
[RNN实战]自动生成对联、古诗
通过了解RNN各项模型后,搭建并对其进行训练,最终实现使用多种RNN网络模型来让AI自动生成古诗以及对对联。
循环神经网络
1. LSTM模型
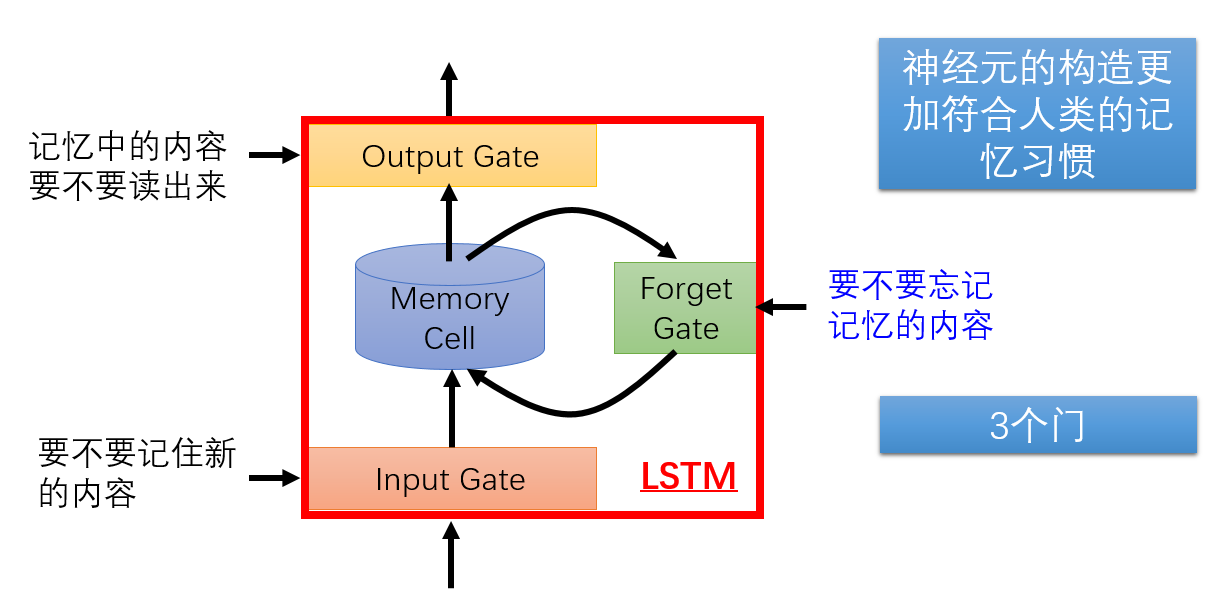
LSTM是一种RNN模型,LSTM 由Hochreiter & Schmidhuber (1997)提出,并在近期被Alex Graves进行了改良和推广。在很多问题,LSTM 都取得相当巨大的成功,并得到了广泛的使用。 LSTM 模型中,当进行训练时,之前所学习到的信息会持续存在,并不会随着任务的更新导致遗忘,能够学习到长期的规律,
LSTM明确旨在避免长期依赖性的问题。 长时间记住信息实际上是他们的默认行为,而不是他们难以学习的东西!
LSTM的关键是单元状态,水平线贯穿图的顶部。有些像传送带。 它直接沿着整个链运行,只有一些次要的线性交互。信息很容易沿着它不变地流动.LSTM能够移除或添加信息到结点来改变信息流状态,由称为门(gate)的结构精心调节。门是一种可选择通过信息的节点。 它们由西格玛(Sigmoid)神经网络层和逐点乘法运算组成。
2. Seq2Seq模型
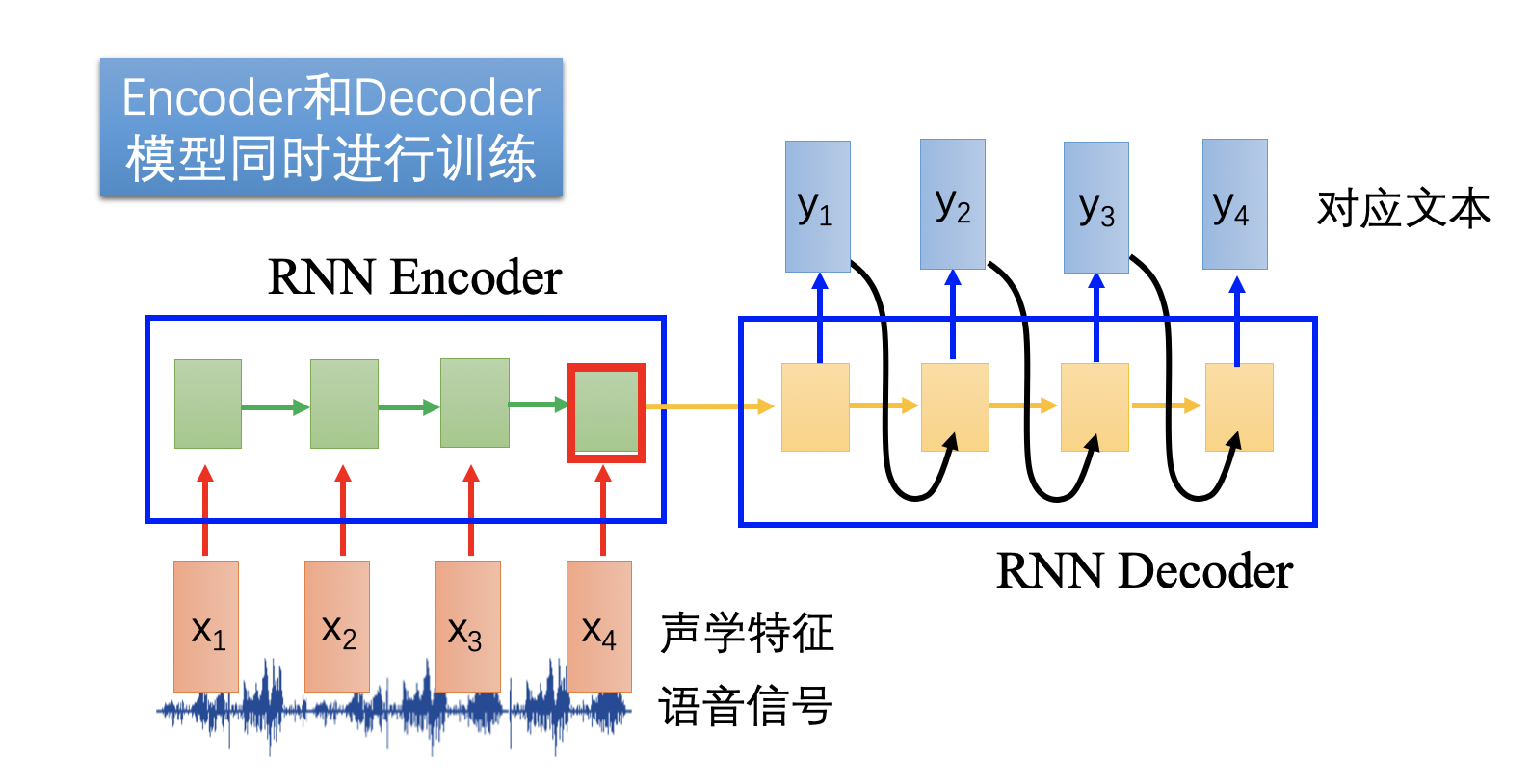
本实验中采用的框架是编码器encoder-解码器decoder框架,它可以将一个任意长度的源序列转换成另一个任意长度的目标序列:在数据编码阶段将整个源序列编码成一个向量,而到了数据解码阶段时就通过预测序列的概率选取概率最大的一个,并从中解码出整个目标序列。编码和解码的过程通常都使用RNN实现。
数据集介绍
对联
采用开源的对联数据集couplet-clean-dataset,该数据集过滤了 couplet-dataset中的低俗、敏感内容。
这个数据集包含70w多条训练样本,1000条验证样本和1000条测试样本。
下面列出一些训练集中对联样例:
上联:晚风摇树树还挺 下联:晨露润花花更红
诗歌
数据集包含41560首唐诗。从json文件中读取41560x10的二维列表,列表中包含卷、作者、诗名、简体诗、繁体诗等内容,我们只需要其中的简体诗。
任务1: 对对联
1. 安装并导入环境包
import paddlenlp
import io
import os
from functools import partial
import numpy as np
import paddle
import paddle.nn as nn
import paddle.nn.functional as F
from paddlenlp.data import Vocab, Pad
from paddlenlp.metrics import Perplexity
from paddlenlp.datasets import load_dataset
train_data, test_data = load_dataset('couplet', splits=('train', 'test'))
100%|██████████| 21421/21421 [00:00<00:00, 54011.86it/s]
2. 查看数据内容
print ('训练集和测试集大小:', len(train_data), len(test_data))
print('展示五幅对联:')
for i in range(5):
couplet_idx = (int)(np.random.rand() * 1000) # 随机选择0~1000里面的对联
print (train_data[couplet_idx]) # 每幅对联由两句话组成,first表示上联,second表示下联。每个中文字之间有\x02作为分割标志
训练集和测试集大小: 702594 999
展示五幅对联:
{'first': '水\x02墨\x02江\x02南\x02真\x02写\x02意', 'second': '风\x02流\x02才\x02子\x02不\x02拘\x02泥'}
{'first': '平\x02平\x02淡\x02淡\x02心\x02情\x02畅', 'second': '顺\x02顺\x02当\x02当\x02钱\x02财\x02多'}
{'first': '赋\x02诗\x02情\x02万\x02里', 'second': '风\x02云\x02入\x02心\x02怀'}
{'first': '谁\x02在\x02人\x02间\x02曾\x02历\x02沧\x02桑\x02百\x02岁', 'second': '公\x02归\x02天\x02上\x02再\x02栽\x02桃\x02李\x02三\x02千'}
{'first': '瑞\x02气\x02盈\x02庭\x02一\x02门\x02兴\x02旺', 'second': '甘\x02霖\x02沃\x02野\x02五\x02谷\x02丰\x02登'}
vocab = Vocab.load_vocabulary(**train_data.vocab_info)
trg_idx2word = vocab.idx_to_token
vocab_size = len(vocab)
pad_id = vocab[vocab.pad_token]
bos_id = vocab[vocab.bos_token]
eos_id = vocab[vocab.eos_token]
print ('pad_id={}, bos_id={}, eos_id={}'.format(pad_id, bos_id, eos_id))
pad_id=0, bos_id=1, eos_id=2
def convert_example(example, vocab):
source = [bos_id] + vocab.to_indices(example['first'].split('\x02')) + [eos_id]
target = [bos_id] + vocab.to_indices(example['second'].split('\x02')) + [eos_id]
return source, target
trans_func = partial(convert_example, vocab=vocab)
train_ds = train_data.map(trans_func)
test_ds = test_data.map(trans_func)
couplet_first = '此处输入想要查看的文本的token ID' # 可以自行输入文字并查看其tokenID 将 晚风摇树树还挺 改成想查看token id的文字
print(vocab.to_indices([c for c in couplet_first]))
[225, 118, 1504, 114, 580, 525, 2491, 156, 1817, 49, 477, 1817, 0, 0, 0, 0, 0, 0, 0, 0]
def create_data_loader(dataset):
data_loader = paddle.io.DataLoader(
dataset,
batch_size = batch_size,
collate_fn=partial(prepare_input, pad_id=pad_id))
return data_loader
def prepare_input(insts, pad_id):
src, src_length = Pad(pad_val=pad_id, ret_length=True)([inst[0] for inst in insts])
tgt, tgt_length = Pad(pad_val=pad_id, ret_length=True)([inst[1] for inst in insts])
tgt_mask = (tgt[:, :-1] != pad_id).astype(paddle.get_default_dtype())
return src, src_length, tgt[:, :-1], tgt[:, 1:, np.newaxis], tgt_mask
device = "gpu"
device = paddle.set_device(device)
batch_size = 128
num_layers = 2
embed_dim = 256
hidden_size =256
dropout = 0.2 # 自行选择每层舍弃的神经元比例,推荐范围(0-0.5)
learning_rate = 0.001 # 自行选择学习率 推荐范围(0.0001-0.1)
max_epoch = 2 # 自行选择训练次数 推荐范围(1-5)
model_path = './couplet_models'
log_freq = 200
train_loader = create_data_loader(train_ds)
test_loader = create_data_loader(test_ds)
print(len(train_ds), len(train_loader), batch_size)
702594 5490 128
3. 模型定义
from work.seq2seq_encoder import *
from work.attn import *
from work.seq2seq_decoder import *
from work.model_utils import *
class Seq2SeqAttnModel(nn.Layer):
def __init__(self, vocab_size, embed_dim, hidden_size, num_layers, eos_id=1):
super(Seq2SeqAttnModel, self).__init__()
self.hidden_size = hidden_size
self.eos_id = eos_id
self.num_layers = num_layers
self.encoder = Seq2SeqEncoder(vocab_size, embed_dim, hidden_size,
num_layers)
self.decoder = Seq2SeqDecoder(vocab_size, embed_dim, hidden_size,
num_layers)
def forward(self, src, src_length, trg):
return lstm_forward(
src,
src_length,
trg,
self.encoder,
self.decoder,
self.num_layers,
self.hidden_size,
self.eos_id)
from work.cross_entropy import CrossEntropyCriterion
model = paddle.Model(
Seq2SeqAttnModel(
vocab_size,
embed_dim,
hidden_size,
num_layers,
pad_id
))
4. 模型的训练
optimizer = paddle.optimizer.Adam(
learning_rate=learning_rate, parameters=model.parameters())
ppl_metric = Perplexity()
model.prepare(optimizer, CrossEntropyCriterion(), ppl_metric)
model.fit(train_data=train_loader,
epochs=max_epoch,
eval_freq=1,
save_freq=1,
save_dir=model_path,
log_freq=log_freq)
5. 预测模型
from work.infer import Seq2SeqAttnInferModel
def post_process_seq(seq, bos_idx, eos_idx, output_bos=False, output_eos=False):
eos_pos = len(seq) - 1
for i, idx in enumerate(seq):
if idx == eos_idx:
eos_pos = i
break
seq = [
idx for idx in seq[:eos_pos + 1]
if (output_bos or idx != bos_idx) and (output_eos or idx != eos_idx)
]
return seq
beam_size = 5
embed_dim = hidden_size
model_infer = paddle.Model(
Seq2SeqAttnInferModel(
vocab_size,
embed_dim,
hidden_size,
num_layers,
bos_id=bos_id,
eos_id=eos_id,
beam_size=beam_size,
max_out_len=256))
model_infer.load('couplet_models/model_18')
idx = 0
it = 0
for data in test_loader():
inputs = data[:2]
finished_seq = model_infer.predict_batch(inputs=list(inputs))[0]
finished_seq = finished_seq[:, :, np.newaxis] if len(
finished_seq.shape) == 2 else finished_seq
finished_seq = np.transpose(finished_seq, [0, 2, 1])
for ins in finished_seq:
for beam in ins:
id_list = post_process_seq(beam, bos_id, eos_id)
word_list_f = [trg_idx2word[id] for id in test_ds[idx][0]][1:-1]
word_list_s = [trg_idx2word[id] for id in id_list]
sequence = "上联: "+"".join(word_list_f)+"\t下联: "+"".join(word_list_s) + "\n"
print(sequence)
break
idx += batch_size
break
it += 1
if it == 5:
break
/opt/conda/envs/python35-paddle120-env/lib/python3.7/site-packages/paddle/fluid/framework.py:689: DeprecationWarning: `np.bool` is a deprecated alias for the builtin `bool`. To silence this warning, use `bool` by itself. Doing this will not modify any behavior and is safe. If you specifically wanted the numpy scalar type, use `np.bool_` here.
Deprecated in NumPy 1.20; for more details and guidance: https://numpy.org/devdocs/release/1.20.0-notes.html#deprecations
elif dtype == np.bool:
上联: 心尘须自扫 下联: 无奈不由人
上联: 闲开樽酒闻诗味 下联: 醉卧梅花醉酒香
上联: 雀语吱喳云甚事 下联: 莺声婉转雨谁声
上联: 马步欢腾传喜讯 下联: 羊毫蘸彩绘宏图
上联: 眄晓日朝霞祥光万里苍茫外 下联: 对清风明月明月千秋寂寞中
此处可以利用训练好的模型来给我们输入的上联生成下联
couplet_first = '晚风摇树树还挺' # 写入想要生成下联的对联 如 '晚风摇树树还挺'
couplet_len = len(couplet_first)
couplet_first_token = [bos_id] + vocab.to_indices([c for c in couplet_first]) + [eos_id]
couplet_len += 2
x = paddle.fluid.dygraph.to_variable([couplet_first_token])
coup_len = paddle.fluid.dygraph.to_variable([couplet_len])
finished_seq = model_infer.predict_batch(inputs=list([x, coup_len]))[0]
finished_seq = np.transpose(finished_seq, [0, 2, 1])
for beam in finished_seq[0]:
couplet_output = ''
for tokenId in beam:
if tokenId == eos_id: break
couplet_output += trg_idx2word[tokenId]
print('上联:', couplet_first, '\t下联:', couplet_output)
上联: 晚风摇树树还挺 下联: 春雨润花花更香
上联: 晚风摇树树还挺 下联: 夜雨敲窗花更香
上联: 晚风摇树树还挺 下联: 晨露润花花更香
上联: 晚风摇树树还挺 下联: 春雨润花花更红
上联: 晚风摇树树还挺 下联: 春雨润花花更芳
任务2:诗歌生成
1.环境导入
import numpy as np
import json
import paddle
import paddle as P
import paddle.nn as nn
import paddle.nn.functional as F
2. 数据导入
poem_data = np.load('work/tang_poem.npz', allow_pickle=True)
tokens = poem_data['data']
id2char_dict = poem_data['ix2word'].item()
char2id_dict = poem_data['word2ix'].item()
poem_id = (int)(np.random.rand() *0)
print('原始诗句:')
for word in tokens[poem_id]:
if word >= 8290: continue
print(id2char_dict[word], end='')
print('\n\npadding诗句:')
for word in tokens[poem_id]:
print(id2char_dict[word], end='')
print('\n\ntokens:')
print(tokens[poem_id])
原始诗句:
度门能不访,冒雪屡西东。已想人如玉,遥怜马似骢。乍迷金谷路,稍变上阳宫。还比相思意,纷纷正满空。
padding诗句:
</s></s></s></s></s></s></s></s></s></s></s></s></s></s></s></s></s></s></s></s></s></s></s></s></s></s></s></s></s></s></s></s></s></s></s></s></s></s></s></s></s></s></s></s></s></s></s></s></s></s></s></s></s></s></s></s></s></s></s></s></s></s></s></s></s></s></s></s></s></s></s></s></s></s></s><START>度门能不访,冒雪屡西东。已想人如玉,遥怜马似骢。乍迷金谷路,稍变上阳宫。还比相思意,纷纷正满空。<EOP>
tokens:
[8292 8292 8292 8292 8292 8292 8292 8292 8292 8292 8292 8292 8292 8292
8292 8292 8292 8292 8292 8292 8292 8292 8292 8292 8292 8292 8292 8292
8292 8292 8292 8292 8292 8292 8292 8292 8292 8292 8292 8292 8292 8292
8292 8292 8292 8292 8292 8292 8292 8292 8292 8292 8292 8292 8292 8292
8292 8292 8292 8292 8292 8292 8292 8292 8292 8292 8292 8292 8292 8292
8292 8292 8292 8292 8292 8291 6731 4770 1787 8118 7577 7066 4817 648
7121 1542 6483 7435 7686 2889 1671 5862 1949 7066 2596 4785 3629 1379
2703 7435 6064 6041 4666 4038 4881 7066 4747 1534 70 3788 3823 7435
4907 5567 201 2834 1519 7066 782 782 2063 2031 846 7435 8290]
3. 模型定义
class Net(paddle.nn.Layer):
def __init__(self,vocab_size=len(char2id_dict),embedding_dim=256,hidden_dim=512, num_layers=3):
super(Net, self).__init__()
self.embeddings = paddle.nn.Embedding(vocab_size,embedding_dim)
self.lstm = paddle.nn.LSTM(
input_size=embedding_dim,
hidden_size=hidden_dim,
num_layers=num_layers,
)
self.linear = paddle.nn.Linear(in_features=hidden_dim,out_features=vocab_size)
def forward(self, x, hidden=None):
y = self.embeddings(x)
if hidden is None:
y, hidden = self.lstm(y)
else:
y, hidden = self.lstm(y, hidden)
y = self.linear(y)
return y, hidden
4. 模型验证
from work.poetry_utils import *
net = Net()
model_path = 'work/model.params.50'
net.set_state_dict(P.load(model_path))
# 下一行代码中输入想要续写的诗句内容,如 春江潮水连海平,
result1 = show1(result='春江潮水连海平', prefix='飞流直下三千尺,疑是银河落九天。', net = net, char2id_dict=char2id_dict, id2char_dict=id2char_dict)
print('续写:', result1)
/opt/conda/envs/python35-paddle120-env/lib/python3.7/site-packages/paddle/tensor/creation.py:125: DeprecationWarning: `np.object` is a deprecated alias for the builtin `object`. To silence this warning, use `object` by itself. Doing this will not modify any behavior and is safe.
Deprecated in NumPy 1.20; for more details and guidance: https://numpy.org/devdocs/release/1.20.0-notes.html#deprecations
if data.dtype == np.object:
续写: 春江潮水连海平,九疑不可入天东。沿江一去无归处,江湖渺渺天涯通。谪仙游者婵娟姿,余霞白日梨花红。故乡不在今人说,一一东风日日长。忆昔登龙南骑传,秦楼美酒蔼华烛。䌽童弦管怨瑶隗,金屋毵毵菜树头。君家南北不相见,妾身如此秦王渡。
# 此处可以生成自行想要的藏头诗,在代码中输入想要的藏头诗开头,如 我喜欢你。
result2 = show2(acrostic='我喜欢你', prefix='飞流直下三千尺,疑是银河落九天。', net = net, char2id_dict=char2id_dict, id2char_dict=id2char_dict)
`python
# 此处可以生成自行想要的藏头诗,在代码中输入想要的藏头诗开头,如 我喜欢你。
result2 = show2(acrostic='我喜欢你', prefix='飞流直下三千尺,疑是银河落九天。', net = net, char2id_dict=char2id_dict, id2char_dict=id2char_dict)
print('藏头诗:', result2)
藏头诗: 我有一声冲晓鼓,喜来一醉在中弦。欢然有意应难会,你尽无人独不眠。
总结
通过对LSTM以及seq2seq模型的学习,实现了让AI自动根据上联生成下联,根据所提供的诗歌首句来编写完整诗歌,或者根据用户所给句子来自动生成藏头诗。
从模型验证结果可以看出,经过训练后的网络模型都能够根据上联自动生成相对较为工整的下联,若能继续提升训练迭代次数,将会获得更为优秀的效果。在诗歌方面,AI所生成诗歌也与用户所给出的首句较为适配,模型也完美实现了藏头诗的自动生成,效果较为优秀。

学大模型,用大模型上飞桨星河社区!每天8点V100G算力免费领!免费领取ERNIE 4.0 100w Token >>>
更多推荐



 1
1 0
0- 0



 已为社区贡献1436条内容
已为社区贡献1436条内容

所有评论(0)