
区块链知识浅谈1
区块链知识浅谈1
区块链知识浅谈1
标签: 密码学,区块链,共识算法
本文吸取Preethi Kasireddy所谈论的区块链技术上总结
📖 1 区块链的基本结构
[由我国区块链白皮书所公布的内容]: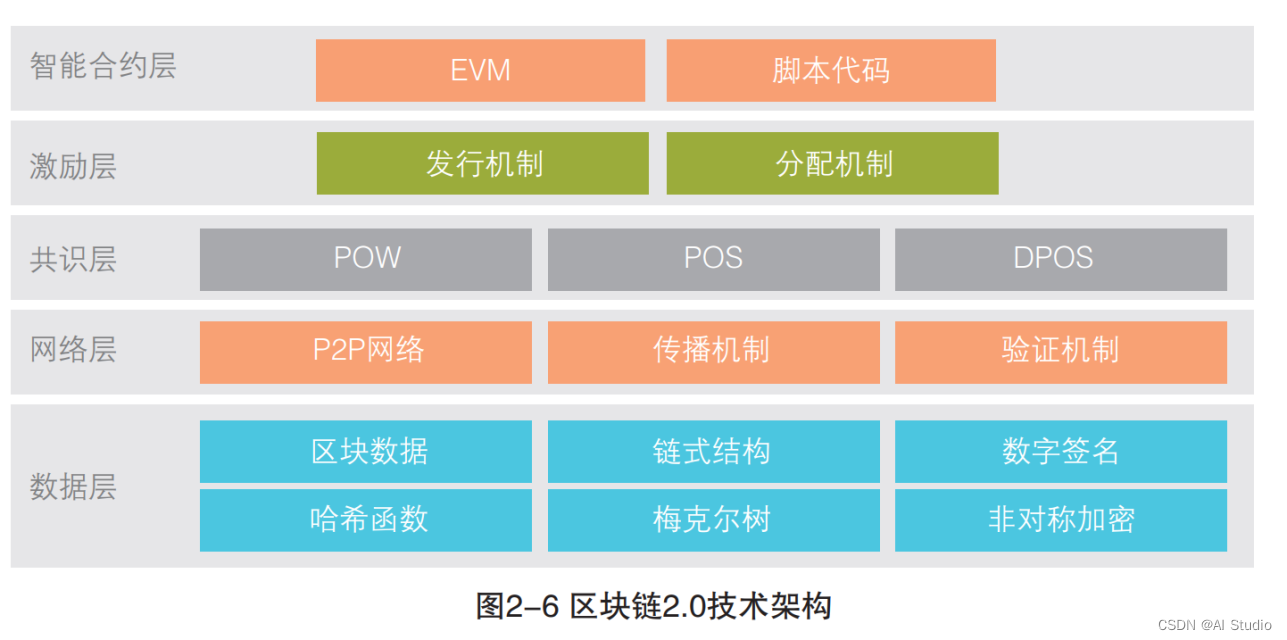
其中最为重要的就是共识层的算法
1.1 区块链的目的和优势
区块链公链的实现并广为人知最早源于“中本聪”的比特币,其主要显示的优点就是其内容有多方的备份,并且相同,因此具有很强的不可抵赖性和可靠性。区块链其本质上更像是一个新兴的分布式系统
那么什么是分布式系统呢:分布式系统是一组不同、分散的的进程,它们之间能够互相协调,通过相互间的信息传递完成一个共同的目标。尽管这些进程是分开的,但呈现给用户的,是一个系统、一个整体。说白了分布式系统就是围绕同一个目标而协同工作的一群计算机设备
区块链更像是一个由独立个体组成的冗余系统,对于一个冗余系统而言最终要的如何做到一致性,由于区块链所在的区域是公共网络,那么存在两个最基本的特征:
1. 并发性:系统中的进程是同时操作的,多个事件同时发生。换言之,网络中的每台计算机都在同时、独立地执行任务。
2. 缺少全局时钟:在分布式计算机系统中,我们需要确定事件发生的先后顺序,但由于各台计算机在空间上是分开的,所以,我们缺少一个全局时钟。
3. 独立进程故障:在分布式系统中,每个进程都可能发生故障,这些故障可能是进程崩溃或失控,可能是信息遗漏、歪曲或重复,也可能是恶意信息,还可能是网络延迟、断网断电。而进程故障由存在三个类型:
崩溃:进程在没有任何警告的情况下停止工作,如计算机崩溃。属于非恶意行为。
遗漏:进程发送消息,但其他节点收不到,如消息丢失。属于非恶意行为。
拜占庭:进程的行为随机。如果是在受控环境(例如 Google 或 Amazon 的数据中心)中,这种情况可以不做考虑。我们主要关心故障发生在“冲突地带”中的情形,他们的行为相当随意,可能会恶意更改和阻断信息,或者根本就不发送。属于恶意行为。
可以想象每台电脑都是一个人在一个混乱且吵闹的场合按顺序写下他们个人的名字,只能通过转纸条来传递消息,纸条可能会弄丢,可能要传很久,那么要让每个人都在自己的本字上写下相同顺序的名字列表就变得很困难。而解决这个问题的方式就是一致性算法。
⚙️ 2 系统的共识问题(一致性算法)
首先,若要求保证在几台服务器之间构造出一种能够有效统一对外的分布式系统可行性,需要依据CAP定理。
CAP分别是如下3个单词的首字母缩写。
Consistency:一致性
Availability:可用性
Partition-tolerance:分区容错性 对此,学者提出的共识算法发展历程可以如下图所表示: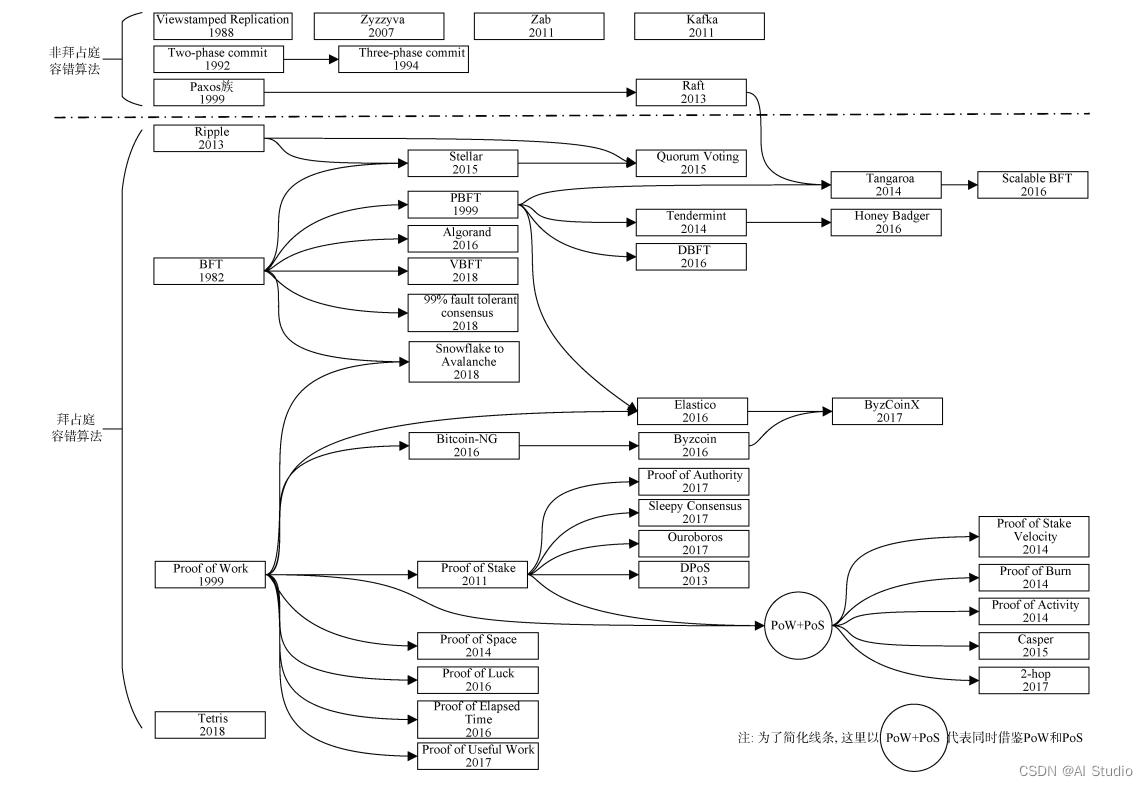
共识”的意思是保证所有的参与者都有相同的认知(可以理解为强一致性)。共识算法本身可以依据是否有恶意节点分为两类,大部分时候共识算法指的都是没有恶意节点的那一类,即系统中的节点不会向其他节点发送恶意请求,比如欺骗请求。共识算法中最有名的应该是Paxos算法。
📦 3 Paxos
Paxos由Leslie Lamport提出,其作为最早提出了共识算法之一具有以下几个特性:
高效,节点通信无须验证身份签名。
Paxos算法有严格的数学证明,系统设计精妙。
容错性能: 允许半数以内的Acceptor失效、任意数量的Proposer失效,都能运行。 ⼀旦value值被确定,即使半数以内的Acceptor失效,此值也可以被获取,并不会再修改。
3.1 Paxos共识提出背景及假设
分布式系统中的节点通信存在两种模型:共享内存(Shared memory)和消息传递(Messages passing)。基于消息传递通信模型的分布式系统,不可避免的会发生以下错误:进程可能会慢、被杀死或者重启,消息可能会延迟、丢失、重复。在最普通的Paxos 场景中,先不考虑可能出现「消息篡改」(即拜占庭错误的情况)。Paxos 算法解决的问题是在一个可能发生前述异常(即排除消息篡改之外的其他任何异常)的分布式系统中,如何对某个值的看法相同,保证无论发生以上任何异常,都不会破坏决议的共识机制。一个典型的场景是,在一个分布式数据库系统中,如果各节点的初始状态一致,每个节点都执行相同的操作序列,那么他们最后能得到一个一致的状态。为保证每个节点执行相同的命令序列,需要在每一条指令上执行一个「共识算法」以保证每个节点看到的指令一致。一个通用的共识算法可以应用在许多场景中,是分布式计算中的重要问题。因此从20世纪80年代起对于共识算法的研究就没有停止过。
为描述Paxos算法,Lamport虚拟了一个叫做Paxos的希腊城邦,这个岛按照议会民主制的政治模式制订法律,但是没有人愿意将自己的全部时间和精力放在这种事情上。所以无论是议员,议长或者传递纸条的服务员都不能承诺别人需要时一定会出现,也无法承诺批准决议或者传递消息的时间。但是这里假设没有拜占庭将军问题(Byzantine failure,即虽然有可能一个消息被传递了两次,但是绝对不会出现错误的消息);只要等待足够的时间,消息就会被传到。另外,Paxos岛上的议员是不会反对其他议员提出的决议的。
对应于分布式系统,议员对应于各个节点,制定的法律对应于系统的状态。各个节点需要进入一个一致的状态,例如在独立Cache的对称多处理器系统中,各个处理器读内存的某个字节时,必须读到同样的一个值,否则系统就违背了一致性的要求。一致性要求对应于法律条文只能有一个版本。议员和服务员的不确定性对应于节点和消息传递通道的不可靠性。
3.2 Paxos共识流程
首先,Lamport对算法中出现的用户角色给出定义:角色分为proposers,acceptors,和learners(允许身兼数职)。proposers 提出提案,提案信息包括提案编号和提议的value;acceptor 收到提案后可以接受(accept)提案,若提案获得多数派(majority)的acceptors 的接受,则称该提案被批准(chosen);learners 只能「学习」被批准的提案。 之后,可以粗略的将算法过程分为两个阶段: * prepare阶段:
1. proposer选择一个提案编号n并将prepare请求发送给acceptors中的一个多数派;
2. acceptor收到prepare消息后,如果提案的编号大于它已经回复的所有prepare消息(回复消息表示接受accept),则acceptor将自己上次接受的提案回复给proposer,并承诺不再回复小于n的提案;
* 批准阶段:
1. 当一个proposer收到了多数acceptors对prepare的回覆后,就进入批准阶段。它要向回复prepare请求的acceptors发送accept请求,包括编号n和根据P2c决定的value(如果根据P2c没有已经接受的value,那么它可以自由决定value)。
2. 在不违背自己向其他proposer的承诺的前提下,acceptor收到accept请求后即批准这个请求。
这个过程在任何时候中断都可以保证正确性。例如如果一个proposer发现已经有其他proposers提出了编号更高的提案,则有必要中断这个过程。因此为了优化,在上述prepare过程中,如果一个acceptor发现存在一个更高编号的提案,则需要通知proposer,提醒其中断这次提案。
3.3 Paxos共识代码实现
In [2]
import queue
import random
import threading
import time
from multiprocessing import Queue
from queue import Empty
mutex = threading.Lock()
###############################################
#辅助函数
#打印信息的辅助函数,避免多线程打印打乱的情况
###############################################
def printStr(string):
mutex.acquire()
print(string)
mutex.release()
###############################################
#paxos 决议管理者
#负责所有的决议管理和编号分发
###############################################
class Leader(threading.Thread):
def init(self, t_name, #发起者名称
queue_to_leader, #接收请求的队列
queue_to_proposers, #和proposer通讯的消息队列
acceptor_num #表决者数量,用来生成表决者编号
):
threading.Thread.init(self, name=t_name)
self.queue_recv=queue_to_leader
self.queue_send_list=queue_to_proposers
#acceptor编号
self.acceptor_list=range(0,acceptor_num)
#议案内容
self.value_index=0
self.values=[“[第一块数据由A进行更新]”,
“[第一块数据由B进行更新]”,
“[第一块数据由C进行更新]”,
“[第一块数据由D进行更新]”,
“[第一块数据由E进行更新]”,
“[第一块数据由F进行更新]”]
#议案编号
self.value_num=100
def run(self):
while(True):
#接收请求,分配议案
var=self.queue_recv.get()
#请求数据
if(var[“type”]“request”):
#接收到数据"
#随机分配半数以上的acceptors
acceptors=random.sample(self.acceptor_list, len(self.acceptor_list)//2)
rsp={
“value”:self.values[self.value_index], #议案内容
“value_num”:self.value_num, #议案编号
“acceptors”:acceptors #表决者编号
}
self.value_num+=1
self.value_index+=1
#更新接收者列表
if(var[“type”]“renew”):
var_list=var[“list”]
for i in var[“failure”]:
var_list.remove(i)
tmp=random.sample(self.acceptor_list,1)
while (tmp[0] in var[“failure”]):
tmp=random.sample(self.acceptor_list,1)
var_list.append(tmp[0])
rsp={
“list”:var_list
}
self.queue_send_list[var["ID"]].put(rsp)
###############################################
#paxos 决议发起者
#议案的提出者,负责提出议案并等待各个接收者的表决
###############################################
class Proposer(threading.Thread):
def init(self, t_name, #发起者名称
q_to_leader, #和leader通信的队列
queue_from_acceptor, #和acceptor通讯的消息队列
queue_to_acceptors, #接收消息队列
m_num, #ID号
m_acceptor_num): #总共的acceptor数量
threading.Thread.init(self, name=t_name)
self.queue_to_leader=q_to_leader
self.queue_recv=queue_from_acceptor
self.queue_send_list=queue_to_acceptors
self.num=m_num
self.reject=0
self.accept=0
self.chosen=0
self.start_propose=False
self.fail_list=[]
def run(self):
#从leader那里获取数据
self.getValueFromLeader()
lens=len(self.acceptors)
#给自己发送一个start信号
start_sig={
“type”:“start”
}
self.queue_recv.put(start_sig)
#循环接收消息
while (True):
try:
var=self.queue_recv.get(True,1)
#接收到消息,准备处理
self.processMsg(var)
except Empty:
#没有接受到消息
if(self.start_propose==True and time.time()-self.time_start > 5):
printStr(self.name +"的本轮决议"+self.value+"投票结束,同意:"+str(self.accept)+"拒绝:"+str(self.reject) + "选择:"+str(self.chosen))
self.start_propose=False
if(self.reject>0):
printStr(self.name+"的决议"+self.value+"被否决,停止提议,退出")
if(self.chosen==len(self.acceptors)):
printStr("############# "+self.name+"的决议"+self.value+"被同意,完成决议过程 #############")
if (self.accept>0 or
(self.chosen<len(self.acceptors) and self.chosen>0 and self.reject==0) or
(self.accept==0 and self.chosen==0 and self.reject==0)):
self.reject=0
self.chosen=0
self.accept=0
self.sendPropose()
continue
###############################################
#
#从leader那里获取数据
#
###############################################
def getValueFromLeader(self):
req={
"type":"request",
"ID":self.num
}
printStr("从管理者处获取数据...")
self.queue_to_leader.put(req)
info=self.queue_recv.get()
#准备数据
self.s_num=info["value_num"]
self.value=info["value"]
self.acceptors=info["acceptors"]
###############################################
#
#处理报文
#
###############################################
def processMsg(self,var):
#如果是启动命令,启动程序
if(var["type"]=="start"):
self.sendPropose()
#如果是acceptor过来的报文,解析报文
if(var["type"]=="accpting"):
#超时丢弃
if(time.time()-self.time_start > 5 ):
printStr("无效报文,丢弃...")
self.fail_list.append(var["accpetor"])
else:
if(var["result"]=="reject"):
self.reject+=1
if(var["result"]=="accept" ):
self.accept+=1
#修改决议为acceptor建议的决议
self.value=var["value"]
self.myvar={
"type":"proposing",
"Vnum":self.s_num,
"Value":var["value"],
"proposer":self.num
}
if(var["result"]=="chosen"):
self.chosen+=1
###############################################
#
#发送议案给表决者
#
###############################################
def sendPropose(self):
self.time_start=time.time()
self.start_propose=True
time.sleep(1/random.randrange(1,20))
printStr(self.name +"发出了一个决议,内容为:"+ str(self.value))
for acceptor in self.acceptors:
#生成决议,有5%概率发送失败
if(random.randrange(100) < 98):
self.myvar={
"type":"proposing",
"Vnum":self.s_num,
"Value":self.value,
"proposer":self.num,
"time":self.time_start
}
#printStr(self.name + " >>>>>" +str(var))
self.queue_send_list[acceptor].put(self.myvar)
else:
printStr(self.name + " >>>>> 发送决议失败")
time.sleep(1/random.randrange(1,10))
###############################################
#paxos 决议表决者acceptor
#负责接收proposer的决议并进行表决
###############################################
class Acceptor(threading.Thread):
def init(self, t_name, queue_from_proposer,queue_to_proposers,m_num):
threading.Thread.init(self, name=t_name)
self.queue_recv=queue_from_proposer
self.queue_to_proposers=queue_to_proposers
self.num=m_num
self.values={
“last”:0, #最后一次表决的议案编号
“value”:“”, #最后一次表决的议案的内容
“max”:0} #承诺的最低表决议案编号
def run(self):
while(True):
try:
var=self.queue_recv.get(False,1)
vars=self.processPropose(var)
#有2%的概率发送失败
if(random.randrange(100) < 98):
self.queue_to_proposers[var[“proposer”]].put(vars)
else:
printStr(self.name + " >>>>> 发送审批失败")
except Empty:
continue
###############################################
#
#处理议案提出者提出的决议
#
###############################################
def processPropose(self,value):
res={}
#如果从来没接收过议案,跟新自身议案
if(0self.values[“max”] and 0self.values[“last”]):
self.values[“max”]=value[“Vnum”]
self.values[“last”]=value[“Vnum”]
self.values[“value”]=value[“Value”]
res={
“type”:“accpting”,
“result”:“accept”,
“last”:0,
“value”:self.values[“value”],
“accpetor”:self.num,
“time”:value[“time”]}
else:
#如果收到的议案大于承诺最低表决的议案,同意并告知之前表决结果
if(self.values[“max”] < value[“Vnum”]):
self.values[“max”]=value[“Vnum”]
res={
“type”:“accpting”,
“result”:“accept”,
“last”:self.values[“last”],
“value”:self.values[“value”],
“accpetor”:self.num ,
“time”:value[“time”]}
else:
#如果收到的议案等于承诺最低表决的议案,完全同意议案,表决结束
if(self.values[“max”] == value[“Vnum”]):
self.values["last"]=value["Vnum"]
self.values["value"]=value["Value"]
res={
"type":"accpting",
"result":"chosen",
"last":self.values["last"],
"value":self.values["value"],
"accpetor":self.num,
"time":value["time"]
}
else:
#如果收到的议案小于承诺最低表决的议案,直接拒绝
res={
"type":"accpting",
"result":"reject",
"last":self.values["last"],
"value":self.values["value"],
"accpetor":self.num,
"time":value["time"]
}
return res
if name == ‘main’:
acceptors_num=20
proposers_num=5
q_to_acceptors=[]
q_to_proposers=[]
proposers=[]
acceptors=[]
q_leader_to_proposers=[]
q_to_leader=Queue()
for i in range(0,acceptors_num):
q_to_acceptors.append(Queue())
for i in range(0,proposers_num):
q_to_proposers.append(Queue())
q_leader_to_proposers.append(Queue())
ld=Leader("Leader",q_to_leader,q_to_proposers,acceptors_num)
ld.setDaemon(True)
ld.start()
for i in range(0,proposers_num):
proposers.append(Proposer("proposer"+str(i),
q_to_leader,
q_to_proposers[i],
q_to_acceptors,
i,
10))
for i in range(0,acceptors_num):
acceptors.append(Acceptor("Acceptor"+str(i),
q_to_acceptors[i],
q_to_proposers,
i))
for i in range(0,len(acceptors)):
acceptors[i].setDaemon(True)
acceptors[i].start()
for i in range(0,len(proposers)):
proposers[i].setDaemon(True)
proposers[i].start()
从管理者处获取数据…
从管理者处获取数据…
从管理者处获取数据…
从管理者处获取数据…
从管理者处获取数据…
proposer1发出了一个决议,内容为:[第一块数据由B进行更新]
proposer0发出了一个决议,内容为:[第一块数据由A进行更新]
proposer2发出了一个决议,内容为:[第一块数据由C进行更新]
proposer3发出了一个决议,内容为:[第一块数据由D进行更新]
🏛️ 4 Raft共识算法
另外一个出名的算法就是raft算法,该算法相比于paxos更加容易理解。Raft是一种用于替代Paxos的共识算法。相比于Paxos,Raft的目标是提供更清晰的逻辑分工使得算法本身能被更好地理解,同时它安全性更高,并能提供一些额外的特性。Raft能为在计算机集群之间部署有限状态机提供一种通用方法,并确保集群内的任意节点在某种状态转换上保持一致。
在Raft集群(Raft cluster)里,服务器可能会是这三种身份其中一个:领袖(leader)、追随者(follower),或是候选人(candidate)。在正常情况下只会有一个领袖,其他都是追随者。而领袖会负责所有外部的请求,如果不是领袖的机器收到时,请求会被导到领袖。通常领袖会借由固定时间发送消息,也就是“心跳(heartbeat)”,让追随者知道集群的领袖还在运作。而每个追随者都会设计超时机制(timeout),当超过一定时间没有收到心跳(通常是150 ms或300 ms),集群就会进入选举状态。
Raft将问题拆成数个子问题分开解决,让人更容易了解:
领袖选举(Leader Election)
记录复写(Log Replication)
安全性(Safety)
4.1 Raft算法流程
Raft集群包含多个服务器。在任何给定的时间,每个服务器都处于三种状态之一:领导者(leader)、追随者(follower)或候选人(candidate)。
follower是被动的:他们不发送任何请求,只是响应来自leader和candidate的请求。leader来处理所有来自客户端的请(如果一个客户端与follower进行通信,follower会将请求信息转发给leader)。candidate是用来选取新的领导人的。下图阐述了这些状态及它们之间的转换。
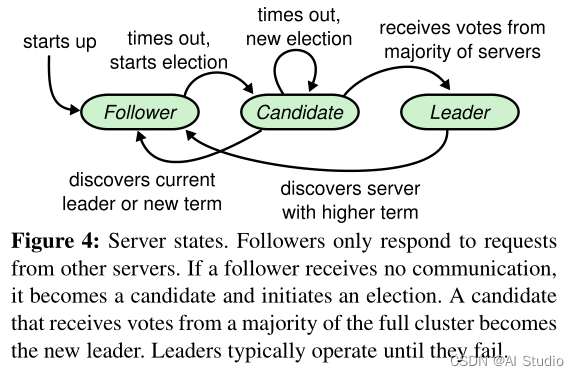
领袖选举
在起始算法或领袖死机、断线的时候,就需要选举出新的领袖。此时集群进入新的任期(英语:term)并开始选举,如果选举成功则新的领袖开始执行工作,反之则视此任期终止,开始新的任期并开始下一场选举。选举是由候选人发动的。当领袖的心跳超时的时候,追随者就会把自己的任期编号(英语:term counter)加一、宣告竞选、投自己一票、并向其他服务器拉票。每个服务器在每个任期只会投一票,固定投给最早拉票的服务器。如果候选人收到其他候选人的拉票、而且拉票的任期编号不小于自己的任期编号,就会自认落选,成为追随者,并认定来拉票的候选人为领袖。如果有候选人收到过半的选票就当选为新的领袖。如果超时仍没有选出新领袖,此任期自动终止,开始新的任期并开始下一场选举。Raft每个服务器的超时期限是随机的,这降低伺服务同时竞选的几率,也降低因两个竞选人得票都不过半而选举失败的几率。
记录复写
记录复写的责任在领袖身上。整个集群有个复写的状态机(英语:state machine),可执行外来的指令。领袖接收指令,将之写入自己记录中的新指令部分,然后把指令转发给追随者。如果有追随者没反应,领袖会不断重发指令、直到每个追随者都成功将新指令写入记录为止。当领袖收到过半追随者确认写入的消息,就会把指令视为已存储(英语:committed)。当追随者发现指令状态变成已存储,就会在其状态机上执行该指令。当领袖死机时,领袖的某些新指令可能还没复写到集群整体,造成集群的记录处于不一致的状态。新领袖会担起重返一致的责任,让每个追随者的记录都和它的一致,做法是:和每个追随者比对记录,找出两者一致的最后一笔指令,删除追随者之后的指令,把自己之后的指令拷贝给追随者。这个机制完成时,每个服务器的记录就会一致。
安全性
Raft保证以下的安全性:
选举安全性:每个任期最多只能选出一个领袖。
领袖附加性:领袖只会把新指令附加(英语:append)在记录尾端,不会改写或删除已有指令。
记录符合性:如果某个指令在两个记录中的任期和指令序号一样,则保证序号较小的指令也完全一样。
领袖完整性:如果某个指令在某个任期中存储成功,则保证存在于领袖该任期之后的记录中。
状态机安全性:如果某服务器在其状态机上执行了某个指令,其他服务器保证不会在同个状态上执行不同的指令。
4.2 代码实现
In [1]
import sys
sys.path.append(‘/home/aistudio/my’)
import enum
import logging
import typing
class Role(enum.Enum):
FOLLOWER = 0
CANDIDATE = 1
LEADER = 2
class VoteRequest(typing.NamedTuple):
node_id: int
current_term: int
log_length: int
last_term: int
class VoteResponse(typing.NamedTuple):
node_id: int
current_term: int
yea: bool
class LogRequest(typing.NamedTuple):
leader_id: int
term: int
ind: int
prev_log_term: int
commit_length: int
entries: typing.List[“LogEntry”]
class LogResponse(typing.NamedTuple):
node_id: int
term: int
ack_length: int
log_ok: bool
class BroadcastMessage(typing.NamedTuple):
data: typing.Any
RaftMessage = typing.Union[VoteRequest, VoteResponse, LogRequest, LogResponse]
class LogEntry(typing.NamedTuple):
message: BroadcastMessage
term: int # term of the leader at the time of broadcast
class Node:
def init(self, node_id):
# must be persisted
self.term = 0
self.voted_for = None
self._log: typing.List[LogEntry] = []
self.commit_length = 0
# maybe persisted?
self.node_id = node_id
# can be ephemeral
self.role = Role.FOLLOWER
self.leader = None
self.votes_received = set()
self.sent_length = {}
self.acked_length = {}
# election timer
@property
def log(self):
logging.debug(
"Accessing log on node %d with entries: %r", self.node_id, self._log
)
return self._log
def promote(self):
# Node suspects leader has failed, or election has timed out
self.term += 1
self.role = Role.CANDIDATE
self.voted_for = self.node_id
self.votes_received = {self.node_id}
last_term = self.log[-1].term if self.log else 0
req = VoteRequest(
self.node_id,
self.term,
len(self.log),
last_term,
)
send_all(req, self.node_id)
# start election timer
def recv_vote_request(self, msg: VoteRequest):
candidate_id, candidate_term, candidate_log_length, candidate_log_term = msg
# ensure the candidate's log isn't behind our own
log_term = self.log[-1].term if self.log else 0
log_ok = (candidate_log_term > log_term) or (
candidate_log_term == log_term and candidate_log_length >= len(self.log)
)
# ensure we only vote once per term
term_ok = (candidate_term > self.term) or (
candidate_term == self.term and self.voted_for in {candidate_id, None}
)
yea = log_ok and term_ok
if yea:
self.term = candidate_term
self.role = Role.FOLLOWER
self.voted_for = {candidate_id}
resp = VoteResponse(self.node_id, self.term, yea)
send(resp, candidate_id)
def recv_vote_response(self, msg: VoteResponse):
voter_id, voter_term, yea = msg
if self.role is Role.CANDIDATE and voter_term == self.term and yea:
# successful vote
self.votes_received.add(voter_id)
if quorum(len(self.votes_received)):
self.role = Role.LEADER
self.leader = self.node_id
# cancel_election_timer()
for follower in nodes.keys() - {self.node_id}:
self.sent_length[follower] = len(self.log)
self.acked_length[follower] = 0
self.replicate_log(follower)
elif voter_term > self.term:
self.term = voter_term
self.role = Role.FOLLOWER
self.voted_for = None
# cancel election timer
def broadcast(self, msg: BroadcastMessage):
# only the leader should be broadcasting messages
if self.role is Role.LEADER:
self.log.append(LogEntry(msg, self.term))
self.acked_length[self.node_id] = len(self.log)
for follower in nodes.keys() - {self.node_id}:
self.replicate_log(follower)
else:
nodes[self.leader].broadcast(msg)
# periodically replicate log across all nodes if you are the leader
def replicate_log(self, follower_id: int):
ind = self.sent_length[follower_id]
entries = self.log[ind:]
prev_log_term = self.log[ind - 1].term if ind > 0 else 0
req = LogRequest(
self.node_id, self.term, ind, prev_log_term, self.commit_length, entries
)
send(req, follower_id)
def recv_log_request(self, msg: LogRequest):
leader_id, term, log_length, log_term, leader_commit, entries = msg
if term > self.term:
self.term = term
self.voted_for = None
# log_length does NOT include the new entries
# check that we are at least up to date with the old entries
log_ok = len(self.log) >= log_length
if log_ok and log_length > 0:
# if the terms agree, then RAFT guarantees the logs are consistent up to log_length
log_ok = log_term == self.log[log_length - 1].term
ack = 0
log_ok = log_ok and term == self.term
if log_ok:
self.role = Role.FOLLOWER
self.leader = leader_id
self.append_entries(log_length, leader_commit, entries)
ack = log_length + len(entries)
resp = LogResponse(self.node_id, self.term, ack, log_ok)
send(resp, leader_id)
def append_entries(self, log_length, leader_commit, entries):
if entries and len(self.log) > log_length:
# if the logs are inconsistent, discard the entries
if self.log[log_length].term != entries[0].term:
self.log = self.log[:log_length]
if log_length + len(entries) > len(self.log):
self.log.extend(entries[len(self.log) - log_length :])
# deliver committed messages to the application
for entry in self.log[self.commit_length : leader_commit]:
self.deliver(entry.message)
self.commit_length = max(self.commit_length, leader_commit)
def deliver(self, msg: BroadcastMessage):
logging.info("Node %s received message %r!", self.node_id, msg)
def recv_log_response(self, msg: LogResponse):
follower_id, term, ack, success = msg
if term == self.term and self.role is Role.LEADER:
if success:
self.sent_length[follower_id] = ack
self.acked_length[follower_id] = ack
self.commit_log_entries()
elif self.sent_length[follower_id] > 0:
# if the logs are inconsistent, send more entries
self.sent_length[follower_id] -= 1
self.replicate_log(follower_id)
elif term > self.term:
self.term = term
self.role = Role.FOLLOWER
self.voted_for = None
def acks(self, ack_length: int):
# how many nodes have acknowledged at least ack_length entries?
return len({n for n in nodes if self.acked_length[n] >= ack_length})
def commit_log_entries(self):
ready = next(
filter(lambda l: quorum(self.acks(l)), range(len(self.log), 1, -1)), 0
)
if ready > self.commit_length and self.log[ready - 1].term == self.term:
# cannot commit a previous leader's log entries; leader must add at
# least one entry to the log before it can commit
for entry in self.log[self.commit_length : ready]:
self.deliver(entry.message)
self.commit_length = ready
def recv(self, msg: RaftMessage):
if isinstance(msg, VoteRequest):
self.recv_vote_request(msg)
elif isinstance(msg, VoteResponse):
self.recv_vote_response(msg)
elif isinstance(msg, LogRequest):
self.recv_log_request(msg)
elif isinstance(msg, LogResponse):
self.recv_log_response(msg)
else:
logging.error("Unknown message type %r", type(msg))
def quorum(n):
return n >= len(nodes) // 2 + 1
def send(msg: RaftMessage, node_id: int):
nodes[node_id].recv(msg)
def send_all(msg: RaftMessage, from_node_id: int):
for node_id in nodes.keys() - {from_node_id}:
nodes[node_id].recv(msg)
nodes = {}
import logging
import raft
logging.basicConfig(level=logging.INFO)
nodes = {i: Node(i) for i in range(5)}
#raft.nodes = nodes
for i, n in nodes.items():
print(i, n.role)
nodes[0].promote()
for i, n in nodes.items():
print(i, n.role)
for i, n in nodes.items():
print(i)
#n.broadcast(raft.BroadcastMessage({“node”: i}))
n.broadcast(BroadcastMessage({“node”: i}))
for i, n in nodes.items():
print(“Node”, i, “has log with entries”, *(entry.message for entry in n.log))
INFO:root:Node 0 received message BroadcastMessage(data={‘node’: 0})!
INFO:root:Node 0 received message BroadcastMessage(data={‘node’: 1})!
INFO:root:Node 3 received message BroadcastMessage(data={‘node’: 0})!
INFO:root:Node 3 received message BroadcastMessage(data={‘node’: 1})!
INFO:root:Node 4 received message BroadcastMessage(data={‘node’: 0})!
INFO:root:Node 4 received message BroadcastMessage(data={‘node’: 1})!
INFO:root:Node 1 received message BroadcastMessage(data={‘node’: 0})!
INFO:root:Node 1 received message BroadcastMessage(data={‘node’: 1})!
INFO:root:Node 2 received message BroadcastMessage(data={‘node’: 0})!
INFO:root:Node 2 received message BroadcastMessage(data={‘node’: 1})!
INFO:root:Node 0 received message BroadcastMessage(data={‘node’: 2})!
INFO:root:Node 3 received message BroadcastMessage(data={‘node’: 2})!
INFO:root:Node 4 received message BroadcastMessage(data={‘node’: 2})!
INFO:root:Node 1 received message BroadcastMessage(data={‘node’: 2})!
INFO:root:Node 2 received message BroadcastMessage(data={‘node’: 2})!
INFO:root:Node 0 received message BroadcastMessage(data={‘node’: 3})!
INFO:root:Node 3 received message BroadcastMessage(data={‘node’: 3})!
INFO:root:Node 4 received message BroadcastMessage(data={‘node’: 3})!
INFO:root:Node 1 received message BroadcastMessage(data={‘node’: 3})!
INFO:root:Node 2 received message BroadcastMessage(data={‘node’: 3})!
INFO:root:Node 0 received message BroadcastMessage(data={‘node’: 4})!
INFO:root:Node 3 received message BroadcastMessage(data={‘node’: 4})!
INFO:root:Node 4 received message BroadcastMessage(data={‘node’: 4})!
0 Role.FOLLOWER
1 Role.FOLLOWER
2 Role.FOLLOWER
3 Role.FOLLOWER
4 Role.FOLLOWER
0 Role.LEADER
1 Role.FOLLOWER
2 Role.FOLLOWER
3 Role.FOLLOWER
4 Role.FOLLOWER
0
1
2
3
4
Node 0 has log with entries BroadcastMessage(data={‘node’: 0}) BroadcastMessage(data={‘node’: 1}) BroadcastMessage(data={‘node’: 2}) BroadcastMessage(data={‘node’: 3}) BroadcastMessage(data={‘node’: 4})
Node 1 has log with entries BroadcastMessage(data={‘node’: 0}) BroadcastMessage(data={‘node’: 1}) BroadcastMessage(data={‘node’: 2}) BroadcastMessage(data={‘node’: 3}) BroadcastMessage(data={‘node’: 4})
Node 2 has log with entries BroadcastMessage(data={‘node’: 0}) BroadcastMessage(data={‘node’: 1}) BroadcastMessage(data={‘node’: 2}) BroadcastMessage(data={‘node’: 3}) BroadcastMessage(data={‘node’: 4})
Node 3 has log with entries BroadcastMessage(data={‘node’: 0}) BroadcastMessage(data={‘node’: 1}) BroadcastMessage(data={‘node’: 2}) BroadcastMessage(data={‘node’: 3}) BroadcastMessage(data={‘node’: 4})
Node 4 has log with entries BroadcastMessage(data={‘node’: 0}) BroadcastMessage(data={‘node’: 1}) BroadcastMessage(data={‘node’: 2}) BroadcastMessage(data={‘node’: 3}) BroadcastMessage(data={‘node’: 4})
🐱 5 未来的工作及总结
本部分介绍了区块链中两个最经典的共识算法,并利用python演示了其过程。可以发现Paxos 随机性使得没有一个节点有完整的最新的数据,因此其恢复流程非常复杂,需要同步节点间的历史记录;而 Raft 可以很容易地找到最新节点,从而加快恢复速度。当然乱序提交和日志的不连续也有好处,那就是写入并发性能会大大提高,从而提高吞吐量。
同时 Raft 和 Paxos 都使用了任期形式的 Leader。好处是性能很高,缺点是在切主的时候会拒绝服务,造成可用性下降。因此一般我们认为共识服务是 CP 类服务(CAP 理论)。但是有些团队为了提高可用性 ,转而采用基础的 Paxos 算法,比如微信的 PaxosStore 都是用了每轮一个单独的 Paxos 这种策略。
与此同时,接下来我们将进一步对区块链的算法和实现方式进行更详细的介绍:
进一步讲解BTC中的POW算法
进一步完善其算法在实际领域的应用
有任何问题,欢迎评论区留言交流。

学大模型,用大模型上飞桨星河社区!每天8点V100G算力免费领!免费领取ERNIE 4.0 100w Token >>>
更多推荐



 0
0 0
0- 0



 已为社区贡献1436条内容
已为社区贡献1436条内容

所有评论(0)