
【综述】CV和NLP领域的Transformer原理和实践
本教程包含BERT、ERNIE等20多个的Transformer类模型的原理讲解,同时配套10+基于Transformer类模型的案例实践,我们一起开始学习吧,相信一定会有很多收获。
CV和NLP领域的Transformer原理和实践
在2017年,Transformer模型由论文《Attention is all you need》提出,最开始被应用于机器翻译任务上并取得了很好的效果。它摒弃了传统LSTM的串行结构,使用了基于Self Attention的模型结构,具有更好的并行计算能力,这使得它在大规模数据模型训练方面更有优势。
后来基于Transformer结构的模型大放异彩,特别是在2018年预训练模型BERT的提出,其在多项NLP任务上均取得了突破性的进展,具有里程碑式的意义。自此,不管是学术界,还是工业界均掀起了基于Transformer的预训练模型研究和应用的热潮,并且逐渐从NLP延伸到CV、语音等多项领域。例如ViT, DETR, TimeSformer分别在图像分类、检测和视频领域全面超过之前SOTA。各种基于Transformer结构的变体模型在模型结构、运行效率和不同领域模型应用等方面纷纷被提出,同时各个领域的多项任务指标更是不断被刷新,深度学习领域进入了一个新的时代。
在这个Transformer类模型发展如火如荼的时代,本着分享和开发的心态,百度研发同学历经多时,打磨并推出了《CV和NLP领域的Transformer》系列教程,本系列教程将包含BERT、ERNIE等20多个的Transformer类模型的原理讲解,同时配套10+基于Transformer类模型的案例实践。
整个教程程结构如图1所示,我们一起开始学习吧,相信一定会有很多收获。
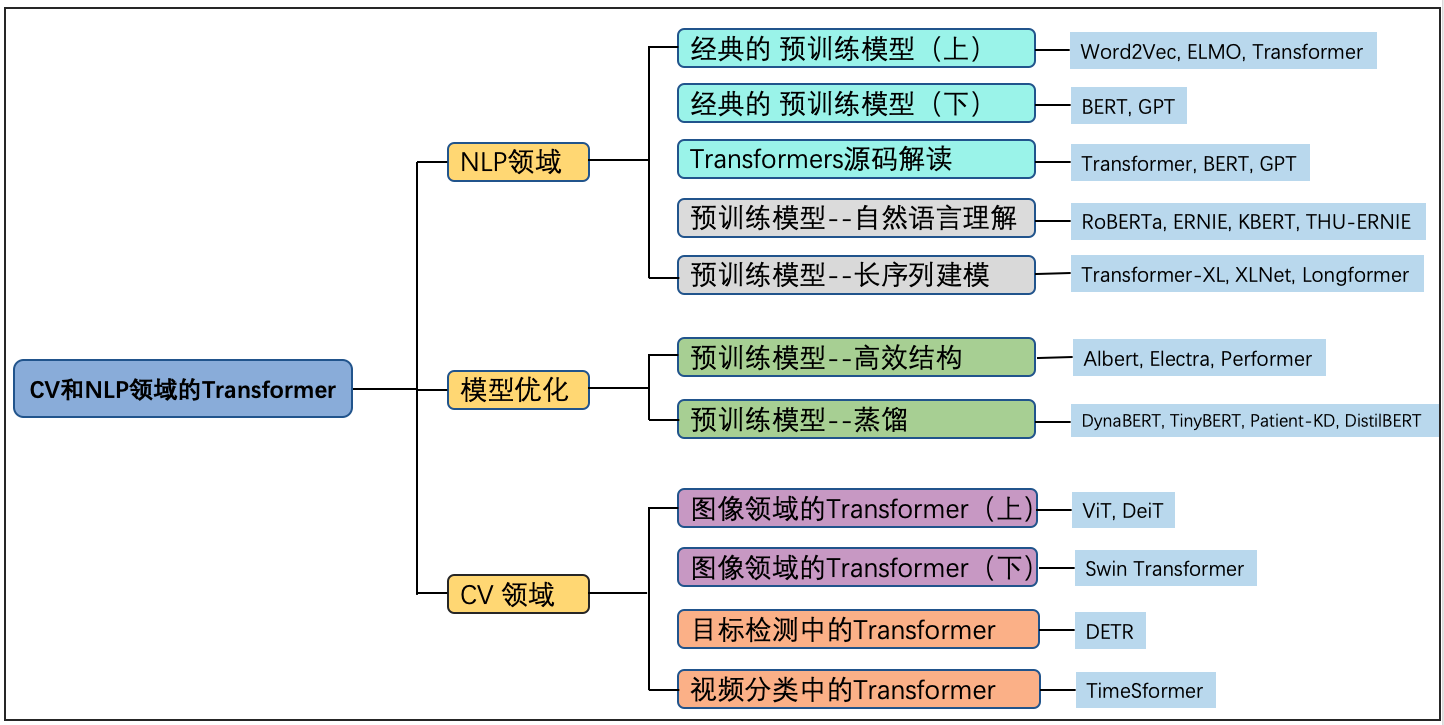
可以看到,教程整体大致可分为三部分:NLP领域、CV领域以及相对通用的模型结构优化技术,涉及20+款模型,整个教程亮点突出,内容丰富。
-
本教程成体系地介绍了前沿预训练模型发展的情况,内容丰富翔实。在当前Transformer类模型如火如荼的背景下,本教程结合前沿模型,将Transformer类模型根据不同方向或领域进行清晰地划分,并根据每个方向展开详尽地讲解。
-
纵向深入剖析经典Transformer模型结构,从原理到源码讲解。 本教程将对经典的Transformer类模型进行深入剖析,包括Transformer、BERT和GPT模型,内容不仅包含原理方面的讲解,更有源码级别的实现分享,保证同学们深刻、透彻地理解这些经典模型。
-
横向展开多个方向的Transformer类模型改进工作。本教程归纳整理了多个方向的模型改进工作,包括预训练模型在自然语言理解、长序列建模、优化的高效结构和蒸馏方向等方向,并对各个不同方向改进的经典模型展开细讲,保证同学们能够深刻地了解到前沿预训练模型的演进方向。
-
前沿CV领域的Transformer类模型讲解。本教程不仅包含经典NLP领域的Transformer类模型,同时更有Transfomer类模型在CV领域的模型讲解,包括图像分类、目标检测和视频分类领域,以便让同学们了解Transformer类模型在不同领域的应用方式,以及Transformer类模型的强大之处。
-
丰富的Transformer类模型实践,原理讲解与实践相结合。本教程设置了10+模型实践内容,从而保证能够学以致用,真真切切地帮助同学们学习各个领域的Transformer类模型。
以下本教程目前开源的模型原理解读和实践:
-
NLP领域
【原理】NLP系列之预训练模型(上):预训练模型发展史
【原理】NLP系列之预训练模型(上):ELMo
【原理】NLP系列之预训练模型(上):Transformer
【原理】NLP系列之预训练模型(下):BERT
【原理】NLP系列之预训练模型(下):GPT
【实践】NLP领域的Transformer在机器翻译上的应用
【原理】预训练模型之自然语言理解:RoBERTa
【原理】预训练模型之自然语言理解:ERNIE
【原理】预训练模型之自然语言理解:KBERT
【原理】预训练模型之自然语言理解:THU-ERNIE
【实践】NLP领域中的ERNIE模型在阅读理解中的应用
【实践】基于ERNIE实现9项GLUE任务
【原理】预训练模型之长序列建模:Transformer-XL
【原理】预训练模型之长序列建模:XLNet
【原理】预训练模型之长序列建模:Longformer
【实践】NLP领域的XLNet模型在情感分析中的应用
-
模型优化
【原理】深度学习中的模型压缩概述与知识蒸馏详解
【原理】预训练模型蒸馏:Patient-KD和DistilBERT
【原理】预训练模型蒸馏:TinyBERT
【原理】预训练模型蒸馏:DynaBERT
【实践】NLP领域的ELECTRA在符号预测上的应用
【实践】预训练模型蒸馏 – 宽度自适应策略蒸馏TinyBERT -
CV领域
【实践】深入理解图像分类中的Transformer-Vit,DeiT
【实践】Swin Transformer
【实践】CV领域的Transformer模型DETR在目标检测任务中的应用
【实践】CV领域的Transformer模型TimeSformer实视频理解
如果同学们对系列教程感兴趣,想了解更多相关信息,请移步我们的官方github: awesome-DeepLearning,也欢迎各位同学点击Star,有大家的支持我们才会走得更远,提供更多优质资源以供学习。同时更多深度学习资料请参阅飞桨深度学习平台。

最后,也欢迎同学们加入我们的官方交流群。

学大模型,用大模型上飞桨星河社区!每天8点V100G算力免费领!免费领取ERNIE 4.0 100w Token >>>
更多推荐


 0
0 0
0- 0



 已为社区贡献1438条内容
已为社区贡献1438条内容

所有评论(0)