
ConvNeXt:探索CNN网络的极限潜力
基于PaddlePaddle实现ConvNeXt,超越 Swin Transformer 的 CNN 架构,挖掘 CNN 的潜力,十分工程化的模型
🔥 PASSL 包含 SimCLR、MoCo v1/v2、BYOL、CLIP 等基于对比学习的图像自监督算法以及 Vision Transformer、Swin Transformer、BEiT、CvT、T2T-ViT、MLP-Mixer 等视觉 Transformer 及相关算法,欢迎 star ~ 🌟🌟🌟 https://github.com/PaddlePaddle/PASSL
CV 真可谓卷,卷中卷,这还没从 ViTs 大爆炸缓过来,这就又来了一篇文章,简单读了很有意思,探索 ConvNet 的极限

🔥 In this work, we reexamine the design spaces and test the limits of what a pure ConvNet can achieve.
⭐ We propose ConvNeXt, a pure ConvNet model constructed entirely from standard ConvNet modules. ConvNeXt is accurate, efficient, scalable and very simple in design. 🦾🦾🦾
📄 Paper: https://arxiv.org/pdf/2201.03545.pdf
⌨️ Code: https://github.com/facebookresearch/ConvNeXt
【老人字体特供版】👨🦳 🌈
Hi guy 我们又又又见面了,这次来搞一篇据说很好探索 CNN 潜力的文章,话不多说先看性能图
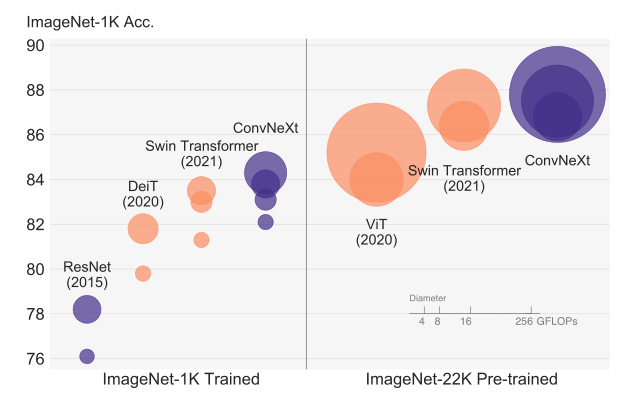
这图一看就明显,ConvNeXt 这篇工作,就是来对标 Swin Transformer,开头的 abstract 就评论了像 Swin 这样的模型
However,
the effectiveness of such hybrid approaches is still largely
credited to the intrinsic superiority of Transformers, rather
than the inherent inductive biases of convolutions
🤷♀️ 不愧是 Meta 硬气(不过笔者也觉得Swin确实太过于技巧化,当然 Swin 确实有自己的优秀之处,毕竟拿过 🏆)
PS:笔者觉得同时期的 ViT、DETR 从 novelty 来说都比Swin好。。。跑题了
回到正题,ConvNeXt是怎么蹦出来的?答:从ResNet逐渐演变
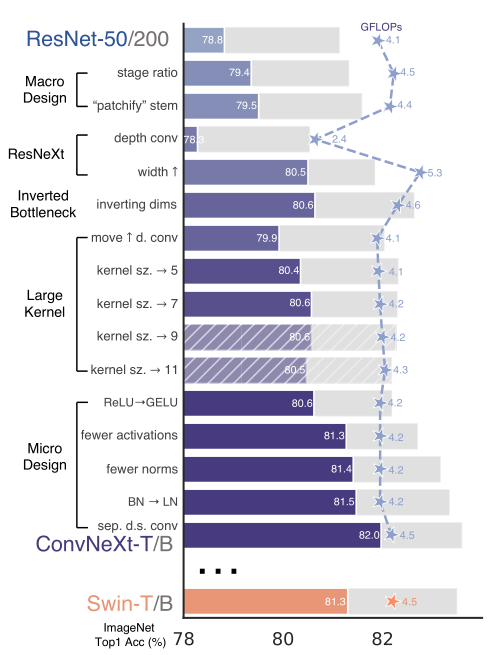
可以看出有很多的改进,我们来一个个简单分析一下 ResNet 怎么变身成为 ConvNeXt 的
原文细节比较多,同学具体可以看论文,这里简单说一些 solid 的改进
🎯 先进的训练设置
首先是训练,原文如下
In our study, we use a training recipe that is close to DeiT’s [68] and Swin Transformer’s [42]. The training is extended to 300 epochs from the original 90 epochs for ResNets. We use the AdamW optimizer [43], data augmentation techniques such as Mixup [85], Cutmix [84], RandAugment [12], Random Erasing [86], and regularization schemes including Stochastic Depth [33] and Label Smoothing [65].
什么意思,就是训练ResNet时候用现在ViT的那套训练方法来训练,包括不限于增加 300 epoch、AdamW、各种 Aug 等,这样的训练涨了大概2个多点
经常关注模型的同学应该想起来了,之前 timm 的大佬 Ross Wightman 就重新训练了 ResNet 精度提升了几个点

时代真的变了,别盯着原来ResNet50的70多精度,强烈建议看看 https://arxiv.org/abs/2110.00476
PS:无疑拉高了门槛,新模型不上去80都不好意思发
🎯 多阶段的改进
卷积神经网络发展了这么多年,其结构都是经过无数研究者之手雕琢出来的,比如多阶段设计思想
而 Swin 从 CNN 网络学习,把 ViT 搞成多阶段,不同阶段有不同分辨率,可以方便做下游,实际上这样的抄作业,不仅仅只有 Swin,PVT v1/v2、CoAtNet 等都体现了这个思想,你得承认现在很多 ViT 的改进方向都往 CNN 结合借鉴,抄抄经验更健康
Swin 性能确实很强,青出于蓝胜于蓝,作为"老师"的 CNN 也感到了压力,于是 ResNet 就学习一下 Swin
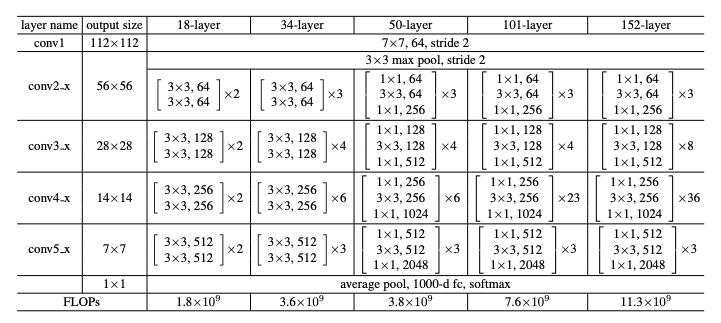
以上图 ResNet50 为例,多阶段 blocck 数为 [3,4,6,3], Swin 参考了这样的多阶段结构,相应比例为 [2,2,6,2],更大的Swin 为 [2,2,18,2]
于是,ConvNeXt 就参考了一下 Swin 高比例的设置,将多阶段 block 数从 ResNet 的 [3,4,6,3] 变成了 [3,3,9,3],这样做涨了 0.6个点左右

🎯 Block 的升级
更少的激活函数,Block 模块的升华,这一点是比较 novelty 的,如下图所示
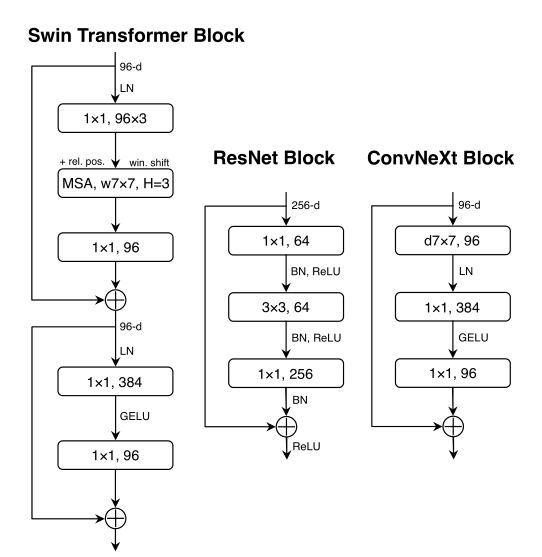
仔细观察 Res Block 和 ConvNeXt Block 的区别,首先是 DW 卷积,其采用了和 Swin MSA 一样大卷积核 7x7,作者说这样是为了效仿 ResNeXt 思想加宽网络,精度提升了1个点
接下来,我们发现 Transformer 的 FFN 层是一个 Inverted Bottleneck 结构
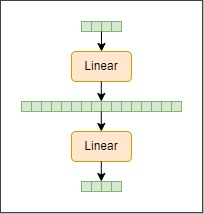
Inverted Bottleneck 特点是两头窄中间宽,于是 ConvNeXt Block 在 Res Block 上做了改进,维度变化为 96 -> 384 -> 96
接下来是激活函数,之前 CNN 中 relu 是标配,咱们为了向 Swin 看齐学习,换成 gelu,和 Transformer 一样激活函数少一点
不只是激活函数,norm 也换,从 bn 换成 ln
就这样,ConvNeXt Block 诞生了!!!
PS:这一点就很工程化,它也没有详细从原理说为啥这样好,咱也不知道咱也不敢问,性能提升就行了
🎯 下采样层
在下采样处添加 Normalization 层有助于收敛
Further investigation shows that, adding normalization layers wherever spatial resolution is changed can help stablize training. These include several LN layers also used in Swin Transformers: one before each downsampling layer, one after the stem, and one after thefinal global average pooling.
分层结构自然避免不了下采样,ResNet 的下采样是使用 Conv 3x3 ,stride 2 来实现下采样,ConvNeXt 升级了一下,学习 Swin 在两个 stage 之间添加一层下采样层,但是发现训练不稳定,解决办法就是加了点 LN 层
Show 代码环节
定义基础点的东西,比如初始化,Identity
import paddle
import paddle.nn as nn
import paddle.nn.functional as F
trunc_normal_ = nn.initializer.TruncatedNormal(std=0.02)
zeros_ = nn.initializer.Constant(value=0.0)
ones_ = nn.initializer.Constant(value=1.0)
class Identity(nn.Layer):
def __init__(self):
super().__init__()
def forward(self, x):
return x
ConvNeXt Block
class Block(nn.Layer):
""" ConvNeXt Block. There are two equivalent implementations:
(1) DwConv -> LayerNorm (channels_first) -> 1x1 Conv -> GELU -> 1x1 Conv; all in (N, C, H, W)
(2) DwConv -> Permute to (N, H, W, C); LayerNorm (channels_last) -> Linear -> GELU -> Linear; Permute back
We use (2) as we find it slightly faster in PyTorch
Args:
dim (int): Number of input channels.
drop_path (float): Stochastic depth rate. Default: 0.0
layer_scale_init_value (float): Init value for Layer Scale. Default: 1e-6.
"""
def __init__(self, dim, drop_path=0., layer_scale_init_value=1e-6):
super().__init__()
self.dwconv = nn.Conv2D(dim, dim, kernel_size=7, padding=3, groups=dim) # depthwise conv
self.norm = LayerNorm(dim, epsilon=1e-6)
self.pwconv1 = nn.Linear(dim, 4 * dim) # pointwise/1x1 convs, implemented with linear layers
self.act = nn.GELU()
self.pwconv2 = nn.Linear(4 * dim, dim)
self.gamma = paddle.create_parameter(
shape=[dim],
dtype='float32',
default_initializer=nn.initializer.Constant(value=layer_scale_init_value)) if layer_scale_init_value > 0 else None
self.drop_path = DropPath(drop_path) if drop_path > 0. else Identity()
def forward(self, x):
input = x
x = self.dwconv(x)
x = x.transpose([0, 2, 3, 1]) # (N, C, H, W) -> (N, H, W, C)
x = self.norm(x)
x = self.pwconv1(x)
x = self.act(x)
x = self.pwconv2(x)
if self.gamma is not None:
x = self.gamma * x
x = x.transpose([0, 3, 1, 2]) # (N, H, W, C) -> (N, C, H, W)
x = input + self.drop_path(x)
return x
LayerNorm
class LayerNorm(nn.Layer):
""" LayerNorm that supports two data formats: channels_last (default) or channels_first.
The ordering of the dimensions in the inputs. channels_last corresponds to inputs with
shape (batch_size, height, width, channels) while channels_first corresponds to inputs
with shape (batch_size, channels, height, width).
"""
def __init__(self, normalized_shape, epsilon=1e-6, data_format="channels_last"):
super().__init__()
self.weight = paddle.create_parameter(
shape=[normalized_shape],
dtype='float32',
default_initializer=ones_)
self.bias = paddle.create_parameter(
shape=[normalized_shape],
dtype='float32',
default_initializer=zeros_)
self.epsilon = epsilon
self.data_format = data_format
if self.data_format not in ["channels_last", "channels_first"]:
raise NotImplementedError
self.normalized_shape = (normalized_shape, )
def forward(self, x):
if self.data_format == "channels_last":
return F.layer_norm(x, self.normalized_shape, self.weight, self.bias, self.epsilon)
elif self.data_format == "channels_first":
u = x.mean(1, keepdim=True)
s = (x - u).pow(2).mean(1, keepdim=True)
x = (x - u) / paddle.sqrt(s + self.epsilon)
x = self.weight[:, None, None] * x + self.bias[:, None, None]
return x
ConvNeXt 组网
class ConvNeXt(nn.Layer):
""" ConvNeXt
Args:
in_chans (int): Number of input image channels. Default: 3
num_classes (int): Number of classes for classification head. Default: 1000
depths (tuple(int)): Number of blocks at each stage. Default: [3, 3, 9, 3]
dims (int): Feature dimension at each stage. Default: [96, 192, 384, 768]
drop_path_rate (float): Stochastic depth rate. Default: 0.
layer_scale_init_value (float): Init value for Layer Scale. Default: 1e-6.
head_init_scale (float): Init scaling value for classifier weights and biases. Default: 1.
"""
def __init__(self, in_chans=3, num_classes=1000,
depths=[3, 3, 9, 3], dims=[96, 192, 384, 768], drop_path_rate=0.,
layer_scale_init_value=1e-6, head_init_scale=1.,
):
super().__init__()
self.downsample_layers = nn.LayerList() # stem and 3 intermediate downsampling conv layers
stem = nn.Sequential(
nn.Conv2D(in_chans, dims[0], kernel_size=4, stride=4),
LayerNorm(dims[0], epsilon=1e-6, data_format="channels_first")
)
self.downsample_layers.append(stem)
for i in range(3):
downsample_layer = nn.Sequential(
LayerNorm(dims[i], epsilon=1e-6, data_format="channels_first"),
nn.Conv2D(dims[i], dims[i+1], kernel_size=2, stride=2),
)
self.downsample_layers.append(downsample_layer)
self.stages = nn.LayerList() # 4 feature resolution stages, each consisting of multiple residual blocks
dp_rates=[x.item() for x in paddle.linspace(0, drop_path_rate, sum(depths))]
cur = 0
for i in range(4):
stage = nn.Sequential(
*[Block(dim=dims[i], drop_path=dp_rates[cur + j],
layer_scale_init_value=layer_scale_init_value) for j in range(depths[i])]
)
self.stages.append(stage)
cur += depths[i]
self.norm = nn.LayerNorm(dims[-1], epsilon=1e-6) # final norm layer
self.head = nn.Linear(dims[-1], num_classes)
self.apply(self._init_weights)
self.head.weight.set_value(self.head.weight*head_init_scale)
self.head.bias.set_value(self.head.bias*head_init_scale)
def _init_weights(self, m):
if isinstance(m, (nn.Conv2D, nn.Linear)):
trunc_normal_(m.weight)
zeros_(m.bias)
def forward_features(self, x):
for i in range(4):
x = self.downsample_layers[i](x)
x = self.stages[i](x)
return self.norm(x.mean([-2, -1])) # global average pooling, (N, C, H, W) -> (N, C)
def forward(self, x):
x = self.forward_features(x)
x = self.head(x)
return x
PASSL 已支持 ConvNeXt
更详细内容可见 https://github.com/PaddlePaddle/PASSL/tree/main/configs/convnext
!git clone https://github.com/PaddlePaddle/PASSL.git # 克隆 PASSL
!pip install ftfy # 安装依赖
!pip install regex # 安装依赖
%cd PASSL
import paddle
from passl.modeling.backbones import build_backbone
from passl.modeling.heads import build_head
from passl.utils.config import get_config
class Model(paddle.nn.Layer):
def __init__(self, cfg_file):
super().__init__()
cfg = get_config(cfg_file)
self.backbone = build_backbone(cfg.model.architecture)
self.head = build_head(cfg.model.head)
def forward(self, x):
x = self.backbone(x)
x = self.head(x)
return x
cfg_file = "configs/convnext/convnext_tiny_224.yaml"
m = Model(cfg_file)
# infer test
x = paddle.randn([2, 3, 224, 224])
out = m(x) # forward
loss = out.sum()
loss.backward() # backward
xt_tiny_224.yaml"
m = Model(cfg_file)
# infer test
x = paddle.randn([2, 3, 224, 224])
out = m(x) # forward
loss = out.sum()
loss.backward() # backward
print('Single iteration completed successfully')
ConvNeXt 性能图如下所示
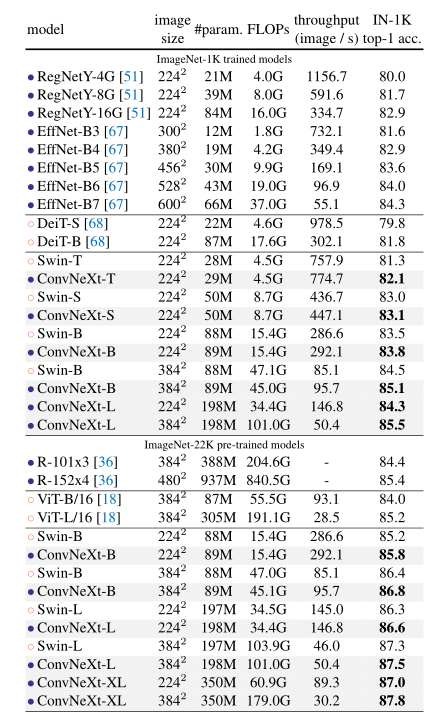
总结一下
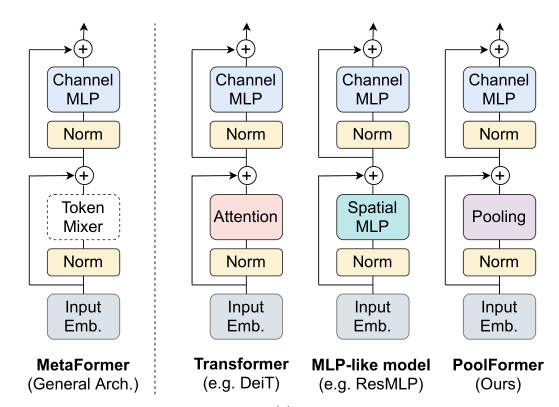
ConvNeXt 是一个非常非常工程化的东西,确实很简单思路很soild,确实没有什么novelty,这也进一步证明了视觉Transformer 威力其实并不一定来自attention,可能是训练或者架构,比如近期颜水成团队 MetaFormer
MetaFormer 将 MSA 模块换成 Pooling 模块,发现也能取得良好的精度
相比被冠以后 CNN 时代顶流的 EfficientNet v2,就论文给出的数据而言,ConvNeXt 实际上性能和它差不了太多,可能 EfficientNetv2知名度不高把,毕竟 ConvNeXt 相比更简单更直接
题外话,不少"有丶学术清高"学者在贬ConvNeXt,说没有新意全是堆卡堆训练罢了,已有 trike 排列组合罢了,实际上目前 ViT 因为在工业部署还没有成熟,但是对 CNN 已经支持的很好了,相比搞学术的,工业界更喜欢 ConvNeXt
期待基于 CNN 的模型突破 90% (top acc1)

学大模型,用大模型上飞桨星河社区!每天8点V100G算力免费领!免费领取ERNIE 4.0 100w Token >>>
更多推荐



 1
1 0
0- 0



 已为社区贡献1436条内容
已为社区贡献1436条内容

所有评论(0)