H T + R ) K k T \begin{aligned} K_kH\bar{P_k}H^TK_k^T + K_kRK_k^T & =K_k(H\bar{P_k}H^T + R)K_k^T \end{aligned} KkHPkˉHTKkT+KkRKkT=Kk(HPkˉHT+R)KkT 然后把剩余的两个一次项添加上面合并好的二次项里面,为了抵消上面中间项 H P k ˉ H T + R H\bar{P_k}H^T + R HPkˉHT+R,所以在添加的时候会额外乘以一个 ( H P k ˉ H T + R ) − 1 (H\bar{P_k}H^T + R)^{-1} (HPkˉHT+R)−1,然后直接就合并好了所有的 K k K_k Kk 项: [ K k − P k ˉ H T ( H P k ˉ H T + R ) − 1 ] ( H P k ˉ H T + R ) [ K k − P k ˉ H T ( H P k ˉ H T + R ) − 1 ] T \left[ K_k - \bar{P_k}H^T(H\bar{P_k}H^T + R)^{-1}\right ](H\bar{P_k}H^T + R)\left[K_k - \bar{P_k}H^T(H\bar{P_k}H^T + R)^{-1} \right ]^T [Kk−PkˉHT(HPkˉHT+R)−1](HPkˉHT+R)[Kk−PkˉHT(HPkˉHT+R)−1]T 当然这里还有个问题是上面合并项里面会多出来一下之前不存在的项,把上面合并好的公式展开然后减去最开始的 K k K_k Kk
项,得到了不包含 K k K_k Kk 项的一些补偿项,这样把补偿项添加回去就完成了。
上面的式子中前两项不包含
K
k
K_k
Kk 因子,所以如果要最小化
P
k
P_k
Pk,只需:
K
k
−
P
k
ˉ
H
T
(
H
P
k
ˉ
H
T
+
R
)
−
1
=
0
K_k - \bar{P_k}H^T(H\bar{P_k}H^T + R)^{-1} = 0
Kk−PkˉHT(HPkˉHT+R)−1=0
所以得到:
K
k
=
P
k
ˉ
H
T
(
H
P
k
ˉ
H
T
+
R
)
−
1
(
2.5
)
K_k = \bar{P_k}H^T(H\bar{P_k}H^T + R)^{-1} \qquad {(2.5)}
Kk=PkˉHT(HPkˉHT+R)−1(2.5)
然后可以得到:
P
k
=
(
I
−
K
k
H
)
P
k
ˉ
(
2.4
)
P_k = (I-K_kH)\bar{P_k} \qquad {(2.4)}
Pk=(I−KkH)Pkˉ(2.4)
先验误差
带入上面的公式(1.1),(2.1)可以得到:
e
k
ˉ
=
x
k
−
x
^
ˉ
k
=
(
A
x
k
−
1
+
w
)
−
(
A
x
^
k
−
1
)
=
A
(
x
k
−
1
−
x
^
k
−
1
)
+
w
=
A
e
k
−
1
+
w
\begin{aligned} \bar{e_k} & = x_k - \bar{\hat{x}}_k \\ & = (Ax_{k-1} + w) - (A\hat{x}_{k-1}) \\ & = A(x_{k-1} - \hat{x}_{k-1}) + w \\ & = Ae_{k-1} + w \end{aligned}
ekˉ=xk−x^ˉk=(Axk−1+w)−(Ax^k−1)=A(xk−1−x^k−1)+w=Aek−1+w
所以带入展开可得:
e
k
ˉ
e
ˉ
k
T
=
(
A
e
k
−
1
+
w
)
(
A
e
k
−
1
+
w
)
T
=
A
e
k
−
1
e
k
−
1
T
A
T
+
w
w
T
+
w
e
k
−
1
T
A
T
+
A
e
k
−
1
w
T
\begin{aligned} \bar{e_k}\bar{e}_{k}^T & = (Ae_{k-1} + w)(Ae_{k-1} + w)^T \\ & = Ae_{k-1}e_{k-1}^TA^T + ww^T + we_{k-1}^TA^T + Ae_{k-1}w^T \end{aligned}
ekˉeˉkT=(Aek−1+w)(Aek−1+w)T=Aek−1ek−1TAT+wwT+wek−1TAT+Aek−1wT
又因为:
E
(
e
k
−
1
w
T
)
=
0
E
(
w
e
k
−
1
T
)
=
0
E(e_{k-1}w^T) = 0 \\ E(we_{k-1}^T) = 0
E(ek−1wT)=0E(wek−1T)=0
然后可以得到:
P
k
ˉ
=
E
[
e
k
ˉ
e
ˉ
k
T
]
=
A
P
k
−
1
A
T
+
Q
(
2.3
)
\bar{P_k} = E[\bar{e_k}\bar{e}_{k}^T] = AP_{k-1}A^T + Q \qquad {(2.3)}
Pkˉ=E[ekˉeˉkT]=APk−1AT+Q(2.3)
基本分析
从上面的公式可以看出来,如果过程误差 P k ˉ = 0 \bar{P_k} = 0 Pkˉ=0 ,那么 K k = 0 K_k = 0 Kk=0 ,可以 得到 x ^ k = x ^ k ˉ = A x ^ k − 1 \hat{x}_k = \bar{\hat{x}_k} = A\hat{x}_{k-1} x^k=x^kˉ=Ax^k−1 ,完全相信以前估计的值,这样就是为啥不能设置 P 0 = 0 P_0 = 0 P0=0 。当然给 Q Q Q 赋值可能能解决这个问题,而且不能设置太小,这样手动引入较大的过程误差,估计结果很不平滑,后面示例3也会讲解。对于 R R R 的变化对结果的作用后面的示例会介绍,同理 R R R 设置太大也会导致这样的结果。在这种情况下,如果初始时设置的不正确,整个估计都是错误的。
基本公式
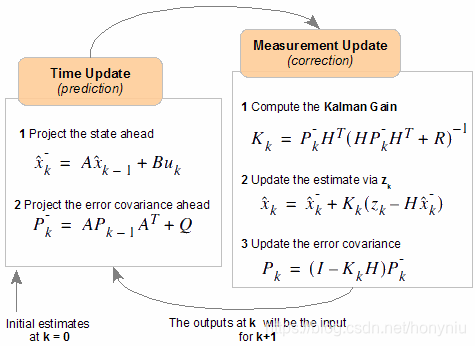
最后得到了上面的上面(2.1)-(2.5)五个方程式,是经典的卡尔曼滤波的五个基本公式,利用这五个公式就可以完成卡尔曼滤波的求解过程。根据迭代过程分成两个方程集合,一个是time update方程,一个是measurement update方程,如下:
| Time Update | Measurement Update |
|---|---|
| x ^ k ˉ = A x ^ k − 1 \bar{\hat{x}_k} = A\hat{x}_{k-1} x^kˉ=Ax^k−1 | K k = P k ˉ H T ( H P k ˉ H T + R ) − 1 K_k = \bar{P_k}H^T(H\bar{P_k}H^T + R)^{-1} Kk=PkˉHT(HPkˉHT+R)−1 |
| P k ˉ = A P k − 1 A T + Q \bar{P_k} = AP_{k-1}A^T + Q Pkˉ=APk−1AT+Q | x ^ k = x ^ k ˉ + K k ( z k − H x ^ k ˉ ) \hat{x}_k = \bar{\hat{x}_k} + K_k(z_k - H\bar{\hat{x}_k}) x^k=x^kˉ+Kk(zk−Hx^kˉ) |
| P k = ( I − K k H ) P k ˉ P_k = (I - K_kH)\bar{P_k} Pk=(I−KkH)Pkˉ |
迭代过程
得到上面的基本公式以后,就可以计算计算后面的状态,但是公式中有一些参数是未知的,需要定义,如下:
u u u 变量一般来说是被忽略的;
A A A , B B B , H H H 上面提到对于每个状态 k k k 都是相同的,同时大部分情况下都是单位矩阵(复杂的计算这里不考虑,由具体应用决定);
R R R 一般来说是相对简单可以求到的,就是仪器的噪声协方差;
Q Q Q 就很难直接的获得,也没有特定的方法,一般是系统过程比较稳定,也就是没有过程噪声;
z z z 所有状态的的测量值都是由仪器测量得到的是已知的;
对于 R R R 和 Q Q Q 的取值来说不是特别重要,虽然可能这两个参数估计的不是很准确(不可能符合纯粹的高斯或者正太分布),但是实际情况中卡尔曼滤波算法也可以得到整的比较准确态估计,但是需要记住的是:
The better you estimate the noise parameters, the better estimates you get.
那么这样只需要传入基本的 x ^ 0 \hat{x}_0 x^0 和 P 0 P_0 P0 就可以了,一般来说需要进行指定。对于 x ^ 0 \hat{x}_0 x^0 来说不需要什么技巧,因为随着卡尔曼滤波算法的运行, x x x 会逐渐的收敛。但是对于 P 0 P_0 P0 ,一般不要取0,因为这样可能会令卡尔曼完全相信你给定的 x ^ 0 \hat{x}_0 x^0 是系统最优的,从而使算法不能收敛。
算法迭代过程如下图(其中 u u u 控制输入一般是忽略的):
参考
- Kalman Filter For Dummies
- Greg Welch, Gary Bishop, “An Introduction to the Kalman Filter”, University of North Carolina at Chapel Hill Department of Computer Science, 2001
- 一个应用实例详解卡尔曼滤波及其算法实现
- 卡尔曼滤波算法–核心公式推导导论

学大模型,用大模型上飞桨星河社区!每天8点V100G算力免费领!免费领取ERNIE 4.0 100w Token >>>
更多推荐


 144
144 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)