
CCKS 2021篇章级事件元素抽取
知识图谱课程实践项目-在线运行版
项目背景
项目说明
- 本实践项目依托于CCKS 2021:面向金融领域的篇章级事件抽取和事件因果关系抽取(一)篇章级事件元素抽取任务
- 代码方案参考2021语言与智能技术竞赛:多形态信息抽取任务的官方基线
- 本实践项目在线部署在百度AI Studio平台,支持免费使用Tesla V100 32G,在线训练预测运行
# 安装paddlenlp最新版本
!pip install --upgrade paddlenlp
Looking in indexes: https://mirror.baidu.com/pypi/simple/
Collecting paddlenlp
[?25l Downloading https://mirror.baidu.com/pypi/packages/62/10/ccc761d3e3a994703f31a4d0f93db0d13789d1c624a0cbbe9fe6439ed601/paddlenlp-2.0.5-py3-none-any.whl (435kB)
[K |████████████████████████████████| 440kB 12.1MB/s eta 0:00:01
[?25hRequirement already satisfied, skipping upgrade: jieba in /opt/conda/envs/python35-paddle120-env/lib/python3.7/site-packages (from paddlenlp) (0.42.1)
Requirement already satisfied, skipping upgrade: visualdl in /opt/conda/envs/python35-paddle120-env/lib/python3.7/site-packages (from paddlenlp) (2.1.1)
Requirement already satisfied, skipping upgrade: h5py in /opt/conda/envs/python35-paddle120-env/lib/python3.7/site-packages (from paddlenlp) (2.9.0)
Collecting multiprocess (from paddlenlp)
[?25l Downloading https://mirror.baidu.com/pypi/packages/aa/d8/d7bbcef5c03890f5fe983d8419b0c5236af3657c5aa9bddf1991a6ed813a/multiprocess-0.70.12.2-py37-none-any.whl (112kB)
[K |████████████████████████████████| 112kB 19.3MB/s eta 0:00:01
[?25hRequirement already satisfied, skipping upgrade: seqeval in /opt/conda/envs/python35-paddle120-env/lib/python3.7/site-packages (from paddlenlp) (1.2.2)
Requirement already satisfied, skipping upgrade: colorama in /opt/conda/envs/python35-paddle120-env/lib/python3.7/site-packages (from paddlenlp) (0.4.4)
Requirement already satisfied, skipping upgrade: colorlog in /opt/conda/envs/python35-paddle120-env/lib/python3.7/site-packages (from paddlenlp) (4.1.0)
Requirement already satisfied, skipping upgrade: six>=1.14.0 in /opt/conda/envs/python35-paddle120-env/lib/python3.7/site-packages (from visualdl->paddlenlp) (1.15.0)
Requirement already satisfied, skipping upgrade: flask>=1.1.1 in /opt/conda/envs/python35-paddle120-env/lib/python3.7/site-packages (from visualdl->paddlenlp) (1.1.1)
Requirement already satisfied, skipping upgrade: bce-python-sdk in /opt/conda/envs/python35-paddle120-env/lib/python3.7/site-packages (from visualdl->paddlenlp) (0.8.53)
Requirement already satisfied, skipping upgrade: protobuf>=3.11.0 in /opt/conda/envs/python35-paddle120-env/lib/python3.7/site-packages (from visualdl->paddlenlp) (3.14.0)
Requirement already satisfied, skipping upgrade: numpy in /opt/conda/envs/python35-paddle120-env/lib/python3.7/site-packages (from visualdl->paddlenlp) (1.20.3)
Requirement already satisfied, skipping upgrade: pre-commit in /opt/conda/envs/python35-paddle120-env/lib/python3.7/site-packages (from visualdl->paddlenlp) (1.21.0)
Requirement already satisfied, skipping upgrade: Pillow>=7.0.0 in /opt/conda/envs/python35-paddle120-env/lib/python3.7/site-packages (from visualdl->paddlenlp) (7.1.2)
Requirement already satisfied, skipping upgrade: flake8>=3.7.9 in /opt/conda/envs/python35-paddle120-env/lib/python3.7/site-packages (from visualdl->paddlenlp) (3.8.2)
Requirement already satisfied, skipping upgrade: shellcheck-py in /opt/conda/envs/python35-paddle120-env/lib/python3.7/site-packages (from visualdl->paddlenlp) (0.7.1.1)
Requirement already satisfied, skipping upgrade: requests in /opt/conda/envs/python35-paddle120-env/lib/python3.7/site-packages (from visualdl->paddlenlp) (2.22.0)
Requirement already satisfied, skipping upgrade: Flask-Babel>=1.0.0 in /opt/conda/envs/python35-paddle120-env/lib/python3.7/site-packages (from visualdl->paddlenlp) (1.0.0)
Collecting dill>=0.3.4 (from multiprocess->paddlenlp)
[?25l Downloading https://mirror.baidu.com/pypi/packages/b6/c3/973676ceb86b60835bb3978c6db67a5dc06be6cfdbd14ef0f5a13e3fc9fd/dill-0.3.4-py2.py3-none-any.whl (86kB)
[K |████████████████████████████████| 92kB 13.2MB/s eta 0:00:01
[?25hRequirement already satisfied, skipping upgrade: scikit-learn>=0.21.3 in /opt/conda/envs/python35-paddle120-env/lib/python3.7/site-packages (from seqeval->paddlenlp) (0.24.2)
Requirement already satisfied, skipping upgrade: Jinja2>=2.10.1 in /opt/conda/envs/python35-paddle120-env/lib/python3.7/site-packages (from flask>=1.1.1->visualdl->paddlenlp) (2.10.1)
Requirement already satisfied, skipping upgrade: click>=5.1 in /opt/conda/envs/python35-paddle120-env/lib/python3.7/site-packages (from flask>=1.1.1->visualdl->paddlenlp) (7.0)
Requirement already satisfied, skipping upgrade: itsdangerous>=0.24 in /opt/conda/envs/python35-paddle120-env/lib/python3.7/site-packages (from flask>=1.1.1->visualdl->paddlenlp) (1.1.0)
Requirement already satisfied, skipping upgrade: Werkzeug>=0.15 in /opt/conda/envs/python35-paddle120-env/lib/python3.7/site-packages (from flask>=1.1.1->visualdl->paddlenlp) (0.16.0)
Requirement already satisfied, skipping upgrade: pycryptodome>=3.8.0 in /opt/conda/envs/python35-paddle120-env/lib/python3.7/site-packages (from bce-python-sdk->visualdl->paddlenlp) (3.9.9)
Requirement already satisfied, skipping upgrade: future>=0.6.0 in /opt/conda/envs/python35-paddle120-env/lib/python3.7/site-packages (from bce-python-sdk->visualdl->paddlenlp) (0.18.0)
Requirement already satisfied, skipping upgrade: pyyaml in /opt/conda/envs/python35-paddle120-env/lib/python3.7/site-packages (from pre-commit->visualdl->paddlenlp) (5.1.2)
Requirement already satisfied, skipping upgrade: toml in /opt/conda/envs/python35-paddle120-env/lib/python3.7/site-packages (from pre-commit->visualdl->paddlenlp) (0.10.0)
Requirement already satisfied, skipping upgrade: cfgv>=2.0.0 in /opt/conda/envs/python35-paddle120-env/lib/python3.7/site-packages (from pre-commit->visualdl->paddlenlp) (2.0.1)
Requirement already satisfied, skipping upgrade: virtualenv>=15.2 in /opt/conda/envs/python35-paddle120-env/lib/python3.7/site-packages (from pre-commit->visualdl->paddlenlp) (16.7.9)
Requirement already satisfied, skipping upgrade: importlib-metadata; python_version < "3.8" in /opt/conda/envs/python35-paddle120-env/lib/python3.7/site-packages (from pre-commit->visualdl->paddlenlp) (0.23)
Requirement already satisfied, skipping upgrade: nodeenv>=0.11.1 in /opt/conda/envs/python35-paddle120-env/lib/python3.7/site-packages (from pre-commit->visualdl->paddlenlp) (1.3.4)
Requirement already satisfied, skipping upgrade: identify>=1.0.0 in /opt/conda/envs/python35-paddle120-env/lib/python3.7/site-packages (from pre-commit->visualdl->paddlenlp) (1.4.10)
Requirement already satisfied, skipping upgrade: aspy.yaml in /opt/conda/envs/python35-paddle120-env/lib/python3.7/site-packages (from pre-commit->visualdl->paddlenlp) (1.3.0)
Requirement already satisfied, skipping upgrade: pycodestyle<2.7.0,>=2.6.0a1 in /opt/conda/envs/python35-paddle120-env/lib/python3.7/site-packages (from flake8>=3.7.9->visualdl->paddlenlp) (2.6.0)
Requirement already satisfied, skipping upgrade: mccabe<0.7.0,>=0.6.0 in /opt/conda/envs/python35-paddle120-env/lib/python3.7/site-packages (from flake8>=3.7.9->visualdl->paddlenlp) (0.6.1)
Requirement already satisfied, skipping upgrade: pyflakes<2.3.0,>=2.2.0 in /opt/conda/envs/python35-paddle120-env/lib/python3.7/site-packages (from flake8>=3.7.9->visualdl->paddlenlp) (2.2.0)
Requirement already satisfied, skipping upgrade: idna<2.9,>=2.5 in /opt/conda/envs/python35-paddle120-env/lib/python3.7/site-packages (from requests->visualdl->paddlenlp) (2.8)
Requirement already satisfied, skipping upgrade: urllib3!=1.25.0,!=1.25.1,<1.26,>=1.21.1 in /opt/conda/envs/python35-paddle120-env/lib/python3.7/site-packages (from requests->visualdl->paddlenlp) (1.25.6)
Requirement already satisfied, skipping upgrade: certifi>=2017.4.17 in /opt/conda/envs/python35-paddle120-env/lib/python3.7/site-packages (from requests->visualdl->paddlenlp) (2019.9.11)
Requirement already satisfied, skipping upgrade: chardet<3.1.0,>=3.0.2 in /opt/conda/envs/python35-paddle120-env/lib/python3.7/site-packages (from requests->visualdl->paddlenlp) (3.0.4)
Requirement already satisfied, skipping upgrade: pytz in /opt/conda/envs/python35-paddle120-env/lib/python3.7/site-packages (from Flask-Babel>=1.0.0->visualdl->paddlenlp) (2019.3)
Requirement already satisfied, skipping upgrade: Babel>=2.3 in /opt/conda/envs/python35-paddle120-env/lib/python3.7/site-packages (from Flask-Babel>=1.0.0->visualdl->paddlenlp) (2.8.0)
Requirement already satisfied, skipping upgrade: joblib>=0.11 in /opt/conda/envs/python35-paddle120-env/lib/python3.7/site-packages (from scikit-learn>=0.21.3->seqeval->paddlenlp) (0.14.1)
Requirement already satisfied, skipping upgrade: scipy>=0.19.1 in /opt/conda/envs/python35-paddle120-env/lib/python3.7/site-packages (from scikit-learn>=0.21.3->seqeval->paddlenlp) (1.6.3)
Requirement already satisfied, skipping upgrade: threadpoolctl>=2.0.0 in /opt/conda/envs/python35-paddle120-env/lib/python3.7/site-packages (from scikit-learn>=0.21.3->seqeval->paddlenlp) (2.1.0)
Requirement already satisfied, skipping upgrade: MarkupSafe>=0.23 in /opt/conda/envs/python35-paddle120-env/lib/python3.7/site-packages (from Jinja2>=2.10.1->flask>=1.1.1->visualdl->paddlenlp) (1.1.1)
Requirement already satisfied, skipping upgrade: zipp>=0.5 in /opt/conda/envs/python35-paddle120-env/lib/python3.7/site-packages (from importlib-metadata; python_version < "3.8"->pre-commit->visualdl->paddlenlp) (0.6.0)
Requirement already satisfied, skipping upgrade: more-itertools in /opt/conda/envs/python35-paddle120-env/lib/python3.7/site-packages (from zipp>=0.5->importlib-metadata; python_version < "3.8"->pre-commit->visualdl->paddlenlp) (7.2.0)
[31mERROR: blackhole 1.0.1 has requirement numpy<=1.19.5, but you'll have numpy 1.20.3 which is incompatible.[0m
Installing collected packages: dill, multiprocess, paddlenlp
Found existing installation: dill 0.3.3
Uninstalling dill-0.3.3:
Successfully uninstalled dill-0.3.3
Found existing installation: paddlenlp 2.0.0rc7
Uninstalling paddlenlp-2.0.0rc7:
Successfully uninstalled paddlenlp-2.0.0rc7
Successfully installed dill-0.3.4 multiprocess-0.70.12.2 paddlenlp-2.0.5
%cd event_element_extraction/
/home/aistudio/event_element_extraction
# 数据格式处理对齐
!bash ./run_event_element_extraction.sh ccks2lic_data_prepare
check and create directory
dir ./ckpt exist
dir ./ckpt/ccks exist
dir ./submit exist
start ccks ccks2lic data prepare
=================start generate train and dev data process==============
=================end generate train and dev data process==============
=================start generate test data process==============
=================end generate test data process==============
end ccks ccks2lic data prepare
# 将原始数据预处理成序列标注格式数据
!bash ./run_event_element_extraction.sh data_prepare
check and create directory
dir ./ckpt exist
dir ./ckpt/ccks exist
dir ./submit exist
start cckslic2021 data prepare
=================CCKS 2021 EVENT ENTITY DATASET==============
=================start schema process==============
input path ./conf/ccks/event_schema.json
save trigger tag 3 at ./conf/ccks/trigger_tag.dict
save trigger tag 27 at ./conf/ccks/role_tag.dict
save enum tag 0 at ./conf/ccks/enum_tag.dict
=================end schema process===============
=================start data process==============
********** start document process **********
train 21879 dev 5436 test 5483
********** end document process **********
********** start sentence process **********
----trigger------for dir ./data/ccks/sentence to ./data/ccks/trigger
train 3111 dev 756
----role------for dir ./data/ccks/sentence to ./data/ccks/role
train 3111 dev 756
----enum------for dir ./data/ccks/sentence to ./data/ccks/enum
train 1 dev 1
********** end sentence process **********
=================end data process==============
end cckslic2021 data prepare
# 模型训练
!bash run_event_element_extraction.sh role_train
check and create directory
dir ./ckpt exist
dir ./ckpt/ccks exist
dir ./submit exist
start ccks role train
/opt/conda/envs/python35-paddle120-env/lib/python3.7/site-packages/paddle/fluid/layers/utils.py:26: DeprecationWarning: `np.int` is a deprecated alias for the builtin `int`. To silence this warning, use `int` by itself. Doing this will not modify any behavior and is safe. When replacing `np.int`, you may wish to use e.g. `np.int64` or `np.int32` to specify the precision. If you wish to review your current use, check the release note link for additional information.
Deprecated in NumPy 1.20; for more details and guidance: https://numpy.org/devdocs/release/1.20.0-notes.html#deprecations
def convert_to_list(value, n, name, dtype=np.int):
----------- Configuration Arguments -----------
gpus: 0
heter_worker_num: None
heter_workers:
http_port: None
ips: 127.0.0.1
log_dir: log
nproc_per_node: None
server_num: None
servers:
training_script: sequence_labeling.py
training_script_args: ['--num_epoch', '10', '--learning_rate', '5e-5', '--tag_path', './conf/ccks/role_tag.dict', '--train_data', './data/ccks/role/train.tsv', '--dev_data', './data/ccks/role/dev.tsv', '--test_data', './data/ccks/role/test.tsv', '--predict_data', './data/ccks/sentence/test.json', '--do_train', 'True', '--do_predict', 'False', '--max_seq_len', '400', '--batch_size', '32', '--skip_step', '10', '--valid_step', '50', '--checkpoints', './ckpt/ccks/role', '--init_ckpt', './ckpt/ccks/role/best.pdparams', '--predict_save_path', './ckpt/ccks/role/test_pred.json', '--device', 'gpu']
worker_num: None
workers:
------------------------------------------------
WARNING 2021-06-28 17:11:43,536 launch.py:316] Not found distinct arguments and compiled with cuda. Default use collective mode
launch train in GPU mode
INFO 2021-06-28 17:11:43,538 launch_utils.py:471] Local start 1 processes. First process distributed environment info (Only For Debug):
+=======================================================================================+
| Distributed Envs Value |
+---------------------------------------------------------------------------------------+
| PADDLE_TRAINER_ID 0 |
| PADDLE_CURRENT_ENDPOINT 127.0.0.1:34156 |
| PADDLE_TRAINERS_NUM 1 |
| PADDLE_TRAINER_ENDPOINTS 127.0.0.1:34156 |
| FLAGS_selected_gpus 0 |
+=======================================================================================+
INFO 2021-06-28 17:11:43,538 launch_utils.py:475] details abouts PADDLE_TRAINER_ENDPOINTS can be found in log/endpoints.log, and detail running logs maybe found in log/workerlog.0
/opt/conda/envs/python35-paddle120-env/lib/python3.7/site-packages/paddle/fluid/layers/utils.py:26: DeprecationWarning: `np.int` is a deprecated alias for the builtin `int`. To silence this warning, use `int` by itself. Doing this will not modify any behavior and is safe. When replacing `np.int`, you may wish to use e.g. `np.int64` or `np.int32` to specify the precision. If you wish to review your current use, check the release note link for additional information.
Deprecated in NumPy 1.20; for more details and guidance: https://numpy.org/devdocs/release/1.20.0-notes.html#deprecations
def convert_to_list(value, n, name, dtype=np.int):
[2021-06-28 17:11:44,979] [ INFO] - Found /home/aistudio/.paddlenlp/models/ernie-1.0/vocab.txt
[2021-06-28 17:11:44,992] [ INFO] - Already cached /home/aistudio/.paddlenlp/models/ernie-1.0/ernie_v1_chn_base.pdparams
W0628 17:11:44.993443 516 device_context.cc:362] Please NOTE: device: 0, GPU Compute Capability: 7.0, Driver API Version: 10.1, Runtime API Version: 10.1
W0628 17:11:44.997738 516 device_context.cc:372] device: 0, cuDNN Version: 7.6.
============start train==========
train epoch: 0 - step: 10 (total: 980) - loss: 0.606767
train epoch: 0 - step: 20 (total: 980) - loss: 0.678302
train epoch: 0 - step: 30 (total: 980) - loss: 0.446083
train epoch: 0 - step: 40 (total: 980) - loss: 0.425867
train epoch: 0 - step: 50 (total: 980) - loss: 0.332645
dev step: 50 - loss: 0.35571, precision: 0.00285, recall: 0.00070, f1: 0.00112 current best 0.00000
==============================================save best model best performerence 0.001121
train epoch: 0 - step: 60 (total: 980) - loss: 0.278910
train epoch: 0 - step: 70 (total: 980) - loss: 0.224100
train epoch: 0 - step: 80 (total: 980) - loss: 0.213022
train epoch: 0 - step: 90 (total: 980) - loss: 0.194727
train epoch: 1 - step: 100 (total: 980) - loss: 0.189554
dev step: 100 - loss: 0.16109, precision: 0.43696, recall: 0.63586, f1: 0.51797 current best 0.00112
==============================================save best model best performerence 0.517971
train epoch: 1 - step: 110 (total: 980) - loss: 0.153203
train epoch: 1 - step: 120 (total: 980) - loss: 0.131498
train epoch: 1 - step: 130 (total: 980) - loss: 0.127948
train epoch: 1 - step: 140 (total: 980) - loss: 0.121271
train epoch: 1 - step: 150 (total: 980) - loss: 0.122285
dev step: 150 - loss: 0.12660, precision: 0.48234, recall: 0.64772, f1: 0.55293 current best 0.51797
==============================================save best model best performerence 0.552925
train epoch: 1 - step: 160 (total: 980) - loss: 0.114661
train epoch: 1 - step: 170 (total: 980) - loss: 0.124772
train epoch: 1 - step: 180 (total: 980) - loss: 0.089885
train epoch: 1 - step: 190 (total: 980) - loss: 0.104141
train epoch: 2 - step: 200 (total: 980) - loss: 0.104110
dev step: 200 - loss: 0.12207, precision: 0.48329, recall: 0.71643, f1: 0.57721 current best 0.55293
==============================================save best model best performerence 0.577209
train epoch: 2 - step: 210 (total: 980) - loss: 0.097670
train epoch: 2 - step: 220 (total: 980) - loss: 0.083028
train epoch: 2 - step: 230 (total: 980) - loss: 0.116537
train epoch: 2 - step: 240 (total: 980) - loss: 0.104902
train epoch: 2 - step: 250 (total: 980) - loss: 0.076913
dev step: 250 - loss: 0.10550, precision: 0.59935, recall: 0.70596, f1: 0.64830 current best 0.57721
==============================================save best model best performerence 0.648302
train epoch: 2 - step: 260 (total: 980) - loss: 0.110526
train epoch: 2 - step: 270 (total: 980) - loss: 0.083158
train epoch: 2 - step: 280 (total: 980) - loss: 0.077159
train epoch: 2 - step: 290 (total: 980) - loss: 0.116299
train epoch: 3 - step: 300 (total: 980) - loss: 0.074681
dev step: 300 - loss: 0.11054, precision: 0.61404, recall: 0.77468, f1: 0.68507 current best 0.64830
==============================================save best model best performerence 0.685071
train epoch: 3 - step: 310 (total: 980) - loss: 0.073892
train epoch: 3 - step: 320 (total: 980) - loss: 0.091613
train epoch: 3 - step: 330 (total: 980) - loss: 0.076240
train epoch: 3 - step: 340 (total: 980) - loss: 0.085282
train epoch: 3 - step: 350 (total: 980) - loss: 0.087634
dev step: 350 - loss: 0.10300, precision: 0.63931, recall: 0.80433, f1: 0.71239 current best 0.68507
==============================================save best model best performerence 0.712388
train epoch: 3 - step: 360 (total: 980) - loss: 0.058747
train epoch: 3 - step: 370 (total: 980) - loss: 0.122197
train epoch: 3 - step: 380 (total: 980) - loss: 0.075389
train epoch: 3 - step: 390 (total: 980) - loss: 0.076576
train epoch: 4 - step: 400 (total: 980) - loss: 0.089777
dev step: 400 - loss: 0.12077, precision: 0.62402, recall: 0.77921, f1: 0.69304 current best 0.71239
train epoch: 4 - step: 410 (total: 980) - loss: 0.084196
train epoch: 4 - step: 420 (total: 980) - loss: 0.069518
train epoch: 4 - step: 430 (total: 980) - loss: 0.058166
train epoch: 4 - step: 440 (total: 980) - loss: 0.057281
train epoch: 4 - step: 450 (total: 980) - loss: 0.061132
dev step: 450 - loss: 0.10970, precision: 0.69868, recall: 0.75863, f1: 0.72742 current best 0.71239
==============================================save best model best performerence 0.727425
train epoch: 4 - step: 460 (total: 980) - loss: 0.053452
train epoch: 4 - step: 470 (total: 980) - loss: 0.085018
train epoch: 4 - step: 480 (total: 980) - loss: 0.058738
train epoch: 5 - step: 490 (total: 980) - loss: 0.046779
train epoch: 5 - step: 500 (total: 980) - loss: 0.052573
dev step: 500 - loss: 0.10714, precision: 0.66933, recall: 0.78793, f1: 0.72381 current best 0.72742
train epoch: 5 - step: 510 (total: 980) - loss: 0.039088
train epoch: 5 - step: 520 (total: 980) - loss: 0.051646
train epoch: 5 - step: 530 (total: 980) - loss: 0.038002
train epoch: 5 - step: 540 (total: 980) - loss: 0.051828
train epoch: 5 - step: 550 (total: 980) - loss: 0.049376
dev step: 550 - loss: 0.11403, precision: 0.67100, recall: 0.80956, f1: 0.73380 current best 0.72742
==============================================save best model best performerence 0.733797
train epoch: 5 - step: 560 (total: 980) - loss: 0.052402
train epoch: 5 - step: 570 (total: 980) - loss: 0.037455
train epoch: 5 - step: 580 (total: 980) - loss: 0.077029
train epoch: 6 - step: 590 (total: 980) - loss: 0.039981
train epoch: 6 - step: 600 (total: 980) - loss: 0.042132
dev step: 600 - loss: 0.12158, precision: 0.67457, recall: 0.81409, f1: 0.73779 current best 0.73380
==============================================save best model best performerence 0.737790
train epoch: 6 - step: 610 (total: 980) - loss: 0.040944
train epoch: 6 - step: 620 (total: 980) - loss: 0.055585
train epoch: 6 - step: 630 (total: 980) - loss: 0.060767
train epoch: 6 - step: 640 (total: 980) - loss: 0.062463
train epoch: 6 - step: 650 (total: 980) - loss: 0.036442
dev step: 650 - loss: 0.13412, precision: 0.66610, recall: 0.82176, f1: 0.73579 current best 0.73779
train epoch: 6 - step: 660 (total: 980) - loss: 0.067182
train epoch: 6 - step: 670 (total: 980) - loss: 0.034973
train epoch: 6 - step: 680 (total: 980) - loss: 0.045866
train epoch: 7 - step: 690 (total: 980) - loss: 0.032834
train epoch: 7 - step: 700 (total: 980) - loss: 0.032531
dev step: 700 - loss: 0.13344, precision: 0.70154, recall: 0.79281, f1: 0.74439 current best 0.73779
==============================================save best model best performerence 0.744392
train epoch: 7 - step: 710 (total: 980) - loss: 0.034761
train epoch: 7 - step: 720 (total: 980) - loss: 0.025256
train epoch: 7 - step: 730 (total: 980) - loss: 0.022619
train epoch: 7 - step: 740 (total: 980) - loss: 0.040854
train epoch: 7 - step: 750 (total: 980) - loss: 0.028917
dev step: 750 - loss: 0.13565, precision: 0.68950, recall: 0.79700, f1: 0.73936 current best 0.74439
train epoch: 7 - step: 760 (total: 980) - loss: 0.035568
train epoch: 7 - step: 770 (total: 980) - loss: 0.030468
train epoch: 7 - step: 780 (total: 980) - loss: 0.029734
train epoch: 8 - step: 790 (total: 980) - loss: 0.019671
train epoch: 8 - step: 800 (total: 980) - loss: 0.045290
dev step: 800 - loss: 0.14691, precision: 0.69611, recall: 0.80537, f1: 0.74677 current best 0.74439
==============================================save best model best performerence 0.746766
train epoch: 8 - step: 810 (total: 980) - loss: 0.027495
train epoch: 8 - step: 820 (total: 980) - loss: 0.029826
train epoch: 8 - step: 830 (total: 980) - loss: 0.023013
train epoch: 8 - step: 840 (total: 980) - loss: 0.030383
train epoch: 8 - step: 850 (total: 980) - loss: 0.025487
dev step: 850 - loss: 0.14448, precision: 0.69720, recall: 0.80712, f1: 0.74814 current best 0.74677
==============================================save best model best performerence 0.748141
train epoch: 8 - step: 860 (total: 980) - loss: 0.037146
train epoch: 8 - step: 870 (total: 980) - loss: 0.042024
train epoch: 8 - step: 880 (total: 980) - loss: 0.038850
train epoch: 9 - step: 890 (total: 980) - loss: 0.027396
train epoch: 9 - step: 900 (total: 980) - loss: 0.035380
dev step: 900 - loss: 0.14516, precision: 0.68703, recall: 0.80398, f1: 0.74092 current best 0.74814
train epoch: 9 - step: 910 (total: 980) - loss: 0.023594
train epoch: 9 - step: 920 (total: 980) - loss: 0.014255
train epoch: 9 - step: 930 (total: 980) - loss: 0.025010
train epoch: 9 - step: 940 (total: 980) - loss: 0.032078
train epoch: 9 - step: 950 (total: 980) - loss: 0.035759
dev step: 950 - loss: 0.14889, precision: 0.66771, recall: 0.82142, f1: 0.73663 current best 0.74814
train epoch: 9 - step: 960 (total: 980) - loss: 0.017284
train epoch: 9 - step: 970 (total: 980) - loss: 0.022624
INFO 2021-06-28 17:26:05,365 launch.py:240] Local processes completed.
end ccks role train
# 测试集事件主体元素预测
!bash run_event_element_extraction.sh role_predict
check and create directory
dir ./ckpt exist
dir ./ckpt/ccks exist
dir ./submit exist
start ccks role predict
/opt/conda/envs/python35-paddle120-env/lib/python3.7/site-packages/paddle/fluid/layers/utils.py:26: DeprecationWarning: `np.int` is a deprecated alias for the builtin `int`. To silence this warning, use `int` by itself. Doing this will not modify any behavior and is safe. When replacing `np.int`, you may wish to use e.g. `np.int64` or `np.int32` to specify the precision. If you wish to review your current use, check the release note link for additional information.
Deprecated in NumPy 1.20; for more details and guidance: https://numpy.org/devdocs/release/1.20.0-notes.html#deprecations
def convert_to_list(value, n, name, dtype=np.int):
[32m[2021-06-28 17:26:24,707] [ INFO][0m - Found /home/aistudio/.paddlenlp/models/ernie-1.0/vocab.txt[0m
[32m[2021-06-28 17:26:24,720] [ INFO][0m - Already cached /home/aistudio/.paddlenlp/models/ernie-1.0/ernie_v1_chn_base.pdparams[0m
W0628 17:26:24.721520 1166 device_context.cc:362] Please NOTE: device: 0, GPU Compute Capability: 7.0, Driver API Version: 10.1, Runtime API Version: 10.1
W0628 17:26:24.725553 1166 device_context.cc:372] device: 0, cuDNN Version: 7.6.
============start predict==========
Loaded parameters from ./ckpt/ccks/role/best.pdparams
save data 5483 to ./ckpt/ccks/role/test_pred.json
[0mend ccks role predict
# 将预测结果处理成比赛指定格式
格式
!bash run_event_element_extraction.sh get_submit
check and create directory
dir ./ckpt exist
dir ./ckpt/ccks exist
dir ./submit exist
start ccks predict data merge to submit fotmat
============start submitted data process==========
============cleaning step is completed==========
============the submitted data has been generated: ./submit/result.txt==========
end ccks role predict data merge
↑运行部分脚本已经结束,↓为项目报告(选看)
项目背景
项目说明
- 本实践项目依托于**CCKS 2021:面向金融领域的篇章级事件抽取和事件因果关系抽取(一)篇章级事件元素抽取**任务
- 代码方案参考2021语言与智能技术竞赛:多形态信息抽取任务的官方基线
- 本实践项目在线部署在AI Studio平台,支持免费使用Tesla V100 32G,支持在线训练预测、运行复现结果
任务描述
事件抽取是舆情监控和金融领域的重要任务之一。“金融事件”在金融领域是投资分析,资产管理的重要决策参考;事件也是知识图谱的重要组成部分,事件抽取是进行图谱推理、事件分析的必要过程。“事件抽取”的挑战体现在文本的复杂和任务的复杂。文本的复杂体现在事件抽取的输入文本可能是句子、段落或者篇章,不定长度的文本使得限制文本长度的模型无法使用;任务的复杂体现在事件识别的任务包括:事件类型识别,事件要素抽取,事件关系抽取等等。本评测任务的目标是解决篇章级事件元素抽取这个核心的知识抽取问题。
本次评测任务的文本语料来自于互联上的公开新闻、报告。在篇章级事件元素抽取任务中,给定篇章级长文本和事件类型,从篇章级文本中识别事件的元素。
事件用事件类型和事件要素来表示,该任务旨在从给定的长文本中抽取事件的13个要素,即给定文本T抽取T中的13个事件要素。同时,该任务提供文本所属的事件类型作为输入,选手可参考使用。每个事件要素的定义和描述如下表所示:

**输入:**一段文本T和额外的三级事件类型level1,level2,level3
**输出:**表格中描述的事件要素
示例:
样例
输入:{“text_id”:”123456”, “text”:“王某新认识一个网友小刘,聊了一会之后了解了一下情况就很自来熟一样,过了几天小刘说肚子疼上医院要软件打五百块钱给她,没过多久脚又被行李箱砸伤又问王某要了八百,之后联系不上”,”level1”:” 欺诈风险”,”level2”:” 冒充身份类”,”level3”:” 好友/领导/婚恋交友”}
输出:{“text_id”:”123456”, “attribute”:[{“type”:”支付渠道”,”entity”:”软件”, “start”:47,”end”:48},{“type”:”资损金额”,”entity”:”五百块钱”, “start”:50,”end”:53},{“type”:”资损金额”,”entity”:”八百”, “start”:75,”end”:76},{“type”:”嫌疑人”,”entity”:”小刘”, “start”:9,”end”:10},{“type”:”受害人”,”entity”:”王某”, “start”:0,”end”:1}]}
数据说明
本次数据主要来自金融领域的公开新闻、报道,样本包含正样本和负样本,训练集、验证集的说明如下:
- 训练集:5000条文本及其所标注的三个事件类型以及每个文本标注的事件要素
- 验证集:1000条验证文本及其所标注的三个事件类型
训练集以json格式,包含“text”、“level1”、“level2”、“level3”分别表示文本和三个事件类型,包含“attributes”表示训练集中事件的要素,注意同一个要素可能有多个取值,需要都识别出来。验证集以json格式,“text”、“level1”、“level2”、“level3”分别表示文本和三个事件类型。
- 数据集已放在项目代码data路径下
- 备用下载地址为https://www.biendata.xyz/media/download_file/8e35ed1cd505bac1999745fd29b6022f.zip
说明:以上数据来源于互联网公开信息样本,仅用于本次比赛交流目的,不具有统计意义
评价指标
本次任务采用精确率(Precision, P)、召回率(Recall, R)、F1值(F1-measure, F1)来评估篇章事件要素的识别效果。采用微平均计算F值即所有样本一起计算P和R。

项目思路
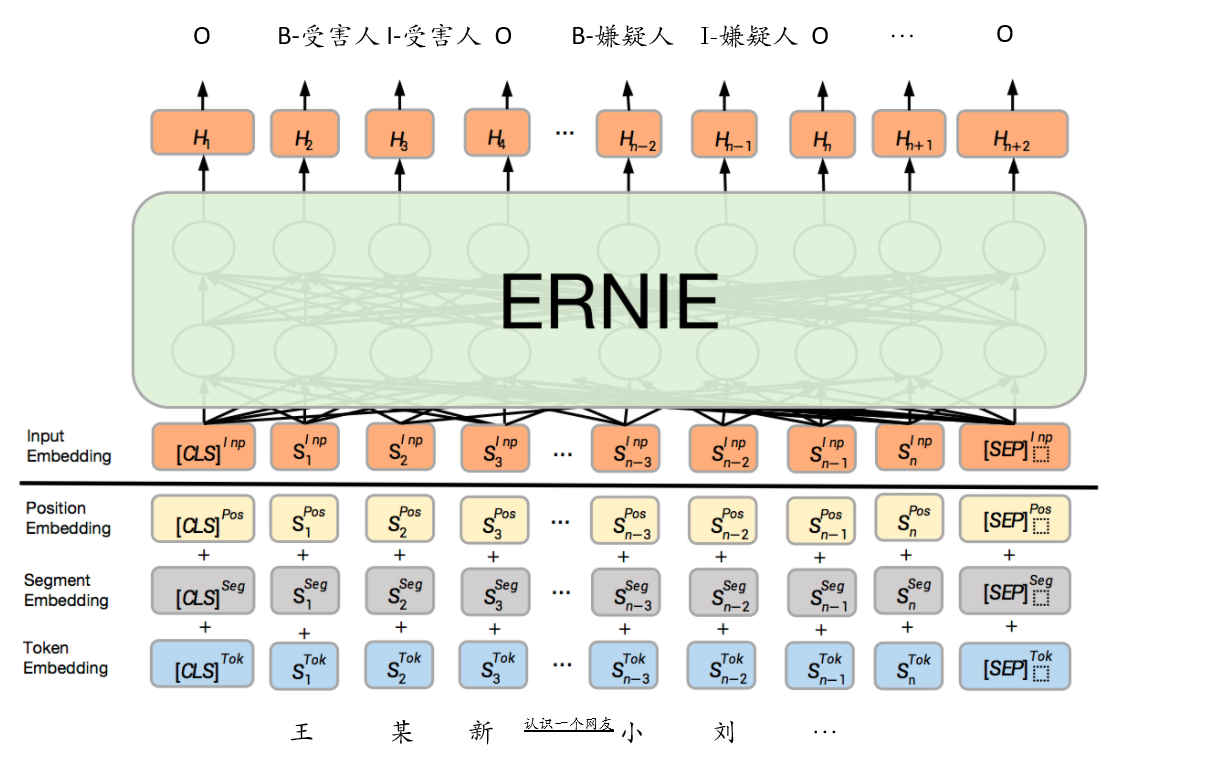
篇章级事件元素抽取任务需要从文本中抽取到命名实体以及对应的类型,因此采用了序列标注方案,首先对数据集进行BIO标注处理,然后使用基于基于ERNIE的序列标注方案进行事件元素及其对应类型的识别。
模型结构
数据前处理
因参考使用LIC2021的paddle框架baseline进行BIO标注,故将ccks2021数据集格式处理成LIC2021 DuEE-Fin的格式
格式对比
- LIC2021训练集格式如下
{"text": "原标题:万讯自控(7.490,-0.10,-1.32%):傅宇晨解除部分股份质押、累计质押比例为39.55% 来源:每日经济新闻\n每经AI快讯,万讯自控(SZ 300112,收盘价:7.49元)6月3日下午发布公告称,公司接到股东傅宇晨的通知,获悉傅宇晨将其部分股份办理了质押业务。截至本公告日,傅宇晨共持有公司股份5790.38万股,占公司总股本的20.25%;累计质押股份2290万股,占傅宇晨持有公司股份总数的39.55%,占公司总股本的8.01%。\n2019年年报显示,万讯自控的主营业务为工业自动控制行业,占营收比例为:99.05%。\n万讯自控的董事长是傅宇晨,男,57岁,中国籍,无境外永久居留权,工学学士,高级工商管理硕士,自动化仪表工程师。 万讯自控的总经理是傅晓阳,男,49岁,中国籍,无境外永久居留权,工学学士。\n(记者 曾剑)", "event_list": [{"trigger": "质押", "event_type": "质押", "arguments": [{"role": "披露时间", "argument": "6月3日下午"}, {"role": "质押方", "argument": "傅宇晨"}, {"role": "质押物所属公司", "argument": "万讯自控"}, {"role": "质押物", "argument": "股份"}, {"role": "质押股票/股份数量", "argument": "2290万"}, {"role": "质押物占持股比", "argument": "39.55%"}, {"role": "质押物占总股比", "argument": "8.01%"}, {"role": "事件时间", "argument": "截至本公告日"}]}], "id": "b2b3d9dc2eb40c41036a1ab12f58de8c", "title": "万讯自控:傅宇晨解除部分股份质押、累计质押比例为39.55%"}
- CCKS2021训练集格式如下
{"text_id": "3906853", "text": "加微信带你炒股? 声称可以赚大钱? 什么感觉??? 是不是以为天上掉馅饼 砸到了你自己 股票诈骗 经常会出现在我们身边,相信不少炒股的投资者,都多多少少遇到过,诈骗说法那是相当的诱人,不惜先让你尝到甜头,好为后面骗大笔资金做铺垫. 典 型 案 例 6月22日,宿城的张女士到派出所报案,称其被一位昵称“紫凡”的微信好友拉进了一个名为“笑傲江湖”的炒股群,并被引导至某平台炒股.几次试探性炒股赚到钱后,张女士对“紫凡”深信不疑,“紫凡”隔三差五的就给张女士发送一些炒股相关的信息,私下频繁交流加上群聊成员鼓吹,张女士不断在平台内加注资金,结果最后账户内246251.34元基本赔光,发现情况不对劲的张女士立即向警方报案. 来源 : 宿城公安", "level1": "欺诈风险", "level2": "违规违禁类", "level3": "投资理财/高额返利", "attributes": [{"start": 130, "type": "案发城市", "end": 131, "entity": "宿城"}, {"start": 133, "type": "受害人", "end": 135, "entity": "张女士"}, {"start": 205, "type": "嫌疑人", "end": 206, "entity": "紫凡"}, {"start": 275, "type": "资损金额", "end": 284, "entity": "246251.34元"}]}
处理思路
import json
import pandas as pd
import numpy as py
# 按标点切句子,只是为了对齐lic2021中的title,思路是将text中的第一句话作为title
def cut_sentences(content):
# 结束符号,包含中文和英文的
end_flag = ['。', ';', ';','?','.','?','.']
content_len = len(content)
sentences = ''
tmp_char = ''
for idx, char in enumerate(content):
# 拼接字符
tmp_char += char
# 判断是否已经到了最后一位
if (idx + 1) == content_len:
sentences += (tmp_char)
break
# 判断此字符是否为结束符号
if char in end_flag:
# 再判断下一个字符是否为结束符号,如果不是结束符号,则切分句子
next_idx = idx + 1
if not content[next_idx] in end_flag:
sentences += tmp_char + '\n'
tmp_char = ''
return sentences
# ccks2021额外提供了三个level1,这里简单的让level1填充lic2021中的trigger槽位,level2填充event_type,只是为了保证lic2021的data_prepare代码正常运行,后续也没用用到trigger和event_type。重心在于属性中的论元角色列表,对应了ccks2021篇章级事件主体的类型和实体名
def ccks2lic(s):
t = {'text': '',
'event_list': [{'trigger': '',
'event_type': '',
'arguments': []}],
'id': '',
'title': ''}
t['id'] = s['text_id']
t['text'] = cut_sentences(s['text'])
t['title'] = cut_sentences(s['text']).split('\n')[0]
t['event_list'][0]['trigger'] = s['level1']
t['event_list'][0]['event_type'] = s['level2']
for i in s['attributes']:
t['event_list'][0]['arguments'].append({'role': i['type'], 'argument': i['entity']})
return t
with open('data/ccks_task1_train.txt', 'r', encoding='utf-8') as f:
ccks_train = f.readlines()
path = 'data/train.json'
with open(path, 'w',encoding='utf-8') as f:
for i,data in enumerate(ccks_train):
new_data = ccks2lic(eval(data))
json.dump(new_data,f,ensure_ascii=False)
f.write('\n')
ccks2021–>lic2021 DuEE-fin格式后
{"text": "加微信带你炒股?\n 声称可以赚大钱?\n 什么感觉???\n 是不是以为天上掉馅饼 砸到了你自己 股票诈骗 经常会出现在我们身边,相信不少炒股的投资者,都多多少少遇到过,诈骗说法那是相当的诱人,不惜先让你尝到甜头,好为后面骗大笔资金做铺垫.\n 典 型 案 例 6月22日,宿城的张女士到派出所报案,称其被一位昵称“紫凡”的微信好友拉进了一个名为“笑傲江湖”的炒股群,并被引导至某平台炒股.\n几次试探性炒股赚到钱后,张女士对“紫凡”深信不疑,“紫凡”隔三差五的就给张女士发送一些炒股相关的信息,私下频繁交流加上群聊成员鼓吹,张女士不断在平台内加注资金,结果最后账户内246251.\n34元基本赔光,发现情况不对劲的张女士立即向警方报案.\n 来源 : 宿城公安", "event_list": [{"trigger": "欺诈风险", "event_type": "违规违禁类", "arguments": [{"role": "案发城市", "argument": "宿城"}, {"role": "受害人", "argument": "张女士"}, {"role": "嫌疑人", "argument": "紫凡"}, {"role": "资损金额", "argument": "246251.34元"}]}], "id": "3906853", "title": "加微信带你炒股?"}
测试数据集的处理类似,核心是text
def test_ccks2lic(s):
t = {'text':'','id':'','title':''}
text = cut_sentences(s['text'])
t['text'] = text
t['id'] = s['text_id']
t['title'] = text.split('\n')[0]
return t
BIO标注
def label_data(data, start, l, _type):
"""label_data"""
for i in range(start, start + l):
suffix = "B-" if i == start else "I-"
data[i] = "{}{}".format(suffix, _type)
return data
for event in d_json.get("event_list", []):
labels = ["O"] * len(text_a)
for arg in event["arguments"]:
role_type = arg["role"]
if role_type == enum_role:
continue
argument = arg["argument"]
start = arg["argument_start_index"]
labels = label_data(labels, start,
len(argument), role_type)
output.append("{}\t{}".format('\002'.join(text_a),
'\002'.join(labels)))
模型训练
STEP 1
-
将原始数据处理成模型可以读入的格式。首先使用tokenizer切词并映射词表中input ids,转化token type ids等。
-
使用paddle.io.DataLoader接口多进程异步加载数据。
-
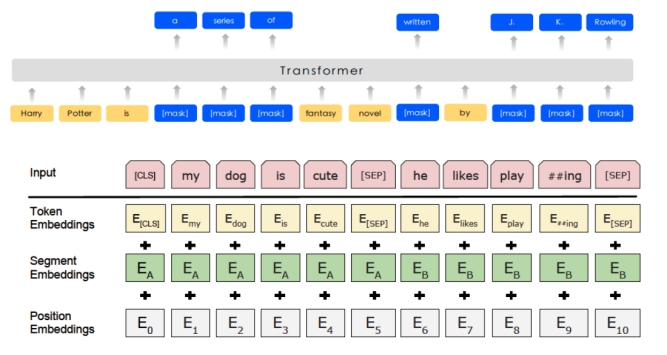
ErnieTokenizer介绍
- input_ids: 表示输入文本的token ID。
- token_type_ids: 表示对应的token属于输入的第一个句子还是第二个句子。(Transformer类预训练模型支持单句以及句对输入。)详细参见左侧 sequence_labeling.py convert_example_to_feature()函数解释。
- seq_len: 表示输入句子的token个数。
- input_mask:表示对应的token是否一个padding token。由于一个batch中的输入句子长度不同,所以需要将不同长度的句子padding到统一固定长度。1表示真实输入,0表示对应token为padding token。
- position_ids: 表示对应token在整个输入序列中的位置。
同时,ERNIE模型输出有2个tensor。
- sequence_output是对应每个输入token的语义特征表示,shape为(1, num_tokens, hidden_size)。其一般用于序列标注、问答等任务。
- pooled_output是对应整个句子的语义特征表示,shape为(1, hidden_size)。其一般用于文本分类、信息检索等任务。
from functools import partial
from paddlenlp.data import Stack, Tuple, Pad
def convert_example_to_feature(example, tokenizer, label_vocab=None, max_seq_len=512, no_entity_label="O", ignore_label=-1, is_test=False):
tokens, labels = example
tokenized_input = tokenizer(
tokens,
return_length=True,
is_split_into_words=True,
max_seq_len=max_seq_len)
input_ids = tokenized_input['input_ids']
token_type_ids = tokenized_input['token_type_ids']
seq_len = tokenized_input['seq_len']
if is_test:
return input_ids, token_type_ids, seq_len
elif label_vocab is not None:
labels = labels[:(max_seq_len-2)]
encoded_label = [no_entity_label] + labels + [no_entity_label]
encoded_label = [label_vocab[x] for x in encoded_label]
return input_ids, token_type_ids, seq_len, encoded_label
no_entity_label = "O"
# padding label value
ignore_label = -1
batch_size = 4
max_seq_len = 300
trans_func = partial(
convert_example_to_feature,
tokenizer=tokenizer,
label_vocab=train_ds.label_vocab,
max_seq_len=max_seq_len,
no_entity_label=no_entity_label,
ignore_label=ignore_label,
is_test=False)
batchify_fn = lambda samples, fn=Tuple(
Pad(axis=0, pad_val=tokenizer.vocab[tokenizer.pad_token]), # input ids
Pad(axis=0, pad_val=tokenizer.vocab[tokenizer.pad_token]), # token type ids
Stack(), # sequence lens
Pad(axis=0, pad_val=ignore_label) # labels
): fn(list(map(trans_func, samples)))
train_loader = paddle.io.DataLoader(
dataset=train_ds,
batch_size=batch_size,
shuffle=True,
collate_fn=batchify_fn)
dev_loader = paddle.io.DataLoader(
dataset=dev_ds,
batch_size=batch_size,
collate_fn=batchify_fn)
STEP 2
选择交叉墒作为损失函数,使用paddle.optimizer.AdamW作为优化器
@paddle.no_grad()
def evaluate(model, criterion, metric, num_label, data_loader):
"""evaluate"""
model.eval()
metric.reset()
losses = []
for input_ids, seg_ids, seq_lens, labels in data_loader:
logits = model(input_ids, seg_ids)
loss = paddle.mean(criterion(logits.reshape([-1, num_label]), labels.reshape([-1])))
losses.append(loss.numpy())
preds = paddle.argmax(logits, axis=-1)
n_infer, n_label, n_correct = metric.compute(seq_lens, preds, labels)
metric.update(n_infer.numpy(), n_label.numpy(), n_correct.numpy())
precision, recall, f1_score = metric.accumulate()
avg_loss = np.mean(losses)
model.train()
return precision, recall, f1_score, avg_loss
STEP 3
使用预训练模型ERNIE进行训练,并保存最优分数的模型
num_training_steps = len(train_loader) * args.num_epoch
# Generate parameter names needed to perform weight decay.
# All bias and LayerNorm parameters are excluded.
decay_params = [
p.name for n, p in model.named_parameters()
if not any(nd in n for nd in ["bias", "norm"])
]
optimizer = paddle.optimizer.AdamW(
learning_rate=args.learning_rate,
parameters=model.parameters(),
weight_decay=args.weight_decay,
apply_decay_param_fun=lambda x: x in decay_params)
metric = ChunkEvaluator(label_list=train_ds.label_vocab.keys(), suffix=False)
criterion = paddle.nn.loss.CrossEntropyLoss(ignore_index=ignore_label)
step, best_f1 = 0, 0.0
model.train()
for epoch in range(args.num_epoch):
for idx, (input_ids, token_type_ids, seq_lens, labels) in enumerate(train_loader):
logits = model(input_ids, token_type_ids).reshape(
[-1, train_ds.label_num])
loss = paddle.mean(criterion(logits, labels.reshape([-1])))
loss.backward()
optimizer.step()
optimizer.clear_grad()
loss_item = loss.numpy().item()
if step > 0 and step % args.skip_step == 0 and rank == 0:
print(f'train epoch: {epoch} - step: {step} (total: {num_training_steps}) - loss: {loss_item:.6f}')
if step > 0 and step % args.valid_step == 0 and rank == 0:
p, r, f1, avg_loss = evaluate(model, criterion, metric, len(label_map), dev_loader)
print(f'dev step: {step} - loss: {avg_loss:.5f}, precision: {p:.5f}, recall: {r:.5f}, ' \
f'f1: {f1:.5f} current best {best_f1:.5f}')
if f1 > best_f1:
best_f1 = f1
print(f'==============================================save best model ' \
f'best performerence {best_f1:5f}')
paddle.save(model.state_dict(), '{}/best.pdparams'.format(args.checkpoints))
step += 1
# save the final model
if rank == 0:
paddle.save(model.state_dict(), '{}/final.pdparams'.format(args.checkpoints))
STEP 4
对测试集数据进行标签的预测
def do_predict():
paddle.set_device(args.device)
no_entity_label = "O"
ignore_label = -1
tokenizer = ErnieTokenizer.from_pretrained("ernie-1.0")
label_map = load_dict(args.tag_path)
id2label = {val: key for key, val in label_map.items()}
model = ErnieForTokenClassification.from_pretrained("ernie-1.0", num_classes=len(label_map))
print("============start predict==========")
if not args.init_ckpt or not os.path.isfile(args.init_ckpt):
raise Exception("init checkpoints {} not exist".format(args.init_ckpt))
else:
state_dict = paddle.load(args.init_ckpt)
model.set_dict(state_dict)
print("Loaded parameters from %s" % args.init_ckpt)
# load data from predict file
sentences = read_by_lines(args.predict_data) # origin data format
sentences = [json.loads(sent) for sent in sentences]
encoded_inputs_list = []
for sent in sentences:
sent = sent["text"].replace(" ", "\002")
input_ids, token_type_ids, seq_len = convert_example_to_feature([list(sent), []], tokenizer,
max_seq_len=args.max_seq_len, is_test=True)
encoded_inputs_list.append((input_ids, token_type_ids, seq_len))
batchify_fn = lambda samples, fn=Tuple(
Pad(axis=0, pad_val=tokenizer.vocab[tokenizer.pad_token]), # input_ids
Pad(axis=0, pad_val=tokenizer.vocab[tokenizer.pad_token]), # token_type_ids
Stack() # sequence lens
): fn(samples)
# Seperates data into some batches.
batch_encoded_inputs = [encoded_inputs_list[i: i + args.batch_size]
for i in range(0, len(encoded_inputs_list), args.batch_size)]
results = []
model.eval()
for batch in batch_encoded_inputs:
input_ids, token_type_ids, seq_lens = batchify_fn(batch)
input_ids = paddle.to_tensor(input_ids)
token_type_ids = paddle.to_tensor(token_type_ids)
logits = model(input_ids, token_type_ids)
probs = F.softmax(logits, axis=-1)
probs_ids = paddle.argmax(probs, -1).numpy()
probs = probs.numpy()
for p_list, p_ids, seq_len in zip(probs.tolist(), probs_ids.tolist(), seq_lens.tolist()):
prob_one = [p_list[index][pid] for index, pid in enumerate(p_ids[1: seq_len - 1])]
label_one = [id2label[pid] for pid in p_ids[1: seq_len - 1]]
results.append({"probs": prob_one, "labels": label_one})
assert len(results) == len(sentences)
for sent, ret in zip(sentences, results):
sent["pred"] = ret
sentences = [json.dumps(sent, ensure_ascii=False) for sent in sentences]
write_by_lines(args.predict_save_path, sentences)
print("save data {} to {}".format(len(sentences), args.predict_save_path))
数据后处理
格式对比
- 模型预测的结果格式如下
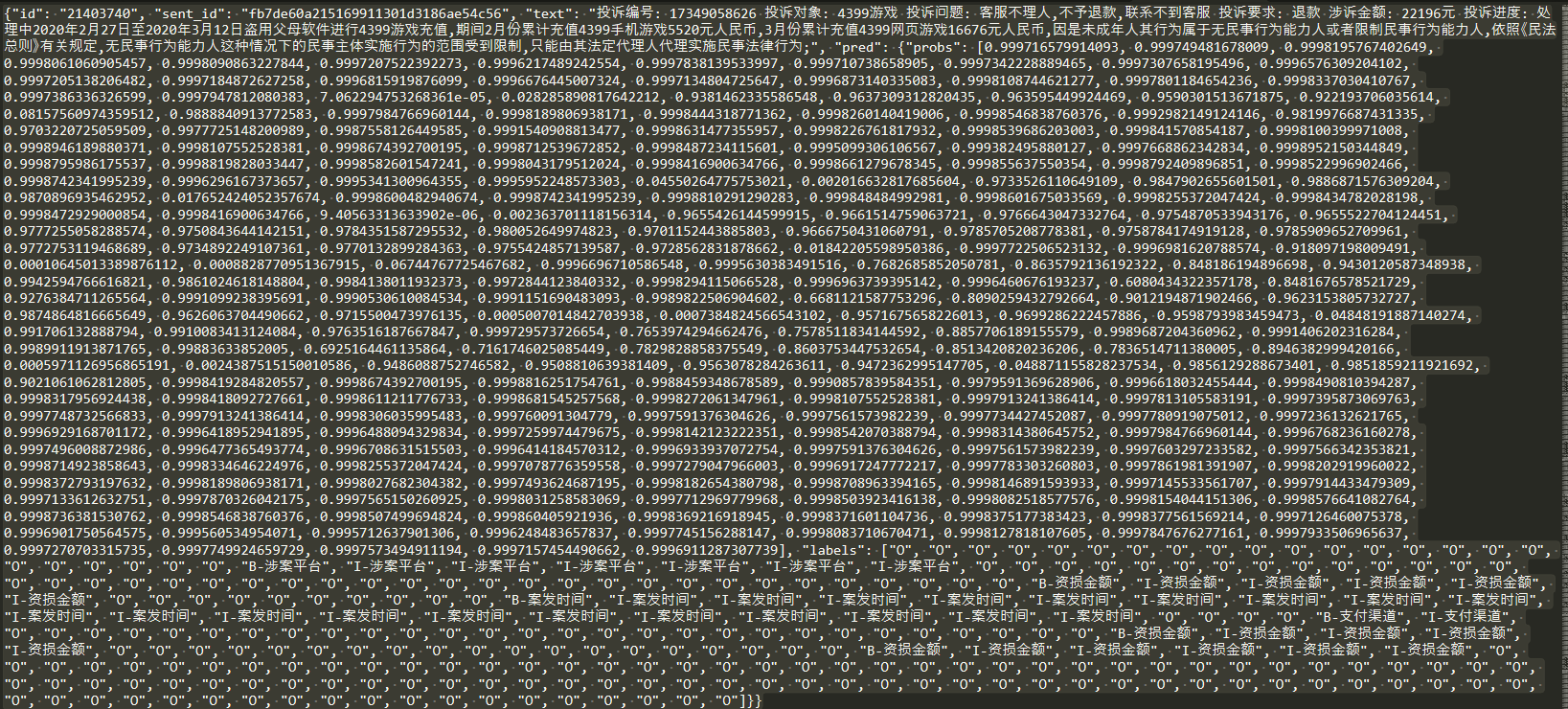
- ccks2021要求的提交结果格式如下

处理思路
import json
import pandas as pd
import numpy as np
# 读取经过基于ERNIE预训练模型序列标注任务得到的预测结果json文件
with open('test_pred.json',encoding='utf-8') as f:
c = f.readlines()
# 保留事件文本内容和对应BIO标签,从text中拿entity,start,end,从labels中拿type
t = pd.DataFrame(columns=['text_id','text','labels'])
for data in c:
a = eval(data)
labels = ''
tmp = a['pred']['labels']
for i,l in enumerate(tmp):
if i<len(tmp)-1:
labels = labels + l + '\t'
else:
labels = labels + l
t.loc[len(t)] = {'text_id':a['id'],'text':a['text'],'labels':labels}
t.to_csv('test_row.csv',index=None)
初步清洗效果展示:

在篇章级事件元素抽取时,由于使用预训练模型的长度限制,对文章进行了截断处理,因此1000条数据被拆成了5483条。第二步需要将同text_id的内容进行合并,而且需要注意text和labels字符的位置对应关系。
def merge(x):
x.reset_index(inplace=True)
num = len(x)
if num > 1:
text,labels = '',''
for i in range(1,num):
text += x['text'][i]
if i <= num-2:
labels = labels + x['labels'][i] + '\t'
else:
labels += x['labels'][i]
else:
text, labels = x['text'][0], x['labels'][0]
return pd.DataFrame({'text':[text],'labels':[labels]})
q = pd.read_csv('test_row.csv')
res = q.groupby('text_id').apply(merge)
res.reset_index(inplace=True)
# 在使用groupby和apply函数进行归并时,多出一个'level_1'的列,这里简单进行了删除操作
res.drop(['level_1'], axis=1,inplace=True)
res.to_csv('test_handle.csv',index=None)
第二步处理后效果展示:
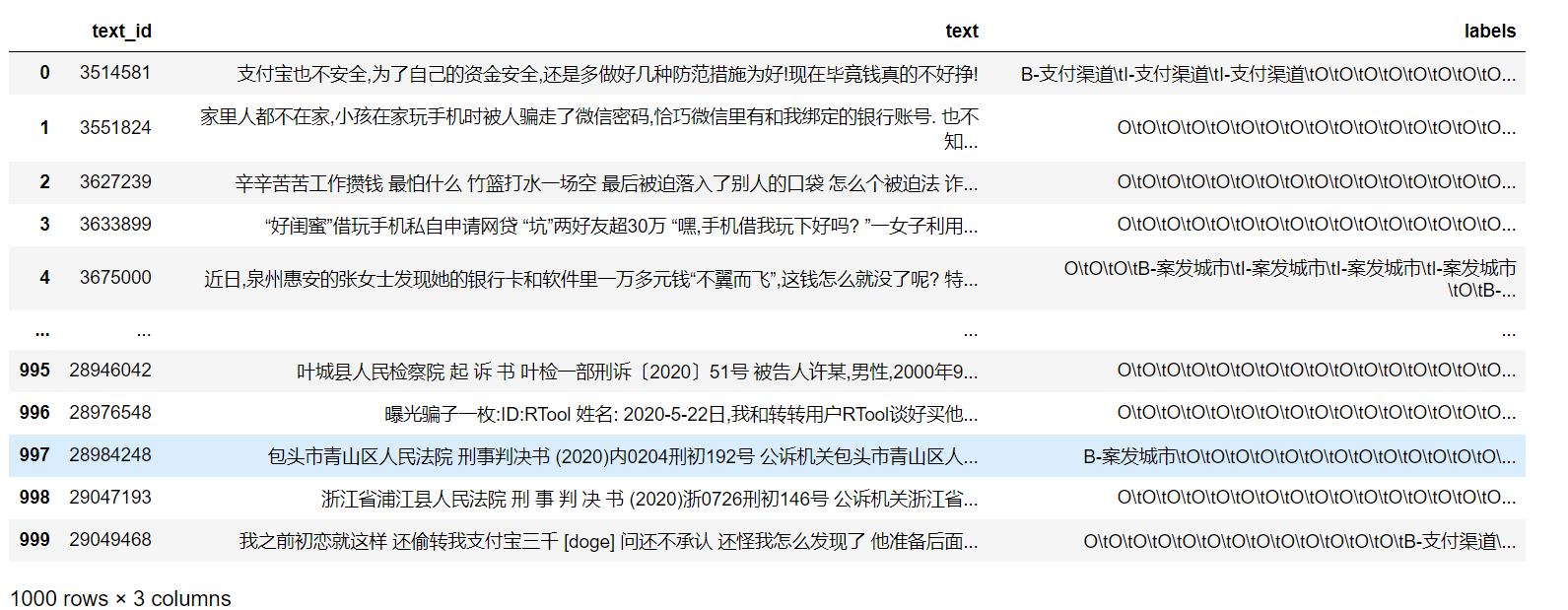
可以在labels的BIO标注中直接拿到type,根据非O的标签索引在text中可以拿到entity以及start和end。这里的处理思路是将每个预测结果的text和labels逐字符拆开,使用pandas快速拿到非O字符,然后根据非O字符的索引连贯性划分出相应实体索引范围。

index列是包含O字符的位置索引,re_index就是简单的从零往后排序,index-re_index如果值相同,意味着是连续的有效实体中的字符。因为无论中间截断了多少O字符,只要非O字符是连续的,他们同自己的递增索引作差都是相同的。根据这个思路去划分实体会出现问题,如果两个实体的索引是连续的,会直接被划分为一个无效的重叠实体,应该进一步结合BI的分布特点进行判定,这也是我的初版预测结果分数很低的原因之一。
根据diff_index进行merge后结果展示:

代码如下:
df = pd.read_csv('test_handle.csv')
# 适配groupby apply的函数,此时传入函数的x还是逐字符形式,将entity进行拼接,同时start就是第一个index,end是最后的index
def final_process(x):
len_ = len(x)
entity = ''
type_ = x['type'].iloc[0]
start = x['index'].iloc[0]
end = x['index'].iloc[-1]
for i in range(len_):
entity += x['word_x'].iloc[i]
return pd.DataFrame({'type':[type_],'entity':[entity],'start':[start],'end':[end]})
# 这里是对1000条数据中的一条进行的处理,每一条都转成DataFrame进行操作
def gain_post_json(text_id, text, labels):
text_tmp = pd.DataFrame({'index':range(len(text)),'word':list(text)})
labels_tmp = pd.DataFrame({'index':range(len(labels)),'word':list(labels)})
res_tmp = pd.merge(text_tmp,labels_tmp,on='index')
res_tmp2 = res_tmp.loc[res_tmp['word_y'] != 'O']
res_tmp2['type'] = res_tmp2['word_y'].apply(lambda x:x.split('-')[1]) # B-嫌疑人 切开后取后者
res_tmp2['re_index'] = range(len(res_tmp2))
res_tmp2['diff_index'] = res_tmp2['index'] - res_tmp2['re_index']
res_tmp3 = res_tmp2.groupby('diff_index').apply(final_process)
res_tmp4 = res_tmp3.reset_index()
post_json = {
'text_id': str(text_id),
'attributes': []
}
for i in range(len(res_tmp4)):
post_json['attributes'].append({'type':res_tmp4['type'][i],'entity':res_tmp4['entity'][i],'start':int(res_tmp4['start'][i]),'end':int(res_tmp4['end'][i])}) # 在存json格式是报错不支持int64,因此在这些数字前加了int()转型
return post_json
with open('result.txt','w',encoding='utf-8') as f:
for i in range(len(df)):
post_json = gain_post_json(df['text_id'][i], df['text'][i],df['labels'][i].split('\t'))
json.dump(post_json, f , ensure_ascii=False) # ensure_ascii=False可以解决中文乱码
f.write('\n')
结果展示
- 对1000条验证数据进行预测,结果如下

↑项目报告结束,↓为运行说明
文章目录
项目链接
项目介绍
- 本项目在线部署在百度AI Studio平台,可以直接点击运行一下,一键Fork后使用在线高性能深度学习训练推理平台运行
- 建议使用百度AI Studio云端算力直接运行,若需在本地运行,请参考飞桨安装文档,
- 本项目选用飞桨(PaddlePaddle)框架,预训练模型选用ERNIE
- 建议点击项目链接fork项目后直接运行,最后的结果存放在submit/result.txt
环境说明
本项目直接在AI Studio平台运行即可,以下仅介绍平台提供机器的环境
-
Ubuntu 16.04.6 LTS
-
+-----------------------------------------------------------------------------+ | NVIDIA-SMI 418.67 Driver Version: 418.67 CUDA Version: 10.1 | |-------------------------------+----------------------+----------------------+ | GPU Name Persistence-M| Bus-Id Disp.A | Volatile Uncorr. ECC | | Fan Temp Perf Pwr:Usage/Cap| Memory-Usage | GPU-Util Compute M. | |===============================+======================+======================| | 0 Tesla V100-SXM2... On | 00000000:05:00.0 Off | 0 | | N/A 38C P0 39W / 300W | 0MiB / 32480MiB | 0% Default | +-------------------------------+----------------------+----------------------+ +-----------------------------------------------------------------------------+ | Processes: GPU Memory | | GPU PID Type Process name Usage | |=============================================================================| | No running processes found | +-----------------------------------------------------------------------------+ -
numpy==1.20.3 paddlepaddle_gpu==2.0.2.post101 paddlenlp==2.0.5 pandas==1.1.5 paddle==1.0.2
运行步骤
-

-
使用百度账号登录(可能需要填注册信息之类)
-
-
直接在Notebook界面按顺序重跑cell即可
-
# 安装paddlenlp最新版本 !pip install --upgrade paddlenlp # 数据格式处理对齐 !bash ./run_event_element_extraction.sh ccks2lic_data_prepare # 将原始数据预处理成序列标注格式数据 !bash ./run_event_element_extraction.sh data_prepare # 模型训练 !bash run_event_element_extraction.sh role_train # 测试集事件主体元素预测 !bash run_event_element_extraction.sh role_predict # 将预测结果处理成比赛指定格式 !bash run_event_element_extraction.sh get_submit -
============the submitted data has been generated: ./submit/result.txt==========
代码架构
├── ccks2lic.py
├── ckpt
│ └── ccks
│ └── role
│ ├── best.pdparams # 模型参数
│ ├── .ipynb_checkpoints
│ └── test_pred.json # 预测结果
├── conf
│ └── ccks
│ ├── enum_tag.dict
│ ├── event_schema.json # 事件元素对应的类型字典
│ ├── role_tag.dict
│ └── trigger_tag.dict
├── data
│ └── ccks
│ ├── dev.json
│ ├── enum
│ │ ├── dev.tsv
│ │ ├── test.tsv
│ │ └── train.tsv
│ ├── pre_submit
│ │ ├── test_handle.csv
│ │ └── test_row.csv
│ ├── raw
│ │ ├── ccks_task1_eval_data.txt # ccks2021原始测试语料数据
│ │ └── ccks_task1_train.txt # ccks2021原始训练语料数据
│ ├── role
│ │ ├── dev.tsv
│ │ ├── test.tsv
│ │ └── train.tsv
│ ├── sentence
│ │ ├── dev.json # 逐句切分后的数据集
│ │ ├── test.json
│ │ └── train.json
│ ├── test.json # ccks2021转成lic2021格式后的数据
│ ├── train.json
│ └── trigger
│ ├── dev.tsv
│ ├── test.tsv
│ └── train.tsv
├── data_prepare.py # BIO标注
├── log
│ ├── endpoints.log
│ └── workerlog.0
├── post_process.py # 处理成ccks2021比赛指定格式
├── __pycache__
│ └── utils.cpython-37.pyc
├── run_event_element_extraction.sh ###### 总控脚本 ######
├── run_sequence_labeling.sh # 序列标注训练和预测脚本
├── sequence_labeling.py # 模型代码
├── submit
│ └── result.txt ###### 最终的提交文件 ######
└── utils.py
框架介绍
飞桨(PaddlePaddle)以百度多年的深度学习技术研究和业务应用为基础,是中国首个自主研发、功能完备、 开源开放的产业级深度学习平台,集深度学习核心训练和推理框架、基础模型库、端到端开发套件和丰富的工具组件于一体。
模型介绍
ERNIE是百度开创性提出的基于知识增强的持续学习语义理解框架,该框架将大数据预训练与多源丰富知识相结合,通过持续学习技术,不断吸收海量文本数据中词汇、结构、语义等方面的知识,实现模型效果不断进化。ERNIE在累积 40 余个典型 NLP 任务取得 SOTA 效果,并在 GLUE、VCR、XTREME、SemEval 等国际权威评测上斩获十余项冠军。
百度构造的 ERNIE[1]在语言推断、语义相似度、命名实体识别、情感分析、问答匹配等多项中文 NLP 任务上表现出色,有些甚至优于 BERT 在处理同类中文任务的结果。ERNIE 模型本身保持基于字特征输入建模,使得模型在应用时不需要依赖其他信息,其通用性和可扩展性更强。相对词特征输入模型,字特征可建模字的组合语义,例如建模红色,绿色,蓝色等表示颜色的词语时,通过相同字的语义组合学到词之间的语义关系。
[1] Sun Y , Wang S , Li Y , et al. ERNIE 2.0: A Continual Pre-training Framework for Language Understanding[J]. 2019.

学大模型,用大模型上飞桨星河社区!每天8点V100G算力免费领!免费领取ERNIE 4.0 100w Token >>>
更多推荐


 0
0 0
0- 0



 已为社区贡献1438条内容
已为社区贡献1438条内容

所有评论(0)