
基于语义标签的短视频推荐
基于语义标签的短视频推荐
- 项目概述
如今短视频行业特别火,很多人都喜欢在等车的时候,地铁上刷几个短视频,甚至在上厕所的时候也要刷上半天。但是你知道吗?短视频APP在向你展示一个大长腿/帅哥视频之前,通常既要预测你对这个视频感兴趣/不感兴趣,又要预测你会看多久?点赞还是不点赞?会不会偷偷收藏起来下次接着看?只有同时在这么多个维度都比较符合您的兴趣,短视频APP才会将这个视频推送到您的手机上。但是问题又来了,有这么多个想要预测的信息维度,如果将每种指标都看做一个任务,每个任务都搞一个模型来学。那花费的线上资源将是非常昂贵的。这个时候,多任务模型就可以出来拯救开发同学了,一个模型多任务学习来一次全搞定。
本项目主要介绍如何使用飞桨大规模推荐算法库PaddleRec ,仅以短视频推荐场景为例,说明多任务技术的应用方法和收益,但多任务技术不仅仅可以使用于视频推荐中,也可以在比如电商场景的点击&转化(购买),信息流推荐场景的点击&点赞(评论,关注等一系列后续行为),搜索广告场景下的点击&再点击(相关广告,相关搜索,猜你喜欢等等)等场景下使用。
- 什么是多任务学习
2.2 多任务学习的概念
多任务学习(multitask)的定义和形式有很多种。我觉得比较直观的理解是和单任务学习相对的一种机器学习方法。
以短视频推荐为例介绍单任务和多任务的区别:
(1)短视频推荐中,同时需要预测点赞率,完播率和收藏率。
(2)单任务学习就是忽略任务之间可能存在的关系分别学习3个回归函数进行分数的预测
(3)而多任务学习则看重任务之间的联系,通过联合学习,同时对3个任务学习不同的回归函数,既考虑到了任务之间的差别,又考虑到任务之间的联系,这也是多任务学习最重要的思想之一。
2.3多任务学习的好处
多任务算法的应用场景还是很广泛的,只要是推荐技术涉及的业务,比如搜索、广告还是推荐都有需求,另外无论是成熟的大规模推荐系统还是处于上升期的初创场景对于多个目标的联合训练一般都有强需求。常见多任务学习的动机和需求还是围绕提升(主)模型的精度(泛化能力)、资源性能和维护成本。
(1)多任务场景下,多个任务(相关性较强)会从不同的角度学习特征,增强模型泛化能力来提升收益,最常见的就是通过增加优化目标。针对很多数据集比稀疏的任务,比如短视频转发,大部分人看了一个短视频是不会进行转发这个操作的,这么稀疏的行为,模型是很难学好的(过拟合问题严重),那我们把预测用户是否转发这个稀疏的事情和用户是否点击观看这个经常发生事情放在一起学,一定程度上会缓解模型的过拟合,提高了模型的泛化能力。
(2)共享参数,不额外增加资源的前提下变相增加参数规模。推荐系统的核心是embedding,对于相关的多个目标,比如点击/时长等,用户及相关特征的重合或者接近的,多个任务共享这部分参数可以极大的节省离线和在线资源
(3)用数据更多的任务指导学习数据较少的任务。一般常见的就是某个任务的数据量较少,期望能通过大数据训练较好的模型指导稀疏数据场景下的模型,比如点击率和转化率,一跳场景和二跳场景。
(4)冷启模型的快速收敛。将冷启模型和收敛模型同时训练,帮助冷启模型可以在一个相对正确的方向上快速收敛。
(5)有更多反馈和指导的模型(人工参与或更接近用户反馈层)指导学习其他模型。最常见的就是在精排阶段或者重排序阶段有一些"精准"评分用来指导更上层的粗排或者召回模型
(6)多个模型合并为一个模型后的线上资源多路请求可以合并为一路,减少请求资源。这个一般是架构同学的强需求,毕竟线上资源还是非常贵的。
(7)减少多模型的维护成本。有很多策略和架构同学减少维护多个"相似"模型的需求是强烈的,一般一个模型有数据链条,离线训练任务,在线任务等多个环节,如果能合并成一个任务会极大的减轻工作量。
(8)混合数据中训练不同任务。由于数据生成或者任务形式的不同,常见的需求是期望不同的数据训练不同的模型(比如mlp塔),而不是所有数据都训练每个模型,这也是多任务学习中的常见需求。不同的数据一般指不同的样本 或者一条样本的不同特征。
-
方案设计&模型选取
推荐系统(深度学习)的演变,往往是从简单到复杂的过程,综合精度和性能考虑,最常见的路径是线性模型/LR -> 双塔模型(user/item) -> DNN全链接 -> 多个目标的联合学习 / 更复杂的特征学习(wide&deep, deepfm等)。
我们在为短视频推荐任务选取模型的时候也可以从简单到复杂,从硬参数共享(Hard parameter sharing) 到软参数共享(Soft parameter sharing),常见的升级路线为从share-bottom -> MMOE -> CGC/PLE的路径,一步步优化,让模型给我们找出最符合口味的短视频。 -
代码实现


在模型实现方面,这里强烈推荐我们组在推荐方向的工作成果——大规模推荐算法库PaddleRec,欢迎大家动手点点star。
我们在PaddleRec模型库中已经开源实现了上述三个模型Share_Bottom,MMoE,PLE。并且进行了论文复现,可以非常方便的运行模型,并获得论文效果。并且我们尝试了在相同数据和参数规模下(很重要,有可比性),上述三个模型的效果随着模型的升级获得了较为显著的提升。
4.1 数据准备
由于没有合适的公开数据集,我们基于公开数据集构造了一个视频数据集。这个数据集会以视频的完播率和点赞率作为label,得到两个tasks, 然后计算不同模型的AUC, 进行比较。
数据集中格式以逗号为分割点,如下所示:
0,0,73,0,0,0,0,1700.09,0,0…
0,0,58,0,0,0,0,1053.55,1,0…
前两个数字为label,具体意义为完播率和点赞率。后面的数字为从该用户之前看过的视频中提取出的用户特征。
label_1 label_2 特征1 特征2 特征3 特征4 特征5 特征6 特征7 特征8 特征9 …
完播 点赞 国家 地理 影视 旅游 美食 游戏 跑车 美妆 科技 …
0 0 73 0 0 0 0 1700 09 0 0 …
0 0 58 0 0 0 0 1053 55 1 0 …
我们将全量的数据放在了dataset目录的video子目录下
In [1]
cd PaddleRec-master/datasets/video/
/home/aistudio/PaddleRec-master/datasets/video
4.2 模型组网,训练,评估
4.2.1 Share_Bottom
share_bottom是多任务学习的基本框架,简单直接易于理解和实现。应用场景广泛。可以满足大部分多任务需求,如快速帮助冷启模型收敛,为稀疏数据场景的子任务扩充数据源,从更多的角度提升模型的泛化性。所以适合作为baseline来对比后续优化效果。其特点是对于不同的任务,底层的参数和网络结构是共享的,这种结构的优点是极大地减少网络的参数数量的情况下也能很好地对多任务进行学习.而最常见的共享部分就是embedding。不论是离散特征比如用户id, 性别男/女, ,年龄(25)还是连续性特征如收入,都可以通过embedding转化为多维空间下的向量,用于更深刻的刻画这个特征值。在一个中等或者大规模的推荐系统中,往往embedding的key(离散id)可以达到上亿甚至十亿以上的规模。用户id的embedding的"表示"能力往往支撑着一个个性化推荐系统的下限。
一个有着数百万以上用户的推荐系统往往sparse部分就占据着相当大的参数规模和计算量。在多任务场景下,如果各个任务都需要embedding映射,那么每个任务都有一个独立的sparse映射表就显得太"奢侈"了。工程师们希望多个任务能同时完整全面的刻画一个用户的画像(embedding表示),且共享sparse可以节省大量资源,所以共享sparse部分成为推荐系统中多任务学习的最常见的行为。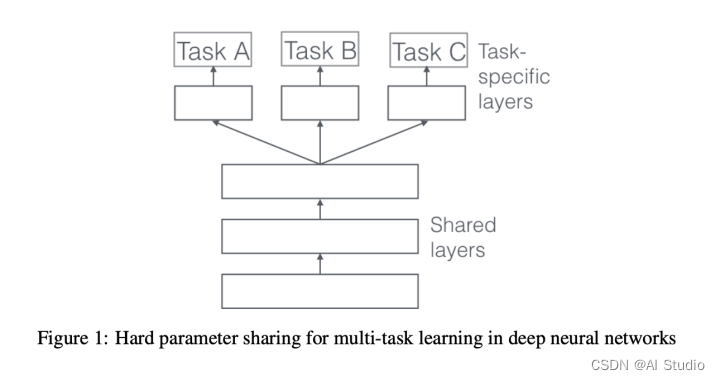
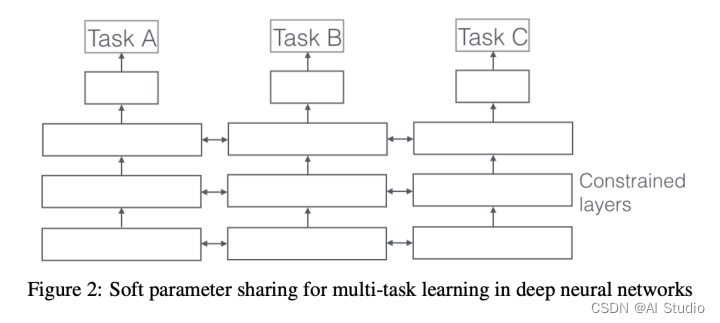
根据上图硬共享的图示,数据进入共享层后会作为不同任务的输入,在反向梯度计算中,不同任务会共同影响共享层的参数。
优点:
(1) 简单直接易于理解,符合多任务学习共享表示的直观思想。
(2) 应用场景广泛。可以满足上一章中提到的大部分多任务需求,如快速帮助冷启模型收敛,为稀疏数据场景的子任务扩充数据源,从更多的角度提升模型的泛化性。
(3) 易于实现。特别适合于快速迭代和简易推荐系统的搭建。
缺点:
(1) 对于不同任务下过于简单草率的"联合"也导致了跷跷板效应,由于底层的参数和网络结构是完全共享的,因此对于相关性不高的两个任务会导致优化冲突.产生一些子任务效果好,一些子任务效果差的结果,甚至会出现表型都差的情况,原因就是直接将共享层作为不同任务的输入有可能会造成互斥任务间的排斥效应。
share_bottom模型网络结构搭建代码如下:
lass ShareBottomLayer(nn.Layer):
def init(self, feature_size, task_num, bottom_size, tower_size):
super(ShareBottomLayer, self).init()
self.task_num = task_num
self._param_bottom = self.add_sublayer(
name='bottom',
sublayer=nn.Linear(
feature_size,
bottom_size,
#weight_attr=nn.initializer.Constant(value=0.1),
bias_attr=paddle.ParamAttr(learning_rate=1.0),
#bias_attr=nn.initializer.Constant(value=0.1),
name='bottom'))
self._param_tower = []
self._param_tower_out = []
for i in range(0, self.task_num):
linear = self.add_sublayer(
name='tower_' + str(i),
sublayer=nn.Linear(
bottom_size,
tower_size,
weight_attr=nn.initializer.Constant(value=0.1),
bias_attr=nn.initializer.Constant(value=0.1),
name='tower_' + str(i)))
self._param_tower.append(linear)
linear = self.add_sublayer(
name='tower_out_' + str(i),
sublayer=nn.Linear(
tower_size,
2,
weight_attr=nn.initializer.Constant(value=0.1),
bias_attr=nn.initializer.Constant(value=0.1),
name='tower_out_' + str(i)))
self._param_tower_out.append(linear)
def forward(self, input_data):
bottom_tmp = self._param_bottom(input_data)
bottom_out = F.relu(bottom_tmp)
output_layers = []
for i in range(0, self.task_num):
cur_tower = self._param_tower[i](bottom_out)
cur_tower = F.relu(cur_tower)
out_tmp = self._param_tower_out[i](cur_tower)
out = F.softmax(out_tmp)
out_clip = paddle.clip(out, min=1e-15, max=1.0 - 1e-15)
output_layers.append(out_clip)
return output_layers
In [2]
cd …/…/models/multitask/share_bottom/
/home/aistudio/PaddleRec-master/models/multitask/share_bottom
In [ ]
动态图训练
! python -u …/…/…/tools/trainer.py -m config_bigdata.yaml
动态图预测
! python -u …/…/…/tools/infer.py -m config_bigdata.yaml
2022-06-07 14:31:10,097 - INFO - ****common.configs
2022-06-07 14:31:10,097 - INFO - use_gpu: True, use_xpu: False, use_npu: False, use_visual: False, train_batch_size: 32, train_data_dir: …/…/…/datasets/video/train_all, epochs: 100, print_interval: 100, model_save_path: output_model_share_btm_all
2022-06-07 14:31:10,097 - INFO - ****common.configs
W0607 14:31:10.098443 220 device_context.cc:447] Please NOTE: device: 0, GPU Compute Capability: 8.0, Driver API Version: 11.2, Runtime API Version: 11.2
W0607 14:31:10.101245 220 device_context.cc:465] device: 0, cuDNN Version: 8.2.
2022-06-07 14:31:13,501 - INFO - read data
2022-06-07 14:31:13,501 - INFO - reader path:video_reader
2022-06-07 14:31:14,752 - INFO - epoch: 0, batch_id: 0, auc_like:0.000000, auc_completion:0.500000, avg_reader_cost: 0.01217 sec, avg_batch_cost: 0.01239 sec, avg_samples: 0.32000, ips: 25.82351 ins/s
2022-06-07 14:31:15,346 - INFO - epoch: 0, batch_id: 100, auc_like:0.449585, auc_completion:0.503983, avg_reader_cost: 0.00005 sec, avg_batch_cost: 0.00578 sec, avg_samples: 32.00000, ips: 5539.53509 ins/s
2022-06-07 14:31:15,932 - INFO - epoch: 0, batch_id: 200, auc_like:0.422094, auc_completion:0.517786, avg_reader_cost: 0.00005 sec, avg_batch_cost: 0.00570 sec, avg_samples: 32.00000, ips: 5612.19064 ins/s
2022-06-07 14:31:16,521 - INFO - epoch: 0, batch_id: 300, auc_like:0.451441, auc_completion:0.518573, avg_reader_cost: 0.00005 sec, avg_batch_cost: 0.00567 sec, avg_samples: 32.00000, ips: 5639.36479 ins/s
2022-06-07 14:31:17,106 - INFO - epoch: 0, batch_id: 400, auc_like:0.478788, auc_completion:0.539945, avg_reader_cost: 0.00005 sec, avg_batch_cost: 0.00568 sec, avg_samples: 32.00000, ips: 5631.13818 ins/s
2022-06-07 14:31:17,701 - INFO - epoch: 0, batch_id: 500, auc_like:0.538686, auc_completion:0.630169, avg_reader_cost: 0.00005 sec, avg_batch_cost: 0.00580 sec, avg_samples: 32.00000, ips: 5521.93168 ins/s
2022-06-07 14:31:18,333 - INFO - epoch: 0, batch_id: 600, auc_like:0.591463, auc_completion:0.702699, avg_reader_cost: 0.00005 sec, avg_batch_cost: 0.00613 sec, avg_samples: 32.00000, ips: 5216.50405 ins/s
2022-06-07 14:31:18,940 - INFO - epoch: 0, batch_id: 700, auc_like:0.631212, auc_completion:0.754032, avg_reader_cost: 0.00005 sec, avg_batch_cost: 0.00590 sec, avg_samples: 32.00000, ips: 5425.64804 ins/s
2022-06-07 14:31:19,510 - INFO - epoch: 0, batch_id: 800, auc_like:0.656848, auc_completion:0.790418, avg_reader_cost: 0.00005 sec, avg_batch_cost: 0.00555 sec, avg_samples: 32.00000, ips: 5761.84684 ins/s
2022-06-07 14:31:20,091 - INFO - epoch: 0, batch_id: 900, auc_like:0.675576, auc_completion:0.818108, avg_reader_cost: 0.00004 sec, avg_batch_cost: 0.00565 sec, avg_samples: 32.00000, ips: 5663.20722 ins/s
2022-06-07 14:31:20,672 - INFO - epoch: 0, batch_id: 1000, auc_like:0.696722, auc_completion:0.838138, avg_reader_cost: 0.00005 sec, avg_batch_cost: 0.00562 sec, avg_samples: 32.00000, ips: 5691.01883 ins/s
2022-06-07 14:31:21,254 - INFO - epoch: 0, batch_id: 1100, auc_like:0.715185, auc_completion:0.854946, avg_reader_cost: 0.00005 sec, avg_batch_cost: 0.00566 sec, avg_samples: 32.00000, ips: 5650.79452 ins/s
2022-06-07 14:31:21,830 - INFO - epoch: 0, batch_id: 1200, auc_like:0.727965, auc_completion:0.866913, avg_reader_cost: 0.00005 sec, avg_batch_cost: 0.00559 sec, avg_samples: 32.00000, ips: 5720.07259 ins/s
2022-06-07 14:31:22,406 - INFO - epoch: 0, batch_id: 1300, auc_like:0.741303, auc_completion:0.875874, avg_reader_cost: 0.00005 sec, avg_batch_cost: 0.00561 sec, avg_samples: 32.00000, ips: 5709.05318 ins/s
2022-06-07 14:31:22,979 - INFO - epoch: 0, batch_id: 1400, auc_like:0.751829, auc_completion:0.886014, avg_reader_cost: 0.00004 sec, avg_batch_cost: 0.00558 sec, avg_samples: 32.00000, ips: 5735.05037 ins/s
2022-06-07 14:31:23,562 - INFO - epoch: 0, batch_id: 1500, auc_like:0.758609, auc_completion:0.893038, avg_reader_cost: 0.00005 sec, avg_batch_cost: 0.00567 sec, avg_samples: 32.00000, ips: 5640.41466 ins/s
2022-06-07 14:31:24,145 - INFO - epoch: 0, batch_id: 1600, auc_like:0.761804, auc_completion:0.899442, avg_reader_cost: 0.00005 sec, avg_batch_cost: 0.00567 sec, avg_samples: 32.00000, ips: 5643.11578 ins/s
2022-06-07 14:31:24,718 - INFO - epoch: 0, batch_id: 1700, auc_like:0.770301, auc_completion:0.906151, avg_reader_cost: 0.00005 sec, avg_batch_cost: 0.00558 sec, avg_samples: 32.00000, ips: 5739.60958 ins/s
2022-06-07 14:31:25,285 - INFO - epoch: 0, batch_id: 1800, auc_like:0.778495, auc_completion:0.911707, avg_reader_cost: 0.00005 sec, avg_batch_cost: 0.00552 sec, avg_samples: 32.00000, ips: 5797.79713 ins/s
2022-06-07 14:31:25,852 - INFO - epoch: 0, batch_id: 1900, auc_like:0.785267, auc_completion:0.916136, avg_reader_cost: 0.00004 sec, avg_batch_cost: 0.00552 sec, avg_samples: 32.00000, ips: 5799.92671 ins/s
2022-06-07 14:31:26,419 - INFO - epoch: 0, batch_id: 2000, auc_like:0.792628, auc_completion:0.920004, avg_reader_cost: 0.00004 sec, avg_batch_cost: 0.00552 sec, avg_samples: 32.00000, ips: 5797.85724 ins/s
2022-06-07 14:31:26,987 - INFO - epoch: 0, batch_id: 2100, auc_like:0.799430, auc_completion:0.923845, avg_reader_cost: 0.00004 sec, avg_batch_cost: 0.00553 sec, avg_samples: 32.00000, ips: 5787.25497 ins/s
2022-06-07 14:31:27,559 - INFO - epoch: 0, batch_id: 2200, auc_like:0.805147, auc_completion:0.927144, avg_reader_cost: 0.00005 sec, avg_batch_cost: 0.00554 sec, avg_samples: 32.00000, ips: 5777.34538 ins/s
2022-06-07 14:31:28,128 - INFO - epoch: 0, batch_id: 2300, auc_like:0.810023, auc_completion:0.930082, avg_reader_cost: 0.00005 sec, avg_batch_cost: 0.00554 sec, avg_samples: 32.00000, ips: 5775.99535 ins/s
2022-06-07 14:31:28,700 - INFO - epoch: 0, batch_id: 2400, auc_like:0.815182, auc_completion:0.932087, avg_reader_cost: 0.00004 sec, avg_batch_cost: 0.00557 sec, avg_samples: 32.00000, ips: 5749.40481 ins/s
2022-06-07 14:31:29,270 - INFO - epoch: 0, batch_id: 2500, auc_like:0.819324, auc_completion:0.934372, avg_reader_cost: 0.00004 sec, avg_batch_cost: 0.00554 sec, avg_samples: 32.00000, ips: 5771.59409 ins/s
2022-06-07 14:31:29,839 - INFO - epoch: 0, batch_id: 2600, auc_like:0.822064, auc_completion:0.935703, avg_reader_cost: 0.00004 sec, avg_batch_cost: 0.00554 sec, avg_samples: 32.00000, ips: 5776.09229 ins/s
2022-06-07 14:31:30,406 - INFO - epoch: 0, batch_id: 2700, auc_like:0.825466, auc_completion:0.936514, avg_reader_cost: 0.00004 sec, avg_batch_cost: 0.00551 sec, avg_samples: 32.00000, ips: 5806.49818 ins/s
2022-06-07 14:31:31,014 - INFO - epoch: 0, batch_id: 2800, auc_like:0.828389, auc_completion:0.937047, avg_reader_cost: 0.00004 sec, avg_batch_cost: 0.00593 sec, avg_samples: 32.00000, ips: 5395.73962 ins/s
2022-06-07 14:31:31,583 - INFO - epoch: 0, batch_id: 2900, auc_like:0.831383, auc_completion:0.937119, avg_reader_cost: 0.00004 sec, avg_batch_cost: 0.00554 sec, avg_samples: 32.00000, ips: 5779.59186 ins/s
2022-06-07 14:31:32,159 - INFO - epoch: 0, batch_id: 3000, auc_like:0.834737, auc_completion:0.938164, avg_reader_cost: 0.00004 sec, avg_batch_cost: 0.00560 sec, avg_samples: 32.00000, ips: 5715.37399 ins/s
2022-06-07 14:31:32,727 - INFO - epoch: 0, batch_id: 3100, auc_like:0.838153, auc_completion:0.940050, avg_reader_cost: 0.00004 sec, avg_batch_cost: 0.00553 sec, avg_samples: 32.00000, ips: 5784.02278 ins/s
2022-06-07 14:31:33,297 - INFO - epoch: 0, batch_id: 3200, auc_like:0.840447, auc_completion:0.941990, avg_reader_cost: 0.00004 sec, avg_batch_cost: 0.00554 sec, avg_samples: 32.00000, ips: 5774.69315 ins/s
2022-06-07 14:31:33,869 - INFO - epoch: 0, batch_id: 3300, auc_like:0.842856, auc_completion:0.943264, avg_reader_cost: 0.00004 sec, avg_batch_cost: 0.00556 sec, avg_samples: 32.00000, ips: 5751.60250 ins/s
2022-06-07 14:31:34,439 - INFO - epoch: 0, batch_id: 3400, auc_like:0.844909, auc_completion:0.944579, avg_reader_cost: 0.00004 sec, avg_batch_cost: 0.00555 sec, avg_samples: 32.00000, ips: 5769.96891 ins/s
2022-06-07 14:31:35,015 - INFO - epoch: 0, batch_id: 3500, auc_like:0.847305, auc_completion:0.945970, avg_reader_cost: 0.00004 sec, avg_batch_cost: 0.00561 sec, avg_samples: 32.00000, ips: 5705.03945 ins/s
2022-06-07 14:31:35,631 - INFO - epoch: 0, batch_id: 3600, auc_like:0.849567, auc_completion:0.947233, avg_reader_cost: 0.00005 sec, avg_batch_cost: 0.00599 sec, avg_samples: 32.00000, ips: 5346.09940 ins/s
2022-06-07 14:31:36,217 - INFO - epoch: 0, batch_id: 3700, auc_like:0.851656, auc_completion:0.947774, avg_reader_cost: 0.00004 sec, avg_batch_cost: 0.00569 sec, avg_samples: 32.00000, ips: 5621.96280 ins/s
2022-06-07 14:31:36,786 - INFO - epoch: 0, batch_id: 3800, auc_like:0.853444, auc_completion:0.948772, avg_reader_cost: 0.00004 sec, avg_batch_cost: 0.00555 sec, avg_samples: 32.00000, ips: 5767.15741 ins/s
2022-06-07 14:31:37,356 - INFO - epoch: 0, batch_id: 3900, auc_like:0.855782, auc_completion:0.949721, avg_reader_cost: 0.00005 sec, avg_batch_cost: 0.00554 sec, avg_samples: 32.00000, ips: 5771.57424 ins/s
2022-06-07 14:31:37,926 - INFO - epoch: 0, batch_id: 4000, auc_like:0.857543, auc_completion:0.950616, avg_reader_cost: 0.00005 sec, avg_batch_cost: 0.00554 sec, avg_samples: 32.00000, ips: 5772.11037 ins/s
2022-06-07 14:31:38,496 - INFO - epoch: 0, batch_id: 4100, auc_like:0.858977, auc_completion:0.951365, avg_reader_cost: 0.00005 sec, avg_batch_cost: 0.00555 sec, avg_samples: 32.00000, ips: 5769.59190 ins/s
2022-06-07 14:31:39,066 - INFO - epoch: 0, batch_id: 4200, auc_like:0.860402, auc_completion:0.951947, avg_reader_cost: 0.00004 sec, avg_batch_cost: 0.00554 sec, avg_samples: 32.00000, ips: 5775.05094 ins/s
2022-06-07 14:31:39,638 - INFO - epoch: 0, batch_id: 4300, auc_like:0.861768, auc_completion:0.952858, avg_reader_cost: 0.00005 sec, avg_batch_cost: 0.00556 sec, avg_samples: 32.00000, ips: 5752.19656 ins/s
2022-06-07 14:31:40,207 - INFO - epoch: 0, batch_id: 4400, auc_like:0.862774, auc_completion:0.953637, avg_reader_cost: 0.00005 sec, avg_batch_cost: 0.00554 sec, avg_samples: 32.00000, ips: 5776.91022 ins/s
2022-06-07 14:31:40,778 - INFO - epoch: 0, batch_id: 4500, auc_like:0.863502, auc_completion:0.954395, avg_reader_cost: 0.00005 sec, avg_batch_cost: 0.00555 sec, avg_samples: 32.00000, ips: 5762.13873 ins/s
2022-06-07 14:31:41,351 - INFO - epoch: 0, batch_id: 4600, auc_like:0.864531, auc_completion:0.955147, avg_reader_cost: 0.00005 sec, avg_batch_cost: 0.00558 sec, avg_samples: 32.00000, ips: 5737.36463 ins/s
2022-06-07 14:31:41,922 - INFO - epoch: 0, batch_id: 4700, auc_like:0.865510, auc_completion:0.955975, avg_reader_cost: 0.00005 sec, avg_batch_cost: 0.00555 sec, avg_samples: 32.00000, ips: 5765.66105 ins/s
2022-06-07 14:31:42,491 - INFO - epoch: 0, batch_id: 4800, auc_like:0.866600, auc_completion:0.956550, avg_reader_cost: 0.00004 sec, avg_batch_cost: 0.00554 sec, avg_samples: 32.00000, ips: 5773.30213 ins/s
2022-06-07 14:31:43,062 - INFO - epoch: 0, batch_id: 4900, auc_like:0.867756, auc_completion:0.957316, avg_reader_cost: 0.00005 sec, avg_batch_cost: 0.00555 sec, avg_samples: 32.00000, ips: 5765.15830 ins/s
2022-06-07 14:31:43,631 - INFO - epoch: 0, batch_id: 5000, auc_like:0.868646, auc_completion:0.957957, avg_reader_cost: 0.00004 sec, avg_batch_cost: 0.00554 sec, avg_samples: 32.00000, ips: 5779.94031 ins/s
2022-06-07 14:31:44,201 - INFO - epoch: 0, batch_id: 5100, auc_like:0.869672, auc_completion:0.958524, avg_reader_cost: 0.00005 sec, avg_batch_cost: 0.00555 sec, avg_samples: 32.00000, ips: 5769.71344 ins/s
2022-06-07 14:31:44,772 - INFO - epoch: 0, batch_id: 5200, auc_like:0.870884, auc_completion:0.959034, avg_reader_cost: 0.00004 sec, avg_batch_cost: 0.00555 sec, avg_samples: 32.00000, ips: 5761.90126 ins/s
2022-06-07 14:31:45,349 - INFO - epoch: 0, batch_id: 5300, auc_like:0.871753, auc_completion:0.959676, avg_reader_cost: 0.00004 sec, avg_batch_cost: 0.00562 sec, avg_samples: 32.00000, ips: 5691.86112 ins/s
2022-06-07 14:31:45,922 - INFO - epoch: 0, batch_id: 5400, auc_like:0.873096, auc_completion:0.960164, avg_reader_cost: 0.00005 sec, avg_batch_cost: 0.00557 sec, avg_samples: 32.00000, ips: 5745.78918 ins/s
2022-06-07 14:31:46,493 - INFO - epoch: 0, batch_id: 5500, auc_like:0.874079, auc_completion:0.960688, avg_reader_cost: 0.00004 sec, avg_batch_cost: 0.00557 sec, avg_samples: 32.00000, ips: 5747.23587 ins/s
2022-06-07 14:31:47,066 - INFO - epoch: 0, batch_id: 5600, auc_like:0.874986, auc_completion:0.961224, avg_reader_cost: 0.00005 sec, avg_batch_cost: 0.00557 sec, avg_samples: 32.00000, ips: 5742.24196 ins/s
2022-06-07 14:31:47,637 - INFO - epoch: 0, batch_id: 5700, auc_like:0.875233, auc_completion:0.961743, avg_reader_cost: 0.00005 sec, avg_batch_cost: 0.00555 sec, avg_samples: 32.00000, ips: 5761.18649 ins/s
2022-06-07 14:31:48,213 - INFO - epoch: 0, batch_id: 5800, auc_like:0.875699, auc_completion:0.962060, avg_reader_cost: 0.00005 sec, avg_batch_cost: 0.00560 sec, avg_samples: 32.00000, ips: 5709.21589 ins/s
2022-06-07 14:31:48,789 - INFO - epoch: 0, batch_id: 5900, auc_like:0.876258, auc_completion:0.962514, avg_reader_cost: 0.00005 sec, avg_batch_cost: 0.00560 sec, avg_samples: 32.00000, ips: 5715.64415 ins/s
2022-06-07 14:31:49,364 - INFO - epoch: 0, batch_id: 6000, auc_like:0.876807, auc_completion:0.962831, avg_reader_cost: 0.00005 sec, avg_batch_cost: 0.00559 sec, avg_samples: 32.00000, ips: 5720.69429 ins/s
2022-06-07 14:31:49,933 - INFO - epoch: 0, batch_id: 6100, auc_like:0.877671, auc_completion:0.963346, avg_reader_cost: 0.00004 sec, avg_batch_cost: 0.00554 sec, avg_samples: 32.00000, ips: 5775.08573 ins/s
2022-06-07 14:31:50,506 - INFO - epoch: 0, batch_id: 6200, auc_like:0.878137, auc_completion:0.963657, avg_reader_cost: 0.00005 sec, avg_batch_cost: 0.00558 sec, avg_samples: 32.00000, ips: 5739.74703 ins/s
2022-06-07 14:31:50,695 - INFO - epoch: 0 done, auc_like: 0.878244,auc_completion: 0.963814, epoch time: 37.19 s
2022-06-07 14:31:50,698 - INFO - Already save model in output_model_share_btm_all/0
2022-06-07 14:31:50,736 - INFO - epoch: 1, batch_id: 0, auc_like:0.000000, auc_completion:1.000000, avg_reader_cost: 0.00013 sec, avg_batch_cost: 0.00026 sec, avg_samples: 0.32000, ips: 1230.62145 ins/s
2022-06-07 14:31:51,329 - INFO - epoch: 1, batch_id: 100, auc_like:0.921579, auc_completion:0.982940, avg_reader_cost: 0.00005 sec, avg_batch_cost: 0.00577 sec, avg_samples: 32.00000, ips: 5543.57338 ins/s
2022-06-07 14:31:51,916 - INFO - epoch: 1, batch_id: 200, auc_like:0.920709, auc_completion:0.984675, avg_reader_cost: 0.00005 sec, avg_batch_cost: 0.00571 sec, avg_samples: 32.00000, ips: 5601.36752 ins/s
2022-06-07 14:31:52,506 - INFO - epoch: 1, batch_id: 300, auc_like:0.921973, auc_completion:0.984668, avg_reader_cost: 0.00005 sec, avg_batch_cost: 0.00574 sec, avg_samples: 32.00000, ips: 5573.01588 ins/s
2022-06-07 14:31:53,094 - INFO - epoch: 1, batch_id: 400, auc_like:0.924560, auc_completion:0.983664, avg_reader_cost: 0.00005 sec, avg_batch_cost: 0.00572 sec, avg_samples: 32.00000, ips: 5589.90851 ins/s
2022-06-07 14:31:53,688 - INFO - epoch: 1, batch_id: 500, auc_like:0.925337, auc_completion:0.983675, avg_reader_cost: 0.00005 sec, avg_batch_cost: 0.00579 sec, avg_samples: 32.00000, ips: 5531.34619 ins/s
2022-06-07 14:31:54,286 - INFO - epoch: 1, batch_id: 600, auc_like:0.924139, auc_completion:0.982966, avg_reader_cost: 0.00005 sec, avg_batch_cost: 0.00583 sec, avg_samples: 32.00000, ips: 5486.58959 ins/s
4.2.2 MMoE
MMoE采用了类似集成学习的思想,用若干个专家模型(expert model)加权影响子任务,门控机制(Gate)就是训练不同专家的影响因子,最终通过softmax输出不同专家的权重。如果对于所有子任务只有一套Gate就是MoE模型,但是更好的处理方式是每个子任务都有一个属于自己的Gate,升级为MMoE模型,详细的模型示意图见下图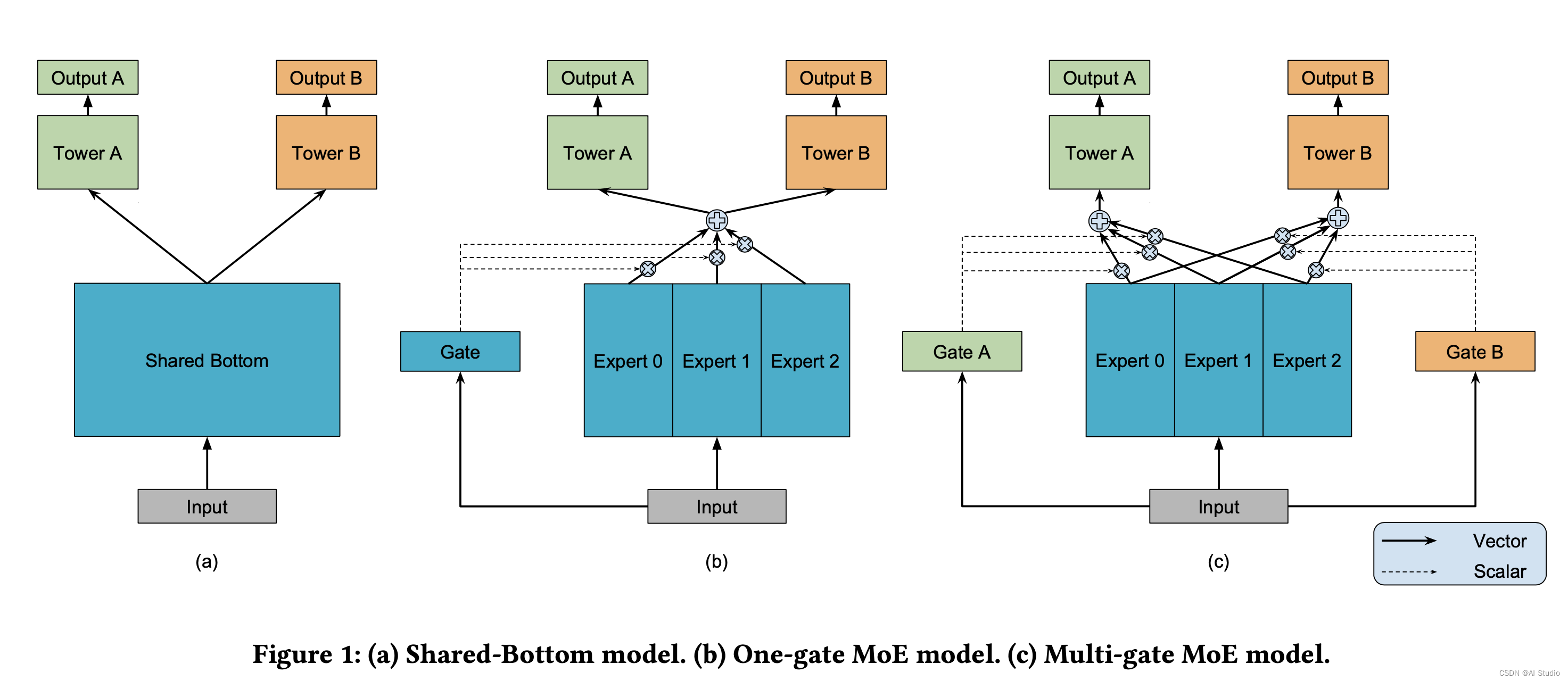
In [ ]
cd …/mmoe/
mmoe模型网络结构搭建代码如下:
class MMoELayer(nn.Layer):
def init(self, feature_size, expert_num, expert_size, tower_size,
gate_num):
super(MMoELayer, self).init()
self.expert_num = expert_num
self.expert_size = expert_size
self.tower_size = tower_size
self.gate_num = gate_num
self._param_expert = []
for i in range(0, self.expert_num):
linear = self.add_sublayer(
name='expert_' + str(i),
sublayer=nn.Linear(
feature_size,
expert_size,
#initialize the weight randly
weight_attr=nn.initializer.XavierUniform(),
bias_attr=nn.initializer.Constant(value=0.1),
#bias_attr=paddle.ParamAttr(learning_rate=1.0),
name='expert_' + str(i)))
self._param_expert.append(linear)
self._param_gate = []
self._param_tower = []
self._param_tower_out = []
for i in range(0, self.gate_num):
linear = self.add_sublayer(
name='gate_' + str(i),
sublayer=nn.Linear(
feature_size,
expert_num,
#initialize the weight randly
weight_attr=nn.initializer.XavierUniform(),
bias_attr=nn.initializer.Constant(value=0.1),
#bias_attr=paddle.ParamAttr(learning_rate=1.0),
name='gate_' + str(i)))
self._param_gate.append(linear)
linear = self.add_sublayer(
name='tower_' + str(i),
sublayer=nn.Linear(
expert_size,
tower_size,
#initialize the weight randly
weight_attr=nn.initializer.XavierUniform(),
bias_attr=nn.initializer.Constant(value=0.1),
#bias_attr=paddle.ParamAttr(learning_rate=1.0),
name='tower_' + str(i)))
self._param_tower.append(linear)
linear = self.add_sublayer(
name='tower_out_' + str(i),
sublayer=nn.Linear(
tower_size,
2,
#initialize the weight randly
weight_attr=nn.initializer.XavierUniform(),
bias_attr=nn.initializer.Constant(value=0.1),
name='tower_out_' + str(i)))
self._param_tower_out.append(linear)
def forward(self, input_data):
expert_outputs = []
for i in range(0, self.expert_num):
linear_out = self._param_expert[i](input_data)
expert_output = F.relu(linear_out)
expert_outputs.append(expert_output)
expert_concat = paddle.concat(x=expert_outputs, axis=1)
expert_concat = paddle.reshape(
expert_concat, [-1, self.expert_num, self.expert_size])
output_layers = []
for i in range(0, self.gate_num):
cur_gate_linear = self._param_gate[i](input_data)
cur_gate = F.softmax(cur_gate_linear)
cur_gate = paddle.reshape(cur_gate, [-1, self.expert_num, 1])
cur_gate_expert = paddle.multiply(x=expert_concat, y=cur_gate)
cur_gate_expert = paddle.sum(x=cur_gate_expert, axis=1)
cur_tower = self._param_tower[i](cur_gate_expert)
cur_tower = F.relu(cur_tower)
out = self._param_tower_out[i](cur_tower)
out = F.softmax(out)
out = paddle.clip(out, min=1e-15, max=1.0 - 1e-15)
output_layers.append(out)
return output_layers
In [ ]
动态图训练
! python -u …/…/…/tools/trainer.py -m config_bigdata.yaml
动态图预测
! python -u …/…/…/tools/infer.py -m config_bigdata.yaml
4.2.3 CGC/PLE
为了解决跷跷板现象(一部分任务效果变好,另一部分效果变差)PLE模型在MMoE的基础上新增了每个任务独有的expert 专家,用来强化自己任务的特性,gate网络用来学习每个子任务的独有expert和共享expert联合的权重,这是单层CGC模型。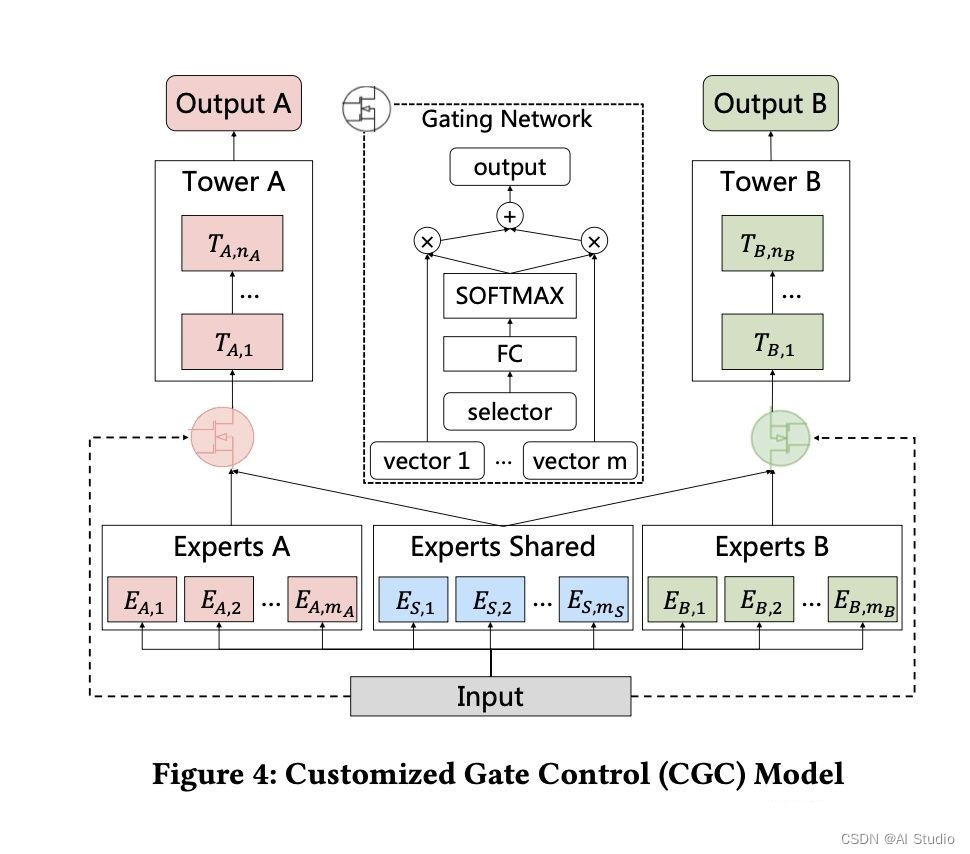
PLE的多层的CGC,与CGC不同的是考虑了不同expert的交互性,在底层的Extraction网络中有一个share gate,他的输入不再是cgc的独有expert和share expert,而是全部expert . 详细模型示意图见下图。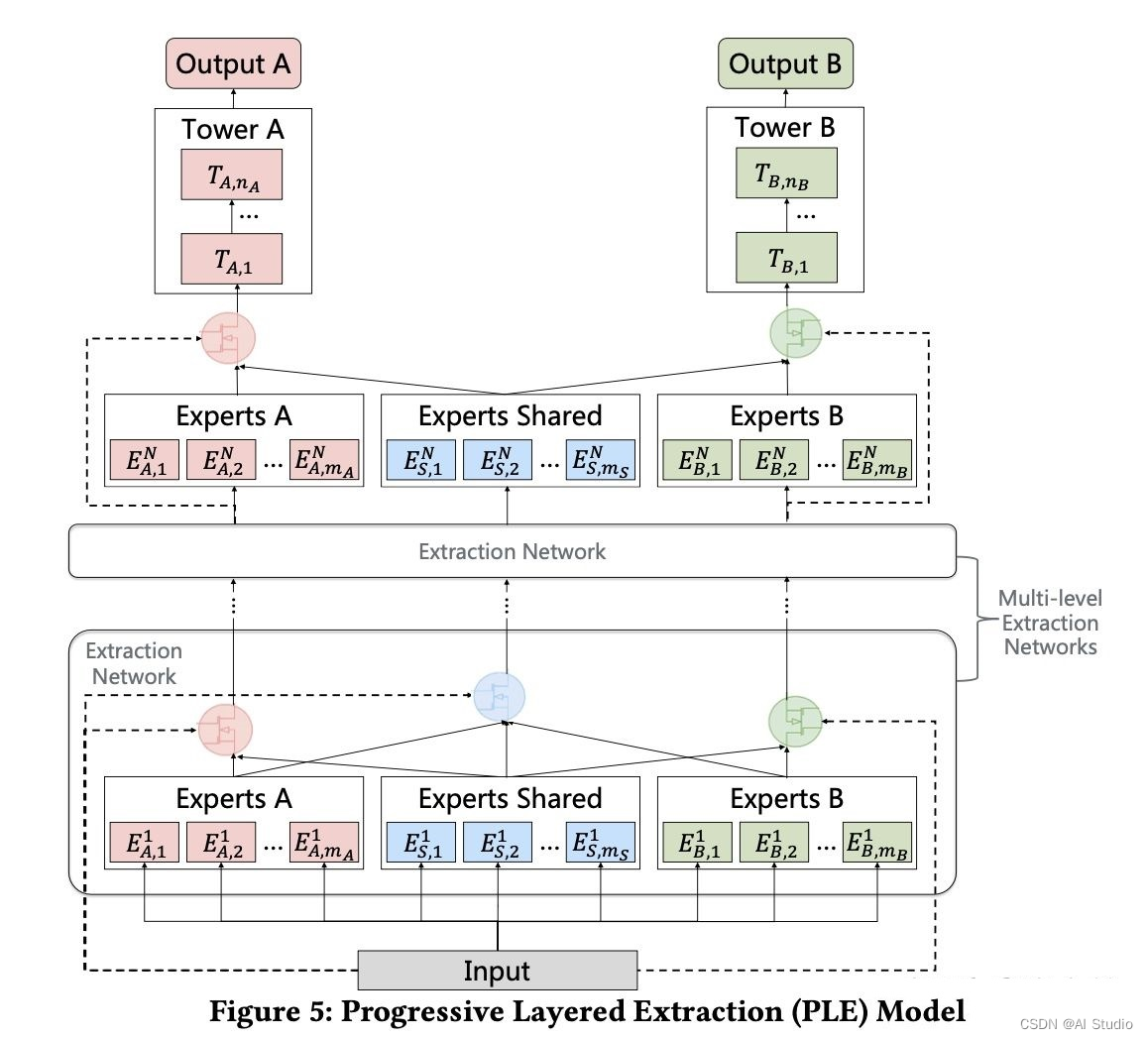
In [ ]
cd …/ple/
mmoe模型网络结构搭建代码如下:
class PLELayer(nn.Layer):
def init(self, feature_size, task_num, exp_per_task, shared_num,
expert_size, tower_size, level_number):
super(PLELayer, self).init()
self.task_num = task_num
self.exp_per_task = exp_per_task
self.shared_num = shared_num
self.expert_size = expert_size
self.tower_size = tower_size
self.level_number = level_number
# ple layer
self.ple_layers = []
for i in range(0, self.level_number):
if i == self.level_number - 1:
ple_layer = self.add_sublayer(
name='lev_' + str(i),
sublayer=SinglePLELayer(
feature_size, task_num, exp_per_task, shared_num,
expert_size, 'lev_' + str(i), True))
self.ple_layers.append(ple_layer)
break
else:
ple_layer = self.add_sublayer(
name='lev_' + str(i),
sublayer=SinglePLELayer(
feature_size, task_num, exp_per_task, shared_num,
expert_size, 'lev_' + str(i), False))
self.ple_layers.append(ple_layer)
feature_size = expert_size
# task tower
self._param_tower = []
self._param_tower_out = []
for i in range(0, self.task_num):
linear = self.add_sublayer(
name='tower_' + str(i),
sublayer=nn.Linear(
expert_size,
tower_size,
#initialize the weight randly
weight_attr=nn.initializer.XavierUniform(),
bias_attr=nn.initializer.Constant(value=0.1),
#bias_attr=paddle.ParamAttr(learning_rate=1.0),
name='tower_' + str(i)))
self._param_tower.append(linear)
linear = self.add_sublayer(
name='tower_out_' + str(i),
sublayer=nn.Linear(
tower_size,
2,
#initialize the weight randly
weight_attr=nn.initializer.XavierUniform(),
bias_attr=nn.initializer.Constant(value=0.1),
name='tower_out_' + str(i)))
self._param_tower_out.append(linear)
def forward(self, input_data):
inputs_ple = []
# task_num part + shared part
for i in range(0, self.task_num + 1):
inputs_ple.append(input_data)
# multiple ple layer
ple_out = []
for i in range(0, self.level_number):
ple_out = self.ple_layers[i](inputs_ple)
inputs_ple = ple_out
#assert len(ple_out) == self.task_num
output_layers = []
for i in range(0, self.task_num):
cur_tower = self._param_tower[i](ple_out[i])
cur_tower = F.relu(cur_tower)
out = self._param_tower_out[i](cur_tower)
out = F.softmax(out)
out = paddle.clip(out, min=1e-15, max=1.0 - 1e-15)
output_layers.append(out)
return output_layers
In [ ]
动态图训练
! python -u …/…/…/tools/trainer.py -m config_bigdata.yaml
动态图预测
! python -u …/…/…/tools/infer.py -m config_bigdata.yaml
5 结果展示
经过如上三轮运算,我们使用同一个短视频数据集(很重要,可比较)训练了三个模型。并对短视频的点赞率和完播率进行了预测。得到的结果入下表所示
模型 点赞率任务的AUC 完播率任务的AUC
share_bottom 0.946 0.993
mmoe 0.957 0.994
ple 0.966 0.997
我们以一条数据为例,直观的向大家展示一下推荐的效果,此时由于三个模型的预测结果均正确,仅为概率上的不同,故仅使用share_bottom模型做出预测来展示:
1,0,18,0,0,0,0,991.95,0,0,2,0,95,0,0,0,1,0,0,0,0,0,1,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,1,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,1,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,1,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,1,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,1,0,0,0,0,0,0,0,0,0,1,0,0,0,1,0,0,0,0,0,0,0,0,0,1,0,0,1,0,0,0,0,1,0,0,0,0,1,0,0,0,0,0,0,0,0,0,1,0,0,0,0,1,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,1,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,1,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,1,0,0,0,0,0,0,0,1,0,0,0,0,0,0,0,0,0,1,0,0,0,0,0,0,0,0,1,0,0,0,0,0,0,0,0,0,0,1,0,1,0,0,0,0,0,0,0,1,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,1,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,1,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,1,0,1,0,0,0,0,0,1,0
在config_bigdata.yaml中做出相应的调整,将“test_data_dir”数据读取路径设置为该条数据的路径,并将“infer_batch_size”设置为1。在“dygrapoh_model.py”中的“infer_forward”部分添加相应的print语句,输出模型预测该用户是否点赞该视频,以及是否完能够看完该视频?
预测结果如下:
模型精确的同时判断了该用户会看完该视频,但是并不会点赞。 我们可以合理猜测,这位用户是否是在偷偷看游戏视频,又害怕被女朋友查到手机【滑稽笑】
6 改进方向
(1)如何确定超参,如expert数和专家模型的实现方案?
实际的expert模型和gate模型都不是固定的,最常见的就是多层FC网络组成的mlp,具体实现可以参考PaddleRec/MMoE 但是在相同的参数规模下,gate模型建议不要太简单,一般直接输出softmax不是最好的方式,在我们的实践中,当gate网络由一层fc升级为3层fc(gate网络参数增大,expert网络参数减少)时效果有明显提升。
expert专家数量根据我们的对比实验(expert数量增大时,每个expert网络模型参数减少),一般呈现中间高两头低的现象,最佳的实验结果是expert专家数量在gate数量(子任务个数)1-2倍区间。对于具体的任务最好的方式还是多组实验对比。
(2) CGC还是PLE,和MMoE对比效果怎么样?
实践中单层CGC在相同参数规模下效果普遍要优于MMoE,从理论上也可以解释的通,毕竟增加了每个子任务各自的expert,对于相关性特别差的多任务,有一个专有的expert做"保底"。我们的实践中多层的PLE只有在个别场景下会好于CGC,所以很多情况下我们就直接采用CGC升级MMoE ,不过这个还是要具体实验一下。
(3) 新加子任务时的热启解决方案?
实践中经常会遇到需要增加任务或者修改模型的情况。实践中尝试过如下解决方案:
a. 完全冷启训练。这种适用于收敛较快,模型改动特别大的场景,尤其是对于sparse部分的修改。
b. 只热启sparse部分(embedding)。这是最常见的方式,一般增加目标的场景或者修改上层模型的场景下,sparse都是共享的,所以直接热启线上训练好的sparse表可以快速收敛,稳定性也更好。
c. 热启sparse部分和部分dense模型。比如只增加目标,不修改expert数量的场景下,直接热启expert专家模型的参数。这个在部分场景下适用,但不建议这样热启,因为当新增加一个任务或者修改上层模型后,整体的分布会改变,从之前的专家模型参数开始重新收敛并不一定比完全冷启expert专家模型效果更好,有可能会出现局部收敛陷阱,这个需要具体场景下的多组实验对比。
In [ ]
cd /home/aistudio
In [ ]
安装AutoLog依赖
!git clone https://github.com/LDOUBLEV/AutoLog
cur_pwd = !pwd
if str(cur_pwd[0]) != ‘/home/aistudio/AutoLog’:
%cd /home/aistudio/AutoLog/
!pip3 install -r requirements.txt
!python3 setup.py bdist_wheel
!pip3 install ./dist/auto_log-1.2.0-py3-none-any.whl
%cd …/
7 部署
7.1 使用save_inference_model接口保存模型
在服务器端使用python部署需要先使用save_inference_model接口保存模型。
首先需要在模型的yaml配置中,加入use_inference参数,并把值设置成True。use_inference决定是否使用save_inference_model接口保存模型,默认为否。若使用save_inference_model接口保存模型,保存下来的模型支持使用Paddle Inference的方法预测,但不支持直接使用paddlerec原生的的预测方法加载模型。
确定需要的输入和输出的预测模型变量,将其变量名以字符串的形式填入save_inference_feed_varnames和save_inference_fetch_varnames列表中。
以share_bottom模型为例,可以在其config.yaml文件中观察到如下结构。训练及测试数据集选用video数据集。
runner:
通用配置不再赘述
…
#use inference save model
use_inference: True # 静态图训练时保存为inference model
save_inference_feed_varnames: [“input”] # inference model 的feed参数的名字
save_inference_fetch_varnames: [“clip_0.tmp_0”, “clip_1.tmp_0”] # inference model 的fetch参数的名字
7.2 动转静导出模型
若您在使用动态图训练完成,希望将保存下来的模型转化为静态图inference,那么可以参考我们提供的to_static.py脚本。
首先正常使用动态图训练保存参数
进入模型目录
cd models/multitask/share_bottom # 在任意目录均可运行
动态图训练
python -u …/…/…/tools/trainer.py -m config.yaml # 全量数据运行config_bigdata.yaml
打开yaml配置,增加model_init_path选项
to_static.py脚本会先加载model_init_path地址处的模型,然后再转化为静态图保存。注意不要在一开始训练时就打开这个选项,不然会变成热启动训练。
更改to_static脚本,根据您的模型需求改写其中to_static语句。 这里我们为您准备好了share_bottom模型的to_static脚本。我们以share_bottom模型为例,在share_bottom模型的组网中,需要保存前向forward的部分,具体代码可参考net.py。其输入参数为499个‘float32’类型的用户特征组成的list。 所以我们在to_static脚本中的paddle.jit.to_static语句中指定input_spec如下所示。input_spec的详细用法:InputSpec 功能介绍。
example share_bottom model forward
dy_model = paddle.jit.to_static(dy_model,input_spec=[paddle.static.InputSpec(shape=[None, 499], dtype=‘float32’)])
运行to_static脚本, 参数为您的yaml文件,即可保存成功。将您在yaml文件中指定的model_init_path路径下的参数,转换并保存到model_save_path/(infer_end_epoch-1)目录下。
注:infer_end_epoch-1是因为epoch从0开始计数,如运行3个epoch即0~2
python -u …/…/…/tools/to_static_share_bottom.py -m config.yaml
将inference预测得到的prediction预测值和数据集中的label对比,使用另外的脚本计算auc指标即可。
7.3 使用推理库预测
paddlerec提供tools/paddle_infer.py脚本,供您方便的使用inference预测库高效的对模型进行预测。
启动paddle_infer.py脚本的参数:
名称 类型 取值 是否必须 作用描述
–model_file string 任意路径 是 模型文件路径(当需要从磁盘加载 Combined 模型时使用)
–params_file string 任意路径 是 参数文件路径 (当需要从磁盘加载 Combined 模型时使用)
–model_dir string 任意路径 是 模型文件夹路径 (当需要从磁盘加载非 Combined 模型时使用)
–use_gpu bool True/False 是 是否使用gpu
–data_dir string 任意路径 是 测试数据目录
–reader_file string 任意路径 是 测试时用的Reader()所在python文件地址
–batchsize int >= 1 是 批训练样本数量
–model_name str 任意名字 否 输出模型名字
–cpu_threads int >= 1 否 在使用cpu时指定线程数,在使用gpu时此参数无效
–enable_mkldnn bool True/False 否 在使用cpu时是否开启mkldnn加速,在使用gpu时此参数无效
–enable_tensorRT bool True/False 否 在使用gpu时是否开启tensorRT加速,在使用cpu时此参数无效
以share_bottom模型的demo数据为例,启动预测:
进入模型目录
cd models/multitask/share_bottom
python -u …/…/…/tools/paddle_infer.py --model_file=output_model_share_btm/2/tostatic.pdmodel --params_file=output_model_share_btm/2/tostatic.pdiparams --use_gpu=False --data_dir=data/train --reader_file=video_reader.py --batchsize=5

学大模型,用大模型上飞桨星河社区!每天8点V100G算力免费领!免费领取ERNIE 4.0 100w Token >>>
更多推荐



 0
0 0
0- 0



 已为社区贡献1436条内容
已为社区贡献1436条内容

所有评论(0)