
实战PP-TinyPose+PicoDet:智能体测新模式的应用化
训练PP-TinyPose+PicoDet的模型并进行联合部署处理视频,最后进行俯卧撑的逻辑判断
·
实战PP-TinyPose+PicoDet:智能体测新模式的应用化
PP-TinyPose 简介
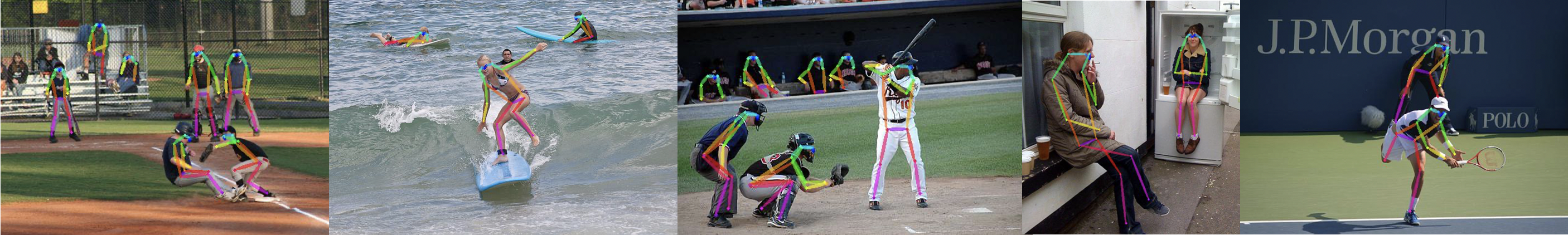
PP-TinyPose是PaddleDetecion针对移动端设备优化的实时姿态检测模型,可流畅地在移动端设备上执行多人姿态估计任务。借助PaddleDetecion自研的优秀轻量级检测模型PicoDet,我们同时提供了特色的轻量级垂类行人检测模型。
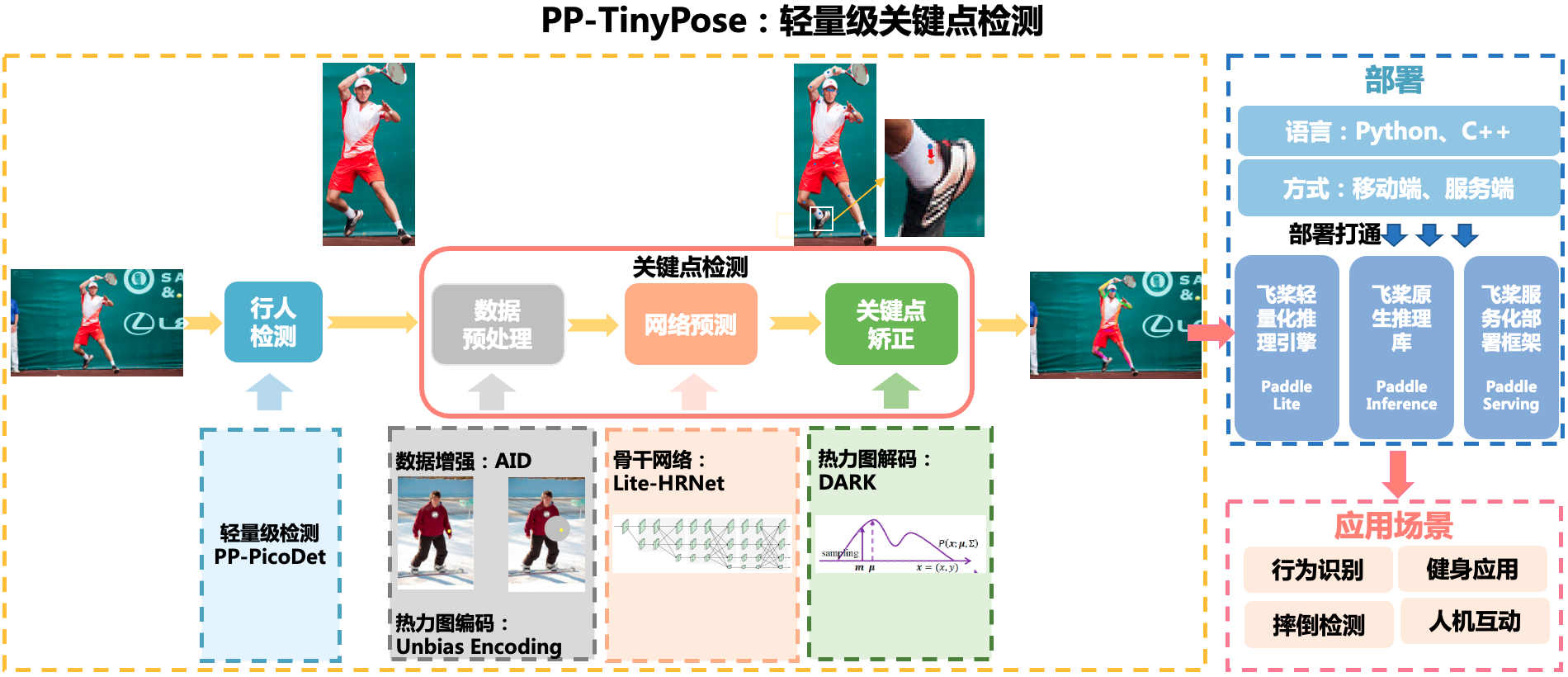
PaddleDetection 简介
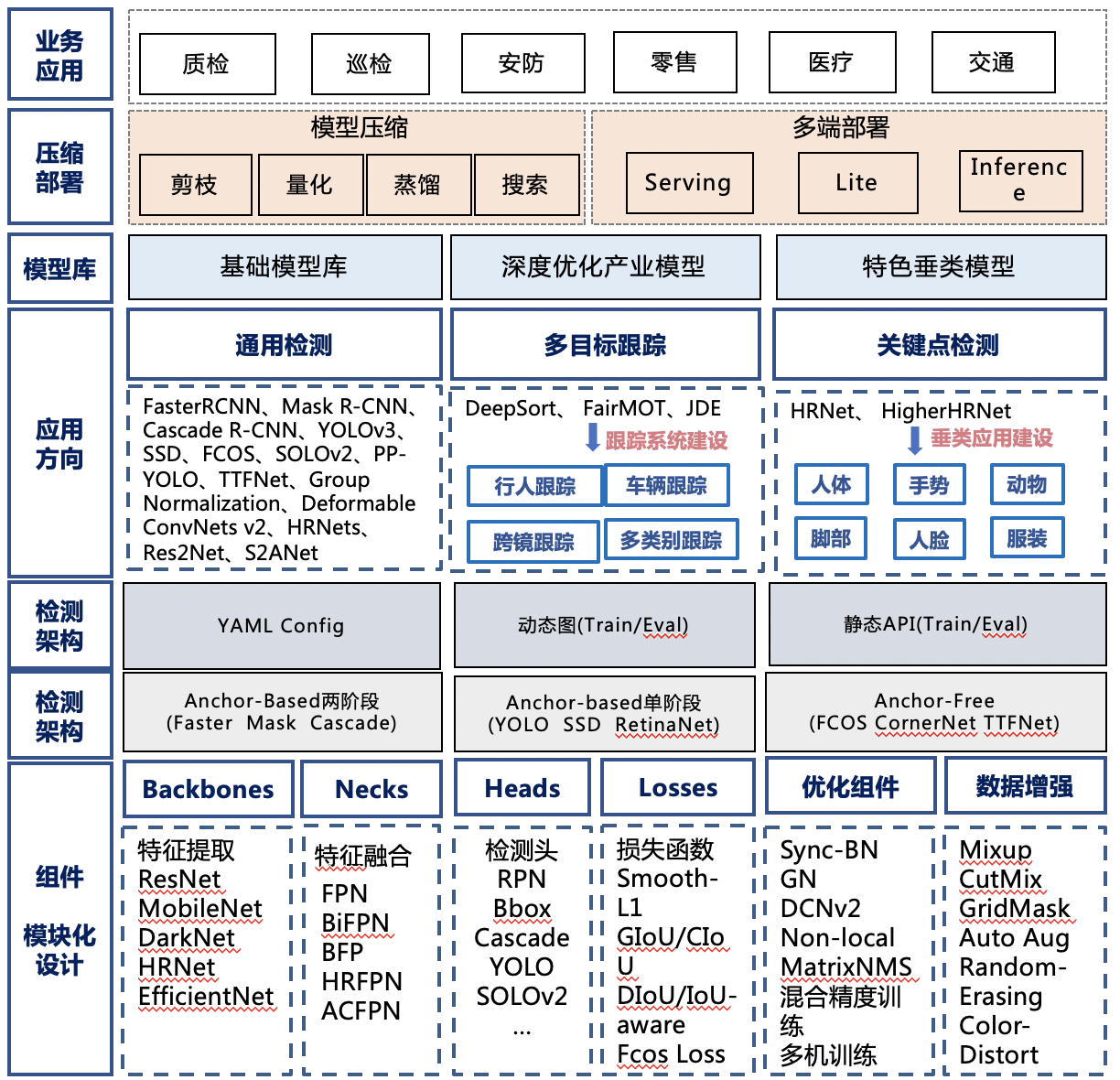
PaddleDetection是基于飞桨PaddlePaddle的端到端目标检测套件,提供多种主流目标检测、实例分割、跟踪、关键点检测算法,目前推出多种服务器端和移动端工业级SOTA模型,并集成了模型压缩和跨平台高性能部署能力,能帮助开发者更快更好完成端到端全开发流程。
- Github地址:https://github.com/PaddlePaddle/PaddleDetection
- Gitee地址:https://gitee.com/PaddlePaddle/PaddleDetection
动手实践
准备代码与运行环境
下载PaddleDetection代码并完成环境配置
效果展示
取视频中其中2帧图片展示
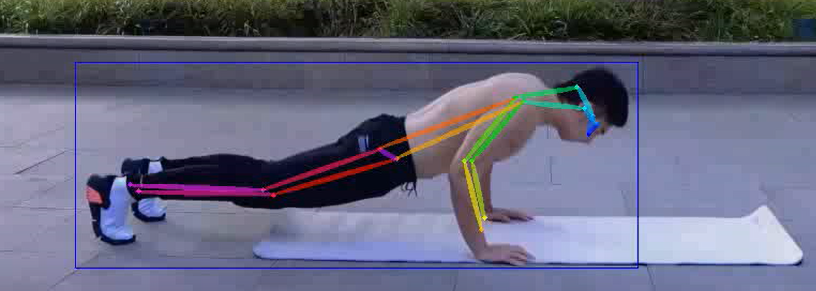
项目背景
根据《中国居民营养与慢性病状况报告(2020年)》最新数据,目前中国的成人中已经有超过1/2的人超重或肥胖,成年居民(≥18岁)超重率为34.3%、肥胖率为16.4%。 这是全国性调查报告中首次出现超过1/2这样一个数字。 同时,1/5(19%)的6-17岁儿童和青少年、1/10(10.4%)的6岁以下儿童存在超重或肥胖。 按照绝对的人口数来计算,全国已经有6亿人超重和肥胖,这个数字在全球是第一位。 近日,《柳叶刀-糖尿病与内分泌学》(The Lancet Diabetes & Endocrinology)发表了中国肥胖专辑( Obesity in China Series)。 目前该专辑上线了两篇文章《中国肥胖流行病学和决定因素》以及《中国肥胖临床管理和治疗》。
同时,在健身房中的大多数人,由于经济原因,不是所有人都能得到专业的健身教练的支持,所以健身达不到效果,于是我们萌生出了一个想法,可不可以训练出一个AI助手,来帮助我们纠正我们的健身动作,达到更好的健身效果。大家看到下面的图片有没有感觉今晚吃了夜宵的自己又有了罪恶感

1、环境准备
- 首先去github上克隆PaddleDetection代码
- 安装相关环境依赖
- 切换到相关的路径
# 下载PaddleDetection代码
!unzip -oq /home/aistudio/data/data121638/PaddleDetection.zip
# 安装相关环境依赖
!pip install --upgrade pip -i https://mirror.baidu.com/pypi/simple
!pip install paddlepaddle-gpu==2.2.0.post101 -f https://www.paddlepaddle.org.cn/whl/linux/mkl/avx/stable.html -i https://mirror.baidu.com/pypi/simple
!cd PaddleDetection && pip install --upgrade -r requirements.txt -i https://mirror.baidu.com/pypi/simple
- 使用下面的命令将默认工作目录切换到PaddleDetection文件夹下
import os
os.chdir("./PaddleDetection/")
!pwd
2、准备训练数据
- 如果需要实现自定义数据的训练,需要将自定义的数据集转成COCO格式,具体可参考[关键点数据准备文档]。(https://github.com/PaddlePaddle/PaddleDetection/blob/release/2.3/docs/tutorials/PrepareKeypointDataSet_cn.md)
- 在对应的配置文件(.yml)中,修改标注文件路径、数据路径等,使其与希望使用的自定义数据集一致。
- 在本项目中,我们准备了一个mini数据集。您可以通过这个mini数据集,体验如何走通整个训练流程。
- 数据集无需网上下载,直接运行下面cell
# 下载/解压数据集,并整理数据集路径
!wget https://bj.bcebos.com/v1/paddledet/data/keypoint/coco_val_person_mini.tar
!tar -xf coco_val_person_mini.tar -C ./dataset/
!mv ./dataset/coco_val_person_mini/* ./dataset/coco
!cp ./dataset/coco/annotations/aic_coco_train_cocoformat.json ./dataset/
!cp ./dataset/coco/annotations/instances_val2017.json ./dataset/coco/annotations/person_keypoints_val2017.json
3、模型训练
- 本项目需要进行两次模型训练,分别是pedestrian_detection的行人检测模型和TinyPose关键点检测模型,时间较长,等不及的同学可以去github上的model_zoo下载模型,不过精度较低
- 训练时调用启动命令python tools/train.py后面生命制定的配置文件和预训练权重
- 本项目中配置文件已配置好,无需修改
- model_zoo链接:https://github.com/PaddlePaddle/PaddleDetection/tree/develop#ModelZoo
!python tools/train.py -c configs/picodet/application/pedestrian_detection/picodet_s_320_pedestrian.yml \
-o pretrain_weights=https://paddledet.bj.bcebos.com/models/picodet_s_320_coco.pdparams \
--eval
- 训练TinyPose关键点检测模型
!python tools/train.py -c configs/keypoint/tiny_pose/tinypose_128x96.yml
- 上述模型训练完成后,默认会分别保存在
output/picodet_s_320_pedestrian和output/tinypose_128x96文件夹下
4、模型评估
- 当训练完成后,使用下面的命令评估模型的精度。
- 这里使用了我们已经训练好的模型。如希望使用自己训练的模型,请对应将
weights=后的值更改为对应模型.pdparams文件的存储路径。 - 使用启动命令python tools/eval.py就可以进行一件评估,后面声明配置文件及权重路径
# 行人检测模型
!python tools/eval.py -c configs/picodet/application/pedestrian_detection/picodet_s_320_pedestrian.yml \
-o weights=https://paddledet.bj.bcebos.com/models/picodet_s_320_pedestrian.pdparams
#关键点检测模型
!python tools/eval.py -c configs/keypoint/tiny_pose/tinypose_128x96.yml \
-o weights=https://bj.bcebos.com/v1/paddledet/models/keypoint/tinypose_128x96.pdparams
5、模型预测
- 1、将两个模型导出到output_inference
- 2、导出模型后进行联合部署预测的方式预测,预测的目标可以是图片和视频
- 3、预测结果保存在PaddleDetection/下
模型导出
- 分别将行人检测、关键点检测模型导出,这里使用了我们已经训练好的模型。如希望使用自己训练的模型,请对应将
weights=后的值更改为对应模型.pdparams文件的存储路径。 - 启动python tools/export_model.py开始导出
- 导出的模型将默认存储在
output_inference/路径下
# 导出行人检测模型
!python tools/export_model.py -c configs/picodet/application/pedestrian_detection/picodet_s_320_pedestrian.yml \
-o weights=https://paddledet.bj.bcebos.com/models/picodet_s_320_pedestrian.pdparams
# 导出关键点检测模型
!python tools/export_model.py -c configs/keypoint/tiny_pose/tinypose_128x96.yml \
-o weights=https://bj.bcebos.com/v1/paddledet/models/keypoint/tinypose_128x96.pdparams
实现预测
- 在完成模型导出后,我们使用联合部署预测的方式,对图片或者视频进行预测。
- 预测的可视化结果图像默认将存储在
output/下。
!python deploy/python/det_keypoint_unite_infer.py --det_model_dir=output_inference/picodet_s_320_pedestrian \
--keypoint_model_dir=output_inference/tinypose_128x96 \
--image_file=demo/1.png --device=GPU --keypoint_threshold=0.35
# 可视化预测图片
import cv2
import matplotlib.pyplot as plt
import numpy as np
image = cv2.imread('output/000000570688_vis.jpg')
plt.figure(figsize=(15,10))
plt.imshow(cv2.cvtColor(image, cv2.COLOR_BGR2RGB))
plt.show()
6、下面对视频进行预测
- 视频预测时,返回视频的处理结果在PaddleDetection/下,同时生成json文件
- json中包含预测视频的帧数,关键点的x、y坐标和置信度
!python deploy/python/det_keypoint_unite_infer.py --det_model_dir=output_inference/picodet_s_320_pedestrian \
--keypoint_model_dir=output_inference/tinypose_128x96 \
--video_file=1.MP4 \
--output_dir=../ \
--keypoint_threshold=0.2 \
.2 \
--device=gpu --save_res=True
7、应用
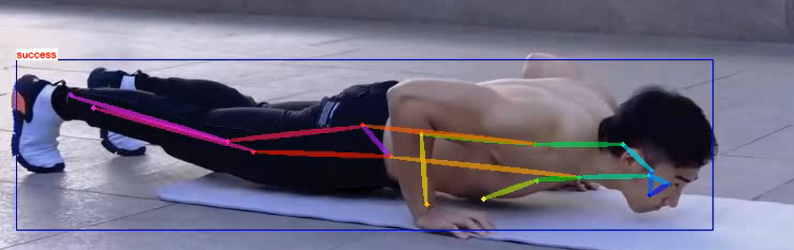
我们可以对json文件和视频进行读取后进行逻辑判断,之后进行俯卧撑动作的标准判断,下面给出判断逻辑:
COCO keypoint indexes:
0: 'nose',
1: 'left_eye',
2: 'right_eye',
3: 'left_ear',
4: 'right_ear',
5: 'left_shoulder',
6: 'right_shoulder',
7: 'left_elbow',
8: 'right_elbow',
9: 'left_wrist',
10: 'right_wrist',
11: 'left_hip',
12: 'right_hip',
13: 'left_knee',
14: 'right_knee',
15: 'left_ankle',
16: 'right_ankle'
一共检测出17个关键点分别对应人体的17个部位,这里只会用到5、7、9和6、8、10,分别对应人的左右手臂。本项目中,当人的左或右肘部成角经过90度时,或者肘部的高度高于肩膀,就说明完成了俯卧撑动作,这时视频里会显示success
逻辑判断核心代码:
if (left_small_arm+left_big_arm)>a or (right_small_arm+right_big_arm)>b:
if kpts_arr[5,1]<kpts_arr[7,1] or kpts_arr[6,1]<kpts_arr[8,1]:
%cd ../
import os
import sys
import cv2
import numpy as np
import json
import collections
from source import check_fall_down, videovis
#1)脚本第一个参数为关键点预测结果json文件
jsonf = "PaddleDetection/det_keypoint_unite_video_results.json"
with open(jsonf, "r") as rf:
kpts_data = json.load(rf)
print("all data length: {}".format(len(kpts_data)))
#2)如果需要视频打印摔倒文字,关键点可视化结果文件放在同路径
videof = "1.mp4"
#3)读取关键点结果后放入判断文件
fallframes = check_fall_down(kpts_data)
#4)根据检测的摔倒帧在视频显示
videovis(videof, kpts_data, fallframes)
8、总结与升华
- 本项目预测的效果已经达到了较高的置信度,有较高应用价值,各位大佬可以进行尝试
- 其他开发者可以开发更快速更轻量的模型
个人简介
本人来自江苏科技大学本科三年级,刚刚接触深度学习不久希望大家多多关注
感兴趣的方向:目标检测,强化学习,自然语言处理、
个人链接:
马骏骁
https://aistudio.baidu.com/aistudio/personalcenter/thirdview/824948
请点击此处查看本环境基本用法.
Please click here for more detailed instructions.

学大模型,用大模型上飞桨星河社区!每天8点V100G算力免费领!免费领取ERNIE 4.0 100w Token >>>
更多推荐



 7
7 0
0- 0



 已为社区贡献1437条内容
已为社区贡献1437条内容

所有评论(0)