
基于PaddleHub的新冠肺炎检测结果图片个人数据脱敏
转自AI Studio,原文链接:基于PaddleHub的新冠肺炎检测结果图片个人数据脱敏 - 飞桨AI Studio一、新冠肺炎数据脱敏1.项目简介项目来源于社区朋友的号召,具体内容如下:各位PPDE大佬们好,我们是上海疫情IT志愿者,其中有来自曾参与了武汉2020新型冠状病毒防疫信息平台建设的开发者,目前我们正在开发一款用于疫情防控的AI机器人:https://github.com/Shang
转自AI Studio,原文链接:基于PaddleHub的新冠肺炎检测结果图片个人数据脱敏 - 飞桨AI Studio
一、新冠肺炎数据脱敏
1.项目简介
项目来源于社区朋友的号召,具体内容如下:
各位PPDE大佬们好,我们是上海疫情IT志愿者,其中有来自曾参与了武汉2020新型冠状病毒防疫信息平台建设的开发者,目前我们正在开发一款用于疫情防控的AI机器人:https://github.com/ShanghaiITVolunteer/AntigenWechatBot,此项目目前获得wechaty社区以及开源社的支持。
目前我们正在开发一个抗原图片检测的功能,输入为居民图片,输出为图片类型和抗原检测图片的结果(阴性和阳性)。详细可见:https://github.com/ShanghaiITVolunteer/AntigenWechatBot/issues/44
此项目完全属于公益性质,毫无任何商业行为和规划,也希望各位大佬能够参与到此项目当中来。
目前已经将功能划分成以下四个部分:
- 1:数据脱敏:mask掉图片中的名字序号等关键信息
- 2:阳性图片数据增强:由于现在大部分都是阴性图片,没有阳性图片,故需要做数据增强
- 3:抗原图片检测:检测图片中是否包含抗原检测仪
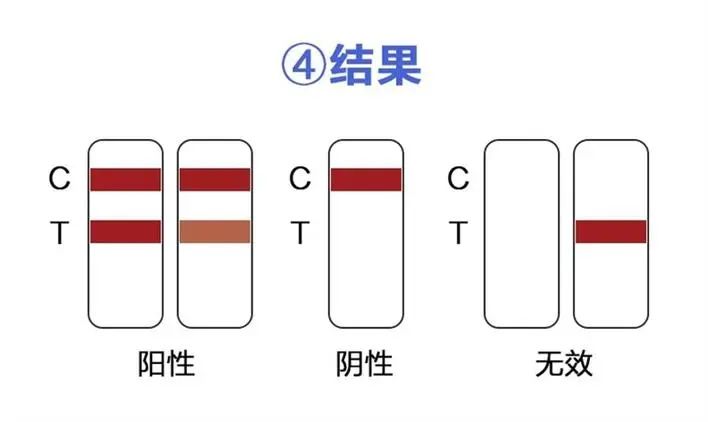
- 4:抗原图片阴阳检测:在抗原图片中检测阴性和阳性的结果
2.数据脱敏
想想就是mask掉图片中的名字序号等关键信息,但是考虑到这些个人信息出现的位置、形式均不相同,怎么处理成为一个让我头痛的问题,一度想到数据标注,检测试剂盒,单独图像分割出试剂盒,但是又考虑到有些字也有写到试剂盒,真的让人头痛。而且使用分隔方法,需要进行数据标注,又是一个暗无天日的时光,怕怕。
3.奇思妙想
思来想去,突然想到,其实PaddleHub的OCR模型就可以实现所有文字识别,在识别的基础上,排除试剂盒自身的序列号,识别的其他非试剂盒的文字全给抹掉即可,这样实现数据脱敏,说干就干,下面看行动。
4.github地址
ShanghaiITVolunteer/AntigenClassifier github地址: GitHub - ShanghaiITVolunteer/AntigenClassifier: Deep Learning Model to classify the antigen image with Paddle*
欢迎大家一起来
二、数据收集
为了准确获得所需数据,对现有的试剂盒进行收集。
新冠自测盒有哪几种
3月12日,国家药监局发布通告,批准南京诺唯赞、北京金沃夫、深圳华大因源、广州万孚生物、北京华科泰生物的新冠抗原产品自测应用申请变更,自此五款新冠抗原自测产品正式上市。

三、环境准备
1.PaddleHub安装
In [11]
!pip install -U pip --user >log.log
!pip install -U paddlehub >log.logIn [12]
!pip list |grep paddlepaddle2onnx 0.9.5 paddlehub 2.2.0 paddlenlp 2.0.1 paddlepaddle 2.2.2 tb-paddle 0.3.6
2.加载预训练模型
PaddleHub提供了以下文字识别模型:
移动端的超轻量模型:仅有8.1M,chinese_ocr_db_crnn_mobile。
服务器端的精度更高模型:识别精度更高,chinese_ocr_db_crnn_server。
识别文字算法均采用CRNN(Convolutional Recurrent Neural Network)即卷积递归神经网络。其是DCNN和RNN的组合,专门用于识别图像中的序列式对象。与CTC loss配合使用,进行文字识别,可以直接从文本词级或行级的标注中学习,不需要详细的字符级的标注。该Module支持直接预测。 移动端与服务器端主要在于骨干网络的差异性,移动端采用MobileNetV3,服务器端采用ResNet50_vd。
In [13]
# -*- coding: utf-8 -*-
# __author__:Livingbody
# 2022/5/6 19:48
import paddlehub as hub
import cv2
import os
import numpy as np
ocr = hub.Module(name="chinese_ocr_db_crnn_server")[2022-05-06 23:57:19,681] [ WARNING] - The _initialize method in HubModule will soon be deprecated, you can use the __init__() to handle the initialization of the object E0506 23:57:19.692303 97 analysis_config.cc:91] Please compile with gpu to EnableGpu() E0506 23:57:19.981134 97 analysis_config.cc:91] Please compile with gpu to EnableGpu()
四、图片脱敏
1.载入图片
In [14]
# 待脱敏路径 work
for root, dirs, files in os.walk("./work"):
test_img_path = [os.path.join("work", file) for file in files]
print(test_img_path)['work/message-5827735361424837534-image-normal-e542cab1-5ffa-4a19-8686-b4bc445342b8..jpg', 'work/message-740057384518308718-image-hd-bdbcb8d8-3230-46b1-b851-5ea134da6e8d..jpg']
In [15]
# 读取测试文件夹test.txt中的照片路径
np_images = [cv2.imread(image_path, 1) for image_path in test_img_path]In [16]
# 新建马赛克目录,一次即可
# !mkdir saved2.马赛克函数
In [17]
def mosaic(selected_image, nsize=9):
rows, cols, _ = selected_image.shape
dist = selected_image.copy()
# 划分小方块,每个小方块填充随机颜色
for y in range(0, rows, nsize):
for x in range(0, cols, nsize):
# dist[y:y + nsize, x:x + nsize] = (np.random.randint(0, 255))
# 调整颜色
dist[y:y + nsize, x:x + nsize] = 255
return dist3.OCR识别
In [18]
import os
os.environ['CUDA_VISIBLE_DEVICES'] = '0'In [19]
# source_dir: 待脱敏图片文件夹
# target_dir: 脱敏后图片保存文件夹
# key_words: 检测盒的基本信息(不用mask掉文字列表)
def data_mask(source_dir, target_dir, key_words=['2019', 'ANC', "C", "T", 'S', "c", "t", "s"]):
ocr = hub.Module(name="chinese_ocr_db_crnn_server")
for root, dirs, files in os.walk(source_dir):
test_img_path = files
test_img_path = [os.path.join(source_dir, file) for file in test_img_path]
# print("test_img_path", test_img_path)
# 读取测试文件夹test.txt中的照片路径
np_images = [cv2.imread(image_path, 1) for image_path in test_img_path]
results = ocr.recognize_text(
images=np_images, # 图片数据,ndarray.shape 为 [H, W, C],BGR格式;
use_gpu=False, # 是否使用 GPU;若使用GPU,请先设置CUDA_VISIBLE_DEVICES环境变量
output_dir='ocr_result', # 图片的保存路径,默认设为 ocr_result;
visualization=False, # 是否将识别结果保存为图片文件;
box_thresh=0.5, # 检测文本框置信度的阈值;
text_thresh=0.3) # 识别中文文本置信度的阈值;
print("results:", results)
for i in range(len(results)):
result = results[i]
data = result['data']
print(f"{i}*******************************************")
for infomation in data:
# print('text: ', infomation['text'], '\nconfidence: ', infomation['confidence'], '\ntext_box_position: ',
# infomation['text_box_position'])
# print(infomation['text'])
flag = True
for word in key_words:
if word in infomation['text']:
flag = False
break
if flag == True:
cut_point = infomation['text_box_position']
roiImg = np_images[i][cut_point[0][1]:cut_point[2][1],
cut_point[0][0]:cut_point[2][0]] # 使用数组切片的方式截取载入图片上的部分,
mosaic_result = mosaic(roiImg)
np_images[i][cut_point[0][1]:cut_point[2][1],
cut_point[0][0]:cut_point[2][0]] = mosaic_result # 然后,将截取的这部分ROI区域的图片保存在roiImg矩阵变量中
# print(f"{i}*******************************************")
cv2.imwrite(filename=os.path.join(target_dir, f"{i}.jpg"), img=np_images[i])In [21]
# test
data_mask(source_dir="work", target_dir="saved")[2022-05-06 23:57:27,560] [ WARNING] - The _initialize method in HubModule will soon be deprecated, you can use the __init__() to handle the initialization of the object E0506 23:57:27.569967 97 analysis_config.cc:91] Please compile with gpu to EnableGpu() E0506 23:57:27.833555 97 analysis_config.cc:91] Please compile with gpu to EnableGpu() [2022-05-06 23:57:28,139] [ WARNING] - The _initialize method in HubModule will soon be deprecated, you can use the __init__() to handle the initialization of the object E0506 23:57:28.142021 97 analysis_config.cc:91] Please compile with gpu to EnableGpu() /home/aistudio/.paddlehub/modules/chinese_text_detection_db_server/module.py:212: DeprecationWarning: `np.int` is a deprecated alias for the builtin `int`. To silence this warning, use `int` by itself. Doing this will not modify any behavior and is safe. When replacing `np.int`, you may wish to use e.g. `np.int64` or `np.int32` to specify the precision. If you wish to review your current use, check the release note link for additional information. Deprecated in NumPy 1.20; for more details and guidance: https://numpy.org/devdocs/release/1.20.0-notes.html#deprecations res['data'] = boxes.astype(np.int).tolist() /home/aistudio/.paddlehub/modules/chinese_ocr_db_crnn_server/module.py:259: DeprecationWarning: `np.int` is a deprecated alias for the builtin `int`. To silence this warning, use `int` by itself. Doing this will not modify any behavior and is safe. When replacing `np.int`, you may wish to use e.g. `np.int64` or `np.int32` to specify the precision. If you wish to review your current use, check the release note link for additional information. Deprecated in NumPy 1.20; for more details and guidance: https://numpy.org/devdocs/release/1.20.0-notes.html#deprecations 'text_box_position': boxes[index].astype(np.int).tolist()
results: [{'save_path': '', 'data': [{'text': '3-802', 'confidence': 0.9995685815811157, 'text_box_position': [[369, 161], [615, 161], [615, 237], [369, 237]]}, {'text': '2个人', 'confidence': 0.9999365210533142, 'text_box_position': [[378, 310], [612, 310], [612, 403], [378, 403]]}, {'text': '2019.nCov', 'confidence': 0.8814417123794556, 'text_box_position': [[402, 470], [448, 470], [444, 681], [399, 681]]}, {'text': '9615N', 'confidence': 0.8228781819343567, 'text_box_position': [[821, 499], [840, 499], [840, 590], [821, 590]]}, {'text': '南', 'confidence': 0.4922979772090912, 'text_box_position': [[909, 502], [980, 502], [980, 549], [909, 549]]}, {'text': '730', 'confidence': 0.9555589556694031, 'text_box_position': [[817, 617], [839, 617], [839, 674], [817, 674]]}, {'text': '2019.nCo', 'confidence': 0.9463883638381958, 'text_box_position': [[397, 943], [438, 943], [435, 1142], [394, 1142]]}, {'text': '5106', 'confidence': 0.998921811580658, 'text_box_position': [[801, 1027], [827, 1027], [827, 1106], [801, 1106]]}]}, {'save_path': '', 'data': [{'text': '37-900(2人)', 'confidence': 0.8939000368118286, 'text_box_position': [[61, 523], [809, 468], [818, 567], [70, 622]]}, {'text': '2019-nCoV', 'confidence': 0.8988072276115417, 'text_box_position': [[454, 636], [487, 636], [487, 782], [454, 782]]}, {'text': 'ANCP51254521', 'confidence': 0.9833608865737915, 'text_box_position': [[172, 656], [194, 656], [194, 790], [172, 790]]}, {'text': '2019-nCoV', 'confidence': 0.9047756195068359, 'text_box_position': [[469, 840], [501, 840], [501, 1002], [469, 1002]]}, {'text': 'ANCP51222889', 'confidence': 0.9969608783721924, 'text_box_position': [[180, 848], [201, 848], [194, 1005], [172, 1005]]}, {'text': 'S', 'confidence': 0.9161548614501953, 'text_box_position': [[571, 847], [600, 840], [605, 863], [578, 869]]}]}]
0*******************************************
1*******************************************
4.基本效果
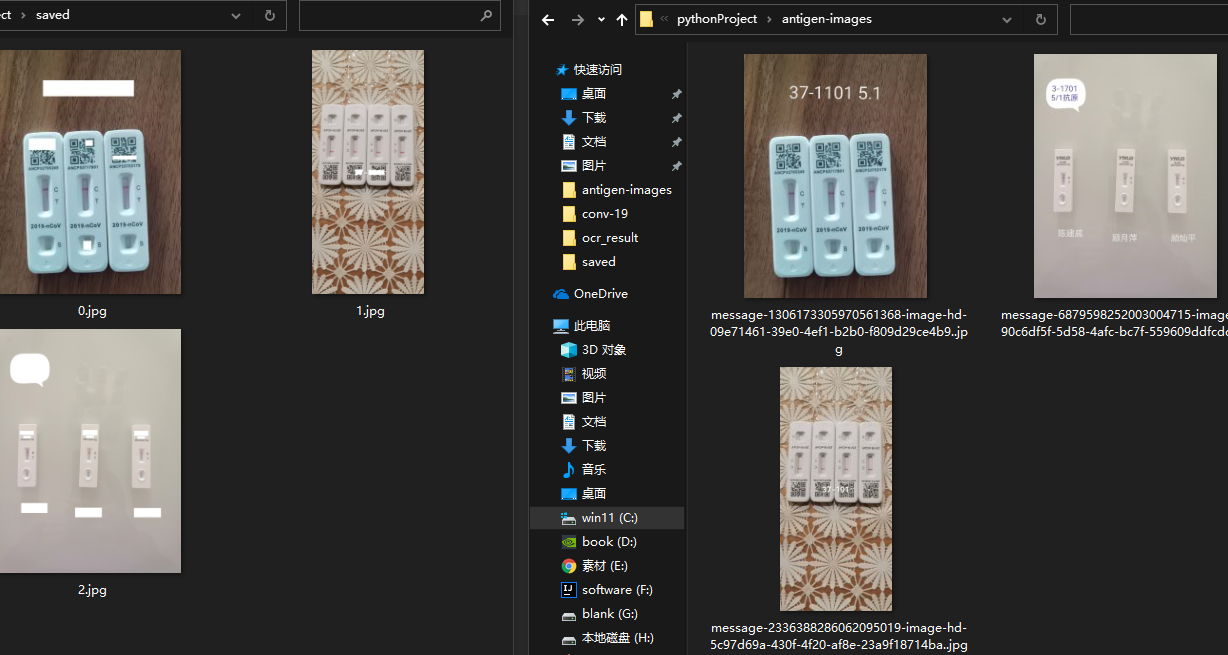
五、完整程序
In [ ]
# -*- coding: utf-8 -*-
# __author__:Livingbody
# 2022/5/6 19:48
import paddlehub as hub
import cv2
import os
# 数据mask
def mosaic(selected_image, nsize=9):
rows, cols, _ = selected_image.shape
dist = selected_image.copy()
# 划分小方块,每个小方块填充随机颜色
for y in range(0, rows, nsize):
for x in range(0, cols, nsize):
# 随机
# dist[y:y + nsize, x:x + nsize] = (np.random.randint(0, 255))
# 用255白色mask
dist[y:y + nsize, x:x + nsize] = 255
return dist
# source_dir: 待脱敏图片文件夹
# target_dir: 脱敏后图片保存文件夹
# key_words: 检测盒的基本信息(不用mask掉文字列表)
def data_mask(source_dir, target_dir, key_words=['2019', 'ANC', "C", "T", 'S', "c", "t", "s"]):
ocr = hub.Module(name="chinese_ocr_db_crnn_server")
for root, dirs, files in os.walk(source_dir):
test_img_path = files
test_img_path = [os.path.join(source_dir, file) for file in test_img_path]
# print("test_img_path", test_img_path)
# 读取测试文件夹test.txt中的照片路径
np_images = [cv2.imread(image_path, 1) for image_path in test_img_path]
results = ocr.recognize_text(
images=np_images, # 图片数据,ndarray.shape 为 [H, W, C],BGR格式;
use_gpu=False, # 是否使用 GPU;若使用GPU,请先设置CUDA_VISIBLE_DEVICES环境变量
output_dir='ocr_result', # 图片的保存路径,默认设为 ocr_result;
visualization=False, # 是否将识别结果保存为图片文件;
box_thresh=0.5, # 检测文本框置信度的阈值;
text_thresh=0.3) # 识别中文文本置信度的阈值;
print("results:", results)
for i in range(len(results)):
result = results[i]
data = result['data']
print(f"{i}*******************************************")
for infomation in data:
# print('text: ', infomation['text'], '\nconfidence: ', infomation['confidence'], '\ntext_box_position: ',
# infomation['text_box_position'])
# print(infomation['text'])
flag = True
for word in key_words:
if word in infomation['text']:
flag = False
break
if flag == True:
cut_point = infomation['text_box_position']
roiImg = np_images[i][cut_point[0][1]:cut_point[2][1],
cut_point[0][0]:cut_point[2][0]] # 使用数组切片的方式截取载入图片上的部分,
mosaic_result = mosaic(roiImg)
np_images[i][cut_point[0][1]:cut_point[2][1],
cut_point[0][0]:cut_point[2][0]] = mosaic_result # 然后,将截取的这部分ROI区域的图片保存在roiImg矩阵变量中
# print(f"{i}*******************************************")
cv2.imwrite(filename=os.path.join(target_dir, f"{i}.jpg"), img=np_images[i])
if __name__ == '__main__':
# test
data_mask(source_dir="work", target_dir="saved")
学大模型,用大模型上飞桨星河社区!每天8点V100G算力免费领!免费领取ERNIE 4.0 100w Token >>>
更多推荐



 0
0 0
0- 0



 已为社区贡献1436条内容
已为社区贡献1436条内容

所有评论(0)