
基于PaddleNLP的小样本学习策略库EFL实现中文科学文献学科分类
基于PaddleNLP的小样本学习策略库EFL实现中文科学文献学科分类
基于Few-shot Learning实现中文科学文献学科分类
近年来,机器学习和深度学习在许多领域中取得了成功。但深度学习模型的成功,却依赖于大量训练数据。而在现实世界的真实场景中,某些类别只有少量数据或少量标注数据,而对无标签数据进行标注将会消耗大量的时间和人力。相反,人类只需要通过少量数据即可实现快速学习。例如,一个智力正常的初中生,甚至是小学生只需要学习过少量的古诗词,就能按照自己的想法创造出新的古诗词,这就是机器学习和人类学习之间存在的差距。小样本学习(Few-Shot Learning)的概念被提出,有助于机器学习更多接近人类思维。
Few-Shot任务旨在研究如何从少量有监督的训练样本中学习出具有良好泛化性的模型,对训练数据很少或监督数据获取成本极高的应用场景有很大价值。
一、数据集简介
小样本学习测评基准
FewCLUE是为中文NLP定制的小样本学习测评基准。其中有针对9个场景的子数据集:
- PRSTMT:电商评论情感分析;
- CSLDCP:中文科学文献学科分类;
- TNEWS:新闻分类;
- IFLYTEK:APP应用描述主题分类;
- OCNLI: 自然语言推理;
- BUSTM: 对话短文本匹配;
- CHID:成语阅读理解;
- CSL:摘要判断关键词判别;
- CLUEWSC: 代词消歧
中文科学文献学科分类数据集
本项目主要基于FewCLUE里的CSLDCP:中文科学文献学科分类数据集。该数据集一共有7979条数据,其中包括67个类别的文献类别,这些类别来自于分别归属于13个大类,范围从社会科学到自然科学,文本为文献的中文摘要。
数据样例
{"content": "通过几年的观察和实践,初步掌握了盆栽菊花的栽培技术及方法,并进行了总结,以满足人们对花卉消费的需求,提高观赏植物的商品价值,为企业化生产的盆菊提供技术指导。",
"label": "园艺学",
"id": 1770}
{"content": "GPS卫星导航定位精度的高低很大程度上取决于站星距离(即伪距)的测量误差.载波相位平滑伪距在保证环路参数满足动态应力误差要求的基础上。。。本文详细论述了载波相位平滑伪距的原理和工程实现方法,并进行了仿真验证.",
"label": "航空宇航科学与技术",
"id": 979}
每一条数据有三个属性,从前往后分别是 id,sentence,label。其中label标签,Positive 表示正向,Negative 表示负向。
数据加载
PaddleNLP 内置了 FewCLUE 数据集,可以直接用来进行训练、评估、预测。
# 安装最新版本的PaddleNLP
!python -m pip install --upgrade paddlenlp==2.0.2 -i https://mirror.baidu.com/pypi/simple
from paddlenlp.datasets import load_dataset
# 通过指定 "fewclue" 和数据集名字 name="csldcp" 即可一键加载 FewCLUE 中的 csldcp 数据集
train_ds, public_test_ds, test_ds = load_dataset("fewclue", name="csldcp", splits=("train_0", "test_public", "test"))
查看训练集、验证集和测试集的第一条数据:
print(train_ds.data[0])
{'content': '为保证发动机在不同的转速时都具有最佳点火提前角,同时提高摩托车的防盗能力,提出一种基于转速匹配的点火提前角和防盗控制方法.利用磁电机脉冲计算发动机转速,线生调整点火信号的触发延迟时间,实现点火提前角的精确控制.根据转速信息,结合GSM和GPS对点火器进行远程点火使能控制,设计数字点火器实现对摩托车进行跟踪与定位,并给出点火器的软硬件结构和详细设计.台架测试和道路测试表明所设计的基于发动机转速的数字点火器点火提前角控制精确,点火性能好,防盗能力强、范围广.', 'label': '控制科学与工程', 'id': 805}
print(public_test_ds.data[0])
{'content': '对黑龙江省东部五星Cu-Ni-Pt-Pd矿床的矿体和与成矿有关的镁铁质杂岩的PGE-Au以及铁族、亲铜元素的地球化学特征研究表明:它们均以亏损Cr、IPGE和富集Ni、Co、Cu、Pt和Pd(Pt<Pd)为特征,与成矿有关的镁铁质岩来自地幔部分熔融形成的玄武岩浆,岩浆(房)演化以结晶分离为主,伴随熔离作用.结合地质和岩相学特征,初步确定铜镍硫化物矿化在岩浆熔离作用的基础上产生,而铂钯矿化则主要发生在岩浆期后,以热液交代作用为主产生.因此,五星矿床是一个岩浆型铜镍硫化物和铂钯热液型复合的内生矿床.', 'label': '地质学/地质资源与地质工程', 'id': 0}
print(test_ds.data[0])
{'id': 0, 'content': '金山金矿床是中国西天山地区一个大型浅成低温热液型金矿,矿体产出主要受各种断裂构造控制.在多年勘探工作的基础上,通过野外填图和大量的勘探线剖面分析,笔者总结出断裂构造活动经历了成矿前、热液成矿期和成矿后3期.断裂控矿基本规律是:北西向断裂总体控制矿床的分布位置,南北向断裂晚期活动造成叠加富集成矿,北东向断裂早期伴随中酸性岩脉活动,成矿后活动造成矿体断开和升降,东西向-北西西断裂早期伴随火山喷发活动,成矿后活动切断南北向矿体.同时还总结了矿区的找矿评价标志.'}
二、通过Entailment构建小样本学习器
论文地址:Entailment as Few-Shot Learner
大型预训练语言模型(LMs)作为小样本学习器已经表现出了非凡的能力,然而,他们的成功在很大程度上取决于模型参数量的提升,这使得其训练,部署和服务具有挑战性。
在《Entailment as Few-Shot Learner》中,作者提出了一种新的方法,名为EFL(Entailment as Few-shot Learner),它可以将小的语言模型变成更好的小样本学习器。这种方法的关键思想是将潜在的NLP任务重新表述为一个entailment任务,然后只需用8个例子就可微调模型。
EFL方法可以:
- 与基于无监督的对比学习的数据增强方法自然结合;
- 容易扩展到多语言的小样本学习。
对18个标准的NLP任务进行的系统评估表明,这种方法将现有的各种SOTA几率学习方法提高了12%,并产生了与500倍大的模型(如GPT-3)具备竞争性的小样本性能。
一开始我还不太理解Entailment,我看了看EFL的训练源代码:
model = ppnlp.transformers.ErnieForSequenceClassification.from_pretrained('ernie-1.0', num_classes=2)
而ErnieForSequenceClassification的源码在PaddleNLP/paddlenlp/transformers/ernie/modeling.py,具体内容如下所示:
class ErnieForSequenceClassification(ErniePretrainedModel):
def __init__(self, ernie, num_classes=2, dropout=None):
super(ErnieForSequenceClassification, self).__init__()
self.num_classes = num_classes
self.ernie = ernie # allow ernie to be config
self.dropout = nn.Dropout(dropout if dropout is not None else
self.ernie.config["hidden_dropout_prob"])
self.classifier = nn.Linear(self.ernie.config["hidden_size"],
num_classes)
self.apply(self.init_weights)
def forward(self,
input_ids,
token_type_ids=None,
position_ids=None,
attention_mask=None):
_, pooled_output = self.ernie(
input_ids,
token_type_ids=token_type_ids,
position_ids=position_ids,
attention_mask=attention_mask)
pooled_output = self.dropout(pooled_output)
logits = self.classifier(pooled_output)
return logits
从代码上可以看出,其核心内容还是Ernie,然后在最后加了一层全连接层,num_classes=2,也就是说EFL将 NLP Fine-tune 任务转换统一转换为 Entailment 2 分类任务。
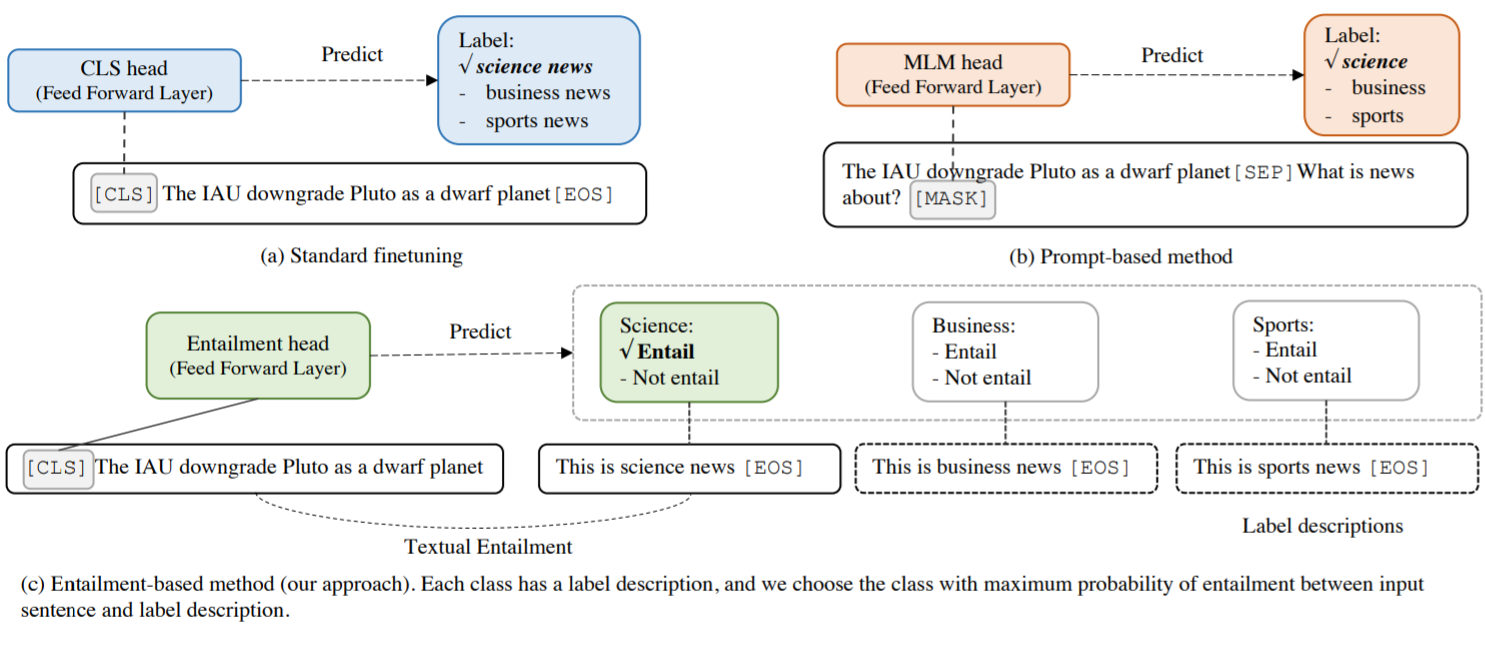
与基于提示的方法相比,这种方法的主要区别在于将任务重新定义为Entailment任务而不是“完形填空”,并设计细粒度的标签描述而不是单个任务描述。因此能在小样本场景下取得不错的效果。
三、模型训练
本项目所使用的代码已上传至左侧work文件夹下,可以通过如下运行train.py开启训练。
train.py参数含义说明:
- task_name: FewCLUE 中的数据集名字
- device: 使用 cpu/gpu 进行训练
- negative_num: 负样本采样个数,对于多分类任务,负样本数量对效果影响很大。负样本数量参数取值范围为 [1, class_num - 1]
- save_dir: 模型存储路径
- batch_size:每个GPU/CPU的训练批大小
- learning_rate:Adam的初始学习速率
- epochs:要执行的训练总数
- max_seq_length: 文本的最大截断长度
!python -u -m paddle.distributed.launch --gpus "0" \
work/train.py \
--task_name "csldcp" \
--device gpu \
--negative_num 66 \
--save_dir "./checkpoints" \
--batch_size 32 \
--learning_rate 1e-5 \
--epochs 2 \
--max_seq_length 512
----------- Configuration Arguments -----------
gpus: 0
heter_worker_num: None
heter_workers:
http_port: None
ips: 127.0.0.1
log_dir: log
nproc_per_node: None
run_mode: None
server_num: None
servers:
training_script: work/train.py
training_script_args: ['--task_name', 'csldcp', '--device', 'gpu', '--negative_num', '66', '--save_dir', './checkpoints', '--batch_size', '32', '--learning_rate', '1e-5', '--epochs', '2', '--max_seq_length', '512']
worker_num: None
workers:
------------------------------------------------
WARNING 2021-06-27 17:55:35,673 launch.py:357] Not found distinct arguments and compiled with cuda or xpu. Default use collective mode
launch train in GPU mode!
INFO 2021-06-27 17:55:35,674 launch_utils.py:510] Local start 1 processes. First process distributed environment info (Only For Debug):
+=======================================================================================+
| Distributed Envs Value |
+---------------------------------------------------------------------------------------+
| PADDLE_TRAINER_ID 0 |
| PADDLE_CURRENT_ENDPOINT 127.0.0.1:41017 |
| PADDLE_TRAINERS_NUM 1 |
| PADDLE_TRAINER_ENDPOINTS 127.0.0.1:41017 |
| PADDLE_RANK_IN_NODE 0 |
| PADDLE_LOCAL_DEVICE_IDS 0 |
| PADDLE_WORLD_DEVICE_IDS 0 |
| FLAGS_selected_gpus 0 |
| FLAGS_selected_accelerators 0 |
+=======================================================================================+
INFO 2021-06-27 17:55:35,675 launch_utils.py:514] details abouts PADDLE_TRAINER_ENDPOINTS can be found in log/endpoints.log, and detail running logs maybe found in log/workerlog.0
launch proc_id:22646 idx:0
[2021-06-27 17:55:37,237] [ INFO] - Already cached /home/aistudio/.paddlenlp/models/ernie-1.0/ernie_v1_chn_base.pdparams
W0627 17:55:37.238456 22646 device_context.cc:404] Please NOTE: device: 0, GPU Compute Capability: 7.0, Driver API Version: 11.0, Runtime API Version: 10.1
W0627 17:55:37.243487 22646 device_context.cc:422] device: 0, cuDNN Version: 7.6.
/opt/conda/envs/python35-paddle120-env/lib/python3.7/site-packages/paddle/fluid/dygraph/layers.py:1297: UserWarning: Skip loading for classifier.weight. classifier.weight is not found in the provided dict.
warnings.warn(("Skip loading for {}. ".format(key) + str(err)))
/opt/conda/envs/python35-paddle120-env/lib/python3.7/site-packages/paddle/fluid/dygraph/layers.py:1297: UserWarning: Skip loading for classifier.bias. classifier.bias is not found in the provided dict.
warnings.warn(("Skip loading for {}. ".format(key) + str(err)))
[2021-06-27 17:55:42,191] [ INFO] - Found /home/aistudio/.paddlenlp/models/ernie-1.0/vocab.txt
global step 200, epoch: 1, batch: 200, loss: 0.04065, speed: 0.06 step/s
global step 400, epoch: 1, batch: 400, loss: 0.02934, speed: 0.06 step/s
global step 600, epoch: 1, batch: 600, loss: 0.13510, speed: 0.06 step/s
global step 800, epoch: 1, batch: 800, loss: 0.03925, speed: 0.06 step/s
global step 1000, epoch: 1, batch: 1000, loss: 0.00930, speed: 0.06 step/s
epoch:1, dev_accuracy:58.408, total_num:1784
global step 1200, epoch: 2, batch: 77, loss: 0.01942, speed: 0.01 step/s
global step 1400, epoch: 2, batch: 277, loss: 0.00554, speed: 0.06 step/s
global step 1600, epoch: 2, batch: 477, loss: 0.00251, speed: 0.06 step/s
global step 1800, epoch: 2, batch: 677, loss: 0.00384, speed: 0.06 step/s
global step 2000, epoch: 2, batch: 877, loss: 0.00228, speed: 0.06 step/s
global step 2200, epoch: 2, batch: 1077, loss: 0.01744, speed: 0.06 step/s
epoch:2, dev_accuracy:60.594, total_num:1784
INFO 2021-06-27 19:26:53,708 launch.py:266] Local processes completed.
四、模型效果评估
!python -u -m paddle.distributed.launch --gpus "0" \
work/predict.py \
--task_name "csldcp" \
--device gpu \
--init_from_ckpt "./checkpoints/model_2246/model_state.pdparams" \
--output_dir "./output" \
--batch_size 32 \
--max_seq_length 512
----------- Configuration Arguments -----------
gpus: 0
heter_worker_num: None
heter_workers:
http_port: None
ips: 127.0.0.1
log_dir: log
nproc_per_node: None
run_mode: None
server_num: None
servers:
training_script: work/predict.py
training_script_args: ['--task_name', 'csldcp', '--device', 'gpu', '--init_from_ckpt', './checkpoints/model_2246/model_state.pdparams', '--output_dir', './output', '--batch_size', '32', '--max_seq_length', '512']
worker_num: None
workers:
------------------------------------------------
WARNING 2021-06-27 20:34:14,282 launch.py:357] Not found distinct arguments and compiled with cuda or xpu. Default use collective mode
launch train in GPU mode!
INFO 2021-06-27 20:34:14,284 launch_utils.py:510] Local start 1 processes. First process distributed environment info (Only For Debug):
+=======================================================================================+
| Distributed Envs Value |
+---------------------------------------------------------------------------------------+
| PADDLE_TRAINER_ID 0 |
| PADDLE_CURRENT_ENDPOINT 127.0.0.1:49189 |
| PADDLE_TRAINERS_NUM 1 |
| PADDLE_TRAINER_ENDPOINTS 127.0.0.1:49189 |
| PADDLE_RANK_IN_NODE 0 |
| PADDLE_LOCAL_DEVICE_IDS 0 |
| PADDLE_WORLD_DEVICE_IDS 0 |
| FLAGS_selected_gpus 0 |
| FLAGS_selected_accelerators 0 |
+=======================================================================================+
INFO 2021-06-27 20:34:14,284 launch_utils.py:514] details abouts PADDLE_TRAINER_ENDPOINTS can be found in log/endpoints.log, and detail running logs maybe found in log/workerlog.0
launch proc_id:5624 idx:0
[2021-06-27 20:34:15,858] [ INFO] - Already cached /home/aistudio/.paddlenlp/models/ernie-1.0/ernie_v1_chn_base.pdparams
W0627 20:34:15.859658 5624 device_context.cc:404] Please NOTE: device: 0, GPU Compute Capability: 7.0, Driver API Version: 11.0, Runtime API Version: 10.1
W0627 20:34:15.864339 5624 device_context.cc:422] device: 0, cuDNN Version: 7.6.
/opt/conda/envs/python35-paddle120-env/lib/python3.7/site-packages/paddle/fluid/dygraph/layers.py:1297: UserWarning: Skip loading for classifier.weight. classifier.weight is not found in the provided dict.
warnings.warn(("Skip loading for {}. ".format(key) + str(err)))
/opt/conda/envs/python35-paddle120-env/lib/python3.7/site-packages/paddle/fluid/dygraph/layers.py:1297: UserWarning: Skip loading for classifier.bias. classifier.bias is not found in the provided dict.
warnings.warn(("Skip loading for {}. ".format(key) + str(err)))
[2021-06-27 20:34:20,753] [ INFO] - Found /home/aistudio/.paddlenlp/models/ernie-1.0/vocab.txt
Loaded parameters from ./checkpoints/model_2246/model_state.pdparams
INFO 2021-06-27 20:53:21,567 launch.py:266] Local processes completed.
把结果下载下来,前10个预测结果如下所示:
{"id": 0, "label": "矿业工程"}
{"id": 1, "label": "交通运输工程"}
{"id": 2, "label": "畜牧学/兽医学"}
{"id": 3, "label": "公共卫生与预防医学"}
{"id": 4, "label": "心理学"}
{"id": 5, "label": "核科学与技术"}
{"id": 6, "label": "应用经济学"}
{"id": 7, "label": "艺术学"}
{"id": 8, "label": "口腔医学"}
{"id": 9, "label": "机械工程"}
for item in range(10):
or item in range(10):
print(test_ds.data[item])
{'id': 0, 'content': '金山金矿床是中国西天山地区一个大型浅成低温热液型金矿,矿体产出主要受各种断裂构造控制.在多年勘探工作的基础上,通过野外填图和大量的勘探线剖面分析,笔者总结出断裂构造活动经历了成矿前、热液成矿期和成矿后3期.断裂控矿基本规律是:北西向断裂总体控制矿床的分布位置,南北向断裂晚期活动造成叠加富集成矿,北东向断裂早期伴随中酸性岩脉活动,成矿后活动造成矿体断开和升降,东西向-北西西断裂早期伴随火山喷发活动,成矿后活动切断南北向矿体.同时还总结了矿区的找矿评价标志.'}
{'id': 1, 'content': '为证明"轴-辐"式运输网络有独立于密度经济而存在的范围经济,在假设运输网络密度收益不变的前提下建立了独立分段运营与整合运营两种模式下运输网络的成本函数,对比发现,采用独立分段运营与"轴-辐"式整合运营两种模式的运输网络运营成本差异较大,当采用"轴-辐"式整合运营模式且运输网络达到最佳运营结构时才能实现范围经济,其原因在于采用"轴-辐"式整合运营模式进行运营线路整合优化时能使营运车辆及人员工作效率得到提高. 结果表明,密度收益恒定时"轴-辐"式网络运营模式下存在范围经济,但范围经济的取得需通过运营线路结构优化才能实现.'}
{'id': 2, 'content': '肉鸡腹脂双向选择系的选育是以第6世代高、低脂系肉鸡为试验材料,通过分析第6世代高、低脂系肉仔鸡腹脂重、腹脂率和体重在两系间的差异,进一步研究腹脂重(率)作为遗传标记对高、低脂系进行选择时,对体重及其他性状是否有影响,同时研究了血浆极低密度脂蛋白(VLDL)间接选择的可能性,为研究鸡的脂类代谢提供素材,并且为我国低质肉鸡的选育奠定良好基础.'}
{'id': 3, 'content': '患者男,35岁.因躯干和双上肢皮疹伴轻度瘙痒4 年,加重1 年于2009 年2 月8 日来我科就诊.患者平素喜好甜食及酗酒,否认患有病毒性肝炎、糖尿病及其他内脏疾病和长期用药史.患者父母及其家族成员无类似疾患.'}
{'id': 4, 'content': '自我的内隐社会认知研究具备坚实的理论基础,又有严格的实证研究方法,可以促进自我理论的深入发展.目前,内隐社会认知的自我研究已经成为自我研究的新生力量.文章最后对该取向的意义和趋势作了展望.'}
{'id': 5, 'content': '介绍了一种用于多层平板型电离室(或裂变室)的多路输出方法,该方法有利于提高电离室的时间响应,缓解因易裂变材料过多而产生的α粒子信号堆积问题,能够使电离室容纳更多的核材料,提高探测效率.'}
{'id': 6, 'content': '本文探讨了最优专利保护宽度的决定机制.在一个三阶段博弈模型中:社会计划者首先制定专利保护宽度,然后各厂商进行专利竞赛,最后市场对专利产品进行非侵权模仿并导致Salop垄断竞争.模型分析表明,在创新阶段,专利保护宽度对应于专利利润,决定了市场的创新激励;但在垄断竞争均衡中,它又对应于非侵权模仿成本,决定了总的模仿成本和消费者购买产品的交通成本.这两种功能对社会福利的影响是相互冲突的,而最优保护宽度正是在两者之间进行权衡的结果.比较静态分析表明,垄断竞争均衡下的最优宽度是创新难度、创新的重要性以及创新环境不确定性程度的增函数,是消费者多样性偏好的减函数,但与市场范围的大小无关.'}
{'id': 7, 'content': '文中的"变态"指的是一种艺术创作中的"颠狂"状态,而非通常贬义上的精神变态.这种"变态"是否有助于绘画表现,尚待基因科学进一步研究证实,但笔者认为,"变态"在一定程度上对艺术创作产生了一定的影响:它推动了艺术创作,有助于艺术创作中情感的表现;但是这种变态不是单纯的精神变异,它在起作用的同时,仍离不开理性的约束.本文根据艺术创作的特点,从心理学的角度对这一影响进行了阐述.'}
{'id': 8, 'content': '目的 观察小鼠腭中缝在机械扩张力作用的不同阶段EphB4/ephrinB2分布和表达规律.方法 选用6周龄健康雄性C57BL/6小鼠40只,随机分成对照组和实验扩张组,每组各20只.用双眼簧扩弓器施加扩张力(0.56 N)于实验加力组小鼠的腭中缝区.实验组分别于加力后1、3、7、14 d抽取5只小鼠通过石蜡切片免疫组化对EphB4/ephrinB2进行组织定位,观察表达规律并与未施力的对照组比较.结果 扩张组EphB4/ephrinB2表达水平高于对照组,差异具有统计学意义.第3天实验组EphB4/ephrinB2表达水平表达最高.结论 对小鼠腭中缝施加扩张力的情况下能够诱导EphB4/ephrinB2的表达增加,说明EphB4/ephrinB2在腭中缝扩张新骨改建过程中具有重要意义.'}
{'id': 9, 'content': '滚动轴承故障振动信号中的冲击成分呈现显著的非高斯性,高阶累积量和高阶谱技术是处理非高斯信号的良好分析工具。在四阶累积量-Teager 峭度的基础上提出滑动 Teager 峭度的分析方法,并联合三阶谱-1.5维谱,提出基于1.5维 Teager 峭度谱的滚动轴承故障诊断方法。该方法首先对轴承故障信号进行滑动 Teager 峭度计算,获得一个反应故障信号冲击特性的 Teager 峭度时间序列,然后通过计算 Teager 峭度时间序列的1.5维谱,提取出滚动轴承故障特征频率。通过仿真信号分析验证了该方法的解调性能和提取滚动轴承弱冲击故障特征的能力。最后分析了滚动轴承内圈故障实验测试信号,并和基于快速 Kurtogram 算法的共振解调方法进行对比分析,验证了该方法的有效性。'}
- 从结果上可以看出,“矿业工程”、“交通运输工程”、“核科学与技术”和“机械工程”这些偏理工科的学科,模型预测的效果比较好,其原因是这些学科分类比较明显,所以也很好区分;
- 但是,“口腔医学”这些有点偏文,且学科门类复杂的学科,模型的预测效果较差,模型需要花更多的时间进行学习。
五、总结与升华
Tip
在EFL中,因为是小样本学习,因此增加数据是非常有必要的,negative_num参数用来配置负样本采样个数,对于多分类任务,负样本数量对效果影响很大,负样本数量参数取值范围为 [1, class_num - 1],这个参数可以尽可能地大一些,这样模型的效果会好一些。
注意
在保存模型权重以后,点开模型权重的文件夹,会报一个“Cannot read property ‘length’ of undefined”的错误,如图所示:
这个问题不大,在终端其实是可以看到文件夹下保存的模型权重的:
后续解决方法:上面出现这个错误的原因是checkpoints这个名字在AI Studio里面内置了,因此,只要换个文件夹的名称即可~
作者简介
北京联合大学 机器人学院 自动化专业 2018级 本科生 郑博培
中国科学院自动化研究所复杂系统管理与控制国家重点实验室实习生
百度飞桨开发者技术专家 PPDE
百度飞桨官方帮帮团、答疑团成员
深圳柴火创客空间 认证会员
百度大脑 智能对话训练师
阿里云人工智能、DevOps助理工程师
我在AI Studio上获得至尊等级,点亮10个徽章,来互关呀!!!
https://aistudio.baidu.com/aistudio/personalcenter/thirdview/147378


学大模型,用大模型上飞桨星河社区!每天8点V100G算力免费领!免费领取ERNIE 4.0 100w Token >>>
更多推荐



 0
0 0
0- 0



 已为社区贡献1437条内容
已为社区贡献1437条内容

所有评论(0)