
ERNIE for CSC:【的、地、得】
基于PaddleNLP的中文文本纠错任务:ERNIE for Chinese Spelling Correction简介
引言
“的、地、得”傻傻分不清?打字太快常出错别字,有时还闹出尴尬的笑话?
在拼音输入法广泛使用的今天,因为拼写导致的错别字情况总是难以避免,更糟糕的是,当文字材料页数过多时,要进行人工复核工作量很大、效率还低。笔者就经常遇到类似困扰,对于一些重要的材料,往往自己反复核对了心里也不见得有底,拜托同事帮忙复核还总能揪出错误。
那么,有没有一种方法,可以又快又好地自动帮我们核对下稿子呢?PaddleNLP有话说!
ERNIE for Chinese Spelling Correction
中文文本纠错(CSC)任务是一项NLP基础任务,其输入是一个可能含有语法错误的中文句子,输出是一个正确的中文句子。语法错误类型很多,有多字、少字、错别字等,目前最常见的错误类型是错别字。大部分研究工作围绕错别字这一类型进行研究。
在PaddleNLP中,就将文本纠错视为一项NLP核心任务。目前,PaddleNLP开源的ERNIE for Chinese Spelling Correction就在SIGHAN数据集上取得SOTA的效果,它是基于ERNIE预训练模型融合拼音特征的端到端中文拼写纠错模型。
环境和数据集准备
# 拉取PaddleNLP
!git clone https://gitee.com/paddlepaddle/PaddleNLP.git
# 本项目paddlenlp的版本要升到2.1
!pip install paddlenlp==2.1
# 原始的训练数据集在github上,这里在码云找了个镜像加速
# !git clone https://github.com/wdimmy/Automatic-Corpus-Generation.git
!git clone https://gitee.com/myth_psy/Automatic-Corpus-Generation.git
# 把训练数据集移动到ernie-csc所在目录下
!mkdir PaddleNLP/examples/text_correction/ernie-csc/extra_train_ds
!cp Automatic-Corpus-Generation/corpus/train.sgml PaddleNLP/examples/text_correction/ernie-csc/extra_train_ds
%cd PaddleNLP/examples/text_correction/ernie-csc/
/home/aistudio/PaddleNLP/examples/text_correction/ernie-csc
# 安装依赖包
!pip install -r requirements.txt
数据集介绍
在本文中,我们使用的训练数据集来自论文 A Hybrid Approach to Automatic Corpus Generation for Chinese Spelling Check 的开源项目 https://github.com/wdimmy/Automatic-Corpus-Generation
这篇论文做的工作,就是为了给中文文本纠错任务提供数据,实现了该任务下的数据自动生成工作。
做法:大量无标注数据,根据 形近似和音近似 两个方面来替换其中的一部分字符。
形近:把一个字转化为图片,把图片模糊一部分,用OCR进行扫描,选出识别错误的,去进行替换。
音近:收集普通话演讲语料和演讲,用ASR对演讲进行语音识别,然后,对比识别结果,如果不一样,就作为生成的错误数据。

当然,这种做法必然产生不少bad case,比如【领】可能被错误识别成【铈】,而人的打字中很少会犯这种错误,所以再引入笔画的相似度来衡量错误字对。ASR的构建方法也类似,同时忽略拼音差异大或者错误太多的case。
最终我们会发现,构建出的数据集效果还是很显著的,也比较符合常理。毕竟中文文本纠错任务这个任务对数据的要求太高了,采用论文的构建方式比较直观,在bad case上的处理也比较好。
因此在ERNIE for Chinese Spelling Correction中,就直接使用了论文构建的混淆集,作为数据集。
参考资料
- DingminWang et al. “A Hybrid Approach to Automatic Corpus Generation for Chinese Spelling Check”, EMNLP, 2018
- 文献阅读笔记-CSC-数据集-A Hybrid Approach to Automatic Corpus Generation for Chinese Spelling Check
- NLP-语法纠错不完全调研
数据集处理
在论文 A Hybrid Approach to Automatic Corpus Generation for Chinese Spelling Check 中,最后给出的中文文本纠错的混淆集,是是sgml格式的,如果用txt打开,我们会发现其格式类似xml格式。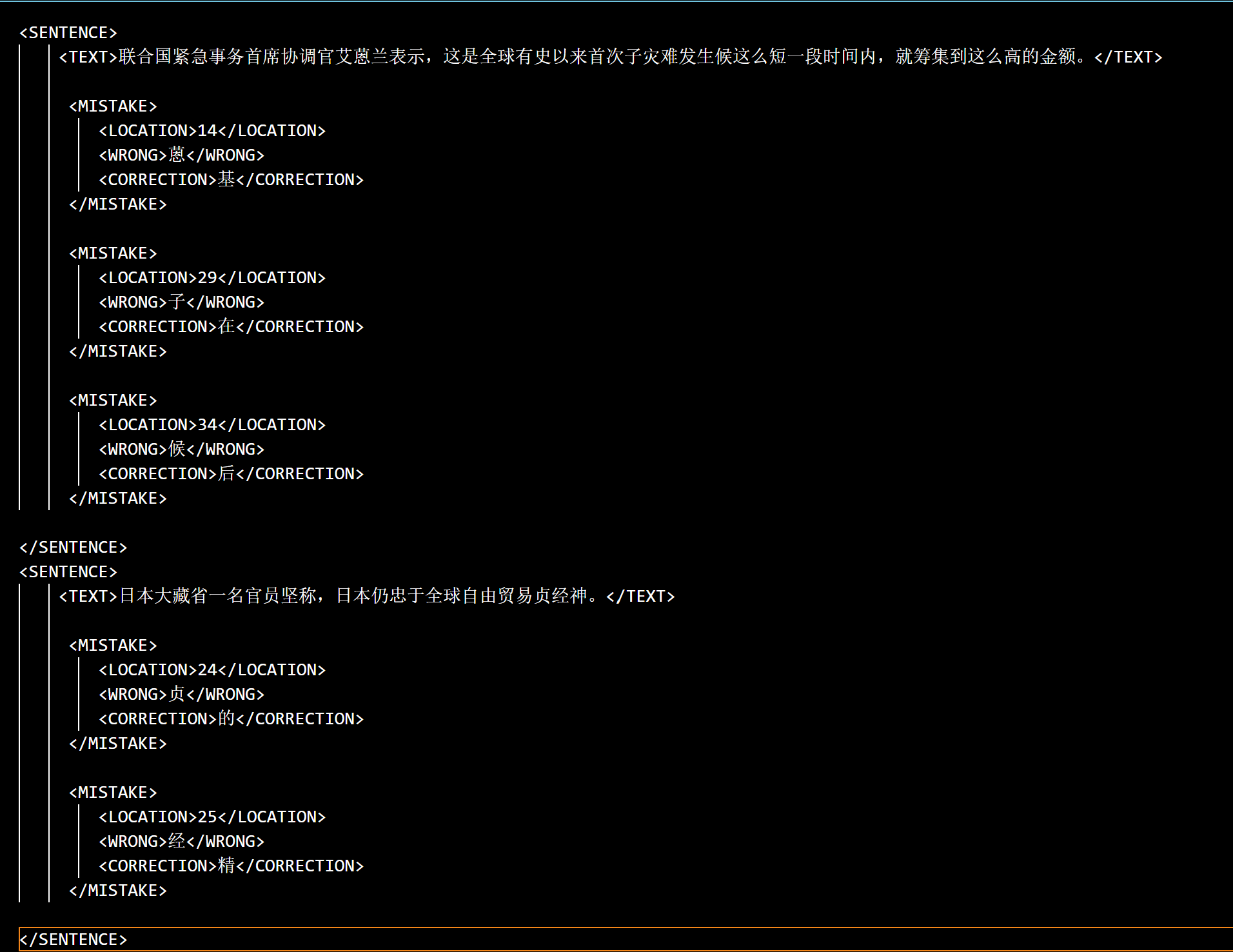
本文给出两种处理方法:
- 用beautifulsoup解析
- 对dom树解析(PaddleNLP的做法)
beautifulsoup解析
效果相对比较直观,生成的csv文件显示如下:
!pip install beautifulsoup4
import logging
import os
import codecs
from tqdm import tqdm
from bs4 import BeautifulSoup
import pandas as pd
def replace_char(string,char,index):
string = list(string)
string[index] = char
return ''.join(string)
def read_langs(file_name):
logging.info(("Reading lines from {}".format(file_name)))
total_data=[]
with codecs.open(file_name, "r", "utf-8") as file:
data = file.read()
soup = BeautifulSoup(data, 'html.parser')
results = soup.find_all('sentence')
for item in tqdm(results):
text = item.find("text").text.strip()
correct_text=text
mistakes = item.find_all("mistake")
locations = []
for mistake in mistakes:
location = mistake.find("location").text.strip()
wrong = mistake.find("wrong").text.strip()
correction_word=mistake.find('correction').text.strip()
correct_text=replace_char(correct_text,correction_word,int(location)-1)
locations.append(int(location))
if text[int(location)-1] != wrong:
print("The character of the given location does not equal to the real character")
sen = list(text)
tags = ["0" for _ in range(len(sen))]
for i in locations:
tags[i - 1] = "1"
total_data.append([correct_text,text, " ".join(tags)])
return total_data
file_name='./extra_train_ds/train.sgml'
total_data=read_langs(file_name)
column_name = ['origin_text','random_text','label']
# 生成一个csv文件,把正确语句、生成语句、标签保存下来
csv_name='Automatic-Corpus-Generation.csv'
xml_df = pd.DataFrame(total_data, columns=column_name)
xml_df.to_csv(csv_name, index=None)
对dom树解析
在PaddleNLP给出的change_sgml_to_txt.py脚本中,会直接把数据集处理为要送入训练的句对形式。
具体形式为错误语句\t正确语句
with open(args.output, "w", encoding="utf-8") as fw:
with open(args.input, 'r', encoding='utf-8') as f:
input_str = f.read()
# Add fake root node <SENTENCES>
input_str = '<SENTENCES>' + input_str + '</SENTENCES>'
dom = xml.dom.minidom.parseString(input_str)
example_nodes = dom.documentElement.getElementsByTagName('SENTENCE')
for example in example_nodes:
raw_text = example.getElementsByTagName('TEXT')[0].childNodes[
0].data
correct_text = list(raw_text)
mistakes = example.getElementsByTagName('MISTAKE')
for mistake in mistakes:
loc = int(
mistake.getElementsByTagName('LOCATION')[0].childNodes[0]
.data) - 1
correction = mistake.getElementsByTagName('CORRECTION')[
0].childNodes[0].data
correct_text[loc] = correction
correct_text = ''.join(correct_text)
fw.write("{}\t{}\n".format(raw_text, correct_text))
!python change_sgml_to_txt.py -i extra_train_ds/train.sgml -o extra_train_ds/train.txt
# 查看处理后的训练集
!head extra_train_ds/train.txt
联合国紧急事务首席协调官艾蒽兰表示,这是全球有史以来首次子灾难发生候这么短一段时间内,就筹集到这么高的金额。 联合国紧急事务首席协调官艾基兰表示,这是全球有史以来首次在灾难发生后这么短一段时间内,就筹集到这么高的金额。
日本大藏省一名官员坚称,日本仍忠于全球自由贸易贞经神。 日本大藏省一名官员坚称,日本仍忠于全球自由贸易的精神。
小泉承诺将革除始曰苯陷于十年经济衰退的弊病。 小泉承诺将革除使日本陷于十年经济衰退的弊病。
澳洲首家母乳银行痔于明年开张莒业,一因应早产儿和高龄母亲越来越殷切的母乳需求。 澳洲首家母乳银行将于明年开张营业,以因应早产儿和高龄母亲越来越殷切的母乳需求。
杜楚所,它看到卫恩斯坦在对其中一名女堇性侵害。 杜楚说,他看到卫恩斯坦在对其中一名女童性侵害。
在故王毕兰德拉的第第贾南德拉登基后,加德满都四曰爆发大规模抗意行动。 在故王毕兰德拉的弟第贾南德拉登基后,加德满都四日爆发大规模抗议行动。
铃术再两好三坏虾,挥出穿越中线的安打破纪录的那一刻,比赛为之中止,水手队球员一拥而上,现场施放烟火,球迷起立鼓掌欢呼。 铃木在两好三坏下,挥出穿越中线的安打破纪录的那一刻,比赛为之中止,水手队球员一拥而上,现场施放烟火,球迷起立鼓掌欢呼。
城府宫员表示,这是过去三十六小时内第三期强烈的余震。 政府官员表示,这是过去三十六小时内第三起强烈的余震。
世界银行禾国际货币基金会亦揭示于未未五年内提共高达九十二亿五干万美元协助伊拉克重建的贷款方案。 世界银行和国际货币基金会亦揭示于未未五年内提供高达九十二亿五千万美元协助伊拉克重建的贷款方案。
万豪万家浙江冬日两家浙江老牌房企。 万好万家浙江东日两家浙江老牌房企。
论文解读
论文 Correcting Chinese Spelling Errors with Phonetic Pre-training 是百度在ACL 2021上提出结合拼音特征的Softmask策略的中文错别字纠错的下游任务网络。
这篇论文的创新点主要在于:
构建了一整套端到端的中文文本纠错模型,包括构建预训练语言模型MLM-phonetics和微调下游纠错任务。
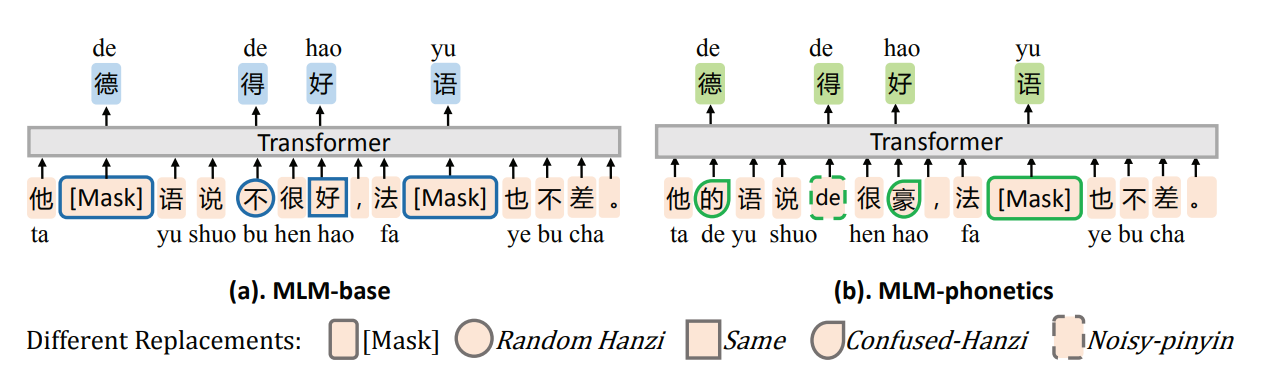
Pre-training MLM-phonetics(加入语音信息的Mask语言模型)
论文中对比了MLM-base和MLM-phonetics的差异:
-
遮盖范围
MLM-base 遮盖了15%的词进行预测;
MLM-phonetics 遮盖了20%的词进行预测。
-
遮盖策略
MLM-base 的遮盖策略基于以下3种:
- [MASK]标记替换(和BERT一致)
- 随机字符替换(Random Hanzi)
- 原词不变(Same)
且3种遮盖策略占比分别为: 80% 、10%、10%。
MLM-phonetics的Mask策略基于以下3种:
- [MASK]标记替换(和BERT一致)
- 字音混淆词替换(Confused-Hanzi)
- 混淆字符的拼音替换(Noisy-pinyin)。
且这3种遮盖策略分别占比为: 40%、30%、30%。
为什么在MLM-phonetics中设置字音混淆词替换和混淆字符拼音替换?
论文指出,主要是下面两个原因:
-
避免输入差异
- MLM-base的输入字符都是正确的,然而在下游纠错任务的输入字符可能是错误的。这种情况会导致预训练和下游任务在输入上的差异。
- MLM-phonetics通过设置字音混淆词替换可以缓解这种输入差异的情况。
-
融入语音特征
- MLM-phonetics通过设置混淆字符拼音替换的遮盖策略,可以将发音类似的字符与其对应的拼音进行关联。
端到端文本纠错模型
端到端文本纠错包括Detection Module和Correction Module2个部分。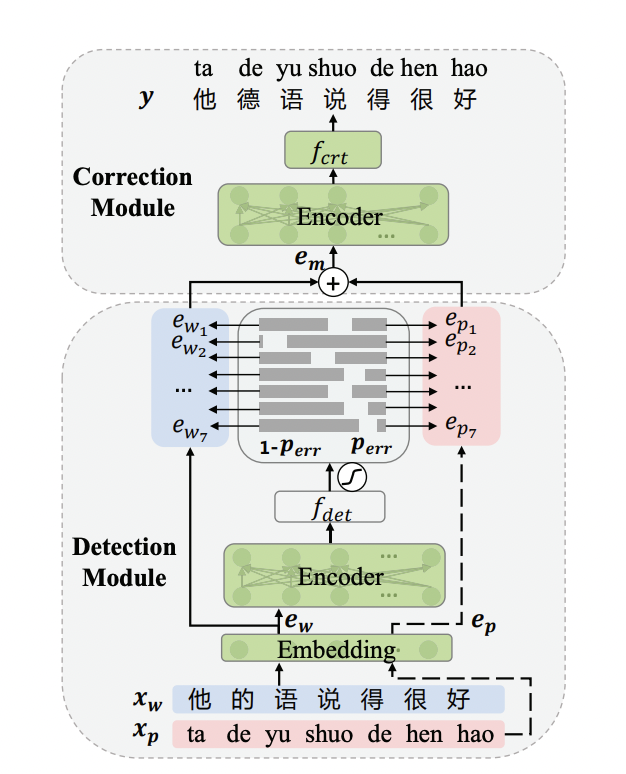
注:论文中暂未开源融合字音特征的预训练模型参数(即MLM-phonetics),所以PaddleNLP提供的ERNIE for Chinese Spelling Correction是在ERNIE-1.0的参数上进行Finetune,纠错模型结构与论文保持一致。
参考资料
- Correcting Chinese Spelling Errors with Phonetic Pre-training
- 2021ACL中文文本纠错论文:Correcting Chinese Spelling Errors with Phonetic Pre-training 论文笔记
模型训练、预测和部署
开始训练
在本项目中,演示的是单卡训练,训练10个epoch大概在10小时以内。
在训练脚本train.py中,可以适当引入visualdl,记录训练过程。
if global_steps % args.logging_steps == 0:
logger.info(
"global step %d, epoch: %d, batch: %d, loss: %f, speed: %.2f step/s"
% (global_steps, epoch, step, loss,
args.logging_steps / (time.time() - tic_train)))
# 记录loss变化
writer.add_scalar(tag="loss", step=global_steps, value=loss)
tic_train = time.time()

# 每个epoch做一次验证,而1个epoch是8794个steps
7107436466)]
```python
# 每个epoch做一次验证,而1个epoch是8794个steps
!python train.py --batch_size 32 --logging_steps 100 --save_steps 8794 --epochs 10 --learning_rate 5e-5 --model_name_or_path ernie-1.0 --output_dir ./checkpoints/ --extra_train_ds_dir ./extra_train_ds/ --max_seq_length 192
在评估时,会对定位错别字和纠正错别字的效果进行评估,不断迭代最优模型。
比如在第1个epoch训练结束后,评估效果如下:
[2021-10-31 01:18:03,812] [ INFO] - Sentence-Level Performance:
[2021-10-31 01:18:03,812] [ INFO] - Detection metric: F1=0.3490, Recall=0.2925, Precision=0.4326
[2021-10-31 01:18:03,812] [ INFO] - Correction metric: F1=0.0459, Recall=0.0325, Precision=0.0781
[2021-10-31 01:18:07,684] [ INFO] - Save best model at 8794 step.
[2021-10-31 01:18:08,743] [ INFO] - Save model at 8794 step.
模型预测
预测SIGHAN测试集
SIGHAN 13,SIGHAN 14,SIGHAN 15是目前中文错别字纠错任务常用的benchmark数据。由于SIGHAN官方提供的是繁体字数据集,PaddleNLP将提供简体版本的SIGHAN测试数据。以下运行SIGHAN预测脚本:
sh run_sighan_predict.sh
该脚本会下载SIGHAN数据集,加载checkpoint的模型参数运行模型,输出SIGHAN测试集的预测结果到predict_sighan文件,并输出预测效果。
注:如果我们仔细看下
run_sighan_predict.sh脚本内容,就会发现简体版本的SIGHAN测试数据链接是在download.py中写好的,需要的可以直接到链接中下载。
参考预测效果
| Metric | SIGHAN 13 | SIGHAN 14 | SIGHAN 15 |
|---|---|---|---|
| Detection F1 | 0.8348 | 0.6534 | 0.7464 |
| Correction F1 | 0.8217 | 0.6302 | 0.7296 |
!sh run_sighan_predict.sh
100%|██████████████████████████████████████| 229/229 [00:00<00:00, 13131.75it/s]
[32m[2021-10-31 11:31:22,211] [ INFO][0m - Already cached /home/aistudio/.paddlenlp/models/ernie-1.0/vocab.txt[0m
[32m[2021-10-31 11:31:22,222] [ INFO][0m - Already cached /home/aistudio/.paddlenlp/models/ernie-1.0/ernie_v1_chn_base.pdparams[0m
W1031 11:31:22.223605 23783 device_context.cc:404] Please NOTE: device: 0, GPU Compute Capability: 7.0, Driver API Version: 11.0, Runtime API Version: 10.1
W1031 11:31:22.227308 23783 device_context.cc:422] device: 0, cuDNN Version: 7.6.
[32m[2021-10-31 11:31:26,081] [ INFO][0m - Weights from pretrained model not used in ErnieModel: ['cls.predictions.layer_norm.weight', 'cls.predictions.decoder_bias', 'cls.predictions.transform.bias', 'cls.predictions.transform.weight', 'cls.predictions.layer_norm.bias'][0m
[32m[2021-10-31 11:31:27,328] [ INFO][0m - Load model from checkpoints: checkpoints/best_model.pdparams[0m
[0m[32m[2021-10-31 11:31:36,204] [ INFO][0m - Already cached /home/aistudio/.paddlenlp/models/ernie-1.0/vocab.txt[0m
[32m[2021-10-31 11:31:36,215] [ INFO][0m - Already cached /home/aistudio/.paddlenlp/models/ernie-1.0/ernie_v1_chn_base.pdparams[0m
W1031 11:31:36.216907 23868 device_context.cc:404] Please NOTE: device: 0, GPU Compute Capability: 7.0, Driver API Version: 11.0, Runtime API Version: 10.1
W1031 11:31:36.220628 23868 device_context.cc:422] device: 0, cuDNN Version: 7.6.
[32m[2021-10-31 11:31:40,088] [ INFO][0m - Weights from pretrained model not used in ErnieModel: ['cls.predictions.layer_norm.weight', 'cls.predictions.decoder_bias', 'cls.predictions.transform.bias', 'cls.predictions.transform.weight', 'cls.predictions.layer_norm.bias'][0m
[32m[2021-10-31 11:31:41,334] [ INFO][0m - Load model from checkpoints: checkpoints/best_model.pdparams[0m
[0m[32m[2021-10-31 11:31:49,500] [ INFO][0m - Already cached /home/aistudio/.paddlenlp/models/ernie-1.0/vocab.txt[0m
[32m[2021-10-31 11:31:49,520] [ INFO][0m - Already cached /home/aistudio/.paddlenlp/models/ernie-1.0/ernie_v1_chn_base.pdparams[0m
W1031 11:31:49.521512 23946 device_context.cc:404] Please NOTE: device: 0, GPU Compute Capability: 7.0, Driver API Version: 11.0, Runtime API Version: 10.1
W1031 11:31:49.525247 23946 device_context.cc:422] device: 0, cuDNN Version: 7.6.
[32m[2021-10-31 11:31:53,352] [ INFO][0m - Weights from pretrained model not used in ErnieModel: ['cls.predictions.layer_norm.weight', 'cls.predictions.decoder_bias', 'cls.predictions.transform.bias', 'cls.predictions.transform.weight', 'cls.predictions.layer_norm.bias'][0m
[32m[2021-10-31 11:31:54,625] [ INFO][0m - Load model from checkpoints: checkpoints/best_model.pdparams[0m
[0m-e Sighan13 Performace
==========================================================
Overall Performance
==========================================================
Detection Level
Precision = 1.0000 (690/690)
Recall = 0.6914 (690/998)
F1-Score = 0.8175 ((2*1.0000*0.6914)/(1.0000+0.6914))
Correction Level
Precision = 1.0000 (677/677)
Recall = 0.6784 (677/998)
F1-Score = 0.8084 ((2*1.0000*0.6784)/(1.0000+0.6784))
==========================================================
-e Sighan14 Performace
==========================================================
Overall Performance
==========================================================
Detection Level
Precision = 0.6609 (341/516)
Recall = 0.6422 (341/531)
F1-Score = 0.6514 ((2*0.6609*0.6422)/(0.6609+0.6422))
Correction Level
Precision = 0.6542 (331/506)
Recall = 0.6234 (331/531)
F1-Score = 0.6384 ((2*0.6542*0.6234)/(0.6542+0.6234))
==========================================================
-e Sighan15 Performace
==========================================================
Overall Performance
==========================================================
Detection Level
Precision = 0.7012 (413/589)
Recall = 0.7509 (413/550)
F1-Score = 0.7252 ((2*0.7012*0.7509)/(0.7012+0.7509))
Correction Level
Precision = 0.6912 (394/570)
Recall = 0.7164 (394/550)
F1-Score = 0.7036 ((2*0.6912*0.7164)/(0.6912+0.7164))
==========================================================
如果将我们单卡训练10个epoch在benchmark的评估效果与官方给出的参考对比,会发现差距还是比较大的,因此模型其实还有继续优化的空间。
预测部署
模型导出
使用动态图训练结束之后,预测部署需要导出静态图参数,具体做法需要运行模型导出脚本export_model.py。以下是脚本参数介绍以及运行方式:
参数
params_path是指动态图训练保存的参数路径。output_path是指静态图参数导出路径。pinyin_vocab_file_path指拼音表路径。model_name_or_path目前支持的预训练模型有:“ernie-1.0”。
!python export_model.py --params_path checkpoints/best_model.pdparams --output_path ./infer_model/static_graph_params
导出静态图参数后,我们也可以到VisualDL里面去查看模型的网络结构图了。
静态图部署预测
导出模型之后,可以用于预测部署,predict.py文件提供了python预测部署示例。
输入待纠错的语句:
samples = [
'遇到逆竟时,我们必须勇于面对,而且要愈挫愈勇,这样我们才能朝著成功之路前进。',
'人生就是如此,经过磨练才能让自己更加拙壮,才能使自己更加乐观。',
]
!python predict.py --model_file infer_model/static_graph_params.pdmodel --params_file infer_model/static_graph_params.pdiparams
中文文本纠错效果如下:
Source: 遇到逆竟时,我们必须勇于面对,而且要愈挫愈勇,这样我们才能朝著成功之路前进。
Target: 遇到逆境时,我们必须勇于面对,而且要愈挫愈勇,这样我们才能朝著成功之路前进。
Source: 人生就是如此,经过磨练才能让自己更加拙壮,才能使自己更加乐观。
Target: 人生就是如此,经过磨练才能让自己更加茁壮,才能使自己更加乐观。
Taskflow一键预测
可以使用PaddleNLP提供的Taskflow工具来对输入的文本进行一键纠错。
paddlenlp.Taskflow是旨在提供开箱即用的NLP预置任务,覆盖自然语言理解与自然语言生成两大核心应用,在中文场景上提供产业级的效果与极致的预测性能。也就是说,其实官方早就为我们封装好了当前SOTA的中文文本纠错模型,直接用也行!
具体使用方法如下:
from paddlenlp import Taskflow
text_correction = Taskflow("text_correction")
text_correction('在拼音输入法广泛使用德今天,因为拼写导致得错别字情况总是难以避免。更糟糕的是,当文字材料地页数过多时,要进行人工复核工作量很大、效率还低。笔者就经常遇到类似困扰,对于一些重要的材料,往往反复核对了心里也不见得有底,拜托同事帮忙复核还总能揪出错误。')
[2021-10-31 14:04:31,462] [ INFO] - Already cached /home/aistudio/.paddlenlp/models/ernie-1.0/vocab.txt
[{'source': '在拼音输入法广泛使用德今天,因为拼写导致得错别字情况总是难以避免。更糟糕的是,当文字材料地页数过多时,要进行人工复核工作量很大、效率还低。笔者就经常遇到类似困扰,对于一些重要的材料,往往反复核对了心里也不见得有底,拜托同事帮忙复核还总能揪出错误。',
'target': '在拼音输入法广泛使用的今天,因为拼写导致的错别字情况总是难以避免。更糟糕的是,当文字材料的页数过多时,要进行人工复核工作量很大、效率还低。笔者就经常遇到类似困扰,对于一些重要的材料,往往反复核对了心里也不见得有底,拜托同事帮忙复核还总能揪出错误。',
'errors': [{'position': 10, 'correction': {'德': '的'}},
{'position': 20, 'correction': {'得': '的'}},
{'position': 44, 'correction': {'地': '的'}}]}]
小结
再也不怕“的、地、得”分不清了!以后,文字材料又多了个把关的小帮手!
下一步,将研究怎么将这个中文文本纠错模型用于实践中,比如上传word文档自动查错,又比如结合机器翻译、语音识别,自动纠错。(坑越挖越多了……)

学大模型,用大模型上飞桨星河社区!每天8点V100G算力免费领!免费领取ERNIE 4.0 100w Token >>>
更多推荐



 0
0 0
0- 0



 已为社区贡献1437条内容
已为社区贡献1437条内容

所有评论(0)