
[AI Workshop] 基于PaddleNLP的web端文本纠错系统
转自AI Studio,原文链接:[AI Workshop] 基于PaddleNLP的web端文本纠错系统 - 飞桨AI Studio基于PaddleNLP的web端文本纠错系统演示视频传送门:基于PaddleNLP的web端文本纠错系统_哔哩哔哩_bilibili一.项目介绍1.1 引言:本次项目分享来源于最近参加的【飞桨校园AI Day】AI Workshop活动,团队名:Soplaying,
转自AI Studio,原文链接:[AI Workshop] 基于PaddleNLP的web端文本纠错系统 - 飞桨AI Studio
基于PaddleNLP的web端文本纠错系统
演示视频传送门: 基于PaddleNLP的web端文本纠错系统_哔哩哔哩_bilibili
一.项目介绍
1.1 引言:
本次项目分享来源于最近参加的【飞桨校园AI Day】AI Workshop活动,团队名:Soplaying,选择项目命题为“文档纠错程序”。其课题主要要求为:训练文档纠错数据集,并开发部署程序,实现上传word文件输出纠错结果。
目前主要实现了文本纠错模型的训练以及前后端分离式的web端部署,支持输入文本或上传word文档,显示纠错后文本结果与保存。通过本项目的学习你也将能够收获一套简易通用的模型web端部署方案,从而在后续完整项目开发或软件开发比赛中更加游刃有余。
感谢课题导师坑姐(深渊上的坑)的创意课题提供与指导。
1.2 项目意义:
中文文本纠错(CSC)任务是一项NLP基础任务,其输入是一个可能含有语法错误的中文句子,输出是一个正确的中文句子。其目的是提高语言正确性的同时有效减少人工校验成本。对于政务公文、新闻出版等行业来说文本纠错更是内容安全的首当其冲的一面,重要程度不言而喻。在通用领域中,中文文本纠错问题是从互联网起始时就一直在解决的问题。如何覆盖各种不同的错误类型,如何应对不同场景下的文本差异,对于文本纠错来说都是一项很有挑战性的工作。同时,文本纠错技术有着广泛的应用场景,值得我们长期投入时间和精力进行研究与打磨。
在避免文本错误上,人工智能比人类更具优势,它能够记住大量的数据,且不会被糟心事影响情绪,不仅能基于客观现实执行任务,还能够比人类更好地评估和权衡相关因素,比人类更快、更准确地识别。基于深度学习方案搭建更精确的智能文本纠错模型,设计一款针对以中文为母语的用户所使用的优质“文本纠错”系统,自动对输入文本进行纠错,可以更好地让政府机构工作人员、媒体人、文字撰稿人、编辑、律师等职业从繁杂的文字“找茬”任务中脱离出来,有效降低内容风险。
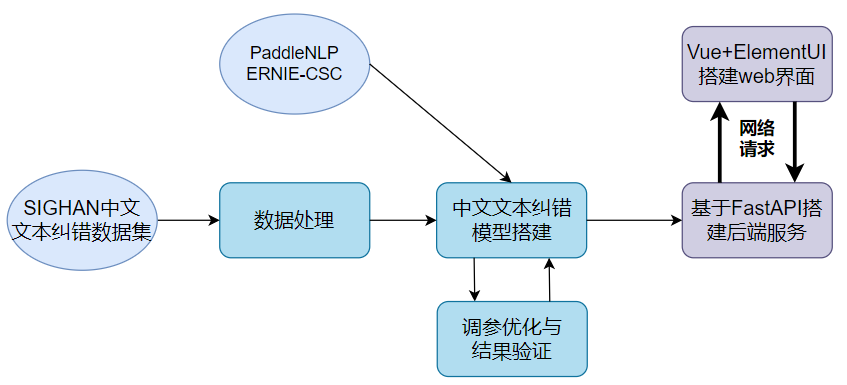
1.3 技术路线:
a.基于PaddleNLP的ERNIE模型在SIGHAN数据集完成中文文本纠错模型的训练。
b.基于FastAPI完成模型部署,开放为后端Restful API接口服务,并通过Postman对接口逻辑和功能进行测试。
c.基于Vue+ElementUI搭建高可扩展的文本纠错系统web界面,并通过网络请求对接后端API接口实现前后端联调。
1.4 系统源码说明:
完整项目源码为便于管理与下载,已通过数据集的方式项目挂载。源码地址:基于PaddleNLP的web端文本纠错系统 - 飞桨AI Studio
感兴趣的可以将其下载到本地解压后根据提供的"项目说明文档.txt"进行项目环境配置操作。项目运行过程中遇到问题欢迎在评论区向我反馈。
希望本项目能够对大家有所帮助,感兴趣的希望可以Fork、喜欢、关注三连❤
In [1]
# 完整项目通过数据集的方式挂载项目
# 下面对其进行解压与查看
%cd /home/aistudio/data/data146957/
!unzip ErrorCorrectionSystem.zip源码目录文件说明:
a.backend文件夹为后端API服务模块,其中best_model文件夹存放基于PaddleNLP训练好的文本纠错模型参数。main.py为后端API服务主程序。
b.frontend文件夹为文本纠错系统web前端界面模块,/src/views下存放搭建的页面。
c.项目说明文档.txt:对整个项目环境配置进行了详细地介绍,项目必看!
二.基于PaddleNLP的文本纠错模型训练
关于文本纠错模型如何从零开始训练,坑姐往期项目:ERNIE for CSC:【的、地、得】傻傻分不清?救星来了! 已经进行了详细的介绍,故此处不再过多展开。
本模块主要介绍基于PaddleNLP加载训练好的文本纠错模型进行文本纠错演示。
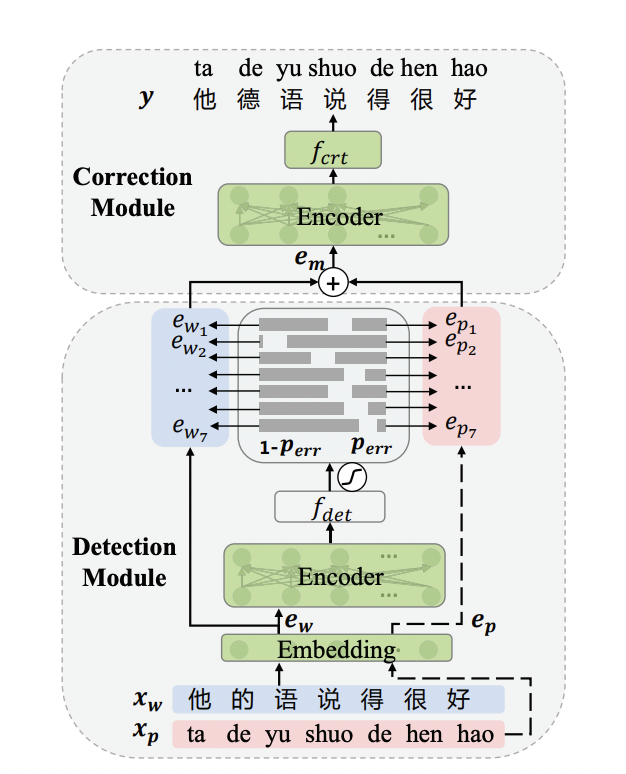
端到端文本纠错模型结构如下图所示,包括Detection Module和Correction Module2个部分:
-
Detection Module 错误检测模块:输入: 待纠错句子;输出: 错误检测标签。
-
Correction Module 错误纠正模块: 输入: 单词嵌入+拼音嵌入;输出: 纠错后结果。
参考学习资料:
Correcting Chinese Spelling Errors with Phonetic Pre-training
2021ACL中文文本纠错论文:Correcting Chinese Spelling Errors with Phonetic Pre-training 论文笔记
In [2]
# 下载所需依赖包
!pip install --upgrade paddlenlp
!pip install pypinyin --upgradeIn [3]
# 进入到backend 后端服务文件夹下
%cd /home/aistudio/data/data146957/backend/home/aistudio/data/data146957/backend
In [4]
# 查看当前路径下文件
# ps: best_model文件夹下存放训练好导出的静态图文本纠错模型参数
!lsbest_model demo2.py predict.py sutil.py demo1.py main.py resource utils.py
In [5]
from paddlenlp.transformers import ErnieTokenizer
from paddlenlp.data import VocabIn [6]
import argparse
import numpy as np
from functools import partial
import paddle
import paddlenlp as ppnlp
from paddle import inference
from paddlenlp.data import Stack, Tuple, Pad, Vocab
from paddlenlp.transformers import ErnieTokenizer
from utils import convert_example, parse_decode
# 对文本纠错模型预测进行封装
class Predictor(object):
def __init__(self, model_file, params_file, device, max_seq_length,
tokenizer, pinyin_vocab):
self.max_seq_length = max_seq_length
config = paddle.inference.Config(model_file, params_file)
if device == "gpu":
# set GPU configs accordingly
config.enable_use_gpu(100, 0)
elif device == "cpu":
# set CPU configs accordingly,
# such as enable_mkldnn, set_cpu_math_library_num_threads
config.disable_gpu()
config.switch_use_feed_fetch_ops(False)
self.predictor = paddle.inference.create_predictor(config)
self.input_handles = [
self.predictor.get_input_handle(name)
for name in self.predictor.get_input_names()
]
self.det_error_probs_handle = self.predictor.get_output_handle(
self.predictor.get_output_names()[0])
self.corr_logits_handle = self.predictor.get_output_handle(
self.predictor.get_output_names()[1])
self.tokenizer = tokenizer
self.pinyin_vocab = pinyin_vocab
def predict(self, data, batch_size=1):
"""
Predicts the data labels.
Args:
data (obj:`List(Example)`): The processed data whose each element is a Example (numedtuple) object.
A Example object contains `text`(word_ids) and `seq_len`(sequence length).
batch_size(obj:`int`, defaults to 1): The number of batch.
Returns:
results(obj:`dict`): All the predictions labels.
"""
examples = []
texts = []
trans_func = partial(
convert_example,
tokenizer=self.tokenizer,
pinyin_vocab=self.pinyin_vocab,
max_seq_length=self.max_seq_length,
is_test=True)
batchify_fn = lambda samples, fn=Tuple(
Pad(axis=0, pad_val=self.tokenizer.pad_token_id, dtype='int64'), # input
Pad(axis=0, pad_val=self.tokenizer.pad_token_type_id, dtype='int64'), # segment
Pad(axis=0, pad_val=self.pinyin_vocab.token_to_idx[self.pinyin_vocab.pad_token], dtype='int64'), # pinyin
Stack(axis=0, dtype='int64'), # length
): [data for data in fn(samples)]
for text in data:
example = {"source": text.strip()}
input_ids, token_type_ids, pinyin_ids, length = trans_func(example)
examples.append((input_ids, token_type_ids, pinyin_ids, length))
texts.append(example["source"])
batch_examples = [
examples[idx:idx + batch_size]
for idx in range(0, len(examples), batch_size)
]
batch_texts = [
texts[idx:idx + batch_size]
for idx in range(0, len(examples), batch_size)
]
results = []
for examples, texts in zip(batch_examples, batch_texts):
token_ids, token_type_ids, pinyin_ids, length = batchify_fn(
examples)
self.input_handles[0].copy_from_cpu(token_ids)
self.input_handles[1].copy_from_cpu(pinyin_ids)
self.predictor.run()
det_error_probs = self.det_error_probs_handle.copy_to_cpu()
corr_logits = self.corr_logits_handle.copy_to_cpu()
det_pred = det_error_probs.argmax(axis=-1)
char_preds = corr_logits.argmax(axis=-1)
for i in range(len(length)):
pred_result = parse_decode(texts[i], char_preds[i], det_pred[i],
length[i], self.tokenizer,
self.max_seq_length)
results.append(''.join(pred_result))
return resultsIn [7]
# 加载训练好的文本纠错模型去完成纠错任务
tokenizer = ErnieTokenizer.from_pretrained("ernie-1.0")
pinyin_vocab = Vocab.load_vocabulary("./best_model/pinyin_vocab.txt", unk_token='[UNK]', pad_token='[PAD]')
# 配置:训练好的静态图模型参数地址,cpu/gpu配置,max_seq_len
predictor = Predictor('./best_model/static_graph_params.pdmodel', './best_model/static_graph_params.pdiparams',
'cpu', 128, tokenizer, pinyin_vocab)In [8]
import re
# 基于正则实现精细中文分句,解决单段文本过长问题
def cut_sent(para):
para = re.sub('([。!?\?])([^”’])', r"\1\n\2", para) # 单字符断句符
para = re.sub('(\.{6})([^”’])', r"\1\n\2", para) # 英文省略号
para = re.sub('(\…{2})([^”’])', r"\1\n\2", para) # 中文省略号
para = re.sub('([。!?\?][”’])([^,。!?\?])', r'\1\n\2', para)
# 如果双引号前有终止符,那么双引号才是句子的终点,把分句符\n放到双引号后,注意前面的几句都小心保留了双引号
para = para.rstrip() # 段尾如果有多余的\n就去掉它
# 很多规则中会考虑分号;,但是这里我把它忽略不计,破折号、英文双引号等同样忽略,需要的再做些简单调整即可。
return para.split("\n")In [9]
# 要进行纠错的文本
samples = [
'遇到逆竟时,我们必须勇于面对,而且要愈挫愈勇,这样我们才能朝著成功之路前进。',
'人生就是如此,经过磨练才能让自己更加拙壮,才能使自己更加乐观。',
]In [10]
# 文本纠错
results = predictor.predict(samples, batch_size=2)
# 输出纠错结果
for source, target in zip(samples, results):
print("要纠错的文本为:", source)
print("纠错后的文本为:", target)
print('\n')要纠错的文本为: 遇到逆竟时,我们必须勇于面对,而且要愈挫愈勇,这样我们才能朝著成功之路前进。 纠错后的文本为: 遇到逆境时,我们必须勇于面对,而且要愈挫愈勇,这样我们才能朝著成功之路前进。 要纠错的文本为: 人生就是如此,经过磨练才能让自己更加拙壮,才能使自己更加乐观。 纠错后的文本为: 人生就是如此,经过磨练才能让自己更加茁壮,才能使自己更加乐观。
三.基于PaddleNLP+FastAPI搭建后端API服务
本模块主要介绍基于FastAPI完成模型部署与后端Restful API接口的开放,并通过Postman对接口功能和逻辑进行测试。
3.1 基于FastAPI搭建后端Restful API接口
后端服务主程序核心关注backend/main.py文件!
对FastAPI后端框架不熟悉的话,建议先学习下其官方文档:FastAPI
解决跨域问题:
# 设置允许跨域请求,解决前后端联调时频繁遇到的跨域问题
app.add_middleware(
CORSMiddleware,
allow_origins=['*'],
allow_credentials=True,
allow_methods=["*"],
allow_headers=["*"],
)
后端API接口处理定义:
# 定义请求体数据类型:发送请求字段为text,类型为字符串
class Document(BaseModel):
text: str
# 定义路径操作装饰器:POST方法 + API接口路径
@app.post("/v1/errorCorrect/", status_code=200)
# 定义路径操作函数,当接口被访问将调用该函数
async def ErrorCorrection(document: Document):
try:
# 获取前端请求发送的要进行纠错的文本内容
text = document.text
# 精细分句处理以更好处理长文本
data = cut_sent(text)
# 调用训练好的文本纠错模型进行纠错
result = predictor.predict(data, batch_size=2)
# 拼接分句后结果
correctionResult = ''
for temp in result:
if temp is not '':
correctionResult += temp;
correctionResult += '\n';
# correctionResult = "\n".join(result)
# 接口结果返回
results = {"message": "success", "originalText": document.text, "correctionResults": correctionResult}
return results
# 异常处理
except Exception as e:
print("异常信息:", e)
raise HTTPException(status_code=500, detail="请求失败,服务器端异常!")
启动后端服务:
运行python main.py

此时后端项目启动成功,注意此处127.0.0.1为本地地址。有服务器的小伙伴可以尝试将项目部署到服务器公网IP,便于接口服务的开放。
本次项目创建的API接口地址为http://127.0.0.1:8000/v1/errorCorrect ,HTTP请求方法为POST,接下来将对刚才创建开放的API接口进行接口测试。
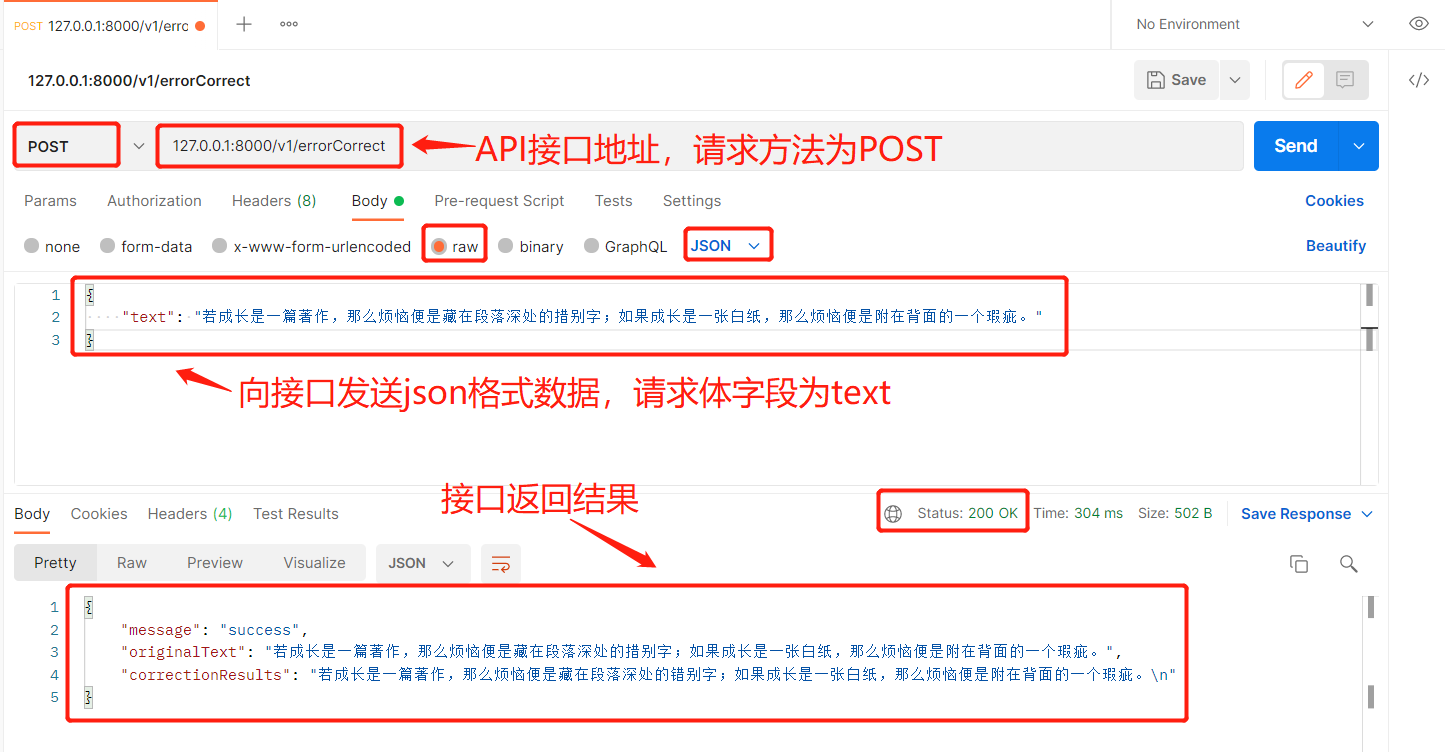
3.2 Postman接口测试
Postman是一款支持http协议的接口调试与测试工具,其主要特点就是功能强大,使用简单且易用性好 。使用教程:Postman工具使用教程
接下来将通过Postman软件对刚才搭建的API接口服务进行简单测试,测试API接口逻辑功能和结果返回是否正常。
四.基于Vue+ElementUI搭建纠错系统web界面
本模块主要介绍基于Vue+ElementUI完成文本纠错系统web界面搭建,并通过Axios发送网络请求对接后端API接口完成前后端的联调。
前端界面上基于vue-admin模板搭建:vue-admin-template
前端界面搭建上核心关注src/router/index.js和src/views/,router中定义了界面路由,views下为搭建的新界面。
对Vue或ElementUI不熟悉的建议先学习下其官方文档:
VUE官方文档:Vue.js
ElementUI文档:Element - The world's most popular Vue UI framework
前端上通过axios向后端API接口发送网络请求及界面数据更新
// 文本纠错功能函数
errorCorrect() {
var that = this
// 获取输入的要进行文本纠错的文本
var context = that.textarea
// 数据为空时弹窗提示输入
if (context === '') {
this.$message({
showClose: true,
message: '输入文本内容不能为空',
type: 'warning'
})
// 清空和隐藏文本纠错结果
that.result = ''
that.visible = false
} else {
// 请求后端API服务,请求方法为post,请求体字段为json格式 text
axios.post('http://127.0.0.1:8000/v1/errorCorrect', {
text: that.textarea
}).then((response) => {
// 获取接口返回结果并动态更新页面数据
console.log(response.data)
that.result = response.data.correctionResults
that.visible = true
that.$message({
showClose: true,
message: '文本纠错完成!',
type: 'success'
})
}).catch((error) => {
// 请求异常提示
console.log(error)
that.result = ''
that.visible = false
that.$message({
showClose: true,
message: '请求出现异常!',
type: 'error'
})
})
}
}
启动前端项目:
命令行窗口进入前端项目frontend目录后依次运行:
npm install
npm run dev
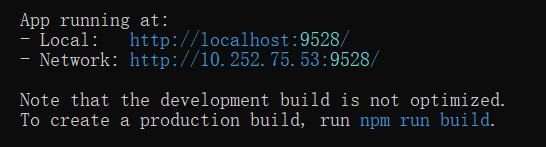
此时web前端系统启动成功,访问http://127.0.0.1:9528即可访问前端界面。
注意项目为前后端分离的,故完整演示需要启动前端和后端两大项目。
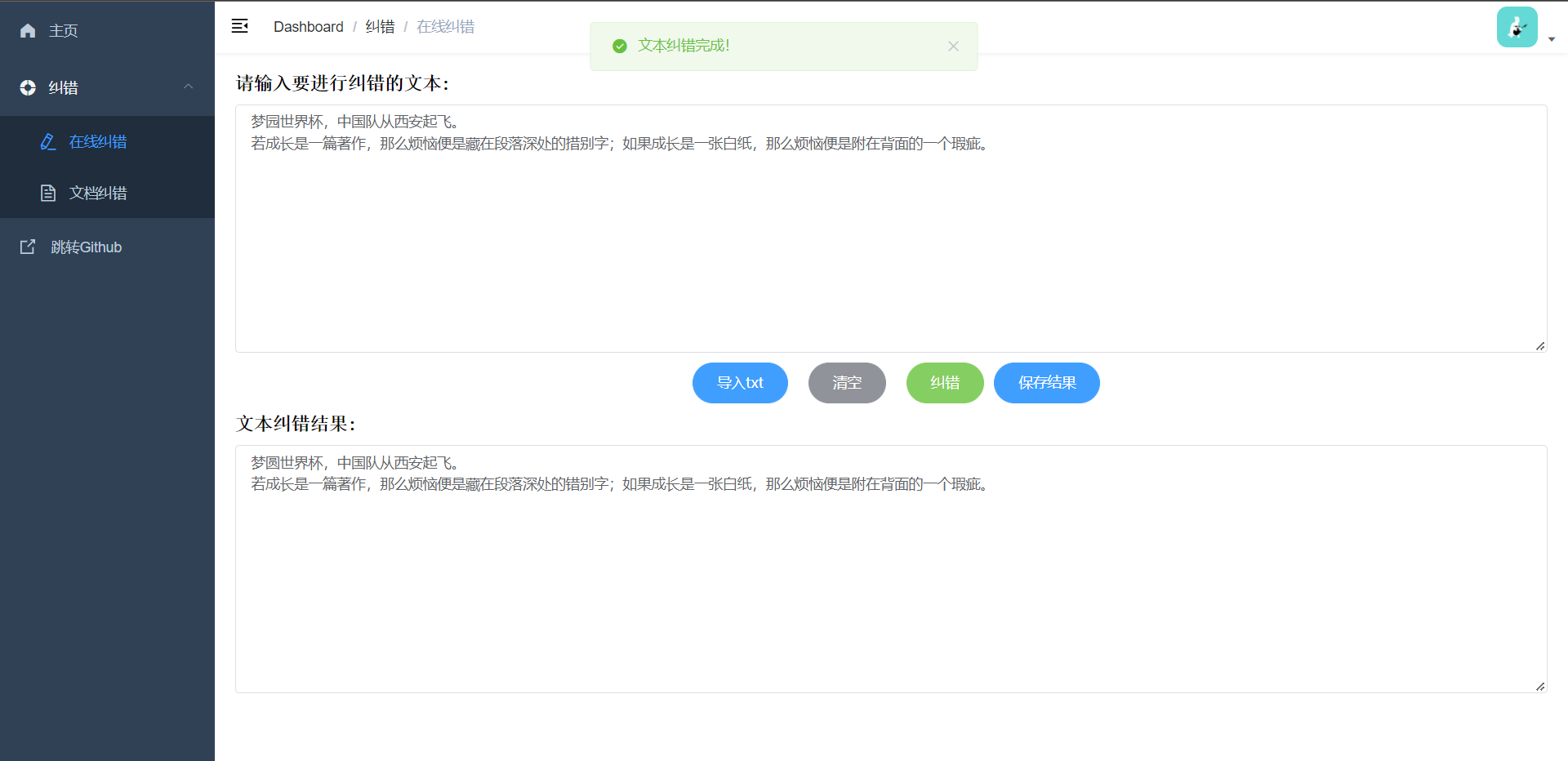
文本纠错演示:输入文本或上传txt导入内容,点击纠错后显示纠错后文本支持结果保存
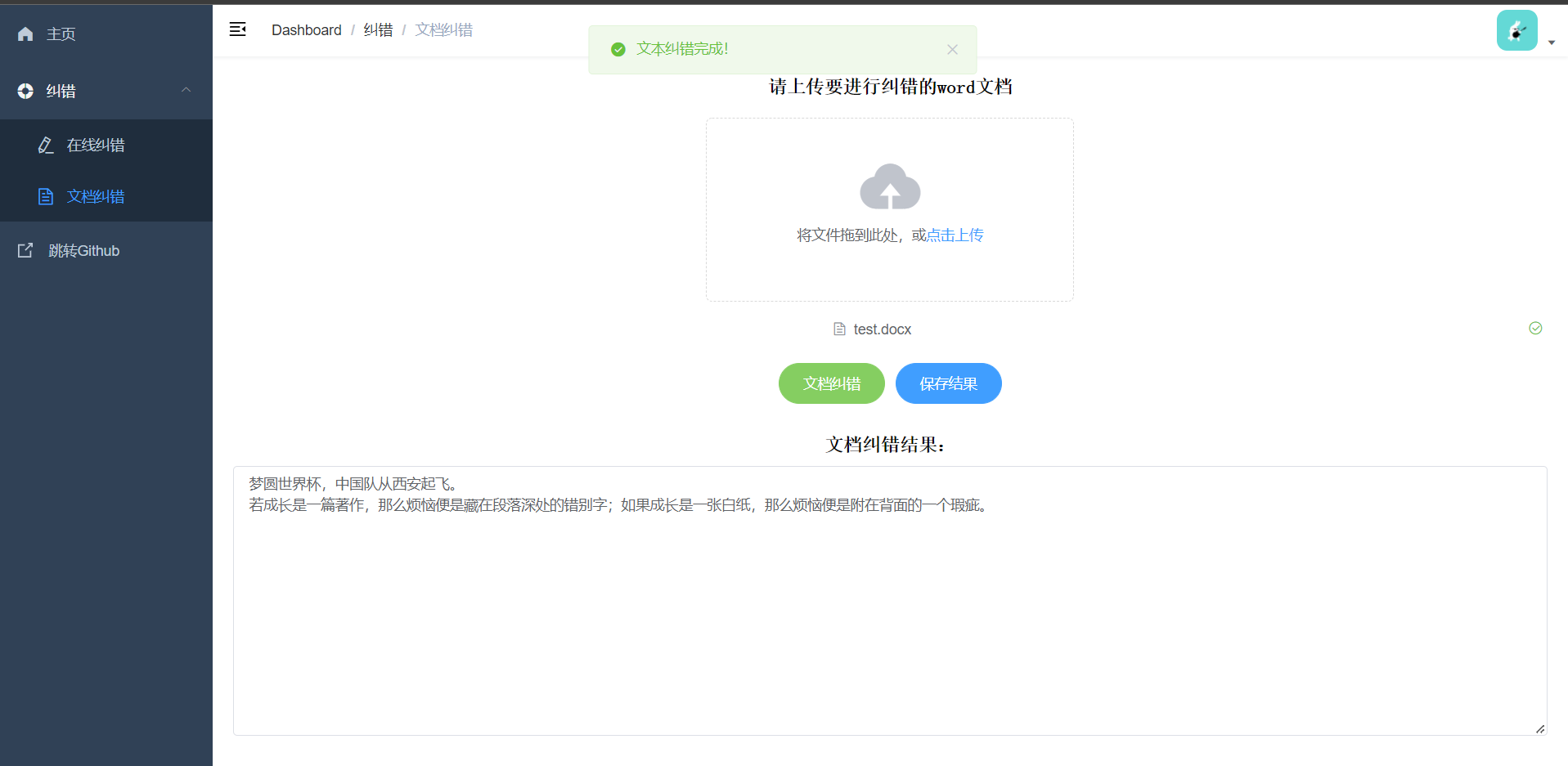
文档纠错演示:上传word文档,点击纠错后显示纠错后文本支持结果保存
五.作者介绍
昵称:炼丹师233
华南师范大学 2019级软件工程本科生
飞桨开发者技术专家 PPDE
主要方向:搞全栈开发,偏向NLP自然语言处理方向研究
Github账号:https://github.com/hchhtc123
飞桨AI Studio - 人工智能学习与实训社区 关注我,下次带来更多精彩项目分享!


学大模型,用大模型上飞桨星河社区!每天8点V100G算力免费领!免费领取ERNIE 4.0 100w Token >>>
更多推荐



 0
0 0
0- 0



 已为社区贡献1436条内容
已为社区贡献1436条内容

所有评论(0)