
Android Malware Detection with Seq2vec
Android Malware Detection with Seq2vec基于Seq2vec的安卓恶意软件检测,数据集取自CICMalDroid 2020,并进行了特征提取。引言最近在做Android恶意软件静态检测的研究,此前发布了两个版本,都对Android恶意软件有很高的识别率,现在尝试用Seq2vec的方法进行Android恶意软件检测。我尝试使用了Bi-LSTM、CNN,发现,Bi-L
Android Malware Detection with Seq2vec
基于Seq2vec的安卓恶意软件检测,数据集取自CICMalDroid 2020,并进行了特征提取。
引言
最近在做Android恶意软件静态检测的研究,此前发布了两个版本,都对Android恶意软件有很高的识别率,现在尝试用Seq2vec的方法进行Android恶意软件检测。我尝试使用了Bi-LSTM、CNN,发现,Bi-LSTM实在训练太慢,而CNN网络不但训练快,而且训练集上准确度可以达到97%以上,验证集以及测试集准确度都能达到93%以上。
先前版本如下:
Android Malware Detection with N-gram
1 数据获取
我们的Android应用数据来自加拿大网络安全研究所的CICMalDroid 2020,该Android应用数据集收录了包括4033个良性软件(Benign)、1512个广告软件(Adware)、2467个网银木马(Banking Malware)、3896个手机风险软件(Mobile Riskware)以及4809个SMS恶意软件。
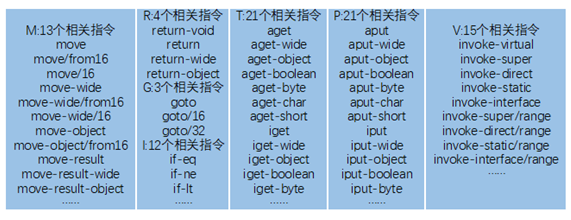
使用Google提供的反编译工具—Apktool对Apk文件进行反编译,并获取了其中的用于在Dalvik虚拟机上运行的主要源码文件—smali文件,批量反编译以及提取特征的脚本文件见上方的先前版本,这里不再提供。smali是对Dalvik字节码的一种解释,虽然不是官方标准语言,但所有语句都遵循一套语法规范。由于Dalvik指令有两百多条,对此我们进行了分类与精简,去掉了无关的指令,只留下了M、R、G、I、T、P、V七大类核心的指令集合,并且只保留操作码字段,去掉了参数。M、R、G、I、T、P、V七大类指令集合分别代表了移动、返回、跳转、判断、取数据、存数据、调用方法七种类型的指令,具体分类如下图所示。
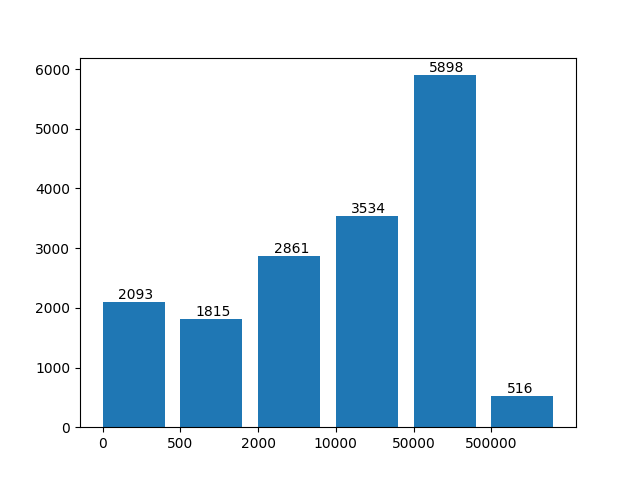
对此特征提取后的数据集进行统计发现,特征最短长度为10,最长可达到1,104,801,其概率分布如下,可见分布极不均衡且数据长度单位可以万计。
# 下载paddlenlp
#!pip install --upgrade paddlenlp -i https://pypi.org/simple
2 导入所需要的包
import os
import numpy as np
import pandas as pd
from functools import partial
from utils import load_vocab, convert_example
from sklearn.model_selection import train_test_split
from matplotlib import pyplot as plt
import paddle
import paddle.nn as nn
import paddle.nn.functional as F
import paddlenlp as ppnlp
from paddlenlp.data import Pad, Stack, Tuple
from paddlenlp.datasets import MapDataset
from Model import CNNModel
import datetime
start=datetime.datetime.now()
3 数据集和数据处理
自定义数据集
除了七大类指令外,原始数据字典还包括了分隔符|以及填充符#,数据读取同样依照压缩比率进行词汇的划分,并使用填充符#进行末位单词的补足。
-
data_split: 按照rate进行数据划分,train_size=origin_size*(1-rate)*(1-rate)test_size=origin_size*rateeval_size=origin_size*(1-rate)*rate -
vocab_compress: vocab压缩,dict随着rate指数级增长,即dict_size=vocab_dict_size^rate,这里rate设为6
#数据集划分
def data_split(input_file, output_path, rate=0.2):
if not os.path.exists(output_path):
os.makedirs(output_path)
origin_dataset = pd.read_csv(input_file, header=None)[[1,2]] # 加入参数
train_data, test_data = train_test_split(origin_dataset, test_size=rate)
train_data, eval_data = train_test_split(train_data, test_size=rate)
train_filename = os.path.join(output_path, 'train.txt')
test_filename = os.path.join(output_path, 'test.txt')
eval_filename = os.path.join(output_path, 'eval.txt')
train_data.to_csv(train_filename, index=False, sep="\t", header=None)
test_data.to_csv(test_filename, index=False, sep="\t", header=None)
eval_data.to_csv(eval_filename, index=False, sep="\t", header=None)
if not os.path.exists('dataset'):
os.mkdir('dataset')
#这里可以使用data_split函数重新划分数据集,也可以将我已经划分的数据集通过cp的方式复制到dataset文件夹下,两种方式请选择一个
#data_split(input_file='data/data86222/mydata.csv',output_path='dataset', rate=0.2)
!cp data/data86222/train.txt dataset/ && cp data/data86222/eval.txt dataset/ && cp data/data86222/test.txt dataset/
vocab_dict={0:'#',1:'|',2:'M',3:'R',4:'G',5:'I',6:'T',7:'P',8:'V'}
#vocab压缩,dict随着rate指数级增长,即len(dict)=len(vocab_dict)^rate
#默认rate=4,建议可以设置为2、4、6、8,其中8容易爆显存
def vocab_compress(vocab_dict,rate=4):
if rate<=0:
return
with open('dict.txt','w',encoding='utf-8') as fp:
arr=np.zeros(rate,int)
while True:
pos=rate-1
for i in range(rate):
fp.write(vocab_dict[arr[i]])
fp.write('\n')
arr[pos]+=1
while True:
if arr[pos]>=len(vocab_dict):
arr[pos]=0
pos-=1
if pos<0:
return
arr[pos]+=1
else:
break
rate=6
pad=''
unk=''
for i in range(rate):
pad+='#'
unk+='|'
#vocab_compress(vocab_dict,rate)
加载词表
from paddlenlp.datasets import load_dataset
def read(data_path):
with open(data_path, 'r', encoding='utf-8') as f:
for line in f:
l = line.strip('\n').split('\t')
if len(l) != 2:
print (len(l), line)
words, labels = line.strip('\n').split('\t')
if len(words)==0:
continue
yield {'tokens': words, 'labels': labels}
# data_path为read()方法的参数
train_ds = load_dataset(read, data_path='dataset/train.txt',lazy=False)
dev_ds = load_dataset(read, data_path='dataset/eval.txt',lazy=True)
test_ds = load_dataset(read, data_path='dataset/test.txt',lazy=True)
# 加载词表
vocab = load_vocab('dict.txt')
#print(vocab)
为了将原始数据处理成模型可以读入的格式,本项目将对数据作以下处理:
-
首先使用切词,每隔压缩比率
rate切为一个词,之后将切完后的单词映射词表中单词id。 -
使用
paddle.io.DataLoader接口多线程异步加载数据。
其中用到了PaddleNLP中关于数据处理的API。PaddleNLP提供了许多关于NLP任务中构建有效的数据pipeline的常用API
| API | 简介 |
|---|---|
paddlenlp.data.Stack |
堆叠N个具有相同shape的输入数据来构建一个batch,它的输入必须具有相同的shape,输出便是这些输入的堆叠组成的batch数据。 |
paddlenlp.data.Pad |
堆叠N个输入数据来构建一个batch,每个输入数据将会被padding到N个输入数据中最大的长度 |
paddlenlp.data.Tuple |
将多个组batch的函数包装在一起 |
更多数据处理操作详见: https://github.com/PaddlePaddle/PaddleNLP/blob/develop/docs/data.md
构造dataloder
下面的create_data_loader函数用于创建运行和预测时所需要的DataLoader对象。
-
paddle.io.DataLoader返回一个迭代器,该迭代器根据batch_sampler指定的顺序迭代返回dataset数据。异步加载数据。 -
batch_sampler:DataLoader通过 batch_sampler 产生的mini-batch索引列表来 dataset 中索引样本并组成mini-batch -
collate_fn:指定如何将样本列表组合为mini-batch数据。传给它参数需要是一个callable对象,需要实现对组建的batch的处理逻辑,并返回每个batch的数据。在这里传入的是prepare_input函数,对产生的数据进行pad操作,并返回实际长度等。
# Reads data and generates mini-batches.
def create_dataloader(dataset,
trans_function=None,
mode='train',
batch_size=1,
pad_token_id=0,
batchify_fn=None):
if trans_function:
dataset_map = dataset.map(trans_function)
# return_list 数据是否以list形式返回
# collate_fn 指定如何将样本列表组合为mini-batch数据。传给它参数需要是一个callable对象,需要实现对组建的batch的处理逻辑,并返回每个batch的数据。在这里传入的是`prepare_input`函数,对产生的数据进行pad操作,并返回实际长度等。
dataloader = paddle.io.DataLoader(
dataset_map,
return_list=True,
batch_size=batch_size,
collate_fn=batchify_fn)
return dataloader
# python中的偏函数partial,把一个函数的某些参数固定住(也就是设置默认值),返回一个新的函数,调用这个新函数会更简单。
trans_function = partial(
convert_example,
vocab=vocab,
rate=rate,
unk_token_id=vocab.get(unk),
is_test=False)
# 将读入的数据batch化处理,便于模型batch化运算。
# batch中的每个句子将会padding到这个batch中的文本最大长度batch_max_seq_len。
# 当文本长度大于batch_max_seq时,将会截断到batch_max_seq_len;当文本长度小于batch_max_seq时,将会padding补齐到batch_max_seq_len.
batchify_fn = lambda samples, fn=Tuple(
Pad(axis=0, pad_val=vocab[pad]), # input_ids
Stack(dtype="int64"), # seq len
Stack(dtype="int64") # label
): [data for data in fn(samples)]
train_loader = create_dataloader(
train_ds,
trans_function=trans_function,
batch_size=4,
mode='train',
batchify_fn=batchify_fn)
dev_loader = create_dataloader(
dev_ds,
trans_function=trans_function,
batch_size=4,
mode='validation',
batchify_fn=batchify_fn)
test_loader = create_dataloader(
test_ds,
trans_function=trans_function,
batch_size=4,
mode='test',
batchify_fn=batchify_fn)
4 模型搭建
使用CNNEncoder搭建一个CNN模型用于进行句子建模,得到句子的向量表示。
然后接一个线性变换层,完成二分类任务。
paddle.nn.Embedding组建word-embedding层ppnlp.seq2vec.CNNEncoder组建句子建模层paddle.nn.Linear构造多分类器

- 除CNNEncoder外,
seq2vec还提供了许多语义表征方法,详细可参考:seq2vec介绍
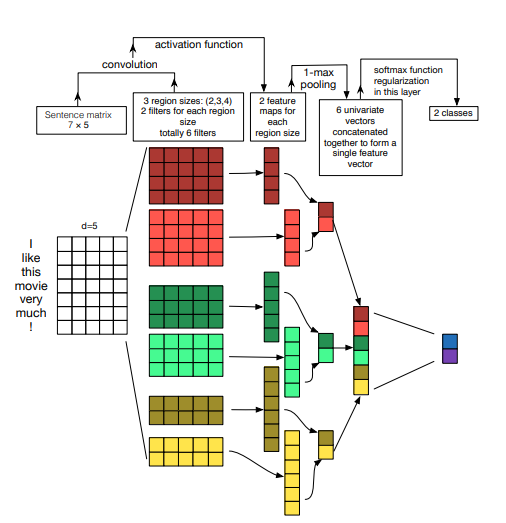
这里使用的CNNEncoer,基于论文“A Sensitivity Analysis of (and Practitioners’ Guide to) Convolutional Neural Networks for Sentence Classification”,原理如下图:
model= CNNModel(
len(vocab),
num_classes=5,
padding_idx=vocab[pad])
model = paddle.Model(model)
# 加载模型
#model.load('./checkpoints/final')
5 模型配置和训练
模型配置
optimizer = paddle.optimizer.Adam(
parameters=model.parameters(), learning_rate=1e-5)
loss = paddle.nn.loss.CrossEntropyLoss()
metric = paddle.metric.Accuracy()
model.prepare(optimizer, loss, metric)
# 设置visualdl路径
log_dir = './visualdl'
callback = paddle.callbacks.VisualDL(log_dir=log_dir)
模型训练
训练过程中会输出loss、acc等信息。这里设置了10个epoch,在训练集上准确率约97%。

model.fit(train_loader, dev_loader, epochs=50, log_freq=50, save_dir='./checkpoints', save_freq=1, eval_freq=1, callbacks=callback)
end=datetime.datetime.now()
print('Running time: %s Seconds'%(end-start))
计算模型准确率
results = model.evaluate(train_loader)
print("Finally train acc: %.5f" % results['acc'])
results = model.evaluate(dev_loader)
print("Finally eval acc: %.5f" % results['acc'])
results = model.evaluate(test_loader)
print("Finally test acc: %.5f" % results['acc'])
6 查看最终预测
label_map = {0: 'benign', 1: 'adware', 2:'banking', 3:'riskware', 4:'sms'}
results = model.predict(test_loader, batch_size=128)
predictions = []
for batch_probs in results:
# 映射分类label
idx = np.argmax(batch_probs, axis=-1)
idx = [idx.tolist()]
labels = label_map[i] for i in idx
predictions.extend(labels)
# 看看预测数据前5个样例分类结果
for i in test_ds:
print(i)
break
for idx, data in enumerate(test_ds):
if idx < 10:
print(type(data))
abels)
# 看看预测数据前5个样例分类结果
for i in test_ds:
print(i)
break
for idx, data in enumerate(test_ds):
if idx < 10:
print(type(data))
print('Data: {} \t Label: {}'.format(data[0], predictions[idx]))
7 小结
CNNEncoder实在是太强了,本次使用1e-5的lr训练了50epoch,然后改为1e-6的lr再做了10次epoch,就达到了上述所说的效果,其中,CNNEncoder的ngram_filter_sizes=(1, 2, 3, 4),num_filter=12就完全足够,若小伙伴有兴趣可以尝试更多的num_filter,来提高精度
请点击此处查看本环境基本用法.
Please click here for more detailed instructions.

学大模型,用大模型上飞桨星河社区!每天8点V100G算力免费领!免费领取ERNIE 4.0 100w Token >>>
更多推荐



 0
0 0
0- 0



 已为社区贡献1436条内容
已为社区贡献1436条内容

所有评论(0)