
【实践】基于DDPG算法的股票量化交易
这个项目介绍并实现了强化学习中的DDPG算法,并用于模拟股票交易。更多有趣项目详见: https://github.com/PaddlePaddle/awesome-DeepLearning
使用DDPG算法应用于股票交易
本项目基于DDPG算法应用于股票交易场景,其包含五个模块,读者可根据需要依次或选择性阅读。
- 深度学习资源推荐
- 项目介绍
- 项目理论解读
- 项目详细实现
- 项目结果
- 项目总结
- 更多PaddleEdu信息内容
深度学习资源推荐
⭐ ⭐ ⭐ 欢迎点个小小的Star支持!⭐ ⭐ ⭐
开源不易,希望大家多多支持~

- 更多实践案例(AI识虫,基于PaddleX实现森林火灾监测,眼疾识别,智能相册分类等)、深度学习资料,请参考:awesome-DeepLearning
- 更多图像分类模型(ResNet_vd系列、MobileNet_v3等),请参考:PaddleClas
- 更多学习资料请参阅飞桨深度学习平台
1.项目介绍
1.1项目目的
- 理解并掌握强化学习的基础要素,包括智能体、环境、状态、动作、策略和奖励;
- 理解DDPG算法,包括该算法解决了DQN的哪些不足,DDPG的创新点及算法的具体内容;
- 熟悉经典强化学习算法的设计原理,以及构建流程;
- 熟悉飞桨框架,并通过飞桨框架实现深度强化学习中的一个经典算法——DDPG算法。
1.2项目内容
股票交易是一个经典的时序决策问题,其指的是在每个交易时间点通过分析历史图表,从而做出对应决策(如:买入、卖出、观望等),以达到长期的最大收益。该问题如图1所示。
因此,该问题可以被建模为一个强化学习问题。在此场景下,人即为智能体,股票市场为环境,人通过对股票做出决策,即与环境交互后,会获得股票当前的状态。在此项目中,股票状态包含19个属性变量,包含所采用第三方股票数据包baostock的一些股票属性和基于此计算得到的一些属性变量,分别为:
| 属性名 | 含义 |
|---|---|
| open | 当天开盘价格 |
| high | 最高价格 |
| low | 最低价格 |
| close | 收盘价格 |
| volume | 成交量 |
| amount | 成交额 |
| adjustflag | 赋权状态(1:后复权,2:前复权,3:不复权) |
| tradestatus | 交易状态(1:正常交易,0:停牌) |
| pctChg | 涨跌幅(百分比) |
| peTTM | 滚动市盈率 |
| pbMRQ | 市净率 |
| psTTM | 滚动市销率 |
| balance | 当前拥有的金钱 |
| max_net_worth | 最大资产净值 |
| shares_held | 持有的手数 |
| cost_basis | 即时买入价格 |
| total_shares_sold | 总共抛出的手数 |
| total_sales_value | 总共抛出的价值 |
NOTE:上述属性值均会经过归一化处理,因此在此项目中,状态为一个长度为19的一维向量,其中每一个值的值域均为 [ 0 , 1 ] [0,1] [0,1]。
人根据当前的状态,依据现有的策略,执行相应的动作,在此项目中,可执行的动作为以下三种:
| 值区间 | 动作 |
|---|---|
| ( − 3 , − 1 ) (-3,-1) (−3,−1) | 卖出股票 |
| ( − 1 , 1 ) (-1,1) (−1,1) | 观望 |
| ( 1 , 3 ) (1,3) (1,3) | 买入股票 |
为了定量买入/卖出的股票数量,此项目加入了另一个值amount,表示买入/卖出的股票的比例。因此,此场景下的动作空间为一个长度为2的一维向量,其中第一个值表示动作种类,值域为 [ − 3 , 3 ] [-3,3] [−3,3];第二个值表示买入/卖出的股票的比例,值域为 [ 0 , 1 ] [0,1] [0,1]。
在该项目中,若触发以下三种情况任意一种,则一轮实验终止(我们称一个序幕(episode)为一轮实验):
- 最大资产净值大于等于最大金钱乘以最大预测的收益比,即:
m a x _ n e t _ w o r t h ≥ i n i t i a l _ a c c o u n t _ b a l a n c e × m a x _ p r e d i c t _ r a t e \mathbb{max\_net\_worth\ge{initial\_account\_balance\times{max\_predict\_rate}}} max_net_worth≥initial_account_balance×max_predict_rate
- 状态转移到数据集中的最后一天
- 当前的资产净值小于等于0,即:
n e t _ w o r t h ≤ 0 \mathbb{net\_worth\le0} net_worth≤0
该项目中的奖励信号reward设计基于相对初始收益比来度量,具体地:
- 计算出当前状态状态 s s s采取动作 a a a的资产净值
net_worth,其由两部分构成:当前资产和当前持有股票的价值,即:
n e t _ w o r t h = b a l a n c e + n u m _ s h a r e s _ h e l d × c u r r e n t _ p r i c e \mathbb{net\_worth=balance+num\_shares\_held\times{current\_price}} net_worth=balance+num_shares_held×current_price
- 计算出相对收益比:
p r o f i t _ p e r c e n t = n e t _ w o r t h − i n i t i a l _ a c c o u n t _ b a l a n c e i n i t i a l _ a c c o u n t _ b a l a n c e \mathbb{profit\_percent=\frac{net\_worth-initial\_account\_balance}{initial\_account\_balance}} profit_percent=initial_account_balancenet_worth−initial_account_balance
- 奖励设计:若相对收益比大于等于0,则奖励信号取相对收益比的1000倍与1之间的较大值;反之,则此轮决策交互的奖励为-100。即有:
r e w a r d = { max ( 1 , p r o f i t _ p e r c e n t 0.001 ) , i f p r o f i t _ p e r c e n t ≥ 0 − 100 , o t h e r s \mathbb{reward=} \begin{cases} \max(1,\mathbb{\frac{profit\_percent}{0.001}}),\quad{if\ }\mathbb{profit\_percent\ge0}\\ -100,\quad\quad\quad\quad\quad\quad\quad{others} \end{cases} reward={max(1,0.001profit_percent),if profit_percent≥0−100,others
该项目的股票环境将继承gym库的环境实现,提供reset(),step()等训练接口。人每次根据环境状态执行上述三种动作中的一种,并根据股票市场交易规则计算奖励信号,DDPG算法同DQN算法一样,会将每一条经验,即 s t , a t , r t , s t + 1 , d o n e s_t,a_t,r_t,s_{t+1},\mathbb{done} st,at,rt,st+1,done存储在经验池中,在随机抽取一批数据,送进神经网络中学习。同时,区别于DQN算法的 ε − g r e e d y \varepsilon-greedy ε−greedy算法选取离散动作,DDPG引入了动作网络actor来得到连续的动作信号。我们将通过这个实验来更好地理解DDPG算法。
1.3项目环境
本项目支持在实训平台或本地环境操作,建议您使用实训平台。
- 实训平台:如果您选择在实训平台上操作,无需安装实验环境。实训平台集成了项目必须的相关环境,代码可在线运行,同时还提供了免费算力,即使实践复杂模型也无算力之忧。
- 本地环境:如果您选择在本地环境上操作,需要安装Python3.7、飞桨开源框架2.0等实验必须的环境,具体要求及实现代码请参见《本地环境安装说明》。
您可通过如下代码导入项目环境。
# 导入项目环境
import random
import numpy as np
import gym
from gym import spaces
import argparse
import os
import copy
import paddle
import pandas as pd
import paddle.nn as nn
import paddle.optimizer as optim
import paddle.nn.functional as F
from visualdl import LogWriter
import model
import ReplayBuffer
import StockEnv
1.4实验设计
强化学习的基本原理在于智能体与其所处环境的交互并从中进行学习。在DQN算法中,智能体会在与所处环境environment进行交互后,获得一个环境提供的状态 s t s_t ststate(也可以说是获得环境提供的观测值observation),接收状态后,智能体会利用actor网络计算出当前状态应采取的动作 a t a_t ataction,同时智能体会根据critic网络预测出在该状态下行动 a t a_t at对应的Q值,当行动反馈给环境后,环境会给出对应的奖励 r t r_t rtreward、新的状态 s t + 1 s_{t+1} st+1,以及是否触发终止条件done。每一次交互完成,DDPG算法都会将 s t , a t , r t , s t + 1 , d o n e s_t,a_t,r_t,s_{t+1},\mathbb{done} st,at,rt,st+1,done作为一条经验储存在经验池中,每次会从经验池中抽取一定量的经验作为输入数据训练神经网络。
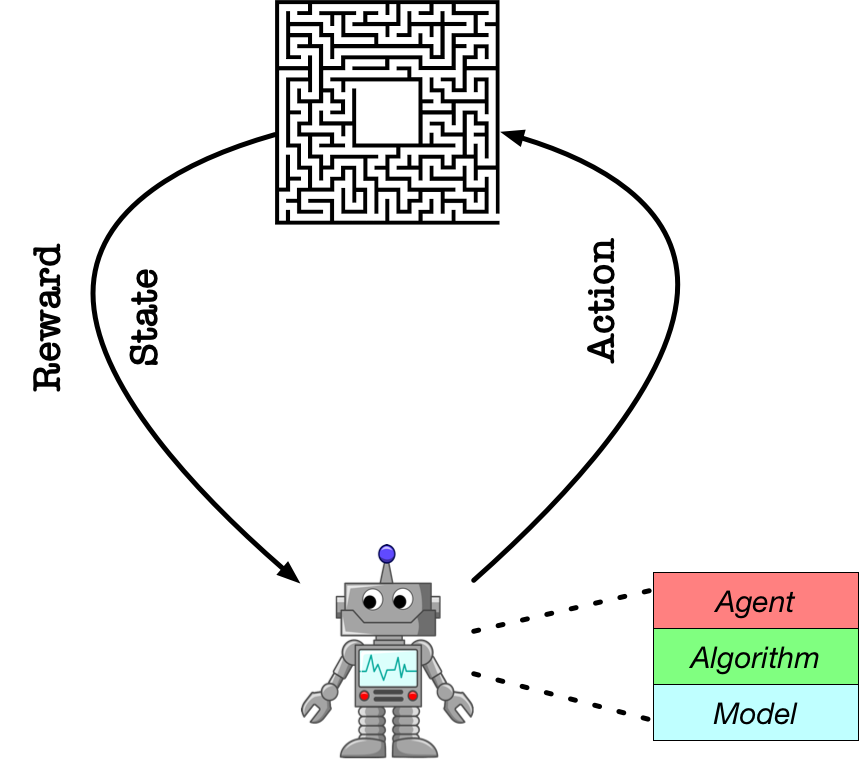
Model: Model用来定义前向 (Forward) 网络,通常是一个策略网络 (Policy Network) 或者一个值函数网络 (Value Function),输入是当前环境状态。在本实验中,我们将在Model结构中构建一个值函数网络和一个策略网络,用于获得在当前环境状态下的action以及对应的Q值。
Algorithm: Algorithm定义了具体的算法来更新前向网络 (Model),也就是通过定义损失函数来更新 Model。和算法相关的计算都可定义在Algorithm中。
Agent: Agent负责算法与环境的交互,在交互过程中把生成的数据提供给Algorithm来更新模型。
2.项目理论解读
在本项目开始前,大家需要对DQN算法有所了解。
2.1 DQN网络的由来
DQN算法使用神经网络来拟合Q函数,以应对高维的、连续的状态空间。常见的强化学习环境的状态数量如图3所示。

同时,由于采用了神经网络来拟合Q函数,会导致一些问题出现。
- 由于强化学习的数据为带有时序关系的数据,因此并不是独立同分布的。为了解决在神经网络梯度更新时,数据样本间的关联性导致的梯度不准的问题,DQN算法采用了经验回放机制。
- 由于参数化了Q函数,因此在q_target中包含了正在优化的网络参数,这样计算出来的梯度也是不准的,我们称为半梯度。针对这个问题,DQN算法采用了固定目标机制。
经验回放机制:
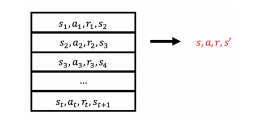
为了减小样本数据之间的相关性,DQN构造了一个存储转移关系的缓冲容器 D D D,即:
D = { < s 1 , a 1 , r 1 , s 2 > , < s 2 , a 2 , r 2 , s 3 > , ⋯ , < s n , r n , a n , s n + 1 > } D=\{<s_1,a_1,r_1,s_{2}>,<s_2,a_2,r_2,s_{3}>,\cdots,<s_n,r_n,a_n,s_{n+1}>\} D={<s1,a1,r1,s2>,<s2,a2,r2,s3>,⋯,<sn,rn,an,sn+1>}
每一个元组 < s t , a t , r t , s t + 1 > <s_t,a_t,r_t,s_{t+1}> <st,at,rt,st+1>表示一次智能体与环境的交互,从而形成转移关系。其示意如图4所示:
执行经验重放算法的框架为:
- 采样
从容器中随机采取数据样本:
( s , a , r , s ′ ) ∼ D (s,a,r,s')\quad\sim\quad{D} (s,a,r,s′)∼D
- 利用采集到批量数据计算TD-target
T D _ t a r g e t = r + γ max a ′ Q ^ ( s ′ , a ′ , ω ) \rm{TD\_{target}}=r+\gamma\max_{a'}\hat{Q}(s',a',\omega) TD_target=r+γa′maxQ^(s′,a′,ω)
- 使用随机梯度下降来更新网络权值
Δ ω = α ( T D _ t a r g e t − Q ^ ( s , a , ω ) ) ∇ ω Q ^ ( s , a , ω ) \Delta{\omega}={\alpha(\rm{TD\_target}-\hat{Q}(s,a,\omega))}\nabla_\omega\hat{Q}(s,a,\omega) Δω=α(TD_target−Q^(s,a,ω))∇ωQ^(s,a,ω)
固定目标机制:
由于TD-target中含有正在优化的参数 ω \omega ω,因此带来了不确定性,会导致训练结果不稳定。为了训练的时候更稳定,需要固定在TD-target中的参数。
因此,考虑一个新的网络,其参数为 ω − \omega^- ω−,表示这个网络参数的更新来自于当前的评估网络,但是更新速度较慢。那么基于此,可以得到带固定目标的算法框架为:
- 采样
从容器中随机采取数据样本:
( s , a , r , s ′ ) ∼ D (s,a,r,s')\quad\sim\quad{D} (s,a,r,s′)∼D
- 利用采集到批量数据和目标网络来计算TD-target
T D _ t a r g e t = r + γ max a ′ Q ^ ( s ′ , a ′ , ω − ) \rm{TD\_{target}}=r+\gamma\max_{a'}\hat{Q}(s',a',\textcolor{red}{\omega^-}) TD_target=r+γa′maxQ^(s′,a′,ω−)
- 使用随机梯度下降来更新当前的评价网络权值
Δ ω = α ( T D _ t a r g e t − Q ^ ( s , a , ω ) ) ∇ ω Q ^ ( s , a , ω ) = α ( r + γ max a ′ Q ^ ( s ′ , a ′ , ω − ) − Q ^ ( s , a , ω ) ) ∇ ω Q ^ ( s , a , ω ) \begin{aligned} \Delta{\omega}&={\alpha(\rm{TD\_target}-\hat{Q}(s,a,\omega))}\nabla_\omega\hat{Q}(s,a,\omega) \\ &={\alpha(r+\gamma\max_{a'}\hat{Q}(s',a',\textcolor{red}{\omega^-})-\hat{Q}(s,a,\omega))}\nabla_\omega\hat{Q}(s,a,\omega) \end{aligned} Δω=α(TD_target−Q^(s,a,ω))∇ωQ^(s,a,ω)=α(r+γa′maxQ^(s′,a′,ω−)−Q^(s,a,ω))∇ωQ^(s,a,ω)
- 训练一定步数后,更新目标网络的参数 ω − \omega^- ω−
ω − = ω i f n _ s t e p % u p d a t e _ f r e q u e n c y = = 0 \omega^-=\omega\quad\rm{if\ {n\_step\ \%\ update\_frequency}==0} ω−=ωif n_step % update_frequency==0
简要说明算法有效性的示意图如下:
使用猫(estimation)追老鼠(target)来表征两个网络

如图6所示,可以看到在固定之前,猫和老鼠参数一样,在状态空间内,猫很难追上老鼠

而固定后,可以看作猫比老鼠跑得快,因此更容易追上老鼠。
2.2 DDPG算法
DDPG算法提出的背景是:如何拓展DQN到拥有连续动作空间的环境。因此DDPG算法可以视作DQN算法在连续状态空间的实现版本,其增加了一个策略网络actor来拟合输出动作信号。其与DQN的对比如下:
D Q N : a ∗ = arg max a Q ∗ ( s , a ) D D P G : a ∗ = arg max a Q ∗ ( s , a ) ≈ Q ϕ ( s , μ θ ( s ) ) \begin{aligned} \mathbf{DQN}&:a^*=\arg\max_{a} Q^*(s,a)\\ \mathbf{DDPG}&:a^*=\arg\max_{a} Q^*(s,a)\approx{Q}_{\phi}(s,\mu_{\theta}(s)) \end{aligned} DQNDDPG:a∗=argamaxQ∗(s,a):a∗=argamaxQ∗(s,a)≈Qϕ(s,μθ(s))
其中, μ θ ( s ) \mu_{\theta}(s) μθ(s)即为actor网络,其基于当前的状态 s s s作为输入,并给出输出动作 a a a;而 Q ϕ Q_{\phi} Qϕ即为critic网络,其基于当前的状态 s s s和动作 a a a作为输入,并输出Q值。
因此,DDPG算法拥有如下的目标函数:
Q − t a r g e t : y ( r , s ′ , d ) = r + γ ( 1 − d ) Q ϕ t a r g ( s ′ , μ θ t a r g ( s ′ ) ) Q − f u n c t i o o n : min E s , r , s ′ , d ∼ D [ Q ϕ ( s , a ) − y ( r , s ′ , d ) ] p o l i c y : max θ E s ∼ D [ Q ϕ ( s ) ] \begin{aligned} \mathbf{Q-target}&:{y(r,s',d)=r+\gamma(1-d)Q_{\phi_{targ}}(s',\mu_{\theta_{targ}}(s'))}\\ \mathbf{Q-functioon}&:\min{E_{s,r,s',d\sim{D}}[Q_{\phi}(s,a)-y(r,s',d)]}\\ \mathbf{policy}&:\max_\theta{E_{s\sim{D}}[Q_{\phi}(s)]} \end{aligned} Q−targetQ−functioonpolicy:y(r,s′,d)=r+γ(1−d)Qϕtarg(s′,μθtarg(s′)):minEs,r,s′,d∼D[Qϕ(s,a)−y(r,s′,d)]:θmaxEs∼D[Qϕ(s)]
其价值网络(参数为 ϕ \phi ϕ)的目标仍为最小化时序差分误差;同时其策略网络(参数为 θ \theta θ)的目标为最大化价值网络。
与DQN思想类似,为了使训练过程更稳定,也引入了经验回放和目标网络机制,因此,DDPG算法中共含有4个神经网络。
3.项目详细实现
DDPG应用于股票交易项目流程包含如下6个步骤:
-
环境构建:继承
gym.env,构建股票交易环境StockEnv; -
容器构建:设计带有存储数据和随机采样的容器
buffer; -
模型构建:设计
model,定义具体的算法,其中包括设计前向网络,指定损失函数及优化器; -
训练配置:定义超参数,加载实验环境,实例化模型;
-
模型训练:执行多轮训练,不断调整参数,以达到较好的效果;
-
模型评估:对训练好的模型进行评估测试,观察reward;
-
模型保存:将模型保存到指定位置,以便后续推理或继续训练使用;
-
模型测试:在测试集数据中测试模型的表现。
3.1 环境构建
继承gym.env,并重写相应的接口即可,如__init__(),reset(),step()等,代码如下,详细代码亦可见StockEnv.py。
# 默认的一些数据,用于归一化属性值
MAX_ACCOUNT_BALANCE = 214748 # 组大的账户财产
MAX_NUM_SHARES = 214748 # 最大的手数
MAX_SHARE_PRICE = 5000 # 最大的单手价格
MAX_VOLUME = 1000e6 # 最大的成交量
MAX_AMOUNT = 3e5 # 最大的成交额
MAX_OPEN_POSITIONS = 5 # 最大的持仓头寸
MAX_STEPS = 500 # 最大的交互次数
MAX_DAY_CHANGE = 1 # 最大的日期改变
max_loss =-50000 # 最大的损失
max_predict_rate = 4 # 最大的预测率
INITIAL_ACCOUNT_BALANCE = 10000 # 初始的金钱
class StockTradingEnv(gym.Env):
"""A stock trading environment for OpenAI gym"""
metadata = {'render.modes': ['human']}
def __init__(self, df):
super(StockTradingEnv, self).__init__()
self.df = df
self.reward_range = (0, MAX_ACCOUNT_BALANCE)
# 动作的可能情况:买入x%, 卖出x%, 观望
self.action_space = spaces.Box(
low=np.array([-3, 0]), high=np.array([3, 1]), dtype=np.float32)
# 环境状态的维度
self.observation_space = spaces.Box(
low=0, high=1, shape=(19,), dtype=np.float32)
def seed(self, seed):
random.seed(seed)
np.random.seed(seed)
# 处理状态
def _next_observation(self):
# 有些股票数据缺失一些数据,处理一下
d10 = self.df.loc[self.current_step, 'peTTM'] / 1e4
d11 = self.df.loc[self.current_step, 'pbMRQ'] / 100
d12 = self.df.loc[self.current_step, 'psTTM'] / 100
if np.isnan(d10): # 某些数据是0.00000000e+00,如果是nan会报错
d10 = d11 = d12 = 0.00000000e+00
obs = np.array([
self.df.loc[self.current_step, 'open'] / MAX_SHARE_PRICE,
self.df.loc[self.current_step, 'high'] / MAX_SHARE_PRICE,
self.df.loc[self.current_step, 'low'] / MAX_SHARE_PRICE,
self.df.loc[self.current_step, 'close'] / MAX_SHARE_PRICE,
self.df.loc[self.current_step, 'volume'] / MAX_VOLUME,
self.df.loc[self.current_step, 'amount'] / MAX_AMOUNT,
self.df.loc[self.current_step, 'adjustflag'] / 10,
self.df.loc[self.current_step, 'tradestatus'] / 1,
self.df.loc[self.current_step, 'pctChg'] / 100,
d10,
d11,
d12,
self.df.loc[self.current_step, 'pctChg'] / 1e3,
self.balance / MAX_ACCOUNT_BALANCE,
self.max_net_worth / MAX_ACCOUNT_BALANCE,
self.shares_held / MAX_NUM_SHARES,
self.cost_basis / MAX_SHARE_PRICE,
self.total_shares_sold / MAX_NUM_SHARES,
self.total_sales_value / (MAX_NUM_SHARES * MAX_SHARE_PRICE),
])
return obs
# 执行当前动作,并计算出当前的数据(如:资产等)
def _take_action(self, action):
# 随机设置当前的价格,其范围上界为当前时间点的价格
current_price = random.uniform(
self.df.loc[self.current_step, "open"], self.df.loc[self.current_step, "close"])
action_type = action[0]
amount = action[1]
if action_type > 1: # 买入amount%
total_possible = int(self.balance / current_price)
shares_bought = int(total_possible * amount)
prev_cost = self.cost_basis * self.shares_held
additional_cost = shares_bought * current_price
self.balance -= additional_cost
self.cost_basis = (
prev_cost + additional_cost) / (self.shares_held + shares_bought)
self.shares_held += shares_bought
elif action_type < -1: # 卖出amount%
shares_sold = int(self.shares_held * amount)
self.balance += shares_sold * current_price
self.shares_held -= shares_sold
self.total_shares_sold += shares_sold
self.total_sales_value += shares_sold * current_price
# 计算出执行动作后的资产净值
self.net_worth = self.balance + self.shares_held * current_price
if self.net_worth > self.max_net_worth:
self.max_net_worth = self.net_worth
if self.shares_held == 0:
self.cost_basis = 0
# 与环境交互
def step(self, action):
# 在环境内执行动作
self._take_action(action)
done = False
# 判断是否终止
self.current_step += 1
if self.max_net_worth >= INITIAL_ACCOUNT_BALANCE * max_predict_rate:
done = True
if self.current_step > len(self.df.loc[:, 'open'].values) - 1:
self.current_step = 0 # loop training
done = True
delay_modifier = (self.current_step / MAX_STEPS)
# 计算相对收益比,并据此来计算奖励
profit = self.net_worth - INITIAL_ACCOUNT_BALANCE
profit_percent = profit / INITIAL_ACCOUNT_BALANCE
if profit_percent>=0:
reward = max(1,profit_percent/0.001)
else:
reward = -100
if self.net_worth <= 0 :
done = True
obs = self._next_observation()
return obs, reward, done, {}
# 重置环境
def reset(self, new_df=None):
# 重置环境的变量为初始值
self.balance = INITIAL_ACCOUNT_BALANCE
self.net_worth = INITIAL_ACCOUNT_BALANCE
self.max_net_worth = INITIAL_ACCOUNT_BALANCE
self.shares_held = 0
self.cost_basis = 0
self.total_shares_sold = 0
self.total_sales_value = 0
self.count = 0
self.interval = 5
# 传入环境数据集
if new_df:
self.df = new_df
self.current_step = 0
return self._next_observation()
# 显示环境至屏幕
def render(self, mode='human'):
# 打印环境信息
profit = self.net_worth - INITIAL_ACCOUNT_BALANCE
print('-'*30)
print(f'Step: {self.current_step}')
print(f'Balance: {self.balance}')
print(f'Shares held: {self.shares_held} (Total sold: {self.total_shares_sold})')
print(f'Avg cost for held shares: {self.cost_basis} (Total sales value: {self.total_sales_value})')
print(f'Net worth: {self.net_worth} (Max net worth: {self.max_net_worth})')
print(f'Profit: {profit}')
return profit
3.2容器构建
在此项目中,采用numpy.array作为容器,并提供添加数据add()和随机采样sample两个接口,详细代码如下:
# 缓存容器:内容为{obs, act, obs_, reward, done}五元组
class SimpleReplayBuffer(object):
def __init__(self, state_dim, action_dim, max_size=int(1e4)):
self.max_size = max_size
self.cur = 0
self.size = 0
self.states = np.zeros((max_size, state_dim))
self.actions = np.zeros((max_size, action_dim))
self.next_states = np.zeros((max_size, state_dim))
self.rewards = np.zeros((max_size, 1))
self.dones = np.zeros((max_size, 1))
self.device = paddle.get_device()
# 存入数据
def add(self, state, action, next_state, reward, done):
self.states[self.cur] = state
self.actions[self.cur] = action
self.next_states[self.cur] = next_state
self.rewards[self.cur] = reward
self.dones[self.cur] = done
# 指针移动
self.cur = (self.cur + 1) % self.max_size
self.size = min(self.size + 1, self.max_size)
# 采样
def sample(self, batch):
ids = np.random.randint(0, self.size, size=batch)
# 返回paddle张量
return (
paddle.to_tensor(self.states[ids], dtype='float32', place=self.device),
paddle.to_tensor(self.actions[ids], dtype='float32', place=self.device),
paddle.to_tensor(self.next_states[ids], dtype='float32', place=self.device),
paddle.to_tensor(self.rewards[ids], dtype='float32', place=self.device),
paddle.to_tensor(self.dones[ids], dtype='float32', place=self.device)
)
在add()中,我们将数据存储在当前数组下标处,并将下标指针加一,当数据超过容器最大容量时,滚动覆盖最开始的数据。
在sample()中,我们根据参数batch的大小,随机采样batch组数据,并将数据转成paddle.tensor格式,方便神经网络的训练。
3.3模型构建
DDPG的算法流程所示:
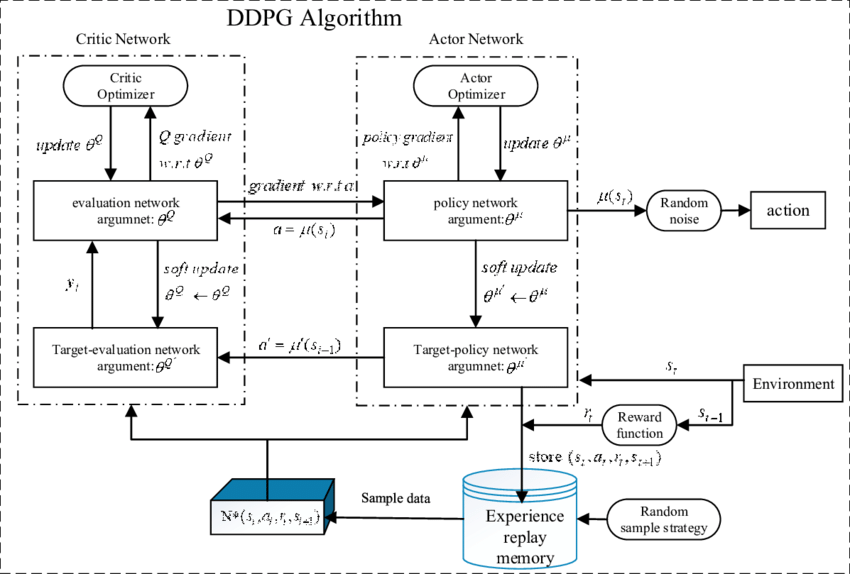
- 基于当前输入状态 s t s_t st,将其输入至
actor_target网络得到当前动作 a t a_t at,然后将 s t , a t s_t,a_t st,at一起输入至critic_target网络得到 Q t a r g Q_{targ} Qtarg的值,基于这个 Q t a r g Q_{targ} Qtarg和将从容器中采样得到的数据计算的 Q Q Q函数对critic网络做梯度回传,权重更新; - 将当前状态 s t s_t st,以及送入
actor生成的 a t a_t at一起送入critic网络得到 Q Q Q函数,利用改Q函数的值对actor网络做梯度回传,权重更新。
DDPG算法的伪代码如下:

实际代码编写:
代码如下,全部代码亦可见model.py。
# 是否使用GPU
device = paddle.get_device()
# 动作网络:输出连续的动作信号
class Actor(nn.Layer):
def __init__(self, state_dim, action_dim, max_action):
super(Actor, self).__init__()
self.l1 = nn.Linear(state_dim, 400)
self.l2 = nn.Linear(400, 300)
self.l3 = nn.Linear(300, action_dim)
self.max_action = max_action
def forward(self, state):
a = F.relu(self.l1(state))
a = F.relu(self.l2(a))
# 输出层激活函数采用tanh,将输出映射至[-1,1]
return F.tanh(self.l3(a))
# 值函数网络:评价一个动作的价值
class Critic(nn.Layer):
def __init__(self, state_dim, action_dim):
super(Critic, self).__init__()
self.l1 = nn.Linear(state_dim + action_dim, 400)
self.l2 = nn.Linear(400, 300)
self.l3 = nn.Linear(300, 1)
def forward(self, state, action):
q = F.relu(self.l1(paddle.concat([state, action], 1)))
q = F.relu(self.l2(q))
return self.l3(q)
# DDPG算法模型
class DDPGModel(object):
def __init__(self, state_dim, action_dim, max_action, gamma = 0.99, tau = 0.001):
# 动作网络与目标动作网络
self.actor = Actor(state_dim, action_dim, max_action)
self.actor_target = copy.deepcopy(self.actor)
self.actor_optimizer = optim.Adam(parameters=self.actor.parameters(), learning_rate=1e-4)
# 值函数网络与目标值函数网络
self.critic = Critic(state_dim, action_dim)
self.critic_target = copy.deepcopy(self.critic)
self.critic_optimizer = optim.Adam(parameters=self.critic.parameters(), weight_decay=1e-2)
self.gamma = gamma
self.tau = tau
# 根据当前状态,选择动作:过一个动作网络得到动作
def select_action(self, state):
state = paddle.to_tensor(state.reshape(1, -1), dtype='float32', place=device)
return self.actor(state).numpy().flatten()
# 训练函数
def train(self, replay_buffer, batch=64):
# 从缓存容器中采样
state, action, next_state, reward, done = replay_buffer.sample(batch)
# 计算目标网络q值
q_target = self.critic_target(next_state, self.actor_target(next_state))
q_target = reward + ((1- done) * self.gamma * q_target).detach()
# 计算当前网络q值
q_eval = self.critic(state, action)
# 计算值网络的损失函数
critic_loss = F.mse_loss(q_eval, q_target)
# print(critic_loss)
# 梯度回传,优化网络参数
self.critic_optimizer.clear_grad()
critic_loss.backward()
self.critic_optimizer.step()
# 计算动作网络的损失函数
actor_loss = -self.critic(state, self.actor(state)).mean()
# print(actor_loss)
# 梯度回传,优化网络参数
self.actor_optimizer.clear_grad()
actor_loss.backward()
self.actor_optimizer.step()
# 更新目标网络参数
for param, target_param in zip(self.critic.parameters(), self.critic_target.parameters()):
target_param.set_value(target_param * (1.0 - self.tau) + param * self.tau)
for param, target_param in zip(self.actor.parameters(), self.actor_target.parameters()):
target_param.set_value(target_param * (1.0 - self.tau) + param * self.tau)
# 保存模型参数
def save(self, filename):
paddle.save(self.critic.state_dict(), filename + '_critic')
paddle.save(self.critic_optimizer.state_dict(), filename + '_critic_optimizer')
paddle.save(self.actor.state_dict(), filename + '_actor')
paddle.save(self.actor_optimizer.state_dict(), filename + '_actor_optimizer')
# 导入模型参数
def load(self, filename):
self.critic.set_state_dict(paddle.load(filename + '_critic'))
self.critic_optimizer.set_state_dict(paddle.load(filename + '_critic_optimizer'))
self.critic_target = copy.deepcopy(self.critic)
self.actor.set_state_dict(paddle.load(filename + '_actor'))
self.actor_optimizer.set_state_dict(paddle.load(filename + '_actor_optimizer'))
self.actor_target = copy.deepcopy(self.actor)
网络actor以状态作为输入。网络输出层采用tanh函数作为激活函数,因此是一个关于动作信号的连续值。
网络critic以状态和动作作为输入,输出为单值Q函数。
在DDPGModel中,定义了4个网络,其主要函数接口为train(),在此,即实现了上述的算法过程,读者可以参考流程图解释和伪代码,亦可参考代码中的注释。
3.4训练配置
训练配置的具体流程为:
- 设置超参数;
- 实例化股票交易环境(StockEnv);
- 实例化DDPG模型
- 实例化容器(ReplayBuffer)模型
代码如下,详细代码亦可见train.py。
# 获得数据
df = pd.read_csv('data/data102715/train.csv')
# df = df.sort_values('date')
# 默认的超参数
seed = 123 # 随机种子
batch = 64 # 批量大小
gamma = 0.95 # 折扣因子
tau = 0.005 # 当前网络参数比例,用于更新目标网络
timesteps = 2e4 # 训练步数
expl_noise = 0.1 # 高斯噪声
eval_freq = 2e3 # 评估模型的频率
# 根据数据集设置环境
env = StockEnv.StockTradingEnv(df)
# 设置随机种子
env.seed(seed)
paddle.seed(seed)
np.random.seed(seed)
# T得到环境的参数信息(如:状态和动作的维度)
state_dim = env.observation_space.shape[0]
action_dim = env.action_space.shape[0]
max_action = float(env.action_space.high[1])
print(state_dim, action_dim, max_action)
kwarg = {
'state_dim': state_dim,
'action_dim': action_dim,
"max_action": max_action,
'gamma': gamma,
'tau': tau
}
# 设置模型:DDPG算法
policy = model.DDPGModel(**kwarg)
# 设置缓存容器
replay_buffer = ReplayBuffer.SimpleReplayBuffer(state_dim, action_dim)
19 2 1.0
W0118 02:02:59.583389 2899 device_context.cc:404] Please NOTE: device: 0, GPU Compute Capability: 7.0, Driver API Version: 10.1, Runtime API Version: 10.1
W0118 02:02:59.587522 2899 device_context.cc:422] device: 0, cuDNN Version: 7.6.
3.5模型训练
在本项目中,我们使用自制的继承自gym.env的环境。gym是强化学习中的经典环境库,用于研究和开发强化学习相关算法的仿真平台。其具体的API如图8所示。
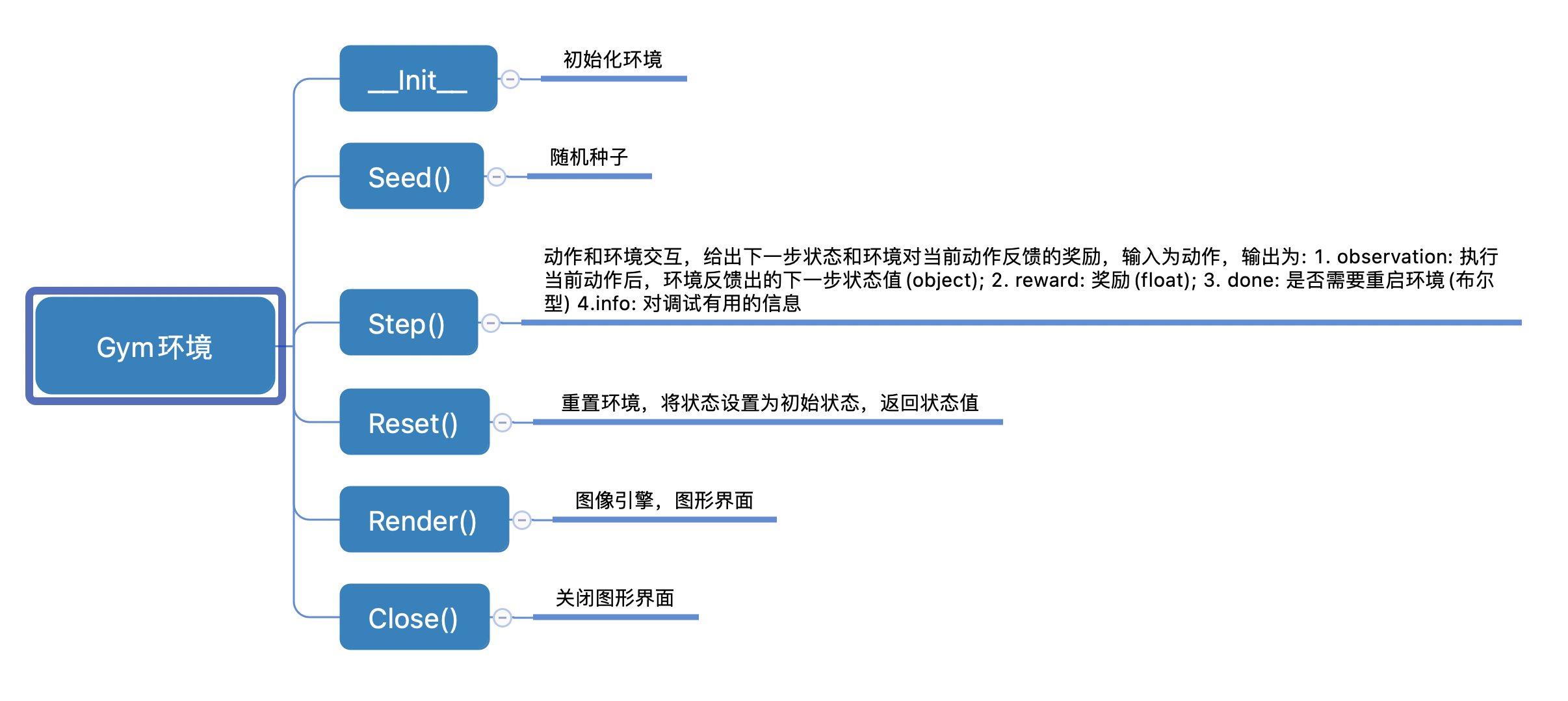
模型训练的具体步骤如下:
- 初始化环境;
- 在未触发终止条件的情况下:
- 根据当前状态,输入至DDPG模型
select_action()函数,获得一个动作; - 动作与环境交互,并给出交互后新的环境状态,针对当前action的reward和是否触发终止条件done;
- 将
state, action, reward, next_state, done作为一条经验,存入经验池中; - 如果经验池中存储的经验数量超过
batch_size且该step为训练step,则:从经验池中随机选取一个batch_size的经验,作为数据输入训练模型;
- 根据当前状态,输入至DDPG模型
- 触发终止条件,一个episode结束,获得整个episode的total_reward。
3.6模型估计
模型评估的具体步骤为:
-
初始化环境
-
在未触发终止条件的情况下:
-
根据当前状态,代入DDPG的
select_action得到动作action,作为预测的动作; -
动作和环境交互,给出交互后新的环境状态,针对当前action的reward和是否触发终止条件done;
-
触发终止条件,一个episode结束,获得整个episode的total_reward.
-
-
十个episode结束,获得total_reward的平均值。
代码如下,详细代码亦可见train.py。
# 评估模型
def eval_policy(iteration, policy, df, seed, eval_episodes=3):
# 创建评估环境,并设置随机种子
eval_env = StockEnv.StockTradingEnv(df)
avg_reward = 0.
for epi in range(eval_episodes):
# 初始化环境
eval_env.seed(seed + (epi + 1)* 123)
state, done = eval_env.reset(), False
# 与环境交互
while not done:
action = policy.select_action(state)
# TODO: step with env
action[0] *= 3
state, reward, done, _ = eval_env.step(action)
avg_reward += reward
# 计算平均奖励
avg_reward /= eval_episodes
print(f'Evaluator: After {iteration} iterations, the average reward is: {avg_reward:.3f} over {eval_episodes} episodes.')
return avg_reward
# 评估初始环境:对照
evaluations = [eval_policy(0, policy, df, seed)]
# 初始化环境
state, done = env.reset(), False
episode_reward = 0
episode_timesteps = 0
episode_num = 0
# 与环境交互
for t in range(int(timesteps)):
episode_timesteps += 1
# 根据状态得到动作
action = (
policy.select_action(np.array(state))
+ np.random.normal(0, max_action * expl_noise, size=action_dim)
).clip(-max_action, max_action)
action[0] *= 3
# 在环境中执行动作
next_state, reward, done, _ = env.step(action)
# 将交互数据存入容器
replay_buffer.add(state, action, next_state, reward, done)
# 状态更新
state = next_state
episode_reward += reward
# 算法训练
policy.train(replay_buffer, batch)
# 该轮交互结束
if done:
# 打印信息,重置状态
# Reset environment
state, done = env.reset(), False
episode_reward = 0
episode_timesteps = 0
episode_num += 1
# 评估算法表现
if (t + 1) % eval_freq == 0:
evaluations.append(eval_policy(t+1, policy, df, seed))
Evaluator: After 0 iterations, the average reward is: -345585.864 over 3 episodes.
Evaluator: After 2000 iterations, the average reward is: 6728.547 over 3 episodes.
Evaluator: After 4000 iterations, the average reward is: 6728.547 over 3 episodes.
Evaluator: After 6000 iterations, the average reward is: 6728.547 over 3 episodes.
Evaluator: After 8000 iterations, the average reward is: 6728.547 over 3 episodes.
Evaluator: After 10000 iterations, the average reward is: 6728.547 over 3 episodes.
Evaluator: After 12000 iterations, the average reward is: -345612.789 over 3 episodes.
Evaluator: After 14000 iterations, the average reward is: 5125.000 over 3 episodes.
Evaluator: After 16000 iterations, the average reward is: 6728.547 over 3 episodes.
Evaluator: After 18000 iterations, the average reward is: 6728.547 over 3 episodes.
Evaluator: After 20000 iterations, the average reward is: 6728.547 over 3 episodes.
3.7模型测试
首先,定义测试集环境,然后,估计模型在测试环境的表现即可,代码如下,详细代码亦可见test.py。
# 导入数据
df = pd.read_csv('data/data102715/test.csv')
# 测试环境使用的随机种子
eval_seed = [53, 47, 99, 107, 1, 17, 57, 97, 179, 777]
# 评估模型的函数
def eval_policy(policy, df, seed, eval_episodes=10):
avg_reward = 0.
for epi in range(eval_episodes):
# 初始化评估环境并设定随机种子
eval_env = StockEnv.StockTradingEnv(df)
eval_env.seed(seed + eval_seed[epi])
# 初始化评估环境
state, done = eval_env.reset(), False
t = 0
epi_reward = 0
# 模型与环境交互
while not done:
action = policy.select_action(state)
action[0] *=3
state, reward, done, _ = eval_env.step(action)
t += 1
epi_reward += reward
avg_reward += reward
# 计算得到平均奖励
avg_reward /= eval_episodes
print(f'Evaluator: The average reward is : {avg_reward:.3f} over {eval_episodes} episodes.')
return avg_reward
# 默认的超参数
seed = 123
# 初始化一个例子环境,用于得到环境的属性信息,例如:状态和动作的维度
env = StockEnv.StockTradingEnv(df)
state_dim = env.observation_space.shape[0]
action_dim = env.action_space.shape[0]
max_action = float(env.action_space.high[1])
kwarg = {
'state_dim': state_dim,
'action_dim': action_dim,
"max_action": max_action,
}
# 沿用上面训好的DDPG策略
policy = policy
# 做评估
evaluations = [eval_policy(policy, df, seed)]
Evaluator: The average reward is : 8141.820 over 10 episodes.
4. 项目代码运行
4.1 训练
默认情况,打开终端执行以下的命令即可,参数save_model表示存储训练好的模型和优化器参数。
python train.py --save_model
m = env.observation_space.shape[0]
action_dim = env.action_space.shape[0]
max_action = float(env.action_space.high[1])
kwarg = {
'state_dim': state_dim,
'action_dim': action_dim,
"max_action": max_action,
}
# 沿用上面训好的DDPG策略
policy = policy
# 做评估
evaluations = [eval_policy(policy, df, seed)]
Evaluator: The average reward is : 8141.820 over 10 episodes.
4. 项目代码运行
4.1 训练
默认情况,打开终端执行以下的命令即可,参数save_model表示存储训练好的模型和优化器参数。
python train.py --save_model
也可以手动修改参数,自定义训练。
下面的例子为设定随机种子为1118,批量大小为128。
python train.py --save_model --seed 1118 --batch_size 128
4.2 测试
直接运行以下命令即可。
python test.py
4.3 模型部署
模型基于飞桨框架实现,具体部署过程可以参考飞桨官方文档的推理部署教程
5.项目总结
本项目为大家详细介绍了如何建模股票环境环境,并用强化学习算法求解。其中也详细解释强化学习的基础要素(如:环境、状态、动作、奖励等)在本项目中的对应关系。同时,也为大家清晰的讲解了DDPG算法的由来、解决了什么痛点、创新点是什么,以及最主要的,DDPG算法的具体流程与案例应用。
6.更多PaddleEdu信息内容
1. PaddleEdu一站式深度学习在线百科awesome-DeepLearning中还有其他的能力,大家可以敬请期待:
- 深度学习入门课
- 深度学习百问

- 特色课

- 产业实践
PaddleEdu使用过程中有任何问题欢迎在awesome-DeepLearning提issue,同时更多深度学习资料请参阅飞桨深度学习平台。
记得点个Star⭐收藏噢~~

2. 飞桨PaddleEdu技术交流群(QQ)
目前QQ群已有2000+同学一起学习,欢迎扫码加入

学大模型,用大模型上飞桨星河社区!每天8点V100G算力免费领!免费领取ERNIE 4.0 100w Token >>>
更多推荐



 3
3 0
0- 0



 已为社区贡献1436条内容
已为社区贡献1436条内容

所有评论(0)