
模型压缩之知识蒸馏
你想让你小模型在满足部署的前提下,进一步提升精度嘛,走过路过不要错过,手把手教你实现模型压缩中的知识蒸馏操作。
·
模型压缩之知识蒸馏(cv领域)
- 之前想学模型压缩的一些方法,发现大都是基于套件去实现的,本着“实践是检验真理的唯一标准”的原则,只好自己去实现一下。

0 背景和项目介绍
0.1 背景
- 现在的深度学习模型越来越大。在线下处理数据,对时间要求不高的话,还能接受,能跑完就好。但是线上运行,对延迟要求高的话,大模型的就很难满足要求。因此,就找了找模型压缩的方法。
- 本项目采用的是蒸馏模型,迁移学习(GPT–ELMO–Bert–XLNET–ERNIE,这些都是迁移学习模型的应用),通过采用预先训练好的负载模型(Teacher model)的输出作为监督信号去训练另一个简单的网络,这个简单的网络被称为student model。
0.2 项目介绍
- 1 本项目流程
- (1)先由Softmax、log_softmax、NLLLoss引出CrossEntropy。CrossEntropy(交叉熵损失)等价于log_softmax 结合 nll_loss
- (2)介绍知识蒸馏的原理,以及关键公式
- (3)开始进行实验操作,考虑到运行时间的关系,使用的是MNIST这种小数据集,为了方便区分不同网络,代码略微些许冗余,所以不要被项目长度所吓到。看完第一个网络,后面的就豁然开朗了。其中关键点也给出了相应的提示,需要注意。
- (4)对比实验结果,得出详细的实验结论
- 2 下图为实验的结果图
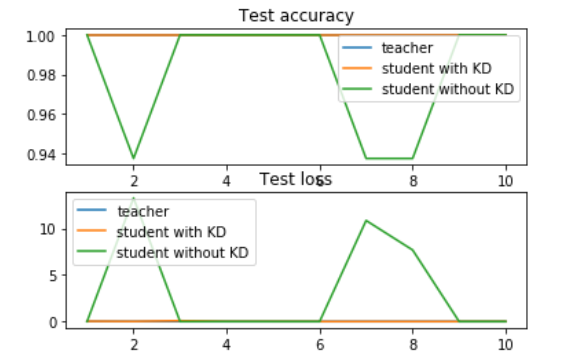
10轮次中,with KD(应用知识蒸馏)的loss、acc相对稳定,反观without KD的loss、acc呈现‘跌宕起伏’的状态,后面会有更详细的实验表格数据
1 ‘亿’点点前馈知识
1.1 Softmax(x)
- 函数Softmax(x): 输入一个实数向量并返回一个概率分布。定义 x 是一个实数的向量(正数或负数都可以)。 然后, 第i个 Softmax(x) 的计算方式为:
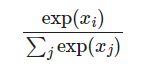
- 输出是一个概率分布: 每个元素都是非负的, 并且所有元素的总和都是1
import paddle
import paddle.nn.functional as F
# 设置全局默认generator的随机种子。
paddle.seed(0)
- 在图片分类问题中,输入m张图片,输出一个[m,N]的Tensor,其中N 是分类类别总数。比如输入2张图片,分三类,最后的输出是一个[2,3]的Tensor,举个例子:
output = paddle.randn([2, 3])
print(output)
- 第1,2行分别是第1,2张图片的结果,假设第123列分别是猫、狗、兔的分类得分。
- 可以看出模型认为两张分别为兔、狗。 然后对每一行使用Softmax,这样可以得到每张图片的概率分布。
# 这里axis的意思是计算Softmax的维度,这里设置axis=1,可以看到每一行的加和为1。
print(F.softmax(output, axis=1))
1.2 log_softmax
- 这个很好理解,其实就是对softmax处理之后的结果执行一次对数运算。
- 可以理解为 log(softmax(output))
# 对比下列输出方式,发现输出结果是一致的
print(F.log_softmax(output, axis=1))
print(paddle.log(F.softmax(output, axis=1)))
1.3 NLLLoss
- 该函数的全称是negative log likelihood loss. 若 x i = [ q 1 , q 2 , . . . , q N ] x_i=[q_1, q_2, ..., q_N] xi=[q1,q2,...,qN] 为神经网络对第i个样本的输出值, y i y_i yi为真实标签。则:
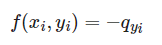
- 输入:log_softmax(output), target
# x样本
X_sample = paddle.to_tensor([[-1.2, -2, -3]], "float32")
print(X_sample)
# y标签
Y_label = paddle.to_tensor([0], "int64")
print(Y_label)
# nll_loss
print(F.nll_loss(X_sample, Y_label))
# 结合 log_softmax 和 nll_loss一起用
output = paddle.to_tensor([[1.2, 2, 3]], "float32")
target = paddle.to_tensor([0], "int64")
log_sm_output = F.log_softmax(output, axis=1)
print('Output is [1.2, 2, 3]. If the target is 0, loss is:', F.nll_loss(log_sm_output, target))
target = paddle.to_tensor([1])
log_sm_output = F.log_softmax(output, axis=1)
print('Output is [1.2, 2, 3]. If the target is 1, loss is:', F.nll_loss(log_sm_output, target))
target = paddle.to_tensor([2])
log_sm_output = F.log_softmax(output, axis=1)
print('Output is [1.2, 2, 3]. If the target is 2, loss is:', F.nll_loss(log_sm_output, target))
1.4在分类问题中,CrossEntropy(交叉熵损失)等价于log_softmax 结合 nll_loss
- N N N分类问题,对于一个特定的样本,已知其真实标签,CrossEntropy的计算公式为:
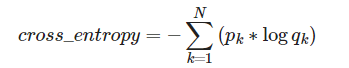
- 其中p表示真实值,在这个公式中是one-hot形式;q是经过softmax计算后的结果, q k q_k qk为神经网络认为该样本为第 k k k类的概率。
- 仔细观察可以知道,因为p的元素不是0就是1,而且又是乘法,所以很自然地我们如果知道1所对应的index,那么就不用做其他无意义的运算了。所以在代码中target不是以one-hot形式表示的,而是直接用scalar表示。若该样本的真实标签为 y y y,则交叉熵的公式可变形为:
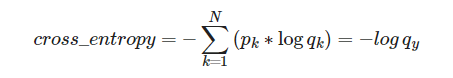
output = paddle.to_tensor([[1.2, 2, 3]], "float32")
target = paddle.to_tensor([0], "int64")
log_sm_output = F.log_softmax(output, axis=1)
nll_loss_of_log_sm_output = F.nll_loss(log_sm_output, target)
print(nll_loss_of_log_sm_output)
ce_loss = F.cross_entropy(output, target)
print(ce_loss)
1.5 More about softmax
- 关于标签平滑操作,结合softmax公式,对比下面程序结果,通过‘t’来调节标签之间的差别
import numpy as np
def softmax(x):
x_exp = np.exp(x)
return x_exp / np.sum(x_exp)
output = np.array([0.1, 1.6, 3.6])
print(softmax(output))
[0.02590865 0.11611453 0.85797681]
def softmax_t(x, t):
x_exp = np.exp(x / t)
return x_exp / np.sum(x_exp)
output = np.array([0.1, 1.6, 3.6])
print(softmax_t(output, 5))
[0.22916797 0.3093444 0.46148762]
print(softmax_t(output, 10000))
[0.33327778 0.33332777 0.33339445]
2 知识蒸馏理论
- 理论源自PaddleEdu官方大佬的项目深度学习中的模型压缩概述与知识蒸馏详解
- (声明一下,我搬理论不是我懒昂)
- 2014年,Geoffrey Hinton在 Distilling the Knowledge in a Neural Network 中提出知识蒸馏(KD)概念:把从一个复杂的大模型(Teacher Network)上学习到的知识迁移到另一个更适合部署的小模型上(Student Network),叫知识蒸馏。
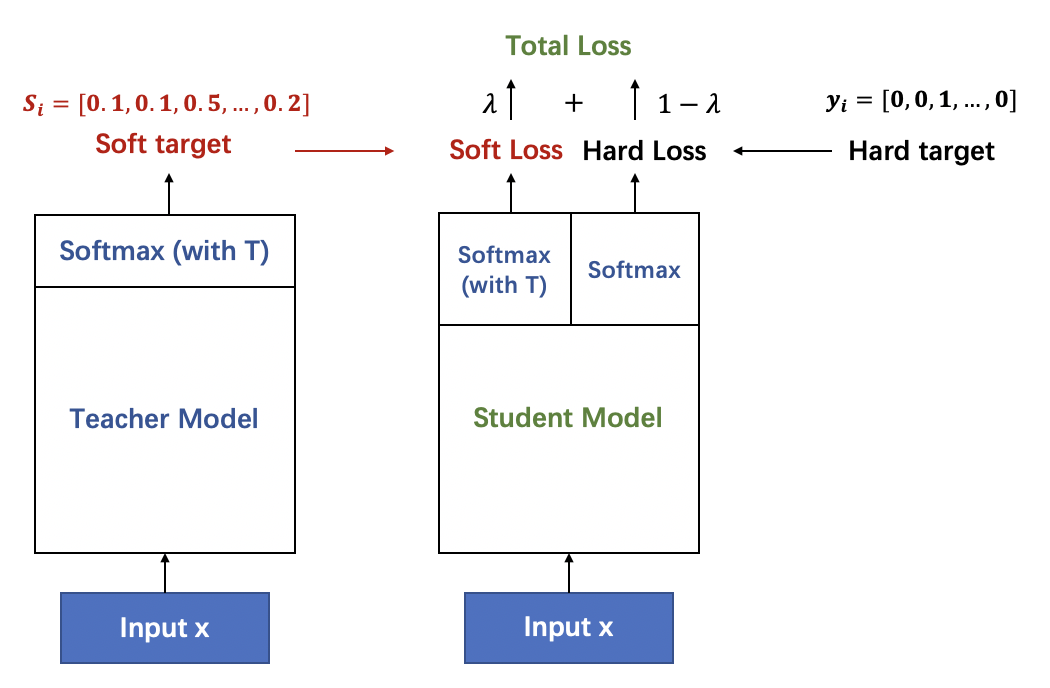
- 1 如上图所示,左边的教师网络是一个复杂的大模型,以它带有温度参数T的softmax输出作为软目标作为学生网络学习的软目标。
- T就是上面1.5提到介绍用来做标签平滑的
- 2 学生网络在学习时,也通过带有温度参数T的softmax进行概率分布预测,与软目标计算soft loss。
- 3 同时,也通过正常的训练流程获得预测的样本类别与真实的样本类别计算hard loss。
- 4 最终根据 γ∗softloss+(1−γ)∗hardloss作为损失函数来训练学生网络。
- 这个公式就是知识蒸馏的核心理论,后面还会提到(有些理论结合一下下面的实践更通透)
3 知识蒸馏实践
3.1 先训练老师网络
# 导入所需包
import math
import paddle
import paddle.nn as nn
import paddle.nn.functional as F
from paddle.vision import datasets, transforms
import paddle.utils
# 定义老师网络结构,没有用太复杂的网络(不是我懒昂)
# Conv2D(输入通道,输出通道,卷积核大小,步长)
class TeacherNet(nn.Layer):
def __init__(self):
super(TeacherNet, self).__init__()
self.conv1 = nn.Conv2D(in_channels=3, out_channels=32, kernel_size=3, stride=1)
self.bn1 = nn.BatchNorm2D(32)
self.relu = nn.ReLU()
self.conv2 = nn.Conv2D(in_channels=32, out_channels=64, kernel_size=3, stride=1)
self.bn2 = nn.BatchNorm2D(64)
self.dropout1 = nn.Dropout2D(0.3)
self.dropout2 = nn.Dropout(0.5)
self.fc1 = nn.Linear(9216,128)
self.fc2 = nn.Linear(128,10)
def forward(self, x):
x = self.conv1(x)
x = self.bn1(x)
x = self.relu(x)
x = self.conv2(x)
x = self.bn2(x)
x = self.relu(x)
x = F.max_pool2d(x, 2)
x = self.dropout1(x)
x = paddle.flatten(x, 1)
x = self.fc1(x)
x = self.relu(x)
x = self.dropout2(x)
x = self.fc2(x)
return x
# 打印输出网络结构
teacher_Net = TeacherNet()
paddle.summary(teacher_Net,(1, 3, 28, 28))
# 导入数据加载的包
from paddle.io import Dataset
from paddle.io import DataLoader
from paddle.vision import datasets
from paddle.vision import transforms
# 图像转tensor操作,也可以加一些数据增强的方式,例如旋转、模糊等等
# 数据增强的方式要加在Compose([ ])中
def get_transforms(mode='train'):
if mode == 'train':
data_transforms = transforms.Compose([
transforms.ToTensor(),
transforms.Normalize(mean=[0.4914, 0.4822, 0.4465], std=[0.2023, 0.1994, 0.2010])])
else:
data_transforms = transforms.Compose([
transforms.ToTensor(),
transforms.Normalize(mean=[0.4914, 0.4822, 0.4465], std=[0.2023, 0.1994, 0.2010])])
return data_transforms
# 获取官方MNIST数据集
def get_dataset(name='MNIST', mode='train'):
if name == 'MNIST':
dataset = datasets.MNIST(mode=mode, transform=get_transforms(mode))
return dataset
# 定义数据加载到模型形式
def get_dataloader(dataset, batch_size=128, mode='train'):
dataloader = DataLoader(dataset, batch_size=batch_size, num_workers=2, shuffle=(mode == 'train'))
return dataloader
# 初始化函数,用于模型初始化
class AverageMeter():
""" Meter for monitoring losses"""
def __init__(self):
self.avg = 0
self.sum = 0
self.cnt = 0
self.reset()
def reset(self):
"""reset all values to zeros"""
self.avg = 0
self.sum = 0
self.cnt = 0
def update(self, val, n=1):
"""update avg by val and n, where val is the avg of n values"""
self.sum += val * n
self.cnt += n
self.avg = self.sum / self.cnt
# 定义老师网络训练
def teacher_train_one_epoch(model, dataloader, criterion, optimizer, epoch, total_epoch, report_freq=20):
print(f'----- Training Epoch [{epoch}/{total_epoch}]:')
loss_meter = AverageMeter()
acc_meter = AverageMeter()
model.train()
for batch_idx, data in enumerate(dataloader):
image = data[0]
label = data[1]
out = model(image)
loss = criterion(out, label)
loss.backward()
optimizer.step()
optimizer.clear_grad()
pred = nn.functional.softmax(out, axis=1)
acc1 = paddle.metric.accuracy(pred, label)
batch_size = image.shape[0]
loss_meter.update(loss.cpu().numpy()[0], batch_size)
acc_meter.update(acc1.cpu().numpy()[0], batch_size)
if batch_idx > 0 and batch_idx % report_freq == 0:
print(f'----- Batch[{batch_idx}/{len(dataloader)}], Loss: {loss_meter.avg:.5}, Acc@1: {acc_meter.avg:.4}')
print(f'----- Epoch[{epoch}/{total_epoch}], Loss: {loss_meter.avg:.5}, Acc@1: {acc_meter.avg:.4}')
return loss,acc1
# 定义老师网络预测
def teacher_validate(model, dataloader, criterion, report_freq=10):
print('----- Validation')
loss_meter = AverageMeter()
acc_meter = AverageMeter()
model.eval()
for batch_idx, data in enumerate(dataloader):
image = data[0]
label = data[1]
out = model(image)
loss = criterion(out, label)
pred = paddle.nn.functional.softmax(out, axis=1)
acc1 = paddle.metric.accuracy(pred, label)
batch_size = image.shape[0]
loss_meter.update(loss.cpu().numpy()[0], batch_size)
acc_meter.update(acc1.cpu().numpy()[0], batch_size)
if batch_idx > 0 and batch_idx % report_freq == 0:
print(f'----- Batch [{batch_idx}/{len(dataloader)}], Loss: {loss_meter.avg:.5}, Acc@1: {acc_meter.avg:.4}')
print(f'----- Validation Loss: {loss_meter.avg:.5}, Acc@1: {acc_meter.avg:.4}')
return loss,acc1
# 老师网络主函数
def teacher_main():
total_epoch = 10
batch_size = 256
model = TeacherNet()
train_dataset = get_dataset(mode='train')
train_dataloader = get_dataloader(train_dataset, batch_size, mode='train')
val_dataset = get_dataset(mode='test')
val_dataloader = get_dataloader(val_dataset, batch_size, mode='test')
criterion = nn.CrossEntropyLoss()
scheduler = paddle.optimizer.lr.CosineAnnealingDecay(0.02, total_epoch)
optimizer = paddle.optimizer.Momentum(learning_rate=scheduler,
parameters=model.parameters(),
momentum=0.9,
weight_decay=5e-4)
eval_mode = False
if eval_mode:
state_dict = paddle.load('./teacher_ep200.pdparams')
model.set_state_dict(state_dict)
teacher_validate(model, val_dataloader, criterion)
return
teacher_history_train = []
teacher_history_vali = []
save_freq = 5
test_freq = 1
for epoch in range(1, total_epoch+1):
loss_train,acc1_train = teacher_train_one_epoch(model, train_dataloader, criterion, optimizer, epoch, total_epoch)
scheduler.step()
teacher_history_train.append((loss_train, acc1_train))
if epoch % test_freq == 0 or epoch == total_epoch:
loss_vali,acc1_vali = teacher_validate(model, val_dataloader, criterion)
teacher_history_vali.append((loss_vali, acc1_vali))
if epoch % save_freq == 0 or epoch == total_epoch:
paddle.save(model.state_dict(), f'./teacher_ep{epoch}.pdparams')
paddle.save(optimizer.state_dict(), f'./teacher_ep{epoch}.pdopts')
return model, teacher_history_train, teacher_history_vali
# 返回值分别是网络模型、训练时的loss和acc、预测时的loss和acc
teacher_model,teacher_history_train,teacher_history_vali = teacher_main()
3.2 看一下老师网络的隐藏知识
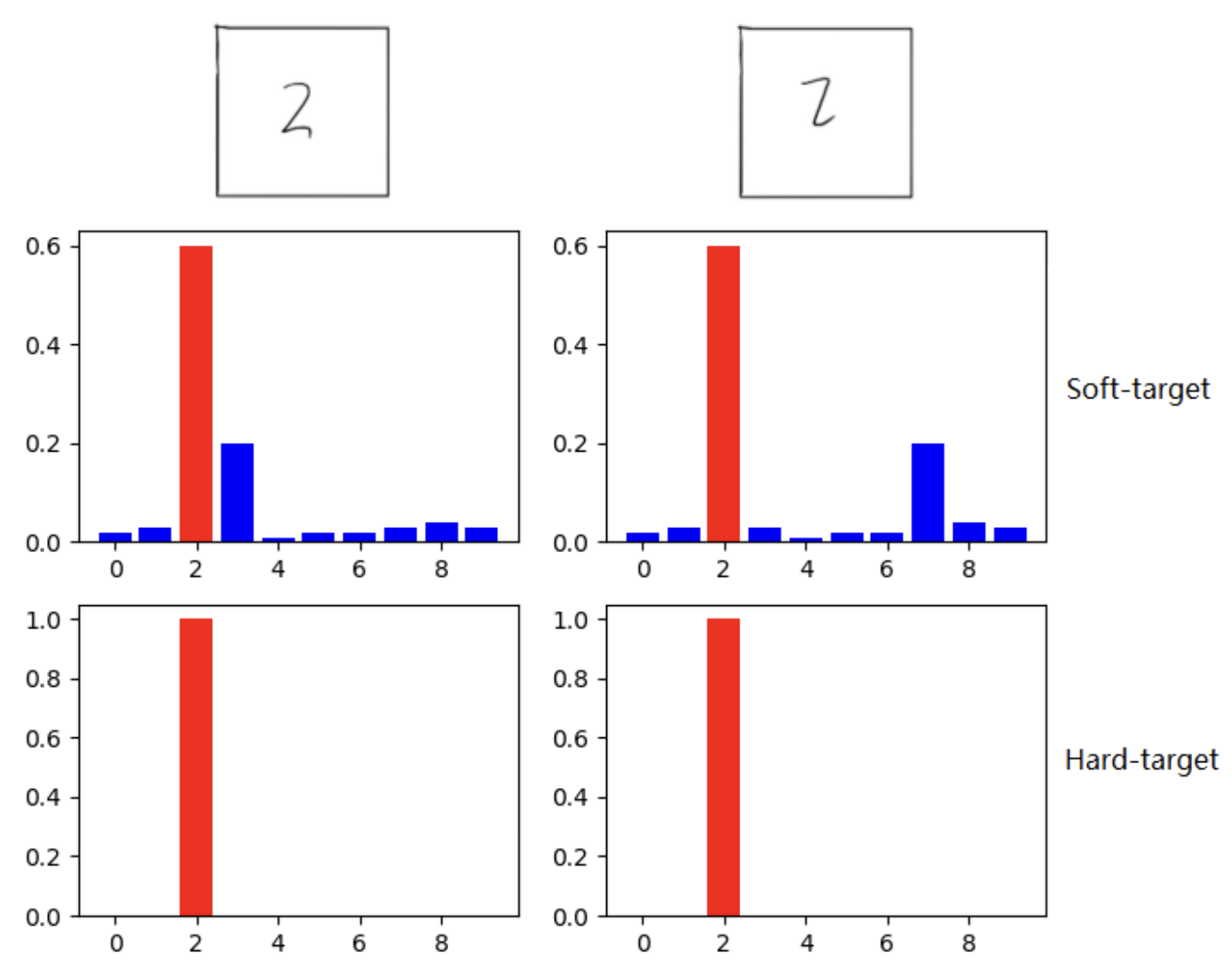
- 举个例子,如上图所示,在用MNIST数据集做手写数字识别任务时,某个输入的“2”更加类似“3”,则softmax的输出值中“3”对应的概率应该要比其他负标签类别高;
- 而另一个“2”更类似于“7”,则这个这个样本的softmax输出值中“7”对应的概率应该比其他负标签类别高。
- 这两个“2”对应的hard target是相同的,但是他们的soft target是不同的,soft target内蕴含着更多的信息。
= 下面程序给大家展示一下这几条理论
import numpy as np
from matplotlib import pyplot as plt
def softmax_t(x, t):
x_exp = np.exp(x / t)
return x_exp / np.sum(x_exp)
# 通过刚刚定义的数据集加载函数,加载数据集
val_dataset_plt = get_dataset(mode='test')
val_dataloader_plt = get_dataloader(val_dataset_plt, batch_size=1, mode='test')
# 这段代码可多次执行看看效果
teacher_model.eval()
with paddle.no_grad():
data, target = next(iter(val_dataloader_plt))
output = teacher_model(data)
test_x = data.cpu().numpy()
y_out = output.cpu().numpy()
y_out = y_out[0, ::]
print('Output (NO softmax):', y_out)
plt.subplot(3, 1, 1)
plt.imshow(test_x[0, 0, ::])
plt.subplot(3, 1, 2)
plt.bar(list(range(10)), softmax_t(y_out, 1), width=0.3)
plt.subplot(3, 1, 3)
plt.bar(list(range(10)), softmax_t(y_out, 10), width=0.3)
plt.show()
3.3 让老师教学生网络
- 关键点,定义kd的loss
# 定义学生网络,一个卷积、一个全连接、没用BN,比老师网络更简单
class StudentNet(nn.Layer):
def __init__(self):
super(StudentNet, self).__init__()
self.conv1 = nn.Conv2D(in_channels=3, out_channels=32, kernel_size=5, stride=1)
self.relu = nn.ReLU()
self.fc1 = nn.Linear(18432, 10)
def forward(self, x):
x = self.conv1(x)
x = self.relu(x)
x = paddle.flatten(x, 1)
x = self.fc1(x)
output = x
return output
# 打印网络结构
student_Net = StudentNet()
paddle.summary(student_Net,(1, 3, 28, 28))
# !!!!!!!!!!这个就是最为关键的地方
# γ∗softloss+(1−γ)∗hardloss
# temp就是上面T,标签平滑
# alpha就是γ
# KLDivLoss计算输入(Input)和输入(Label)之间的Kullback-Leibler散度损失。注意其中输入(Input)应为对数概率值,输入(Label)应为概率值。
def distillation(y, labels, teacher_scores, temp, alpha):
return nn.KLDivLoss()(F.log_softmax(y / temp, axis=1), F.softmax(teacher_scores / temp, axis=1)) * (
temp * temp * 2.0 * alpha) + F.cross_entropy(y, labels) * (1. - alpha)
# 定义学生训练网络(有老师教)
def student_train_one_epoch(model, dataloader, criterion, optimizer, epoch, total_epoch, report_freq=20):
print(f'----- Training Epoch [{epoch}/{total_epoch}]:')
loss_meter = AverageMeter()
acc_meter = AverageMeter()
model.train()
for batch_idx, data in enumerate(dataloader):
image = data[0]
label = data[1]
out = model(image)
# 下面3行是主要区别
teacher_output = teacher_model(image)
teacher_output = teacher_output.detach() # 切断老师网络的反向传播
loss = distillation(out, label, teacher_output, temp=5.0, alpha=0.7)
loss.backward()
optimizer.step()
optimizer.clear_grad()
pred = nn.functional.softmax(out, axis=1)
acc1 = paddle.metric.accuracy(pred, label)
batch_size = image.shape[0]
loss_meter.update(loss.cpu().numpy()[0], batch_size)
acc_meter.update(acc1.cpu().numpy()[0], batch_size)
if batch_idx > 0 and batch_idx % report_freq == 0:
print(f'----- Batch[{batch_idx}/{len(dataloader)}], Loss: {loss_meter.avg:.5}, Acc@1: {acc_meter.avg:.4}')
print(f'----- Epoch[{epoch}/{total_epoch}], Loss: {loss_meter.avg:.5}, Acc@1: {acc_meter.avg:.4}')
return loss,acc1
# 定义学生预测网络(有老师教)
def student_validate(model, dataloader, criterion, report_freq=10):
print('----- Validation')
loss_meter = AverageMeter()
acc_meter = AverageMeter()
model.eval()
for batch_idx, data in enumerate(dataloader):
image = data[0]
label = data[1]
out = model(image)
loss = criterion(out, label)
pred = paddle.nn.functional.softmax(out, axis=1)
acc1 = paddle.metric.accuracy(pred, label)
batch_size = image.shape[0]
loss_meter.update(loss.cpu().numpy()[0], batch_size)
acc_meter.update(acc1.cpu().numpy()[0], batch_size)
if batch_idx > 0 and batch_idx % report_freq == 0:
print(f'----- Batch [{batch_idx}/{len(dataloader)}], Loss: {loss_meter.avg:.5}, Acc@1: {acc_meter.avg:.4}')
print(f'----- Validation Loss: {loss_meter.avg:.5}, Acc@1: {acc_meter.avg:.4}')
return loss,acc1
# 定义学生网络主函数(有老师教)
def student_main():
total_epoch = 10
batch_size = 256
model = StudentNet()
train_dataset = get_dataset(mode='train')
train_dataloader = get_dataloader(train_dataset, batch_size, mode='train')
val_dataset = get_dataset(mode='test')
val_dataloader = get_dataloader(val_dataset, batch_size, mode='test')
criterion = nn.CrossEntropyLoss()
scheduler = paddle.optimizer.lr.CosineAnnealingDecay(0.02, total_epoch)
optimizer = paddle.optimizer.Momentum(learning_rate=scheduler,
parameters=model.parameters(),
momentum=0.9,
weight_decay=5e-4)
eval_mode = False
if eval_mode:
state_dict = paddle.load('./student_ep200.pdparams')
model.set_state_dict(state_dict)
student_validate(model, val_dataloader, criterion)
return
student_history_train = []
student_history_vali = []
save_freq = 5
test_freq = 1
for epoch in range(1, total_epoch+1):
loss_train,acc1_train = student_train_one_epoch(model, train_dataloader, criterion, optimizer, epoch, total_epoch)
scheduler.step()
student_history_train.append((loss_train, acc1_train))
if epoch % test_freq == 0 or epoch == total_epoch:
loss_vali,acc1_vali = student_validate(model, val_dataloader, criterion)
student_history_vali.append((loss_vali, acc1_vali))
if epoch % save_freq == 0 or epoch == total_epoch:
paddle.save(model.state_dict(), f'./student_ep{epoch}.pdparams')
paddle.save(optimizer.state_dict(), f'./student_ep{epoch}.pdopts')
return model, student_history_train, student_history_vali
# 学生网络训练(有老师教)返回值分别是网络模型、训练时的loss和acc、预测时的loss和acc
student_model,student_history_train,student_history_vali = student_main()
3.4让学生自己学,不使用KD(知识蒸馏)
# 定义学生训练函数,跟老师训练函数一样,跟(有老师教)的学生网络不同
def student_no_teacher_train_one_epoch(model, dataloader, criterion, optimizer, epoch, total_epoch, report_freq=20):
print(f'----- Training Epoch [{epoch}/{total_epoch}]:')
loss_meter = AverageMeter()
acc_meter = AverageMeter()
model.train()
for batch_idx, data in enumerate(dataloader):
image = data[0]
label = data[1]
out = model(image)
loss = criterion(out, label)
loss.backward()
optimizer.step()
optimizer.clear_grad()
pred = nn.functional.softmax(out, axis=1)
acc1 = paddle.metric.accuracy(pred, label)
batch_size = image.shape[0]
loss_meter.update(loss.cpu().numpy()[0], batch_size)
acc_meter.update(acc1.cpu().numpy()[0], batch_size)
if batch_idx > 0 and batch_idx % report_freq == 0:
print(f'----- Batch[{batch_idx}/{len(dataloader)}], Loss: {loss_meter.avg:.5}, Acc@1: {acc_meter.avg:.4}')
print(f'----- Epoch[{epoch}/{total_epoch}], Loss: {loss_meter.avg:.5}, Acc@1: {acc_meter.avg:.4}')
return loss,acc1
# 定义学生训练主函数,跟老师主函数一样,跟(有老师教)的学生网络不同
def student_no_teacher_main():
total_epoch = 20
batch_size = 256
model = StudentNet()
train_dataset = get_dataset(mode='train')
train_dataloader = get_dataloader(train_dataset, batch_size, mode='train')
val_dataset = get_dataset(mode='test')
val_dataloader = get_dataloader(val_dataset, batch_size, mode='test')
criterion = nn.CrossEntropyLoss()
scheduler = paddle.optimizer.lr.CosineAnnealingDecay(0.02, total_epoch)
optimizer = paddle.optimizer.Momentum(learning_rate=scheduler,
parameters=model.parameters(),
momentum=0.9,
weight_decay=5e-4)
eval_mode = False
if eval_mode:
state_dict = paddle.load('./student_no_teacher_ep200.pdparams')
model.set_state_dict(state_dict)
student_validate(model, val_dataloader, criterion)
return
student_history_train = []
student_history_vali = []
save_freq = 5
test_freq = 1
for epoch in range(1, total_epoch+1):
loss_train,acc1_train = student_no_teacher_train_one_epoch(model, train_dataloader, criterion, optimizer, epoch, total_epoch)
scheduler.step()
student_history_train.append((loss_train, acc1_train))
if epoch % test_freq == 0 or epoch == total_epoch:
loss_vali,acc1_vali = student_validate(model, val_dataloader, criterion)
student_history_vali.append((loss_vali, acc1_vali))
if epoch % save_freq == 0 or epoch == total_epoch:
paddle.save(model.state_dict(), f'./student_no_teacher_ep{epoch}.pdparams')
paddle.save(optimizer.state_dict(), f'./student_no_teacher_ep{epoch}.pdopts')
return model, student_history_train, student_history_vali
# 学生网络训练(没有老师教)返回值分别是网络模型、训练时的loss和acc、预测时的loss和acc
student_no_teacher_model,student_no_teacher_history_train,student_no_teacher_history_vali = student_no_teacher_main()
4 对比实验结果
import matplotlib.pyplot as plt
epochs = 10 # 10个轮次
x = list(range(1, epochs+1))
plt.subplot(2, 1, 1)
plt.plot(x, [teacher_history_vali[i][1] for i in range(epochs)], label='teacher')
plt.plot(x, [student_history_vali[i][1] for i in range(epochs)], label='student with KD')
plt.plot(x, [student_no_teacher_history_vali[i][1] for i in range(epochs)], label='student without KD')
plt.title('Test accuracy')
plt.legend()
plt.subplot(2, 1, 2)
plt.plot(x, [teacher_history_vali[i][0] for i in range(epochs)], label='teacher')
plt.plot(x, [student_history_vali[i][0] for i in range(epochs)], label='student with KD')
plt.plot(x, [student_no_teacher_history_vali[i][0] for i in range(epochs)], label='student without KD')
plt.title('Test loss')
ent_no_teacher_history_vali[i][1] for i in range(epochs)], label='student without KD')
plt.title('Test accuracy')
plt.legend()
plt.subplot(2, 1, 2)
plt.plot(x, [teacher_history_vali[i][0] for i in range(epochs)], label='teacher')
plt.plot(x, [student_history_vali[i][0] for i in range(epochs)], label='student with KD')
plt.plot(x, [student_no_teacher_history_vali[i][0] for i in range(epochs)], label='student without KD')
plt.title('Test loss')
plt.legend()
<matplotlib.legend.Legend at 0x7f706c138910>
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-UqcrjOp1-1639283544000)(output_49_1.png)]](https://i-blog.csdnimg.cn/blog_migrate/69915907971df1ae1289ce332192f2bc.png)
- 验证集上的准确率比较:
- with KD表示有‘老师网络’,without KD表示没有‘老师网络’
- with KD跑了10轮次,without KD跑了20轮次
| 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 | 10 | 11 | 12 | 13 | … | 19 | 20 | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| with KD | 0.925 | 0.960 | 0.906 | 0.947 | 0.958 | 0.962 | 0.966 | 0.967 | 0.968 | 0.968 | ||||||
| without KD | 0.952 | 0.953 | 0.951 | 0.951 | 0.951 | 0.942 | 0.931 | 0.942 | 0.940 | 0.943 | 0.926 | 0.942 | 0.920 | … | 0.947 | 0.949 |
- 从实验结果我们不难看出,with KD(应用知识蒸馏)的网络在9、10轮次就趋于稳定,而without KD直到20轮次也没趋于稳定,同时准确率也没with KD的高
- 再结合上程序输出图,10轮次中,with KD的loss、acc相对稳定,反观without KD的loss、acc呈现‘跌宕起伏’的状态
- 综上所述,在同种网络结构,应用知识蒸馏方法的网络,训练时更为稳定,收敛速度快
小结
- 以上是作者平时学习做的项目笔记,不同见解欢迎各位大佬指正
- 奥利给
- 如若存在问题,可在评论区留言,作者会不时为大家讲解
- 作者aistudio主页链接,欢迎各位互粉、提问:aistudio

学大模型,用大模型上飞桨星河社区!每天8点V100G算力免费领!免费领取ERNIE 4.0 100w Token >>>
更多推荐



 0
0 0
0- 0



 已为社区贡献1436条内容
已为社区贡献1436条内容

所有评论(0)