
PARL集群并行计算-再也不说python是伪线程了
PARL集群并行计算-再也不说python是伪线程了PARL 是一个高性能、灵活的强化学习框架。PARL的目标是构建一个可以完成复杂任务的智能体。在PARL中提供了简易高效的并行接口,只要一个修饰符(parl.remote_class)就可以帮助用户实现自己的并行算法。下面我们用最近的飞桨2.2.0RC版本进行实验展示,这个版本比正式版本会多一些输出信息。最新决定:还是用2.1.2版本进行展示,最
PARL集群并行计算-再也不说python是伪线程了
PARL 是一个高性能、灵活的强化学习框架。PARL的目标是构建一个可以完成复杂任务的智能体。在PARL中提供了简易高效的并行接口,只要一个修饰符(parl.remote_class)就可以帮助用户实现自己的并行算法。
下面我们用最近的飞桨2.2.0RC版本进行实验展示,这个版本比正式版本会多一些输出信息。
最新决定:还是用2.1.2版本进行展示,最新版本实在难以掌控。2021.11.9
飞桨升级到2.2正式发行版了,经测试本项目运行正常,因此升级到2.2版本。 2021.11.10日
开始一个PARL集群
启动一个PARL集群可以通过执行下面的 xparl 命令:
xparl start --port 6006
这个命令会启动一个主节点(master)来管理集群的计算资源,同时会把本地机器的CPU资源加入到集群中。命令中的6006端口只是作为示例,可以修改成任何有效的端口。启动后可通过 xparl status 查看目前集群有多少CPU资源可用,可以在 xparl start 的命令中加入选项 --cpu_num [CPU_NUM] (例如:–cpu_num 10)指定本机加入集群的CPU数量。
比如设置加入集群的cpu数量为2:
xparl start --port 6006 --cpu_num 2
通过执行下面命令可以让其它资源加入集群:
xparl connect --address localhost:6006
下面就在AIStudio环境下实践一下
首先安装需要的库文件:
# 安装需要的库,大约38秒时间
!pip install pip -U
!pip install blackhole pyarrow -Uq
# !pip install pyarrow -Uq
# !pip install parl -U
Looking in indexes: https://pypi.tuna.tsinghua.edu.cn/simple
Collecting pip
[?25l Downloading https://pypi.tuna.tsinghua.edu.cn/packages/a4/6d/6463d49a933f547439d6b5b98b46af8742cc03ae83543e4d7688c2420f8b/pip-21.3.1-py3-none-any.whl (1.7MB)
[K |████████████████████████████████| 1.7MB 2.3MB/s eta 0:00:01
[?25hInstalling collected packages: pip
Found existing installation: pip 19.2.3
Uninstalling pip-19.2.3:
Successfully uninstalled pip-19.2.3
Successfully installed pip-21.3.1
# 大约需要50秒时间,至尊版9秒
!pip install pyarrow blackhole parl numpy gym atari-py -Uq
# !pip install parl -U -q
# !pip install gym[accept-rom-license] -q
[31mERROR: pip's dependency resolver does not currently take into account all the packages that are installed. This behaviour is the source of the following dependency conflicts.
paddlefsl 1.0.0 requires numpy~=1.19.2, but you have numpy 1.21.4 which is incompatible.
paddlefsl 1.0.0 requires pillow==8.2.0, but you have pillow 7.1.2 which is incompatible.
paddlefsl 1.0.0 requires requests~=2.24.0, but you have requests 2.22.0 which is incompatible.[0m
让我们看下当前飞桨版本,并通过创建一个张量验证飞桨是否正常工作。若有报错,需要查找错误原因并解决问题。
看到这个就证明飞桨正常工作:
Tensor(shape=[2], dtype=int64, place=CUDAPlace(0), stop_gradient=True,
[0, 1])
会有极小的概率碰到AIStudio出问题,通过验证张量就能提前发现问题,这时候把项目停止,稍等一会儿再启动,大概率就能恢复正常了。
import paddle
paddle.utils.run_check()
print(paddle.__version__)
print(paddle.to_tensor([0,1]))
Running verify PaddlePaddle program ...
W1110 20:48:41.470507 904 device_context.cc:447] Please NOTE: device: 0, GPU Compute Capability: 7.0, Driver API Version: 10.1, Runtime API Version: 10.1
W1110 20:48:41.475559 904 device_context.cc:465] device: 0, cuDNN Version: 7.6.
PaddlePaddle works well on 1 GPU.
PaddlePaddle works well on 1 GPUs.
PaddlePaddle is installed successfully! Let's start deep learning with PaddlePaddle now.
2.2.0
Tensor(shape=[2], dtype=int64, place=CUDAPlace(0), stop_gradient=True,
[0, 1])
/opt/conda/envs/python35-paddle120-env/lib/python3.7/site-packages/paddle/tensor/creation.py:130: DeprecationWarning: `np.object` is a deprecated alias for the builtin `object`. To silence this warning, use `object` by itself. Doing this will not modify any behavior and is safe.
Deprecated in NumPy 1.20; for more details and guidance: https://numpy.org/devdocs/release/1.20.0-notes.html#deprecations
if data.dtype == np.object:
启动PARL集群
使用命令xparl start --port 6006来启动并行计算集群,可以设置cpu数量,比如我们这里设置为5 --cpu_num 5
# !xparl start --port 6006 --cpu_num 5
import os
os.system("nohup xparl start --port 6006 --cpu_num 5")
# os.system("nohup xparl start --port 6006")
# 查看6006端口服务是否启动
!netstat -an |grep 6006
tcp 0 0 0.0.0.0:6006 0.0.0.0:* LISTEN
tcp 0 0 127.0.0.1:6006 127.0.0.1:33754 ESTABLISHED
tcp 0 0 127.0.0.1:33752 127.0.0.1:6006 ESTABLISHED
tcp 0 0 127.0.0.1:33754 127.0.0.1:6006 ESTABLISHED
tcp 0 0 127.0.0.1:6006 127.0.0.1:33752 ESTABLISHED
加入更多CPU资源
启动集群后,就可以直接使用集群了,如果CPU资源不够用,可以在任何时候和任何机器(包括本机或其他机器)上,通过执行 xparl connect 命令把更多CPU资源加入到集群中。
xparl connect --address localhost:6006
# !xparl connect --address localhost:6006
查看并行服务器状态
看看集群服务是否正常启动,观察vacant cpus数量是否与设置的一样。
# Cluster localhost:6006 has 0 used cpus, 0 vacant cpus.
import os
os.system("xparl status")
关闭集群
在master机器上运行 xparl stop 命令即可关闭集群程序。当master节点退出后,与之关联的worker节点也会自动退出并结束相关程序。
在本项目中,因为是用os.system启动的,所以关闭的时候也要用os.system命令。关闭之后,再用!netstat -an |grep 6006命令,没有输出,证明xparl集群已经关闭。
# os.system("xparl stop")
用命令测试
netstat -an |grep 6006
若没有匹配输出,证明xparl服务已经关闭,有时候需要等待一段时间再来执行这条命令,确认服务已经关闭
# 没有匹配输出,证明xparl服务已经关闭
# !netstat -an |grep 6006
再次打开Xparl服务
# os.system("xparl start --port 6006 --cpu_num 3")
# !netstat -an |grep 6006
两步调度外部的计算资源:
-
使用 parl.remote_class 修饰一个类,之后这个类就被转化为可以运行在其他CPU或者机器上的类。
-
调用 parl.connect 函数来初始化并行通讯,通过这种方式获取到的实例和原来的类是有同样的函数的。由于这些类是在别的计算资源上运行的,执行这些函数 不再消耗当前线程计算资源 。
下面是一个PARL集群的例子,只要加上@parl.remote_class 和parl.connect("localhost:6008")这两句话即可。注意并行代码的语句不会在本地输出信息,比如例子中的打印语句。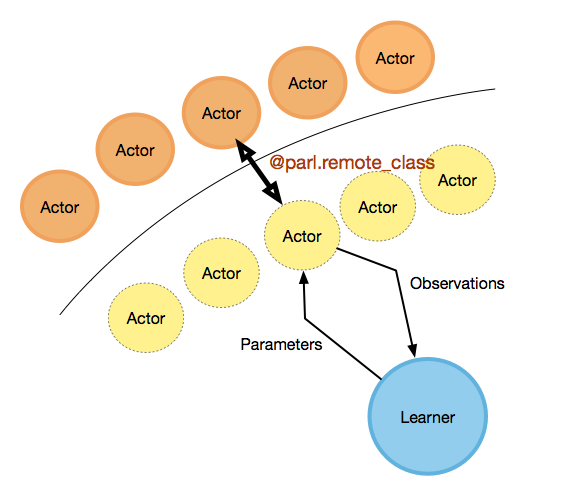
一个简单例子
下面cell将代码写入test.py问题,然后执行该文件,会发现改程序的hello_world并没有打印语句,但是调用add有返回两个数的加和。
%%writefile test.py
import warnings
warnings.filterwarnings("ignore")
import parl
@parl.remote_class
class Actor(object):
def hello_world(self):
print("Hello world.")
def add(self, a, b):
return a + b
# Connect to the master node.
parl.connect("localhost:6006")
actor = Actor()
actor.hello_world()# no log in the current terminal, as the computation is placed in the cluster.
tmp = actor.add(1, 2) # return 3
print("1 add 2 is ", tmp)
Writing test.py
!python test.py
[32m[11-10 20:49:00 MainThread @logger.py:242][0m Argv: test.py
[32m[11-10 20:49:01 MainThread @utils.py:73][0m paddlepaddle version: 2.2.0.
[32m[11-10 20:49:01 MainThread @client.py:440][0m Remote actors log url: http://172.29.153.13:57498/logs?client_id=172.29.153.13_34728_1636548541
1 add 2 is 3
并行加速简单案例时间对比
众所周知,Python下的多线程让人一言难尽。因为全局解释器锁(GIL)的存在,导致python的多线程是伪多线程,在计算量大的时候,跟单线程比没有优势甚至还有可能更慢。下面代码就是比较了普通代码、普通多线程代码、PARL并行加速代码以及并行加速简化代码。普通代码和普通多线程代码的用时差不多,普通代码9.79秒,普通多线程9.20秒,xparl并行4.95秒。而且有时候普通多线程反而会比普通代码还要更慢一点。
以下三个文件,分别为普通代码normal.py 普通多线程multi.py 以及xparl并行加速xparlpro.py
%%writefile normal.py
class A(object):
def run(self):
ans = 0
for i in range(50000000):
ans += i
a = A()
for _ in range(4):
a.run()
Writing normal.py
!python normal.py # 9.79秒
%%writefile multi.py
import threading
class A(object):
def run(self):
ans = 0
for i in range(50000000):
ans += i
threads = []
for _ in range(4):
a = A()
th = threading.Thread(target=a.run)
th.start()
threads.append(th)
for th in threads:
th.join()
Writing multi.py
!python multi.py # 9.20秒
%%writefile xparlpro.py
import threading
import parl
@parl.remote_class
class A(object):
def run(self):
ans = 0
for i in range(50000000):
ans += i
threads = []
parl.connect("localhost:6006")
for _ in range(4):
a = A()
th = threading.Thread(target=a.run)
th.start()
threads.append(th)
for th in threads:
th.join()
print("OK")
Writing xparlpro.py
!python xparlpro.py # 4.95秒
XPARL能否对Numpy加速
寻找质因数-Fermat费马因式分解法
通过寻找质因数的方式破解密码看似几乎不可能,但如果使用正确的算法-Fermat因式分解法,这将变得很容易。
基本思路就是使用如下公式把整数N(奇数)分解为c和d两个数
N = c d = ( a + b ) ( a − b ) = a 2 − b 2 N = cd =(a+b)(a-b) = a^2 -b^2 N=cd=(a+b)(a−b)=a2−b2
递归的应用这个因式分解,直至得到需要的质因数.
费马因式分解的问题是:不适用于合数的两个质因数差别很大的情况,在这种情况下,要么速度比较慢,要么为了提高速度就会错认该合数是质数。下面的代码就是为了提高速度,在两个质因数相差超过LIM = 10 ** 6的时候会误判。
普通程序代码如下,我们会发现大数的质因数分解运算速度非常快:
import numpy as np
N = 60851475143*13 # 这个数无法快速分解
N = 60851475143 # 这个数无法快速和慢速分解,很可能是质数
N = 123456891 # 不是质数,但是会被误认为是质数
N = 600851475143 # 这个数可以分解
LIM = 10 ** 6
def factor(n, LIM=10**6):
# LIM = 10 ** 6
a = np.ceil(np.sqrt(n))
lim = min(n,LIM)
a = np.arange(a,a+lim)
b2 = a ** 2 - n
fractions = np.modf(np.sqrt(b2))[0]
indices = np.where(fractions == 0 ) # 有些数可能找不到符合要求的位置值
if indices[0].size == 0: # 找不到的可能是质数,直接返回
print(n)
return n
a = np.ravel(np.take(a, indices))[0]
a = int(a)
b = np.sqrt(a ** 2 -n)
b = int(b)
c = a + b
d = a - b
if c == 1 or d ==1 :
return n
print (c,d)
factor(c)
factor(d)
factor(N)
1234169 486847
1471 839
6857 71
%%writefile prime.py
import numpy as np
N = 60851475143*13 # 这个数无法快速分解
N = 60851475143 # 这个数无法快速和慢速分解,很可能是质数
N = 600851475143 # 这个数可以分解
LIM = 10 ** 6
def factor(n, LIM=10**6):
a = np.ceil(np.sqrt(n))
lim = min(n,LIM)
a = np.arange(a,a+lim)
b2 = a ** 2 - n
fractions = np.modf(np.sqrt(b2))[0]
indices = np.where(fractions == 0 ) # 有些数可能找不到符合要求的位置值
if indices[0].size == 0: # 找不到的可能是质数,直接返回
print(n)
return n
a = np.ravel(np.take(a, indices))[0]
a = int(a)
b = np.sqrt(a ** 2 -n)
b = int(b)
c = a + b
d = a - b
if c == 1 or d ==1 :
return n
print (c,d)
factor(c)
factor(d)
factor(N)
Writing prime.py
同样的代码,使用python prime.py的形式运行时需要400ms左右,比直接在cell里面执行慢了很多。
!python prime.py
1234169 486847
1471 839
6857 71
6857 71
# 又慢又费内存的费马因式分解,理论上在内存和时间足够的情况下,可以分解任意奇数。
import numpy as np
N = 60851475143 # 这是质数,大质数会爆内存
# N = 600851475143
N = 123456891
# N = 3 ** 27
# N = 6857 * 3
LIM = max(10 **6, N /3)
def factormem(n):
a = np.ceil(np.sqrt(n))
lim = min(n,LIM)
a = np.arange(a,a+lim)
b2 = a ** 2 - n
fractions = np.modf(np.sqrt(b2))[0]
indices = np.where(fractions == 0 )
if indices[0].size == 0:
return n
a = np.ravel(np.take(a, indices))[0]
a = int(a)
b = np.sqrt(a ** 2 -n)
b = int(b)
c = a + b
d = a - b
if c == 1 or d ==1 :
return
print (c,d)
factormem(c)
factormem(d)
factormem(N)
41152297 3
PARL并行计算的质因数分解对比实验
- 首先在cell里面执行普通代码用时10s,因为在cell无法正确的执行后面的对比代码,所以后面三者都写入.py文件进行速度对比。
- 普通版本运行,用时16.8s
- 执行多线程 用时17.2s
- 执行xparl加持的多线程,用时15.5s
在cell里运行的时候能明显看到cpu的某一个核心被用满。其它三着执行的时候都没有碰到这样的情况估计这是cell下特别快的原因。
import numpy as np
def factor(n, LIM=10**6):
# LIM = 10 ** 6
a = np.ceil(np.sqrt(n))
lim = min(n,LIM)
a = np.arange(a,a+lim)
b2 = a ** 2 - n
fractions = np.modf(np.sqrt(b2))[0]
indices = np.where(fractions == 0 ) # 有些数可能找不到符合要求的位置值
if indices[0].size == 0: # 找不到的可能是质数,直接返回
print(n)
return n
a = np.ravel(np.take(a, indices))[0]
a = int(a)
b = np.sqrt(a ** 2 -n)
b = int(b)
c = a + b
d = a - b
if c == 1 or d ==1 :
return n
# print (c,d)
factor(c)
factor(d)
class Primetest(object):
def __init__(self, EPOCH):
self.epoch = EPOCH
def run(self, N):
for i in range(self.epoch):
factor(N)
for _ in range(4):
test = Primetest(100) # 100
test.run(600851475143) # 11秒
%%writefile primenormal.py
import parl
import threading
import numpy as np
def factor(n, LIM=10**6):
# LIM = 10 ** 6
a = np.ceil(np.sqrt(n))
lim = min(n,LIM)
a = np.arange(a,a+lim)
b2 = a ** 2 - n
fractions = np.modf(np.sqrt(b2))[0]
indices = np.where(fractions == 0 ) # 有些数可能找不到符合要求的位置值
if indices[0].size == 0: # 找不到的可能是质数,直接返回
print(n)
return n
a = np.ravel(np.take(a, indices))[0]
a = int(a)
b = np.sqrt(a ** 2 -n)
b = int(b)
c = a + b
d = a - b
if c == 1 or d ==1 :
return n
# print (c,d)
factor(c)
factor(d)
# @parl.remote_class
class PrimeParl(object):
def __init__(self, EPOCH=100):
self.epoch = EPOCH
def run(self, N):
for i in range(self.epoch):
factor(N)
# if __name__ == "__main__":
# parl.connect("localhost:6006")
# parl.connect("127.0.0.1:6006")
threads = []
for _ in range(2):
test = PrimeParl()
test.run(600851475143) # 15秒
print("OK")
Writing primenormal.py
!python primenormal.py
[32m[11-10 20:49:40 MainThread @logger.py:242][0m Argv: primenormal.py
[32m[11-10 20:49:42 MainThread @utils.py:73][0m paddlepaddle version: 2.2.0.
/opt/conda/envs/python35-paddle120-env/lib/python3.7/site-packages/parl/remote/communication.py:38: FutureWarning: 'pyarrow.default_serialization_context' is deprecated as of 2.0.0 and will be removed in a future version. Use pickle or the pyarrow IPC functionality instead.
context = pyarrow.default_serialization_context()
OK
%%writefile primethread.py
import parl
import threading
import numpy as np
def factor(n, LIM=10**6):
# LIM = 10 ** 6
a = np.ceil(np.sqrt(n))
lim = min(n,LIM)
a = np.arange(a,a+lim)
b2 = a ** 2 - n
fractions = np.modf(np.sqrt(b2))[0]
indices = np.where(fractions == 0 ) # 有些数可能找不到符合要求的位置值
if indices[0].size == 0: # 找不到的可能是质数,直接返回
print(n)
return n
a = np.ravel(np.take(a, indices))[0]
a = int(a)
b = np.sqrt(a ** 2 -n)
b = int(b)
c = a + b
d = a - b
if c == 1 or d ==1 :
return n
# print (c,d)
factor(c)
factor(d)
# @parl.remote_class
class PrimeParl(object):
def __init__(self, EPOCH=100):
self.epoch = EPOCH
def run(self, N):
for i in range(self.epoch):
factor(N)
# if __name__ == "__main__":
# parl.connect("localhost:6006")
# parl.connect("127.0.0.1:6006")
threads = []
for _ in range(2):
test = PrimeParl()
th = threading.Thread(target=test.run(600851475143)) # 15秒
th.start()
threads.append(th)
for th in threads:
th.join()
print("OK")
Writing primethread.py
!python primethread.py
[32m[11-10 20:49:55 MainThread @logger.py:242][0m Argv: primethread.py
[32m[11-10 20:49:57 MainThread @utils.py:73][0m paddlepaddle version: 2.2.0.
/opt/conda/envs/python35-paddle120-env/lib/python3.7/site-packages/parl/remote/communication.py:38: FutureWarning: 'pyarrow.default_serialization_context' is deprecated as of 2.0.0 and will be removed in a future version. Use pickle or the pyarrow IPC functionality instead.
context = pyarrow.default_serialization_context()
OK
%%writefile primexparl.py
import parl
import threading
import numpy as np
def factor(n, LIM=10**6):
# LIM = 10 ** 6
a = np.ceil(np.sqrt(n))
lim = min(n,LIM)
a = np.arange(a,a+lim)
b2 = a ** 2 - n
fractions = np.modf(np.sqrt(b2))[0]
indices = np.where(fractions == 0 ) # 有些数可能找不到符合要求的位置值
if indices[0].size == 0: # 找不到的可能是质数,直接返回
print(n)
return n
a = np.ravel(np.take(a, indices))[0]
a = int(a)
b = np.sqrt(a ** 2 -n)
b = int(b)
c = a + b
d = a - b
if c == 1 or d ==1 :
return n
# print (c,d)
factor(c)
factor(d)
@parl.remote_class
class PrimeParl(object):
def __init__(self, EPOCH=100):
self.epoch = EPOCH
def run(self, N):
for i in range(self.epoch):
factor(N)
# if __name__ == "__main__":
parl.connect("localhost:6006")
# parl.connect("127.0.0.1:6006")
threads = []
for _ in range(2):
test = PrimeParl()
th = threading.Thread(target=test.run(600851475143)) # 15秒
th.start()
threads.append(th)
for th in threads:
th.join()
print("OK")
Writing primexparl.py
!python primexparl.py
结论
XPARL对numpy的加速不明显,可能原因是numpy本身已经进行了并行处理。同样python自己的多线程也无法提速numpy。
PARL集群并行A2C 案例
强化学习——Advantage Actor-Critic(A2C)
主要思想是将模型分为两部分:一个用于基于状态计算动作,另一个用于估计动作的Q值。
Actor演员将状态作为输入并输出最佳动作。 它实质上是通过控制代理的行为来学习最佳策略 (基于策略) 。 另一方面,Critic评论家通过计算值函数评估动作 (基于值)来 。 这两个模型参加了一场比赛,随着时间的流逝,他们各自的角色都变得更好。 结果是,与单独使用两种方法相比,整个体系结构将学会更有效地玩游戏。
训练时几个注意点:
- 下面的两句pip安装命令一定要执行,即使刚开始已经安装了这两个库,也需要执行一下
- 因为是xparl并行执行,只能看到开头的log信息,后面的log信息就到xparl的log文件里面去了,可以通过
tail -f train_log/train/log.log来查看
下图图片中第三个就是PongNoFrameskip-v4的训练图,可以看到训练500万-600万左右,reward就达到20左右。
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-Clt5eeLx-1637295400934)(work/result_a2c_paddle0.png)]
!pip install ale-py -q
!pip install gym[accept-rom-license] -q
# 开始训练
!python work/train.py
通过修改work/a2c_config.py文件中的actor_num参数,可以设定并行的actor数目。下面是不同数目的log信息。
‘actor_num’: 2
[10-27 15:02:11 MainThread @train.py:176] {'sample_steps': 55000, 'max_episode_rewards': -20.0, 'mean_episode_rewards': -20.833333333333332, 'min_episode_rewards': -21.0, 'max_episode_steps': 3844, 'mean_episode_steps': 3402.3333333333335, 'min_episode_steps': 3132, 'total_loss': 8.261118, 'pi_loss': 2.724749, 'vf_loss': 18.02188, 'entropy': 347.45706, 'learn_time_s': 0.021220602989196778, 'elapsed_time_s': 132, 'lr': 0.0009945000000000002, 'entropy_coeff': -0.01}
[10-27 15:02:21 MainThread @train.py:176] {'sample_steps': 59800, 'max_episode_rewards': -17.0, 'mean_episode_rewards': -19.833333333333332, 'min_episode_rewards': -21.0, 'max_episode_steps': 5043, 'mean_episode_steps': 3861.6666666666665, 'min_episode_steps': 3132, 'total_loss': 10.759564, 'pi_loss': 5.258734, 'vf_loss': 18.009485, 'entropy': 350.3912, 'learn_time_s': 0.020256004333496093, 'elapsed_time_s': 142, 'lr': 0.00099402, 'entropy_coeff': -0.01}
‘actor_num’: 4
[11-09 20:32:17 MainThread @train.py:176] {'sample_steps': 24400, 'max_episode_rewards': -20.0, 'mean_episode_rewards': -20.6, 'min_episode_rewards': -21.0, 'max_episode_steps': 3703, 'mean_episode_steps': 3452.8, 'min_episode_steps': 3305, 'total_loss': -25.857307, 'pi_loss': -40.658012, 'vf_loss': 42.31675, 'entropy': 635.76697, 'learn_time_s': 0.0581492048795106, 'elapsed_time_s': 30, 'lr': 0.00099756, 'entropy_coeff': -0.01}
[11-09 20:32:27 MainThread @train.py:176] {'sample_steps': 32800, 'max_episode_rewards': -20.0, 'mean_episode_rewards': -20.75, 'min_episode_rewards': -21.0, 'max_episode_steps': 3377, 'mean_episode_steps': 3302.75, 'min_episode_steps': 3169, 'total_loss': -16.47223, 'pi_loss': -30.15582, 'vf_loss': 39.746986, 'entropy': 618.9895, 'learn_time_s': 0.058261028150232826, 'elapsed_time_s': 40, 'lr': 0.00099672, 'entropy_coeff': -0.01}
可以看到’actor_num’: 2时每个log间隔10秒 大约4800步(每次间隔的步数有浮动),这样一次训练1000万步就需要 1000万/4800 * 10 = 3000*10 = 300000秒 = 5.78小时
最终实际耗时为6小时54分钟。
当’actor_num’: 4时,每个log间隔10秒,大约8400步 。这样一次训练1000万步大约需要3.3小时。
通过以上的对比实验这样可以看到xparl确实起了并行加速作用,‘actor_num’ 4比2时要快了75%
报错调试
报错:gym.error.UnregisteredEnv: No registered env with id: PongNoFrameskip-v4
运行:
!pip install ale-py
报错We’re Unable to find the game
f"We're Unable to find the game \"{self._game}\". Note: Gym no longer distributes ROMs. "
gym.error.Error: We're Unable to find the game "Pong". Note: Gym no longer distributes ROMs. If you own a license to use the necessary ROMs for research purposes you can download them via `pip install gym[accept-rom-license]`. Otherwise, you should try importing "Pong" via the command `ale-import-roms`. If you believe this is a mistake perhaps your copy of "Pong" is unsupported. To check if this is the case try providing the environment variable `PYTHONWARNINGS=default::ImportWarning:ale_py.roms`. For more information see: https://github.com/mgbellemare/Arcade-Learning-Environment#rom-management
安装 !pip install gym[accept-rom-license]
报错Cuda error(2), out of memory
File "/opt/conda/envs/python35-paddle120-env/lib/python3.7/site-packages/paddle/fluid/dygraph/tracer.py", line 45, in trace_op
not stop_gradient)
OSError: (External) Cuda error(2), out of memory.
[Advise: The API call failed because it was unable to allocate enough memory to perform the requested operation. ] (at /paddle/paddle/fluid/platform/stream/cuda_stream.cc:49)
自己写了一个tensor数据data1 = paddle.ones(shape=[3, 2]),还是报这个错,证明是环境问题。大重启环境。
大环境重启后,测试通过
启动报错
原来这两句话还是要单独再执行一下
!pip install ale-py -q
!pip install gym[accept-rom-license]
执行后报错input address localhost:6006 is correct.
Exception: Client can not connect to the master, please check if master is started and ensure the input address localhost:6006 is correct.
这是因为还没开xparl服务器。
Xparl服务器相关报错
开启服务xparl start --port 6006 --cpu_num 1,运行报错:
[10-27 12:45:12 Thread-6 @remote_wrapper.py:175] WRN No vacant cpu resources at the moment, will try 270 times later.
再来一句加上服务xparl connect --address 127.0.0.1:6006
还是报错
把agent数量减少:
'actor_num': 5,
改成2
启动服务用xparl start --port 6006
再进行训练,终于成功了!
但是在使用的时候,一直时好时坏,主要问题就是cpu资源太少。比如有这样的报错
Exception: Can not submit job to the master. Please check if master is still alive.
解决的方法是再手动启动。
刚开始写质因数分解的时候报错
---> 14 test = Primeparl(100)
--> 653 raise TypeError('{!r} is a built-in class'.format(object))
654 if ismethod(object):
655 object = object.__func__
TypeError: <class '__main__.PrimeParl'> is a built-in class
解决方法是,把进程放到if name == “main”:里面
Exception: Can not submit job to the master. Please check if master is still alive.
不知道为什么,xparl的服务有几次莫名其妙的没有了。 再手动启动。
碰到报错a built-in class
<class '__main__.PrimeParl'> is a built-in class
放弃分离代码,改成一体式代码,即将原来cell里的代码写到一个.py文件中。
经过测试,还是至尊版好
在普通版本和高端版本里,因为只有2核cpu,xparl非常难调试,很容易出现No vacant cpu resources 的错误。
建议在至尊版下面运行。
心得体会
在不熟悉的时候,可以通过xparl status以及netstat -an |grep 6006来确认服务端口是否开始,是否有设定数量的空闲cpu资源。
可以使用xparl stop来停止集群服务,但是会有延时。
有时候xparl服务会自己停,这时候就需要再手工启动。xparl start --port 6006 --cpu_num 5
实在不行,停止整个项目,然后再重新进入项目。
个人认为这是因为在AIStudio服务器里面的缘故,在物理机环境下可能就不会碰到这么多问题。
Python的多线程,只适用于非计算密集型任务。只能多任务,但不能计算密集。
PARL并行集群,借助Python的多线程,把计算密集的任务发到XPARL主控台,再通过主控台分发给不同的CPU。可以理解为相对Python的多线程,XPARL的优点是实现了多线程的计算密集型任务。
结束语
让我们荡起双桨,在AI的海洋乘风破浪!
飞桨官网:https://www.paddlepaddle.org.cn
因为水平有限,难免有不足之处,还请大家多多帮助。
作者:段春华, 网名skywalk 或 天马行空,济宁市极快软件科技有限公司的AI架构师,百度飞桨PPDE。
我在AI Studio上获得至尊等级,点亮10个徽章,来互关呀~ https://aistudio.baidu.com/aistudio/personalcenter/thirdview/141218

学大模型,用大模型上飞桨星河社区!每天8点V100G算力免费领!免费领取ERNIE 4.0 100w Token >>>
更多推荐



 2
2 0
0- 0



 已为社区贡献1437条内容
已为社区贡献1437条内容

所有评论(0)