
k折交叉验证
一般情况将K折交叉验证用于模型调优,找到使得模型泛化性能最优的超参值。,找到后,在全部训练集上重新训练模型,并使用独立测试集对模型性能做出最终评价。 K折交叉验证使用了无重复抽样技术的好处:每次迭代过程中每个样本点只有一次被划入训练集或测试集的机会。K折交叉验证图:如果训练数据集相对较小,则增大k值。增大k值,在每次迭代过程中将会有更多的数据用于模型训练,能够得到最小偏差,同时算法时间延长。且训练
一般情况将K折交叉验证用于模型调优,找到使得模型泛化性能最优的超参值。,找到后,在全部训练集上重新训练模型,并使用独立测试集对模型性能做出最终评价。
K折交叉验证使用了无重复抽样技术的好处:每次迭代过程中每个样本点只有一次被划入训练集或测试集的机会。
K折交叉验证图:
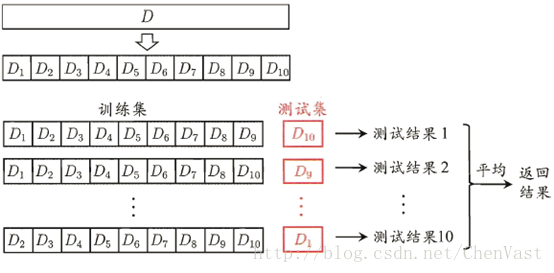

如果训练数据集相对较小,则增大k值。
增大k值,在每次迭代过程中将会有更多的数据用于模型训练,能够得到最小偏差,同时算法时间延长。且训练块间高度相似,导致评价结果方差较高。
如果训练集相对较大,则减小k值。
减小k值,降低模型在不同的数据块上进行重复拟合的性能评估的计算成本,在平均性能的基础上获得模型的准确评估。
K折交叉验证的一个特例:
留一(LOO)交叉验证法:将数据子集划分的数量等于样本数(k=n),每次只有一个样本用于测试,数据集非常小时,建议用此方法。
K折交叉验证改进成的 分层K折交叉验证:
获得偏差和方差都低的评估结果,特别是类别比例相差较大时。
实现K折交叉验证:
使用数据集中的类标y_train初始化sklearn.cross_validation模块下的StratifiedKFold迭代器,通过n_folds参数设置块的数量。
使用kfold在k个块中迭代时,使用train中返回的索引去拟合流水线,通过pipe_lr流水线保证样本都得到适当的缩放。
使用test索引计算模型的准确率,存在score中。
- # 使用k-fold交叉验证来评估模型性能。
- import numpy as np
- from sklearn.cross_validation import StratifiedKFold
- kfold = StratifiedKFold(y=y_train,
- n_folds=10,
- random_state=1)
- scores = []
- for k, (train, test) in enumerate(kfold):
- pipe_lr.fit(X_train[train], y_train[train])
- score = pipe_lr.score(X_train[test], y_train[test])
- scores.append(score)
- print('Fold: %s, Class dist.: %s, Acc: %.3f' % (k+1, np.bincount(y_train[train]), score))
- print('\nCV accuracy: %.3f +/- %.3f' % (np.mean(scores), np.std(scores)))


学大模型,用大模型上飞桨星河社区!每天8点V100G算力免费领!免费领取ERNIE 4.0 100w Token >>>
更多推荐


 50
50 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)