
金融图表OCR检测与文本识别
债券文本文档类型丰富,汉字结构复杂识别难度较大,债券文本识别现在正在发展期。借助信息化手段,提高债券文本文档信息处理能力、处理效率、准确率,实现债券文本文档自动识别是解决问题的好方法。
演示视频戳这里(或文件)
ChartOCR.exe戳这里下载
背景介绍
项目背景
日常生活中,个人或企事业单位的各种经济活动都可能会产生大量的债券文本文档,随着信息化不断发展,各行各业都在将传统的纸质文件电子化保存。传统的方式是人工手动录入税务票据进入计算机系统,面对急剧增长的债券文档,错误率高、时效性差的手动操作已和高速发展,信息化的当前社会不相协同。因此借助信息化手段,提高债券文本文档信息处理能力、处理效率、准确率,实现债券文本文档自动识别是解决问题的好方法。·
表格识别可以分为两种,一是文档转的图片,横平竖直、字迹清晰。二是直接生成的图片,比如照片、扫描件,表格可能根本就是斜的,模模糊糊,甚至还有别的页的痕迹。对于第一种,常见的工具都可以试试,如abbyy finereader、百度API等,识别效果和图片的分辨率有关系;对于第二种情况,需要基于深度学习的框架,针对专门的环境调参,达到比较好的效果。
债券文本文档类型丰富,汉字结构复杂识别难度较大,因此相对来讲,债券文本识别现在正在发展期。目前做的较好的公式为:薪火科技,在人脸识别、多票据/发票识别、表格OCR识别等一方面推出了商业化产品,同时也推出了API服务接口。
市场现状
现在市场上有很多OCR文本识别软件与在线API,例如OCRMaker,天若OCR,薪火科技在线OCR等。近现代OCR技术起步较晚,对于中文和表格的识别技能尚不成熟,在国内有很大的市场。现在的OCR接口大多都是线上API,用户需要导入需要检测的图片,后续由服务器端经过计算输出结果。本项目试图将项目打包成离线可运行版本,将项目封装成一个安装包,用户不用安装环境,下载即可运行。
创作思路
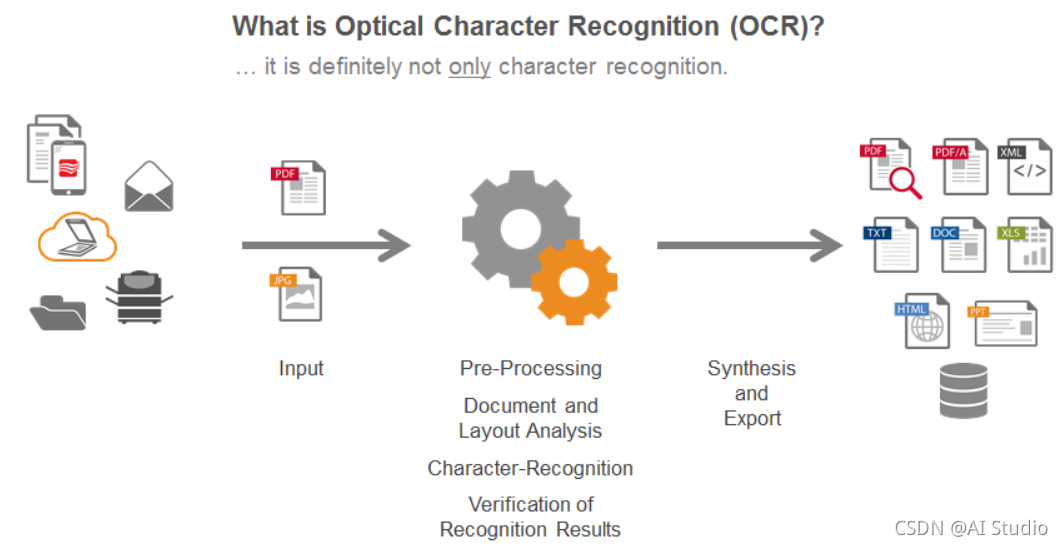
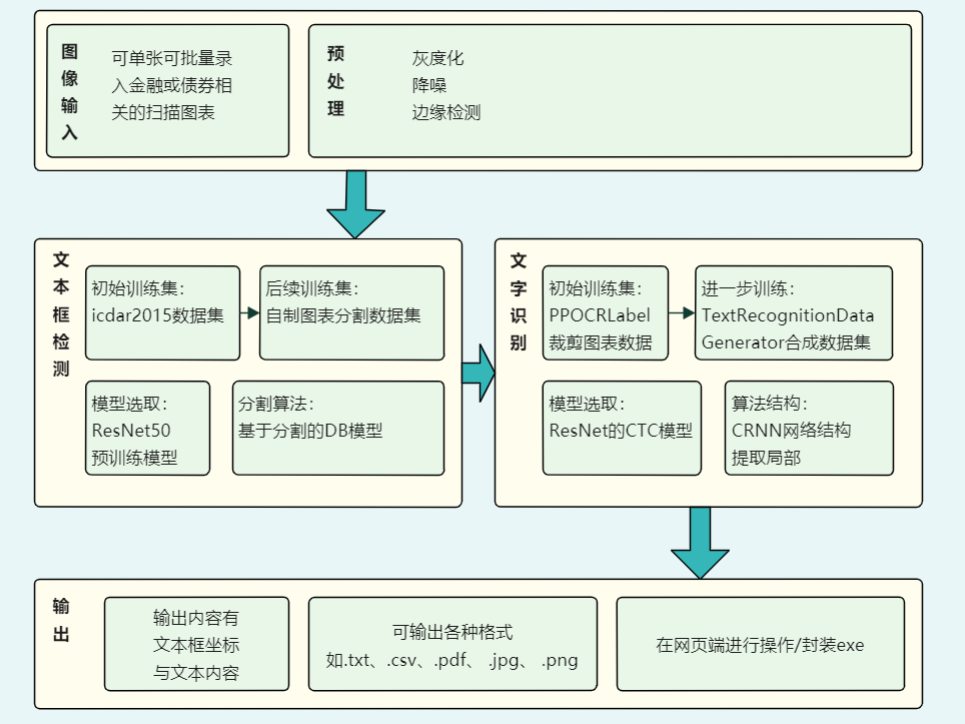
本项目用了飞桨平台的PaddleOCR框架,在预训练模型的基础上稍作修改并加以训练,最后导出精确度较高的模型。运行流程如下图。
技术方案
选用了飞桨的OCR平台,分别实现了文本框检测与文本识别功能。
(1)文本框检测
本任务选用icdar2015数据集,利用基于分割的Differenttiable Binarization module(DB模型)算法,选取基于飞桨PaddlePaddle的多种图像分类ReatNet50预训练模型,训练过程中根据精确度acc与损失值loss评测指标的断点保存定期对结果进行评估;后期使用自制的债券文本相关文本框识别数据集进行训练与测试,训练过程中采用了L2范数,学习率在0.01-0.0001之间周期性变化,结果验证本方案与最终测试集内容更加贴合,可以达到更高的识别精度。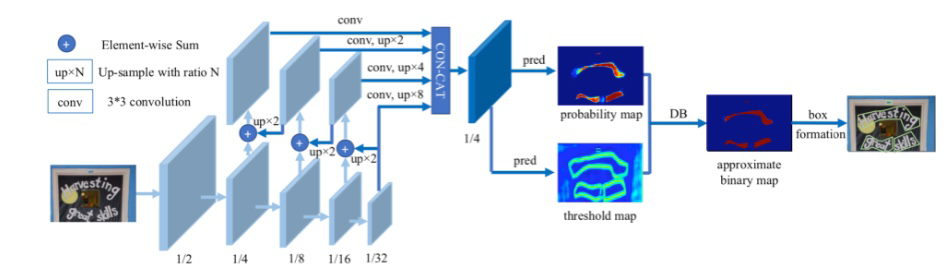
(2)文本识别
采用大量自制债券文本相关数据集,使数据与债券相关字符大量重复训练,选用了ResNet结构的CTC模型以及CRNN网络结构。训练过程中用TextRecognitionDataGenerator合成了带有标签的数据集,为确保训练精度与实际预测数据精度相差不大,引导模型预测陌生数据来对比精确度更有实际可行度。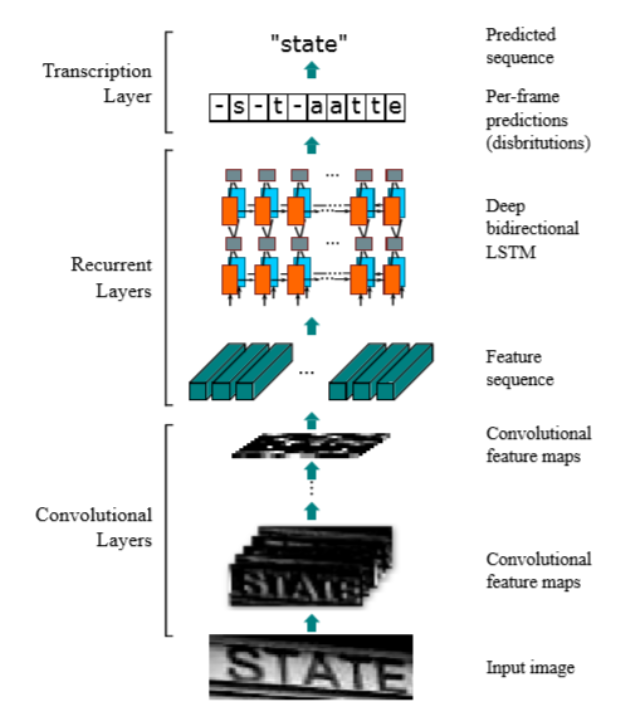
(3)数据集处理
A.文本检测
a.初步训练。本阶段选用了icdar 2015数据集,其中包含1000个训练图像和500个测试图像;数据集的语言是英文,包含了大量的实景样本;和icdar2013数据集不同的是,icdar 2013数据集整齐排列,而icdar2015更偏向于复杂场景文字检测 ,比如文本显示方向与大小都很随意,对于文本定位的训练度更高。
b.数据集选取。经过训练后,当损失值loss在0.3左右趋于稳定时,我们将icdar2015数据集替换为自制债券文本相关数据集。本数据集的图片来源于现实中上市公司公开的金融财务报表等文档图片,该数据集更加贴合题意的图表检测,用来训练定位标注效率更高。
c.数据集处理。本阶段利用开源的PPOCRLabel半自动化文本与识别框标注工具处理文档图片,实现文字识别框的坐标定位标记后导出图片与txt文档作为训练集与测试集。
B.文本识别
a.训练数据集。PPOCRLabel是一款适用于OCR领域的半自动化图形标注工具,使用python3和pyqt5编写,支持矩形框标注和四点标注模式,导出格式可直接用于PPOCR检测和识别模型的训练。训练集选用了先前文本检测用的PPOCRLabel处理裁剪过的文本数据集,大多是金融相关文本与数字,同样的字符与数字重复多次出现使得训练更加有效,更加贴合官方测试集。
b.测试数据集。测试集为确保训练精度与预测精度差别不大,使用TextRecognitionDataGenerator(下文称TRDG)开源项目合成数据集。TRDG可以根据现有字典内的文字加以处理,随机生成带有不同背景不同字体的数据集和对应的txt文档。和债券文本文档相比,更陌生的数据集对于模型的测试更有意义。如果用同一出处的测试集进行测验,会使精确度acc非常高,但测试其它数据的时候达不到预期的结果,普遍性的预测结果较差。
(4)训练调优
A.断点训练
设置好rec_chinese_common_v2.0模型开始用GPU进行训练,定时定量观察训练过程,合理设置epoch的值,设置模型保存间隔防止训练突然停止而中止进度。设置checkpoints断点保存,有利于不同训练量的模型精度做对比,实时观察模型训练效果。
B.学习率调整
在训练时尝试周期性地改变学习率。学习率对于模型训练很重要。学习率过小会发生过拟合,过大则导致学习出现误差。训练过程中尝试在0.01-0.0001之间周期性地改变学习率而没有设定为固定值。这样的操作使损失值loss比较稳定而不会强烈波动。周期性改变学习率使模型训练更加稳定,训练结果与预测结果更加贴近。
C.边训练边评估
参数设置上添加了模型评估间隔,开始训练2000 epoch后每1000 epoch评估一次,训练与评估检测同时进行。因为有设置断点保存,中止训练进行评估也是可行的。
D.L2范数
训练过程中用到了L2范数,向量各元素的平方和然后求平方根,实现了对模型空间的限制,提升模型的泛化能力,有效避免过拟合问题。
运行结果
结果分析
文本检测对照可视化结果可以检查有没有漏框错框的现象,文本OCR识别可以与文档中的原字句相对照,还有识别过程中的精度acc数据与损失值loss。
RestNet50预训练模型训练经过10000次后用图表的方式分析了日志文件,可以看出acc与loss随epoch进度的变化曲线,清晰地看出模型训练的结果。约5k处的抖动更换了训练集和调整学习率,出现斜率不稳的情况。
用比值的方法可视化出训练数/精确度与训练数/损失率的结果,可看出精度按、随着训练的增加上升,损失率逐步减少。较浅色的线为实时数据线的平滑化
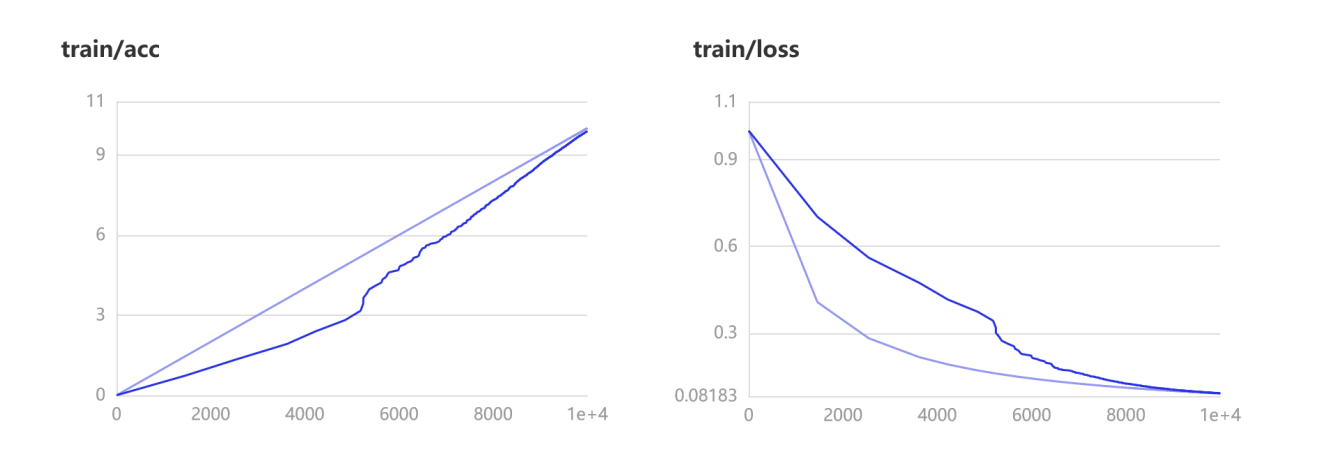
可视化输出
在PPOCRLabel的基础上改进,打包并导出了图表扫描可运行程序ChartOCR.exe,
经过实践可运行,准确度高,可以点击框内文字直接复制或输出为txt格式的文档。
打包成exe格式的文件

运行界面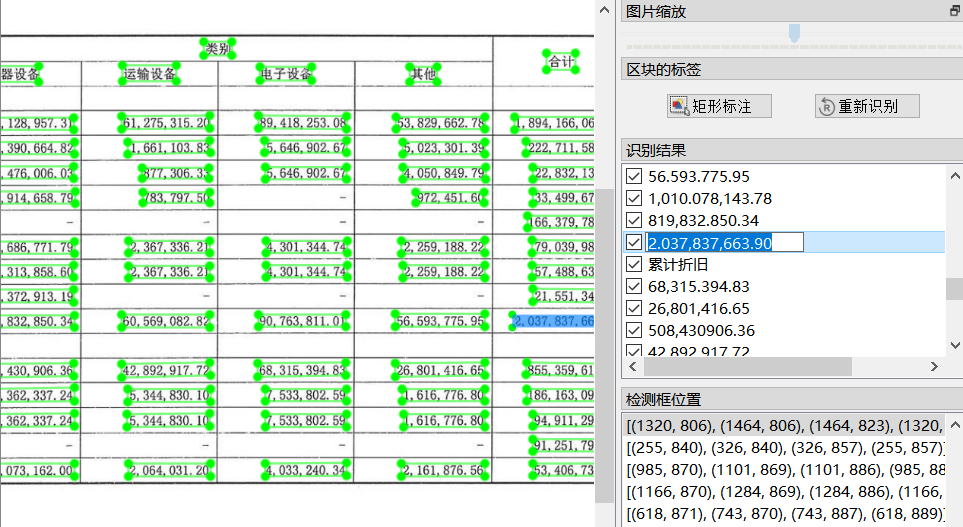
输出结果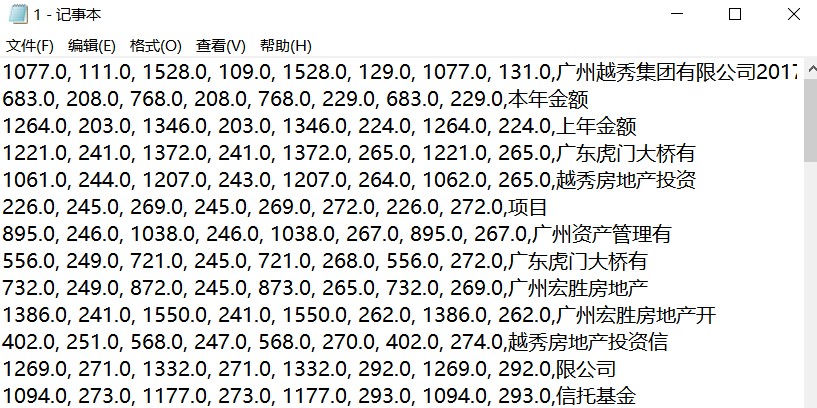
分析
从后面括号的准确度看,训练完成度较高(代码见下方)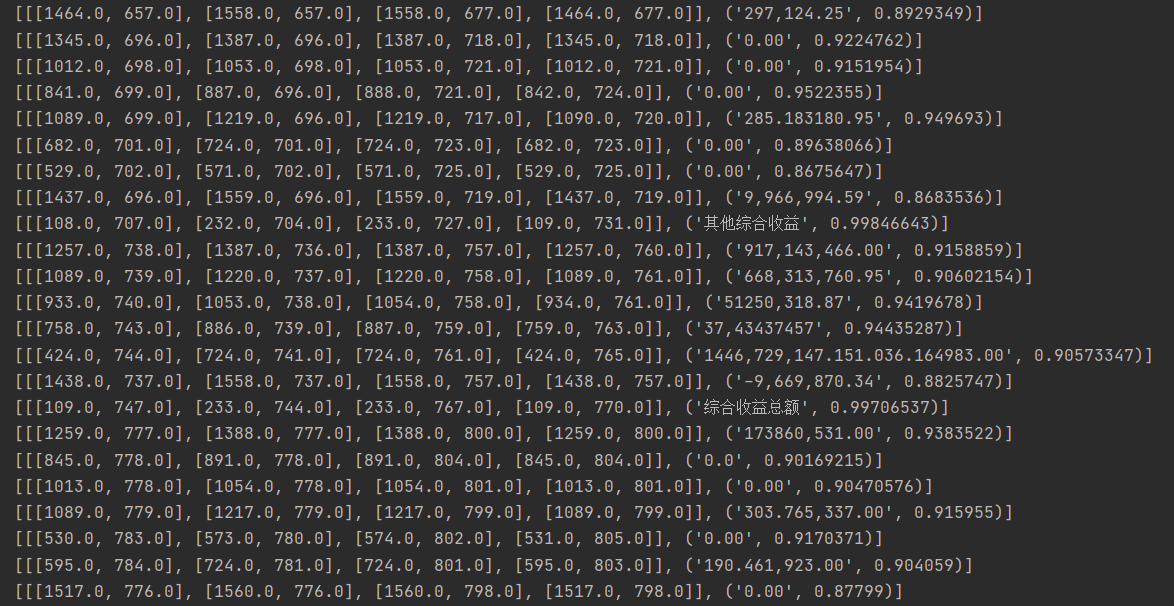
现实运用
应用前景
各种应用领域较广,有金融处理部门的企事业单位都可以使用到。
本项目面向需要处理大量图表数据的金融类企业或部门业务,相比于数字图像处理技术不成熟阶段的手动誊写抄录计算,自动化处理使图表内容的数字化存储更加便利也更加精准。
市场价值
同类或相似产品大多数是在线API传输,一些私密性较高的数据上传有泄露信息的风险,封装后的.exe格式文件可以装在本机上直接运行,没有数据泄露的风险。网页端产品大多按次数收费,工作量越大消耗资金越多。封装后的产品可以一次下载多次使用,大批量操作性价比高。
总结
小结
- OCR文本检测与识别实现了对图表的扫描与输出,可以分步得到文字所在文本框的定位坐标与文本框内容。本项目主要在百度开源的PaddlePaddle框架上加以改进,分det检测部分与rec识别部分。测试用例多数选用债券相关图表文档,取自上市公司公开报表图像文件。经验证,各项功能正常,在债券图表上测试识别准确率达到90%以上。
展望
- 基于深度学习的字符识别在准确率,识别速度方面有了提高,但比较消耗内存且对设备要求较高,如何降低内存消耗方面还有一定的探索前景。提高算法的进一步运算效率是下一步准备进行研究的方向。
- 现在使用文本检测与识别需要安装依赖环境,可运行程序使用顺利后考虑对项目进行封装,不用下载环境就可以直接使用,无深度学习基础的用户也能零门槛上手。
'''保存输出结果并可视化的测试代码'''
from paddleocr import PaddleOCR, draw_ocr
import os
os.environ["KMP_DUPLICATE_LIB_OK"] = "TRUE"
ocr = PaddleOCR(use_angle_cls=True, use_gpu=True)
img_path = '/图片路径'
result = ocr.ocr(img_path, cls=True)
for line in result:
print(line)
from PIL import Image
image = Image.open(img_path).convert('RGB')
boxes = [line[0] for line in result]
txts = [line[1][0] for line in result]
scores = [line[1][1] for line in result]
im_show = draw_ocr(image, boxes, txts, scores)
im_show = Image.fromarray(im_show)
im_show.save('result.jpg')
def save_txt(list1, list2, save_path):
if os.path.isfile(save_path):
os.remove(save_path)
with open(save_path,'a') as f:
for i in range(len(list1)):
x='{},\n'.format(list1[i])
x=x.replace('[', '').replace(']', '')
f.write(x)
f.close()
f.write(x)
f.close()
save_txt(boxes, txts, '/路径/保存的txt文件名.txt')

学大模型,用大模型上飞桨星河社区!每天8点V100G算力免费领!免费领取ERNIE 4.0 100w Token >>>
更多推荐



 0
0 0
0- 0



 已为社区贡献1437条内容
已为社区贡献1437条内容

所有评论(0)