
基于PaddleClas的浮世绘人脸多属性分类实践
本项目对该数据集的人脸多属性分类任务进行了探索,基于PaddleClas建立了一个基线模型,感兴趣的同学可以基于此项目进行深入研究。对于该数据集的研究,下一步计划探索GAN网络在该数据集上的表现。...
1、项目意义
随着深度学习算法的发展,其应用领域也越来越宽广,对于历史人文领域来说借助机器学习的自动化能力对浩如烟海的史料进行分析和理解具有十分重要的意义。社会文化领域的数据集可以有效驱动历史、艺术、社会、人类学等方面的发展。
为此,来自谷歌大脑、日本人文科学开放数据研究中心、剑桥大学和蒙特利尔大学的研究人员们收集了名为KaoKore的日本近代艺术作品中人脸表情数据集,并构建了基于数据集的分类和生成艺术模型,为艺术、艺术史和社会人类学等研究领域提出了新的研究思路。
在这项工作中,研究人员提出的数据集 KaoKore 包含从前现代日本艺术品中提取的面部数据。针对原始数据,研究人员首先将图像的元数据标签重新组织成了工业标准的格式,使其与现有的机器学习模型更容易集成。由于Collection of Facial Expressions中的图像尺寸大小不一,研究人员还对图像的尺寸进行了归一化,最终得到了5552张尺寸为256x256的RGB数据,涵盖了不同艺术风格和属性的人脸,其格式也与ImageNet一致,便于现有的模型对其进行研究。
此外为了便于监督学习的研究,数据还选择了人物性别(男/女)和社会阶层(贵族/武士/化身/庶民)来作为标签,充分考虑了数据均衡的问题。
数据集整体信息与预览如下图所示,
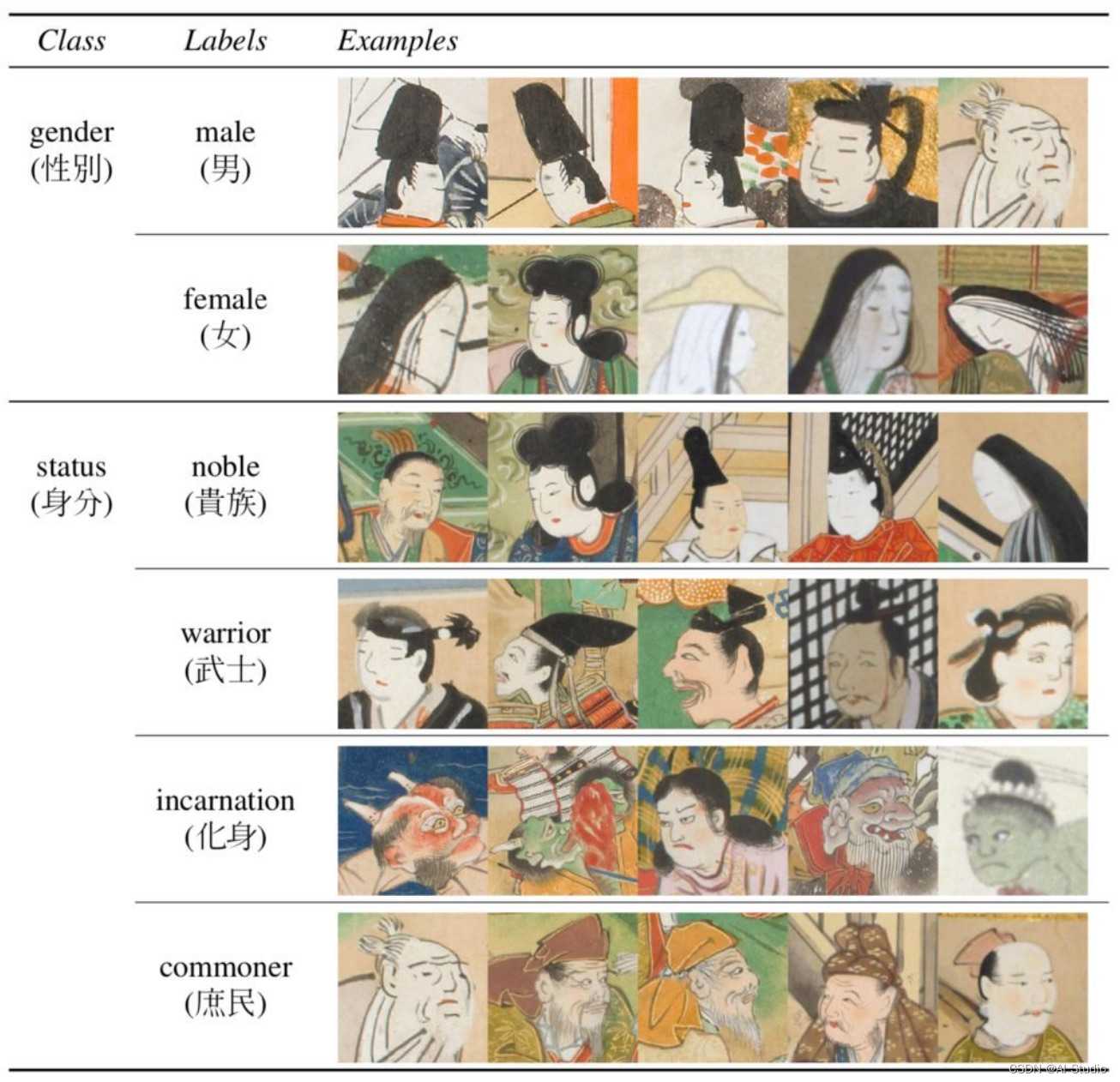
在论文:KaoKore: A Pre-modern Japanese Art Facial Expression Dataset中,研究人员展示了它作为图像分类数据集以及创意和艺术数据集的价值。在论文中,研究人员分你别针对人脸属性分类、图像生成进行了研究,结果展示如下:


2、数据概览
- 注意
使用opencv读取需要转换一下图像通道,不然显示出来的图片颜色通道是不正确的。
!cd data/data159438 && unzip -q kaokore.zip
%matplotlib inline
# 导入相关包
import os
import cv2
import random
from tqdm import tqdm
import numpy as np
import seaborn as sns
import matplotlib.pyplot as plt
TRAIN = '/home/aistudio/data/data159438/kaokore/images_256'
train = os.listdir(TRAIN)
f, axs = plt.subplots(4,5, figsize=(16,8))
for i in range(4):
for j in range(5):
img = cv2.imread(os.path.join(TRAIN, train[random.randint(0,len(train)-1)]), cv2.COLOR_RGB2BGR)
image = img[:, :, ::-1]
axs[i][j].imshow(image);

3、数据集预处理
此处需要将数据格式处理为PaddleClas需要的格式,并将训练文件放在
import pandas as pd
df = pd.read_csv('data/data159438/kaokore/labels.csv')
df1 = df['gender'].values
df2 = df['status'].values
df3 = df['image'].values
name_list1 = {0:"male", 1:'female'}
name_list2 = {0:"noble", 1:'warrior', 2:'incarnation', 3:'commoner'}
label = list()
for l1,l2 in zip(df1,df2):
label1 = name_list1[l1]
# print(label1)
label2 = name_list2[l2]
# print(label2)
label.append((label1, label2))
from sklearn.preprocessing import MultiLabelBinarizer
import numpy as np
mlb = MultiLabelBinarizer()
multilabel_index = mlb.fit_transform(label)
np.savetxt('test.txt', multilabel_index, fmt='%d', delimiter=',')
mlb.classes_
array(['commoner', 'female', 'incarnation', 'male', 'noble', 'warrior'],
dtype=object)
file2 = open("test.txt",'r',encoding='utf-8-sig')
lines = file2.readlines()
with open('train11.txt',"w",encoding='utf-8') as file1:
for img,line in zip(df3, lines):
file1.write(img+'\t'+line)#把listall列表中的信息保存到目标txt文件中
file1.close()
!head train11.txt
00002311.jpg 0,1,0,0,1,0
00005529.jpg 0,0,1,1,0,0
00002282.jpg 0,0,1,1,0,0
00004413.jpg 1,1,0,0,0,0
00003214.jpg 0,1,0,0,1,0
00005236.jpg 0,0,0,1,0,1
00002261.jpg 0,0,0,1,0,1
00003753.jpg 1,1,0,0,0,0
00004353.jpg 1,0,0,1,0,0
00004730.jpg 0,0,0,1,0,1
4、模型训练
此处为了方便大家快速上手此项目,已经对项目中需要使用的配置文件进行修改,大家直接运行下面的代码即可。
class_num: 6
train
image_root: /home/aistudio/kaokore-master/kaokore/images_256/
cls_label_path: /home/aistudio/train1.txt
eval
image_root: /home/aistudio/kaokore-master/kaokore/images_256/
cls_label_path: /home/aistudio/train1.txt
!cd PaddleClas && bash train.sh
6、预测结果展示
预测结果:{‘class_ids’: [2, 3], ‘scores’: [0.94357, 0.97514], ‘file_name’: ‘/home/aistudio/data/data159438/kaokore/images_256/00000010.jpg’,
即:‘incarnation’, ‘male’,

!cd PaddleClas && bash infer.sh
7、总结
本项目对该数据集的人脸多属性分类任务进行了探索,基于PaddleClas建立了一个基线模型,感兴趣的同学可以基于此项目进行深入研究。对于该数据集的研究,下一步计划探索GAN网络在该数据集上的表现。
转载自:https://aistudio.baidu.com/aistudio/projectdetail/4413857?forkThirdPart=1

学大模型,用大模型上飞桨星河社区!每天8点V100G算力免费领!免费领取ERNIE 4.0 100w Token >>>
更多推荐



 0
0 0
0- 0



 已为社区贡献1437条内容
已为社区贡献1437条内容

所有评论(0)