
c++扩展算子开发②:cpu算子的开发
c++扩展算子开发②:cpu算子的开发
c++扩展算子开发②:cpu算子的开发
项目说明
在使用c++进行cpu算子开发
开发流程
- 编写.cpp文件
-
- 实现该算子的运算部分,返回运算成果,并绑定到python中使用
- 编写.py文件
-
- 实现该算子安装
项目展示
在CPU上面运行tanh算子,可以看到官方实现的算子和我们自己实现的cpu算子的前向输出和回传梯度都一致
安装自己实现的tanh算子,运行后请刷新下环境!!!
!python setup.py install
import numpy as np
x = np.random.random((4, 10)).astype("float32")
print(x)
[[0.08001675 0.00685823 0.977641 0.12384951 0.25485933 0.6080684
0.2576995 0.579619 0.2988902 0.9303997 ]
[0.31165263 0.91015273 0.9286078 0.28871018 0.49681845 0.9890461
0.11687255 0.8417647 0.71204054 0.20625657]
[0.612322 0.06017618 0.5243807 0.05294127 0.8621352 0.9054168
0.22857977 0.31994537 0.21134183 0.47577775]
[0.77470446 0.52597314 0.4896697 0.8867159 0.3593999 0.18468197
0.83999014 0.41859856 0.51255083 0.32560456]]
tanh(Offical)
import paddle
paddle_x = paddle.to_tensor(x, place=paddle.CPUPlace())
paddle_x.stop_gradient = False
paddle_y = paddle.tanh(paddle_x)
paddle_y.backward()
grad = paddle_x.gradient()
print("==========================================================")
print("前向传播:")
print(paddle_y)
print("==========================================================")
print("检测是否在CPU上:")
print(paddle_y.place)
print("==========================================================")
print("梯度:")
print(grad)
==========================================================
前向传播:
Tensor(shape=[4, 10], dtype=float32, place=CPUPlace, stop_gradient=False,
[[0.07984640, 0.00685812, 0.75204295, 0.12322014, 0.24948104, 0.54276597,
0.25214252, 0.52238846, 0.29029664, 0.73078030],
[0.30193979, 0.72120559, 0.72994423, 0.28094721, 0.45961139, 0.75695539,
0.11634330, 0.68674266, 0.61195481, 0.20338064],
[0.54575956, 0.06010363, 0.48107401, 0.05289185, 0.69735616, 0.71892518,
0.22468024, 0.30945751, 0.20825049, 0.44285581],
[0.64965671, 0.48229694, 0.45395419, 0.70976794, 0.34468532, 0.18261053,
0.68580383, 0.39574915, 0.47193030, 0.31456575]])
==========================================================
检测是否在CPU上:
CPUPlace
==========================================================
梯度:
[[0.99362457 0.999953 0.43443137 0.9848168 0.9377592 0.7054051
0.93642414 0.72711027 0.91572785 0.46596014]
[0.9088324 0.4798625 0.46718144 0.92106867 0.7887574 0.42701852
0.98646426 0.5283845 0.6255113 0.9586363 ]
[0.70214653 0.99638754 0.7685678 0.99720246 0.5136944 0.4831466
0.9495188 0.9042361 0.9566317 0.8038787 ]
[0.5779462 0.76738966 0.7939256 0.49622947 0.881192 0.9666534
0.5296731 0.8433826 0.77728176 0.9010484 ]]
tanh(Ours)
1、安装tanh算子,运行后请刷新下环境!!!(前面已经安装了)
!python setup.py install
2、开始测试
import paddle
from custom_ops import tanh_op
custom_ops_x = paddle.to_tensor(x)
custom_ops_x.stop_gradient = False
custom_ops_y = tanh_op(custom_ops_x)
custom_ops_y.backward()
grad = custom_ops_x.gradient()
print("==========================================================")
print("前向传播:")
print(custom_ops_y)
print("==========================================================")
print("检测是否在CPU上:")
print(custom_ops_y.place)
print("==========================================================")
print("梯度:")
print(grad)
==========================================================
前向传播:
Tensor(shape=[4, 10], dtype=float32, place=CPUPlace, stop_gradient=False,
[[0.07984642, 0.00685812, 0.75204289, 0.12322014, 0.24948102, 0.54276597,
0.25214252, 0.52238852, 0.29029667, 0.73078024],
[0.30193982, 0.72120547, 0.72994411, 0.28094721, 0.45961136, 0.75695533,
0.11634332, 0.68674266, 0.61195481, 0.20338066],
[0.54575950, 0.06010364, 0.48107395, 0.05289186, 0.69735610, 0.71892524,
0.22468026, 0.30945751, 0.20825051, 0.44285581],
[0.64965665, 0.48229691, 0.45395425, 0.70976782, 0.34468532, 0.18261056,
0.68580383, 0.39574915, 0.47193030, 0.31456575]])
==========================================================
检测是否在CPU上:
CPUPlace
==========================================================
梯度:
[[0.99362457 0.999953 0.4344315 0.9848168 0.9377592 0.7054051
0.93642414 0.7271102 0.91572785 0.46596023]
[0.9088324 0.47986266 0.4671816 0.92106867 0.7887574 0.42701864
0.9864642 0.5283845 0.6255113 0.9586363 ]
[0.7021466 0.99638754 0.76856786 0.99720246 0.51369447 0.4831465
0.9495188 0.9042361 0.9566317 0.8038787 ]
[0.57794625 0.7673897 0.7939255 0.49622965 0.881192 0.9666534
0.5296731 0.8433826 0.7772818 0.90104836]]
项目主体
.cpp文件
.cpp文件实现该算子的运算部分,返回运算成果,并绑定到python中使用
代码拆分
1、引入头文件
#include <paddle/extension.h>
#include <vector>
2、编写前向传播函数
说明:该函数是一个返回paddle::Tensor类型的函数,传入值为const paddle::Tensor类型
①output = paddle::Tensor(paddle::PlaceType::kCPU, input.shape())实现了在cpu上面创建一个output tensor,用以返回(但还没申请内存)
②input_numel = input.size()获取输入的size
③input_data = input.data<float>()用来获取输入的数据,并且这里将模板实例化为float型,当然也可以继续使用模板data_t,这里是CPU就不麻烦了
④output_data = output.mutable_data<float>(input.place());用来根据前面input.shape在指定设备上申请内存,并返回内存的起始地址
⑤for循环用以运算
⑥返回
std::vector<paddle::Tensor> tanh_forward(const paddle::Tensor &input){
auto output = paddle::Tensor(paddle::PlaceType::kCPU, input.shape());
auto input_numel = input.size();
auto* input_data = input.data<float>();
auto* output_data = output.mutable_data<float>(input.place());
for(int i=0; i<input_numel; i++){
output_data[i] = std::tanh(input_data[i]);
}
return {output};
}
3、编写反向传播函数
说明:该函数是一个返回paddle::Tensor类型的函数,用于返回input的梯度
①按照前面一样创建好input_grad(input的梯度)
②按照前面一样创建好剩余部分
③进行求偏导运算,这里可以知道tanh的导数为tanh' = 1 - tanh^2,所以input的梯度就是output的梯度 * tanh在input上面的导数,即input_grad = output_grad * (1 - tanh^2(input)),这里使用std::或者cmath::去实现
std::vector<paddle::Tensor> tanh_backward(const paddle::Tensor &input,
const paddle::Tensor &output,
const paddle::Tensor &output_grad){
auto input_grad = paddle::Tensor(paddle::PlaceType::kCPU, input.shape());
auto output_numel = output.size();
auto* input_data = input.data<float>();
auto* output_grad_data = output_grad.data<float>();
auto* input_grad_data = input_grad.mutable_data<float>(input.place());
for(int i=0; i<output_numel; i++){
input_grad_data[i] = output_grad_data[i] * (1 - std::pow(std::tanh(input_data[i]), 2));
}
return {input_grad};
}
4、使用PD_BUILD_OP系列宏,构建算子的描述信息,实现python与c++算子的绑定,作用有点类似PYBIND11_MODULE
PD_BUILD_OP:用于构建前向算子
PD_BUILD_GRAD_OP:用于构建前向算子对应的反向算子
注意:构建同一个算子的前向、反向实现,宏后面使用的算子名需要保持一致(此例中的tanh_op)
注意:PD_BUILD_OP与PD_BUILD_GRAD_OP中的Inputs与Outputs的name有强关联,对于前向算子的某个输入,如果反向算子仍然要复用,那么其name一定要保持一致(此例中的Inputs({"input"}和Outputs({"output"}),因为内部执行时,会以name作为key去查找对应的变量,比如这里前向算子的input与反向算子的input指代同一个Tensor
PD_BUILD_OP(tanh_op)
.Inputs({"input"})
.Outputs({"output"})
.SetKernelFn(PD_KERNEL(tanh_forward));
PD_BUILD_GRAD_OP(tanh_op)
.Inputs({"input", "output", paddle::Grad("output")})
.Outputs({paddle::Grad("input")})
.SetKernelFn(PD_KERNEL(tanh_backward));
完整代码
#include <paddle/extension.h>
#include <vector>
std::vector<paddle::Tensor> tanh_forward(const paddle::Tensor &input){
auto output = paddle::Tensor(paddle::PlaceType::kCPU, input.shape());
auto input_numel = input.size();
auto* input_data = input.data<float>();
auto* output_data = output.mutable_data<float>(input.place());
for(int i=0; i<input_numel; i++){
output_data[i] = std::tanh(input_data[i]);
}
return {output};
}
std::vector<paddle::Tensor> tanh_backward(const paddle::Tensor &input,
const paddle::Tensor &output,
const paddle::Tensor &output_grad){
auto input_grad = paddle::Tensor(paddle::PlaceType::kCPU, input.shape());
auto output_numel = output.size();
auto* input_data = input.data<float>();
auto* output_grad_data = output_grad.data<float>();
auto* input_grad_data = input_grad.mutable_data<float>(input.place());
for(int i=0; i<output_numel; i++){
input_grad_data[i] = output_grad_data[i] * (1 - std::pow(std::tanh(input_data[i]), 2));
}
return {input_grad};
}
PD_BUILD_OP(tanh_op)
.Inputs({"input"})
.Outputs({"output"})
.SetKernelFn(PD_KERNEL(tanh_forward));
PD_BUILD_GRAD_OP(tanh_op)
.Inputs({"input", "output", paddle::Grad("output")})
.Outputs({paddle::Grad("input")})
.SetKernelFn(PD_KERNEL(tanh_backward));
.py文件
.py文件主要是实现该算子安装
在安装后引用该算子,以此为例,是通过from custom_ops import tanh_op来引用的
其中custom_ops来自setup.py部分的name里
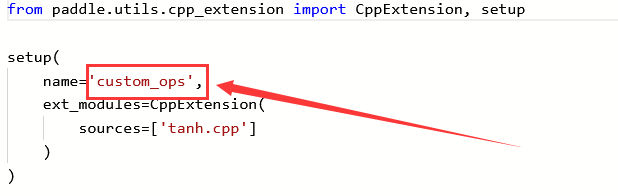
其中tan_op来自.cpp部分的PD_BUILD_OP里

from paddle.utils.cpp_extension import CppExtension, setup
setup(
name='custom_ops',
ext_modules=CppExtension(
sources=['tanh.cpp']
)
sion, setup
setup(
name='custom_ops',
ext_modules=CppExtension(
sources=['tanh.cpp']
)
)
个人简介
我的公众号

小作者会将在AI Studio上的划桨记录分享到公众号上,而且公众号不定期更新深度学习相关内容,有关于深度学习方面好玩的应用,有论文解读复现,有精读深度学习著作等,小作者还会将在AI Studio公开的项目的背后故事和思考点在公众号同步更新,欢迎关注鸭~
关于作者
| 学校 | 哈尔滨工业大学(深圳) 大三在读 |
|---|---|
| 感兴趣的方向 | 大号关注:图像视频、强化学习、点云 |
| 小号关注:文本、语音处理 | |
| 个人兴趣 | 本人比较喜欢有趣的事情,会开源一些有趣的项目,项目简单且适合新手,欢迎大家常来fork |
| 主页 | 大号主页 |
| 小号主页 | |
| 我的邮箱 | firewhitefox@qq.com |
| 我的公众号 | Hello Neural Networks |

学大模型,用大模型上飞桨星河社区!每天8点V100G算力免费领!免费领取ERNIE 4.0 100w Token >>>
更多推荐



 0
0 0
0- 0



 已为社区贡献1436条内容
已为社区贡献1436条内容

所有评论(0)