
【原理】预训练模型之长序列建模--Transformer-XL
Transformer-XL: Attentive Language Models Beyonds a Fixed-Length Context1. Transformer-XL的由来在正式讨论Transformer-XL之前,我们先来看看经典的Transformer(后文称Vanilla Transformer)是如何处理数据和训练评估模型的将,如图1所示。图1 Vanilla Transfor
Transformer-XL: Attentive Language Models Beyonds a Fixed-Length Context
1. Transformer-XL的由来
在正式讨论Transformer-XL之前,我们先来看看经典的Transformer(后文称Vanilla Transformer)是如何处理数据和训练评估模型的将,如图1所示。
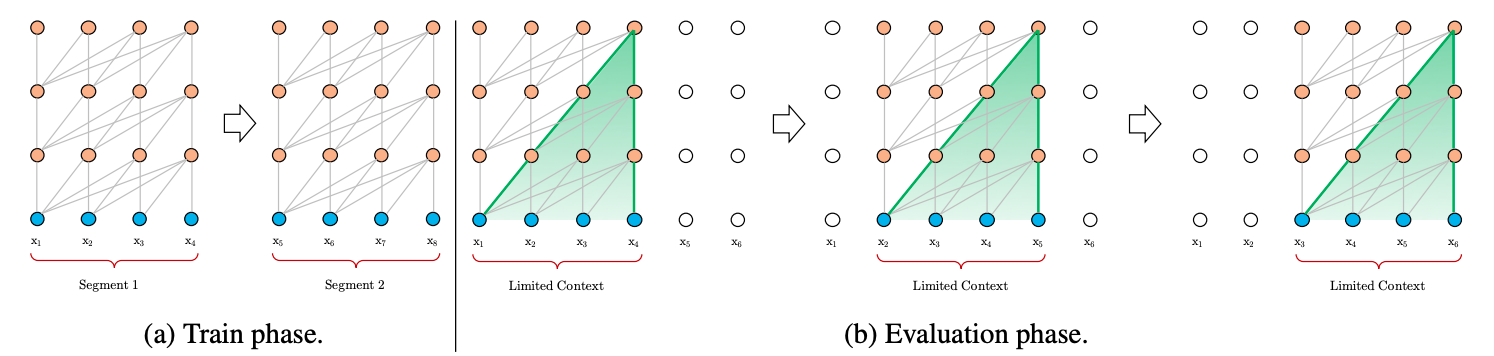
在数据处理方面,给定一串较长的文本串,Vanilla Transformer会按照固定的长度(比如512),直接将该文本串进行划分成若干Segment。这个处理方式不会关注文本串中语句本身的边界(比如标点或段落),这样"粗暴"的划分通常会将一句完整的话切分到两个Segment里面,导致上下文碎片化(context fragmentation)。另外,Transformer本身能够维持的依赖长度很有可能会超出这个固定的划分长度,从而导致Transformer能够捕获的最大依赖长度不超过这个划分长度,Transformer本身达不到更好的性能。
在模型训练方面,如图1a所示,Vanilla Transformer每次传给模型一个Segment进行训练,第1个Segment训练完成后,传入第2个Segment进行训练,然而前后的这两个Segment是没有任何联系的,也就是前后的训练是独立的。但事实是前后的Segment其实是有关联的。
在模型评估方面,如图1b所示,Vanilla Transformer会采用同训练阶段一致的划分长度,但仅仅预测最后一个位置的token,完成之后,整个序列向后移动一个位置,预测下一个token。这个处理方式保证了模型每次预测都能使用足够长的上下文信息,也缓解了训练过程中的context framentation问题。但是每次的Segment都会重新计算,计算代价很大。
基于上边的这些不足,Transformer-XL被提出来解决这些问题。它主要提出了两个技术:Segment-Level 循环机制和相对位置编码。Transformer-XL能够建模更长的序列依赖,比RNN长80%,比Vanilla Transformer长450%。同时具有更快的评估速度,比Vanilla Transformer快1800+倍。同时在多项任务上也达到了SoTA的效果。
2. Transformer-XL 建模更长序列
2.1 Segment-Level 循环机制
Transformer-XL通过引入Segment-Level recurrence mechanism来建模更长序列,它通过融合前后两个Segment的信息来到这个目的。
这里循环机制和RNN循环机制类似,在RNN中,每个时刻的RNN单元会接收上个时刻的输出和当前时刻的输入,然后将两者融合计算得出当前时刻的输出。Transformer-XL同样是接收上个时刻的输出和当前时刻的输入,然后将两者融合计算得出当前时刻的输出。但是两者的处理单位并不相同,RNN的处理单位是一个词,Transformer-XL的处理单位是一个Segment。图2展示了Transformer-XL在训练阶段和评估阶段的Segment处理方式。
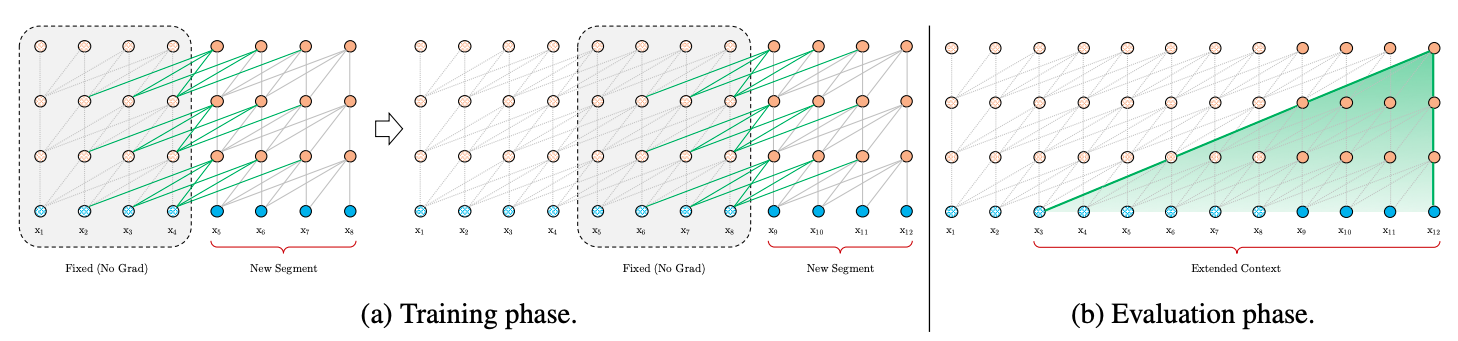
在模型训练阶段,如图2a所示,Transformer-XL会缓存前一个Segment的输出序列,在计算下一个Segment的输出时会使用上一个Segment的缓存信息,将前后不同Segment的信息进行融合,能够帮助模型看见更远的地方,建模更长的序列依赖能力,同时也避免了context fragmentation问题。
在模型评估阶段,如图2b所示,Transformer-XL通过缓存前一个Segment的输出序列,当下一个Segment需要用这些输出时(前后两个Segment具有大部分的重复),不需要重新计算,从而加快了推理速度。
下边我们来具体聊聊这些事情是怎么做的,假设前后的两个Segment分别为: s τ = [ x τ , 1 , x τ , 2 , . . . , x τ , L ] \text{s}_{\tau}=[x_{\tau,1},x_{\tau,2},...,x_{\tau,L}] sτ=[xτ,1,xτ,2,...,xτ,L]和 s τ + 1 = [ x τ + 1 , 1 , x τ + 1 , 2 , . . . , x τ + 1 , L ] \text{s}_{\tau+1}=[x_{\tau+1,1},x_{\tau+1,2},...,x_{\tau+1,L}] sτ+1=[xτ+1,1,xτ+1,2,...,xτ+1,L],其中序列长度为 L L L。另外假定 h τ n ∈ R L × d h_{\tau}^n \in \mathbb{R}^{L \times d} hτn∈RL×d为由 s τ \text{s}_{\tau} sτ计算得出的第 n n n层的状态向量,则下一个Segment s τ + 1 \text{s}_{\tau+1} sτ+1的第 n n n层可按照如下方式计算:
$
\tilde{h}{\tau+1}^{n-1} = \left[ \text{SG}(h{\tau}^{n-1}) ; \circ ;h_{\tau+1}^{n-1} \right]
$
$
q_{\tau+1}^{n}, ; k_{\tau+1}^n, ; v_{\tau+1}^n = h_{\tau+1}{n-1}W_{q}{\mathrm{ T }}, ; \tilde{h}{\tau+1}{n-1}W_{k}{\mathrm{ T }}, ; \tilde{h}{\tau+1}{n-1}W_{v}{\mathrm{ T }}
$
$
h_{\tau+1}^n = \text{Transformer-Layer}(q_{\tau+1}^{n}, ; k_{\tau+1}^n, ; v_{\tau+1}^n)
$
其中, SG ( h τ n − 1 ) \text{SG}(h_{\tau}^{n-1}) SG(hτn−1)表示不使用梯度, [ SG ( h τ n − 1 ) ∘ h τ + 1 n − 1 ] \left[ \text{SG}(h_{\tau}^{n-1}) \; \circ \;h_{\tau+1}^{n-1} \right] [SG(hτn−1)∘hτ+1n−1]表示将前后两个Segment的输出向量在序列维度上进行拼接。中间的公式表示获取Self-Attention计算中相应的 q , k , v q,k,v q,k,v矩阵,其中在计算 q q q的时候仅仅使用了当前Segment的向量,在计算 k k k和 v v v的时候同时使用前一个Segment和当前Segment的信息。最后通过Self-Attention融合计算,得出当前Segment的输出向量序列。
2.2 相对位置编码
Segment-Level recurrence mechanism看起来已经做到了长序列建模,但是这里有个问题需要进一步讨论一下。我们知道,在Vanilla Transformer使用了绝对位置编码,我们来看看如果将绝对位置编码应用到Segment-Level recurrence mechanism中会怎样。
还是假设前后的两个Segment分别为: s τ = [ x τ , 1 , x τ , 2 , . . . , x τ , L ] \text{s}_{\tau}=[x_{\tau,1},x_{\tau,2},...,x_{\tau,L}] sτ=[xτ,1,xτ,2,...,xτ,L]和 s τ + 1 = [ x τ + 1 , 1 , x τ + 1 , 2 , . . . , x τ + 1 , L ] \text{s}_{\tau+1}=[x_{\tau+1,1},x_{\tau+1,2},...,x_{\tau+1,L}] sτ+1=[xτ+1,1,xτ+1,2,...,xτ+1,L],其中序列长度为 L L L。每个Segment的Position Embedding矩阵为 U 1 : L ∈ R L × d U_{1:L} \in \mathbb{R}^{L \times d} U1:L∈RL×d, 每个Segment s τ \text{s}_{\tau} sτ的词向量矩阵为 E s τ ∈ R L × d E_{\text{s}_{\tau}} \in \mathbb{R}^{L \times d} Esτ∈RL×d,在Vanilla Transformer中,两者相加输入模型参与计算,如下式所示:
h τ + 1 = f ( h τ , E s τ + 1 + U 1 : L ) h τ = f ( h τ − 1 , E s τ + U 1 : L ) h_{\tau+1} = f(h_{\tau},\; E_{\text{s}_{\tau+1}}+U_{1:L}) \\ h_{\tau} = f(h_{\tau-1},\; E_{\text{s}_{\tau}}+U_{1:L}) hτ+1=f(hτ,Esτ+1+U1:L)hτ=f(hτ−1,Esτ+U1:L)
很明显,如果按照这个方式计算,前后两个段 E s τ E_{\text{s}_{\tau}} Esτ和 E s τ + 1 E_{\text{s}_{\tau+1}} Esτ+1将具有相同的位置编码,这样两者信息融合的时候肯定会造成位置信息混乱。为了避免这份尴尬的操作,Transformer-XL使用了相对位置编码。
相对位置是通过计算两个token之间的距离定义的,例如第5个token相对第2个token之间的距离是3, 那么位置 i i i相对位置 j j j的距离是 i − j i-j i−j,假设序列之中的最大相对距离 L m a x L_{max} Lmax,则我们可以定义这样的一个相对位置矩阵 R ∈ R L m a x × d R \in \mathbb{R}^{L_{max} \times d} R∈RLmax×d,其中 R k R_k Rk表示两个token之间距离是 k k k的相对位置编码向量。注意在Transformer-XL中,相对位置编码向量不是可训练的参数,以 R k = [ r k , 1 , r k , 2 , . . . , r k , d ] R_k = [r_{k,1}, r_{k,2},...,r_{k,d}] Rk=[rk,1,rk,2,...,rk,d]为例,每个元素通过如下形式生成:
r b , 2 j = sin ( b 1000 0 2 j / d ) , r b , 2 j + 1 = cos ( b 1000 0 ( 2 j ) / d ) r_{b,2j} = \text{sin}(\frac{b}{10000^{2j/d}}), \quad r_{b,2j+1} = \text{cos}(\frac{b}{10000^{(2j)/d}}) rb,2j=sin(100002j/db),rb,2j+1=cos(10000(2j)/db)
Transformer-XL将相对位置编码向量融入了Self-Attention机制的计算过程中,这里可能会有些复杂,我们先来看看Vanilla Transformer的Self-Attention计算过程,如下:
$
A_{i,j}^{\text{abs}} = (W_q(E_{x_i}+U_i))^{\text{T}}(W_k(E_{x_j}+U_j)))
$
$
= \underbrace {E_{x_i}^{\text{T}} W_q^{\text{T}} W_k E_{x_j}}{(a)} + \underbrace {E{x_i}^{\text{T}} W_q^{\text{T}} W_k U_j}{(b)} + \underbrace {U{i}^{\text{T}} W_q^{\text{T}} W_k E_{x_j}}{©} + \underbrace {U{i}^{\text{T}} W_q^{\text{T}} W_k U_{j}}_{(d)}
$
其中 E x i E_{x_i} Exi表示token x i x_i xi的词向量, U i U_i Ui表示其绝对位置编码,根据这个展开公式,Transformer-XL将相对位置编码信息融入其中,如下:
$
A_{i,j}^{\text{rel}} = \underbrace {E_{x_i}^{\text{T}} W_q^{\text{T}} W_{k,E} E_{x_j}}{(a)} + \underbrace {E{x_i}^{\text{T}} W_q^{\text{T}} W_{k,R} R_{i-j}}{(b)} + \underbrace {u^{\text{T}} W{k,E} E_{x_j}}{©} + \underbrace {v^{\text{T}} W{k,R} R_{i-j}}_{(d)}
$
这里做了这样几处改变以融入相对位置编码:
- 在分项 ( b ) (b) (b)和 ( d ) (d) (d)中,使用相对位置编码 R i − j R_{i-j} Ri−j取代绝对位置编码 U j U_j Uj。
- 在分项 ( c ) (c) (c)和 ( d ) (d) (d)中,使用可训练参数 u u u和 v v v取代 U i T W q T U_{i}^{\text{T}} W_q^{\text{T}} UiTWqT。因为 U i T W q T U_{i}^{\text{T}} W_q^{\text{T}} UiTWqT表示第 i i i个位置的query 向量,这个query向量对于其他要进行Attention的位置来说都是一样的,因此可以直接使用统一的可训练参数进行替换。
- 在所有分项中,使用 W k , E W_{k,E} Wk,E和 W k , R W_{k,R} Wk,R计算基于内容(词向量)的key向量和基于位置的key向量。
式子中的每个分项分别代表的含义如下:
- ( a ) (a) (a)描述了基于内容的Attention
- ( b ) (b) (b)描述了内容对于每个相对位置的bias
- ( c ) (c) (c)描述了内容的全局bias
- ( d ) (d) (d)描述了位置的全局bias
2.3 完整的Self-Attention计算过程
上边描述了Transformer-XL中的两个核心技术:Segment-Level 循环机制和相对位置编码,引入了这两项技术之后,Transformer-XL中从第 n − 1 n-1 n−1层到第 n n n层完整的计算过程是这样的:
$
\tilde{h}{\tau}^{n-1} = \left[ \text{SG}(h{\tau-1}^{n-1}) ; \circ ;h_{\tau}^{n-1} \right]
$
$
q_{\tau}^{n}, ; k_{\tau}^n, ; v_{\tau}^n = h_{\tau}{n-1}{W_{q}n}^{\mathrm{ T }}, ; \tilde{h}{\tau}{n-1}{W_{k,E}n}^{\mathrm{ T }}, ; \tilde{h}{\tau}{n-1}{W_{v}n}^{\mathrm{ T }}
$
$
A_{\tau,i,j}^{n} = {q_{\tau, i}{n}}{\text{T}}k_{\tau,j}^{n} + {q_{\tau, i}{n}}{\text{T}}W_{k,R}^{n}R_{i-j} + u^{\text{T}}k_{\tau,j} + v{\text{T}}W_{k,R}{n}R_{i-j}
$
$
{\alpha}{\tau}^n = \text{Masked-Softmax}(A{\tau}n)v_{\tau}n
$
$
{\omicron}{\tau}^n = \text{LayerNorm}(\text{Linear}({\alpha}{\tau}n)+h_{\tau}{n-1})
$
$
h_{\tau}^n = \text{Positionwise-Feed-Forward}({\omicron}_{\tau}^n)
$
3. 相关资料
如果同学们对本课程感兴趣,想了解更多课程相关信息,或者查阅更多课程资料,请移步我们的官方github: awesome-DeepLearning,也欢迎各位同学点击Star,有大家的支持我们才会走得更远,提供更多优质资源以供学习。同时更多深度学习资料请参阅飞桨深度学习平台。

最后,也欢迎同学们加入我们的官方交流群。


学大模型,用大模型上飞桨星河社区!每天8点V100G算力免费领!免费领取ERNIE 4.0 100w Token >>>
更多推荐



 0
0 0
0- 0



 已为社区贡献1437条内容
已为社区贡献1437条内容

所有评论(0)