
数据预处理:中英文印刷字体图片分类数据集生成
转载AI Studio项目链接https://aistudio.baidu.com/aistudio/projectdetail/34810760 项目背景现在,随着OCR技术普及,从PDF或者图片中提取到文字内容已经不是什么难事。但是,对于排版的格式文档,如何在提取内容的时候,完整地还原其排版、字体,仍然是一个比较大的挑战。比如,面对这样一个场景:我们手上有一份扫描版的PDF论文,希望能转化出它
转载AI Studio项目链接https://aistudio.baidu.com/aistudio/projectdetail/3481076
0 项目背景
现在,随着OCR技术普及,从PDF或者图片中提取到文字内容已经不是什么难事。
但是,对于排版的格式文档,如何在提取内容的时候,完整地还原其排版、字体,仍然是一个比较大的挑战。
比如,面对这样一个场景:我们手上有一份扫描版的PDF论文,希望能转化出它的word版本,保留它的排版、图片、字体、公式……
这里面至少涉及到:
- 版面分析和图表提取
- OCR公式识别
- OCR字体识别
因此,本系列项目(又开一坑……)研究的就是其中的OCR字体识别场景。
1 场景分析
对于该场景,我们先做个初步分析。一般来说,基于印刷字体的PDF或图片文档,字体分布会有两种情况:
- 一种是整段整段的字体相同,这种场景可能比较普遍,版面字体分析准备数据集时,相对也比较简单,只要能定位段落的字体就行;
- 另一种就是我们比较熟悉的论文形式,尤其是中文论文,往往规定了,中文用哪种字体、英文用哪种字体、公式用哪种字体,一个段落里,它们是混着用的。
1.1 处理思路
还是走从易到难的路线,在第一个项目中,先研究对印刷字单字的字体识别。
由于商用字体在版权上是比较敏感的,这个项目中,我们就先用一些开源字体,跑通整个流程。
1.2 难点分析
项目一上来就面临比较大的难点,包括了不同字体的图片在哪里?如何组织?
这里就涉及到如何将字体文件转换为图片了。我们先看下AI Studio系统(Ubuntu系统)的字体文件在哪里。
# 定位系统某个字体文件位置
!ls /usr/share/fonts/
!ls /usr/share/fonts/truetype/noto/
cmap fangzheng truetype type1 X11
NotoMono-Regular.ttf
然后我们先试试看,如何实现字体文件转图片,参考这篇文章:python 由ttf字体文件生成png预览图
from PIL import Image, ImageDraw, ImageFont
import os
%matplotlib inline
def draw_png(fontpath, name, text_content, font_size = 24):
font=ImageFont.truetype(fontpath + name, font_size)
text_width, text_height = font.getsize(name[:-4])
image = Image.new(mode='RGBA', size=(text_width, text_height))
draw_table = ImageDraw.Draw(im=image)
draw_table.text(xy=(0, 0), text=text_content, fill='#000000', font=font) # text是要显示的文本
image.show() # 直接显示图片
draw_png('/usr/share/fonts/truetype/noto/','NotoMono-Regular.ttf','test ttf to png')
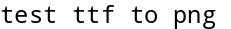
但是,这种做法,在我们传入中文字符的时候,就遇到了问题。乱码出现了,因为NotoMono-Regular.tff这个字体文件中,没有对中文字符的支持。
draw_png('/usr/share/fonts/truetype/noto/', 'NotoMono-Regular.ttf','测试 ttf to png')

我们找个支持中文字符显示的字体看看。
!ls /usr/share/fonts/fangzheng/
FZHLJW.TTF FZSYJW.TTF
# 换成支持中文的字体,就不会乱码了
draw_png('/usr/share/fonts/fangzheng/', 'FZHLJW.TTF','测试 ttf to png')
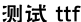
2 准备数据集
# 拉取开源中文字体包
!git clone https://gitee.com/mirrors/noto-cjk.git
# 把简体中文字体整理在一个目录
!mkdir cn-fonts
!mv noto-cjk/Serif/OTF/SimplifiedChinese/*.otf ./cn-fonts
!mv noto-cjk/Sans/OTF/SimplifiedChinese/*.otf ./cn-fonts
!cp /usr/share/fonts/fangzheng/*.TTF ./cn-fonts
2.1 fontTools库的应用
fontTools是一系列用于在Python中操作字体的库和实用程序。
# 准备工具库
!pip install fontTools
!pip install freetype-py
对一个字体文件,使用fontTools可以获得很多关键信息。同时,结合FreeTypePen这个库,还可用绘制字形图。
# 获取各节点名称,返回为列表
print(font.keys())
# 获取getGlyphOrder节点的name值,返回为列表
print(font.getGlyphOrder())
print(font.getGlyphNames())
# 获取cmap节点code与name值映射, 返回为字典
print(font.getBestCmap())
# 获取glyf节点TTGlyph字体xy坐标信息
print(font['glyf']['uniE1A0'].coordinates)
# 获取glyf节点TTGlyph字体xMin,yMin,xMax,yMax坐标信息
print(font['glyf']['uniE1A0'].xMin, font['glyf']['uniE1A0'].yMin,
font['glyf']['uniE1A0'].xMax, font['glyf']['uniE1A0'].yMax)
# 获取glyf节点TTGlyph字体on信息
print(font['glyf']['uniE1A0'].flags)
# 获取GlyphOrder节点GlyphID的id信息, 返回int型
print(font.getGlyphID('uniE1A0'))
# 查看指定字体是否支持中文
from fontTools.ttLib import TTFont
font = TTFont('cn-fonts/FZSYJW.TTF')
# 随机找个中文字符
print(ord('很') in font.getBestCmap())
True
注:ord() 函数是 chr() 函数(对于8位的ASCII字符串)或 unichr() 函数(对于Unicode对象)的配对函数,它以一个字符(长度为1的字符串)作为参数,返回对应的 ASCII 数值,或者 Unicode 数值,如果所给的 Unicode 字符超出了你的 Python 定义范围,则会引发一个 TypeError 的异常。
# 换一个不支持中文的字体文件
font = TTFont('/usr/share/fonts/truetype/noto/NotoMono-Regular.ttf')
# 随机找个中文字符
print(ord('很') in font.getBestCmap())
False
# 绘制字形图
from fontTools.ttLib import TTFont
from fontTools.pens.freetypePen import FreeTypePen
from fontTools.misc.transform import Offset
pen = FreeTypePen(None) # 实例化Pen子类
font = TTFont('cn-fonts/FZSYJW.TTF')
glyph = font.getGlyphSet()[font.getBestCmap()[28183]] # 通过字形名称选择某一字形对象
glyph.draw(pen) # “画”出字形轮廓
width, ascender, descender = glyph.width, font['OS/2'].usWinAscent, -font['OS/2'].usWinDescent # 获取字形的宽度和上沿以及下沿
height = ascender - descender # 利用上沿和下沿计算字形高度
pen.show(width=width, height=height, transform=Offset(0, -descender)) # 显示以及矫正
# 同时显示多种字体效果
!pip install uharfbuzz
import uharfbuzz as hb
from fontTools.pens.freetypePen import FreeTypePen
from fontTools.pens.transformPen import TransformPen
from fontTools.misc.transform import Offset
en1, en2, ar, ja = 'Tset', '不同', '字体', '效果'
for text, font_path, direction, typo_ascender, typo_descender, vhea_ascender, vhea_descender, contain, features in (
(en1, 'cn-fonts/NotoSerifCJKsc-SemiBold.otf', 'ltr', 2189, -600, None, None, False, {"kern": True, "liga": True}),
(en2, 'cn-fonts/FZHLJW.TTF', 'ltr', 2189, -600, None, None, True, {"kern": True, "liga": True}),
(ar, 'cn-fonts/FZSYJW.TTF', 'rtl', 1374, -738, None, None, False, {"kern": True, "liga": True}),
(ja, 'cn-fonts/NotoSansCJKsc-Light.otf', 'ltr', 880, -120, 500, -500, False, {"palt": True, "kern": True}),
(ja, 'cn-fonts/NotoSerifCJKsc-Black.otf', 'ttb', 880, -120, 500, -500, False, {"vert": True, "vpal": True, "vkrn": True})
):
blob = hb.Blob.from_file_path(font_path)
face = hb.Face(blob)
font = hb.Font(face)
buf = hb.Buffer()
buf.direction = direction
buf.add_str(text)
buf.guess_segment_properties()
hb.shape(font, buf, features)
x, y = 0, 0
pen = FreeTypePen(None)
for info, pos in zip(buf.glyph_infos, buf.glyph_positions):
gid = info.codepoint
transformed = TransformPen(pen, Offset(x + pos.x_offset, y + pos.y_offset))
font.draw_glyph_with_pen(gid, transformed)
x += pos.x_advance
y += pos.y_advance
offset, width, height = None, None, None
if direction in ('ltr', 'rtl'):
offset = (0, -typo_descender)
width = x
height = typo_ascender - typo_descender
else:
offset = (-vhea_descender, -y)
width = vhea_ascender - vhea_descender
height = -y
pen.show(width=width, height=height, transform=Offset(*offset), contain=contain)
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-jDemWZiE-1645194652815)(output_25_0.png)]](https://i-blog.csdnimg.cn/blog_migrate/ddffcd1583df75b7f59eedfdccf1cc14.png)
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-0mbLawLp-1645194652816)(output_25_1.png)]](https://i-blog.csdnimg.cn/blog_migrate/cf5835d1d6b50047f6766793a39ba57e.png)
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-Wy7jK42q-1645194652816)(output_25_2.png)]](https://i-blog.csdnimg.cn/blog_migrate/ecde9150358efa8403db5bfa46ed5459.png)
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-H6b9tfa1-1645194652816)(output_25_3.png)]](https://i-blog.csdnimg.cn/blog_migrate/8a36d8a3394fb3e460868290f2369fac.png)
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-QFbWmbzA-1645194652817)(output_25_4.png)]](https://i-blog.csdnimg.cn/blog_migrate/62b6127351e89733562774a5a5a0239f.png)
2.2 字体文件批量转图片
!mkdir MyDataset
from tqdm import tqdm
fileList = os.listdir('cn-fonts')
for f in fileList:
print(f)
font_dir = 'MyDataset/' + f[:-4]
font_path = 'cn-fonts/' + f
isExists=os.path.exists(font_dir)
# 判断结果
if not isExists:
# 如果不存在则创建目录
# 创建目录操作函数
os.makedirs(font_dir)
font = TTFont(font_path) # 实例化TTFont
for key in tqdm(font.getBestCmap()):
pen = FreeTypePen(None) # 实例化Pen子类
glyph = font.getGlyphSet()[font.getBestCmap()[key]] # 通过字形名称选择某一字形对象
glyph.draw(pen) # “画”出字形轮廓
width, ascender, descender = glyph.width, font['OS/2'].usWinAscent, -font['OS/2'].usWinDescent # 获取字形的宽度和上沿以及下沿
height = ascender - descender # 利用上沿和下沿计算字形高度
im = pen.image(width=width, height=height, transform=Offset(0, -descender)) # 显示以及矫正
# 个别字符在裁剪时会出现越界,这里做个处理
if width > 10:
im.save(font_dir + '/' + font.getBestCmap()[key]+'.png')
3 训练分类模型
3.1 数据集划分
PaddleX提供了数据集一键划分的功能,这么省力的操作怎能不用?
!pip install paddlex
# 数据集划分
!paddlex --split_dataset --format ImageNet --dataset_dir MyDataset --val_value 0.2 --test_value 0.1
[32m[02-14 19:56:44 MainThread @logger.py:242][0m Argv: /opt/conda/envs/python35-paddle120-env/bin/paddlex --split_dataset --format ImageNet --dataset_dir MyDataset --val_value 0.2 --test_value 0.1
[0m[33m[02-14 19:56:44 MainThread @utils.py:79][0m [5m[33mWRN[0m paddlepaddle version: 2.2.2. The dynamic graph version of PARL is under development, not fully tested and supported
[0m/opt/conda/envs/python35-paddle120-env/lib/python3.7/site-packages/parl/remote/communication.py:38: DeprecationWarning: 'pyarrow.default_serialization_context' is deprecated as of 2.0.0 and will be removed in a future version. Use pickle or the pyarrow IPC functionality instead.
context = pyarrow.default_serialization_context()
[0m/opt/conda/envs/python35-paddle120-env/lib/python3.7/site-packages/matplotlib/__init__.py:107: DeprecationWarning: Using or importing the ABCs from 'collections' instead of from 'collections.abc' is deprecated, and in 3.8 it will stop working
from collections import MutableMapping
[0m/opt/conda/envs/python35-paddle120-env/lib/python3.7/site-packages/matplotlib/rcsetup.py:20: DeprecationWarning: Using or importing the ABCs from 'collections' instead of from 'collections.abc' is deprecated, and in 3.8 it will stop working
from collections import Iterable, Mapping
[0m/opt/conda/envs/python35-paddle120-env/lib/python3.7/site-packages/matplotlib/colors.py:53: DeprecationWarning: Using or importing the ABCs from 'collections' instead of from 'collections.abc' is deprecated, and in 3.8 it will stop working
from collections import Sized
[0m2022-02-14 19:56:47 [INFO] Dataset split starts...[0m
[0m2022-02-14 19:56:48 [INFO] Dataset split done.[0m
[0m2022-02-14 19:56:48 [INFO] Train samples: 61957[0m
[0m2022-02-14 19:56:48 [INFO] Eval samples: 17700[0m
[0m2022-02-14 19:56:48 [INFO] Test samples: 8849[0m
[0m2022-02-14 19:56:48 [INFO] Split files saved in MyDataset[0m
[0m[0m
3.2 模型训练
本文对字体图片文件进行了分类模型训练尝试,结果却发现,无论是哪种模型,效果都不太好,这里有个猜测。
-
怀疑问题在于resize这个操作,所有的字形图,输入神经网络前都被resize到了相同大小,这里面,一些线条受到了扭曲,自然导致字形图原始特征遭到破坏,分类也就难以分出效果了。
-
第二个可能,也许不同字体的差异,这种特征过于微弱,即使用深度学习,也存在困难?
-
还有可能,就是卷积神经网络的固有曲线,在字体分类任务中被严重放大了。
不管怎么说,这也是一个挑战,单字字体识别分类准确率是否能进一步提升?后续的项目中,我们将进一步研究。
import paddlex as pdx
from paddlex import transforms as T
# 定义训练和验证时的transforms
# API说明:https://github.com/PaddlePaddle/PaddleX/blob/develop/docs/apis/transforms/transforms.md
train_transforms = T.Compose(
[T.RandomCrop(crop_size=224), T.Normalize(), T.MixupImage(alpha=1.5, beta=1.5, mixup_epoch=-1)])
eval_transforms = T.Compose([
T.ResizeByShort(short_size=256), T.CenterCrop(crop_size=224), T.Normalize()
])
# 定义训练和验证所用的数据集
# API说明:https://github.com/PaddlePaddle/PaddleX/blob/develop/docs/apis/datasets.md
train_dataset = pdx.datasets.ImageNet(
data_dir='MyDataset',
file_list='MyDataset/train_list.txt',
label_list='MyDataset/labels.txt',
transforms=train_transforms,
shuffle=True)
eval_dataset = pdx.datasets.ImageNet(
data_dir='MyDataset',
file_list='MyDataset/val_list.txt',
label_list='MyDataset/labels.txt',
transforms=eval_transforms)
# 初始化模型,并进行训练
# 可使用VisualDL查看训练指标,参考https://github.com/PaddlePaddle/PaddleX/blob/develop/docs/visualdl.md
num_classes = len(train_dataset.labels)
model = pdx.cls.MobileNetV3_small(num_classes=num_classes)
# API说明:https://github.com/PaddlePaddle/PaddleX/blob/develop/docs/apis/models/classification.md
# 各参数介绍与调整说明:https://github.com/PaddlePaddle/PaddleX/tree/develop/docs/parameters.md
model.train(
num_epochs=10,
train_dataset=train_dataset,
train_batch_size=32,
eval_dataset=eval_dataset,
lr_decay_epochs=[4, 6, 8],
learning_rate=0.01,
save_dir='output/mobilenetv3_small',
use_vdl=True)
4 再看场景
4.1 生成短语字体分类数据集
在单字识别上碰了壁,现在我们回来思考下,字体识别分类的“初心”是什么?
其实既不是整段相同字体的识别、也不是单字字体的识别,二是短语的识别。
比如,我们把PaddleOCR文档的第一句话拎出来,是这么写的:
PaddleOCR旨在打造一套丰富、领先、且实用的OCR工具库,助力使用者训练出更好的模型,并应用落地。
好了,即使用中文论文的排版要求,最多也就要求PaddleOCR和OCR是Times New Roman字体,其它中文字体是宋体吧?
那么在识别的时候,即使是最复杂的场景,大不了再对各种短语加个检测模型?
—— 一个非常不成熟的设想是,用OCR文字识别,然后结合分词信息,框出短语检测框。
所以,现在我们完全可以试着降低下难度,把单字识别弄成短语识别,看看分类器是否能起作用?
from PIL import Image, ImageDraw, ImageFont
import os
import jieba
fileList = os.listdir('cn-fonts')
textList = ['PPOCRLabel是一款适用于OCR领域的半自动化图形标注工具',
'内置PPOCR模型对数据自动标注和重新识别',
'使用python3和pyqt5编写',
'支持矩形框标注和四点标注模式',
'导出格式可直接用于PPOCR检测和识别模型的训练',
'近期更新2021-8-11:新增功能',
'打开数据所在文件夹、图像旋转(注意:旋转前的图片上不能存在标记框)',
'(by Wei-JL)新增快捷键说明(帮助-快捷键)',
'修复批处理下的方向快捷键移动功能(by d2623587501)',
'新增批处理与撤销功能(by Evezerest)批处理功能',
'按住Ctrl键选择标记框后可批量移动、复制、删除、重新识别',
'撤销功能:在绘制四点标注框过程中或对框进行编辑操作后',
'按下Ctrl+Z可撤销上一部操作',
'修复图像旋转和尺寸问题',
'优化编辑标记框过程(by ninetailskim、 edencfc)',
'优化标注体验(by edencfc):用户可在“视图',
'弹出标记输入框”选择在画完检测框后标记输入框是否弹出',
'识别结果与检测框同步滚动',
'识别结果更改为单击修改',
'(如果无法修改,请切换为系统自带输入法,或再次切回原输入法)',
'支持对单个标记框进行重新识别(by ninetailskim)',
'完善快捷键。尽请期待锁定框模式:针对同一场景数据',
'被锁定的检测框的大小与位置能在不同图片之间传递',
'如果您对以上内容感兴趣或对完善工具有不一样的想法',
'欢迎加入我们的SIG队伍与我们共同开发',
'可以在此处完成问卷和前置任务',
'经过我们确认相关内容后即可正式加入',
'享受SIG福利',
'共同为OCR开源事业贡献(特别说明:针对PPOCRLabel的改进也属于PaddleOCR前置任务)',
'PaddleX集成飞桨智能视觉领域图像分类',
'目标检测、语义分割、实例分割任务能力',
'将深度学习开发全流程从数据准备',
'模型训练与优化到多端部署端到端打通',
'并提供统一任务API接口及图形化开发界面Demo',
'开发者无需分别安装不同套件',
'以低代码的形式即可快速完成飞桨全流程开发。',
'PASSL is a Paddle based vision library for state-of-the-art Self-Supervised Learning research with PaddlePaddle',
'PASSL aims to accelerate research cycle in self-supervised learning: from designing a new self-supervised task to evaluating the learned representations.',
'新增产业最实用目标检测模型PP-YOLO',
'FasterRCNN、MaskRCNN、YOLOv3、DeepLabv3p等模型',
'新增内置COCO数据集预训练模型,适用于小模型精调',
'新增多种Backbone,优化体积及预测速度',
'优化OpenVINO、PaddleLite Android、服务端C++预测部署方案',
'新增树莓派部署方案等。',
'新增人像分割、工业标记读数案例',
'模型新增HRNet、FastSCNN、FasterRCNN',
'实例分割MaskRCNN新增Backbone HRNet',
'集成X2Paddle','PaddleX所有分类模型和语义分割模型支持导出为ONNX协议',
'新增模型加密Windows平台支持。新增Jetson、Paddle Lite模型部署预测方案。']
# 随机找一段短语
# mytext = 'PPOCRLabel是一款适用于OCR领域的半自动化图形标注工具,内置PPOCR模型对数据自动标注和重新识别。使用python3和pyqt5编写,支持矩形框标注和四点标注模式,导出格式可直接用于PPOCR检测和识别模型的训练。近期更新2021-8-11:新增功能:打开数据所在文件夹、图像旋转(注意:旋转前的图片上不能存在标记框)(by Wei-JL)新增快捷键说明(帮助-快捷键)、修复批处理下的方向快捷键移动功能(by d2623587501)2021-2-5:新增批处理与撤销功能(by Evezerest)批处理功能:按住Ctrl键选择标记框后可批量移动、复制、删除、重新识别。撤销功能:在绘制四点标注框过程中或对框进行编辑操作后,按下Ctrl+Z可撤销上一部操作。修复图像旋转和尺寸问题、优化编辑标记框过程(by ninetailskim、 edencfc)2021-1-11:优化标注体验(by edencfc):用户可在“视图 - 弹出标记输入框”选择在画完检测框后标记输入框是否弹出。识别结果与检测框同步滚动。识别结果更改为单击修改。(如果无法修改,请切换为系统自带输入法,或再次切回原输入法)2020-12-18: 支持对单个标记框进行重新识别(by ninetailskim),完善快捷键。尽请期待锁定框模式:针对同一场景数据,被锁定的检测框的大小与位置能在不同图片之间传递。如果您对以上内容感兴趣或对完善工具有不一样的想法,欢迎加入我们的SIG队伍与我们共同开发。可以在此处完成问卷和前置任务,经过我们确认相关内容后即可正式加入,享受SIG福利,共同为OCR开源事业贡献(特别说明:针对PPOCRLabel的改进也属于PaddleOCR前置任务)'
# mytext = "".join(jieba.cut(mytext))
# textList = list(jieba.cut(mytext))
!mkdir StsDataset
!mkdir StsDataset/FZHLJW
!mkdir StsDataset/FZSYJW
!mkdir StsDataset/NotoSansCJKsc-Black
!mkdir StsDataset/NotoSansCJKsc-Bold
!mkdir StsDataset/NotoSansCJKsc-DemiLight
!mkdir StsDataset/NotoSansCJKsc-Light
!mkdir StsDataset/NotoSansCJKsc-Medium
!mkdir StsDataset/NotoSansCJKsc-Regular
!mkdir StsDataset/NotoSansCJKsc-Thin
!mkdir StsDataset/NotoSerifCJKsc-Black
!mkdir StsDataset/NotoSerifCJKsc-Bold
!mkdir StsDataset/NotoSerifCJKsc-ExtraLight
!mkdir StsDataset/NotoSerifCJKsc-Light
!mkdir StsDataset/NotoSerifCJKsc-Medium
!mkdir StsDataset/NotoSerifCJKsc-Regular
!mkdir StsDataset/NotoSerifCJKsc-SemiBold
# 批量生成长文本、短语字体分类图片
for name in fileList:
print(name)
# font_dir = 'MyDataset/' + f[:-4]
font_path = 'cn-fonts/'
font=ImageFont.truetype(font_path + name, 24)
text_width, text_height = font.getsize(name[:-4])
for i,text_content in enumerate(textList):
image = Image.new(mode='RGBA', size=(text_width, text_height))
draw_table = ImageDraw.Draw(im=image)
if len(text_content) >= 2 :
draw_table.text(xy=(0, 0), text=text_content, fill='#000000', font=font) # text是要显示的文本
image.save('StsDataset/' + name[:-4] + '/' + str(i) + '.png')
NotoSansCJKsc-Medium.otf
NotoSerifCJKsc-ExtraLight.otf
FZSYJW.TTF
NotoSerifCJKsc-Black.otf
FZHLJW.TTF
NotoSerifCJKsc-Regular.otf
NotoSansCJKsc-Black.otf
NotoSansCJKsc-DemiLight.otf
NotoSerifCJKsc-Bold.otf
NotoSerifCJKsc-Light.otf
NotoSerifCJKsc-Medium.otf
NotoSansCJKsc-Thin.otf
NotoSansCJKsc-Light.otf
NotoSansCJKsc-Bold.otf
NotoSerifCJKsc-SemiBold.otf
NotoSansCJKsc-Regular.otf
# 数据集划分
!paddlex --split_dataset --format ImageNet --dataset_dir StsDataset --val_value 0.2 --test_value 0.1
4.2 生成固定size字体分类数据集
前面我们生成的是字形图,不同字形图大小不一。
现在,尝试生成不同固定字号的单字图片。
!mkdir MyDataset/FZHLJW
!mkdir MyDataset/FZSYJW
!mkdir MyDataset/NotoSansCJKsc-Black
!mkdir MyDataset/NotoSansCJKsc-Bold
!mkdir MyDataset/NotoSansCJKsc-DemiLight
!mkdir MyDataset/NotoSansCJKsc-Light
!mkdir MyDataset/NotoSansCJKsc-Medium
!mkdir MyDataset/NotoSansCJKsc-Regular
!mkdir MyDataset/NotoSansCJKsc-Thin
!mkdir MyDataset/NotoSerifCJKsc-Black
!mkdir MyDataset/NotoSerifCJKsc-Bold
!mkdir MyDataset/NotoSerifCJKsc-ExtraLight
!mkdir MyDataset/NotoSerifCJKsc-Light
!mkdir MyDataset/NotoSerifCJKsc-Medium
!mkdir MyDataset/NotoSerifCJKsc-Regular
!mkdir MyDataset/NotoSerifCJKsc-SemiBold
from tqdm import tqdm
for name in fileList:
print(name)
font_dir = 'MyDataset/' + f[:-4]
font_path = 'cn-fonts/'
font = ImageFont.truetype(font_path + name, 196)
font1 = TTFont(font_path + name)
text_width, text_height = font.getsize(name[:-4])
for i in tqdm(font1.getBestCmap()):
image = Image.new(mode='RGBA', size=(text_width, text_height))
draw_table = ImageDraw.Draw(im=image)
if i < 100:
draw_table.text(xy=(0, 0), text=chr(i), fill='#000000', font=font) # text是要显示的文本,我们可以直接生成ascii字符,也可以考虑在此处引入一个字典,逐字生成图片
image.save('MyDataset/' + name[:-4] + '/' + str(i) + '.png')
# 数据集划分
!paddlex --split_dataset --format ImageNet --dataset_dir MyDataset --val_value 0.2 --test_value 0.1
5 小结
对于从字体转图片这个任务,在本项目中,对多种形式的字体分类识别数据集完成了准备。
当然,挑战才刚刚开始,字体分类这个任务,究竟用哪种模型才能达到较好的效果?还是要引入匹配算法?
后续项目中,将开始更加深入的探讨。

学大模型,用大模型上飞桨星河社区!每天8点V100G算力免费领!免费领取ERNIE 4.0 100w Token >>>
更多推荐



 2
2 0
0- 0



 已为社区贡献1436条内容
已为社区贡献1436条内容

所有评论(0)