
Paddle2.2复现经典论文Transformer(理论篇)
经典论文复现Paddle2.2-transformer,这半部分为论文研读部分,篇幅太长,下半篇为实践篇
手把手带你复现经典论文Transformer
上部(理论篇)
BERT大火却不懂Transformer?
Transformer由论文《Attention is All You Need》提出,现在是谷歌云TPU推荐的参考模型。
论文相关的Tensorflow的代码可以从GitHub获取,其作为Tensor2Tensor包的一部分。
哈佛的NLP团队也实现了一个基于PyTorch的版本,并注释该论文。
当然,不乏也有飞桨开发者已经将transformer进行了复现。
这里我的复现,希望更能贴近于小白的理解。
首先附上原文pdf地址:
《Attention is All You Need》
https://arxiv.org/abs/1706.03762
左侧文件列表也有已经下载下来的原文pdf
0 读论文
四级刚过的本人,全靠自己的薄弱翻译和翻译软件来进行阅读论文(其实基本全靠机器翻译),若有翻译不当的地方或者可以有更好的翻译的地方,还请谅解或者评论区指出。
全文总共分了七个章节(除摘要)
- Abstract 摘要
- Introduction 介绍
- Background 背景
- Model Architecture 模型架构
- Why Self-Attention 为什么要用自注意力机制
- Training 训练
- Results 结果
- Conclusion 结论
我们明显可以知道我们如果只关注于复现论文的代码,那么只关注上述345章节即可。
但我希望我们从本质上去理解全文,将会逐步阅读论文,也会把我认为的核心原文也会附上,同时,论文中纯理论的地方将会快速带过。
0.0 Abstract 摘要
重点片段:
The dominant sequence transduction models are based on complex recurrent or convolutional neural networks that include an encoder and a decoder. The best performing models also connect the encoder and decoder through an attention mechanism. We propose a new simple network architecture, the Transformer, based solely on attention mechanisms, dispensing with recurrence and convolutions entirely.
论文指出,目前占主导地位的序列转换模型是基于复杂的递归或卷积神经网络,包括一个编码器和一个解码器。
性能最好的模型还通过注意机制将编码器和解码器连接起来。
对于这个现状,谷歌他们这篇论文提出了一个新的简单的网络结构,即Transformer,只基于注意力机制,完全不需要递归和卷积。
后面的就不再翻译了,就是巴拉巴拉说自己的这个模型架构多牛逼,已经取得了验证。
0.1 Introduction 介绍
早期经典的RNN,LSTM,GRU三个模型在语言建模和机器翻译方面已经很成熟了,然后指出递归模型和注意力机制的特点,引出transformer结合了二者的优点,是一种避免了递归和只采用注意力机制的模型体系结构。
同时transformer允许更多的并行化,并且在8个P100 gpu上经过12个小时的培训后,可以达到翻译质量的新水平。。
重点片段:
In this work we propose the Transformer, a model architecture eschewing recurrence and instead relying entirely on an attention mechanism to draw global dependencies between input and output. The Transformer allows for significantly more parallelization and can reach a new state of the art in translation quality after being trained for as little as twelve hours on eight P100 GPUs.
0.2 Background 背景
简述: (其实简述这一句看完就可以不看后面我读原文的内容了)
主要是四大段,第一段讲顺序计算的特点,第二段讲自注意力机制的特点,第三段讲端到端记忆机制,第四段再次引出他们的transformer。
提一嘴,论文的背景嘛,都是这个套路。
- 之前的人做了什么
- 他们不行,我的行
- 给你们讲讲我的
片段1:
The goal of reducing sequential computation also forms the foundation of the Extended Neural GPU [16], ByteNet [18] and ConvS2S [9], all of which use convolutional neural networks as basic building block, computing hidden representations in parallel for all input and output positions. In these models, the number of operations required to relate signals from two arbitrary input or output positions grows in the distance between positions, linearly for ConvS2S and logarithmically for ByteNet. This makes it more difficult to learn dependencies between distant positions [12]. In the Transformer this is reduced to a constant number of operations, albeit at the cost of reduced effective resolution due to averaging attention-weighted positions, an effect we counteract with Multi-Head Attention as described in section 3.2.
减少顺序计算的目标成为了ByteNet and ConvS2S这两个模型的基础。这两个模型都使用卷积神经网络作为基本构建块,并行计算所有的输入和输出位置的隐藏表现。
在这些模型中,将两个任意输入或输出位置的信号关联起来所需的操作数量随着位置之间的距离增长,ConvS2S呈线性增长,ByteNet呈对数增长。
这使得学习遥远位置之间的依赖性变得更加困难。
在Transformer中,这被减少到一个固定的操作数量,尽管这是以由于平均注意力加权位置而降低的有效分辨率为代价的,这一点将会在3.2节中描述的多头注意力抵消的影响中体现。
片段2:
Self-attention, sometimes called intra-attention is an attention mechanism relating different positions of a single sequence in order to compute a representation of the sequence. Self-attention has been used successfully in a variety of tasks including reading comprehension, abstractive summarization, textual entailment and learning task-independent sentence representations.
自注意力(Self-attention),有时也称为内部注意力(intra-attention),是一种将单个序列的不同位置联系起来,以计算该序列的表示的注意机制。
自注意已经成功地用于各种任务,包括阅读理解、抽象总结、文本蕴涵和学习任务独立的句子表征。
片段3:
End-to-end memory networks are based on a recurrent attention mechanism instead of sequence-aligned recurrence and have been shown to perform well on simple-language question answering and language modeling tasks.
端到端记忆网络基于重复注意力机制,而不是序列对齐的重复注意力机制,在简单语言问题回答和语言建模任务中表现良好。
片段4:
To the best of our knowledge, however, the Transformer is the first transduction model relying entirely on self-attention to compute representations of its input and output without using sequence-aligned RNNs or convolution.
Transformer是第一个完全依靠自注意来计算其输入和输出表示的转导模型,而不使用序列对齐的rnn或卷积神经网络。
0.3 Model Architecture 模型架构
大部分的有竞争力的模型还是使用的编码器-解码器结构(encoder-decoder structure),Transformer遵循这种总体架构,编码器和解码器都使用了堆叠的自注意层和点式的、全连接层。
结构如下图:(麻了,麻了,人麻了,看着都头大,别急,跟着文章慢慢来看)
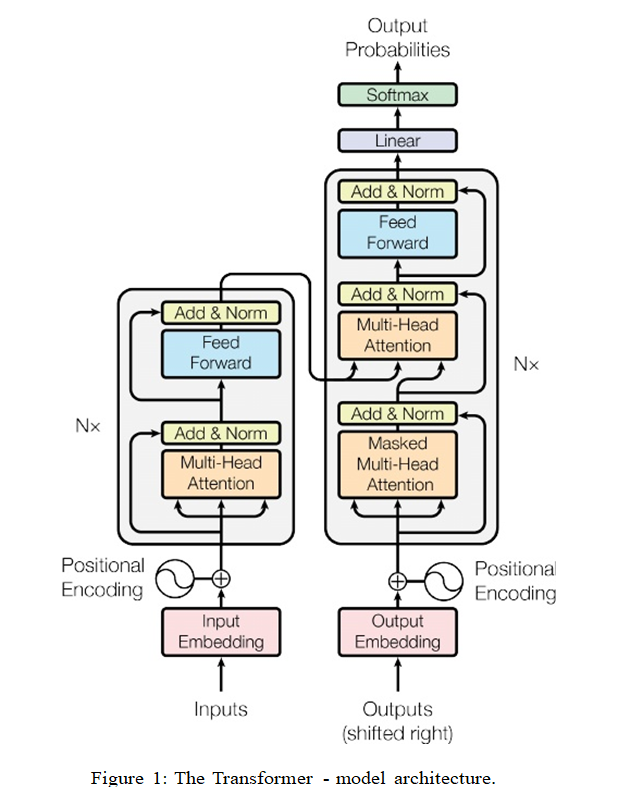
0.3.1 Encoder and Decoder Stacks 编码器和解码器堆栈
先将上图进行分解,不看输入和输出,就只剩下了左边一个Nx的大块是编码器,右边一个Nx的大块是解码器。
然后我们将这个模型看成是一个黑箱操作。在机器翻译中,就是输入一种语言,输出另一种语言。
拆开这个黑箱,我们可以看到它是由编码器、解码器和它们之间的连接组成。
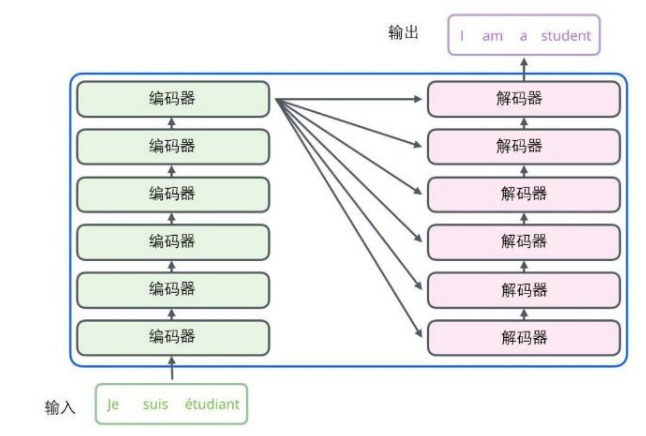
编码组件部分由一堆编码器(encoder)构成(论文中是将6个编码器叠在一起—数字6没有什么神奇之处,一般也会换成12或者24)。
解码组件部分也是由相同数量(与编码器对应)的解码器(decoder)组成的。
大致理解了之后,我们再去看原文细读细节的部分:
Encoder: The encoder is composed of a stack of N = 6 identical layers. Each layer has two sub-layers. The first is a multi-head self-attention mechanism, and the second is a simple, position-wise fully connected feed-forward network. We employ a residual connection around each of the two sub-layers, followed by layer normalization. That is, the output of each sub-layer is LayerNorm(x + Sublayer(x)), where Sublayer(x) is the function implemented by the sub-layer itself. To facilitate these residual connections, all sub-layers in the model, as well as the embedding layers, produce outputs of dimension dmodel = 512.
编码器由N = 6个相同的层组成。每一层有两个子层。第一种是多头自注意力机制,第二种是简单的位置全连接前馈网络。我们在两个子层周围使用残差连接,然后是层归一化。也就是说,每个子层的输出是LayerNorm(x +Sublayer(x)),其中Sublayer(x)是子层本身实现的函数。为了方便这些剩余连接,模型中的所有子层以及嵌入层都会产生d维度的输出model = 512。
Decoder: The decoder is also composed of a stack of N = 6 identical layers. In addition to the two sub-layers in each encoder layer, the decoder inserts a third sub-layer, which performs multi-head attention over the output of the encoder stack. Similar to the encoder, we employ residual connections around each of the sub-layers, followed by layer normalization. We also modify the self-attention sub-layer in the decoder stack to prevent positions from attending to subsequent positions. This masking, combined with fact that the output embeddings are offset by one position, ensures that the predictions for position i can depend only on the known outputs at positions less than i.
解码器也由N = 6个相同的层组成。除每个编码器层中的两个子层外,解码器还插入第三个子层,该子层对编码器堆栈的输出执行多头注意力。与编码器类似,我们在每个子层周围使用残差连接,然后进行层归一化。我们还修改了解码器堆栈中的自注意子层,以防止位置注意到后续位置。这种掩蔽,加上输出嵌入被一个位置偏移的事实,确保了位置i的预测只能依赖于位置小于i的已知输出。
0.3.2 Attention 注意力
这里,也是文章的最重点部分了。
- 首先,再将编码器和解码器结构图进行汉化看一下:
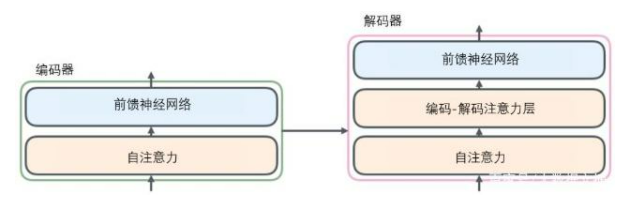
从编码器输入的句子首先会经过一个自注意力(self-attention)层,这层帮助编码器在对每个单词编码时关注输入句子的其他单词。我们将在稍后的文章中更深入地研究自注意力。
自注意力层的输出会传递到前馈(feed-forward)神经网络中。每个位置的单词对应的前馈神经网络都完全一样(译注:另一种解读就是一层窗口为一个单词的一维卷积神经网络)。
解码器中也有编码器的自注意力(self-attention)层和前馈(feed-forward)层。除此之外,这两个层之间还有一个注意力层,用来关注输入句子的相关部分(和seq2seq模型的注意力作用相似)。
- 回过头来,再看原文采用的attention操作:
(这一部分我将不再按照原文的理论进行介绍,因为在百度找到一篇极其通俗易懂的文章(BERT大火却不懂Transformer?读这一篇就够了)来解释这一部分的内容,以下内容均来自这篇文章,已经附在最后的参考文献中)
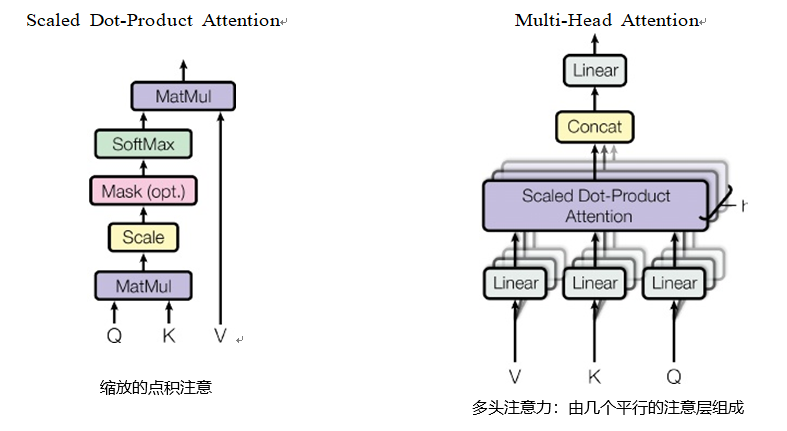
我们要知道多头注意力机制,就要知道其中的这一部分缩放点积注意机制。
首先,要引入的肯定是张量的概念。我们已经了解了模型的主要部分,接下来我们看一下各种向量或张量(译注:张量概念是矢量概念的推广,可以简单理解矢量是一阶张量、矩阵是二阶张量。)是怎样在模型的不同部分中,将输入转化为输出的。
像大部分NLP应用一样,我们首先将每个输入单词通过词嵌入算法转换为词向量。
每个单词都被嵌入为512维的向量,我们用这些简单的方框来表示这些向量。
词嵌入过程只发生在最底层的编码器中。所有的编码器都有一个相同的特点,即它们接收一个向量列表,列表中的每个向量大小为512维。在底层(最开始)编码器中它就是词向量,但是在其他编码器中,它就是下一层编码器的输出(也是一个向量列表)。向量列表大小是我们可以设置的超参数——一般是我们训练集中最长句子的长度。
将输入序列进行词嵌入之后,每个单词都会流经编码器中的两个子层。
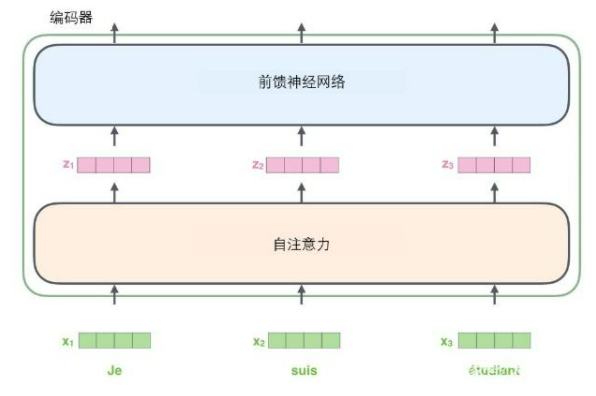
接下来我们看看Transformer的一个核心特性,在这里输入序列中每个位置的单词都有自己独特的路径流入编码器。在自注意力层中,这些路径之间存在依赖关系。而前馈(feed-forward)层没有这些依赖关系。因此在前馈(feed-forward)层时可以并行执行各种路径。
然后我们将以一个更短的句子为例,看看编码器的每个子层中发生了什么。
如上述已经提到的,一个编码器接收向量列表作为输入,接着将向量列表中的向量传递到自注意力层进行处理,然后传递到前馈神经网络层中,将输出结果传递到下一个编码器中。
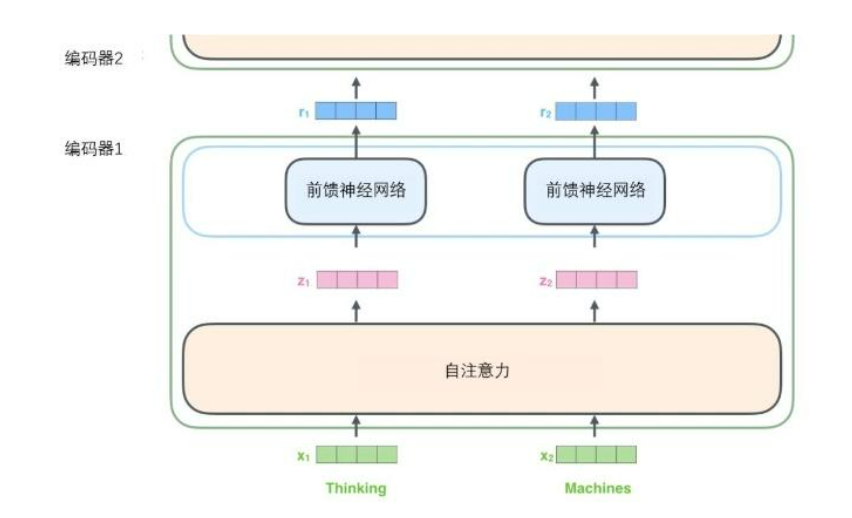
输入序列的每个单词都经过自编码过程。然后,他们各自通过前向传播神经网络——完全相同的网络,而每个向量都分别通过它。
不要被自注意力这个词弄迷糊了,好像每个人都应该熟悉这个概念。
self-attention工作原理:
例如,下列句子是我们想要翻译的输入句子:
The animal didn’t cross the street because it was too tired
这个“it”在这个句子是指什么呢?它指的是street还是这个animal呢?这对于人类来说是一个简单的问题,但是对于算法则不是。
当模型处理这个单词“it”的时候,自注意力机制会允许“it”与“animal”建立联系。
随着模型处理输入序列的每个单词,自注意力会关注整个输入序列的所有单词,帮助模型对本单词更好地进行编码。
如果你熟悉RNN(循环神经网络),回忆一下它是如何维持隐藏层的。RNN会将它已经处理过的前面的所有单词/向量的表示与它正在处理的当前单词/向量结合起来。而自注意力机制会将所有相关单词的理解融入到我们正在处理的单词中。
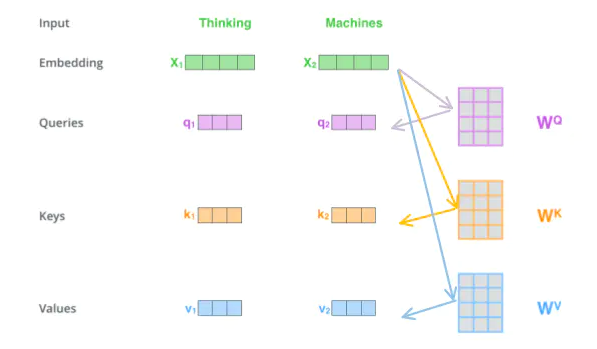
第一步: 为编码器的每个输入单词创建三个向量,即 Query vector, Key vector, Value vector,也就是经典的Q,K,V。
这些向量通过 embedding 和三个矩阵相乘得到
请注意,这些新向量的尺寸小于嵌入向量。它们的维数为64,而嵌入和编码器输入/输出向量的维数为512.它们不一定要小,这是一种架构选择,可以使多头注意力计算(大多数)不变。
将x1乘以WQ得到Query向量 q1,同理得到Key 向量 和, Value 向量
这三个向量对 attention 的计算有很重要的作用
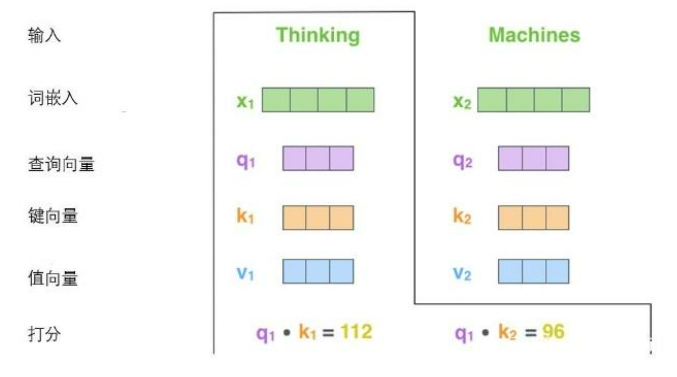
第二步,是计算一个得分
假设我们要计算一个例子中第一个单词 “Thinking” 的 self-attention,就需要根据这个单词,对输入句子的每个单词进行评分,这个分数决定了对其他单词放置多少关注度。
分数的计算方法是,
例如我们正在考虑 Thinking 这个词,就用它的 q1 去乘以每个位置的 ki
第三步和第四步,是将得分加以处理再传递给 softmax
将得分除以 8(因为论文中使用的 key 向量的维数是 64,8 是它的平方根)
这样可以有更稳定的梯度,
然后传递给 softmax,Softmax 就将分数标准化,这样加起来保证为 1。
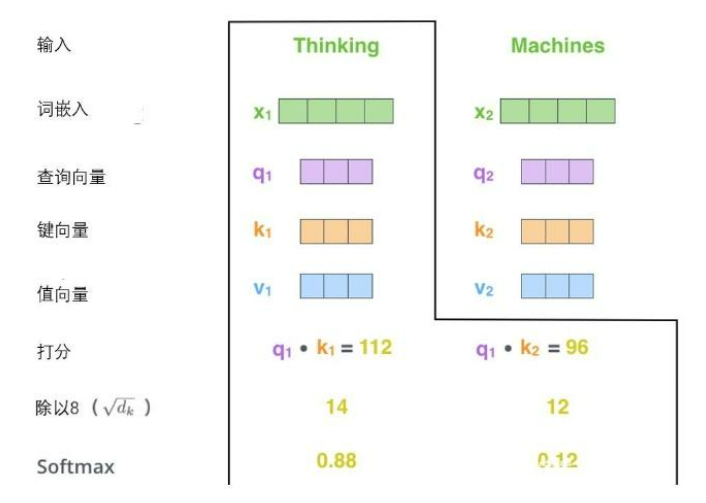
这个 softmax 分数决定了每个单词在该位置被表达的程度。
很明显,这个位置上的单词将具有最高的softmax分数,但有时候注意与当前单词相关的另一个单词是有用的。
第五步,用这个得分乘以每个 value 向量
目的让我们想要关注单词的值保持不变,并通过乘以 0.001 这样小的数字,来淹没不相关的单词
第六步,加权求和这些 value 向量
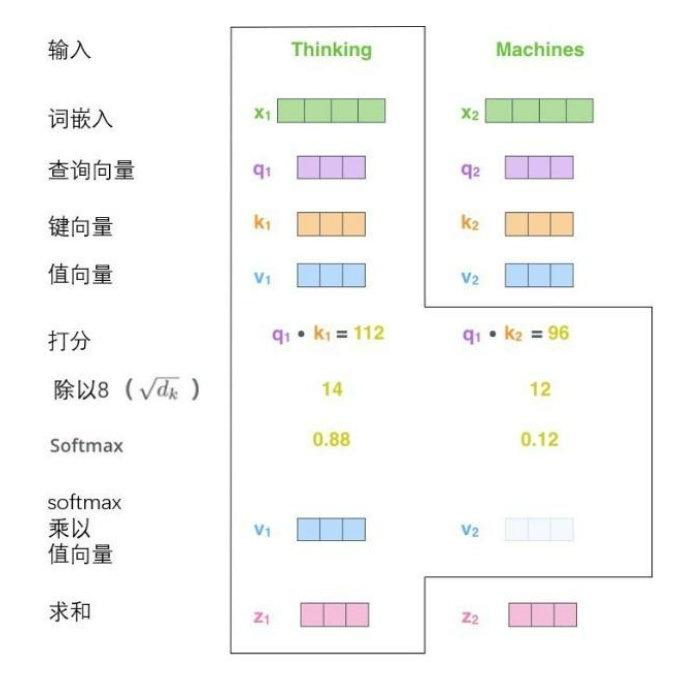
得到的向量接下来要输入到前馈神经网络,在实际实现中用矩阵乘法的形式完成。
通过矩阵运算实现自注意力机制
第一步是计算查询矩阵、键矩阵和值矩阵。为此,我们将将输入句子的词嵌入装进矩阵X中,将其乘以我们训练的权重矩阵(WQ,WK,WV)。
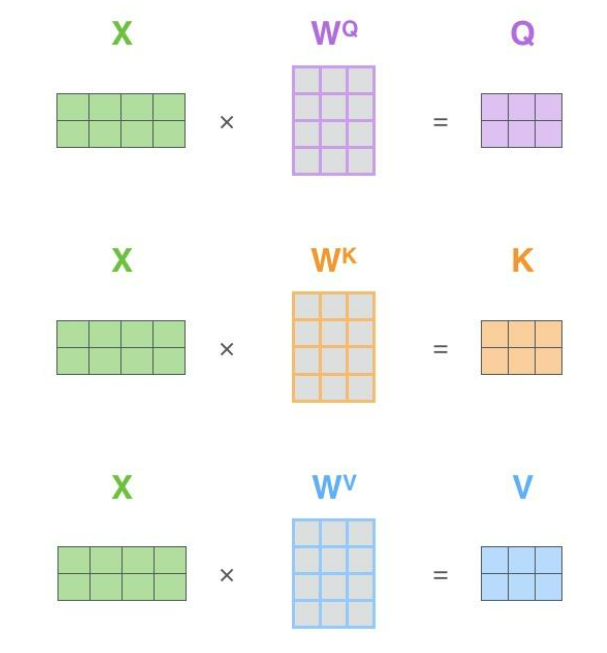
x矩阵中的每一行对应于输入句子中的一个单词。我们再次看到词嵌入向量 (512,或图中的4个格子)和q/k/v向量(64,或图中的3个格子)的大小差异。
最后,由于我们处理的是矩阵,我们可以将步骤2到步骤6合并为一个公式来计算自注意力层的输出。
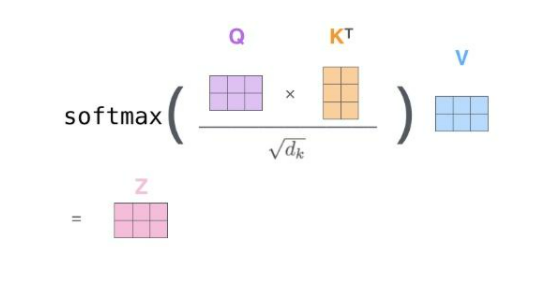
multi-headed 注意力机制
论文中还增加一种称为 multi-headed 注意力机制,可以提升注意力层的性能
它使得模型可以关注不同位置
虽然在上面的例子中,z1 包含了一点其他位置的编码,但当前位置的单词还是占主要作用, 当我们想知道“The animal didn’t cross the street because it was too tired” 中 it 的含义时,这时就需要关注到其他位置
这个机制为注意层提供了多个“表示子空间”。下面我们将具体介绍,
- 经过 multi-headed , 我们会得到和 heads 数目一样多的 Query / Key / Value 权重矩阵组
论文中用了8个,那么每个encoder/decoder我们都会得到 8 个集合。
这些集合都是随机初始化的,经过训练之后,每个集合会将input embeddings 投影到不同的表示子空间中。
- 简单来说,就是定义 8 组权重矩阵,每个单词会做 8 次上面的 self-attention 的计算
这样每个单词会得到 8 个不同的加权求和 z
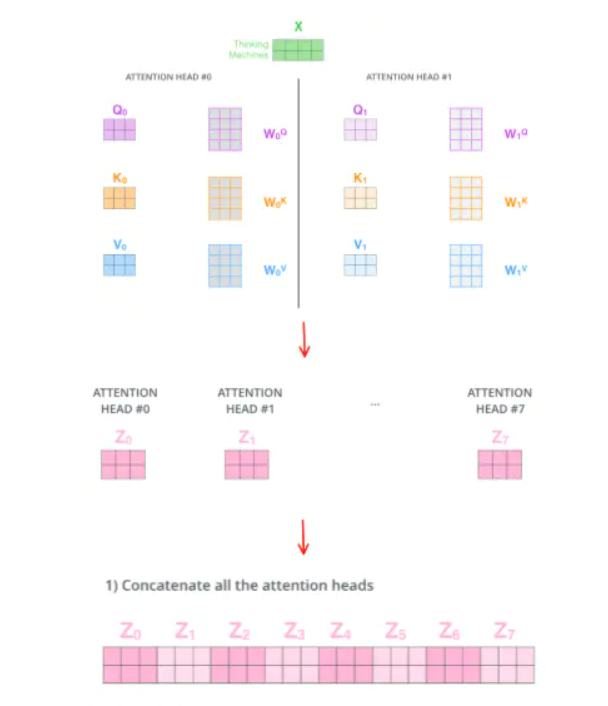
这给我们带来了一点挑战。前馈层不需要8个矩阵,它只需要一个矩阵(由每一个单词的表示向量组成)。
所以我们需要一种方法把这八个矩阵压缩成一个矩阵。
那该怎么做?其实可以直接把这些矩阵拼接在一起,然后用一个附加的权重矩阵WO与它们相乘。
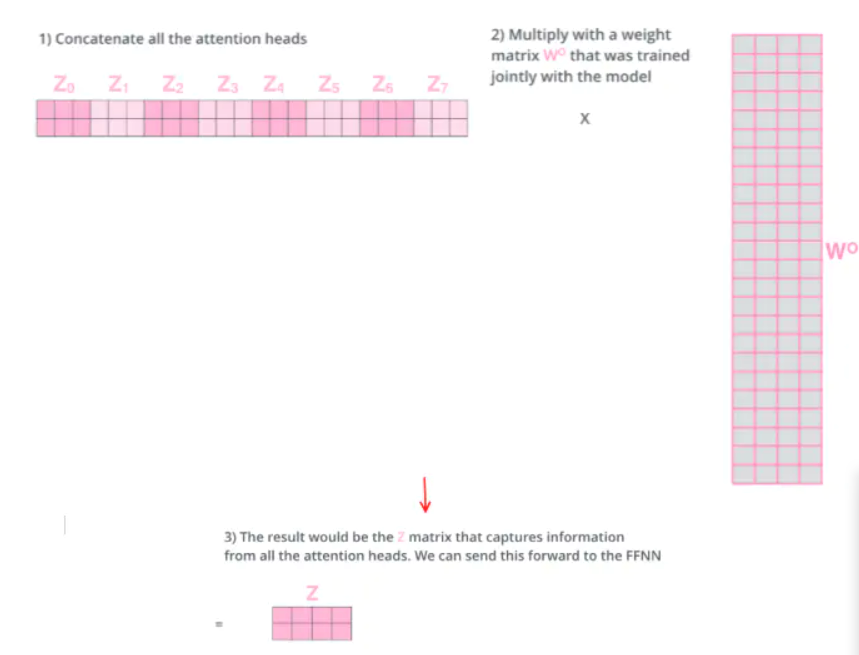
这几乎就是多头自注意力的全部。这确实有好多矩阵,我们试着把它们集中在一个图片中,这样可以一眼看清。
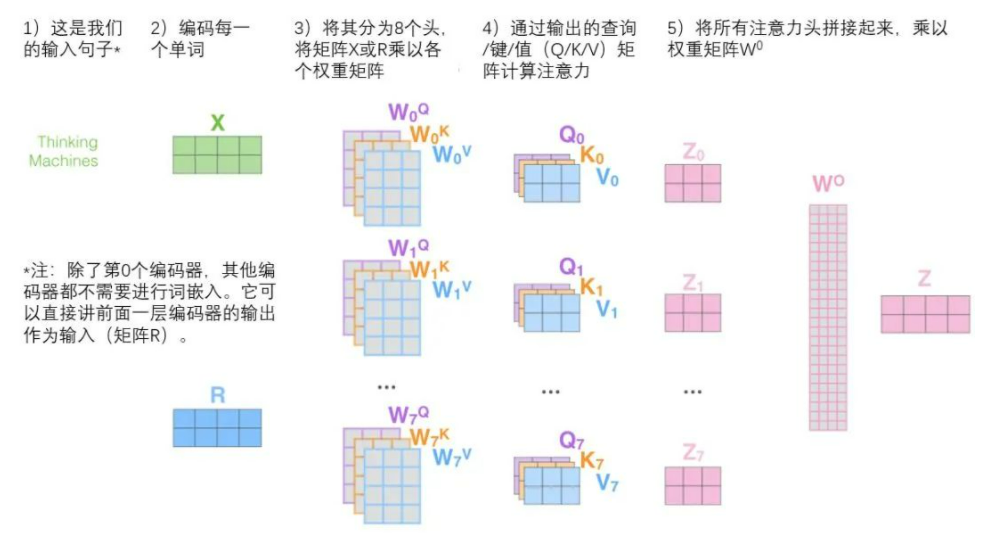
然后后面三张图进行一到多头之间的对比:
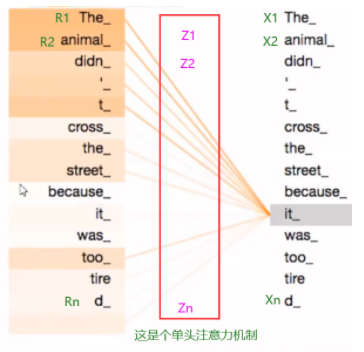
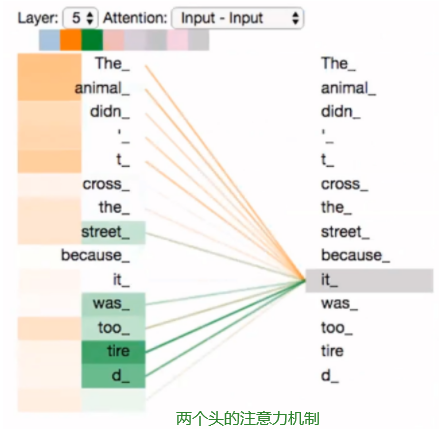

可以明显的看出,其实太多头的话,变得更为难以看懂了
这一部分讲完,基本上transformer的重头戏就已经结束了。
(hu~如释重负
0.3.3 Position-wise Feed-Forward Networks 位置前馈网络
这段原文的东西并不多:
In addition to attention sub-layers, each of the layers in our encoder and decoder contains a fully connected feed-forward network, which is applied to each position separately and identically. This consists of two linear transformations with a ReLU activation in between.
除了Attention子层之外,Encoder和Decoder中的每个层都包含一个全连接前馈网络,分别地应用于每个位置。其中包括两个线性变换,然后使用ReLU作为激活函数。
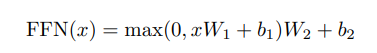
While the linear transformations are the same across different positions, they use different parameters from layer to layer. Another way of describing this is as two convolutions with kernel size 1. The dimensionality of input and output is dmodel = 512, and the inner-layer has dimensionality dff = 2048.
虽然线性变换在不同的位置上是相同的,但它们在不同的层上使用不同的参数在各层之间使用不同的参数。
另一种描述方式是将其作为两个内核大小为1的卷积。
输入和输出的维度是dmodel = 512,内层的维度是dff = 2048。
0.3.4 Embeddings and Softmax
这个部分了解了解即可。
与其他序列转换模型类似,使用预学习的Embedding将输入Token序列和输出Token序列转化为维向量。
还使用常用的预训练的线性变换和Softmax函数将解码器输出转换为预测下一个Token的概率。
在模型中,在两个Embedding层和Pre-softmax线性变换之间共享相同的权重矩阵。在Embedding层中,我们将这些权重乘以 d m o d e l \sqrt{d_{model}} dmodel。
0.3.5 Positional Encoding 位置编码
个人感觉这个部分也是了解了解即可。(其实是我自己没有看太懂,被数学那一块受住了限制)
知乎有个大佬讲的有数学推理,建议感兴趣的看一下
一文读懂Transformer模型的位置编码https://zhuanlan.zhihu.com/p/106644634
到目前为止,由于模型不包含递归和卷积,为了使模型利用序列的顺序,必须注入一些关于相对或绝对位置的信息
为了解决这个问题,Transformer为每个输入的词嵌入添加了一个向量。
这些向量遵循模型学习到的特定模式,这有助于确定每个单词的位置,或序列中不同单词之间的距离。
这里的价值是,将位置向量添加到词嵌入中使得它们在接下来的运算中,能够更好地表达的词与词之间的距离。
In this work, we use sine and cosine functions of different frequencies:
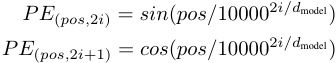
where p o s pos pos is the position and i i i is the dimension. That is, each dimension of the positional encoding corresponds to a sinusoid. The wavelengths form a geometric progression from 2 π 2π 2π to 10000 ∗ 2 π 10000*2π 10000∗2π. We chose this function because we hypothesized it would allow the model to easily learn to attend by relative positions, since for any fixed offset k k k, P E p o s + k PE_{pos+k} PEpos+k can be represented as a linear function of P E p o s PE_{pos} PEpos.
其中pos是位置,i是维度。也就是说,位置编码的每个维度对应于一个正弦波,波长形成一个从2π到10000*2π的几何级数。我们选择这个正弦函数是因为我们假设它能让模型很容易地学会通过相对位置来关注,因为对于任何固定的偏移量k,PEpos+k可以被表示为PEpos的线性函数。
然后论文中再次进行实验发现这二者公式使用后没有什么太大的变化,最终使用正弦函数,因为它可以让模型推断出比训练中遇到的更长序列长度。
下面将用图来解释这一系列流程
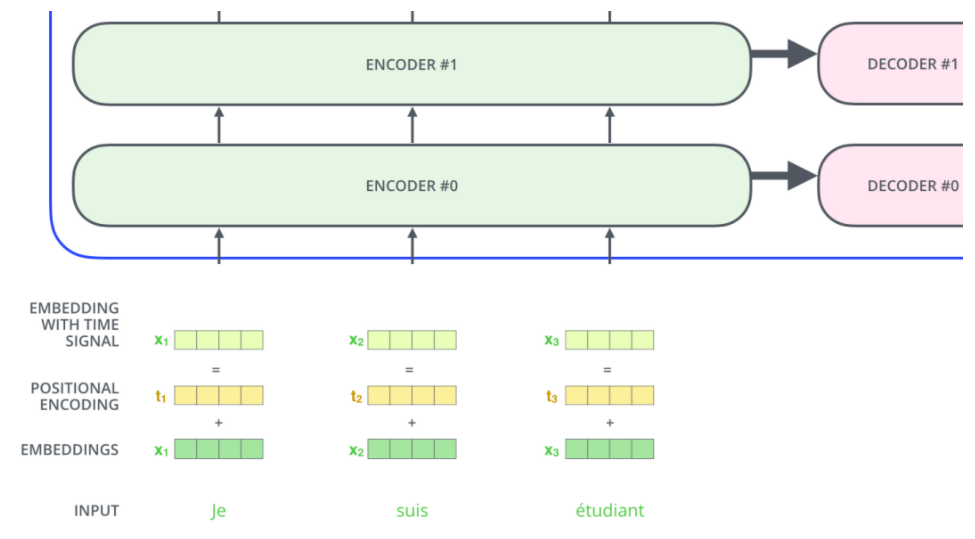
为了让模型了解单词的顺序,我们添加了带有位置编码的向量–这些向量的值遵循特定的模式。
如果我们假设词向量的维度是 4,那么带有位置编码的向量可能如下所示:
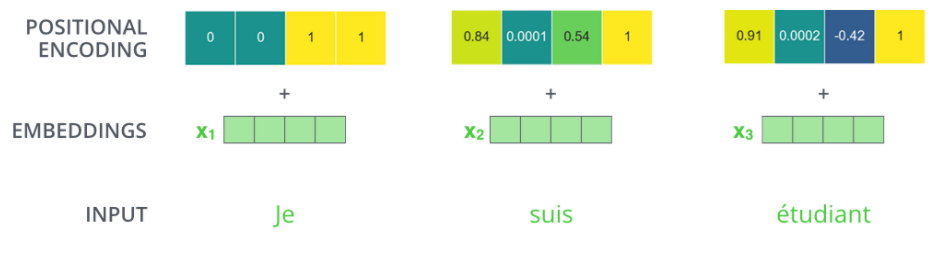
在下图中,是20个单词的 positional encoding,每行代表一个单词的位置编码,即第一行是加在输入序列中第一个词嵌入的,每行包含 512 个值, 每个值介于 -1 和 1 之间,用颜色表示出来。
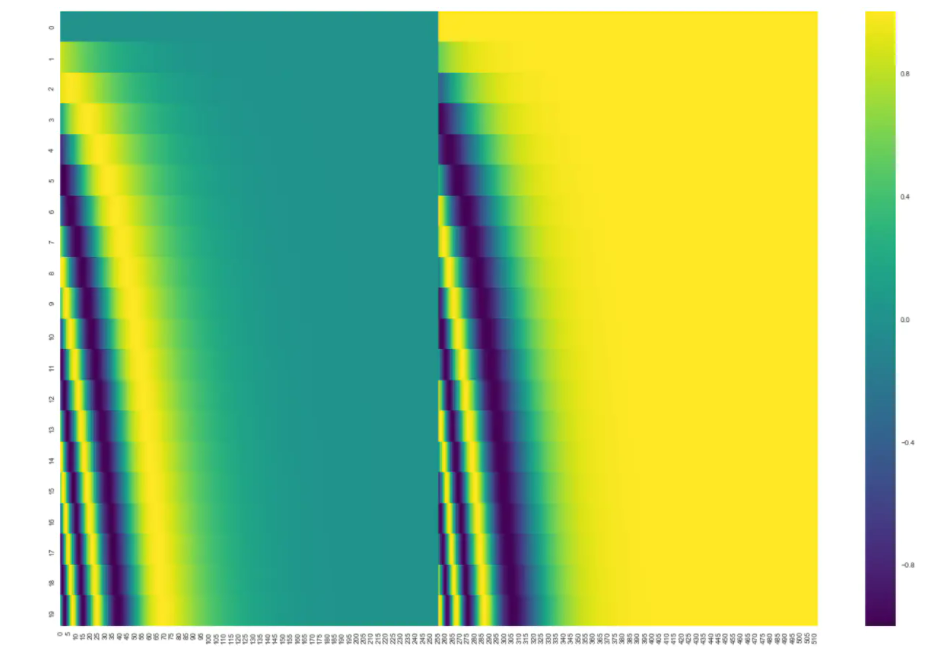
这是一个真实的例子,包含了 20 个词,每个词向量的维度是 512。你可以看到,它看起来像从中间一分为二。这是因为左半部分的值是由 sin 函数产生的,而右半部分的值是由 cos 函数产生的,然后将他们拼接起来,得到每个位置编码向量。
而论文中的方法和上面图中的稍有不同,它不是直接拼接两个向量,而是将两个向量交织在一起。如下图所示。
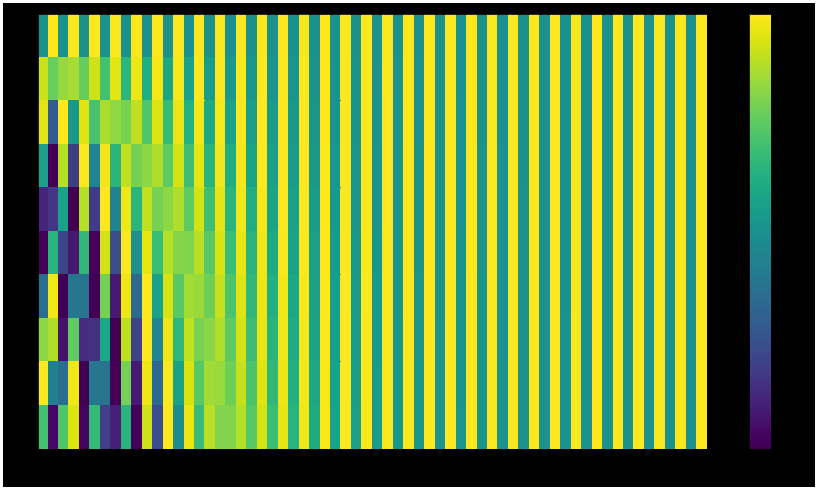
这不是唯一一种生成位置编码的方法。但这种方法的优点是:可以扩展到未知的序列长度。
例如:当我们的模型需要翻译一个句子,而这个句子的长度大于训练集中所有句子的长度,这时,这种位置编码的方法也可以生成一样长的位置编码向量。
0.3.6 补充部分—残差模块(简介)
论文没有细说残差模块,这里简单说一说。
每个 encoders 和 decoders 里面的 self-attention, ffnn,encoders-decoders attention 层,都有 residual 连接,还有一步 layer-normalization。
细化到图中就是:
编码器的每个子层(Self Attention 层和 FFNN)都有一个残差连接和层标准化(layer-normalization)。
在解码器的子层里面也有层标准化(layer-normalization)。
Layer Normalization是一个通用的技术,其本质是规范优化空间,加速收敛,这个不再细说。
假设一个 Transformer 是由 2 层编码器和两层解码器组成的,如下图所示。
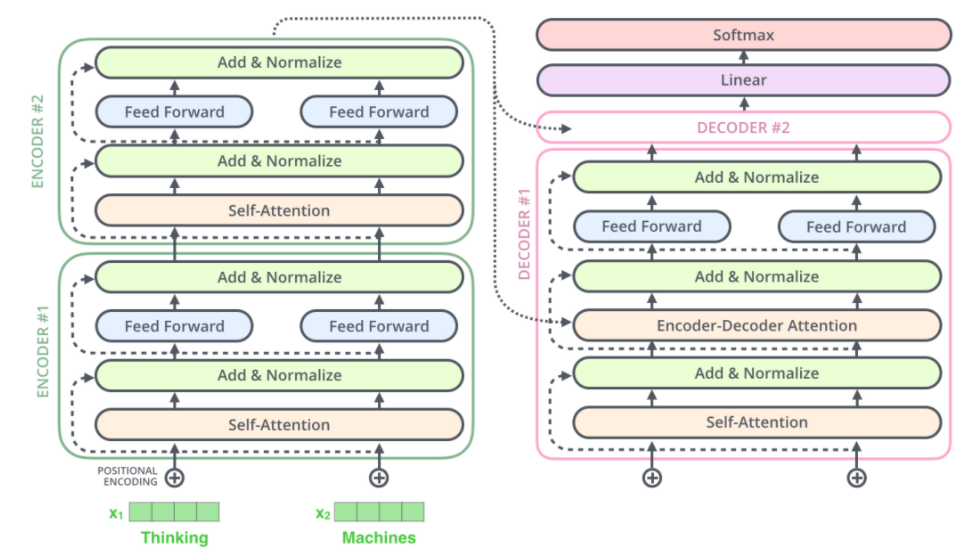
残差块如下:
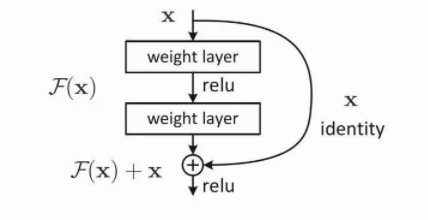
可以看到X是这一层残差块的输入,也称作F(x)为残差,x为输入值,F(X)是经过第一层线性变化并激活后的输出,该图表示在残差网络中,第二层进行线性变化之后激活之前,F(x)加入了这一层输入值X,然后再进行激活后输出。
在第二层输出值激活前加入X,这条路径称作shortcut连接。
0.4 Why Self-Attention 为什么要用自注意力机制
这一部分,就不再赘述了,感兴趣的自己看原文即可。
同时推荐一篇文章值得细读,对为什么要用自注意力机制介绍的很详细
https://zhuanlan.zhihu.com/p/104393915
0.5 Training 训练
这一部分主要是说他们的数据是什么,批处理的设置,硬件用的什么,训练了多长时间,优化器的策略是什么,以及正规化的方式。
最终达到了如下的效果:
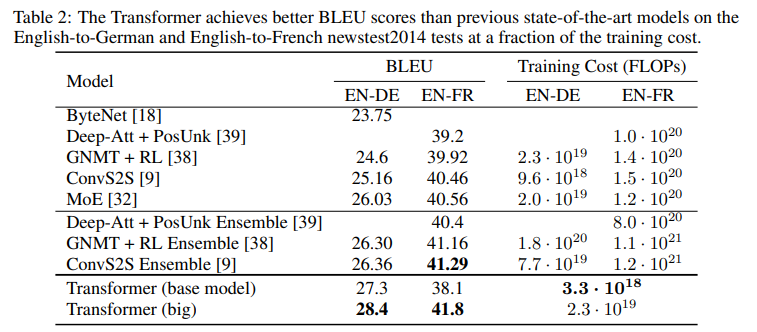
特别说明:
Label Smoothing: During training, we employed label smoothing of value e l s e_{ls} els = 0.1.
This hurts perplexity, as the model learns to be more unsure, but improves accuracy and BLEU score.
标签平滑:在训练过程中,我们采用了 e l s e_{ls} els = 0.1的标签平滑。这降低了复杂度,但是模型学会了更多的不确定性,但提高了准确性和BLEU得分。
0.6 Results 结果
这个章节主要说了transformer在机器翻译和不同参数对模型的影响。
他们通过实测来进行统计效果。这里我们不做深究,仅仅拿他们最好的参数来用就行了。
0.7 Conclusion 结论
这个部分当然也可以忽略了!概括起来就是总结现在,展望未来。
总结
-
全文看下来,不去深究的话,不算是那么的难以理解,重点还是在复现代码上,要将语言转换为代码,还是非常的需要代码功底,将会在下一篇进行详细的复现。
-
Transformer是17年提出来的模型,在当时确实引起了很大的轰动,但是到现在事后看来,Transformer模型的能力很强,即便是现在霸榜的前十名也是跟transformer息息相关的,但是并不像论文题目说的那样《attention is all you need》,反而我觉得论文最大的贡献在于它第一次做到了在自然语言处理任务中把网络的深度堆叠上去还能取得很好的效果,而机器翻译恰好也是一个目前数据量非常丰富且问题本身难度不大的一个任务了,这样充分发挥了 Transformer 的优势。
-
另外self-attention 其实并不是 Transformer 的全部(是否self-attention的思想首次出现于该论文中也不得而知,Google也总是喜欢将以前没有明确定义的概念(但是做法已经很明显了),给出一个明确的定义或者做集大成者的工作,如bert),实际上从深度 CNN 网络中借鉴而来的 FFN 可能更加重要。
-
理智看待Transformer,面对不同的任务,选择最合适自己任务的模型就好了~
个人总结
全网同名: iterhui
我在AI Studio上获得钻石等级,点亮10个徽章,来互关呀~
https://aistudio.baidu.com/aistudio/personalcenter/thirdview/643467
参考文献

学大模型,用大模型上飞桨星河社区!每天8点V100G算力免费领!免费领取ERNIE 4.0 100w Token >>>
更多推荐



 3
3 0
0- 0



 已为社区贡献1436条内容
已为社区贡献1436条内容

所有评论(0)