
抠像任务:基于飞桨复现BackgroundMattingV2模型
人工智能创新应用大赛——飞桨开源框架前沿模型复现专题赛,使用Paddle复现Real-Time-High-Resolution-Background-Matting论文。
前言
人工智能创新应用大赛——飞桨开源框架前沿模型复现专题赛,使用Paddle复现Real-Time-High-Resolution-Background-Matting论文。
github: https://github.com/zackzhao1/BackgroundMattingV2-paddle
aistudio: https://aistudio.baidu.com/aistudio/projectdetail/2467759
依赖环境:
paddlepaddle-gpu2.1.2
python3.7
论文简介
该方法中将整个pipeline划分为两个部分:base和refine部分,前一个部分在缩小分辨率的输入下生成粗略的结果输出,其主要用于提供大体的区域位置定位(coarse predcition)。后一个网络在该基础上通过path selection选取固定数量的path(这些区域主要趋向于选择头发/手等难分区域)进行refine,之后将path更新之后的结果填充回原来的结果,从而得到其在高分辨率下的matting结果。
图1:BGMv2的网络结构,其中蓝色的是base网络,绿色的是refine网络
论文细节
BGMv2的网络分成两个模块: G b a s e G_{base} Gbase 和 G r e f i n e G_{refine} Grefine 。给定一张输入图像 I I I 和空屏图像 B B B ,首先将其降采样 c c c 倍,得到 I c I_c Ic 和 B c B_c Bc 。 G b a s e G_{base} Gbase 取 I c I_c Ic 和 B c B_c Bc 作为输入,输出同样是降采样尺寸的前景概率 a c a_c ac ,前景残差 F c R F_c^R FcR ,Error Map E c E_c Ec 以及隐层节点特征 H c H_c Hc 。然后 G r e f i n e G_{refine} Grefine 根据 E c E_c Ec 中值较大的像素点取 H c H_c Hc , I I I 以及 B B B 中对应的patch(难样本)来优化 F R F^R FR 和 a a a ,整个过程如图1所示。
- base网络
BGMv2借鉴了deeplab v3的网络结构,包含骨干网络,空洞空间金字塔池化和解码器三部分组成:
骨干网络:可以采用主流的卷积网络作为,作者开源的模型包括ResNet-50,ResNet-101以及MobileNetV2,用户可以根据速度和精度的不同需求选择不同的模型;空洞空间金字塔池化:(Atrous Spatial Pyramid Pooling,ASPP)是由DeeplabV3提出并在实例分割领域得到广泛应用的结构,人像抠图和实例分割本质上式非常接近的,因此也可以通过ASPP来提升模型准确率;解码器:解码器是由一些列的双线性插值上采样和跳跃连接组成,每个卷几块由 3 ∗ 3 3 * 3 3∗3 卷积,BN以及ReLU激活函数组成。
如前面介绍的, G b a s e G_{base} Gbase 的输入是 I c I_c Ic 和 B c B_c Bc ,输出是 a c a_c ac , F c R F_c^R FcR , E c E_c Ec 以及 H c H_c Hc 。其中Error Map E c E_c Ec 的Ground Truth是 E ∗ E* E∗ ,Error Map是一个人像轮廓的一个图。通过对Error Map的优化,可以使得BGMv2有更好的边缘检测效果。
- Refine网络
G r e f i n e G_{refine} Grefine 的输入是在根据 E c E_c Ec 提取的 k 个补丁块(patches)上进行进行精校, k 可以提前指定选择top- k 个或是根据阈值卡若干个。用户也可以根据速度和精度的trade-off自行设置 k 或者阈值的具体值。对于缩放到原图 1 / c 1/c 1/c 的 E c E_c Ec ,我们首先将其上采样到原图的 1/4 ,那么 E 4 E_4 E4 中的一个点便相当于原图上一个 4 ∗ 4 4 * 4 4∗4 的补丁块,那么相当于我们要优化的像素点的个数总共有 16k 个。
G r e f i n e G_{refine} Grefine 的网络分成两个阶段:在1/2的分辨率和原尺寸的分辨率上进行精校。
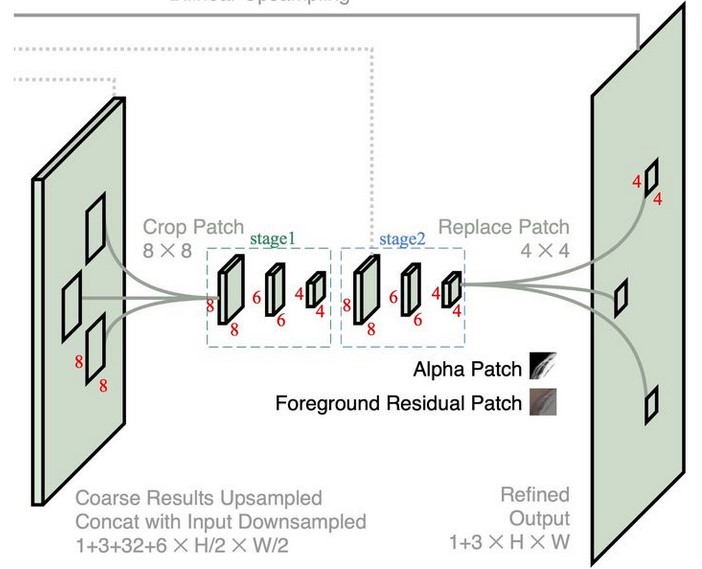
Stage 1:首先将 G b a s e G_{base} Gbase 的输出上采样到原图的 1/2 ;然后再根据 E 4 E_4 E4 选择出的补丁块,从其周围在其中提取 8 ∗ 8 8 * 8 8∗8 的补丁块;再依次经过两组 3 ∗ 3 3 * 3 3∗3 的有效卷积,BN,ReLU将Feature Map的尺寸依次降为 6 ∗ 6 6 * 6 6∗6 和 4 ∗ 4 4 * 4 4∗4 。
Stage2:再将Stage 1得到的 4 ∗ 4 4 * 4 4∗4 的Feature Map上采样到 8 ∗ 8 8 * 8 8∗8 ,再依次经过两组 3 ∗ 3 3 * 3 3∗3 的有效卷积,BN,ReLU将Feature Map的最终尺寸降为 4 ∗ 4 4 * 4 4∗4 。而这个尺寸的Feature Map对应的ground truth就是我们上面根据 E 4 E_4 E4 得到的补丁块。最后我们将降采样的 a c a_c ac 和 F c R F_c^R FcR 上采样到原图大小,再将Refine优化过后的补丁块替换到原图中便得到了最终的结果。
复现思路
1.在复现过程中我们参考论文中的方法,做了多阶段的训练,并做了修改:
stage1:使用VideoMatte240K数据集做预训练,提升模型鲁棒性。注:由于预训练耗时较长,提供了训练好得模型,方便在自己的数据上微调,模型为stage1.pdparams。
stage2:使用Distinctions646数据集做微调,提升模型细节表现。注:此时模型最好精度为SAD: 7.58,MSE: 9.49,模型为stage2.pdparams。
stage3:使用个人数据集微调。注:本次比赛提交的是stage2模型,因为训练所用数据集都为公开数据集,方便复现。 原作者在论文中也使用了个人数据集微调,但没有公开。因此我增加了自己数据进行训练,没有条件的同学可以利用原工程生成pha作为训练数据。 模型最好精度为SAD: 7.61,MSE: 9.47,模型为stage3.pdparams。
2.添加了原作者新论文中用到的laplacian_loss,可以提高收敛速度。
3.模型api对照表 https://blog.csdn.net/qq_32097577/article/details/112383360?utm_medium=distribute.pc_relevant.none-task-blog-2%7Edefault%7EBlogCommendFromMachineLearnPai2%7Edefault-2.vipsorttest&depth_1-utm_source=distribute.pc_relevant.none-task-blog-2%7Edefault%7EBlogCommendFromMachineLearnPai2%7Edefault-2.vipsorttest
复现

模型下载 链接:https://pan.baidu.com/s/1WfpzLcjaDJPXYSrzPWvsyQ 提取码:nsfy
训练
- stage1:使用VideoMatte240K数据集做预训练,提升模型鲁棒性。
注:由于预训练耗时较长,提供了训练好得模型,方便在自己的数据上微调,模型为stage1.pdparams。
- stage2:使用Distinctions646数据集做微调,提升模型细节表现。
注:此时模型最好精度为SAD: 7.58,MSE: 9.49,模型为stage2.pdparams。
- **stage3:使用个人数据集微调。
注:本次比赛提交的是stage2模型,因为训练所用数据集都为公开数据集,方便复现。
原作者在论文中也使用了个人数据集微调,但没有公开。因此我增加了自己数据进行训练,没有条件的同学可以利用原工程生成pha作为训练数据。
模型最好精度为SAD: 7.61,MSE: 9.47,模型为stage3.pdparams。
# [VideoMatte240K & PhotoMatte85 数据集](https://grail.cs.washington.edu/projects/background-matting-v2/#/datasets)
# [Distinctions646_person 数据集](https://github.com/cs-chan/Total-Text-Dataset)
# 数据集需要申请,请自行下载
! ./run.sh
验证
# 解压测试集
解压测试集
!unzip ./data/data111962/PhotoMatte85_eval.zip -d ./data/
!python eval.py
W1013 17:35:31.830500 406 device_context.cc:404] Please NOTE: device: 0, GPU Compute Capability: 7.0, Driver API Version: 10.1, Runtime API Version: 10.1
W1013 17:35:31.835165 406 device_context.cc:422] device: 0, cuDNN Version: 7.6.
0%| | 0/85 [00:00<?, ?it/s]/opt/conda/envs/python35-paddle120-env/lib/python3.7/site-packages/paddle/tensor/creation.py:125: DeprecationWarning: `np.object` is a deprecated alias for the builtin `object`. To silence this warning, use `object` by itself. Doing this will not modify any behavior and is safe.
Deprecated in NumPy 1.20; for more details and guidance: https://numpy.org/devdocs/release/1.20.0-notes.html#deprecations
if data.dtype == np.object:
/opt/conda/envs/python35-paddle120-env/lib/python3.7/site-packages/paddle/fluid/dygraph/math_op_patch.py:239: UserWarning: The dtype of left and right variables are not the same, left dtype is paddle.float32, but right dtype is paddle.bool, the right dtype will convert to paddle.float32
format(lhs_dtype, rhs_dtype, lhs_dtype))
/opt/conda/envs/python35-paddle120-env/lib/python3.7/site-packages/paddle/fluid/dygraph/math_op_patch.py:239: UserWarning: The dtype of left and right variables are not the same, left dtype is paddle.float32, but right dtype is paddle.float64, the right dtype will convert to paddle.float32
format(lhs_dtype, rhs_dtype, lhs_dtype))
100%|███████████████████████████████████████████| 85/85 [00:28<00:00, 2.96it/s]
paddle output: SAD: 8.519970015918508, MSE: 9.885075489212484
预测
!python predict.py
W1013 18:00:01.562386 1535 device_context.cc:404] Please NOTE: device: 0, GPU Compute Capability: 7.0, Driver API Version: 10.1, Runtime API Version: 10.1
W1013 18:00:01.567060 1535 device_context.cc:422] device: 0, cuDNN Version: 7.6.
save results:./image/01_pred.jpg
请点击此处查看本环境基本用法.
Please click here for more detailed instructions.

学大模型,用大模型上飞桨星河社区!每天8点V100G算力免费领!免费领取ERNIE 4.0 100w Token >>>
更多推荐



 1
1 0
0- 0



 已为社区贡献1436条内容
已为社区贡献1436条内容

所有评论(0)