
又快、又小、又准的中文特色预训练模型—— PP-MiniLM 发布啦
PaddleNLP新发中文特色小模型PP-MiniLM,一文解读蒸馏、裁剪、量化级联模型压缩技术!
转载自AI Studio
标题项目链接https://aistudio.baidu.com/aistudio/projectdetail/3401596
又快、又小、又准的中文特色预训练模型—— PP-MiniLM 发布啦!
Transformer类预训练模型在NLP各项任务上取得的效果显著,但是其模型参数巨大,推断速度慢等特点限制了其广泛应用。直接使用现成的小模型,或者自行对预训练模型进行模型压缩,是当前工业界的常见做法。
近年来,涌现了很多小型化模型,如DistillBert、TinyBERT、ALBERT。
飞桨PaddleNLP 针对中文的特点,采用PaddleSlim 中蒸馏、剪裁、量化等级联模型压缩技术,发布又快、又小、又准的中文特色预训练模型—— PP-MiniLM(6L768H),保证模型精度的同时模型推理速度达 BERT(12L768H) 的 8.88 倍,参数量减少 52%,在中文语言理解评测基准 CLUE 上模型精度提升 0.62。在 CLUE 7 个分类任务上的模型精度超过 BERTbase、TinyBERT6、UER-py RoBERTa L6-H768、RBT6。
本教程会先对小模型 PP-MiniLM 进行简单介绍,然后介绍如何使用 PP-MiniLM 进行微调、裁剪、量化、预测部署。
PP-MiniLM
简介
PP-MiniLM 压缩方案以面向预训练模型的任务无关知识蒸馏(Task-agnostic Distillation)技术、裁剪(Pruning)技术、量化(Quantization)技术为核心,使得 PP-MiniLM 又快、又小、又准。
-
推理速度快: 依托 PaddleSlim 的裁剪、量化技术对 PP-MiniLM 小模型进行压缩、加速, 使得 PP-MiniLM 量化后模型 GPU 推理速度相比 BERT base 加速比高达 8.88;
-
精度高: 我们以 MiniLMv2 提出的 Multi-Head Self-Attention Relation Distillation 技术为基础,通过引入样本间关系知识蒸馏做了进一步算法优化,6 层 PP-MiniLM 模型在 CLUE 数据集上比 12 层
bert-base-chinese还高 0.62%,比同等规模的 TinyBERT6、UER-py RoBERTa 分别高 2.57%、2.24%; -
参数规模小:依托 Task-agnostic Distillation 技术和 PaddleSlim 裁剪技术,模型参数量相比 BERT 减少 52%。
PP-MiniLM 是使用任务无关蒸馏方法,以 roberta-wwm-ext-large 做教师模型蒸馏产出的含 6 层 Transformer Encoder Layer、Hidden Size 为 768 的预训练小模型,在 CLUE 上 7 个分类任务上的模型精度超过 BERTbase、TinyBERT6、UER-py RoBERTa L6-H768、RBT6。
NOTE: 如果对 PP-MiniLM 的训练过程感兴趣,可以查看 任务无关蒸馏文档 了解相关细节。
整体效果
| Model | #Params | #FLOPs | Speedup | AFQMC | TNEWS | IFLYTEK | CMNLI | OCNLI | CLUEWSC2020 | CSL | Avg |
|---|---|---|---|---|---|---|---|---|---|---|---|
| BERT-base, Chinese | 102.3M | 10.87B | 1.00x | 74.14 | 56.81 | 61.10 | 81.19 | 74.85 | 79.93 | 81.47 | 72.78 |
| TinyBERT6, Chinese | 59.7M | 5.44B | 2.04x | 72.59 | 55.70 | 57.64 | 79.57 | 73.97 | 76.32 | 80.00 | 70.83 |
| UER-py RoBERTa L6-H768 | 59.7M | 5.44B | 2.04x | 69.62 | 66.45 | 59.91 | 76.89 | 71.36 | 71.05 | 82.87 | 71.16 |
| RBT6, Chinese | 59.7M | 5.44B | 2.04x | 73.93 | 56.63 | 59.79 | 79.28 | 73.12 | 77.30 | 80.80 | 71.55 |
| ERNIE-Tiny | 90.7M | 4.83B | 2.30x | 71.55 | 58.34 | 61.41 | 76.81 | 71.46 | 72.04 | 79.13 | 70.11 |
| PP-MiniLM 6L-768H | 59.7M | 5.44B | 2.12x | 74.14 | 57.43 | 61.75 | 81.01 | 76.17 | 86.18 | 79.17 | 73.69 |
| PP-MiniLM 裁剪后 | 49.1M | 4.08B | 2.60x | 73.91 | 57.44 | 61.64 | 81.10 | 75.59 | 85.86 | 78.53 | 73.44 |
| PP-MiniLM 裁剪 + 量化后 | 49.2M | - | 9.26x | 74.00 | 57.37 | 61.33 | 81.09 | 75.56 | 85.85 | 78.57 | 73.40 |
(右划可以看到更多)
NOTE:
1.上表所有模型的精度测试均是基于下方超参数范围进行的 Grid Search 超参寻优。在每个配置下训练时,每隔 100 个 steps 在验证集上评估一次,取验证集上最佳准确率作为当前超参数配置下的准确率;
- batch sizes: 16, 32, 64;
- learning rates: 3e-5, 5e-5, 1e-4
2.量化后比量化前模型参数量多了 0.1M 是因为保存了 scale 值;
3.性能测试的条件是:
硬件:NVIDIA Tesla T4 单卡;
软件:CUDA 11.1, cuDNN 8.1, TensorRT 7.2, PaddlePaddle 2.2.2;
实验配置:batch_size: 32, max_seq_len: 128;
其中,除上表最后一行 PP-MiniLM 裁剪 + 量化后的模型是对 INT8 模型进行预测,其余模型均基于 FP32 精度测试。
4.PP-MiniLM 模型接入了FasterTokenizer,FasterTokenizer 对模型的精度没有影响,但是会加快推理速度。
推荐用法
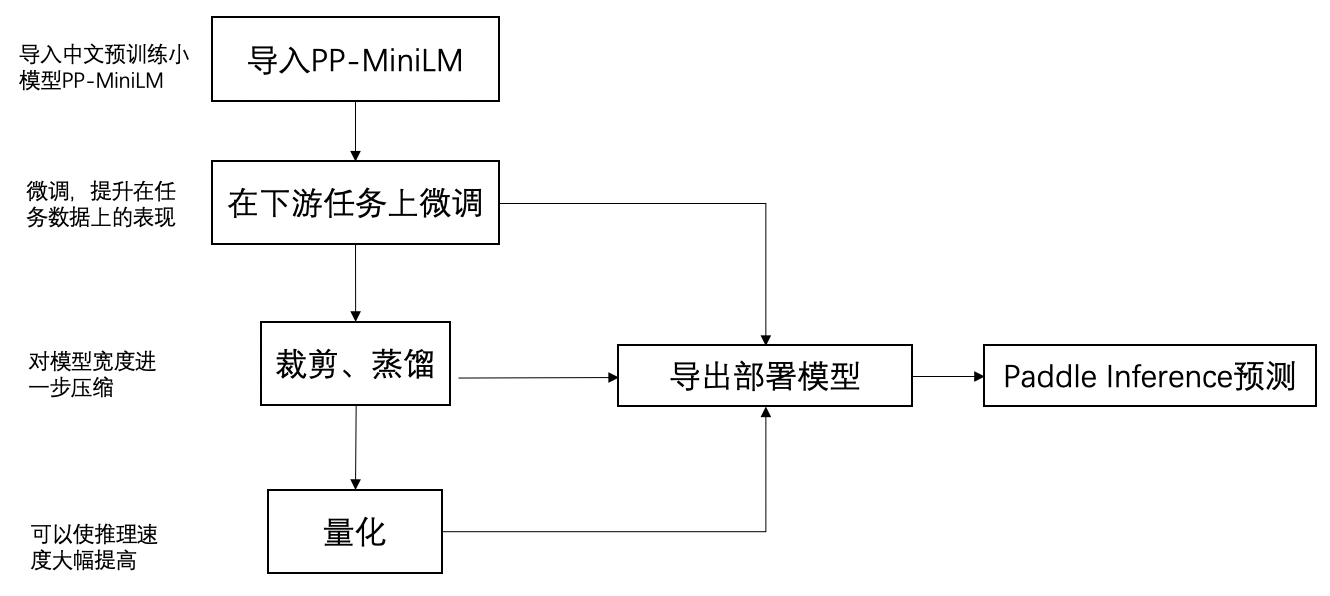
PP-MiniLM 使用流程图
-
PP-MiniLM 是一个 6 层的预训练模型,同其他预训练模型的使用方法一样,调用
from_pretrained()接口导入 PP-MiniLM 之后,就可以在下游任务中,使用自己的数据集上进行 fine-tuning。 -
如果希望进一步提升预测性能,可以通过裁剪、离线量化策略对微调好的模型继续压缩。完整的中文小模型方案为:导入 PP-MiniLM 中文预训练小模型、下游任务微调、裁剪、离线量化、预测部署五大步。下面会对这里的每一个步骤进行介绍。除了下游任务微调步骤,其余步骤均可以省略,如果追求极致的性能,我们建议保留下面的每一个步骤。
PP-MiniLM 压缩方案
为了展示如何对 PP-MiniLM 进行进一步压缩,接下来会以 CLUE 中的 CLUEWSC2020 数据集为例,分别进行微调、裁剪、量化、模型部署。
一、环境准备
- Python
Python的版本要求 3.6+
-
PaddlePaddle
PP-MiniLM 的压缩方案依赖于带有预测库的 PaddlePaddle 2.2.2 及以上版本,请参考 安装指南 进行安装
-
PaddleNLP
PP-MiniLM 依赖于 PaddleNLP 2.2.3 及之后的版本。可按如下命令进行安装:
pip install --upgrade paddlenlp -i https://pypi.org/simple
- PaddleSlim
压缩方案依赖 PaddleSlim 提供的裁剪、量化功能,因此需要安装 paddleslim。PaddleSlim 是个专注于深度学习模型压缩的工具库,提供剪裁、量化、蒸馏、和模型结构搜索等模型压缩策略,帮助用户快速实现模型的小型化。可按如下命令进行安装:
pip install --upgrade paddleslim -i https://pypi.org/simple
!pip install --upgrade paddlenlp -i https://pypi.org/simple
!pip install -U paddleslim -i https://pypi.org/simple
Requirement already satisfied: paddlenlp in /opt/conda/envs/python35-paddle120-env/lib/python3.7/site-packages (2.1.1)
Collecting paddlenlp
Downloading paddlenlp-2.2.4-py3-none-any.whl (1.1 MB)
|████████████████████████████████| 1.1 MB 7.6 kB/s
[?25hRequirement already satisfied: jieba in /opt/conda/envs/python35-paddle120-env/lib/python3.7/site-packages (from paddlenlp) (0.42.1)
Requirement already satisfied: colorama in /opt/conda/envs/python35-paddle120-env/lib/python3.7/site-packages (from paddlenlp) (0.4.4)
Requirement already satisfied: colorlog in /opt/conda/envs/python35-paddle120-env/lib/python3.7/site-packages (from paddlenlp) (4.1.0)
Requirement already satisfied: seqeval in /opt/conda/envs/python35-paddle120-env/lib/python3.7/site-packages (from paddlenlp) (1.2.2)
Requirement already satisfied: h5py in /opt/conda/envs/python35-paddle120-env/lib/python3.7/site-packages (from paddlenlp) (2.9.0)
Requirement already satisfied: multiprocess in /opt/conda/envs/python35-paddle120-env/lib/python3.7/site-packages (from paddlenlp) (0.70.11.1)
Requirement already satisfied: six in /opt/conda/envs/python35-paddle120-env/lib/python3.7/site-packages (from h5py->paddlenlp) (1.16.0)
Requirement already satisfied: numpy>=1.7 in /opt/conda/envs/python35-paddle120-env/lib/python3.7/site-packages (from h5py->paddlenlp) (1.19.5)
Requirement already satisfied: dill>=0.3.3 in /opt/conda/envs/python35-paddle120-env/lib/python3.7/site-packages (from multiprocess->paddlenlp) (0.3.3)
Requirement already satisfied: scikit-learn>=0.21.3 in /opt/conda/envs/python35-paddle120-env/lib/python3.7/site-packages (from seqeval->paddlenlp) (0.24.2)
Requirement already satisfied: joblib>=0.11 in /opt/conda/envs/python35-paddle120-env/lib/python3.7/site-packages (from scikit-learn>=0.21.3->seqeval->paddlenlp) (0.14.1)
Requirement already satisfied: scipy>=0.19.1 in /opt/conda/envs/python35-paddle120-env/lib/python3.7/site-packages (from scikit-learn>=0.21.3->seqeval->paddlenlp) (1.6.3)
Requirement already satisfied: threadpoolctl>=2.0.0 in /opt/conda/envs/python35-paddle120-env/lib/python3.7/site-packages (from scikit-learn>=0.21.3->seqeval->paddlenlp) (2.1.0)
Installing collected packages: paddlenlp
Attempting uninstall: paddlenlp
Found existing installation: paddlenlp 2.1.1
Uninstalling paddlenlp-2.1.1:
Successfully uninstalled paddlenlp-2.1.1
Successfully installed paddlenlp-2.2.4
Collecting paddleslim
Downloading paddleslim-2.2.2-py3-none-any.whl (311 kB)
|████████████████████████████████| 311 kB 19 kB/s
[?25hRequirement already satisfied: pillow in /opt/conda/envs/python35-paddle120-env/lib/python3.7/site-packages (from paddleslim) (8.2.0)
Requirement already satisfied: pyyaml in /opt/conda/envs/python35-paddle120-env/lib/python3.7/site-packages (from paddleslim) (5.1.2)
Requirement already satisfied: tqdm in /opt/conda/envs/python35-paddle120-env/lib/python3.7/site-packages (from paddleslim) (4.27.0)
Requirement already satisfied: pyzmq in /opt/conda/envs/python35-paddle120-env/lib/python3.7/site-packages (from paddleslim) (22.3.0)
Requirement already satisfied: opencv-python in /opt/conda/envs/python35-paddle120-env/lib/python3.7/site-packages (from paddleslim) (4.1.1.26)
Requirement already satisfied: matplotlib in /opt/conda/envs/python35-paddle120-env/lib/python3.7/site-packages (from paddleslim) (2.2.3)
Requirement already satisfied: numpy>=1.7.1 in /opt/conda/envs/python35-paddle120-env/lib/python3.7/site-packages (from matplotlib->paddleslim) (1.19.5)
Requirement already satisfied: cycler>=0.10 in /opt/conda/envs/python35-paddle120-env/lib/python3.7/site-packages (from matplotlib->paddleslim) (0.10.0)
Requirement already satisfied: pytz in /opt/conda/envs/python35-paddle120-env/lib/python3.7/site-packages (from matplotlib->paddleslim) (2019.3)
Requirement already satisfied: pyparsing!=2.0.4,!=2.1.2,!=2.1.6,>=2.0.1 in /opt/conda/envs/python35-paddle120-env/lib/python3.7/site-packages (from matplotlib->paddleslim) (3.0.7)
Requirement already satisfied: kiwisolver>=1.0.1 in /opt/conda/envs/python35-paddle120-env/lib/python3.7/site-packages (from matplotlib->paddleslim) (1.1.0)
Requirement already satisfied: six>=1.10 in /opt/conda/envs/python35-paddle120-env/lib/python3.7/site-packages (from matplotlib->paddleslim) (1.16.0)
Requirement already satisfied: python-dateutil>=2.1 in /opt/conda/envs/python35-paddle120-env/lib/python3.7/site-packages (from matplotlib->paddleslim) (2.8.2)
Requirement already satisfied: setuptools in /opt/conda/envs/python35-paddle120-env/lib/python3.7/site-packages (from kiwisolver>=1.0.1->matplotlib->paddleslim) (56.2.0)
Installing collected packages: paddleslim
Successfully installed paddleslim-2.2.2
环境准备好之后,接下来会介绍如何用下游任务数据在导入的 PP-MiniLM 上进行微调、进一步压缩及推理部署。
二、微调
PP-MiniLM 是一个 6 层的预训练模型,同其他预训练模型的使用方法一样,调用 from_pretrained() 接口导入 PP-MiniLM 模型之后,就可以在自己的数据集上进行 fine-tuning。
from paddlenlp.transformers import PPMiniLMModel, PPMiniLMForSequenceClassification
model = PPMiniLMModel.from_pretrained('ppminilm-6l-768h')
model = PPMiniLMForSequenceClassification.from_pretrained('ppminilm-6l-768h') # 用于分类任务
本教程已经提供了一个在 CLUEWSC2020 数据集上训好的模型了,它位于 './data/data124999/'。读者也可以参考 PaddleNLP 文档中的微调过程,在自己的数据上训练。
在下游任务上训练好模型之后,可以直接用于部署,可以利用 PaddleNLP 中提供的模型导出脚本导出对应的部署模型,然后使用 预测脚本 进行预测。但我们建议对模型进行进一步的裁剪、量化,这样可以得到一个推理速度更快的模型。
三、裁剪
PP-MiniLM 中的裁剪借鉴了 DynaBERT-Dynamic BERT with Adaptive Width and Depth 中宽度自适应裁剪的思想,其本质还是知识蒸馏。对知识蒸馏还不太了解的同学可以回看教程 『NLP打卡营』实践课12:预训练模型小型化与部署实战 进行学习。
DynaBERT 的思想是用原始网络作为教师模型,并用原始网络构建一个超网络(包含所有搜索空间在内的网络,其中原始网络是超网络中最大的子模型),每个 batch 训练开始前,要选择当前训练的子模型,让它作为学生模型。补充说明一下,多个子模型之间的参数是共享的。
其中,基于宽度的实验,搜索空间是由一个 width_mult_list 来定义的,例如 width_mult_list=[0.5, 0.75] 表示搜索空间包含2个宽度为原宽度 0.5、0.75 的子模型。标题中“自适应”指的是训练的过程中可以同时训练多个裁剪比例下的子模型,最终根据不同模型间的评估结果选择大小和精度最满足我们需求的模型。
在训练开始前,需要对 Head 和 FFN 中的神经元进行重要性排序,然后按照重要性分数对 Head 和 FFN 中的神经元参数进行重新排布。这样做的目的是让更重要的参数出现在更多的子网络中,避免被裁掉。在每次训练前,选择不同模型时,会按不同比例裁剪,如下图所示:
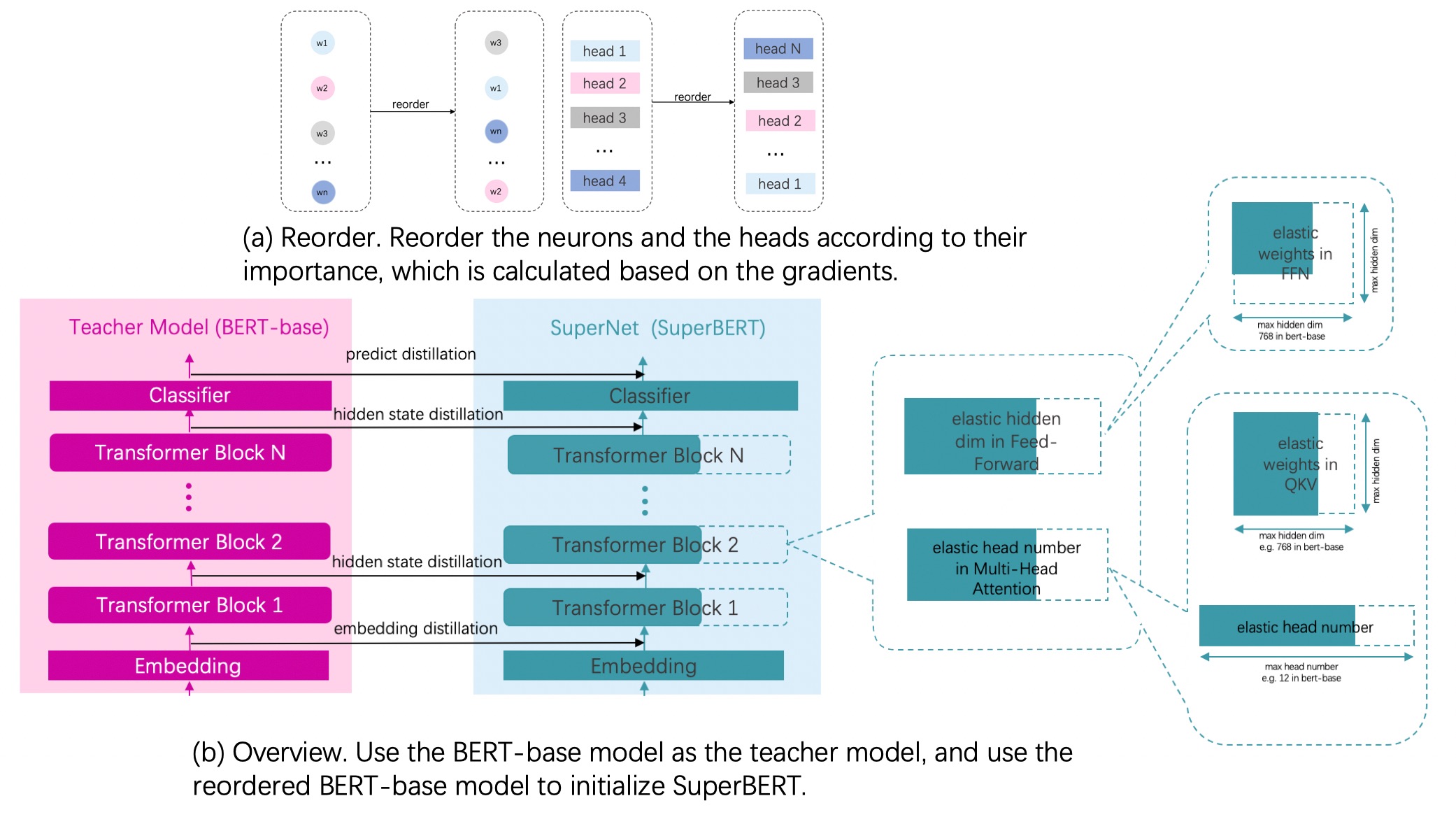
裁剪的基本原理就是这样,为了更清晰的展示裁剪的步骤,教程已把数据处理部分写在了文件 data.py 中,由于这部分数据处理和其他任务非常接近,这里就不再详细讲述了。fork 本项目后再启动项目就可以查看、编辑这部分代码了。
裁剪训练前数据准备
数据处理等部分都体现在本教程中的文件 data.py 中。下面的内容我们可以专注于裁剪过程。
paddle.set_device('gpu')
set_seed(2022)
task_name = 'cluewsc2020'
model_type = 'ppminilm'
model_name_or_path = './data/data124999/'
train_ds = load_dataset('clue', task_name, splits='train')
train_data_loader = ...
from data import *
/opt/conda/envs/python35-paddle120-env/lib/python3.7/site-packages/paddlenlp/transformers/funnel/modeling.py:30: DeprecationWarning: Using or importing the ABCs from 'collections' instead of from 'collections.abc' is deprecated, and in 3.8 it will stop working
from collections import Iterable
[01-28 15:17:47 MainThread @utils.py:79] WRN paddlepaddle version: 2.2.2. The dynamic graph version of PARL is under development, not fully tested and supported
100%|██████████| 275/275 [00:00<00:00, 5732.91it/s]
裁剪中的蒸馏配置
第一步:导入 PP-MiniLM 在任务上 fine-tuning 后的模型,这是我们原始的模型。同时,该模型也是教师模型。
from paddlenlp.transformers import PPMiniLMForSequenceClassification
# 用一个dict来保存原始PP-MiniLM的参数
model = PPMiniLMForSequenceClassification.from_pretrained(
model_name_or_path, num_classes=num_labels)
origin_weights = model.state_dict()
# 定义教师模型
teacher_model = PPMiniLMForSequenceClassification.from_pretrained(
model_name_or_path, num_classes=num_labels)
W0128 15:17:49.254159 236 device_context.cc:447] Please NOTE: device: 0, GPU Compute Capability: 7.0, Driver API Version: 10.1, Runtime API Version: 10.1
W0128 15:17:49.259351 236 device_context.cc:465] device: 0, cuDNN Version: 7.6.
[2022-01-28 15:17:55,106] [ INFO] - Loaded parameters from ./data/data124999/model_state.pdparams
[2022-01-28 15:17:56,419] [ INFO] - Loaded parameters from ./data/data124999/model_state.pdparams
第二步:将原始模型转化为超网络。
这里的超网络是指所有搜索空间在内的一个网络。并用刚才的原始网络的参数去初始化这个超网络参数。
from paddleslim.nas.ofa import utils
from paddleslim.nas.ofa.convert_super import Convert, supernet
sp_config = supernet(expand_ratio=[1.0])
model = Convert(sp_config).convert(model)
# 使用dict中保存的参数初始化超网络
utils.set_state_dict(model, origin_weights)
del origin_weights
super_sd = paddle.load(
os.path.join(model_name_or_path, 'model_state.pdparams'))
model.set_state_dict(super_sd)
第三步:配置蒸馏相关的参数
这里将蒸馏需要的配置,写进一个dict default_distill_config 里,并用这个 dict 初始化一个 paddleslim 的 DistillConfig 对象 distill_config
from paddleslim.nas.ofa import DistillConfig
mapping_layers = ['ppminilm.embeddings']
for idx in range(model.ppminilm.config['num_hidden_layers']):
mapping_layers.append('ppminilm.encoder.layers.{}'.format(idx))
default_distill_config = {
'lambda_distill': 0.1,
'teacher_model': teacher_model,
'mapping_layers': mapping_layers,
}
distill_config = DistillConfig(**default_distill_config)
第四步:进行超网络训练的配置
利用paddleslim提供的 OFA 接口用上面我们转化出的超网络 model 初始化一个 ofa_model。这个 ofa_model 就是我们之后蒸馏训练所需要的,同时,需要传入上面我们生成的 DistillConfig 实例 distill_config。由于我们是只对宽度进行裁剪和搜索,所以需要对 elastic_order 参数传入 ['width'] 即可。
ofa_model 里面其实包含了超网络和教师网络。例如,学生网络有参数 'model.ppminilm.embeddings.word_embeddings.fn.weight',对应着教师网络的参数 'ofa_teacher_model.model.ppminilm.embeddings.word_embeddings.weight'
from paddleslim.nas.ofa import OFA
ofa_model = OFA(model,
distill_config=distill_config,
elastic_order=['width'])
第五步:计算 Head 和 FFN 中神经元的重要性,并对参数的顺序进行重新排序。
在开始蒸馏训练前,还需要把 Head 和 FFN 中的神经元按照重要性进行重新排序,这样可以使更重要的神经元可以出现在更多的子模型中,并减少它们被裁掉的可能。
- 对于Head来说,我们是对 SelfAttention中的
q_proj、k_proj、v_proj、out_proj按照width_mult_list中指定的比例裁剪(这里是0.75)。下图是裁剪后导出图的可视化,可以看出q_proj.weight的 shape 已由(768, 768)变成了(768, 576)
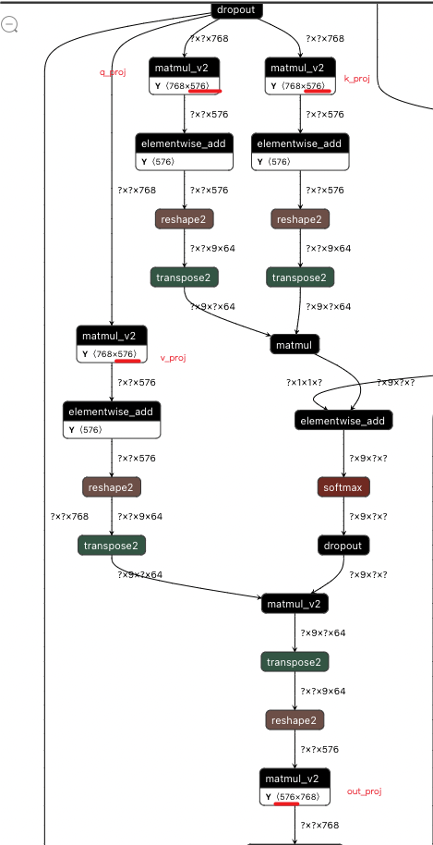
裁剪后的 HEAD 图
- 对于 FFN 的神经元来说,我们是对 EncoderLayer 中的
linear1和linear2进行等比例裁剪(比例是0.75)。下图是裁剪后导出图的可视化。

裁剪后的 FFN 图
在这里,我们使用 compute_neuron_head_importance API 计算神经元的重要性。并调用 reorder_neuron_head,将模型参数按照神经元重要性进行重新排列。
from paddleslim.nas.ofa.utils import nlp_utils
# 计算神经元的重要性
head_importance, neuron_importance = nlp_utils.compute_neuron_head_importance(
task_name,
ofa_model.model,
dev_data_loader,
loss_fct=paddle.nn.loss.CrossEntropyLoss(
) if train_ds.label_list else paddle.nn.loss.MSELoss(),
num_layers=model.ppminilm.config['num_hidden_layers'],
num_heads=model.ppminilm.config['num_attention_heads'])
# 重新组合参数的顺序
reorder_neuron_head(ofa_model.model, head_importance, neuron_importance)
第六步:定义蒸馏训练用到的优化器、评估器。蒸馏训练用到的优化器是 AdamW ,并使用 paddle.nn.ClipGradByGlobalNorm 进行梯度裁剪。评估器则是 'Accuracy'。
decay_params = [
p.name for n, p in model.named_parameters()
if not any(nd in n for nd in ["bias", "norm"])
]
# 定义优化器
optimizer = paddle.optimizer.AdamW(
learning_rate=lr_scheduler,
beta1=0.9,
beta2=0.999,
epsilon=adam_epsilon,
parameters=model.parameters(),
weight_decay=weight_decay,
apply_decay_param_fun=lambda x: x in decay_params,
grad_clip=nn.ClipGradByGlobalNorm(max_grad_norm))
# 定义评估器
metric = Accuracy()
裁剪训练
这一步会进行裁剪的训练,我们这里定义的搜索空间只有单个模型[0.75],经过裁剪训练后,可以在 CLUE 大部分分类数据集上保证精度无损。
可以发现裁剪的训练和普通的蒸馏过程几乎相同,ofa_model 包含了教师模型和当前子模型,调用 calc_distill_loss() 就可以计算出 学生模型和教师模型 EncoderLayer 输出之间的均方误差损失,并用学生模型和教师模型的 logits 计算交叉熵损失,两者通过 lambda_logit 来平衡权重。然后学生模型根据 loss 进行反向传播更新参数。如果width_mult_list有多个比例,那么每次只更新当前子模型所拥有的那部分参数,所有子模型的参数是共享的。
width_mult_list = [0.75]
lambda_logit = 1.0
logging_steps = 100
save_steps = 100
output_dir = './pruned_models/CLUEWSC2020/0.75/best_model'
global_step = 0
best_res = 0.0
num_train_epochs = 50
tic_train = time.time()
for epoch in range(num_train_epochs):
# 设置当前的epoch和task
ofa_model.set_epoch(epoch)
ofa_model.set_task('width')
for step, batch in enumerate(train_data_loader):
global_step += 1
input_ids, segment_ids, labels = batch
for width_mult in width_mult_list:
# 对每个width_mult进行遍历,并用当前width_mult在超网络里设置当前训练的子网络,并对当前的子网络进行训练
net_config = utils.dynabert_config(ofa_model, width_mult)
ofa_model.set_net_config(net_config)
# 对学生模型和教师模型同时计算前向
logits, teacher_logits = ofa_model(
input_ids, segment_ids, attention_mask=[None, None])
# 计算中间层的损失
rep_loss = ofa_model.calc_distill_loss()
# 用学生模型和教师模型的logits计算交叉熵损失
logit_loss = soft_cross_entropy(logits, teacher_logits.detach())
# 最终的loss是中间层损失 + logits带来的损失之和。
loss = rep_loss + lambda_logit * logit_loss
loss.backward()
optimizer.step()
lr_scheduler.step()
optimizer.clear_grad()
if global_step % logging_steps == 0:
logger.info(
"global step %d, epoch: %d, batch: %d, loss: %f, speed: %.2f step/s"
% (global_step, epoch, step, loss,
logging_steps / (time.time() - tic_train)))
tic_train = time.time()
if global_step % save_steps == 0 or global_step == num_training_steps:
tic_eval = time.time()
evaluate(teacher_model, metric, dev_data_loader, width_mult=100)
print("eval done total : %s s" % (time.time() - tic_eval))
# 对不同的宽度的子网络进行评估
for idx, width_mult in enumerate(width_mult_list):
net_config = utils.dynabert_config(ofa_model, width_mult)
ofa_model.set_net_config(net_config)
tic_eval = time.time()
res = evaluate(ofa_model, metric, dev_data_loader,
width_mult)
print("eval done total : %s s" % (time.time() - tic_eval))
if best_res < res:
output_dir = output_dir
if not os.path.exists(output_dir):
os.makedirs(output_dir)
model_to_save = model
model_to_save.save_pretrained(output_dir)
tokenizer.save_pretrained(output_dir)
best_res = res
if global_step >= num_training_steps:
break
if global_step >= num_training_steps:
break
print("best_res: ", best_res)
[2022-01-28 15:18:08,169] [ INFO] - global step 100, epoch: 1, batch: 21, loss: 0.105064, speed: 14.88 step/s
width_mult: 100, acc: 0.8486842105263158, eval done total : 0.5741927623748779 s
width_mult: 0.75, acc: 0.8157894736842105, eval done total : 0.7455508708953857 s
[2022-01-28 15:18:16,804] [ INFO] - global step 200, epoch: 2, batch: 43, loss: 0.305842, speed: 11.60 step/s
width_mult: 100, acc: 0.8486842105263158, eval done total : 0.43573880195617676 s
width_mult: 0.75, acc: 0.819078947368421, eval done total : 0.6900777816772461 s
[2022-01-28 15:18:25,356] [ INFO] - global step 300, epoch: 3, batch: 65, loss: 0.331153, speed: 11.71 step/s
width_mult: 100, acc: 0.8486842105263158, eval done total : 0.48416948318481445 s
width_mult: 0.75, acc: 0.8125, eval done total : 0.6980392932891846 s
[2022-01-28 15:18:33,080] [ INFO] - global step 400, epoch: 5, batch: 9, loss: 0.043065, speed: 12.96 step/s
width_mult: 100, acc: 0.8486842105263158, eval done total : 0.4365711212158203 s
width_mult: 0.75, acc: 0.8256578947368421, eval done total : 0.697986364364624 s
[2022-01-28 15:18:41,518] [ INFO] - global step 500, epoch: 6, batch: 31, loss: 0.037226, speed: 11.87 step/s
width_mult: 100, acc: 0.8486842105263158, eval done total : 0.4355888366699219 s
width_mult: 0.75, acc: 0.8125, eval done total : 0.6854457855224609 s
[2022-01-28 15:18:49,361] [ INFO] - global step 600, epoch: 7, batch: 53, loss: 0.040827, speed: 12.77 step/s
width_mult: 100, acc: 0.8486842105263158, eval done total : 0.4369015693664551 s
width_mult: 0.75, acc: 0.7763157894736842, eval done total : 0.7017619609832764 s
[2022-01-28 15:18:57,307] [ INFO] - global step 700, epoch: 8, batch: 75, loss: 0.037858, speed: 12.60 step/s
width_mult: 100, acc: 0.8486842105263158, eval done total : 0.44539570808410645 s
width_mult: 0.75, acc: 0.7993421052631579, eval done total : 0.7165935039520264 s
[2022-01-28 15:19:05,209] [ INFO] - global step 800, epoch: 10, batch: 19, loss: 0.034154, speed: 12.67 step/s
width_mult: 100, acc: 0.8486842105263158, eval done total : 0.443023681640625 s
width_mult: 0.75, acc: 0.7894736842105263, eval done total : 0.6999709606170654 s
[2022-01-28 15:19:13,000] [ INFO] - global step 900, epoch: 11, batch: 41, loss: 0.037347, speed: 12.85 step/s
width_mult: 100, acc: 0.8486842105263158, eval done total : 0.43897581100463867 s
width_mult: 0.75, acc: 0.7861842105263158, eval done total : 0.7127141952514648 s
[2022-01-28 15:19:20,796] [ INFO] - global step 1000, epoch: 12, batch: 63, loss: 0.031297, speed: 12.84 step/s
width_mult: 100, acc: 0.8486842105263158, eval done total : 0.44092798233032227 s
width_mult: 0.75, acc: 0.7960526315789473, eval done total : 0.697458028793335 s
[2022-01-28 15:19:28,672] [ INFO] - global step 1100, epoch: 14, batch: 7, loss: 0.034092, speed: 12.71 step/s
width_mult: 100, acc: 0.8486842105263158, eval done total : 0.4513673782348633 s
width_mult: 0.75, acc: 0.7993421052631579, eval done total : 0.7105143070220947 s
[2022-01-28 15:19:36,614] [ INFO] - global step 1200, epoch: 15, batch: 29, loss: 0.032366, speed: 12.61 step/s
width_mult: 100, acc: 0.8486842105263158, eval done total : 0.4504852294921875 s
width_mult: 0.75, acc: 0.8157894736842105, eval done total : 0.7143106460571289 s
[2022-01-28 15:19:44,787] [ INFO] - global step 1300, epoch: 16, batch: 51, loss: 0.031708, speed: 12.25 step/s
width_mult: 100, acc: 0.8486842105263158, eval done total : 0.4466538429260254 s
width_mult: 0.75, acc: 0.8223684210526315, eval done total : 0.7035527229309082 s
[2022-01-28 15:19:52,710] [ INFO] - global step 1400, epoch: 17, batch: 73, loss: 0.033588, speed: 12.64 step/s
width_mult: 100, acc: 0.8486842105263158, eval done total : 0.44365739822387695 s
width_mult: 0.75, acc: 0.805921052631579, eval done total : 0.773322582244873 s
[2022-01-28 15:20:01,197] [ INFO] - global step 1500, epoch: 19, batch: 17, loss: 0.031626, speed: 11.80 step/s
width_mult: 100, acc: 0.8486842105263158, eval done total : 0.45194482803344727 s
width_mult: 0.75, acc: 0.8157894736842105, eval done total : 0.7937252521514893 s
[2022-01-28 15:20:09,254] [ INFO] - global step 1600, epoch: 20, batch: 39, loss: 0.032826, speed: 12.43 step/s
width_mult: 100, acc: 0.8486842105263158, eval done total : 0.44441723823547363 s
width_mult: 0.75, acc: 0.7927631578947368, eval done total : 0.7097764015197754 s
[2022-01-28 15:20:17,078] [ INFO] - global step 1700, epoch: 21, batch: 61, loss: 0.029700, speed: 12.81 step/s
width_mult: 100, acc: 0.8486842105263158, eval done total : 0.4427919387817383 s
width_mult: 0.75, acc: 0.8092105263157895, eval done total : 0.7078409194946289 s
[2022-01-28 15:20:24,921] [ INFO] - global step 1800, epoch: 23, batch: 5, loss: 0.031197, speed: 12.77 step/s
width_mult: 100, acc: 0.8486842105263158, eval done total : 0.4403066635131836 s
width_mult: 0.75, acc: 0.805921052631579, eval done total : 0.7044663429260254 s
[2022-01-28 15:20:33,194] [ INFO] - global step 1900, epoch: 24, batch: 27, loss: 0.031075, speed: 12.11 step/s
width_mult: 100, acc: 0.8486842105263158, eval done total : 0.46996545791625977 s
width_mult: 0.75, acc: 0.8092105263157895, eval done total : 0.7440495491027832 s
[2022-01-28 15:20:41,574] [ INFO] - global step 2000, epoch: 25, batch: 49, loss: 0.030019, speed: 11.95 step/s
width_mult: 100, acc: 0.8486842105263158, eval done total : 0.4463233947753906 s
width_mult: 0.75, acc: 0.8157894736842105, eval done total : 0.7100734710693359 s
[2022-01-28 15:20:49,539] [ INFO] - global step 2100, epoch: 26, batch: 71, loss: 0.032354, speed: 12.57 step/s
width_mult: 100, acc: 0.8486842105263158, eval done total : 0.45970797538757324 s
width_mult: 0.75, acc: 0.805921052631579, eval done total : 0.7155802249908447 s
[2022-01-28 15:20:57,579] [ INFO] - global step 2200, epoch: 28, batch: 15, loss: 0.034274, speed: 12.45 step/s
width_mult: 100, acc: 0.8486842105263158, eval done total : 0.44640588760375977 s
width_mult: 0.75, acc: 0.8125, eval done total : 0.7163288593292236 s
[2022-01-28 15:21:05,496] [ INFO] - global step 2300, epoch: 29, batch: 37, loss: 0.032193, speed: 12.65 step/s
width_mult: 100, acc: 0.8486842105263158, eval done total : 0.44902658462524414 s
width_mult: 0.75, acc: 0.8125, eval done total : 0.7374258041381836 s
[2022-01-28 15:21:13,560] [ INFO] - global step 2400, epoch: 30, batch: 59, loss: 0.029288, speed: 12.41 step/s
width_mult: 100, acc: 0.8486842105263158, eval done total : 0.44863224029541016 s
width_mult: 0.75, acc: 0.8125, eval done total : 0.7201321125030518 s
[2022-01-28 15:21:21,654] [ INFO] - global step 2500, epoch: 32, batch: 3, loss: 0.029359, speed: 12.37 step/s
width_mult: 100, acc: 0.8486842105263158, eval done total : 0.44440150260925293 s
width_mult: 0.75, acc: 0.8092105263157895, eval done total : 0.7205178737640381 s
[2022-01-28 15:21:29,797] [ INFO] - global step 2600, epoch: 33, batch: 25, loss: 0.480859, speed: 12.30 step/s
width_mult: 100, acc: 0.8486842105263158, eval done total : 0.47400641441345215 s
width_mult: 0.75, acc: 0.8026315789473685, eval done total : 0.9264335632324219 s
[2022-01-28 15:21:38,327] [ INFO] - global step 2700, epoch: 34, batch: 47, loss: 0.030747, speed: 11.74 step/s
width_mult: 100, acc: 0.8486842105263158, eval done total : 0.48304057121276855 s
width_mult: 0.75, acc: 0.8289473684210527, eval done total : 0.7780828475952148 s
[2022-01-28 15:21:47,228] [ INFO] - global step 2800, epoch: 35, batch: 69, loss: 0.034642, speed: 11.25 step/s
width_mult: 100, acc: 0.8486842105263158, eval done total : 0.4455270767211914 s
width_mult: 0.75, acc: 0.8256578947368421, eval done total : 0.7098217010498047 s
[2022-01-28 15:21:55,208] [ INFO] - global step 2900, epoch: 37, batch: 13, loss: 0.032040, speed: 12.55 step/s
width_mult: 100, acc: 0.8486842105263158, eval done total : 0.4510841369628906 s
width_mult: 0.75, acc: 0.8223684210526315, eval done total : 0.7204141616821289 s
[2022-01-28 15:22:03,325] [ INFO] - global step 3000, epoch: 38, batch: 35, loss: 0.030037, speed: 12.34 step/s
width_mult: 100, acc: 0.8486842105263158, eval done total : 0.5255749225616455 s
width_mult: 0.75, acc: 0.8223684210526315, eval done total : 0.77712082862854 s
[2022-01-28 15:22:11,855] [ INFO] - global step 3100, epoch: 39, batch: 57, loss: 0.029965, speed: 11.74 step/s
width_mult: 100, acc: 0.8486842105263158, eval done total : 0.44854116439819336 s
width_mult: 0.75, acc: 0.8157894736842105, eval done total : 0.7175805568695068 s
[2022-01-28 15:22:20,477] [ INFO] - global step 3200, epoch: 41, batch: 1, loss: 0.028272, speed: 11.61 step/s
width_mult: 100, acc: 0.8486842105263158, eval done total : 0.4660167694091797 s
width_mult: 0.75, acc: 0.8157894736842105, eval done total : 0.7658946514129639 s
[2022-01-28 15:22:29,449] [ INFO] - global step 3300, epoch: 42, batch: 23, loss: 0.032405, speed: 11.15 step/s
width_mult: 100, acc: 0.8486842105263158, eval done total : 0.4678215980529785 s
width_mult: 0.75, acc: 0.819078947368421, eval done total : 0.7498805522918701 s
[2022-01-28 15:22:38,056] [ INFO] - global step 3400, epoch: 43, batch: 45, loss: 0.029382, speed: 11.64 step/s
width_mult: 100, acc: 0.8486842105263158, eval done total : 0.4404871463775635 s
width_mult: 0.75, acc: 0.8157894736842105, eval done total : 0.6975588798522949 s
[2022-01-28 15:22:46,052] [ INFO] - global step 3500, epoch: 44, batch: 67, loss: 0.029915, speed: 12.52 step/s
width_mult: 100, acc: 0.8486842105263158, eval done total : 0.4386465549468994 s
width_mult: 0.75, acc: 0.8223684210526315, eval done total : 0.6895158290863037 s
[2022-01-28 15:22:53,911] [ INFO] - global step 3600, epoch: 46, batch: 11, loss: 0.030097, speed: 12.75 step/s
width_mult: 100, acc: 0.8486842105263158, eval done total : 0.43879246711730957 s
width_mult: 0.75, acc: 0.8223684210526315, eval done total : 0.6866724491119385 s
[2022-01-28 15:23:01,544] [ INFO] - global step 3700, epoch: 47, batch: 33, loss: 0.027487, speed: 13.12 step/s
width_mult: 100, acc: 0.8486842105263158, eval done total : 0.4383969306945801 s
width_mult: 0.75, acc: 0.819078947368421, eval done total : 0.6880450248718262 s
[2022-01-28 15:23:09,187] [ INFO] - global step 3800, epoch: 48, batch: 55, loss: 0.031854, speed: 13.11 step/s
width_mult: 100, acc: 0.8486842105263158, eval done total : 0.4406898021697998 s
width_mult: 0.75, acc: 0.8157894736842105, eval done total : 0.6892104148864746 s
[2022-01-28 15:23:16,862] [ INFO] - global step 3900, epoch: 49, batch: 77, loss: 0.029160, speed: 13.03 step/s
width_mult: 100, acc: 0.8486842105263158, eval done total : 0.44138550758361816 s
width_mult: 0.75, acc: 0.8223684210526315, eval done total : 0.7905969619750977 s
best_res: 0.8289473684210527
导出裁剪模型
裁剪模型完成训练后,我们需要把之前保存下来的最好的模型 load 进来,并将其导出静态图模型。对于模型的导出,我们使用的是 ofa_model 中的export方法实现。主要参数介绍如下:
origin_model: 原始模型的实例。config:所要导出子模型的配置。可以通过OFA.get_current_config()或其他特殊配置得到,例如paddleslim.nas.ofa.utils.dynabert_config(width_mult)。input_shapes:所有输入的 shape。input_dtypes:所有输入的 dtype。load_weights_from_supernet:是否从超网络中导入参数,默认: False。
import paddle.fluid.core as core
width_mult = 0.75
static_sub_model='pruning/pruned_models/CLUEWSC2020/0.75/sub_static/float'
sub_model_output_dir='pruning/pruned_models/CLUEWSC2020/0.75/sub'
# 对ofa_model的属性进行设置,使其可以直接导出部署模型
ofa_model = enable_ofa_export(ofa_model)
sd = paddle.load(os.path.join(output_dir, "model_state.pdparams"))
origin_model = PPMiniLMForSequenceClassification.from_pretrained(output_dir)
ofa_model.model.set_state_dict(sd)
best_config = utils.dynabert_config(ofa_model, width_mult)
# 调用ofa的 export接口进行模型导出
origin_model_new = ofa_model.export(
best_config,
input_shapes=[1],
input_dtypes=core.VarDesc.VarType.STRINGS,
origin_model=origin_model)
for name, sublayer in origin_model_new.named_sublayers():
if isinstance(sublayer, paddle.nn.MultiHeadAttention):
sublayer.num_heads = int(width_mult * sublayer.num_heads)
origin_model_new.to_static(static_sub_model)
[2022-01-28 15:23:19,764] [ INFO] - Loaded parameters from ./pruned_models/CLUEWSC2020/0.75/best_model/model_state.pdparams
2022-01-28 15:23:20,090-INFO: Start to get pruned params, please wait...
2022-01-28 15:23:20,539-INFO: Start to get pruned model, please wait...
[2022-01-28 15:23:24,986] [ INFO] - Already save the static model to the path pruning/pruned_models/CLUEWSC2020/0.75/sub_static/float
四、量化
量化简介
量化的目的:用 INT8 代替 Float32 存储,减少模型体积,减少模型的存储空间,降低内存带宽的需求,加快推理速度。
PaddleSlim 中的量化采用的是线性映射的方式,如下面两张图:
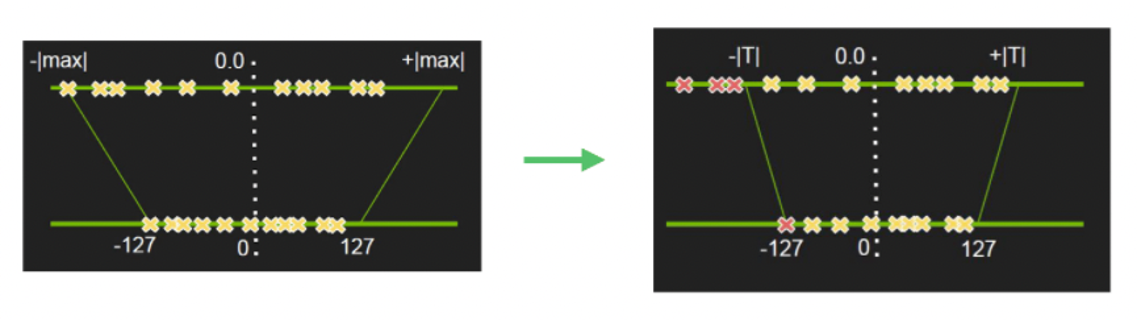
量化
如左图,假设 |max| = 5,那么 scale = 127 / 5 = 25.4,那么 float 值 3.0 将会映射至 int(25.4 * 3) = int(76.2) = 76。因此,我们可以看出,量化的核心是计算出量化比例因子 scale。
PP-MiniLM中的训练后量化方法
PP-MiniLM 这里的量化采用的是训练后量化方法(静态离线量化方法),即不需要训练,只使用少量校准数据计算量化因子,就可快速得到量化模型。一般采用绝对值最大值、均方误差loss、基于KL散度loss等方法计算量化比例因子 Scale。在 PaddleSlim 中,一般使用 mse、avg、abs_max、hist 等方法对于激活 Tensor 进行量化,以及 channel_wise_abs_max 对权重 Tensor 进行量化。
这一步需要有训练好的预测(静态图)模型。上一步我们已经导出了静态图模型。
训练后量化我们可以直接使用 PaddleSlim 提供的离线量化 API paddleslim.quant.quant_post_static 实现,,并使用 4、8 两种校准集数量,对 matmul、matmul_v2 算子进行量化。
下面,对于 quant_post_static API 中的参数进行简单的介绍。其中 batch_size 是由 data_loader 体现。
quantizable_op_type: 待量化的 op 类型,对于 PP-MiniLM、BERT、ERNIE等模型,传入['matmul', 'matmul_v2']即可,默认值是['conv2d', 'depthwise_conv2d', 'mul'].weight_quantize_type: 权重 Tensor 的量化方法,有'abs_max'和'channel_wise_abs_max'两种,一般来说后者效果更好,默认值:'channel_wise_abs_max'。algo:获取 scale 的方法,可以是'hist'、'mse'、'abs_max'、'KL'等weight_bits:量化的比特数,这里是 8 bit 的量化data_loader:产生校准数据的paddle.io.DataLoader对象或者是一个Python Generator。hist_percent:使用'hist'方法时,直方图的百分率,统计数量达到0.9999 * 总数时的直方图的平均值作为阈值。默认值:0.9999.batch_nums:如果不为None,校准数据的个数是batch_size * batch_nums;如果是None,使用Generator产生的所有的数据作为校准数据。
import paddleslim
algo = 'hist'
input_dir = os.path.dirname(static_sub_model)
quantize_model_path = os.path.join(task_name + '_quant_models', algo, "int8")
save_model_filename = 'int8.pdmodel'
save_params_filename = 'int8.pdiparams'
input_model_filename = 'float.pdmodel'
input_param_filename = 'float.pdiparams'
# 需要在静态图下完成,由动态图模式切换成静态图模式
paddle.enable_static()
place = paddle.set_device("gpu")
exe = paddle.static.Executor(place)
# 调用接口直接一步实现离线量化
paddleslim.quant.quant_post_static(
exe,
input_dir,
quantize_model_path,
save_model_filename=save_model_filename,
save_params_filename=save_params_filename,
algo=algo,
hist_percent=0.9999,
data_loader=batch_generator,
model_filename=input_model_filename,
params_filename=input_param_filename,
quantizable_op_type=['matmul', 'matmul_v2'],
weight_bits=8,
weight_quantize_type='channel_wise_abs_max',
batch_nums=1, )
algo = 'hist'
input_dir = os.path.dirname(static_sub_model)
quantize_model_path = os.path.join(task_name + '_quant_models', algo)
save_model_filename = 'int8.pdmodel'
save_params_filename = 'int8.pdiparams'
input_model_filename = 'float.pdmodel'
input_param_filename = 'float.pdiparams'
# 需要在静态图下完成,由动态图模式切换成静态图模式
paddle.enable_static()
place = paddle.set_device("gpu")
exe = paddle.static.Executor(place)
# 调用接口直接一步实现离线量化
paddleslim.quant.quant_post_static(
exe,
input_dir,
quantize_model_path,
save_model_filename=save_model_filename,
save_params_filename=save_params_filename,
algo=algo,
hist_percent=0.9999,
data_loader=batch_generator,
model_filename=input_model_filename,
params_filename=input_param_filename,
quantizable_op_type=['matmul', 'matmul_v2'],
weight_bits=8,
weight_quantize_type='channel_wise_abs_max',
batch_nums=1, )
Fri Jan 28 15:23:24-INFO: Load model and set data loader ...
Fri Jan 28 15:23:25-INFO: Collect quantized variable names ...
Fri Jan 28 15:23:25-INFO: Preparation stage ...
Fri Jan 28 15:23:25-INFO: Run batch: 0
Fri Jan 28 15:23:25-INFO: Finish preparation stage, all batch:1
Fri Jan 28 15:23:25-INFO: Sampling stage ...
Fri Jan 28 15:23:28-INFO: Run batch: 0
Fri Jan 28 15:23:28-INFO: Finish sampling stage, all batch: 1
Fri Jan 28 15:23:28-INFO: Calculate hist threshold ...
Fri Jan 28 15:23:29-INFO: Update the program ...
Fri Jan 28 15:23:33-INFO: The quantized model is saved in cluewsc2020_quant_models/hist/int8
Fri Jan 28 15:23:33-INFO: Load model and set data loader ...
Fri Jan 28 15:23:33-INFO: Collect quantized variable names ...
Fri Jan 28 15:23:33-INFO: Preparation stage ...
Fri Jan 28 15:23:33-INFO: Run batch: 0
Fri Jan 28 15:23:33-INFO: Finish preparation stage, all batch:1
Fri Jan 28 15:23:33-INFO: Sampling stage ...
Fri Jan 28 15:23:36-INFO: Run batch: 0
Fri Jan 28 15:23:36-INFO: Finish sampling stage, all batch: 1
Fri Jan 28 15:23:36-INFO: Calculate hist threshold ...
Fri Jan 28 15:23:37-INFO: Update the program ...
Fri Jan 28 15:23:41-INFO: The quantized model is saved in cluewsc2020_quant_models/hist
五、预测
预测部署借助 PaddlePaddle 安装包中自带的 Paddle Inference 进行预测。
想要得到更明显的加速效果,推荐在 NVIDA Tensor Core GPU(如 T4、A10、A100)上进行测试。若在 V 系列 GPU 卡上测试,由于其不支持 Int8 Tensor Core,加速效果将达不到本教程最上方表格中的效果。
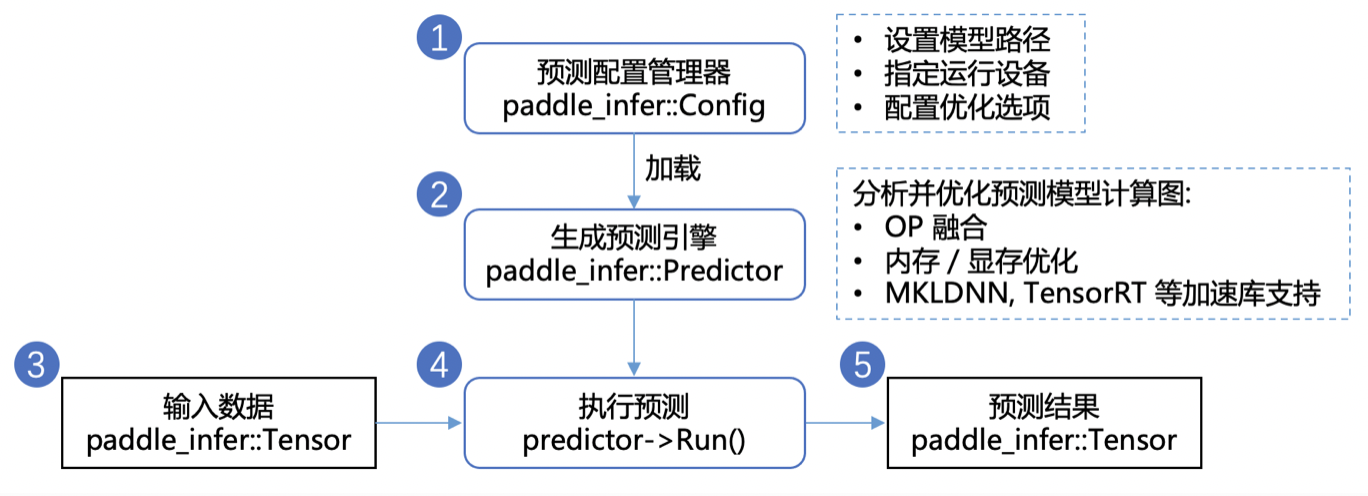
经过上一步的量化后,我们获得了静态图模型,就可以使用 Paddle Inference 进行预测部署啦。Paddle Inference 是飞桨的原生推理库,作用于服务器端和云端,提供高性能的推理能力。
Paddle Inference 采用 Predictor 进行预测。Predictor 是一个高性能预测引擎,该引擎通过对计算图的分析,
完成对计算图的一系列的优化(如OP的融合、内存/显存的优化、 MKLDNN,TensorRT 等底层加速库的支持等),
能够大大提升预测性能。另外 Paddle Inference 提供了 Python、C++、GO 等多语言的API,可以根据实际环境需要进行选择,为了得到更高速的推理性能,建议安装使用带有TensorRT的预测库进行预测。受限于本教程环境中的 Paddle 版本,这里仅演示不带 TensorRT 预测库的预测,大家可以在Paddle Inference 中下载和自己环境匹配的预测库,参考项目中源代码进行 TensorRT 预测:
使用 Paddle Inference 开发 Python 预测程序仅需以下步骤:
from paddle import inference
use_trt = True
collect_shape = True
batch_size = 32
# 1. 创建配置对象,设置预测模型路径
config = inference.Config(os.path.join(quantize_model_path, save_model_filename), os.path.join(quantize_model_path, save_params_filename))
# 启用 GPU 进行预测 - 初始化 GPU 显存 100M, Deivce_ID 为 0
config.enable_use_gpu(100, 0)
# 2. 根据配置内容创建推理引擎
predictor = inference.create_predictor(config)
# 3. 设置输入数据
# 获取输入句柄
input_handles = [
predictor.get_input_handle(name)
for name in predictor.get_input_names()
]
# 获取输入数据
dev_ds = load_dataset("clue", task_name, splits="dev")
trans_func = partial(
convert_example, label_list=dev_ds.label_list, is_test=False)
dev_ds = dev_ds.map(trans_func, lazy=True)
data = [[dev_ds[0]['sentence']]]
# 设置输入数据
for input_field, input_handle in zip(data, input_handles):
print(input_field)
input_handle.copy_from_cpu(input_field)
# 4. 执行预测
predictor.run()
# 5. 获取预测结果
# 获取输出句柄
output_handles = [
predictor.get_output_handle(name)
for name in predictor.get_output_names()
]
# 从输出句柄获取预测结果
output = [output_handle.copy_to_cpu() for output_handle in output_handles]
print(output)
W0128 15:23:41.411352 236 analysis_predictor.cc:795] The one-time configuration of analysis predictor failed, which may be due to native predictor called first and its configurations taken effect.
[1m[35m--- Running analysis [ir_graph_build_pass][0m
[1m[35m--- Running analysis [ir_graph_clean_pass][0m
[1m[35m--- Running analysis [ir_analysis_pass][0m
[32m--- Running IR pass [is_test_pass][0m
[32m--- Running IR pass [simplify_with_basic_ops_pass][0m
[32m--- Running IR pass [conv_affine_channel_fuse_pass][0m
[32m--- Running IR pass [conv_eltwiseadd_affine_channel_fuse_pass][0m
[32m--- Running IR pass [conv_bn_fuse_pass][0m
[32m--- Running IR pass [conv_eltwiseadd_bn_fuse_pass][0m
[32m--- Running IR pass [embedding_eltwise_layernorm_fuse_pass][0m
I0128 15:23:41.686870 236 fuse_pass_base.cc:57] --- detected 1 subgraphs
[32m--- Running IR pass [multihead_matmul_fuse_pass_v2][0m
[32m--- Running IR pass [squeeze2_matmul_fuse_pass][0m
[32m--- Running IR pass [reshape2_matmul_fuse_pass][0m
[32m--- Running IR pass [flatten2_matmul_fuse_pass][0m
[32m--- Running IR pass [map_matmul_v2_to_mul_pass][0m
I0128 15:23:41.696921 236 fuse_pass_base.cc:57] --- detected 38 subgraphs
[32m--- Running IR pass [map_matmul_v2_to_matmul_pass][0m
I0128 15:23:41.698750 236 fuse_pass_base.cc:57] --- detected 6 subgraphs
[32m--- Running IR pass [map_matmul_to_mul_pass][0m
[32m--- Running IR pass [fc_fuse_pass][0m
[32m--- Running IR pass [fc_elementwise_layernorm_fuse_pass][0m
[32m--- Running IR pass [conv_elementwise_add_act_fuse_pass][0m
[32m--- Running IR pass [conv_elementwise_add2_act_fuse_pass][0m
[32m--- Running IR pass [conv_elementwise_add_fuse_pass][0m
[32m--- Running IR pass [transpose_flatten_concat_fuse_pass][0m
[32m--- Running IR pass [runtime_context_cache_pass][0m
[1m[35m--- Running analysis [ir_params_sync_among_devices_pass][0m
I0128 15:23:41.722019 236 ir_params_sync_among_devices_pass.cc:45] Sync params from CPU to GPU
[1m[35m--- Running analysis [adjust_cudnn_workspace_size_pass][0m
[1m[35m--- Running analysis [inference_op_replace_pass][0m
[1m[35m--- Running analysis [ir_graph_to_program_pass][0m
I0128 15:23:42.005632 236 analysis_predictor.cc:714] ======= optimize end =======
I0128 15:23:42.015040 236 naive_executor.cc:98] --- skip [feed], feed -> text
I0128 15:23:42.019754 236 naive_executor.cc:98] --- skip [linear_151.tmp_1], fetch -> fetch
['有些这样的“_洋人_”就站在大众之间,如同鹤立鸡群,毫不掩饰自己的优越感。[他们]排在非凡的甲菜盆后面,虽然人数寥寥无几,但却特别惹眼。']
[array([[ 3.7948644, -4.1197 ]], dtype=float32)]
本项目源代码全部开源在 PaddleNLP 中。
如果对您有帮助,欢迎⭐️ star⭐️收藏一下,不易走丢哦! 链接指路:https://github.com/PaddlePaddle/PaddleNLP

加入 Wechat 交流群,一起学习吧
添加小助手微信,回复“NLP”,即刻加入PaddleNLP的技术交流群,一起交流NLP技术吧!


学大模型,用大模型上飞桨星河社区!每天8点V100G算力免费领!免费领取ERNIE 4.0 100w Token >>>
更多推荐



 0
0 0
0- 0



 已为社区贡献1437条内容
已为社区贡献1437条内容

所有评论(0)