
PaddleNLP:实现 NeZha 预训练语言模型
引入最近实现了不少 CV 模型,这次来换个方向,整个 NLP 模型玩一下这次准备实现的模型是华为诺亚方舟实验室在 2019 年发布的一个面向中文 NLU 任务的模型——NeZha(哪吒)小声 BB,又是一个强行凑出来的名字NeZha 基于 Bert 模型开发,并进行了多处优化,能够在一系列中文自然语言理解任务达到先进水平相关资料论文:NEZHA: Neural Contextualized Rep
引入
- 最近实现了不少 CV 模型,这次来换个方向,整个 NLP 模型玩一下
- 这次准备实现的模型是华为诺亚方舟实验室在 2019 年发布的一个面向中文 NLU 任务的模型——NeZha(哪吒)
- 小声 BB,又是一个强行凑出来的名字
- NeZha 基于 Bert 模型开发,并进行了多处优化,能够在一系列中文自然语言理解任务达到先进水平
相关资料
- 论文:NEZHA: Neural Contextualized Representation for Chinese Language Understanding
- 官方实现:huawei-noah/Pretrained-Language-Model
主要改进
- 函数式相对位置编码(Functional Relative Positional Encoding)
- 全词掩码训练(Whole Word Masking)
- 混合精度训练(Automatic Mixed Precision)
- 训练过程中使用 LAMB 优化器(Layer-wise Adaptive Moments optimizer)
位置编码
-
在 Transformer 中,每个词之间互相都要 Attending,并不知道每个词离自己的距离有多远,这样把每个词平等的对待,可能会出现问题。
-
所以 Transformer 和 Bert 分别在模型中增加了函数式和参数式绝对位置编码来解决这个问题。
- 函数式绝对位置编码:
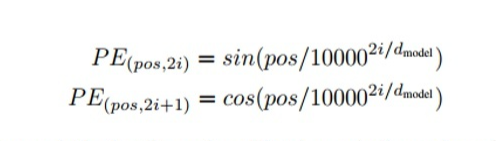
- 参数式绝对位置编码:
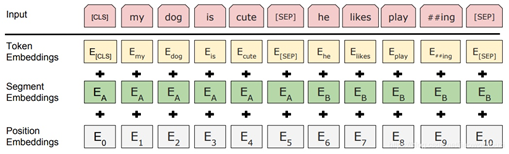
-
NeZha 模型采用了另一种方式,即函数式相对位置编码,通过使用相对位置的正弦函数计算输出和 Attention 的得分,该想法源于 Transformer 中使用的函数式绝对位置编码。
函数式相对位置编码
- 原始 Multi-Head Attention 是基于 Scaled Dot-Product Attention 实现的,而 Scaled Dot-Product Attention 的实现下图所示:
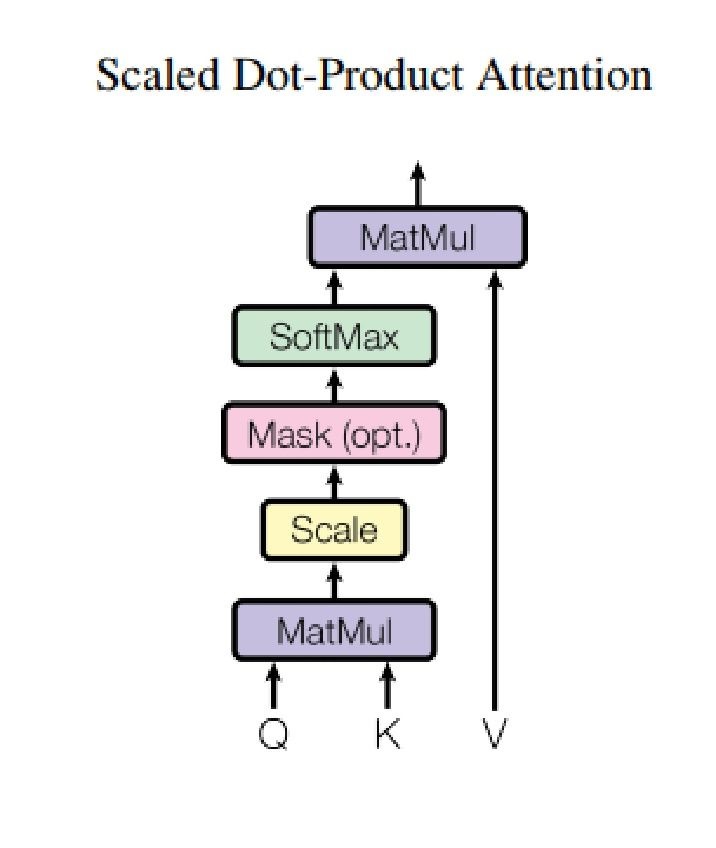
-
输入的 Q、K 和 V 分别由真实输入的序列 [外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-RImlW9OM-1635902198218)(https://www.zhihu.com/equation?tex=x+%3D++%28x_%7B1%7D%2Cx_%7B2%7D%2C%5Ccdot%5Ccdot%5Ccdot%2Cx_%7Bn%7D%29)] 乘上不同权重 [外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-yZ1pbeK1-1635902198225)(https://www.zhihu.com/equation?tex=W%5E%7BQ%7D)] 、[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-my4aDajV-1635902198233)(https://www.zhihu.com/equation?tex=W%5E%7BK%7D)] 和 [外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-vluixNwM-1635902198241)(https://www.zhihu.com/equation?tex=W%5E%7BV%7D)] 得到,输出为序列 [外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-czt80vki-1635902198247)(https://www.zhihu.com/equation?tex=z+%3D++%28z_%7B1%7D%2Cz_%7B2%7D%2C%5Ccdot%5Ccdot%5Ccdot%2Cz_%7Bn%7D%29)] 长度与输入序列一致。输出 [外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-Ctj6aLH7-1635902198257)(https://www.zhihu.com/equation?tex=z_%7Bi%7D)] 的计算公式如下:
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-nqE0ErrZ-1635902198296)(https://www.zhihu.com/equation?tex=z_%7Bi%7D+%3D+%5Csum_%7Bj%3D1%7D%5E%7Bn%7D%7B%5Calpha_%7Bij%7D%28x_%7Bj%7DW%5E%7BV%7D%29%7D)](公式1)
-
其中, [外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-uobrLSXu-1635902198300)(https://www.zhihu.com/equation?tex=%5Calpha_%7Bij%7D)] 是由位置 [外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-PEihjp3P-1635902198306)(https://www.zhihu.com/equation?tex=i)] 和位置 [外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-vgcJsAtL-1635902198322)(https://www.zhihu.com/equation?tex=j)] 的隐藏状态求 softmax 得到,如下:
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-T0dxvyNl-1635902198332)(https://www.zhihu.com/equation?tex=%5Calpha_%7Bij%7D+%3D+%5Cfrac%7Bexp++++e_%7Bij%7D%7D%7B%5Csum_%7Bk%7D%5E%7B%7D%7Bexp++++e_%7Bik%7D%7D%7D)](公式2)
-
其中, [外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-MIDRI0Gf-1635902198343)(https://www.zhihu.com/equation?tex=e_%7Bij%7D)] 为输入元素的通过 [外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-xKxyfxu4-1635902198372)(https://www.zhihu.com/equation?tex=W%5E%7BQ%7D)] 和 [外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-mFHEajaU-1635902198388)(https://www.zhihu.com/equation?tex=W%5E%7BK%7D)] 变换缩放点积得到,如下:
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-lO5GJZVp-1635902198402)(https://www.zhihu.com/equation?tex=e_%7Bij%7D+%3D+%5Cfrac%7B%28x_%7Bi%7DW%5E%7BQ%7D%29%28x_%7Bj%7DW%5E%7BK%7D%29%5E%7BT%7D%7D%7B%5Csqrt%7Bd_%7Bz%7D%7D%7D)](公式3)
-
在相对位置编码方案中,将输出 [外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-gjL91IUJ-1635902198413)(https://www.zhihu.com/equation?tex=z_%7Bi%7D)] 加入两个位置之间相对距离的参数,在上述公式1和公式3中,分别加入两个 token 的相对位置信息,修改如下得到:
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-8KmkJRXi-1635902198416)(https://www.zhihu.com/equation?tex=z_%7Bi%7D+%3D+%5Csum_%7Bj%3D1%7D%5E%7Bn%7D%7B%5Calpha_%7Bij%7D%28x_%7Bj%7DW%5E%7BV%7D+%2B+a_%7Bij%7D%5E%7BV%7D%29%7D)] (公式4)
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-DPECG6EC-1635902198427)(https://www.zhihu.com/equation?tex=e_%7Bij%7D+%3D+%5Cfrac%7B%28x_%7Bi%7DW%5E%7BQ%7D%29%28x_%7Bj%7DW%5E%7BK%7D%2Ba_%7Bij%7D%5E%7BK%7D%29%5E%7BT%7D%7D%7B%5Csqrt%7Bd_%7Bz%7D%7D%7D)] (公式5)
-
其中, [外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-1v5N4SGf-1635902198434)(https://www.zhihu.com/equation?tex=a_%7Bij%7D%5E%7BV%7D)] 和 [外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-FntQnGAX-1635902198446)(https://www.zhihu.com/equation?tex=a_%7Bij%7D%5E%7BK%7D)] 是位置 [外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-t3k6tByZ-1635902198454)(https://www.zhihu.com/equation?tex=i)] 和位置 [外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-i0sjpSu8-1635902198463)(https://www.zhihu.com/equation?tex=j)] 的相对位置编码,定义 [外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-gNFad9qE-1635902198478)(https://www.zhihu.com/equation?tex=a_%7Bij%7D)] 位置编码如下:
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-OiLEr4pz-1635902198489)(https://www.zhihu.com/equation?tex=a_%7Bij%7D%5B2k%5D%3Dsin%28%28j-i%29%2F%2810000%5E%7B%5Cfrac%7B2k%7D%7Bd_%7Bz%7D%7D%7D%29%29)]
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-6wx1bkQG-1635902198526)(https://www.zhihu.com/equation?tex=+a_%7Bij%7D%5B2k%2B1%5D%3Dcos%28%28j-i%29%2F%2810000%5E%7B%5Cfrac%7B2k%7D%7Bd_%7Bz%7D%7D%7D%29%29++)]
全词掩码训练
- Bert 模型通过词掩码的方式实现了双向 Transformer。在 Bert 模型中,被掩住的词是随机挑选的。
- 通过 Pre-Training with Whole Word Masking for Chinese BERT 研究表明,将随机掩码词汇替换成全词掩码,可以有效提高预训练模型效果。
- 即如果有一个汉字被掩蔽,属于同一个汉字的其他汉字都被掩蔽在一起。
- 词掩码 vs 全词掩码:

混合精度训练
-
一般情况下,训练深度学习模型时使用的数据类型为单精度(FP32)。
-
2018年,百度与 NVIDIA 联合发表论文:MIXED PRECISION TRAINING,提出了混合精度训练的方法。
-
混合精度训练是指在训练过程中,同时使用单精度(FP32)和半精度(FP16),其目的是相较于使用单精度(FP32)训练模型,在保持精度持平的条件下,能够加速训练。
-
如图1所示,半精度(FP16)是一种相对较新的浮点类型,在计算机中使用2字节(16位)存储。
-
在IEEE 754-2008标准中,它亦被称作binary16。与计算中常用的单精度(FP32)和双精度(FP64)类型相比,FP16更适于在精度要求不高的场景中使用。
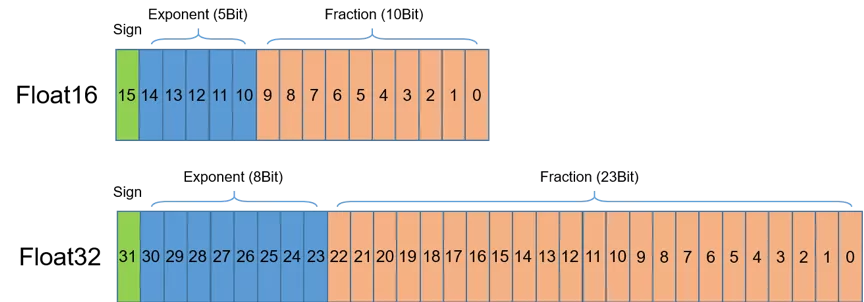
LAMB 优化器
- LAMB 优化器(Layer-wise Adaptive Moments optimizer)旨在不降低精度的前提下增大训练的批量大小,其支持自适应的逐元素更新和精确的分层校正。
- LAMB 主要是综合了 Adam 和 LARS(Layerwise Adaptive Rate Scaling),对学习率进行调整,具体的实现如下:

模型实现
- 模型介绍完了,接下来就是实际的搭建了
- 由于这个模型的代码量有点大,就不全部展示在 NoteBook 里面了,挑一些比较重要的提一下
安装依赖
!pip install paddlenlp==2.0.1
嵌入层
- 因为 NeZha 引入了函数式相对位置编码,所以其使用的 Embeddings 不需要位置嵌入(Position Embeddings)
class NeZhaEmbeddings(nn.Layer):
def __init__(self,
vocab_size,
hidden_size=768,
hidden_dropout_prob=0.1,
max_position_embeddings=512,
type_vocab_size=16,
use_relative_position=True):
super(NeZhaEmbeddings, self).__init__()
self.use_relative_position = use_relative_position
self.word_embeddings = nn.Embedding(vocab_size, hidden_size)
# 是否使用相对位置编码
if not use_relative_position:
self.position_embeddings = nn.Embedding(
max_position_embeddings, hidden_size)
self.token_type_embeddings = nn.Embedding(type_vocab_size, hidden_size)
self.layer_norm = nn.LayerNorm(hidden_size)
self.dropout = nn.Dropout(hidden_dropout_prob)
def forward(self, input_ids, token_type_ids=None):
seq_length = input_ids.shape[1]
position_ids = paddle.arange(seq_length, dtype='int64')
position_ids = position_ids.unsqueeze(0).expand_as(input_ids)
if token_type_ids is None:
token_type_ids = paddle.zeros_like(input_ids, dtype="int64")
words_embeddings = self.word_embeddings(input_ids)
embeddings = words_embeddings
if not self.use_relative_position:
position_embeddings = self.position_embeddings(position_ids)
embeddings += position_embeddings
token_type_embeddings = self.token_type_embeddings(token_type_ids)
embeddings += token_type_embeddings
embeddings = self.layer_norm(embeddings)
embeddings = self.dropout(embeddings)
return embeddings
注意力机制
- 因为 NeZha 引入了函数式相对位置编码,所以其使用的 Attention 和 Bert 有比较大的差异
import copy
import math
import numpy as np
import paddle
import paddle.nn as nn
import paddle.nn.functional as F
class NeZhaAttention(nn.Layer):
def __init__(self,
hidden_size,
num_attention_heads,
hidden_dropout_prob,
attention_probs_dropout_prob,
max_relative_position,
layer_norm_eps):
super(NeZhaAttention, self).__init__()
if hidden_size % num_attention_heads != 0:
raise ValueError(
"The hidden size (%d) is not a multiple of the number of attention "
"heads (%d)" % (hidden_size, num_attention_heads))
self.num_attention_heads = num_attention_heads
self.attention_head_size = int(hidden_size / num_attention_heads)
self.all_head_size = self.num_attention_heads * self.attention_head_size
self.query = nn.Linear(hidden_size, self.all_head_size)
self.key = nn.Linear(hidden_size, self.all_head_size)
self.value = nn.Linear(hidden_size, self.all_head_size)
self.relative_positions_embeddings = self.generate_relative_positions_embeddings(
length=512, depth=self.attention_head_size, max_relative_position=max_relative_position
)
self.attention_dropout = nn.Dropout(attention_probs_dropout_prob)
self.dense = nn.Linear(hidden_size, hidden_size)
self.layer_norm = nn.LayerNorm(hidden_size, epsilon=layer_norm_eps)
self.output_dropout = nn.Dropout(hidden_dropout_prob)
# 生成函数式相对位置编码
def generate_relative_positions_embeddings(self, length, depth, max_relative_position=127):
vocab_size = max_relative_position * 2 + 1
range_vec = paddle.arange(length)
range_mat = paddle.tile(
range_vec, repeat_times=[length]
).reshape((length, length))
distance_mat = range_mat - paddle.t(range_mat)
distance_mat_clipped = paddle.clip(
distance_mat.astype( 'float32'),
-max_relative_position,
max_relative_position
)
final_mat = distance_mat_clipped + max_relative_position
embeddings_table = np.zeros([vocab_size, depth])
for pos in range(vocab_size):
for i in range(depth // 2):
embeddings_table[pos, 2 * i] = np.sin(pos / np.power(10000, 2 * i / depth))
embeddings_table[pos, 2 * i + 1] = np.cos(pos / np.power(10000, 2 * i / depth))
embeddings_table_tensor = paddle.to_tensor(embeddings_table, dtype='float32')
flat_relative_positions_matrix = final_mat.reshape((-1,))
one_hot_relative_positions_matrix = paddle.nn.functional.one_hot(
flat_relative_positions_matrix.astype('int64'),
num_classes=vocab_size
)
embeddings = paddle.matmul(
one_hot_relative_positions_matrix,
embeddings_table_tensor
)
my_shape = final_mat.shape
my_shape.append(depth)
embeddings = embeddings.reshape(my_shape)
return embeddings
def transpose_for_scores(self, x):
new_x_shape = x.shape[:-1] + [self.num_attention_heads, self.attention_head_size]
x = x.reshape(new_x_shape)
return x.transpose((0, 2, 1, 3))
def forward(self, hidden_states, attention_mask):
mixed_query_layer = self.query(hidden_states)
mixed_key_layer = self.key(hidden_states)
mixed_value_layer = self.value(hidden_states)
query_layer = self.transpose_for_scores(mixed_query_layer)
key_layer = self.transpose_for_scores(mixed_key_layer)
value_layer = self.transpose_for_scores(mixed_value_layer)
# Take the dot product between "query" and "key" to get the raw attention scores.
attention_scores = paddle.matmul(
query_layer,
key_layer.transpose((0, 1, 3, 2))
)
batch_size, num_attention_heads, from_seq_length, to_seq_length = attention_scores.shape
relations_keys = self.relative_positions_embeddings.detach().clone()[:to_seq_length, :to_seq_length, :]
query_layer_t = query_layer.transpose((2, 0, 1, 3))
query_layer_r = query_layer_t.reshape(
(from_seq_length, batch_size *
num_attention_heads, self.attention_head_size)
)
key_position_scores = paddle.matmul(
query_layer_r,
relations_keys.transpose((0, 2, 1))
)
key_position_scores_r = key_position_scores.reshape(
(from_seq_length, batch_size, num_attention_heads, from_seq_length)
)
key_position_scores_r_t = key_position_scores_r.transpose((1, 2, 0, 3))
attention_scores = attention_scores + key_position_scores_r_t
attention_scores = attention_scores / math.sqrt(self.attention_head_size)
attention_scores = attention_scores + attention_mask
# Normalize the attention scores to probabilities.
attention_probs = nn.Softmax(axis=-1)(attention_scores)
# This is actually dropping out entire tokens to attend to, which might
# seem a bit unusual, but is taken from the original Transformer paper.
attention_probs = self.attention_dropout(attention_probs)
context_layer = paddle.matmul(attention_probs, value_layer)
relations_values = self.relative_positions_embeddings.clone()[:to_seq_length, :to_seq_length, :]
attention_probs_t = attention_probs.transpose((2, 0, 1, 3))
attentions_probs_r = attention_probs_t.reshape(
(from_seq_length, batch_size * num_attention_heads, to_seq_length)
)
value_position_scores = paddle.matmul(attentions_probs_r, relations_values)
value_position_scores_r = value_position_scores.reshape(
(from_seq_length, batch_size,
num_attention_heads, self.attention_head_size)
)
value_position_scores_r_t = value_position_scores_r.transpose((1, 2, 0, 3))
context_layer = context_layer + value_position_scores_r_t
context_layer = context_layer.transpose((0, 2, 1, 3))
new_context_layer_shape = context_layer.shape[:-2] + [self.all_head_size]
context_layer = context_layer.reshape(new_context_layer_shape)
projected_context_layer = self.dense(context_layer)
projected_context_layer_dropout = self.output_dropout(projected_context_layer)
layer_normed_context_layer = self.layer_norm(
hidden_states + projected_context_layer_dropout
)
return layer_normed_context_layer, attention_scores
加载完整模型
- 除了上述的两个模块与 Bert 差别较大之外,其他基本没啥大区别
- 接下来就演示一下如何使用 PaddleNLP 来调用加载完整的预训练模型
from nezha import NeZhaForPretraining, NeZhaTokenizer
# 加载预训练模型
model = NeZhaForPretraining.from_pretrained('nezha-base-chinese')
# 加载编解码器
tokenizer = NeZhaTokenizer.from_pretrained('nezha-base-chinese')
[2021-06-01 20:19:08,605] [ INFO] - Already cached /home/aistudio/.paddlenlp/models/nezha-base-chinese/3c4627e89eb2434e8aaacfd71a410e2c7be852abb79541a7ac010a6b5c2157b1?responseContentDisposition=attachment%3B%20filename%3Dnezha-base-chinese.pdparams
[2021-06-01 20:19:13,288] [ INFO] - Found /home/aistudio/.paddlenlp/models/nezha-base-chinese/79659c66a389469e89ce2bc966a82471151b07dbcb40411ba222c215ee032d36?responseContentDisposition=attachment%3B%20filename%3Dvocab.txt
模型测试
import paddle
# 测试的输入数据
input_ids = paddle.to_tensor([[31, 51, 99], [15, 5, 0]], dtype='int64')
input_mask = paddle.to_tensor([[1, 1, 1], [1, 1, 0]], dtype='int64')
token_type_ids = paddle.to_tensor([[0, 0, 1], [0, 1, 0]], dtype='int64')
masked_lm_labels = paddle.to_tensor([[31, 51, 99], [15, 5, 0]], dtype='int64')
next_sentence_label = paddle.to_tensor([[0], [1]], dtype='int64')
# 模型测试
with paddle.no_grad():
out = model(input_ids, token_type_ids, input_mask)
print(out[0].shape, out[1].shape)
out = model(input_ids, token_type_ids, input_mask, masked_lm_labels, next_sentence_label)
print(out.shape)
model.eval()
with paddle.no_grad():
out = model(input_ids, token_type_ids, input_mask)
print(out[0].shape, out[1].shape)
out = model(input_ids, token_type_ids, input_mask, masked_lm_labels, next_sentence_label)
print(out.shape)
[2, 3, 21128] [2, 2]
[1]
[2, 3, 21128] [2, 2]
[1]
模型微调
文本分类任务微调
- 这里就使用经典的文本分类任务来演示一下模型微调的操作
import paddlenlp as ppnlp
import paddle.nn.functional as F
from paddlenlp.datasets import load_dataset
from paddlenlp.data import Stack, Tuple, Pad
from paddlenlp.transformers import LinearDecayWithWarmup
from functools import partial
from utils import convert_example, create_dataloader, evaluate
from nezha import NeZhaForSequenceClassification, NeZhaTokenizer
train_ds, dev_ds, test_ds = load_dataset(
"chnsenticorp",
splits=["train", "dev", "test"]
)
model = NeZhaForSequenceClassification.from_pretrained(
'nezha-base-chinese',
num_classes=len(train_ds.label_list)
)
tokenizer = NeZhaTokenizer.from_pretrained('nezha-base-chinese')
# 模型运行批处理大小
batch_size = 32
max_seq_length = 128
trans_func = partial(
convert_example,
tokenizer=tokenizer,
max_seq_length=max_seq_length)
batchify_fn = lambda samples, fn=Tuple(
Pad(axis=0, pad_val=tokenizer.pad_token_id), # input
Pad(axis=0, pad_val=tokenizer.pad_token_type_id), # segment
Stack(dtype="int64") # label
): [data for data in fn(samples)]
train_data_loader = create_dataloader(
train_ds,
mode='train',
batch_size=batch_size,
batchify_fn=batchify_fn,
trans_fn=trans_func)
dev_data_loader = create_dataloader(
dev_ds,
mode='dev',
batch_size=batch_size,
batchify_fn=batchify_fn,
trans_fn=trans_func)
test_data_loader = create_dataloader(
test_ds,
mode='test',
batch_size=batch_size,
batchify_fn=batchify_fn,
trans_fn=trans_func)
# 训练过程中的最大学习率
learning_rate = 5e-5
# 训练轮次
epochs = 3
# 学习率预热比例
warmup_proportion = 0.1
# 权重衰减系数,类似模型正则项策略,避免模型过拟合
weight_decay = 0.01
num_training_steps = len(train_data_loader) * epochs
lr_scheduler = LinearDecayWithWarmup(learning_rate, num_training_steps, warmup_proportion)
optimizer = paddle.optimizer.AdamW(
learning_rate=lr_scheduler,
parameters=model.parameters(),
weight_decay=weight_decay,
apply_decay_param_fun=lambda x: x in [
p.name for n, p in model.named_parameters()
if not any(nd in n for nd in ["bias", "norm"])
])
criterion = paddle.nn.loss.CrossEntropyLoss()
metric = paddle.metric.Accuracy()
global_step = 0
for epoch in range(1, epochs + 1):
for step, batch in enumerate(train_data_loader, start=1):
input_ids, segment_ids, labels = batch
logits = model(input_ids, segment_ids)
loss = criterion(logits, labels)
probs = F.softmax(logits, axis=1)
correct = metric.compute(probs, labels)
metric.update(correct)
acc = metric.accumulate()
global_step += 1
if global_step % 10 == 0 :
print("global step %d, epoch: %d, batch: %d, loss: %.5f, acc: %.5f" % (global_step, epoch, step, loss, acc))
loss.backward()
optimizer.step()
lr_scheduler.step()
optimizer.clear_grad()
evaluate(model, criterion, metric, dev_data_loader)
model.save_pretrained('/home/aistudio/checkpoint')
tokenizer.save_pretrained('/home/aistudio/checkpoint')
效果测试
from utils import predict
data = [
{"text":'这个宾馆比较陈旧了,特价的房间也很一般。总体来说一般'},
{"text":'怀着十分激动的心情放映,可是看着看着发现,在放映完毕后,出现一集米老鼠的动画片'},
{"text":'作为老的四星酒店,房间依然很整洁,相当不错。机场接机服务很好,可以在车上办理入住手续,节省时间。'},
]
label_map = {0: 'negative', 1: 'positive'}
results = predict(
model, data, tokenizer, label_map, batch_size=batch_size)
for idx, text in enumerate(data):
t":'这个宾馆比较陈旧了,特价的房间也很一般。总体来说一般'},
{"text":'怀着十分激动的心情放映,可是看着看着发现,在放映完毕后,出现一集米老鼠的动画片'},
{"text":'作为老的四星酒店,房间依然很整洁,相当不错。机场接机服务很好,可以在车上办理入住手续,节省时间。'},
]
label_map = {0: 'negative', 1: 'positive'}
results = predict(
model, data, tokenizer, label_map, batch_size=batch_size)
for idx, text in enumerate(data):
print('Data: {} \t Lable: {}'.format(text, results[idx]))
Data: {'text': '这个宾馆比较陈旧了,特价的房间也很一般。总体来说一般'} Lable: negative
Data: {'text': '怀着十分激动的心情放映,可是看着看着发现,在放映完毕后,出现一集米老鼠的动画片'} Lable: negative
Data: {'text': '作为老的四星酒店,房间依然很整洁,相当不错。机场接机服务很好,可以在车上办理入住手续,节省时间。'} Lable: positive
总结
- 比较详细地介绍了 NeZha 模型的改进点
- 基于 Paddle2.0 和 PaddleNLP 套件实现了 NeZha 模型
- 使用 NeZha 模型进行文本分类任务的微调

学大模型,用大模型上飞桨星河社区!每天8点V100G算力免费领!免费领取ERNIE 4.0 100w Token >>>
更多推荐



 2
2 0
0- 0



 已为社区贡献1436条内容
已为社区贡献1436条内容

所有评论(0)