
【实践】基于ERNIE实现9项GLUE任务
基于ERNIE实现9项GLUE任务
基于ERNIE实现GLUE各项任务
1. 实验内容
本实验将使用ERNIE对NLP领域中的经典任务GLUE数据集进行fine-tuning, GLUE数据集中包含多项子数据集,现整理如下:
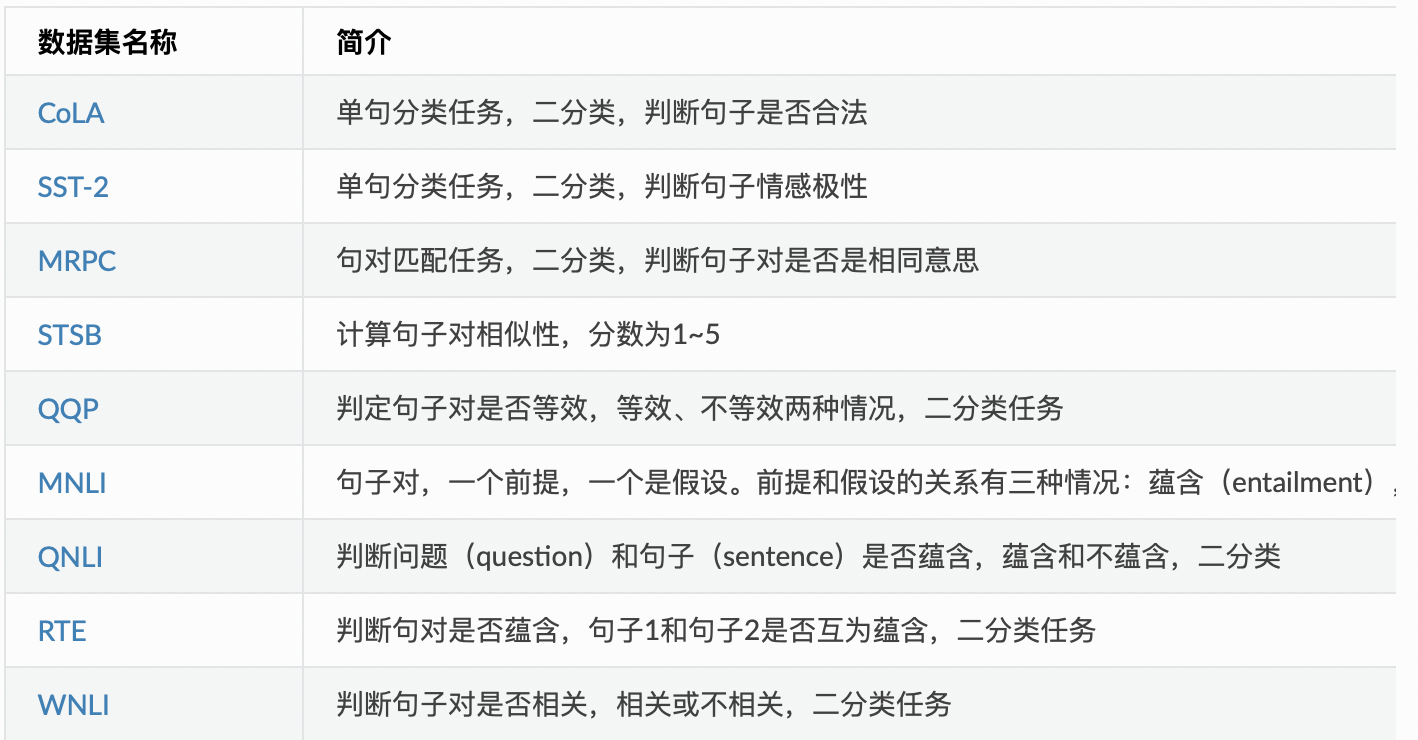
2. 数据加载
由于PaddleNLP中已经集成好了GLUE数据集,所以本实验直接调用PaddleNLP中的load_dataset API加载数据集。这里我们将定一个函数load_glue_sub_data,其将用来帮助我们方便的加载GLUE各个子项数据集。
另外,我们整理了GLUE数据集中各个子项任务的类型glue_task_type,以及分类的标签数量glue_task_num_labels。
import random
import numpy as np
from functools import partial
from paddlenlp.data import Stack, Tuple, Pad
from utils.data_processor import convert_example, create_dataloader
import paddle
import paddlenlp
from paddlenlp.datasets import load_dataset
from paddlenlp.transformers import LinearDecayWithWarmup
glue_tasks = ["cola", "sst-2", "sts-b", "qqp", "mnli", "qnli", "rte", "wnli", "mrpc"]
glue_tasks_num_labels = {
"cola": 2,
"sst-2": 2,
"sts-b": 1,
"qqp": 2,
"mnli": 3,
"qnli": 2,
"rte": 2,
"wnli": 3,
"mrpc": 2
}
glue_task_type = {
"cola": "classification",
"sst-2": "classification",
"sts-b": "regression" ,
"qqp": "classification",
"mnli": "classification",
"qnli": "classification",
"rte": "classification",
"wnli": "classification",
"mrpc": "classification"
}
def load_glue_sub_data(name):
if name not in glue_tasks:
raise Exception("Name Error: name must in ", glue_tasks)
splits = ("train", "dev")
if name == "mnli":
splits = ("train", "dev_matched")
dataset = load_dataset("glue", name=name, splits=splits)
return dataset
# task_name = "wnli"
# train, dev, test = load_glue_sub_data(task_name)
# print(test[:2])
3. 模型构建
这里我们将构建基于ERNIE模型进行序列分类/回归的类ErnieForSequenceClassification,它主要接受两个参数ernie模型和num_class,其中num_class用于指定各个子项任务的类别数量,其中回归任务默认为1。
class ErnieForSequenceClassification(paddle.nn.Layer):
"""
Model for sentence (pair) classification task with ERNIE.
"""
def __init__(self, ernie, num_class=2, dropout=None):
super(ErnieForSequenceClassification, self).__init__()
self.num_class = num_class
self.ernie = ernie
self.dropout = paddle.nn.Dropout(dropout if dropout is not None else self.ernie.config["hidden_dropout_prob"])
self.classifier = paddle.nn.Linear(self.ernie.config["hidden_size"], num_class)
def forward(self, input_ids, token_type_ids=None, position_ids=None, attention_mask=None):
_, pooled_output = self.ernie(input_ids, token_type_ids=token_type_ids, position_ids=position_ids, attention_mask=attention_mask)
pooled_output = self.dropout(pooled_output)
logits = self.classifier(pooled_output)
return logits
4. 训练配置
本节将进行设置模型训练需要的一些环境,包括超参数的定义,训练数据dataloader的构造,模型实例化,优化器的指定等等内容。其中超参定义时,我们针对某些参数,比如learning_rate,可根据不同子项任务进行调整。相应代码如下。
def set_seed(seed):
"""sets random seed"""
random.seed(seed)
np.random.seed(seed)
paddle.seed(seed)
# 定义任务参数
task_name = "cola"
model_name = "ernie-2.0-en"
# 定义超参数
epochs={
"cola":3,
"sst-2":4,
"sts-b":3,
"qqp":3,
"mnli":3,
"qnli":4,
"rte":4,
"wnli":4,
"mrpc":4
}
learning_rate={
"cola":3e-5,
"sst-2":2e-5,
"sts-b":5e-5,
"qqp":3e-5,
"mnli":3e-5,
"qnli":2e-5,
"rte":2e-5,
"wnli":2e-5,
"mrpc":3e-5
}
batch_size=32
warmup_proportion = 0.1
weight_decay = 0.01
max_seq_length= 128
# 设置环境
set_seed(0)
paddle.set_device("gpu:0")
# 加载和处理数据
train_ds, dev_ds = load_glue_sub_data(task_name)
tokenizer = paddlenlp.transformers.ErnieTokenizer.from_pretrained(model_name)
trans_func = partial(convert_example, task_name=task_name, tokenizer=tokenizer, max_seq_length=max_seq_length)
batchify_fn = lambda samples, fn=Tuple(
Pad(axis=0, pad_val=tokenizer.pad_token_type_id), # input
Pad(axis=0, pad_val=tokenizer.pad_token_type_id), # segment
Stack(dtype="int64") if glue_task_type[task_name]=="classification" else Stack(dtype="float32") # label
): [data for data in fn(samples)]
train_data_loader = create_dataloader(train_ds, mode="train", batch_size=batch_size[task_name], batchify_fn=batchify_fn, trans_fn=trans_func)
dev_data_loader = create_dataloader(dev_ds, mode="dev", batch_size=batch_size[task_name], batchify_fn=batchify_fn, trans_fn=trans_func)
# 模型实例化
ernie_model = paddlenlp.transformers.ErnieModel.from_pretrained(model_name)
model = ErnieForSequenceClassification(ernie_model, num_class=glue_tasks_num_labels[task_name])
# 设置lr_scheduler
num_training_steps = len(train_data_loader) * epochs[task_name]
lr_scheduler = LinearDecayWithWarmup(learning_rate[task_name], num_training_steps, warmup_proportion)
optimizer = paddle.optimizer.AdamW(
learning_rate=lr_scheduler,
parameters=model.parameters(),
weight_decay=weight_decay,
apply_decay_param_fun=lambda x: x in [
p.name for n, p in model.named_parameters()
if not any(nd in n for nd in ["bias", "norm"])
])
100%|██████████| 369/369 [00:00<00:00, 5040.16it/s]
[2021-08-19 11:27:41,116] [ INFO] - Downloading vocab.txt from https://paddlenlp.bj.bcebos.com/models/transformers/ernie_v2_base/vocab.txt
100%|██████████| 227/227 [00:00<00:00, 4079.07it/s]
[2021-08-19 11:27:41,265] [ INFO] - Downloading https://paddlenlp.bj.bcebos.com/models/transformers/ernie_v2_base/ernie_v2_eng_base.pdparams and saved to /home/aistudio/.paddlenlp/models/ernie-2.0-en
[2021-08-19 11:27:41,267] [ INFO] - Downloading ernie_v2_eng_base.pdparams from https://paddlenlp.bj.bcebos.com/models/transformers/ernie_v2_base/ernie_v2_eng_base.pdparams
100%|██████████| 427692/427692 [00:06<00:00, 68215.99it/s]
5. 模型训练与评估
在以上训练环境准备完成之后,我们就可以进行开始训练了,其中在训练过程中,每训练1轮,使用开发集进行评估一次。相关代码如下。
import paddle.nn.functional as F
from utils.metrics import compute_metrics
@paddle.no_grad()
def evaluate(model, data_loader, task_type="classification"):
model.eval()
losses = []
preds = None
out_labels = None
for batch in data_loader:
input_ids, token_type_ids, labels = batch
logits = model(input_ids, token_type_ids)
if task_type == "classification":
loss = F.cross_entropy(logits, labels)
losses.append(loss.numpy())
if preds is None:
preds = np.argmax(logits.detach().numpy(), axis=1).reshape([len(logits), 1])
out_labels = labels.detach().numpy()
else:
preds = np.append(preds, np.argmax(logits.detach().numpy(), axis=1).reshape([len(logits), 1]), axis=0)
out_labels = np.append(out_labels, labels.detach().numpy(), axis=0)
else:
loss = F.mse_loss(logits, labels)
losses.append(loss.numpy())
if preds is None:
preds = logits.detach().numpy()
out_labels = labels.detach().numpy()
else:
preds = np.append(preds, logits.detach().numpy(), axis=0)
out_labels = np.append(out_labels, labels.detach().numpy(), axis=0)
result = compute_metrics(task_name, preds.reshape(-1), out_labels.reshape(-1))
print("evaluate result: ",result)
model.train()
def do_train():
model.train()
for epoch in range(1, epochs[task_name]+1):
for step, batch in enumerate(train_data_loader, start=1):
input_ids, segment_ids, labels = batch
logits = model(input_ids, segment_ids)
if glue_task_type[task_name] == "classification":
loss = F.cross_entropy(logits, labels)
else:
loss = F.mse_loss(logits, labels)
if step%20 == 0:
print("epoch: {}/{}, step: {}/{}, loss: {} ".format(epoch, epochs[task_name], step, len(train_data_loader), loss.numpy()))
loss.backward()
optimizer.step()
lr_scheduler.step()
optimizer.clear_grad()
evaluate(model, dev_data_loader, task_type=glue_task_type[task_name])
# 开始模型训练
do_train()
epoch: 1/3, step: 20/268, loss: [0.13451196]
epoch: 1/3, step: 40/268, loss: [0.06055285]
epoch: 1/3, step: 60/268, loss: [0.02542446]
epoch: 1/3, step: 80/268, loss: [0.1956732]
epoch: 1/3, step: 100/268, loss: [0.0759825]
epoch: 1/3, step: 120/268, loss: [0.11043643]
epoch: 1/3, step: 140/268, loss: [0.0810241]
epoch: 1/3, step: 160/268, loss: [0.09277922]
epoch: 1/3, step: 180/268, loss: [0.02443065]
epoch: 1/3, step: 200/268, loss: [0.12841964]
epoch: 1/3, step: 220/268, loss: [0.1023003]
epoch: 1/3, step: 240/268, loss: [0.05106329]
epoch: 1/3, step: 260/268, loss: [0.11647318]
evaluate result: {'mcc': 0.6244666931728993}
epoch: 2/3, step: 20/268, loss: [0.2604182]
epoch: 2/3, step: 40/268, loss: [0.03504209]
epoch: 2/3, step: 60/268, loss: [0.15183952]
epoch: 2/3, step: 80/268, loss: [0.11418241]
epoch: 2/3, step: 100/268, loss: [0.12136559]
epoch: 2/3, step: 120/268, loss: [0.04706593]
epoch: 2/3, step: 140/268, loss: [0.01597433]
epoch: 2/3, step: 160/268, loss: [0.12209365]
epoch: 2/3, step: 180/268, loss: [0.04617871]
epoch: 2/3, step: 200/268, loss: [0.01696031]
epoch: 2/3, step: 220/268, loss: [0.10801802]
epoch: 2/3, step: 240/268, loss: [0.02620783]
epoch: 2/3, step: 260/268, loss: [0.11894499]
evaluate result: {'mcc': 0.6244666931728993}
epoch: 3/3, step: 20/268, loss: [0.02899554]
epoch: 3/3, step: 40/268, loss: [0.09603783]
epoch: 3/3, step: 60/268, loss: [0.1549092]
epoch: 3/3, step: 80/268, loss: [0.11537941]
epoch: 3/3, step: 100/268, loss: [0.06026918]
epoch: 3/3, step: 120/268, loss: [0.06986095]
epoch: 3/3, step: 140/268, loss: [0.06762329]
epoch: 3/3, step: 160/268, loss: [0.11107697]
epoch: 3/3, step: 180/268, loss: [0.13259125]
epoch: 3/3, step: 200/268, loss: [0.32414383]
epoch: 3/3, step: 220/268, loss: [0.01820294]
epoch: 3/3, step: 240/268, loss: [0.08801244]
epoch: 3/3, step: 260/268, loss: [0.27648443]
evaluate result: {'mcc': 0.6244666931728993}
恭喜,当你看到这里的时候,就已经完成了基于ERNIE进行GLUE数据集训练的内容。相信聪明的你一定有所收获。
如果同学们对系列教程感兴趣,想了解更多相关信息,请移步我们的官方github: awesome-DeepLearning,也欢迎各位同学点击Star,有大家的支持我们才会走得更远,提供更多优质资源以供学习。同时更多深度学习资料请参阅飞桨深度学习平台。

最后,也欢迎同学们加入我们的官方交流群。


学大模型,用大模型上飞桨星河社区!每天8点V100G算力免费领!免费领取ERNIE 4.0 100w Token >>>
更多推荐



 0
0 0
0- 0



 已为社区贡献1437条内容
已为社区贡献1437条内容

所有评论(0)