
基于PaddleX的纸板缺陷检测
基于PaddleX的纸板缺陷检测
一、项目背景
随着物流行业和包装行业的快速发展,瓦楞纸板用量需求变得越来越大。当前纸板生产过程中,缺陷检测仍然依赖人眼,检测效率低、成本高,无法满足当前工业生产的要求。因此,采用机器视觉的方法代替人工检测已成为行业的迫切需求。纸板在生产过程中容易发生破损、起泡、划痕等一些缺陷,纸板加工成型后通过机器视觉进行检测,然后配合PLC或其他执行结构,可以将有缺陷的纸板挑选出来,避免残次品的出厂。目前纸板的质量检测都是通过人工进行的,既费时又增加了生产成本的投入。通过将机器视觉技术与纸板加工自动控制系统的结合可以有效解决这些问题,在提高纸板质量合格率,减少损失率的同时也降低了生产成本。该项目只是智能质检的一小部分,借助深度学习的快速发展助力智能制造。
二、PaddleX简介
PaddleX 集成飞桨智能视觉领域图像分类、目标检测、语义分割、实例分割任务能力,将深度学习开发全流程从数据准备、模型训练与优化到多端部署端到端打通,以极少的代码即可快速完成飞桨全流程开发。
PaddleX目前已经在质检、安防、巡检、遥感、零售、医疗等十多个行业实际应用场景验证,沉淀产业实际经验,并提供丰富的案例实践教程,全程助力开发者产业实践落地。
PaddleX更适合新入门的小白,或者没有python基础的传统机器视觉从业者,aistudio上也是有很多教程,十分钟教你入门PaddleX,当然这些便利来源于飞桨的开发人员的开源。
产品全景图: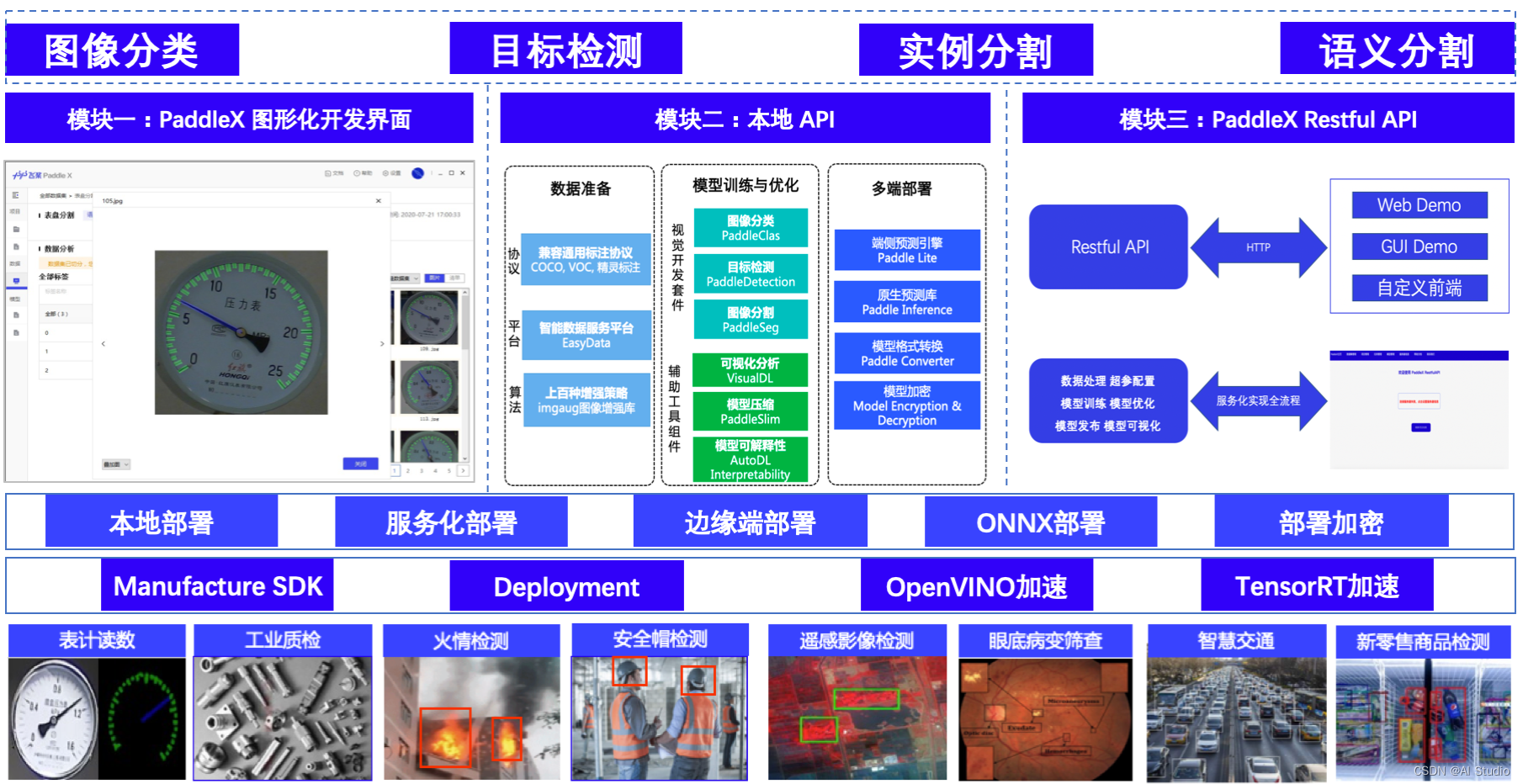
更多介绍:PaddleX
大家也可以使用GUI开发模式:图像化解决深度学习开发全流程,目前最新版本的GUI(Version 2.1.0)仅提供WIN和Linux版.
GUI开发教程
GUI教程学习笔记
三、算法
该项目大多应用在现场环境,大多会使用移动端部署。因此优先考率推理速度,部署方便,最终选择PicoDet
PicoDet论文
PicoDet代码
3.1 算法特色
精度高:PicoDet-S仅1M参数量以内,416输入COCO mAP达到30.6;PicoDet-L仅3.3M参数量以内,640输入COCO mAP达到40.9。是全网新SOTA移动端检测模型。
速度快:PicoDet-S-320在SD865上可达150FPS;PicoDet-L-640模型接近服务器端模型精度前提下,在移动端可达20FPS实时预测。
部署友好:支持Paddle Inference、Paddle Lite;支持快速导出为ONNX格式,可用于Openvino、NCNN、MNN部署;支持Python、C++、Android 部署。
3.2算法介绍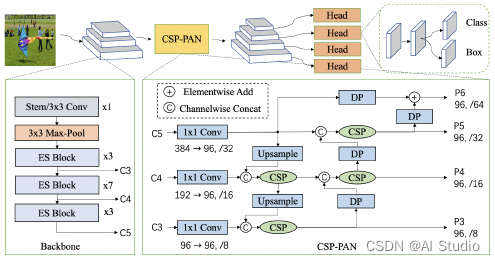
3.2.1骨干网络
遵循PP-LCNe的一些方法来增强网络结构,并构建了新的主干网络,称为ESNet(Enhanced ShuffleNet)。
SE模块能很好地对网络通道进行加权并获得更好的特征。因此,在所有blocks中加入了SE模块。类似于MobileNetV3,SE模块中两个layers的激活函数分别是ReLU和H-Sigmoid。Channel shuffle在ShuffleNetV2中提供了通道间的信息交换,但是也导致了特征融合的损失。为了解决这个问题,论文在stride为2时加入了 depthwise convolution和 pointwise convolution来结合不同通道的信息(图a)。GhostNet的作者提出了一种新型的Ghost模块能在较少参数量下产生更多特征图,从而提升网络的学习能力。论文在blocks中加入了Ghost模块并将stride设为1,来进一步增强ESNet的性能(图b)。
ES-Block如图所示: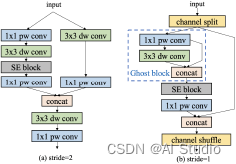
Neural Architecture Search(NAS),论文中没有去搜索一个较佳的分类器,而是在检测数据集上训练和搜索检测的超网络,从而介绍了大量计算并且达到检测而不是分类的最优。此框架仅需两步:
(1)在检测数据集上训练one-shot超网
(2)使用EA(evolutionary algorithm,进化算法)算法对训练好的超网络进行架构搜索。
3.2.2CSP-PAN和 detector head
本文使用PAN结构来获得多层特征图以及CSP结构来进行相邻特征图间的特征连接和融合。CSP结构被广泛用于YOLOv4和YOLOX的neck部分。在原始的CSP-PAN中,每个输出特征图的通道数与来自主干网络的输入特征图保持相同。对于移动设备来说,这样大通道数的结构具有昂贵的计算成本。为了解决这个问题,本文用1×1卷积使所有特征图中的通道数与最小的通道数相等,(也就是都设为96)。通过CSP结构实现top-down和bottom-up的特征融合。缩小的特征使得计算成本更低且不损失准确性。此外,论文还在原有CSP-PAN的顶部加入了一个特征图尺度分支来检测更多物体。与此同时,所有除了1×1卷积外的卷积层都使用 Depthwise Separable Convolution。深度可分离卷积使用5×5卷积扩大感受野。这种结构在使用很少参数的情况下给精度带来了大幅度提升。
在检测头中,论文使用 Depthwise Separable Convolution和5 × 5卷积来扩大感受野。深度可分离卷积的数量可以被设置为2、4或更多。Neck和head部分都有四个尺度分支。论文中head部分的通道数与neck部分保持一致,并将分类和回归分支耦合在一起。YOLOX使用参数更少的解耦预测头来提高精度。本文中耦合预测头在没有降低通道数时表现更好。参数和推理速度与检测头解耦基本相同。
3.2.3标签分配策略和损失函数
正负样本标签分配对目标检测模型有着本质的影响。大多数检测器使用fixed标签分配策略。论文中使用SimOTA动态标签分配策来优化训练过程。SimOTA首先通过中心点先验信息决定候选区域,之后计算候选区内真值跟预测框的IoU,最后对每个真值框将n个最大的IoU求和获得参数K。通过直接计算候选区内所有预测框跟真值框的损失作为代价矩阵。对于每个真值框,选最小K损失对应的锚点作为正样本。原始SimOTA使用CE-Loss和IoU-Loss的加权和来计算代价矩阵。为了跟SimOTA中的代价矩阵和目标函数对齐,论文中使用Varifocal-Loss和GIoU-Loss的加权和作为代价矩阵。GIoU-loss的权重为λ,这里设置为6。具体的公式为
cost=lossvfl+λlossgioucost = loss_{vfl} + \lambda loss_{giou}cost=loss
vfl
+λloss
giou
在检测head中,对于分类,论文中使用Varifocal-Loss来耦合分类预测和置信度预测。对于回归,论文使中用GIoU-Loss和Distribution-Focal-Loss。其公式如下:
loss=lossvfl+2lossgiou+0.25lossdflloss = loss_{vfl} + 2loss_{giou}+0.25loss_{dfl}loss=loss
vfl
+2loss
giou
+0.25loss
dfl
四、项目内容
主要给大家演示,如何利用PaddleX快速实现自己的开发需求
4.1 环境配置
这里的环境配置也是十分的简单,执行下面一条指令就可以了
In [ ]
!pip install paddlex
4.2数据准备
数据集中包含了1057张已经标注好的数据,标注格式为 VOC 。点击此处查看在这里插入图片描述
在这里插入图片描述

更多数据准备请参考目标检测数据标注说明
In [ ]
#解压数据集
!unzip -oq /home/aistudio/data/data146356/defect.zip
4.3数据集划分
将训练集、测试集按照8:2的比例划分。 PaddleX只需要一行代码,就可以代替我们之前那么长的数据集划分程序,通过对比就知道差距了,哈哈
配置好参数即可:
–split_dataset 指定功能 --format 数据集格式 -dataset_dir 数据集路径 --val_value 划分比例
In [ ]
#划分数据集0.8:0.2
!paddlex --split_dataset --format voc --dataset_dir defect/ --val_value 0.2
数据集切分前后的状态如下
4.4模型训练
模型的训练按照下面的这个流程图进行操作
4.4.1定义数据预处理
这里用到的是transform里的Compose类将我们使用的各种预处理/图像增强进行组合。该项目主要使用了RandomCrop():随机裁剪图像
RandomHorizontalFlip():随机水平翻转
RandomDistort():随机像素内容变换,可包括亮度、对比度、饱和度、色相角度、通道顺序的调整
BatchRandomResize():随机选取目标尺寸调整图像大小
Normalize():对图像进行标准化
transform API说明 说得已经非常详细了,其他这里不做过多介绍。
注意:预处理/数据增强并不是越多越好,而是适合最重要,大家在开发过程中可以根据自己数据集的不同进行合理选择。
4.4.2定义数据集路径
读取PascalVOC格式的检测数据集,并对样本进行相应的处理。 paddlex.datasets.VOCDetection
参数:
data_dir (str): 数据集所在的目录路径。
file_list (str): 描述数据集图片文件和对应标注文件的文件路径(文本内每行路径为相对data_dir的相对路径)。
label_list (str): 描述数据集包含的类别信息文件路径。
transforms (paddlex.transforms): 数据集中每个样本的预处理/增强算子,详见paddlex.transforms。
num_workers (int|str):数据集中样本在预处理过程中的进程数。默认为’auto’。当设为’auto’时,根据系统的实际CPU核数设置num_workers: 如果CPU核数的一半大于8,则num_workers为8,否则为CPU核数的一半。如果在aistudio上训练出错,将num_workers改为0
shuffle (bool): 是否需要对数据集中样本打乱顺序。默认为False。
allow_empty (bool): 是否加载无标注框的图片(即负样本)进行训练。默认为False。该参数设置为True时,也要求每个负样本都有对应的标注文件。
empty_ratio (float): 用于指定负样本占总样本数的比例。如果小于0或大于等于1,则保留全部的负样本。默认为1。
更多datasets说明
4.4.3 初始化模型
paddlex.det.PicoDet() 构建PicoDet检测器
主要参数:
num_classes (int): 类别数。
backbone (str): PicoDet的backbone网络,取值范围为[‘ESNet_s’, ‘ESNet_m’, ‘ESNet_l’, ‘LCNet’, ‘MobileNetV3’, ‘ResNet18_vd’]。
更多模型初始化说明
4.4.4 模型训练
更详细参数介绍与调整说明
In [ ]
import paddlex as pdx
from paddlex import transforms as T
定义训练和验证时的transforms
train_transforms = T.Compose([
T.RandomCrop(), T.RandomHorizontalFlip(), T.RandomDistort(),
T.BatchRandomResize(
target_sizes=[576, 608, 640, 672, 704], interp=‘RANDOM’), T.Normalize(
mean=[0.485, 0.456, 0.406], std=[0.229, 0.224, 0.225])
])
eval_transforms = T.Compose([
T.Resize(
target_size=640, interp=‘CUBIC’), T.Normalize(
mean=[0.485, 0.456, 0.406], std=[0.229, 0.224, 0.225])
])
定义训练和验证所用的数据集,将这些路径设置正确即可
train_dataset = pdx.datasets.VOCDetection(
data_dir=‘defect/’,
file_list=‘defect/train_list.txt’,
label_list=‘defect/labels.txt’,
transforms=train_transforms,
shuffle=True)
eval_dataset = pdx.datasets.VOCDetection(
data_dir=‘defect/’,
file_list=‘defect/val_list.txt’,
label_list=‘defect/labels.txt’,
transforms=eval_transforms,
shuffle=False)
初始化模型,并进行训练
num_classes = len(train_dataset.labels)
model = pdx.det.PicoDet(num_classes=num_classes, backbone=‘ESNet_l’)
#模型训练
model.train(
num_epochs=100,#训练代数
train_dataset=train_dataset,#训练集
train_batch_size=16,#bs
eval_dataset=eval_dataset,#验证集
pretrain_weights=‘COCO’,#预训练权重
learning_rate=.01,#学习率
warmup_steps=24,#学习率优化
warmup_start_lr=0.005,#起始学习率
save_interval_epochs=1,#保存间隔
lr_decay_epochs=[6, 8, 11],#学习率衰减间隔
use_ema=True,
save_dir=‘output/picodet_esnet_l’,#模型保存路径
use_vdl=True) #开启可视化
4.5训练可视化
由于使用的BML直接使用可视化工具即可查看训练结果,精度达到90.6%,仍有提升的空间。在这里插入图片描述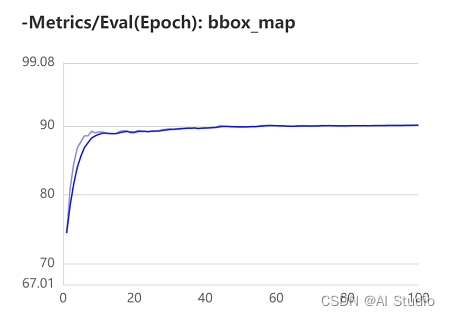
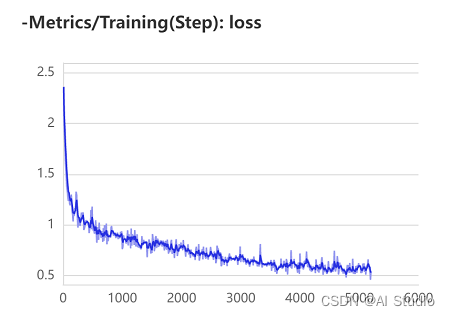
4.6模型推理
这里训练完成后或者预测后,需要重启一下释放内存(不知道为什么?回头填坑),否则会在model.predict()出错。
In [ ]
import paddlex as pdx
model = pdx.load_model(‘output/picodet_esnet_l/best_model’)
image_name = ‘defect/JPEGImages/0069.jpg’
result = model.predict(image_name)
pdx.det.visualize(image_name, result, threshold=0.5, save_dir=‘./output/’)
In [ ]
#把瑕疵检测结果保存在txt文件中
import glob
import numpy as np
import threading
import time
import random
import os
import base64
import cv2
import json
import paddlex as pdx
model = pdx.load_model(‘output/picodet_esnet_l/best_model’)
image_name = ‘defect/JPEGImages/0069.jpg’
img = cv2.imread(image_name)
result = model.predict(img)
keep_results = []
areas = []
f = open(‘result.txt’,‘a’)
count = 0
for dt in np.array(result):
cname, bbox, score = dt[‘category’], dt[‘bbox’], dt[‘score’]
if score < 0.5:
continue
keep_results.append(dt)
count+=1
f.write(str(dt)+‘\n’)
f.write(‘\n’)
areas.append(bbox[2] * bbox[3])
areas = np.asarray(areas)
sorted_idxs = np.argsort(-areas).tolist()
keep_results = [keep_results[k]
for k in sorted_idxs] if len(keep_results) > 0 else []
print(keep_results)
print(count)
f.write(“the total number is :”+str(int(count)))
f.close()
pdx.det.visualize(image_name, result, threshold=0.5, save_dir=‘./output/’)
预测结果
4.7模型导出
模型训练处理被保存在了output文件夹,此时模型文件还是动态图文档,需要导出成静态图的模型才可以进一步部署预测,运行如下命令,会自动在output文件夹下创建一个inference_model的文件夹,用来存放预测好的模型。
In [ ]
!paddlex --export_inference --model_dir=output/picodet_esnet_l/best_model --save_dir=output/inference_model
五、总结
本项目以很少的代码完成了项目需求中的模型训练部分,接下来是实际生产中的部署应用问题。利用深度学习代替传统行业的纸板质检,后面可以基于该项目做具体的纸板破损类型检测,根据故障类型和数量,反映生产线哪里出了问题,及时解决改善。提高纸板质量合格率同时也降低了生产成本。

学大模型,用大模型上飞桨星河社区!每天8点V100G算力免费领!免费领取ERNIE 4.0 100w Token >>>
更多推荐



 0
0 0
0- 0



 已为社区贡献1436条内容
已为社区贡献1436条内容

所有评论(0)