
基于PaddleDetection的中国交通标志图像分类任务
转自AI Studio,原文链接:基于PaddleDetection的中国交通标志图像分类任务 - 飞桨AI Studio【AI Workshop】基于PaddleDetection的中国交通标志图像分类任务1 引言1.1 项目简介对于交通标志识别系统,其核心作用就是可以准确并及时的识别道路交通标志信息获取当前路况以及行车环境,从而起到提醒和辅助驾驶员对道路信息的把控以及纠正错误交通行为的作用。传
转自AI Studio,原文链接:基于PaddleDetection的中国交通标志图像分类任务 - 飞桨AI Studio
【AI Workshop】基于PaddleDetection的中国交通标志图像分类任务
1 引言
1.1 项目简介
对于交通标志识别系统,其核心作用就是可以准确并及时的识别道路交通标志信息获取当前路况以及行车环境,从而起到提醒和辅助驾驶员对道路信息的把控以及纠正错误交通行为的作用。
传统的目标检测算法容易受到多种因素影响导致算法实现困难、识别精度低、识别速率慢等问题。随着深度学习的发展,人工智能的检测方法受到广泛关注与认可,可以有效地解决误检率高、速度慢等问题。
为解决交通标志识别问题,本项目使用飞桨场景应用开发套件PaddleDetecion中的PicoDet_LCNet模型进行训练,预测,并完成整体流程。本项目包括环境安装、数据准备、模型训练、模型评估、模型预测、模型导出、模型量化压缩、总结以及附录等主要部分。
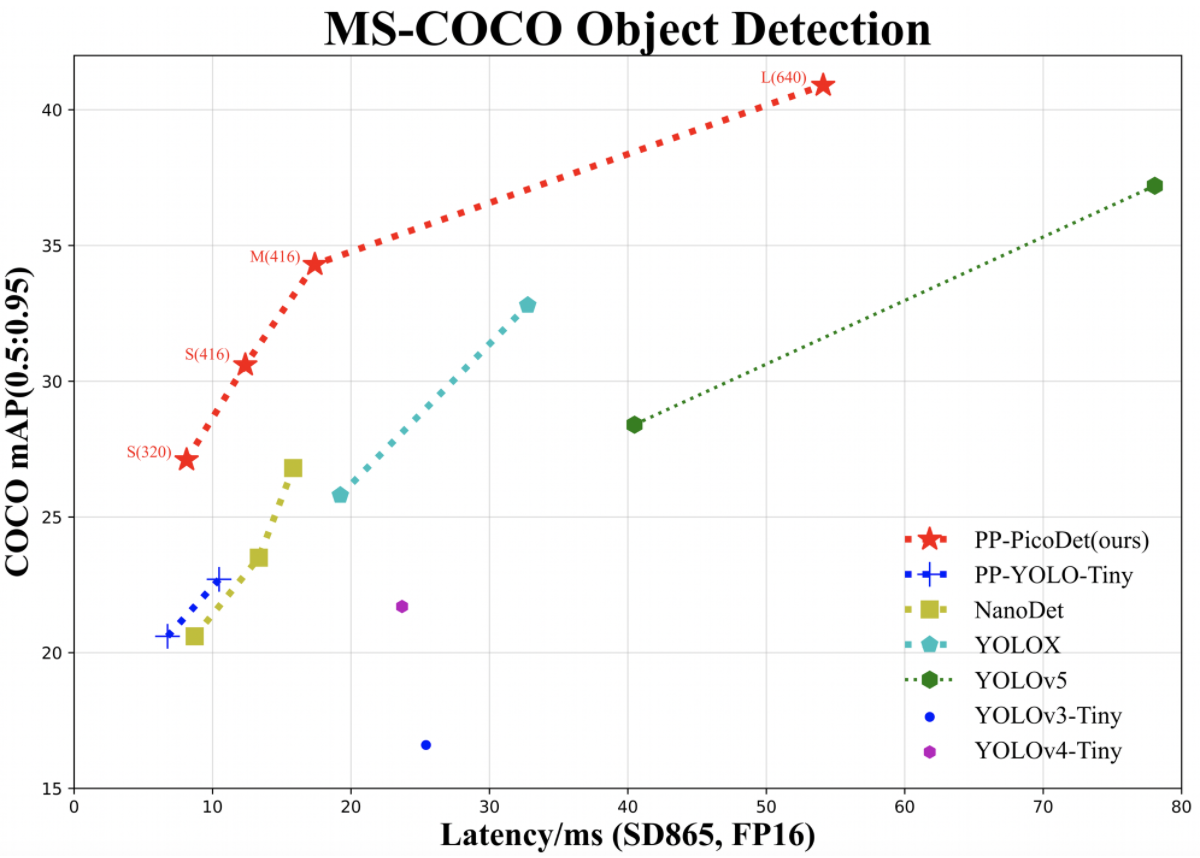
PP-PicoDet有着精度高(PicoDet-S仅1M参数量以内,416输入COCO mAP达到30.6),速度快(PicoDet-S-320在SD865上可达150FPS),部署友好(支持Paddle Inference、Paddle Lite,支持快速导出为ONNX格式,支持Python、C++、Android 部署)等特点。PicoDet具体的指标如下图所示:
1.2 数据集介绍
该数据集源自中国交通标志识别数据库。里加数据科学俱乐部成员已经探索了它,以便对卷积神经网络进行一些训练。
数据集由 58 个类别的 5998 张交通标志图像组成。每个图像都是单个交通标志的放大视图。注释提供图像属性(文件名、宽度、高度)以及图像和类别中的交通标志坐标(例如,限速 5 公里/小时),如下图所示。


该数据集由png图片以及annotations.csv文件构成。
annotations.csv构成:
file_name:包含交通标志的图像的文件名
width:图片宽度
height:图片高度
x1:边界矩形左上角X坐标
y1:边界矩形左上角Y坐标
x2:边界矩形右下角X坐标
y2:边界矩形右下角Y坐标
category:交通标志类别
2 环境安装
2.1 克隆PaddleDetection
PaddleDetection作为成熟的目标检测开发套件,提供了从数据准备、模型训练、模型评估、模型导出到模型部署的全流程。
- Github地址:GitHub - PaddlePaddle/PaddleDetection: Object Detection toolkit based on PaddlePaddle. It supports object detection, instance segmentation, multiple object tracking and real-time multi-person keypoint detection.
- Gitee地址:PaddleDetection: PaddleDetection的目的是为工业界和学术界提供丰富、易用的目标检测模型
In [3]
# 从github上克隆,若网速较慢也可以考虑从gitee上克隆
#! git clone https://github.com/PaddlePaddle/PaddleDetection
! git clone https://gitee.com/PaddlePaddle/PaddleDetectionCloning into 'PaddleDetection'... remote: Enumerating objects: 23983, done. remote: Counting objects: 100% (4453/4453), done. remote: Compressing objects: 100% (2058/2058), done. remote: Total 23983 (delta 3214), reused 3374 (delta 2387), pack-reused 19530 Receiving objects: 100% (23983/23983), 264.01 MiB | 10.12 MiB/s, done. Resolving deltas: 100% (17763/17763), done. Checking connectivity... done.
In [4]
! mv PaddleDetection ~/work/PaddleDetection2.2 安装依赖库
通过如下方式安装PaddleDetection依赖,并设置环境变量
In [ ]
%cd ~/work/PaddleDetection/
!pip install -r requirements.txt
%env PYTHONPATH=.:$PYTHONPATH
%env CUDA_VISIBLE_DEVICES=0通过如下命令验证是否安装成功
In [6]
! python ppdet/modeling/tests/test_architectures.pyWarning: import ppdet from source directory without installing, run 'python setup.py install' to install ppdet firstly W0522 11:24:04.259032 723 device_context.cc:447] Please NOTE: device: 0, GPU Compute Capability: 8.0, Driver API Version: 11.2, Runtime API Version: 11.2 W0522 11:24:04.262081 723 device_context.cc:465] device: 0, cuDNN Version: 8.2. ....... ---------------------------------------------------------------------- Ran 7 tests in 2.962s OK
3 数据准备
该数据集源自中国交通标志识别数据库。里加数据科学俱乐部成员已经探索了它,以便对卷积神经网络进行一些培训。
数据集由 58 个类别的 5998 张交通标志图像组成。每个图像都是单个交通标志的放大视图。注释提供图像属性(文件名、宽度、高度)以及图像和类别中的交通标志坐标(例如,限速 5 公里/小时)
目前PaddleDetection支持:COCO VOC WiderFace, MOT四种数据格式。因此,先解压数据集压缩包,再按照VOC格式将csv文件转化为xml。
3.1 解压数据集
In [7]
%cd ~/home/aistudio
In [8]
# 解压所挂载的数据集在同级目录下
!unzip -oq data/data107275/archive\(5\).zip -d data/TrafficSignsVoc3.2 数据集格式转换
本项目采用VOC格式数据。VOC数据格式的目标检测数据,是指每个图像文件对应一个同名的xml文件,xml文件中标记物体框的坐标和类别等信息。
├── Annotations
│ ├── 001_0001.xml
│ ├── 001_0002.xml
│ ...
├── pngImages
│ ├── 001_0001.png
│ ├── 001_0002.png
│ ...
├── label_list.txt
├── train.txt
└── valid.txt
label_list.txt:
0
1
...
57
train.txt/valid.txt:
./pngImages/014_0051.png ./Annotations/014_0051.xml
./pngImages/017_0031.png ./Annotations/017_0031.xml
./pngImages/015_0012.png ./Annotations/015_0012.xml
./pngImages/028_0025.png ./Annotations/028_0025.xml
...
xml文件中包含以下字段:
-
filename,表示图像名称。
<filename>001_0008.png</filename> -
size,表示图像尺寸。包括:图像宽度、图像高度、图像深度
<size> <width>118</width> <height>119</height> <depth>3</depth> </size> -
object字段,表示每个物体。包括
name: 目标物体类别名称pose: 关于目标物体姿态描述(非必须字段)truncated: 目标物体目标因为各种原因被截断(非必须字段)occluded: 目标物体是否被遮挡(非必须字段)difficult: 目标物体是否是很难识别(非必须字段)bndbox: 物体位置坐标,用左上角坐标和右下角坐标表示:xmin、ymin、xmax、ymax
按照以上所述VOC格式,通过运行以下脚本可以将csv文件转化为xml,并生成相应txt文件
In [ ]
import os
import numpy as np
import codecs
import pandas as pd
import json
from glob import glob
import cv2
import shutil
from sklearn.model_selection import train_test_split
# from IPython import embed
#1.标签路径
csv_file = "data/TrafficSignsVoc/annotations.csv"
saved_path = "data/TrafficSignsVoc/VOC2007/" #VOC格式数据的保存路径
image_save_path = "./pngImages"
image_raw_parh = "data/TrafficSignsVoc/images/"
#2.创建需要的文件夹
if not os.path.exists(saved_path + "Annotations"):
os.makedirs(saved_path + "Annotations")
if not os.path.exists(saved_path + "pngImages/"):
os.makedirs(saved_path + "pngImages/")
#if not os.path.exists(saved_path + "ImageSets/Main/"):
# os.makedirs(saved_path + "ImageSets/Main/")
#3.获取待处理文件
total_csv_annotations = {}
annotations = pd.read_csv(csv_file,header=None).values
for annotation in annotations:
key = annotation[0].split(os.sep)[-1]
value = np.array([annotation[1:]])
if key in total_csv_annotations.keys():
total_csv_annotations[key] = np.concatenate((total_csv_annotations[key],value),axis=0)
else:
total_csv_annotations[key] = value
# print(total_csv_annotations)
# for item in total_csv_annotations:
# print(item,item[1])
#4.读取标注信息,按VOC格式写入xml
for filename,label in total_csv_annotations.items():
if filename == 'file_name':
continue
height, width, channels = cv2.imread(image_raw_parh + filename).shape
with codecs.open(saved_path + "Annotations/"+filename.replace(".png",".xml"),"w","utf-8") as xml:
xml.write('<annotation>\n')
#xml.write('\t<folder>' + 'VOC2007' + '</folder>\n')
xml.write('\t<folder>' + 'pngImages' + '</folder>\n')
xml.write('\t<filename>' + filename + '</filename>\n')
#xml.write('\t<source>\n')
#xml.write('\t\t<database>The UAV autolanding</database>\n')
#xml.write('\t\t<annotation>UAV AutoLanding</annotation>\n')
#xml.write('\t\t<image>flickr</image>\n')
#xml.write('\t\t<flickrid>NULL</flickrid>\n')
#xml.write('\t</source>\n')
#xml.write('\t<owner>\n')
#xml.write('\t\t<flickrid>NULL</flickrid>\n')
#xml.write('\t\t<name>ZHH</name>\n')
#xml.write('\t</owner>\n')
xml.write('\t<size>\n')
xml.write('\t\t<width>'+ str(width) + '</width>\n')
xml.write('\t\t<height>'+ str(height) + '</height>\n')
xml.write('\t\t<depth>' + str(channels) + '</depth>\n')
xml.write('\t</size>\n')
xml.write('\t<segmented>0</segmented>\n')
if isinstance(label,float):
xml.write('</annotation>')
continue
for label_detail in label:
labels = label_detail
xmin = int(labels[2])
ymin = int(labels[3])
xmax = int(labels[4])
ymax = int(labels[5])
label_ = labels[-1]
if xmax <= xmin:
pass
elif ymax <= ymin:
pass
else:
xml.write('\t<object>\n')
xml.write('\t\t<name>'+label_+'</name>\n')
xml.write('\t\t<pose>Unspecified</pose>\n')
xml.write('\t\t<truncated>1</truncated>\n')
xml.write('\t\t<difficult>0</difficult>\n')
xml.write('\t\t<bndbox>\n')
xml.write('\t\t\t<xmin>' + str(xmin) + '</xmin>\n')
xml.write('\t\t\t<ymin>' + str(ymin) + '</ymin>\n')
xml.write('\t\t\t<xmax>' + str(xmax) + '</xmax>\n')
xml.write('\t\t\t<ymax>' + str(ymax) + '</ymax>\n')
xml.write('\t\t</bndbox>\n')
xml.write('\t</object>\n')
print(filename,xmin,ymin,xmax,ymax,labels)
xml.write('</annotation>')
#6.创建txt文件(可以不创建,后面用Paddlex划分数据集时生成相应的txt文件)
txtsavepath = saved_path
#ftrainval = open(txtsavepath+'/trainval.txt', 'w')
#ftest = open(txtsavepath+'/test.txt', 'w')
ftrain = open(txtsavepath+'/train.txt', 'w')
fval = open(txtsavepath+'/valid.txt', 'w')
flabel = open(txtsavepath+'/label_list.txt', 'w')
total_files = glob(saved_path+"./Annotations/*.xml")
total_files = [i.split("/")[-1].split(".xml")[0] for i in total_files]
#test_filepath = ""
#for file in total_files:
# ftrainval.write(file + "\n")
# 将图片复制到voc pngImages文件夹
for image in glob(image_raw_parh+"/*.png"):
shutil.copy(image,saved_path+image_save_path)
train_files,val_files = train_test_split(total_files,test_size=0.15,random_state=42)
for file in train_files:
ftrain.write("./pngImages/" + file + ".png" + " ./Annotations/" + file+ ".xml" + "\n")
#val
for file in val_files:
fval.write("./pngImages/" + file + ".png" + " ./Annotations/" + file+ ".xml" + "\n")
for i in range(58):
flabel.write(str(i) + "\n")
#ftrainval.close()
ftrain.close()
fval.close()
#ftest.close()
flabel.close()
In [10]
! mv data/TrafficSignsVoc/VOC2007 work/PaddleDetection/dataset/4 模型训练
4.1 修改配置文件
本项目使用的是work/PaddleDetection/configs/picodet/picodet_s_320_coco_lcnet.yml配置文件,该配置文件中涉及到的其他配置文件以及修改的具体配置如下所示:
(1) work/PaddleDetection/configs/picodet/picodet_s_320_coco_lcnet.yml
- 保存训练的轮数:
snapshot_epoch: 10
(2) work/PaddleDetection/configs/picodet/base/picodet_320_reader.yml
- 数据读取进程数量,根据本地算力资源调整:
worker_num: 6 - 根据显存大小调整:
batch_size: 64
(3) work/PaddleDetection/configs/picodet/base/optimizer_300e.yml
- 学习率:
base_lr: 0.04 - 训练轮数:
epoch: 300
(4) work/PaddleDetection/configs/datasets/voc.yml
- 数据集包含的类别数:
num_classes: 58 - 图片相对路径:
dataset_dir: dataset/VOC2007 anno_path: train.txtlabel_list: label_list.txt- 数据格式
metric: VOC
更多关于PaddleDetection的详细信息可参考30分钟快速上手PaddleDetection以及官方说明文档
In [11]
%cd /home/aistudio/work/PaddleDetection/home/aistudio/work/PaddleDetection
4.2 启动训练
通过指定visualDL可视化工具,对loss变化曲线可视化。仅需要指定 use_vdl 参数和 vdl_log_dir 参数即可。
In [ ]
# 选择配置开始训练。可以通过 -o 选项覆盖配置文件中的参数
!python tools/train.py -c configs/picodet/picodet_s_320_coco_lcnet.yml \
-o use_gpu=true \
-o pretrain_weights=https://paddledet.bj.bcebos.com/models/picodet_s_320_coco.pdparams \
--use_vdl=true \
--vdl_log_dir=vdl_dir/scalar \
--eval
# 指定配置文件
# 设置或更改配置文件里的参数内容
# 预训练权重
# 使用VisualDL记录数据
# 指定VisualDL记录数据的存储路径
# 边训练边测试4.3 训练可视化
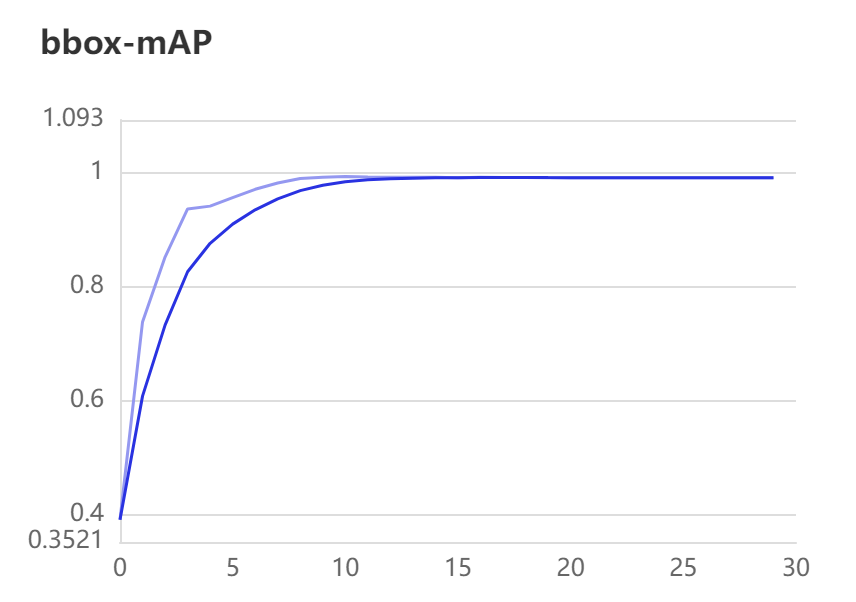
上一步训练过程中已开启VisualDL可视化工具,VisualDL记录数据的存储路径为work/PaddleDetection/vdl_dir/scalar,其训练可视化结果如下所示:
最终训练结果 mAP = 99.16%,训练效果很不错,达到应用级别效果。
5 模型评估
In [3]
!python tools/eval.py -c configs/picodet/picodet_s_320_coco_lcnet.yml \
-o weights=output/picodet_s_320_coco_lcnet/model_final.pdparams
# 指定模型配置文件
# 加载训练好的模型 Warning: import ppdet from source directory without installing, run 'python setup.py install' to install ppdet firstly W0522 20:14:56.671387 3034 device_context.cc:447] Please NOTE: device: 0, GPU Compute Capability: 8.0, Driver API Version: 11.2, Runtime API Version: 11.2 W0522 20:14:56.674559 3034 device_context.cc:465] device: 0, cuDNN Version: 8.2. [05/22 20:14:58] ppdet.data.source.voc WARNING: Found an invalid bbox in annotations: xml_file: dataset/VOC2007/./Annotations/002_0029.xml, x1: 59.0, y1: 37.0, x2: 42.0, y2: 42.0. [05/22 20:14:59] ppdet.data.source.voc WARNING: Found an invalid bbox in annotations: xml_file: dataset/VOC2007/./Annotations/002_1_0029.xml, x1: 59.0, y1: 37.0, x2: 42.0, y2: 42.0. [05/22 20:15:00] ppdet.utils.checkpoint INFO: Finish loading model weights: output/picodet_s_320_coco_lcnet/model_final.pdparams [05/22 20:15:01] ppdet.engine INFO: Eval iter: 0 [05/22 20:15:07] ppdet.engine INFO: Eval iter: 100 [05/22 20:15:08] ppdet.metrics.metrics INFO: Accumulating evaluatation results... [05/22 20:15:08] ppdet.metrics.metrics INFO: mAP(0.50, 11point) = 99.16% [05/22 20:15:08] ppdet.engine INFO: Total sample number: 900, averge FPS: 118.6191439734885
6 模型预测
6.1 开始预测
加载训练好的模型,置信度阈值设置为0.5,执行下行命令对验证集或测试集图片进行预测,此处挑选了一张验证集图片进行预测,并输出预测后的结果到infer_output文件夹下。得到的预测结果如下所示:

In [4]
!python3.7 tools/infer.py -c configs/picodet/picodet_s_320_coco_lcnet.yml \
--infer_img=/home/aistudio/work/PaddleDetection/dataset/VOC2007/pngImages/005_0047.png \
--output_dir=infer_output/ \
--draw_threshold=0.5 \
-o weights=output/picodet_s_320_coco_lcnet/model_final
# 指定模型配置文件
# 测试图片
# 结果输出位置
# 置信度阈值
# 加载训练好的模型 Warning: import ppdet from source directory without installing, run 'python setup.py install' to install ppdet firstly W0522 20:15:19.818154 5057 device_context.cc:447] Please NOTE: device: 0, GPU Compute Capability: 8.0, Driver API Version: 11.2, Runtime API Version: 11.2 W0522 20:15:19.821303 5057 device_context.cc:465] device: 0, cuDNN Version: 8.2. [05/22 20:15:22] ppdet.utils.checkpoint INFO: Finish loading model weights: output/picodet_s_320_coco_lcnet/model_final.pdparams 100%|█████████████████████████████████████████████| 1/1 [00:02<00:00, 2.23s/it] [05/22 20:15:24] ppdet.engine INFO: Detection bbox results save in infer_output/005_0047.png
6.2 可视化预测图片
In [6]
import cv2
import matplotlib.pyplot as plt
import numpy as np
image = cv2.imread('infer_output/005_0047.png')
plt.figure(figsize=(8,8))
plt.imshow(cv2.cvtColor(image, cv2.COLOR_BGR2RGB))
plt.show()
<Figure size 576x576 with 1 Axes>
7 模型导出
将模型进行导成部署需要的模型格式。 执行下面命令,即可导出模型。
预测模型会导出到inference_model/目录下,包括model.pdmodel、model.pdiparams、model.pdiparams.info和infer_cfg.yml四个文件,分别表示模型的网络结构、模型权重、模型权重名称和模型的配置文件(包括数据预处理参数等)的流程配置文件。
In [7]
!python tools/export_model.py \
-c configs/picodet/picodet_s_320_coco_lcnet.yml \
-o weights=output/picodet_s_320_coco_lcnet/model_final.pdparams \
--output_dir=inference_modelWarning: import ppdet from source directory without installing, run 'python setup.py install' to install ppdet firstly [05/22 20:16:39] ppdet.utils.checkpoint INFO: Finish loading model weights: output/picodet_s_320_coco_lcnet/model_final.pdparams [05/22 20:16:39] ppdet.engine INFO: Export inference config file to inference_model/picodet_s_320_coco_lcnet/infer_cfg.yml W0522 20:16:43.261752 5477 device_context.cc:447] Please NOTE: device: 0, GPU Compute Capability: 8.0, Driver API Version: 11.2, Runtime API Version: 11.2 W0522 20:16:43.261806 5477 device_context.cc:465] device: 0, cuDNN Version: 8.2. [05/22 20:16:45] ppdet.engine INFO: Export model and saved in inference_model/picodet_s_320_coco_lcnet
8 模型压缩
Paddle提供了模型压缩库PaddleSlim,是一个专注于深度学习模型压缩的工具库,提供剪裁、量化、蒸馏、和模型结构搜索等模型压缩策略,帮助用户快速实现模型的小型化。更多PaddleSlim使用教程请参考PaddleSlim
在检测中用到比较多的是量化训练,不仅可以减小体积,还能提升预测速度。
使用PaddleSlim量化训练,需要修改work/PaddleDetection/configs/slim/quant/picodet_s_quant.yml量化配置文件,将pretrain_weights参数改为量化前训练好的模型路径。
注意:如果模型报错,适当调小picodet_s_quant.yml文件中的batch_size
8.1 环境安装
In [ ]
# 安装相关包
! pip install paddleslim8.2 开始量化训练
量化训练轮数设定为50轮
In [ ]
!python tools/train.py \
-c configs/picodet/picodet_s_320_coco_lcnet.yml \
--slim_config configs/slim/quant/picodet_s_quant.yml
# -c: 指定模型配置文件
# --slim_config: 量化配置文件8.3 量化后模型评估
经量化训练后,模型的mAP(0.50, 11point) = 98.93%
In [14]
# 量化训练结束,同上可进行模型评估,只是需要多增加slim_config
!python tools/eval.py -c configs/picodet/picodet_s_320_coco_lcnet.yml \
--slim_config configs/slim/quant/picodet_s_quant.yml \
-o weights=output/picodet_s_quant/model_finalWarning: import ppdet from source directory without installing, run 'python setup.py install' to install ppdet firstly W0522 22:17:48.955442 60339 device_context.cc:447] Please NOTE: device: 0, GPU Compute Capability: 8.0, Driver API Version: 11.2, Runtime API Version: 11.2 W0522 22:17:48.958680 60339 device_context.cc:465] device: 0, cuDNN Version: 8.2. [05-22 22:17:51 MainThread @logger.py:242] Argv: tools/eval.py -c configs/picodet/picodet_s_320_coco_lcnet.yml --slim_config configs/slim/quant/picodet_s_quant.yml -o weights=output/picodet_s_quant/model_final [05-22 22:17:51 MainThread @utils.py:79] WRN paddlepaddle version: 2.2.2. The dynamic graph version of PARL is under development, not fully tested and supported [05/22 22:17:53] ppdet.utils.checkpoint INFO: Finish loading model weights: output/picodet_s_quant/model_final.pdparams [05/22 22:17:53] ppdet.data.source.voc WARNING: Found an invalid bbox in annotations: xml_file: dataset/VOC2007/./Annotations/002_0029.xml, x1: 59.0, y1: 37.0, x2: 42.0, y2: 42.0. [05/22 22:17:53] ppdet.data.source.voc WARNING: Found an invalid bbox in annotations: xml_file: dataset/VOC2007/./Annotations/002_1_0029.xml, x1: 59.0, y1: 37.0, x2: 42.0, y2: 42.0. [05/22 22:17:56] ppdet.engine INFO: Eval iter: 0 [05/22 22:18:06] ppdet.engine INFO: Eval iter: 100 [05/22 22:18:07] ppdet.metrics.metrics INFO: Accumulating evaluatation results... [05/22 22:18:07] ppdet.metrics.metrics INFO: mAP(0.50, 11point) = 98.93% [05/22 22:18:07] ppdet.engine INFO: Total sample number: 900, averge FPS: 65.4153563662017
8.4 量化后模型预测
加载量化训练好的模型,置信度阈值设置为0.5,此处选取了一张图片进行预测。执行下行命令对验证集或测试集图片进行预测,将预测结果输出在work/PaddleDetection/slim_infer_output文件夹下,如下图所示:

In [ ]
!python3.7 tools/infer.py -c configs/picodet/picodet_s_320_coco_lcnet.yml \
--infer_img=/home/aistudio/work/PaddleDetection/dataset/VOC2007/pngImages/054_0020.png \
--output_dir=slim_infer_output/ \
--draw_threshold=0.5 \
--slim_config configs/slim/quant/picodet_s_quant.yml \
-o weights=output/picodet_s_quant/model_final
# 指定模型配置文件
# 测试图片
# 结果输出位置
# 置信度阈值
# 指定量化模型配置文件
# 加载训练好的模型 8.5 可视化预测图片
In [8]
import cv2
import matplotlib.pyplot as plt
import numpy as np
image = cv2.imread('slim_infer_output/0.png')
plt.figure(figsize=(8,8))
plt.imshow(cv2.cvtColor(image, cv2.COLOR_BGR2RGB))
plt.show()
<Figure size 576x576 with 1 Axes>
8.6 量化后模型导出
导出后的模型保存在:inference_model/picodet_s_quant
In [ ]
# 模型导出
!python tools/export_model.py \
-c configs/picodet/picodet_s_320_coco_lcnet.yml \
--slim_config configs/slim/quant/picodet_s_quant.yml \
-o weights=output/picodet_s_quant/model_final.pdparams \
--output_dir=inference_model
# 将inference模型配置转化为json格式
!python deploy/lite/convert_yml_to_json.py inference_model/picodet_s_quant/infer_cfg.ymlIn [17]
# 查看模型大小
! ls -lh inference_model/picodet_s_quanttotal 11M -rw-r--r-- 1 aistudio aistudio 1.8K May 22 22:18 infer_cfg.json -rw-r--r-- 1 aistudio aistudio 868 May 22 22:18 infer_cfg.yml -rw-r--r-- 1 aistudio aistudio 4.7M May 22 22:18 model.pdiparams -rw-r--r-- 1 aistudio aistudio 166K May 22 22:18 model.pdiparams.info -rw-r--r-- 1 aistudio aistudio 5.2M May 22 22:18 model.pdmodel
9 附录配置文件代码
In [ ]
# picodet_320_reader.yml
# 数据读取进程数量,根据本地算力资源调整
worker_num: 6
eval_height: &eval_height 320
eval_width: &eval_width 320
eval_size: &eval_size [*eval_height, *eval_width]
TrainReader:
sample_transforms:
- Decode: {}
- RandomCrop: {}
- RandomFlip: {prob: 0.5}
- RandomDistort: {}
batch_transforms:
- BatchRandomResize: {target_size: [256, 288, 320, 352, 384], random_size: True, random_interp: True, keep_ratio: False}
- NormalizeImage: {is_scale: true, mean: [0.485,0.456,0.406], std: [0.229, 0.224,0.225]}
- Permute: {}
- PadGT: {}
# 根据显存大小调整
batch_size: 64
shuffle: true
drop_last: true
EvalReader:
sample_transforms:
- Decode: {}
- Resize: {interp: 2, target_size: *eval_size, keep_ratio: False}
- NormalizeImage: {is_scale: true, mean: [0.485,0.456,0.406], std: [0.229, 0.224,0.225]}
- Permute: {}
batch_transforms:
- PadBatch: {pad_to_stride: 32}
batch_size: 8
shuffle: false
TestReader:
inputs_def:
image_shape: [1, 3, *eval_height, *eval_width]
sample_transforms:
- Decode: {}
- Resize: {interp: 2, target_size: *eval_size, keep_ratio: False}
- NormalizeImage: {is_scale: true, mean: [0.485,0.456,0.406], std: [0.229, 0.224,0.225]}
- Permute: {}
batch_size: 1
In [ ]
# picodet_s_320_cco_lcnet.yml
_BASE_: [
'../datasets/voc.yml',
'../runtime.yml',
'_base_/picodet_v2.yml',
'_base_/optimizer_300e.yml',
'_base_/picodet_320_reader.yml',
]
pretrain_weights: https://paddle-imagenet-models-name.bj.bcebos.com/dygraph/legendary_models/PPLCNet_x0_75_pretrained.pdparams
weights: output/picodet_s_320_coco/best_model
find_unused_parameters: True
use_ema: true
epoch: 300
# 保存训练的轮数
snapshot_epoch: 10
LCNet:
scale: 0.75
feature_maps: [3, 4, 5]
LCPAN:
out_channels: 96
PicoHeadV2:
conv_feat:
name: PicoFeat
feat_in: 96
feat_out: 96
num_convs: 2
num_fpn_stride: 4
norm_type: bn
share_cls_reg: True
use_se: True
feat_in_chan: 96
TrainReader:
batch_size: 64
LearningRate:
base_lr: 0.04
schedulers:
- !CosineDecay
max_epochs: 300
- !LinearWarmup
start_factor: 0.1
steps: 300
In [ ]
# voc.yml
metric: VOC
map_type: 11point
# 种类
num_classes: 58
TrainDataset:
!VOCDataSet
# 图片相对路径
dataset_dir: dataset/VOC2007
anno_path: train.txt
label_list: label_list.txt
data_fields: ['image', 'gt_bbox', 'gt_class', 'difficult']
EvalDataset:
!VOCDataSet
dataset_dir: dataset/VOC2007
anno_path: valid.txt
label_list: label_list.txt
data_fields: ['image', 'gt_bbox', 'gt_class', 'difficult']
TestDataset:
!ImageFolder
anno_path: dataset/VOC2007/label_list.txt
In [ ]
# optimizer_300e.yml
epoch: 300
LearningRate:
# 学习率 1/8
base_lr: 0.04
schedulers:
- !CosineDecay
max_epochs: 300
- !LinearWarmup
start_factor: 0.1
steps: 300
OptimizerBuilder:
optimizer:
momentum: 0.9
type: Momentum
regularizer:
factor: 0.00004
type: L2
In [ ]
# picodet_s_quant.yml
pretrain_weights: output/picodet_s_320_coco_lcnet/model_final.pdparams
slim: QAT
QAT:
quant_config: {
'activation_preprocess_type': 'PACT',
'weight_quantize_type': 'channel_wise_abs_max', 'activation_quantize_type': 'moving_average_abs_max',
'weight_bits': 8, 'activation_bits': 8, 'dtype': 'int8', 'window_size': 10000, 'moving_rate': 0.9,
'quantizable_layer_type': ['Conv2D', 'Linear']}
print_model: False
epoch: 50
LearningRate:
base_lr: 0.001
schedulers:
- !PiecewiseDecay
gamma: 0.1
milestones:
- 30
- 40
- !LinearWarmup
start_factor: 0.
steps: 100
TrainReader:
batch_size: 96
10 总结
-
经模型评估,对于经过300轮训练的模型效果为:mAP(0.50, 11point) = 99.16%。
-
经量化训练后,模型的效果为:mAP(0.50, 11point) = 98.93%
-
PaddleDetecion中的PicoDet_LCNet模型上手方便,各种模型的配置文件可根据自己需求去修改调整,可复用程度高,因此大大提高了效率。当然,PaddleDetection套件中还包含了很多种类的模型,提供多种主流目标检测、实例分割、跟踪、关键点检测算法,能够满足大大小小的开发需求,从而更好完成端到端全开发流程。
-
本次【AI Workshop】活动受益匪浅,不仅小组成员共同协作感受到了深度学习的乐趣,也对PicoDet有了更熟悉的了解,为今后的学习研究打下良好的基础。同时要感谢本项目的导师
高睿的细心指导和答疑解惑,使得复杂的问题也能够很轻松的化解,有问必答,亦师亦友。
-
队伍名称:Zachery&Susie勇往直前
-
学校:北京科技大学、同济大学、大连海洋大学、东北农业大学
-
再次感谢本项目导师
高睿的悉心指导

学大模型,用大模型上飞桨星河社区!每天8点V100G算力免费领!免费领取ERNIE 4.0 100w Token >>>
更多推荐



 0
0 0
0- 0



 已为社区贡献1436条内容
已为社区贡献1436条内容

所有评论(0)