
ATAC:激活函数和注意力机制的统一
激活功能和注意机制通常被视为具有不同的目的,并且具有不同的演变。然而,这两个概念都可以表述为非线性门控函数。受其相似性的启发,我们提出了一种新的激活单元类型,称为注意激活(ATAC)单元,作为激活功能和注意机制的统一。特别地,我们提出了一个局部通道注意模块,用于同时进行非线性激活和元素级特征细化,它可以局部聚集点级跨通道特征上下文。通过在卷积网络中用这种ATAC单元取代众所周知的修正线性单元,我们
摘要
激活功能和注意机制通常被视为具有不同的目的,并且具有不同的演变。然而,这两个概念都可以表述为非线性门控函数。受其相似性的启发,我们提出了一种新的激活单元类型,称为注意激活(ATAC)单元,作为激活功能和注意机制的统一。特别地,我们提出了一个局部通道注意模块,用于同时进行非线性激活和元素级特征细化,它可以局部聚集点级跨通道特征上下文。通过在卷积网络中用这种ATAC单元取代众所周知的修正线性单元,我们可以构建完全注意的网络,在少量额外参数的情况下,网络的表现明显更好。我们使用不同网络深度的主机网络对ATAC单元进行了详细的消融研究,以经验地验证该单元的有效性和效率。此外,我们比较了ATAC单元与现有激活函数以及其他注意机制在CIFAR-10、CIFAR-100和ImageNet数据集上的性能。我们的实验结果表明,由提出的ATAC单元构造的网络,在给定可比较数量的参数时,通常可以获得比其竞争对手更好的性能。
1.ATAC
激活函数和注意力机制通常被视为具有不同的目的,并且具有不同的演变。但是,这两个概念都可以表述为:nonlinear gating function—— x ′ = x ⊗ f ( x ) x'=x \otimes f (x) x′=x⊗f(x) 的形式。受它们相似性的启发,本文提出了一种新型的激活单元,称为注意力激活(ATAC)单元,作为激活函数和注意力机制的统一。
从计算的角度来看,注意激活函数必须是廉价的。
为了同时满足激活函数的局部性和注意力机制的上下文聚集要求,ATAC单元采用逐点卷积来实现局部注意。所提出的基于局部通道注意的注意激活单元的架构如图1所示:目标是使网络能够根据逐点跨通道相关性有选择地、逐元素地激活和细化特征。为了减少参数,通过瓶颈结构计算注意权值 L ( X ) ∈ R C × H × W L(X) \in R^{C×H×W} L(X)∈RC×H×W ,如下所示:
L ( X ) = σ ( B ( P W C o n v 2 ( δ ( B ( P W C o n v 1 ( X ) ) ) ) ) ) \mathbf{L}(\mathbf{X})=\sigma\left(\mathcal{B}\left(\mathrm{PWConv}_{2}\left(\delta\left(\mathcal{B}\left(\mathrm{PWConv}_{1}(\mathbf{X})\right)\right)\right)\right)\right) L(X)=σ(B(PWConv2(δ(B(PWConv1(X))))))
2. 代码复现
2.1 下载并导入所需要的包
!pip install paddlex
%matplotlib inline
import paddle
import paddle.fluid as fluid
import numpy as np
import matplotlib.pyplot as plt
from paddle.vision.datasets import Cifar10
from paddle.vision.transforms import Transpose
from paddle.io import Dataset, DataLoader
from paddle import nn
import paddle.nn.functional as F
import paddle.vision.transforms as transforms
import os
import matplotlib.pyplot as plt
from matplotlib.pyplot import figure
import paddlex
from paddle import ParamAttr
2.2 创建数据集
train_tfm = transforms.Compose([
transforms.Resize((130, 130)),
transforms.ColorJitter(brightness=0.2,contrast=0.2, saturation=0.2),
paddlex.transforms.MixupImage(),
transforms.RandomResizedCrop(128, scale=(0.6, 1.0)),
transforms.RandomHorizontalFlip(0.5),
transforms.RandomRotation(20),
transforms.ToTensor(),
transforms.Normalize(mean=(0.485, 0.456, 0.406), std=(0.229, 0.224, 0.225)),
])
test_tfm = transforms.Compose([
transforms.Resize((128, 128)),
transforms.ToTensor(),
transforms.Normalize(mean=(0.485, 0.456, 0.406), std=(0.229, 0.224, 0.225)),
])
paddle.vision.set_image_backend('cv2')
# 使用Cifar10数据集
train_dataset = Cifar10(data_file='data/data152754/cifar-10-python.tar.gz', mode='train', transform = train_tfm, )
val_dataset = Cifar10(data_file='data/data152754/cifar-10-python.tar.gz', mode='test',transform = test_tfm)
print("train_dataset: %d" % len(train_dataset))
print("val_dataset: %d" % len(val_dataset))
train_dataset: 50000
val_dataset: 10000
batch_size=128
train_loader = DataLoader(train_dataset, batch_size=batch_size, shuffle=True, drop_last=True, num_workers=2)
val_loader = DataLoader(val_dataset, batch_size=batch_size, shuffle=False, drop_last=False, num_workers=2)
2.3 标签平滑
class LabelSmoothingCrossEntropy(nn.Layer):
def __init__(self, smoothing=0.1):
super().__init__()
self.smoothing = smoothing
def forward(self, pred, target):
confidence = 1. - self.smoothing
log_probs = F.log_softmax(pred, axis=-1)
idx = paddle.stack([paddle.arange(log_probs.shape[0]), target], axis=1)
nll_loss = paddle.gather_nd(-log_probs, index=idx)
smooth_loss = paddle.mean(-log_probs, axis=-1)
loss = confidence * nll_loss + self.smoothing * smooth_loss
return loss.mean()
2.4 AlexNet-ATAC
2.4.1 ATAC
class ATAC(nn.Layer):
def __init__(self, dim, r=2, init_weight=False):
super().__init__()
self.conv1 = nn.Conv2D(dim, dim // r, 1)
self.conv2 = nn.Conv2D(dim // r, dim, 1)
self.bn1 = nn.BatchNorm2D(dim // r)
self.bn2 = nn.BatchNorm2D(dim)
self.sigmoid = nn.Sigmoid()
self.relu = nn.ReLU()
if init_weight:
self.apply(self._init_weight)
def _init_weight(self, m):
init = nn.initializer.Normal(mean=0, std=.02)
zeros = nn.initializer.Constant(0.)
ones = nn.initializer.Constant(1.)
if isinstance(m, nn.Conv2D):
init(m.weight)
zeros(m.bias)
if isinstance(m, nn.BatchNorm2D):
ones(m.weight)
zeros(m.bias)
def forward(self, x):
attn = self.conv1(x)
attn = self.bn1(attn)
attn = self.relu(attn)
attn = self.conv2(attn)
attn = self.bn2(attn)
attn = self.sigmoid(attn)
out = x * attn
return out
model = ATAC(64)
paddle.summary(model, (1, 64, 224, 224))
W0728 09:15:01.934214 260 gpu_resources.cc:61] Please NOTE: device: 0, GPU Compute Capability: 7.0, Driver API Version: 11.2, Runtime API Version: 10.1
W0728 09:15:01.938031 260 gpu_resources.cc:91] device: 0, cuDNN Version: 7.6.
---------------------------------------------------------------------------
Layer (type) Input Shape Output Shape Param #
===========================================================================
Conv2D-1 [[1, 64, 224, 224]] [1, 32, 224, 224] 2,080
BatchNorm2D-1 [[1, 32, 224, 224]] [1, 32, 224, 224] 128
ReLU-5 [[1, 32, 224, 224]] [1, 32, 224, 224] 0
Conv2D-2 [[1, 32, 224, 224]] [1, 64, 224, 224] 2,112
BatchNorm2D-2 [[1, 64, 224, 224]] [1, 64, 224, 224] 256
Sigmoid-2 [[1, 64, 224, 224]] [1, 64, 224, 224] 0
===========================================================================
Total params: 4,576
Trainable params: 4,192
Non-trainable params: 384
---------------------------------------------------------------------------
Input size (MB): 12.25
Forward/backward pass size (MB): 110.25
Params size (MB): 0.02
Estimated Total Size (MB): 122.52
---------------------------------------------------------------------------
{'total_params': 4576, 'trainable_params': 4192}
2.4.2 AlexNet-ATAC
class AlexNet_ATAC(nn.Layer):
def __init__(self,num_classes=10):
super().__init__()
self.features=nn.Sequential(
nn.Conv2D(3,48, kernel_size=11, stride=4, padding=11//2),
ATAC(48),
nn.MaxPool2D(kernel_size=3,stride=2),
nn.Conv2D(48,128, kernel_size=5, padding=2),
ATAC(128),
nn.MaxPool2D(kernel_size=3,stride=2),
nn.Conv2D(128, 192,kernel_size=3,stride=1,padding=1),
ATAC(192),
nn.Conv2D(192,192,kernel_size=3,stride=1,padding=1),
ATAC(192),
nn.Conv2D(192,128,kernel_size=3,stride=1,padding=1),
ATAC(128),
nn.MaxPool2D(kernel_size=3,stride=2),
)
self.classifier=nn.Sequential(
nn.Linear(3 * 3 * 128,2048),
nn.ReLU(),
nn.Dropout(0.5),
nn.Linear(2048,2048),
nn.ReLU(),
nn.Dropout(0.5),
nn.Linear(2048,num_classes),
)
def forward(self,x):
x = self.features(x)
x = paddle.flatten(x, 1)
x=self.classifier(x)
return x
model = AlexNet_ATAC(num_classes=10)
paddle.summary(model, (1, 3, 128, 128))

2.5 训练
learning_rate = 0.001
n_epochs = 50
paddle.seed(42)
np.random.seed(42)
work_path = 'work/model'
model = AlexNet_ATAC(num_classes=10)
criterion = LabelSmoothingCrossEntropy()
scheduler = paddle.optimizer.lr.CosineAnnealingDecay(learning_rate=learning_rate, T_max=50000 // batch_size * n_epochs, verbose=False)
optimizer = paddle.optimizer.Adam(parameters=model.parameters(), learning_rate=scheduler, weight_decay=1e-5)
gate = 0.0
threshold = 0.0
best_acc = 0.0
val_acc = 0.0
loss_record = {'train': {'loss': [], 'iter': []}, 'val': {'loss': [], 'iter': []}} # for recording loss
acc_record = {'train': {'acc': [], 'iter': []}, 'val': {'acc': [], 'iter': []}} # for recording accuracy
loss_iter = 0
acc_iter = 0
for epoch in range(n_epochs):
# ---------- Training ----------
model.train()
train_num = 0.0
train_loss = 0.0
val_num = 0.0
val_loss = 0.0
accuracy_manager = paddle.metric.Accuracy()
val_accuracy_manager = paddle.metric.Accuracy()
print("#===epoch: {}, lr={:.10f}===#".format(epoch, optimizer.get_lr()))
for batch_id, data in enumerate(train_loader):
x_data, y_data = data
labels = paddle.unsqueeze(y_data, axis=1)
logits = model(x_data)
loss = criterion(logits, y_data)
acc = paddle.metric.accuracy(logits, labels)
accuracy_manager.update(acc)
if batch_id % 10 == 0:
loss_record['train']['loss'].append(loss.numpy())
loss_record['train']['iter'].append(loss_iter)
loss_iter += 1
loss.backward()
optimizer.step()
scheduler.step()
optimizer.clear_grad()
train_loss += loss
train_num += len(y_data)
total_train_loss = (train_loss / train_num) * batch_size
train_acc = accuracy_manager.accumulate()
acc_record['train']['acc'].append(train_acc)
acc_record['train']['iter'].append(acc_iter)
acc_iter += 1
# Print the information.
print("#===epoch: {}, train loss is: {}, train acc is: {:2.2f}%===#".format(epoch, total_train_loss.numpy(), train_acc*100))
# ---------- Validation ----------
model.eval()
for batch_id, data in enumerate(val_loader):
x_data, y_data = data
labels = paddle.unsqueeze(y_data, axis=1)
with paddle.no_grad():
logits = model(x_data)
loss = criterion(logits, y_data)
acc = paddle.metric.accuracy(logits, labels)
val_accuracy_manager.update(acc)
val_loss += loss
val_num += len(y_data)
total_val_loss = (val_loss / val_num) * batch_size
loss_record['val']['loss'].append(total_val_loss.numpy())
loss_record['val']['iter'].append(loss_iter)
val_acc = val_accuracy_manager.accumulate()
acc_record['val']['acc'].append(val_acc)
acc_record['val']['iter'].append(acc_iter)
print("#===epoch: {}, val loss is: {}, val acc is: {:2.2f}%===#".format(epoch, total_val_loss.numpy(), val_acc*100))
# ===================save====================
if val_acc > best_acc:
best_acc = val_acc
paddle.save(model.state_dict(), os.path.join(work_path, 'best_model.pdparams'))
paddle.save(optimizer.state_dict(), os.path.join(work_path, 'best_optimizer.pdopt'))
print(best_acc)
paddle.save(model.state_dict(), os.path.join(work_path, 'final_model.pdparams'))
paddle.save(optimizer.state_dict(), os.path.join(work_path, 'final_optimizer.pdopt'))

2.6 实验结果
def plot_learning_curve(record, title='loss', ylabel='CE Loss'):
''' Plot learning curve of your CNN '''
maxtrain = max(map(float, record['train'][title]))
maxval = max(map(float, record['val'][title]))
ymax = max(maxtrain, maxval) * 1.1
mintrain = min(map(float, record['train'][title]))
minval = min(map(float, record['val'][title]))
ymin = min(mintrain, minval) * 0.9
total_steps = len(record['train'][title])
x_1 = list(map(int, record['train']['iter']))
x_2 = list(map(int, record['val']['iter']))
figure(figsize=(10, 6))
plt.plot(x_1, record['train'][title], c='tab:red', label='train')
plt.plot(x_2, record['val'][title], c='tab:cyan', label='val')
plt.ylim(ymin, ymax)
plt.xlabel('Training steps')
plt.ylabel(ylabel)
plt.title('Learning curve of {}'.format(title))
plt.legend()
plt.show()
plot_learning_curve(loss_record, title='loss', ylabel='CE Loss')

plot_learning_curve(acc_record, title='acc', ylabel='Accuracy')

import time
work_path = 'work/model'
model = AlexNet_ATAC(num_classes=10)
model_state_dict = paddle.load(os.path.join(work_path, 'best_model.pdparams'))
model.set_state_dict(model_state_dict)
model.eval()
aa = time.time()
for batch_id, data in enumerate(val_loader):
x_data, y_data = data
labels = paddle.unsqueeze(y_data, axis=1)
with paddle.no_grad():
logits = model(x_data)
bb = time.time()
print("Throughout:{}".format(int(len(val_dataset)//(bb - aa))))
Throughout:987
def get_cifar10_labels(labels):
"""返回CIFAR10数据集的文本标签。"""
text_labels = [
'airplane', 'automobile', 'bird', 'cat', 'deer', 'dog', 'frog',
'horse', 'ship', 'truck']
return [text_labels[int(i)] for i in labels]
def show_images(imgs, num_rows, num_cols, pred=None, gt=None, scale=1.5):
"""Plot a list of images."""
figsize = (num_cols * scale, num_rows * scale)
_, axes = plt.subplots(num_rows, num_cols, figsize=figsize)
axes = axes.flatten()
for i, (ax, img) in enumerate(zip(axes, imgs)):
if paddle.is_tensor(img):
ax.imshow(img.numpy())
else:
ax.imshow(img)
ax.axes.get_xaxis().set_visible(False)
ax.axes.get_yaxis().set_visible(False)
if pred or gt:
ax.set_title("pt: " + pred[i] + "\ngt: " + gt[i])
return axes
work_path = 'work/model'
X, y = next(iter(DataLoader(val_dataset, batch_size=18)))
model = AlexNet_ATAC(num_classes=10)
model_state_dict = paddle.load(os.path.join(work_path, 'best_model.pdparams'))
model.set_state_dict(model_state_dict)
model.eval()
logits = model(X)
y_pred = paddle.argmax(logits, -1)
X = paddle.transpose(X, [0, 2, 3, 1])
axes = show_images(X.reshape((18, 128, 128, 3)), 1, 18, pred=get_cifar10_labels(y_pred), gt=get_cifar10_labels(y))
plt.show()
Clipping input data to the valid range for imshow with RGB data ([0..1] for floats or [0..255] for integers).
Clipping input data to the valid range for imshow with RGB data ([0..1] for floats or [0..255] for integers).
Clipping input data to the valid range for imshow with RGB data ([0..1] for floats or [0..255] for integers).
Clipping input data to the valid range for imshow with RGB data ([0..1] for floats or [0..255] for integers).
Clipping input data to the valid range for imshow with RGB data ([0..1] for floats or [0..255] for integers).
Clipping input data to the valid range for imshow with RGB data ([0..1] for floats or [0..255] for integers).
Clipping input data to the valid range for imshow with RGB data ([0..1] for floats or [0..255] for integers).
Clipping input data to the valid range for imshow with RGB data ([0..1] for floats or [0..255] for integers).
Clipping input data to the valid range for imshow with RGB data ([0..1] for floats or [0..255] for integers).
Clipping input data to the valid range for imshow with RGB data ([0..1] for floats or [0..255] for integers).
Clipping input data to the valid range for imshow with RGB data ([0..1] for floats or [0..255] for integers).
Clipping input data to the valid range for imshow with RGB data ([0..1] for floats or [0..255] for integers).
Clipping input data to the valid range for imshow with RGB data ([0..1] for floats or [0..255] for integers).
Clipping input data to the valid range for imshow with RGB data ([0..1] for floats or [0..255] for integers).
Clipping input data to the valid range for imshow with RGB data ([0..1] for floats or [0..255] for integers).
Clipping input data to the valid range for imshow with RGB data ([0..1] for floats or [0..255] for integers).
Clipping input data to the valid range for imshow with RGB data ([0..1] for floats or [0..255] for integers).
Clipping input data to the valid range for imshow with RGB data ([0..1] for floats or [0..255] for integers).

3. AlexNet
3.1 AlexNet
class AlexNet(nn.Layer):
def __init__(self,num_classes=10):
super().__init__()
self.features=nn.Sequential(
nn.Conv2D(3,48, kernel_size=11, stride=4, padding=11//2),
nn.ReLU(),
nn.MaxPool2D(kernel_size=3,stride=2),
nn.Conv2D(48,128, kernel_size=5, padding=2),
nn.ReLU(),
nn.MaxPool2D(kernel_size=3,stride=2),
nn.Conv2D(128, 192,kernel_size=3,stride=1,padding=1),
nn.ReLU(),
nn.Conv2D(192,192,kernel_size=3,stride=1,padding=1),
nn.ReLU(),
nn.Conv2D(192,128,kernel_size=3,stride=1,padding=1),
nn.ReLU(),
nn.MaxPool2D(kernel_size=3,stride=2),
)
self.classifier=nn.Sequential(
nn.Linear(3 * 3 * 128,2048),
nn.ReLU(),
nn.Dropout(0.5),
nn.Linear(2048,2048),
nn.ReLU(),
nn.Dropout(0.5),
nn.Linear(2048,num_classes),
)
def forward(self,x):
x = self.features(x)
x = paddle.flatten(x, 1)
x=self.classifier(x)
return x
model = AlexNet(num_classes=10)
paddle.summary(model, (1, 3, 128, 128))

3.2 训练
learning_rate = 0.001
n_epochs = 50
paddle.seed(42)
np.random.seed(42)
work_path = 'work/model1'
model = AlexNet(num_classes=10)
criterion = LabelSmoothingCrossEntropy()
scheduler = paddle.optimizer.lr.CosineAnnealingDecay(learning_rate=learning_rate, T_max=50000 // batch_size * n_epochs, verbose=False)
optimizer = paddle.optimizer.Adam(parameters=model.parameters(), learning_rate=scheduler, weight_decay=1e-5)
gate = 0.0
threshold = 0.0
best_acc = 0.0
val_acc = 0.0
loss_record1 = {'train': {'loss': [], 'iter': []}, 'val': {'loss': [], 'iter': []}} # for recording loss
acc_record1 = {'train': {'acc': [], 'iter': []}, 'val': {'acc': [], 'iter': []}} # for recording accuracy
loss_iter = 0
acc_iter = 0
for epoch in range(n_epochs):
# ---------- Training ----------
model.train()
train_num = 0.0
train_loss = 0.0
val_num = 0.0
val_loss = 0.0
accuracy_manager = paddle.metric.Accuracy()
val_accuracy_manager = paddle.metric.Accuracy()
print("#===epoch: {}, lr={:.10f}===#".format(epoch, optimizer.get_lr()))
for batch_id, data in enumerate(train_loader):
x_data, y_data = data
labels = paddle.unsqueeze(y_data, axis=1)
logits = model(x_data)
loss = criterion(logits, y_data)
acc = paddle.metric.accuracy(logits, labels)
accuracy_manager.update(acc)
if batch_id % 10 == 0:
loss_record1['train']['loss'].append(loss.numpy())
loss_record1['train']['iter'].append(loss_iter)
loss_iter += 1
loss.backward()
optimizer.step()
scheduler.step()
optimizer.clear_grad()
train_loss += loss
train_num += len(y_data)
total_train_loss = (train_loss / train_num) * batch_size
train_acc = accuracy_manager.accumulate()
acc_record1['train']['acc'].append(train_acc)
acc_record1['train']['iter'].append(acc_iter)
acc_iter += 1
# Print the information.
print("#===epoch: {}, train loss is: {}, train acc is: {:2.2f}%===#".format(epoch, total_train_loss.numpy(), train_acc*100))
# ---------- Validation ----------
model.eval()
for batch_id, data in enumerate(val_loader):
x_data, y_data = data
labels = paddle.unsqueeze(y_data, axis=1)
with paddle.no_grad():
logits = model(x_data)
loss = criterion(logits, y_data)
acc = paddle.metric.accuracy(logits, labels)
val_accuracy_manager.update(acc)
val_loss += loss
val_num += len(y_data)
total_val_loss = (val_loss / val_num) * batch_size
loss_record1['val']['loss'].append(total_val_loss.numpy())
loss_record1['val']['iter'].append(loss_iter)
val_acc = val_accuracy_manager.accumulate()
acc_record1['val']['acc'].append(val_acc)
acc_record1['val']['iter'].append(acc_iter)
print("#===epoch: {}, val loss is: {}, val acc is: {:2.2f}%===#".format(epoch, total_val_loss.numpy(), val_acc*100))
# ===================save====================
if val_acc > best_acc:
best_acc = val_acc
paddle.save(model.state_dict(), os.path.join(work_path, 'best_model.pdparams'))
paddle.save(optimizer.state_dict(), os.path.join(work_path, 'best_optimizer.pdopt'))
print(best_acc)
paddle.save(model.state_dict(), os.path.join(work_path, 'final_model.pdparams'))
paddle.save(optimizer.state_dict(), os.path.join(work_path, 'final_optimizer.pdopt'))

3.3 实验结果
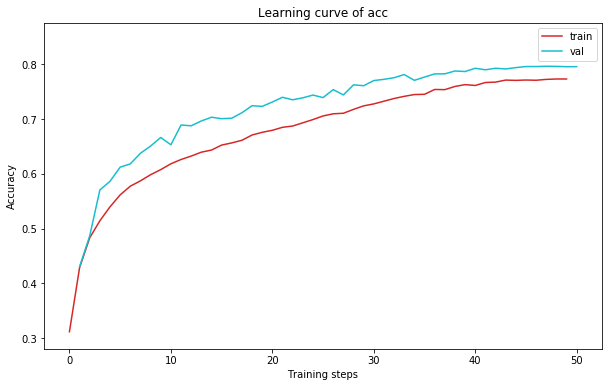
plot_learning_curve(loss_record1, title='loss', ylabel='CE Loss')

plot_learning_curve(acc_record1, title='acc', ylabel='Accuracy')
import time
work_path = 'work/model1'
model = AlexNet(num_classes=10)
model_state_dict = paddle.load(os.path.join(work_path, 'best_model.pdparams'))
model.set_state_dict(model_state_dict)
model.eval()
aa = time.time()
for batch_id, data in enumerate(val_loader):
x_data, y_data = data
labels = paddle.unsqueeze(y_data, axis=1)
with paddle.no_grad():
logits = model(x_data)
bb = time.time()
print("Throughout:{}".format(int(len(val_dataset)//(bb - aa))))
Throughout:1162
work_path = 'work/model1'
X, y = next(iter(DataLoader(val_dataset, batch_size=18)))
model = AlexNet(num_classes=10)
model_state_dict = paddle.load(os.path.join(work_path, 'best_model.pdparams'))
model.set_state_dict(model_state_dict)
model.eval()
logits = model(X)
y_pred = paddle.argmax(logits, -1)
X = paddle.transpose(X, [0, 2, 3, 1])
axes = show_images(X.reshape((18, 128, 128, 3)), 1, 18, pred=get_cifar10_labels(y_pred), gt=get_cifar10_labels(y))
plt.show()
Clipping input data to the valid range for imshow with RGB data ([0..1] for floats or [0..255] for integers).
Clipping input data to the valid range for imshow with RGB data ([0..1] for floats or [0..255] for integers).
Clipping input data to the valid range for imshow with RGB data ([0..1] for floats or [0..255] for integers).
Clipping input data to the valid range for imshow with RGB data ([0..1] for floats or [0..255] for integers).
Clipping input data to the valid range for imshow with RGB data ([0..1] for floats or [0..255] for integers).
Clipping input data to the valid range for imshow with RGB data ([0..1] for floats or [0..255] for integers).
Clipping input data to the valid range for imshow with RGB data ([0..1] for floats or [0..255] for integers).
Clipping input data to the valid range for imshow with RGB data ([0..1] for floats or [0..255] for integers).
Clipping input data to the valid range for imshow with RGB data ([0..1] for floats or [0..255] for integers).
Clipping input data to the valid range for imshow with RGB data ([0..1] for floats or [0..255] for integers).
Clipping input data to the valid range for imshow with RGB data ([0..1] for floats or [0..255] for integers).
Clipping input data to the valid range for imshow with RGB data ([0..1] for floats or [0..255] for integers).
Clipping input data to the valid range for imshow with RGB data ([0..1] for floats or [0..255] for integers).
Clipping input data to the valid range for imshow with RGB data ([0..1] for floats or [0..255] for integers).
Clipping input data to the valid range for imshow with RGB data ([0..1] for floats or [0..255] for integers).
Clipping input data to the valid range for imshow with RGB data ([0..1] for floats or [0..255] for integers).
Clipping input data to the valid range for imshow with RGB data ([0..1] for floats or [0..255] for integers).
Clipping input data to the valid range for imshow with RGB data ([0..1] for floats or [0..255] for integers).

4. 对比实验结果
| model | Train Acc | Val Acc | parameter |
|---|---|---|---|
| AlexNet w/o ATAC | 0.7710 | 0.79658 | 7524042 |
| AlexNet w ATAC | 0.9032 | 0.88617 | 7638002 |
总结
ATAC在增加较少参数(+113960)的情况下大大加快了收敛速度以及精度(+0.08959)
本文作者很巧妙地get到激活函数与注意力机制的共同点,将其进行结合,虽然方法设计的较为简单,但是切入点非常牛!!!
转载自:https://aistudio.baidu.com/aistudio/projectdetail/4383607

学大模型,用大模型上飞桨星河社区!每天8点V100G算力免费领!免费领取ERNIE 4.0 100w Token >>>
更多推荐



 0
0 0
0- 0



 已为社区贡献1437条内容
已为社区贡献1437条内容

所有评论(0)