
飞桨常规赛:图神经网络入门节点分类-七月第7名方案
百度飞桨比赛:https://aistudio.baidu.com/aistudio/competition/detail/59 ;七月第七名,本项目基于paddle 2.1.0 和 PGL 实现。
比赛介绍
比赛地址: https://aistudio.baidu.com/aistudio/competition/detail/59
飞桨(PaddlePaddle)以百度多年的深度学习技术研究和业务应用为基础,是中国首个开源开放、技术领先、功能完备的产业级深度学习平台。更多飞桨资讯,点击此处查看。
飞桨常规赛由百度飞桨于2019年发起,面向全球AI开发者,赛题范围广,涵盖领域多。常规赛旨在通过长期发布的经典比赛项目,为开发者提供学习锻炼机会。
赛题介绍
本次赛题数据集由学术网络图构成,该图会给出每个节点的特征,以及节点与节点间关系(训练集节点的标注结果已给出)。
数据:
输入数据是一整张图,该图包含1647958条有向边,130644个节点。
提供的数据文件说明:
| 数据集 | 简介 |
|---|---|
| edges.csv | 边数据:用于标记论文间引用关系 |
| feat.npy | 节点数据:每个节点含100维特征 |
| train.csv | 训练集数据 |
| test.csv | 测试集数据 |
-
edges.csv,用于标记论文引用关系,为无向图,且由两列组成,没有表头。
-
feat.npy, Numpy格式存储的节点特征矩阵,Shape为(130644, 100),可以用numpy.load(“feat.npy”)
-
train.csv,包含两个字段,nid 和 label。
-
test.csv,只包含 nid
提交结果介绍
提交内容与格式
最终提交的submission.csv 格式如下:
| 字段 | 说明 |
|---|---|
| nid | 测试集节点在图上的id |
| label | 测试集的节点类别 |
提交样例
| nid | label |
|---|---|
| 2 | 34 |
| 3 | 1 |
| 4 | 5 |
| … | … |
项目杂谈
环境
1)AI studio; 这个不用说,32G V100 谁用谁知道,白嫖的最香。
2)PaddlePaddle 2.1.0; 支持最新的动态图模型,简单易用,上手快。
3)PGL 2.1.5; PGL 2.0版本更加易用,并且github上还有各种模型使用的example,简直不要太好用。如果加上UniMP就更完美了。
说明
在七月份的这次比赛中,我们仅使用了单模型,没有进行模型融合,取得的分数为0.74777,获得第七名。 比较遗憾的是,模型文件被覆盖掉了。因此无法复现出原来的结果。但是我们在八月初跑出了0.74938的分数,我们将提供跑出这个结果的预训练模型
项目贡献
我们的项目是第一个使用paddle2.1.0去打这个比赛的,因此我们的整个项目都是基于动态图模型,相较于paddle1.8更容易理解和修改,并且使用的是最新版本的PGL 2.1.5,这个版本代码更加易用并且容易理解和上手。
不足之处
由于时间关系,我们仅利用了PGL提供的一些基本图卷积算法,例如GCN,GAT,APPNP,GCNII等,没有使用更复杂的模型,比如榜首使用UniMP算法,因为没有找到现成的动态图实现,加上时间不够,也没有机会去复现这个算法,不然结果应该会更好。有机会我们会尝试用动态图模型去复现这个算法。
项目介绍
我们将整个项目目录结构如下:
.
├── config.py // 模型的基本配置参数
├── model // 保存训练好的模型
├── network // 使用的图神经网络算法
│ ├── appnp.py
│ ├── gat.py
│ ├── gcnii.py
│ ├── gcn.py
│ ├── __init__.py
│ └── transformer.py
├── result // 每个模型跑出的结果文件
│ ├── APPNP.csv
│ ├── GAT.csv
│ ├── gat-lstm.csv
│ ├── gcn.csv
│ ├── GCN.csv
│ ├── gcn-lstm.csv
│ ├── ResGAT.csv
│ └── sage.csv
├── submission.csv // 提交的结果文件
├── train.py // 训练文件
└── util // 数据集加载以及准确率计算和模型创建函数
├── __init__.py
├── load_dataset.py
└── tools.py
整个项目已经完全结构化,如果需要定义自己的模型,可以将模型加入到network文件夹下,然后在 ./util/tools.py 中定义模型的初始化。 最后在train.py 中调用config, model = get_config_model(‘model_name’) 即可。
思路介绍
我们尝试了不同的模型,GCN, GAT, GCNII, APPNP等。 后来又在GAT的基础上引入了ResGAT,本次实验的结果也是基于ResGAT。ResGAT相对于GCN效果要好很多,缺点是比较费显存,需要在32G显卡上运行,训练速度也比较慢。
network文件夹下面有我们尝试的其他模型,可以自己跑一跑。
代码
# 首先安装最新版本的pgl
!pip install pgl
Looking in indexes: https://mirror.baidu.com/pypi/simple/
Collecting pgl
[?25l Downloading https://mirror.baidu.com/pypi/packages/4f/77/f7da1735b936a9ce1b199d7d0cf00379d8c53f3f6ae7ca93ec585fe2342f/pgl-2.1.5-cp37-cp37m-manylinux_2_5_x86_64.manylinux1_x86_64.whl (7.9MB)
[K |████████████████████████████████| 7.9MB 16.7MB/s eta 0:00:01
[?25hRequirement already satisfied: cython>=0.25.2 in /opt/conda/envs/python35-paddle120-env/lib/python3.7/site-packages (from pgl) (0.29)
Requirement already satisfied: numpy>=1.16.4 in /opt/conda/envs/python35-paddle120-env/lib/python3.7/site-packages (from pgl) (1.20.3)
Installing collected packages: pgl
Successfully installed pgl-2.1.5
导入包
import paddle
import paddle.nn as nn
import paddle.nn.functional as F
from visualdl import LogWriter
from util import *
import pandas as pd
import os
参数设置
# 定义参数配置
class Config(object):
def __init__(self):
# 文件路径定义
self.data_path = './data/data101014'
self.test = os.path.join(self.data_path, 'test.csv')
self.train = os.path.join(self.data_path, 'train.csv')
self.edges = os.path.join(self.data_path, 'edges.csv')
self.feat = os.path.join(self.data_path, 'feat.npy')
self.model_path = './model'
self.result_path = './result'
# 超参数定义
self.lr = 1e-3
self.epoch = 8000
self.num_class = 35
self.in_features = 100 # 输入节点特征维度,固定为100维
# 继承自Config类
# Config类中定义了基础的参数配置
class GATConfig(Config):
def __init__(self):
super(GATConfig, self).__init__()
# 模型名字,模型保存和结果保存均使用这个前缀
self.model_name = 'ResGAT'
# 表示搭建几层网络
self.num_layers = 3
# 每一层的输出特征维度
self.out_features_per_layer = [64, 64, self.num_class]
# 每一层中注意力头的个数
self.num_heads_per_layer = [8, 8, 8]
# dropout
self.feat_drop = 0.3
self.attn_drop = 0.3
定义模型
# 基于残差连接的图注意力神经网络
class ResGAT(nn.Layer):
"""Implement of ResGAT
"""
def __init__(self, in_features, out_features_per_layer, num_heads_per_layer, num_layers=3, feat_drop=0.2, attn_drop=0.6):
super(ResGAT, self).__init__()
hidden_size = out_features_per_layer[0] * num_heads_per_layer[0]
# 仅进行线性映射,不加偏置
self.in_features_proj = nn.Linear(in_features, hidden_size, bias_attr=False)
self.num_layers = num_layers
self.ln = nn.LayerNorm(hidden_size)
out_features_per_layer = [hidden_size] + out_features_per_layer
num_heads_per_layer = [1] + num_heads_per_layer
self.gats = nn.LayerList()
for i in range(num_layers):
self.gats.append(
GATConv(out_features_per_layer[i] * num_heads_per_layer[i],
out_features_per_layer[i+1],
feat_drop,
attn_drop,
num_heads_per_layer[i+1],
concat=True if i < num_layers - 1 else False, # 只有最后一层不使用concat方法
activation='elu' if i < num_layers - 1 else None
)
)
def forward(self, graph, feature):
feature_proj = self.in_features_proj(feature)
# out = None
# for i, m in enumerate(self.gats):
# out = m(graph, feature_proj)
# if i < self.num_layers - 1:
# out = out + feature_proj
# feature_proj = self.ln(out)
out1 = self.gats[0](graph, feature_proj)
feature_proj = out1 + feature_proj
out2 = self.gats[1](graph, feature_proj)
feature_proj = out2 + feature_proj
out3 = self.gats[2](graph, feature_proj)
return out3
模型训练
# 模型训练
def train(node_index, node_label, model, graph, criterion, optim):
model.train()
pred = model(graph, graph.node_feat["feat"])
pred = paddle.gather(pred, node_index)
loss = criterion(pred, node_label)
loss.backward()
pred = paddle.argmax(F.softmax(pred, axis=1), axis=1).numpy()
node_label = node_label.flatten().numpy()
acc = calc_accuracy(pred, node_label)
optim.step()
optim.clear_grad()
return loss.numpy()[0], acc
# 模型评估
def evaluate(node_index, node_label, model, graph, criterion):
model.eval()
pred = model(graph, graph.node_feat["feat"])
pred = paddle.gather(pred, node_index)
loss = criterion(pred, node_label)
pred = paddle.argmax(F.softmax(pred, axis=1), axis=1).numpy()
node_label = node_label.flatten().numpy()
acc = calc_accuracy(pred, node_label)
return loss.numpy()[0], acc
# 模型预测
def predict(model, config, graph):
# 加载预训练模型参数
model.set_dict(paddle.load(os.path.join(config.model_path, config.model_name + '.params')))
model.eval()
# 加载数据集并进行预测
test_ids = load_test(config.test)
pred = model(graph, graph.node_feat["feat"])
pred = paddle.gather(pred, test_ids)
pred = paddle.argmax(F.softmax(pred, axis=1), axis=1).numpy()
# 保存预测结果文件
df = pd.DataFrame({'nid': test_ids, 'label': pred})
df.to_csv(os.path.join(config.result_path, config.model_name + '.csv'), index=False)
df.to_csv('submission.csv', index=False)
def main(is_train=True, is_predict=True):
# 获取配置信息和模型
config = GATConfig()
model = ResGAT(
config.in_features,
config.out_features_per_layer,
config.num_heads_per_layer,
config.num_layers,
config.feat_drop,
config.attn_drop)
print('train model: ', config.model_name)
# 定义损失函数,优化器
criterion = paddle.nn.CrossEntropyLoss()
optimizer = paddle.optimizer.AdamW(parameters=model.parameters(), learning_rate=config.lr)
# 获取训练、测试数据
graph = build_graph(config)
graph.tensor()
train_ids, train_labels, eval_ids, eval_labels = load_train(config.train)
best_acc = 0.0
writer = LogWriter(logdir='./log', file_name='resgat')
if is_train:
print('start training...')
for epoch in range(config.epoch):
train_loss, train_acc = train(train_ids, train_labels, model, graph, criterion, optimizer)
eval_loss, eval_acc = evaluate(eval_ids, eval_labels, model, graph, criterion)
if epoch % 20 == 0:
print('epoch: {} train_loss: {:.4f} train_acc: {:.4f} eval_loss: {:.4f} eval_acc: {:.4f}'.format(
epoch, train_loss, train_acc, eval_loss, eval_acc))
writer.add_scalar(tag="acc", step=epoch, value=eval_acc)
writer.add_scalar(tag="loss", step=epoch, value=eval_loss)
# 每找到一个最好的模型就保存下来
if eval_acc > best_acc:
best_acc = eval_acc
paddle.save(model.state_dict(), os.path.join(config.model_path, config.model_name + '.params'))
if is_predict:
print('start predicting...')
predict(model, config, graph)
writer.close()
if __name__ == '__main__':
# 训练完成之后立即对结果进行预测
main(True, True)
结果
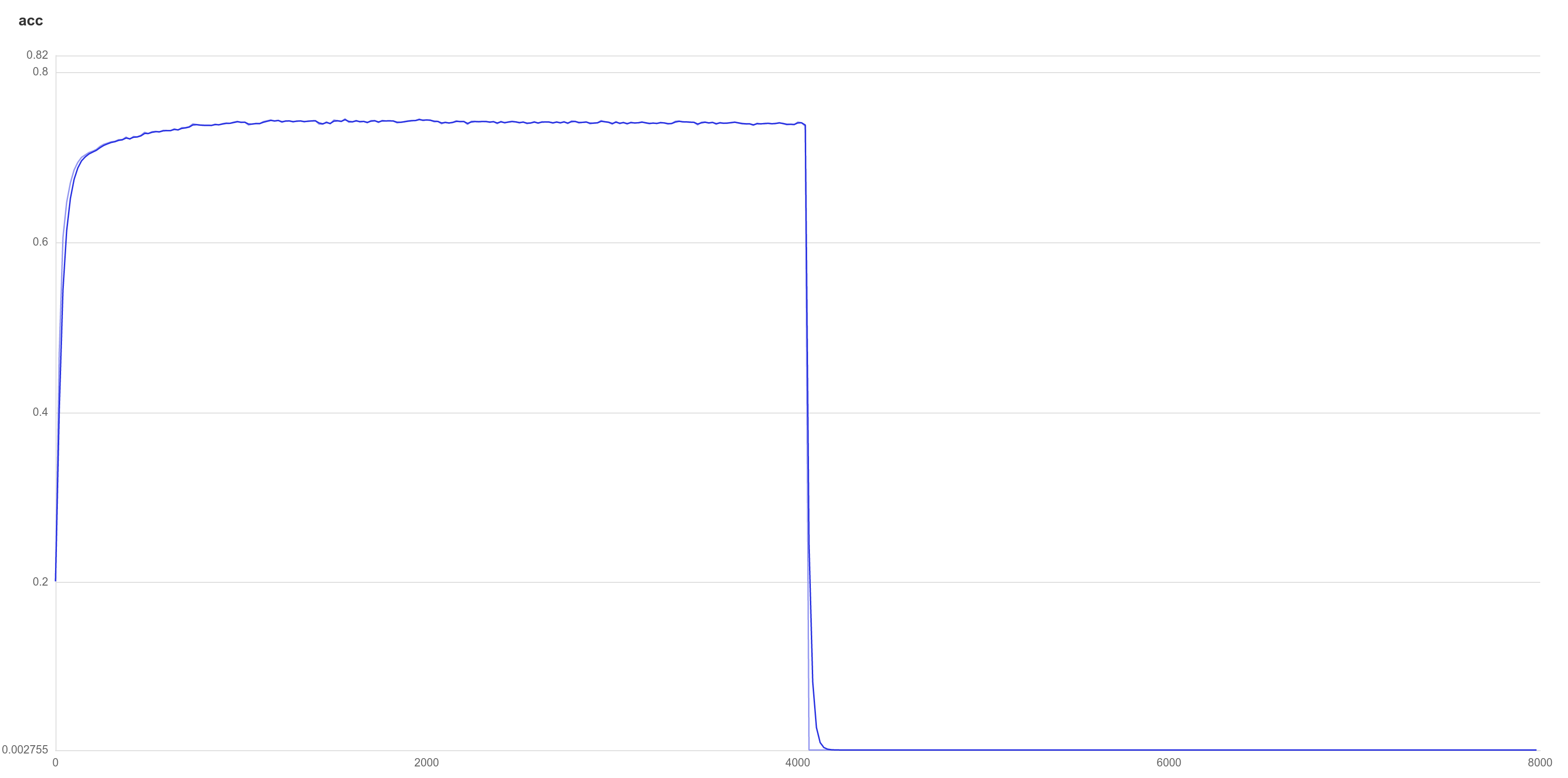
上图是模型准确率随训练轮数的变化,模型在700多轮的时候,就已经接近收敛了,然后模型取得最好的结果是在1560轮。之后在4000多轮的时候出现了梯度消失
梯度消失
训练到4000多轮的时候出现了梯度消失问题,这个问题在GAT网络中经常遇到;如果训练几十轮或者几百轮,模型未收敛,但是突然出现梯度消失问题,可以尝试降低网络层数或者增大dropout。
epoch: 3980 train_loss: 0.4416 train_acc: 0.8407 eval_loss: 1.1098 eval_acc: 0.7387
epoch: 4000 train_loss: 0.4414 train_acc: 0.8419 eval_loss: 1.1105 eval_acc: 0.7417
epoch: 4020 train_loss: 0.4434 train_acc: 0.8418 eval_loss: 1.1106 eval_acc: 0.7408
epoch: 4040 train_loss: 0.4393 train_acc: 0.8428 eval_loss: 1.1096 eval_acc: 0.7369
epoch: 4060 train_loss: 0.4374 train_acc: 0.8423 eval_loss: nan eval_acc: 0.0031
epoch: 4080 train_loss: nan train_acc: 0.0040 eval_loss: nan eval_acc: 0.0031
epoch: 4100 train_loss: nan train_acc: 0.0040 eval_loss: nan eval_acc: 0.0031
epoch: 4120 train_loss: nan train_acc: 0.0040 eval_loss: nan eval_acc: 0.0031
epoch: 4140 train_loss: nan train_acc: 0.0040 eval_loss: nan eval_acc: 0.0031
总结
从实验结果分析,可以有以下几点结论:
-
利用了注意力机制的网络要比没有用的效果更好,但是训练时间更长;
-
使用残差结构的网络要比没有用的效果更好,例如:ResGAT 效果比 GAT 效果更好
-
模型层数不宜过深,效果会下降
改进思路:
-
使用效果更好的模型,在这里我们使用的模型都是相对比较老的,基本上都是18年,19年提出的。可以尝试更新的模型,例如百度提出的UniMP模型,榜单上的top1都使用了这个模型。
-
还有就是可以尝试使用多模型投票策略,我们这仅使用了单模型的结果,没有进行多模型的融合。
-
除此之外还可以从模型的数据集上下手,整个图网络非常大,可以每次抽取部分节点进行训练,最后将训练出的节点特征进行融合,或许能学到不一样的东西。
学习建议
学习paddle,最好的方式就是去不断去跑一些demo,同时结合API 文档去学习。这个文档一定要当做字典去用,不会就查,但是不要想着从头到尾去学习所有接口,这是不现实的。字典是用来查的不是用来背的,用多了自然就记住了。
更进一步,基础打好之后,可以尝试用一些更高级的模型,比如PGL 2.1.5,可以让你事半功倍,自己造轮子,不如先拿造好的轮子来用。
还可从飞桨课程中学习,这里有很多领域的课程,跟大佬学习,比自己学习更快。
总结:

学大模型,用大模型上飞桨星河社区!每天8点V100G算力免费领!免费领取ERNIE 4.0 100w Token >>>
更多推荐



 0
0 0
0- 0



 已为社区贡献1437条内容
已为社区贡献1437条内容

所有评论(0)