
『图像去噪』基于ADnet的高斯噪声去除
该项目是对论文《Attention-guided CNN for image denoising》的全流程复现,主要包括网络结构实现及高斯噪声去除的效果展示。
基于ADnet的高斯噪声去除
目前AIstudio还没有对模拟高斯噪声进行去除的项目,本项目基于ADNet开源代码实现一个去噪网络的全流程复现。
ADNet发表于2020年Neural Networks期刊

0.摘要
高斯噪声的去除一直图像恢复领域的重点问题,图像的噪声严重干扰下游任务的性能。由于深度学习的优越性,卷积神经网络被引入该领域进行噪声的去除。
但随着网络层数的加深,浅层网络的影响越来越弱,由此提出一个基于注意力的卷积神经网络ADNet,包括稀疏块 (SB)、特征增强块 (FEB)、注意块 (AB) 和重建块 (RB)。
1.创新点
- (1)提出了由扩张卷积和普通卷积组成的SB,用于减小深度以提高去噪性能和效率。
- (2)FEB使用长路径融合来自浅层和深层的信息,增强去噪模型的表达能力。
- (3)AB用于从给定的噪点图像中深度挖掘隐藏在复杂背景中的噪声信息,例如真实的噪点图像和盲降噪。
- (4)FEB与AB集成在一起,可以提高效率并降低训练降噪模型的复杂度。
- (5)在六个基准数据集上,ADNet在合成和真实噪点图像以及盲降噪方面均优于最新技术(2020)。
2.数据集
使用Waterloo Exploration_Gray数据集,该数据用于图像质量评估(IQA)任务。
本数据集包括4259张灰度图像,数据为BMP格式的自然场景图像。适用于图像超分辨率,图像去噪等任务。
对数据集进行处理切分,最终生成1,348,480个数据块作为训练数据集
图像处理中常用SET68(包含68张灰度自然图像),SET12(包含12张灰度自然图像)进行模型验证。
本项目对SET68数据集进行切分生成验证数据集,SET12数据集不切分作为测试数据集。

# 安装需要的库函数
!pip install scikit_image==0.15.0
# 导入需要使用的包
import math
import numpy as np
import skimage
from skimage.measure.simple_metrics import compare_psnr
import cv2
import os
import random
import h5py
import cv2
import glob
from PIL import Image
import matplotlib.pyplot as plt
import paddle
from paddle.distribution import Normal
import warnings
warnings.filterwarnings("ignore")
## 解压数据集,仅制作训练数据时运行
# 此处演示tar.gz 数据集的解压缩命令,制作数据后在work下生成h5就不用再运行
!tar -xzvf data/data123695/pristine_images_gray.tar.gz -C /home/aistudio/data/
# 解压验证集Set68 测试集Set12
!unzip -o /home/aistudio/work/SET.zip -d /home/aistudio/work/
'\n## 解压数据集,仅制作训练数据时运行\n# 此处演示tar.gz 数据集的解压缩命令\n!tar -xzvf data/data123695/pristine_images_gray.tar.gz -C /home/aistudio/data/\n# 解压验证集Set68 测试集Set12\n!unzip -o /home/aistudio/work/SET.zip -d /home/aistudio/work/\n'
3.数据预处理
处理图像数据集时,数据读取速度是模型训练的关键因素。大量的时间往往被用于读取数据,直接将数据全部读取到内存中对内存的压力又太大。
本项目通过将在线数据增强修改为离线数据增强,重新制作h5数据集,显著增加了模型训练速度。
# 定义离线数据增强方法
def data_augmentation(image, mode):
out = np.transpose(image, (1,2,0))
if mode == 0:
# original
out = out
elif mode == 1:
# flip up and down
out = np.flipud(out)
elif mode == 2:
# rotate counterwise 90 degree
out = np.rot90(out)
elif mode == 3:
# rotate 90 degree and flip up and down
out = np.rot90(out)
out = np.flipud(out)
elif mode == 4:
# rotate 180 degree
out = np.rot90(out, k=2)
elif mode == 5:
# rotate 180 degree and flip
out = np.rot90(out, k=2)
out = np.flipud(out)
elif mode == 6:
# rotate 270 degree
out = np.rot90(out, k=3)
elif mode == 7:
# rotate 270 degree and flip
out = np.rot90(out, k=3)
out = np.flipud(out)
return np.transpose(out, (2,0,1))
离线数据生成
训练数据集使用伯克利分割数据集(BSD)的400幅大小为180 × 180的图像和滑铁卢勘探数据库的3859幅图像来训练高斯合成去噪模型。
图像的不同区域包含不同的详细信息,因此将训练噪声图像分成大小为50 × 50的1,348,480个小块,并对其进行数据增强,有助于促进更鲁棒的特征并提高训练去噪模型的效率;
## 制作数据集
# 最终训练集14GB 验证集42MB
def normalize(data):
return data/255.
def Im2Patch(img, win, stride=1):
k = 0
endc = img.shape[0]
endw = img.shape[1]
endh = img.shape[2]
patch = img[:, 0:endw-win+0+1:stride, 0:endh-win+0+1:stride]
TotalPatNum = patch.shape[1] * patch.shape[2]
Y = np.zeros([endc, win*win,TotalPatNum], np.float32)
for i in range(win):
for j in range(win):
patch = img[:,i:endw-win+i+1:stride,j:endh-win+j+1:stride]
Y[:,k,:] = np.array(patch[:]).reshape(endc, TotalPatNum)
k = k + 1
return Y.reshape([endc, win, win, TotalPatNum])
def prepare_data(patch_size, stride, aug_times=1):
'''
该函数用于将图像切成方块,并进行数据增强
patch_size: 图像块的大小,本项目50*50
stride: 步长,每个图像块的间隔
aug_times: 数据增强次数,默认从八种增强方式中选择一种
'''
# train
print('process training data')
scales = [1, 0.9, 0.8, 0.7] # 对数据进行随机放缩
files = glob.glob(os.path.join('data', 'pristine_images_gray', '*'))
files.sort()
h5f = h5py.File('work/train.h5', 'w')
train_num = 0
for i in range(len(files)):
img = cv2.imread(files[i])
h, w, c = img.shape
for k in range(len(scales)):
Img = cv2.resize(img, (int(h*scales[k]), int(w*scales[k])), interpolation=cv2.INTER_CUBIC)
Img = np.expand_dims(Img[:,:,0].copy(), 0)
Img = np.float32(normalize(Img))
patches = Im2Patch(Img, win=patch_size, stride=stride)
print("file: %s scale %.1f # samples: %d" % (files[i], scales[k], patches.shape[3]*aug_times))
for n in range(patches.shape[3]):
data = patches[:,:,:,n].copy()
h5f.create_dataset(str(train_num), data=data)
train_num += 1
for m in range(aug_times-1):
data_aug = data_augmentation(data, np.random.randint(1,8))
h5f.create_dataset(str(train_num)+"_aug_%d" % (m+1), data=data_aug)
train_num += 1
h5f.close()
# val
print('\nprocess validation data')
#files.clear()
files = glob.glob(os.path.join('work', 'Set68', '*.png'))
files.sort()
h5f = h5py.File('work/val.h5', 'w')
val_num = 0
for i in range(len(files)):
print("file: %s" % files[i])
img = cv2.imread(files[i])
img = np.expand_dims(img[:,:,0], 0)
img = np.float32(normalize(img))
h5f.create_dataset(str(val_num), data=img)
val_num += 1
h5f.close()
print('training set, # samples %d\n' % train_num)
print('val set, # samples %d\n' % val_num)
## 生成数据
prepare_data( patch_size=50, stride=40, aug_times=1)
'\nprepare_data( patch_size=50, stride=40, aug_times=1) \n'
4.定义数据读取类
import paddle
from paddle.io import Dataset
import random
import numpy as np
# 重写数据读取类
class DenoiseDataset(Dataset):
def __init__(self,mode = 'train',transform =None):
self.mode = mode
self.transforms = transform
# 选择前训练集和验证集
if self.mode == 'train':
h5f = h5py.File('work/train.h5', 'r')
else:
h5f = h5py.File('work/train.h5', 'r')
self.keys = list(h5f.keys())
random.shuffle(self.keys)
h5f.close()
def __getitem__(self, index):
if self.mode == 'train':
h5f = h5py.File('work/train.h5', 'r')
else:
h5f = h5py.File('work/train.h5', 'r')
key = self.keys[index]
data = np.array(h5f[key])
# data = np.transpose(data,(1,2,0))
if self.transforms:
data = self.transforms(data)
h5f.close()
return data
def __len__(self):
return len(self.keys)
数据读取可视化
dataset = DenoiseDataset(mode='train')
print('=============train dataset=============')
img = dataset[4]
img = np.squeeze(img)
imga = Image.fromarray(img*255)
#当要保存的图片为灰度图像时,灰度图像的 numpy 尺度是 [1, h, w]。需要将 [1, h, w] 改变为 [h, w]
print(img.shape)
plt.figure(figsize=(8, 8))
plt.xticks([]),plt.yticks([]),plt.imshow(imga)
=============train dataset=============
(50, 50)
(([], <a list of 0 Text xticklabel objects>),
([], <a list of 0 Text yticklabel objects>),
<matplotlib.image.AxesImage at 0x7ffa11ab5410>)
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-h1v66vCu-1642082146378)(output_11_2.png)]](https://i-blog.csdnimg.cn/blog_migrate/28ff7e52ed9d7f2066d9bacd5a25b34d.png)
4.定义评价指标
PSNR:Peak Signal to Noise Ratio,即峰值信噪比,是一种评价图像的客观标准。
SSIM:Structural Similarity,结构相似性,是一种衡量两幅图像相似度的指标。
# 定义辅助函数用于计算PSNR,SSIM
import numpy as np
from skimage.measure.simple_metrics import compare_psnr
import skimage
def batch_psnr_ssim(img, imclean, data_range):
r"""
Computes the PSNR along the batch dimension (not pixel-wise)
Args:
img: a `torch.Tensor` containing the restored image
imclean: a `torch.Tensor` containing the reference image
data_range: The data range of the input image (distance between
minimum and maximum possible values). By default, this is estimated
from the image data-type.
"""
img_cpu = img.cpu().numpy().astype(np.float32)
imgclean = imclean.cpu().numpy().astype(np.float32)
psnr = 0
ssim = 0
for i in range(img_cpu.shape[0]):
tclean = np.squeeze(imgclean[i, :, :, :])
timg = np.squeeze(img_cpu[i, :, :, :])
psnr += compare_psnr(tclean,timg, data_range=data_range)
ssim += skimage.measure.compare_ssim(tclean, timg, data_range=data_range)
return psnr/img_cpu.shape[0],ssim/img_cpu.shape[0]
5.定义ADNet模型
模型结构如图所示:
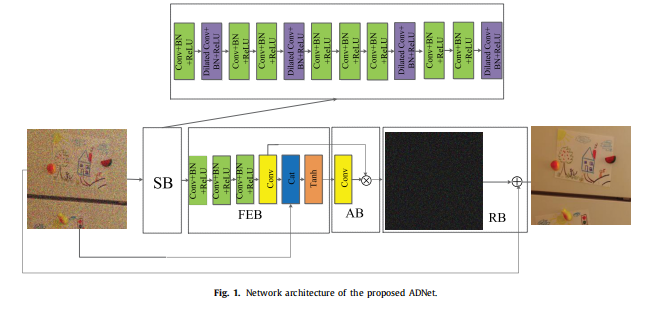
# 定义ADNet网络结构
import paddle
import paddle.nn as nn
class Conv_BN_Relu_first(nn.Layer):
def __init__(self,in_channels,out_channels,kernel_size,padding,groups,bias_attr):
super(Conv_BN_Relu_first,self).__init__()
kernel_size = 3
padding = 1
features = 64
groups =1
self.conv = nn.Conv2D(in_channels=channels, out_channels=features, kernel_size=kernel_size, padding=padding,groups=groups, bias_attr=False)
self.bn = nn.BatchNorm(features)
self.relu = nn.ReLU()
def forward(self,x):
return self.relu(self.bn(self.conv(x)))
class Conv_BN_Relu_other(nn.Layer):
def __init__(self,in_channels,out_channels,kernel_size,padding,groups,bias_attr):
super(Conv_BN_Relu_other,self).__init__()
kernel_size = 3
padding = 1
features = out_channels
groups =1
self.conv = nn.Conv2D(in_channels=in_channels, out_channels=features, kernel_size=kernel_size, padding=padding,groups=groups, bias_attr=False)
self.bn = nn.BatchNorm(features)
self.relu = nn.ReLU()
def forward(self,x):
return self.relu(self.bn(self.conv(x)))
class Conv(nn.Layer):
def __init__(self,in_channels,out_channels,kernel_size,padding,groups,bais):
super(Conv,self).__init__()
kernel_size = 3
padding = 1
features = 1
groups =1
self.conv = nn.Conv2D(in_channels=channels, out_channels=features, kernel_size=kernel_size, padding=padding,groups=groups, bias_attr=False)
def forward(self,x):
return self.conv(x)
class Self_Attn(nn.Layer):
def __init__(self,in_dim):
super(Self_Attn,self).__init__()
self.chanel_in = in_dim
self.query_conv = nn.Conv2D(in_channels=in_dim,out_channels=in_dim//8,kernel_size=1)
self.key_conv = nn.Conv2D(in_channels=in_dim,out_channels=in_dim//8,kernel_size=1)
self.value_conv = nn.Conv2D(in_channels=in_dim,out_channels=in_dim,kernel_size=1)
self.gamma=nn.Parameter(paddle.zeros(1))
self.softmax=nn.Softmax(dim=-1)
def forward(self,x):
m_batchsize, C, width,height = x.size()
proj_query = self.query_conv(x).view(m_batchsize,-1,width*height).transpose(0,2,1)
proj_key = self.key_conv(x).view(m_batchsize,-1,width*height)
print(proj_query.size())
print(proj_key.size())
print('5')
energy = paddle.bmm(proj_query,proj_key)
print('6')
#print energy.size()
attention = self.softmax(energy)
proj_value = self.value_conv(x).view(m_batchsize,-1,width*height)
print('1')
out = paddle.bmm(proj_value,attention.transpose(0,2,1))
print('2')
out = out.view(m_batchsize,C,width,height)
out = self.gamma*out + x
return out, attention
class ADNet(nn.Layer):
def __init__(self, channels, num_of_layers=15):
super(ADNet, self).__init__()
kernel_size = 3
padding = 1
features = 64
groups =1
layers = []
kernel_size1 = 1
self.conv1_1 = nn.Sequential(nn.Conv2D(in_channels=channels,out_channels=features,kernel_size=kernel_size,padding=padding,groups=groups,bias_attr=False),nn.BatchNorm(features),nn.ReLU())
self.conv1_2 = nn.Sequential(nn.Conv2D(in_channels=features,out_channels=features,kernel_size=kernel_size,padding=2,groups=groups,bias_attr=False,dilation=2),nn.BatchNorm(features),nn.ReLU())
self.conv1_3 = nn.Sequential(nn.Conv2D(in_channels=features,out_channels=features,kernel_size=kernel_size,padding=1,groups=groups,bias_attr=False),nn.BatchNorm(features),nn.ReLU())
self.conv1_4 = nn.Sequential(nn.Conv2D(in_channels=features,out_channels=features,kernel_size=kernel_size,padding=1,groups=groups,bias_attr=False),nn.BatchNorm(features),nn.ReLU())
self.conv1_5 = nn.Sequential(nn.Conv2D(in_channels=features,out_channels=features,kernel_size=kernel_size,padding=2,groups=groups,bias_attr=False,dilation=2),nn.BatchNorm(features),nn.ReLU())
self.conv1_6 = nn.Sequential(nn.Conv2D(in_channels=features,out_channels=features,kernel_size=kernel_size,padding=1,groups=groups,bias_attr=False),nn.BatchNorm(features),nn.ReLU())
self.conv1_7 = nn.Sequential(nn.Conv2D(in_channels=features,out_channels=features,kernel_size=kernel_size,padding=padding,groups=groups,bias_attr=False),nn.BatchNorm(features),nn.ReLU())
self.conv1_8 = nn.Sequential(nn.Conv2D(in_channels=features,out_channels=features,kernel_size=kernel_size,padding=1,groups=groups,bias_attr=False),nn.BatchNorm(features),nn.ReLU())
self.conv1_9 = nn.Sequential(nn.Conv2D(in_channels=features,out_channels=features,kernel_size=kernel_size,padding=2,groups=groups,bias_attr=False,dilation=2),nn.BatchNorm(features),nn.ReLU())
self.conv1_10 = nn.Sequential(nn.Conv2D(in_channels=features,out_channels=features,kernel_size=kernel_size,padding=1,groups=groups,bias_attr=False),nn.BatchNorm(features),nn.ReLU())
self.conv1_11 = nn.Sequential(nn.Conv2D(in_channels=features,out_channels=features,kernel_size=kernel_size,padding=1,groups=groups,bias_attr=False),nn.BatchNorm(features),nn.ReLU())
self.conv1_12 = nn.Sequential(nn.Conv2D(in_channels=features,out_channels=features,kernel_size=kernel_size,padding=2,groups=groups,bias_attr=False,dilation=2),nn.BatchNorm(features),nn.ReLU())
self.conv1_13 = nn.Sequential(nn.Conv2D(in_channels=features,out_channels=features,kernel_size=kernel_size,padding=padding,groups=groups,bias_attr=False),nn.BatchNorm(features),nn.ReLU())
self.conv1_14 = nn.Sequential(nn.Conv2D(in_channels=features,out_channels=features,kernel_size=kernel_size,padding=padding,groups=groups,bias_attr=False),nn.BatchNorm(features),nn.ReLU())
self.conv1_15 = nn.Sequential(nn.Conv2D(in_channels=features,out_channels=features,kernel_size=kernel_size,padding=1,groups=groups,bias_attr=False),nn.BatchNorm(features),nn.ReLU())
self.conv1_16 = nn.Conv2D(in_channels=features,out_channels=1,kernel_size=kernel_size,padding=1,groups=groups,bias_attr=False)
self.conv3 = nn.Conv2D(in_channels=2,out_channels=1,kernel_size=1,stride=1,padding=0,groups=1,bias_attr=True)
self.ReLU = nn.ReLU()
self.Tanh= nn.Tanh()
self.sigmoid = nn.Sigmoid()
def _make_layers(self, block,features, kernel_size, num_of_layers, padding=1, groups=1, bias_attr=False):
layers = []
for _ in range(num_of_layers):
layers.append(block(in_channels=features, out_channels=features, kernel_size=kernel_size, padding=padding, groups=groups, bias_attr=bias_attr))
return nn.Sequential(*layers)
def forward(self, x):
x1 = self.conv1_1(x)
x1 = self.conv1_2(x1)
x1 = self.conv1_3(x1)
x1 = self.conv1_4(x1)
x1 = self.conv1_5(x1)
x1 = self.conv1_6(x1)
x1 = self.conv1_7(x1)
x1t = self.conv1_8(x1)
x1 = self.conv1_9(x1t)
x1 = self.conv1_10(x1)
x1 = self.conv1_11(x1)
x1 = self.conv1_12(x1)
x1 = self.conv1_13(x1)
x1 = self.conv1_14(x1)
x1 = self.conv1_15(x1)
x1 = self.conv1_16(x1)
out = paddle.concat([x,x1],1)
out= self.Tanh(out)
out = self.conv3(out)
out = out*x1
out2 = x - out
return out2
if __name__ == "__main__":
n= 10
x = paddle.rand([n, 1, 44, 44])
model = ADNet(1)
out = model(x)
print("out size: {}".format(out.shape))
W0111 00:56:08.678906 10000 device_context.cc:447] Please NOTE: device: 0, GPU Compute Capability: 7.0, Driver API Version: 10.1, Runtime API Version: 10.1
W0111 00:56:08.684541 10000 device_context.cc:465] device: 0, cuDNN Version: 7.6.
out size: [10, 1, 44, 44]
# 模型可视化
import numpy
import paddle
adnet = ADNet(1)
model = paddle.Model(adnet)
model.summary((2,1, 50, 50))
---------------------------------------------------------------------------
Layer (type) Input Shape Output Shape Param #
===========================================================================
Conv2D-18 [[2, 1, 50, 50]] [2, 64, 50, 50] 576
BatchNorm-16 [[2, 64, 50, 50]] [2, 64, 50, 50] 256
ReLU-17 [[2, 64, 50, 50]] [2, 64, 50, 50] 0
Conv2D-19 [[2, 64, 50, 50]] [2, 64, 50, 50] 36,864
BatchNorm-17 [[2, 64, 50, 50]] [2, 64, 50, 50] 256
ReLU-18 [[2, 64, 50, 50]] [2, 64, 50, 50] 0
Conv2D-20 [[2, 64, 50, 50]] [2, 64, 50, 50] 36,864
BatchNorm-18 [[2, 64, 50, 50]] [2, 64, 50, 50] 256
ReLU-19 [[2, 64, 50, 50]] [2, 64, 50, 50] 0
Conv2D-21 [[2, 64, 50, 50]] [2, 64, 50, 50] 36,864
BatchNorm-19 [[2, 64, 50, 50]] [2, 64, 50, 50] 256
ReLU-20 [[2, 64, 50, 50]] [2, 64, 50, 50] 0
Conv2D-22 [[2, 64, 50, 50]] [2, 64, 50, 50] 36,864
BatchNorm-20 [[2, 64, 50, 50]] [2, 64, 50, 50] 256
ReLU-21 [[2, 64, 50, 50]] [2, 64, 50, 50] 0
Conv2D-23 [[2, 64, 50, 50]] [2, 64, 50, 50] 36,864
BatchNorm-21 [[2, 64, 50, 50]] [2, 64, 50, 50] 256
ReLU-22 [[2, 64, 50, 50]] [2, 64, 50, 50] 0
Conv2D-24 [[2, 64, 50, 50]] [2, 64, 50, 50] 36,864
BatchNorm-22 [[2, 64, 50, 50]] [2, 64, 50, 50] 256
ReLU-23 [[2, 64, 50, 50]] [2, 64, 50, 50] 0
Conv2D-25 [[2, 64, 50, 50]] [2, 64, 50, 50] 36,864
BatchNorm-23 [[2, 64, 50, 50]] [2, 64, 50, 50] 256
ReLU-24 [[2, 64, 50, 50]] [2, 64, 50, 50] 0
Conv2D-26 [[2, 64, 50, 50]] [2, 64, 50, 50] 36,864
BatchNorm-24 [[2, 64, 50, 50]] [2, 64, 50, 50] 256
ReLU-25 [[2, 64, 50, 50]] [2, 64, 50, 50] 0
Conv2D-27 [[2, 64, 50, 50]] [2, 64, 50, 50] 36,864
BatchNorm-25 [[2, 64, 50, 50]] [2, 64, 50, 50] 256
ReLU-26 [[2, 64, 50, 50]] [2, 64, 50, 50] 0
Conv2D-28 [[2, 64, 50, 50]] [2, 64, 50, 50] 36,864
BatchNorm-26 [[2, 64, 50, 50]] [2, 64, 50, 50] 256
ReLU-27 [[2, 64, 50, 50]] [2, 64, 50, 50] 0
Conv2D-29 [[2, 64, 50, 50]] [2, 64, 50, 50] 36,864
BatchNorm-27 [[2, 64, 50, 50]] [2, 64, 50, 50] 256
ReLU-28 [[2, 64, 50, 50]] [2, 64, 50, 50] 0
Conv2D-30 [[2, 64, 50, 50]] [2, 64, 50, 50] 36,864
BatchNorm-28 [[2, 64, 50, 50]] [2, 64, 50, 50] 256
ReLU-29 [[2, 64, 50, 50]] [2, 64, 50, 50] 0
Conv2D-31 [[2, 64, 50, 50]] [2, 64, 50, 50] 36,864
BatchNorm-29 [[2, 64, 50, 50]] [2, 64, 50, 50] 256
ReLU-30 [[2, 64, 50, 50]] [2, 64, 50, 50] 0
Conv2D-32 [[2, 64, 50, 50]] [2, 64, 50, 50] 36,864
BatchNorm-30 [[2, 64, 50, 50]] [2, 64, 50, 50] 256
ReLU-31 [[2, 64, 50, 50]] [2, 64, 50, 50] 0
Conv2D-33 [[2, 64, 50, 50]] [2, 1, 50, 50] 576
Tanh-2 [[2, 2, 50, 50]] [2, 2, 50, 50] 0
Conv2D-34 [[2, 2, 50, 50]] [2, 1, 50, 50] 3
===========================================================================
Total params: 521,091
Trainable params: 517,251
Non-trainable params: 3,840
---------------------------------------------------------------------------
Input size (MB): 0.02
Forward/backward pass size (MB): 110.02
Params size (MB): 1.99
Estimated Total Size (MB): 112.02
---------------------------------------------------------------------------
{'total_params': 521091, 'trainable_params': 517251}
6.定义主函数
包括模型的超参数设置,数据读取,训练,测试,保存最佳结果。
全流程实现,配有完整注释,详细情况请阅读代码
论文中的去噪性能结果如下:

# 主函数定义
"""
处理固定高斯噪声
@author: xupeng
"""
import numpy as np
import pandas as pd
from tqdm import tqdm
import os
import matplotlib.pyplot as plt
import glob
from PIL import Image
from skimage.measure.simple_metrics import compare_psnr
import skimage
from paddle.vision.transforms import *
class Solver(object):
def __init__(self):
self.model = None
self.lr = 0.001 # 学习率
self.epochs = 50 # 训练的代数
self.batch_size = 128 # 训练批次数量
self.optimizer = None
self.scheduler = None
self.device = None
self.noiselevel = 15/255 # 噪声等级
self.saveSetDir = 'work/Set12'
self.train_set = None
self.test_set = None
self.train_loader = None
self.test_loader = None
self.work_dir = r'work/' # 保存数据的地址
self.Modelname = 'ADNet_' # 使用的网络声明(生成的文件会以该声明为区分)
self.evaTOP =0
self.PATH = None # 用于记录最优模型的名称
def InitModeAndData(self):
print("---------------trainInit:---------------")
transform = Compose([ColorJitter(), Resize(size=608)])
self.train_set = DenoiseDataset(mode='train')
self.test_set = DenoiseDataset(mode='test')
# 使用paddle.io.DataLoader 定义DataLoader对象用于加载Python生成器产生的数据,
self.train_loader = paddle.io.DataLoader(self.train_set, batch_size=self.batch_size, shuffle=False)
self.test_loader = paddle.io.DataLoader(self.test_set, batch_size=self.batch_size, shuffle=False)
# model info
self.model =ADNet(1)
self.scheduler = paddle.optimizer.lr.MultiStepDecay(learning_rate=self.lr, milestones=[int(self.epochs*0.4), int(self.epochs*0.8)], gamma=0.1, verbose=False)
self.optimizer = paddle.optimizer.SGD(learning_rate=self.scheduler, parameters=self.model.parameters())
def train(self,epoch):
print("=======Epoch:{}/{}=======".format(epoch,self.epochs))
self.model.train()
criterion = paddle.nn.MSELoss() # paddle.nn.BCELoss()
try: # 使用这种写法(try-except 和 ascii=True),可以避免windows终端或异常中断tqdm出现的混乱
with tqdm(enumerate(self.train_loader),total=len(self.train_loader), ascii=True) as tqdmData:
mean_loss ,temp_train_psnr ,temp_train_ssim,temp_noise_psnr,temp_noise_ssim= [],[],[],[],[]
for idx, (img_train) in tqdmData:
tqdmData.set_description('train')
# 加噪
img_train = paddle.to_tensor(img_train,dtype="float32")
noise = Normal([0], [self.noiselevel])
noise = noise.sample(img_train.shape)
noise = paddle.squeeze(noise, axis=4)
imgn_train = img_train + paddle.to_tensor(noise,dtype="float32")
# 对噪声进行拟合
out_noise = self.model(imgn_train) # 模型输出的是噪声
outputs_img = imgn_train - out_noise
loss = criterion(outputs_img, img_train)
tloss = loss.item()
mean_loss.append(tloss)
outputs_noise = paddle.clip(out_noise, 0., 1.)#
noise_psnr_train,noise_ssim_train = batch_psnr_ssim(outputs_noise, noise, 1.)#
#print(psnr_train,ssim_train) #
outputs_denoise = paddle.clip(outputs_img, 0., 1.)
psnr_train,ssim_train = batch_psnr_ssim(outputs_denoise, img_train, 1.)
#print(psnr_train,ssim_train) #
temp_train_psnr.append(psnr_train)
temp_train_ssim.append(ssim_train)
temp_noise_psnr.append(noise_psnr_train)
temp_noise_ssim.append(noise_ssim_train)
self.optimizer.clear_grad()
loss.backward()
self.optimizer.step()
except KeyboardInterrupt:
tqdmData.close()
os._exit(0)
tqdmData.close()
# 清除中间变量,释放内存
del loss,img_train,imgn_train,noise
paddle.device.cuda.empty_cache()
return {'train_loss': np.mean(mean_loss),'train_psnr':np.mean(temp_train_psnr),'train_ssim':np.mean(temp_train_ssim),'noise_psnr':np.mean(temp_noise_psnr),'noise_ssim':np.mean(temp_noise_ssim)}
def test(self,modelname):
self.model.eval()
temp_test_psnr ,temp_test_ssim= [],[]
with torch.no_grad():
try:
with tqdm(enumerate(self.test_loader),total=len(self.test_loader), ascii=True) as tqdmData:
for idx, (img_test) in tqdmData:
tqdmData.set_description(' test')
# 加噪
img_test= paddle.to_tensor(img_test,dtype="float32")
noise = Normal([0], [self.noiselevel])
noise = noise.sample(img_test.shape)
noise = paddle.squeeze(noise, axis=4)
imgn_test = img_test + paddle.to_tensor(noise,dtype="float32")
img_test,imgn_test,noise = img_test.to(self.device),imgn_test.to(self.device),noise.to(self.device)
out_noise = self.model(imgn_test) # 模型输出的是噪声
outputs_denoise = imgn_test-out_noise # 去噪后的图像
outputs_denoise = paddle.clip(outputs_denoise, 0., 1.)
psnr_test,ssim_test = batch_psnr_ssim(outputs_denoise, img_test, 1.)
temp_test_psnr.append(psnr_test)
temp_test_ssim.append(ssim_test)
except KeyboardInterrupt:
tqdmData.close()
os._exit(0)
tqdmData.close()
paddle.device.cuda.empty_cache()
# 打印test psnr & ssim
print('test_psnr:',np.mean(temp_test_psnr),'test_ssim:',np.mean(temp_test_ssim))
return {'test_psnr':np.mean(temp_test_psnr),'test_ssim':np.mean(temp_test_ssim)}
def saveModel(self,trainloss,modelname):
trainLoss = trainloss['test_psnr']
if trainLoss < self.evaTOP and self.evaTOP!=0:
return 0
else:
folder = './saveModel/'
self.PATH = folder+modelname+str(trainLoss)+'.pdparams'
removePATH = folder+modelname+str(self.evaTOP)+'.pdparams'
paddle.save(self.model.state_dict(), self.PATH)
if self.evaTOP!=0:
os.remove(removePATH)
self.evaTOP = trainLoss
return 1
def saveResult(self):
self.model.set_state_dict(paddle.load(self.PATH))
self.model.eval()
paddle.set_grad_enabled(False)
paddle.device.cuda.empty_cache()
data_dir = glob.glob(self.saveSetDir+'*.png')
saveSet = pd.DataFrame()
tpsnr,tssim = [],[]
for ori_path in data_dir:
ori= np.asarray(Image.open(ori_path))
ori_img = paddle.to_tensor(ori,dtype="float32")
noise = Normal([0], [self.noiselevel])
noise = noise.sample(ori_img.shape)
noise = paddle.squeeze(noise, axis=4)
noise_img = ori_img+ paddle.to_tensor(noise,dtype="float32")
ori_img = paddle.unsqueeze(ori_img,0)
noise_img = paddle.unsqueeze(noise_img,0)
ori_img,noise_img = ori_img.to(self.device),noise_img.to(self.device)
out_noise = self.model(noise_img)
outputs = noise_img - out_noise
outputs = paddle.clip(outputs, 0., 1.)
img_cpu = np.squeeze(outputs.data.cpu().numpy()).astype(np.float32)
imgclean = np.squeeze(ori_img.data.cpu().numpy()).astype(np.float32)
#保存结果
savepic = Image.fromarray((img_cpu*255).astype('float32')).convert('L')
savedir = ori_path.split('.')[0]+self.Modelname+'.'+ori_path.split('.')[1]
print(savedir)
savepic.save(savedir)
psnr = compare_psnr(imgclean,img_cpu, data_range=1.)
ssim = skimage.measure.compare_ssim(imgclean,img_cpu, data_range=1.)
tpsnr.append(psnr)
tssim.append(ssim)
temp = {'name':ori_path.split('\\')[-1],'SSIM':ssim,'PSNR':psnr}
saveSet = saveSet.append(temp,ignore_index=True)
avgtemp = {'name':'AVG','SSIM':np.mean(tssim),'PSNR':np.mean(tpsnr)}
saveSet = saveSet.append(avgtemp,ignore_index=True)
saveSet.to_csv(str(self.noiselevel)+self.Modelname+'.csv',index=False)
def run(self):
self.InitModeAndData()
dataname ='DEnoise_' #额外的文件名
modelname = self.Modelname # 保存的文件名
result = pd.DataFrame()
for epoch in range(1, self.epochs + 1):
trainloss = self.train(epoch)
evalloss = self.test(modelname)#
Type = self.saveModel(evalloss,modelname)
type_ = {'Type':Type}
trainloss.update(evalloss)#
trainloss.update(type_)
result = result.append(trainloss,ignore_index=True)
print(trainloss,Type)
#self.scheduler.step(evalloss['test_psnr'])
self.scheduler.step()
evalloss = self.test(modelname)#
result.to_csv(dataname+str(self.noiselevel)+modelname+str(evalloss['test_psnr'])+'_'+str(evalloss['test_ssim'])+'.csv')#
#result.to_csv(dataname+str(self.noiselevel)+modelname+'.csv')
self.saveResult()
'''
plt.figure(figsize=(7, 7), dpi=300)
result['train_loss'].plot(label='train loss')
plt.legend()
plt.xlabel('Train Epoch')
plt.ylabel('Loss Value')
plt.text(result['train_loss'].argmin(),np.min(result['train_loss'])+0.005,'Minest:' + str(round(np.min(result['train_loss']),3)),fontdict={'size':'10','color':'b'})
plt.savefig(dataname+ str(evalloss['test_psnr'])+'_'+str(evalloss['test_ssim']) +modelname+'.png')
plt.show()
'''
def main():
solver = Solver()
solver.run()
if __name__ == '__main__':
main()
re(figsize=(7, 7), dpi=300)
result['train_loss'].plot(label='train loss')
plt.legend()
plt.xlabel('Train Epoch')
plt.ylabel('Loss Value')
plt.text(result['train_loss'].argmin(),np.min(result['train_loss'])+0.005,'Minest:' + str(round(np.min(result['train_loss']),3)),fontdict={'size':'10','color':'b'})
plt.savefig(dataname+ str(evalloss['test_psnr'])+'_'+str(evalloss['test_ssim']) +modelname+'.png')
plt.show()
'''
def main():
solver = Solver()
solver.run()
if __name__ == '__main__':
main()
7.项目总结
本项目对ADNet论文进行了复现,填补了平台高斯噪声去除的小空白。有很多小的tips可以学习
包括tqdm的使用,PSNR/SSIM的定义,使用h5文件缩小内存(50GB->14GB),自定义数据增强方法,tar.gz的解压缩等
本代码是根据作者开源pytorch代码进行改良,pytorch结果已成功复现。
模型需要50个epoch,每个epoch需要约2h。完整跑完需要四天多(作者算力不太够,没跑完)
模型,数据及预处理,包括评价指标均与原论文对其,可以放心阅读学习。
如果该项目Fork数超过100,就单独开项目对训练时间进行优化,再讲解下加速训练的注意事项。
8.参考资料
[1] https://blog.csdn.net/qq_35200351/article/details/108962037
[3] https://www.sciencedirect.com/science/article/abs/pii/S0893608019304241
[4] https://blog.csdn.net/qq_35200351/article/details/108962037
- (o゜▽゜)o☆[BINGO!] 欢迎FORK!点赞!关注!

学大模型,用大模型上飞桨星河社区!每天8点V100G算力免费领!免费领取ERNIE 4.0 100w Token >>>
更多推荐



 7
7 1
1- 0



 已为社区贡献1436条内容
已为社区贡献1436条内容

所有评论(0)