
基于多通道标签和极坐标变换的视杯视盘联合分割
参考PaddleSeg逻辑结构,设计多通道标签和损失函数,搭建多尺度网络,实现视杯视盘联合分割。
0 项目引言
在前一个项目 基于PaddleX和PaddleSeg的眼底彩照视盘分割 中,提供了基于目标检测的视盘区域裁剪方法,构建了自定义 PaddleSeg 模型 M-Net 进行视盘的 2 类别分割。
原 MNet 模型的输出通道数为 2,使用 Sigmoid 分别对每个通道做 2 类分割,如果我们想要使用 PaddleSeg 自定义组件构建 MNet,虽然可以通过 1x1 卷积将输出通道由 2 转变为 3 进行 Softmax + Argmax(本次项目的数据是 3 类别:背景,视盘,视杯。),但引文的标签构建方法独具特色(使用 3 通道 PNG),所以本项目以此为契机,手动实现全流程:项目各个模块的结构参考 PaddleSeg-API,增进对 PaddleSeg-API 代码组织和细节的了解,方便以后提交PR。
源码地址:https://github.com/ucsk/optic-disc-cup-segmentation 。
1 数据说明
本项目背景是 GAMMA 挑战赛下之任务三,对2D眼底图像中的视杯和视盘结构进行分割:将2D眼底图像中的视盘和视杯区域分割出来。分割结果中视盘区域像素值置为128,视杯区域像素值置为0,其他区域像素值置为255。
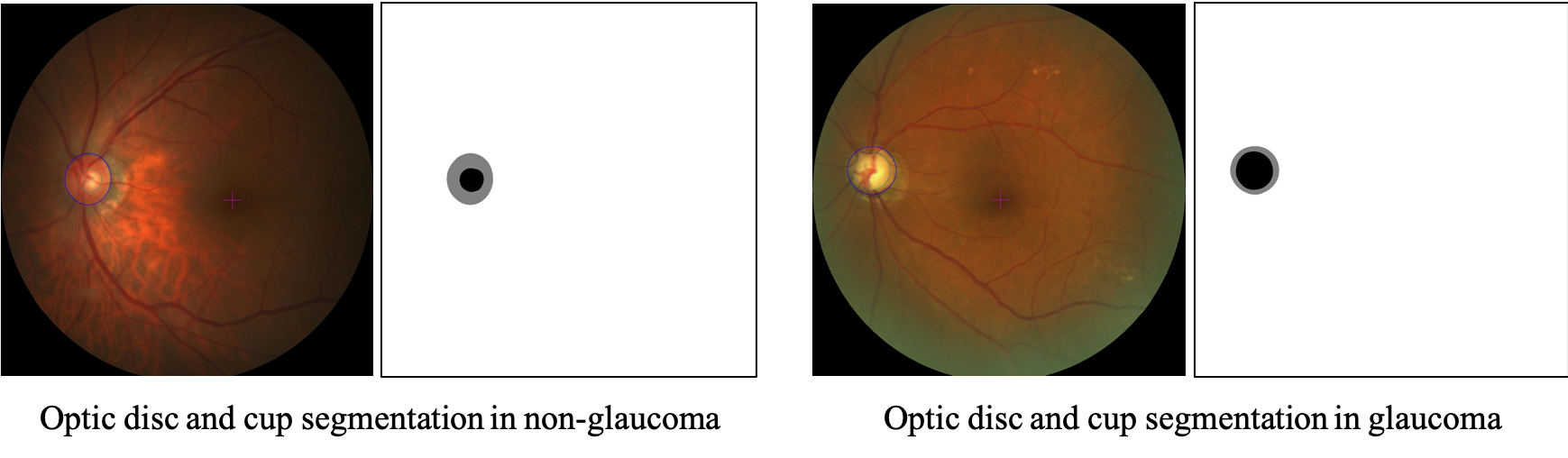
1.1 数据背景
本数据集由中国广州中山大学中山眼科中心提供,数据集中包含200个2D眼底彩照样本,分别为:训练集100对,测试集100对。
制作方式: 各样本的初始视杯视盘分割区域标注由中国中山大学中山眼科中心4名临床眼科医生手动完成。这4名医生在没有获得任何患者信息或数据中疾病流行情况的情况下,独立对图像中视盘和视杯区域进行勾勒。随后,4个初始标注结果汇总给任务二中的更高级医生进行融合。视杯视盘分割结果的融合采用多数投票的方式,融合医生检查初始的分割标注,并选择取哪几位医生标注结果的交集作为最终视杯视盘分割金标准。
1.2 数据描述
训练集; 训练数据集包括100个样本0001-0100,每个样本对应一个2D眼底彩照数据,存储为0001.jpg。
视杯视盘分割金标准以bmp图像格式存储,每个样本的眼底图像对应一个视杯视盘分割结果图像。分割结果图像命名与输入的待分割眼底图像命名前缀一致。分割图像中,像素值为0代表视杯区域、像素值为128代表视盘中非视杯区域、像素值为255代表其他区域。所有样本的分割图像存储在 Disc_Cup_Masks 文件夹中。
测试集: 测试数据集包括100个样本的数据对0101-0200,数据存储格式与训练集中一致。
2 方案架构
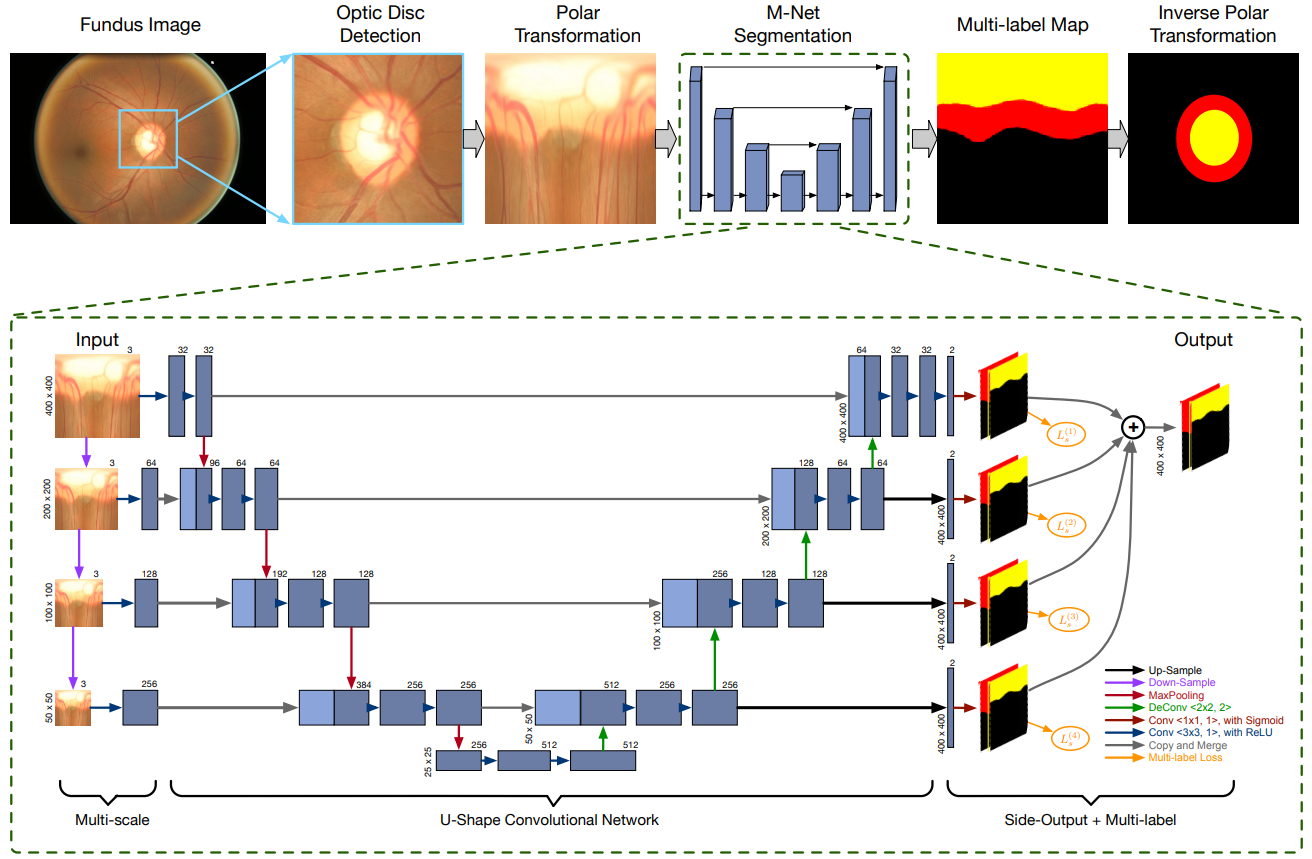
与前一个数据集相比,该数据在视盘分割的基础上还需要分割视杯,三类别语义分割任务。整体的流程还是按照引文的框架进行,其中 ROI 裁剪与还原已经在 基于PP-YOLO Tiny和M-Net的眼底彩照视盘分割 详细阐述。
-
根据训练集标注图,利用图形学获取视盘边框以生成目标检测训练集,通过训练 PP-YOLO Tiny ROI 检测器预测候选区域中心 (x, y),以中心点扩展裁剪得到尺寸为 (512, 512) 的视盘候选区域(该部分已经在上一个项目中实现了,模型地址为 眼底彩照中视盘目标检测模型);
-
将裁减得到的候选数据进行极坐标变换,将椭圆语义约束修改为常规语义约束;
-
该模型对 U-Net 进行改进:
- 对输入进行 3 次平均池化,其分别对应一个卷积层,实现多尺度输入。
- 对多尺度输入层的解码层进行上采样以恢复到输入层的大小,而后进行 1x1 卷积统一输出通道数为 2,2 个通道分别为背景和视杯、视盘的 sigmoid 二分类任务。
- 训练阶段的损失计算方式为,4 个层级输出加上 1 个平均层;预测阶段仅使用平均层,以上的深度监督训练利于梯度回传,加快收敛。
3 训练数据与标签
3.1 数据准备
!pip install paddlex
!pip install paddleseg
!pip install scikit-image
import warnings
warnings.filterwarnings('ignore')
import os
import shutil
import glob
import paddle
import paddlex
import paddleseg
import numpy as np
import pandas as pd
import cv2
import imghdr
from PIL import Image
import matplotlib.pyplot as plt
%matplotlib inline
该数据包含训练集100+100张,测试集 100 张;下载好之后统一一下文件夹名称。
!wget https://dataset-bj.cdn.bcebos.com/%E5%8C%BB%E7%96%97%E6%AF%94%E8%B5%9B/task3_disc_cup_segmentation.zip -O data/dataset.zip
!unzip -oq data/dataset.zip -d data/
!mv data/training/fundus\ color\ images data/training/images
!mv data/training/Disc_Cup_Mask data/training/labels
!mv data/testing/fundus\ color\ images data/testing/images
将图片和标签的尺寸对齐,编码格式统一为 JPG(RGB)/PNG(L)。
image_path_list = sorted(glob.glob('data/training/images/*.jpg'))
for i in range(len(image_path_list)):
image_path = image_path_list[i]
image_name = str(image_path.split('/')[-1]).split('.')[0]
gt_path = os.path.join('data/training/labels', f'{image_name}.png')
assert imghdr.what(image_path) and imghdr.what(gt_path)
img = Image.open(image_path).convert('RGB')
gt = Image.open(gt_path).convert('L')
if img.size != gt.size:
img = img.resize(gt.size, Image.ANTIALIAS)
img.save(image_path)
cv2.imwrite(gt_path, np.array(gt, dtype='uint8'))
image_path_list = sorted(glob.glob('data/testing/images/*.jpg'))
for i in range(len(image_path_list)):
image_path = image_path_list[i]
assert imghdr.what(image_path)
img = Image.open(image_path).convert('RGB')
img.save(image_path)
整理好的数据目录结构如下。
!tree data -d
data
├── data119773
├── testing
│ └── images
└── training
├── images
└── labels
6 directories
3.2 视盘检测
该部分已经在此项目中:基于PaddleX和PaddleSeg的眼底彩照视盘分割[章节3] 实现,挂载在 data/data119773/PPYOLOTiny.zip。
将代码和模型克隆到本地,切换工作目录(后续需要注意相对路径);后续将组件导入到notebook中使用。
注意左边文件夹,已经克隆好了。
!git clone https://github.com/ucsk/optic-disc-cup-segmentation.git
%cd optic-disc-cup-segmentation/
/home/aistudio/optic-disc-cup-segmentation
将清洗好的数据移动到项目的根目录中来。
!mkdir data/
!mv /home/aistudio/data/training data/training
!mv /home/aistudio/data/testing data/testing
3.3 视盘裁剪
首先定义好检测器路径和将要裁剪的图片文件夹路径,传入 image_dir 和 label_dir(可选) 将会被裁剪成 Patches。
from utils.crop_patches import DiscCrop
train_crop = DiscCrop(
model_path='utils/PPYOLOTiny',
image_dir='data/training/images',
label_dir='data/training/labels')
test_crop = DiscCrop(
model_path='utils/PPYOLOTiny',
image_dir='data/testing/images')
开始裁剪,裁剪保存位置和数据文件夹位置是平级的,文件夹末尾会加上 _patch。
train_crop.crop(write_file=True)
test_crop.crop(write_file=True)
模型训练和预测的是 Patches,所以结束之后将裁剪的 Patches 复原成笛卡尔坐标下的原图尺寸。这里将所有刚裁剪下来的的 Patches 都复原。
train_crop.paste_origin(
patch_dir='data/training/images_patch')
train_crop.paste_origin(
patch_dir='data/training/labels_patch')
test_crop.paste_origin(
patch_dir='data/testing/images_patch')
以下就是经过裁剪和复原之后数据的目录情况。
!tree data/ -d
data/
├── testing
│ ├── images
│ ├── images_patch
│ └── images_patch_pasted
└── training
├── images
├── images_patch
├── images_patch_pasted
├── labels
├── labels_patch
└── labels_patch_pasted
11 directories
数据可视化: 原图,裁剪图和复原图的对比效果。
image_list = ['data/training/images/0001.jpg', 'data/training/images_patch/0001.jpg', 'data/training/images_patch_pasted/0001.jpg']
for gt_path in [path.replace('.jpg', '.png') for path in [path.replace('images', 'labels') for path in image_list]]:
image_list.append(gt_path)
plt.figure(figsize=(8, 5))
for i in range(6):
plt.subplot(int('23'+str(i+1)))
if i < len(image_list) // 2:
plt.title(['Origin Image', 'Crop Patch', 'Pasted Image'][i])
img = cv2.imread(image_list[i])
img = cv2.cvtColor(img, cv2.COLOR_BGR2RGB)
else:
img = cv2.imread(image_list[i], cv2.IMREAD_GRAYSCALE)
plt.imshow(img)
plt.tight_layout()
plt.show()
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-WpV9XqYR-1639096006826)(output_30_0.png)]](https://i-blog.csdnimg.cn/blog_migrate/40319fdb1f6da3318459a570a7b91456.png)
3.4 数据划分与标签制作
首先数据划分,生成训练列表和验证列表,代码中配置的是80%(80)训练 + 20%(20)验证。
生成了如下文件:
data/training/train_list.txtdata/training/val_list.txt
%cd utils/
!python dataset_split.py
%cd ..
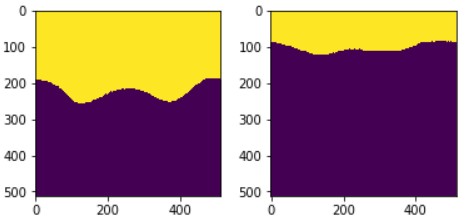
常规的语义分割标签都是单通道图像,一个数值(从0开始递增)的是一个类别;但我们要做的是生成 2 通道标签(当然,因为不支持 2 通道图像,所以用 3 通道 PNG 代替,计算损失时候将最后通道丢弃即可)。

下面生成三通道标注图(下面单元格中的label_t),其中通道 B 表示 {背景 / 视盘+视杯} 二分类;通道 G 表示 {背景 / 视杯} 二分类;通道 R 置为 0。
label_path_list = sorted(glob.glob('data/training/labels_patch/*.png'))
for path in label_path_list:
label = cv2.imread(path, cv2.IMREAD_GRAYSCALE)
label_t = np.zeros(shape=label.shape+(3,), dtype='uint8')
label_t[:, :, 0] = np.where(label != 255, 1, 0)
label_t[:, :, 1] = np.where(label == 0, 1, 0)
cv2.imwrite(path, label_t)
因为制作完成之后数值 1 的图片显示不明显。这里我们挑选图片,拆分各个验证一下是否成功。
image = cv2.imread('data/training/labels_patch/0001.png')
plt.figure(figsize=(8, 5))
for i in range(3):
plt.subplot(int('13'+str(i+1)))
plt.imshow(image[:, :, i])
plt.tight_layout()
plt.show()
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-6vKxswLo-1639096006827)(output_37_0.png)]](https://i-blog.csdnimg.cn/blog_migrate/cc3f49d9916b1471f6ce568bcc213b21.png)
可以观察到通道 BG 和 R 都是被正确赋值的,训练图像和标签(data/training/{images_patch, labels_patch})都制作完成了。
4 组件构建与调试
本步骤主要是对各个模块进行设计和测试,要实际开始执行训练和预测则是在章节5。
4.1 数据加载器
我们使用 PaddleSeg 内置的数据变换方法 transforms.py。
在 Dataset 的设计中,需要注意 paddleseg.transforms.Compose() 会将图片的 HWC 改为 CHW,但标签却不变,并且标签是用 PIL.Image 读取的,所以我们为了统一,也对标签转换为 CHW 和 BGR 顺序。

执行 DataLoader(batch_size=10) 调试程序。
!python dataset.py
4.2 分割模型
训练时是4个尺度的输出和他们的平均这5个,并且加上了 Sigmoid 激活函数,后续对模型的输出处理就是以 0.5 为阈值了。
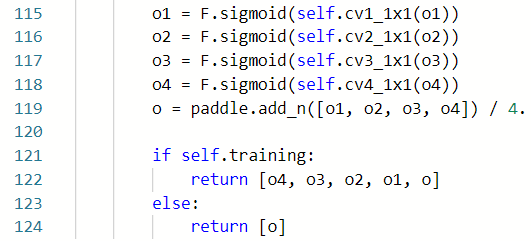
本项目的模型对原模型的卷积层增加了批归一化层,以下调试是打印模型结构。
!python models.py
4.3 损失函数
因为标签中的 1 个通道对应 2 个类别,我们设计了对 2 个通道分别求 Dice Loss 并加权求和的方式计算损失;注意此处是 NCHW,在数据读取阶段已经处理了。

执行调试程序,计算随机输入的损失情况。
!python losses.py
/opt/conda/envs/python35-paddle120-env/lib/python3.7/site-packages/paddle/fluid/dygraph/math_op_patch.py:253: UserWarning: The dtype of left and right variables are not the same, left dtype is paddle.float32, but right dtype is paddle.int32, the right dtype will convert to paddle.float32
format(lhs_dtype, rhs_dtype, lhs_dtype))
/opt/conda/envs/python35-paddle120-env/lib/python3.7/site-packages/paddle/fluid/dygraph/math_op_patch.py:253: UserWarning: The dtype of left and right variables are not the same, left dtype is paddle.float32, but right dtype is paddle.int64, the right dtype will convert to paddle.float32
format(lhs_dtype, rhs_dtype, lhs_dtype))
Tensor(shape=[1], dtype=float32, place=CUDAPlace(0), stop_gradient=True,
[0.49935663])
4.4 评估函数
为了训练时候能指导模型训练的效果,设计一个 val.evaluate() 以在训练时评估。
其中,我们为了计算的方便,将会调用 PaddleSeg 自带评估组件,所以我们设计了两个函数来对模型输出的 [2, H, W] 转变为 [H, W] 常规标注图;其中主要是对模型输出和多通道标签统一为单通道标签的两个转换函数。

评估模块调试,利用刚构建的随机参数模型在验证集上进行评估。
!python val.py
W1208 19:33:02.879942 1391 device_context.cc:447] Please NOTE: device: 0, GPU Compute Capability: 7.0, Driver API Version: 10.1, Runtime API Version: 10.1
W1208 19:33:02.885793 1391 device_context.cc:465] device: 0, cuDNN Version: 7.6.
Start evaluating (total_samples: 20, total_iters: 20)...
[EVAL] #Images: 20 mIoU: 0.1720 Acc: 0.3737 Kappa: 0.0971
[EVAL] Class IoU:
[0.1475 0.019 0.3495]
[EVAL] Class Acc:
[0.9903 0.0762 0.3497]
4.5 训练函数
这个部分要调试的话相当于直接进行训练了,所以后续将函数导入进来使用。该函数主要是模型训练的常规流程,打印日志和模型保存等等。

4.6 预测函数
这个部分也放最后再演示吧,主要是模型推理结果的处理:2 个通道分别以 0.5 为阈值分为背景和{视杯+视盘, 视杯},转换为单通道灰度图。

5 训练与预测
5.1 模型训练
下面就将各个组件都导入进来,开始模型训练和评估(main.py),有需要的话在各个组件文件中修改需要的细节。
其实这个流程和 PaddleSeg-API 很像,因为笔者就是参照学习该项目的源码。
# 注意:如果执行出现了问题,重启内核后需要先切换默认的相对路径
%cd optic-disc-cup-segmentation
/home/aistudio/optic-disc-cup-segmentation
import paddle
from transforms import train_transforms, val_transforms
from dataset import OpticDisc
from models import MNet
from losses import MultiChannelsDiceLoss
from train import train
from predict import predict
首先定义数据集类和相应的数据变换方法。
train_db = OpticDisc(
db_root='data/training',
file_path='data/training/train_list.txt',
transforms=train_transforms)
val_db = OpticDisc(
db_root='data/training',
file_path='data/training/val_list.txt',
transforms=val_transforms)
常规流程:初始化训练模型,配置优化器、损失函数,相应的超参数设置。
model = MNet()
num_iters = 5000
train_batch_size = 4
learning_rate = 0.005
decayed_lr = paddle.optimizer.lr.CosineAnnealingDecay(
learning_rate=learning_rate,
T_max=num_iters)
decayed_lr = paddle.optimizer.lr.LinearWarmup(
learning_rate=decayed_lr,
warmup_steps=500,
start_lr=0.0,
end_lr=learning_rate)
optimizer = paddle.optimizer.Momentum(
learning_rate=decayed_lr,
momentum=0.9,
weight_decay=paddle.regularizer.L2Decay(5e-4),
parameters=model.parameters())
losses = {
'types': [MultiChannelsDiceLoss()] * 5,
'coef': [0.05, 0.1, 0.2, 0.4, 0.75]}
装载参数,开始训练。因为样本比较少,所以不同超参数配置下的指标波动还是有的,例如损失函数权重、学习率等。
train(
model=model,
train_db=train_db,
val_db=val_db,
optimizer=optimizer,
losses=losses,
batch_size=train_batch_size,
max_iter=num_iters,
log_per_iter=100,
save_per_iter=500,
save_dir='output/MNet')
[TRAIN] epoch: 5, iter: 100/5000, loss: 0.7918, lr: 0.000990
[TRAIN] epoch: 10, iter: 200/5000, loss: 0.5967, lr: 0.001990
[TRAIN] epoch: 15, iter: 300/5000, loss: 0.4918, lr: 0.002990
[TRAIN] epoch: 20, iter: 400/5000, loss: 0.4174, lr: 0.003990
[TRAIN] epoch: 25, iter: 500/5000, loss: 0.3638, lr: 0.004990
Start evaluating (total_samples: 20, total_iters: 20)...
[EVAL] #Images: 20 mIoU: 0.6116 Acc: 0.7916 Kappa: 0.6724
[EVAL] Class IoU:
[0.8432 0.3472 0.6443]
[EVAL] Class Acc:
[0.9366 0.6493 0.6849]
[EVAL] The model with the best validation mIoU (0.6116) was saved at iter 500.
[TRAIN] epoch: 30, iter: 600/5000, loss: 0.3168, lr: 0.004995
[TRAIN] epoch: 35, iter: 700/5000, loss: 0.2789, lr: 0.004980
[TRAIN] epoch: 40, iter: 800/5000, loss: 0.2431, lr: 0.004956
[TRAIN] epoch: 45, iter: 900/5000, loss: 0.2142, lr: 0.004922
[TRAIN] epoch: 50, iter: 1000/5000, loss: 0.1921, lr: 0.004878
Start evaluating (total_samples: 20, total_iters: 20)...
[EVAL] #Images: 20 mIoU: 0.7158 Acc: 0.8496 Kappa: 0.7620
[EVAL] Class IoU:
[0.8077 0.5629 0.7767]
[EVAL] Class Acc:
[0.8707 0.7667 0.8723]
[EVAL] The model with the best validation mIoU (0.7158) was saved at iter 1000.
[TRAIN] epoch: 55, iter: 1100/5000, loss: 0.1835, lr: 0.004825
[TRAIN] epoch: 60, iter: 1200/5000, loss: 0.1704, lr: 0.004763
[TRAIN] epoch: 65, iter: 1300/5000, loss: 0.1662, lr: 0.004692
[TRAIN] epoch: 70, iter: 1400/5000, loss: 0.1602, lr: 0.004612
[TRAIN] epoch: 75, iter: 1500/5000, loss: 0.1509, lr: 0.004523
Start evaluating (total_samples: 20, total_iters: 20)...
[EVAL] #Images: 20 mIoU: 0.7658 Acc: 0.8825 Kappa: 0.8156
[EVAL] Class IoU:
[0.8704 0.6075 0.8194]
[EVAL] Class Acc:
[0.9357 0.799 0.8612]
[EVAL] The model with the best validation mIoU (0.7658) was saved at iter 1500.
[TRAIN] epoch: 80, iter: 1600/5000, loss: 0.1450, lr: 0.004427
[TRAIN] epoch: 85, iter: 1700/5000, loss: 0.1415, lr: 0.004323
[TRAIN] epoch: 90, iter: 1800/5000, loss: 0.1348, lr: 0.004213
[TRAIN] epoch: 95, iter: 1900/5000, loss: 0.1309, lr: 0.004095
[TRAIN] epoch: 100, iter: 2000/5000, loss: 0.1254, lr: 0.003971
Start evaluating (total_samples: 20, total_iters: 20)...
[EVAL] #Images: 20 mIoU: 0.7900 Acc: 0.8956 Kappa: 0.8367
[EVAL] Class IoU:
[0.8856 0.6461 0.8384]
[EVAL] Class Acc:
[0.9527 0.8031 0.8792]
[EVAL] The model with the best validation mIoU (0.7900) was saved at iter 2000.
[TRAIN] epoch: 105, iter: 2100/5000, loss: 0.1211, lr: 0.003841
[TRAIN] epoch: 110, iter: 2200/5000, loss: 0.1192, lr: 0.003706
[TRAIN] epoch: 115, iter: 2300/5000, loss: 0.1164, lr: 0.003566
[TRAIN] epoch: 120, iter: 2400/5000, loss: 0.1129, lr: 0.003422
[TRAIN] epoch: 125, iter: 2500/5000, loss: 0.1105, lr: 0.003274
Start evaluating (total_samples: 20, total_iters: 20)...
[EVAL] #Images: 20 mIoU: 0.8078 Acc: 0.9053 Kappa: 0.8526
[EVAL] Class IoU:
[0.9041 0.6835 0.8357]
[EVAL] Class Acc:
[0.9812 0.8156 0.8677]
[EVAL] The model with the best validation mIoU (0.8078) was saved at iter 2500.
[TRAIN] epoch: 130, iter: 2600/5000, loss: 0.1082, lr: 0.003123
[TRAIN] epoch: 135, iter: 2700/5000, loss: 0.1032, lr: 0.002970
[TRAIN] epoch: 140, iter: 2800/5000, loss: 0.1001, lr: 0.002815
[TRAIN] epoch: 145, iter: 2900/5000, loss: 0.0988, lr: 0.002659
[TRAIN] epoch: 150, iter: 3000/5000, loss: 0.0972, lr: 0.002502
Start evaluating (total_samples: 20, total_iters: 20)...
[EVAL] #Images: 20 mIoU: 0.8197 Acc: 0.9119 Kappa: 0.8628
[EVAL] Class IoU:
[0.9135 0.7015 0.8441]
[EVAL] Class Acc:
[0.9787 0.8162 0.8903]
[EVAL] The model with the best validation mIoU (0.8197) was saved at iter 3000.
[TRAIN] epoch: 155, iter: 3100/5000, loss: 0.0949, lr: 0.002345
[TRAIN] epoch: 160, iter: 3200/5000, loss: 0.0902, lr: 0.002188
[TRAIN] epoch: 165, iter: 3300/5000, loss: 0.0907, lr: 0.002033
[TRAIN] epoch: 170, iter: 3400/5000, loss: 0.0881, lr: 0.001880
[TRAIN] epoch: 175, iter: 3500/5000, loss: 0.0870, lr: 0.001729
Start evaluating (total_samples: 20, total_iters: 20)...
[EVAL] #Images: 20 mIoU: 0.8142 Acc: 0.9084 Kappa: 0.8573
[EVAL] Class IoU:
[0.9071 0.6927 0.8426]
[EVAL] Class Acc:
[0.9726 0.8014 0.9001]
[EVAL] The model with the best validation mIoU (0.8197) was saved at iter 3000.
[TRAIN] epoch: 180, iter: 3600/5000, loss: 0.0864, lr: 0.001581
[TRAIN] epoch: 185, iter: 3700/5000, loss: 0.0845, lr: 0.001437
[TRAIN] epoch: 190, iter: 3800/5000, loss: 0.0836, lr: 0.001297
[TRAIN] epoch: 195, iter: 3900/5000, loss: 0.0817, lr: 0.001162
[TRAIN] epoch: 200, iter: 4000/5000, loss: 0.0809, lr: 0.001032
Start evaluating (total_samples: 20, total_iters: 20)...
[EVAL] #Images: 20 mIoU: 0.8098 Acc: 0.9070 Kappa: 0.8544
[EVAL] Class IoU:
[0.906 0.6807 0.8428]
[EVAL] Class Acc:
[0.9595 0.8128 0.8998]
[EVAL] The model with the best validation mIoU (0.8197) was saved at iter 3000.
[TRAIN] epoch: 205, iter: 4100/5000, loss: 0.0804, lr: 0.000908
[TRAIN] epoch: 210, iter: 4200/5000, loss: 0.0793, lr: 0.000790
[TRAIN] epoch: 215, iter: 4300/5000, loss: 0.0782, lr: 0.000679
[TRAIN] epoch: 220, iter: 4400/5000, loss: 0.0777, lr: 0.000575
[TRAIN] epoch: 225, iter: 4500/5000, loss: 0.0770, lr: 0.000478
Start evaluating (total_samples: 20, total_iters: 20)...
[EVAL] #Images: 20 mIoU: 0.8216 Acc: 0.9125 Kappa: 0.8636
[EVAL] Class IoU:
[0.9134 0.7052 0.8462]
[EVAL] Class Acc:
[0.9724 0.8008 0.9154]
[EVAL] The model with the best validation mIoU (0.8216) was saved at iter 4500.
[TRAIN] epoch: 230, iter: 4600/5000, loss: 0.0767, lr: 0.000390
[TRAIN] epoch: 235, iter: 4700/5000, loss: 0.0763, lr: 0.000310
[TRAIN] epoch: 240, iter: 4800/5000, loss: 0.0769, lr: 0.000239
[TRAIN] epoch: 245, iter: 4900/5000, loss: 0.0777, lr: 0.000176
[TRAIN] epoch: 250, iter: 5000/5000, loss: 0.0754, lr: 0.000123
Start evaluating (total_samples: 20, total_iters: 20)...
[EVAL] #Images: 20 mIoU: 0.8161 Acc: 0.9094 Kappa: 0.8587
[EVAL] Class IoU:
[0.9064 0.6962 0.8458]
[EVAL] Class Acc:
[0.9656 0.8022 0.9121]
[EVAL] The model with the best validation mIoU (0.8216) was saved at iter 4500.
5.2 模型预测
该部分主要是章节3.3的已经演示的内容和 predict.py。
导入视盘区域裁剪类,初始化裁剪图在原图上的坐标信息。
from utils.crop_patches import DiscCrop
test_crop = DiscCrop(
model_path='utils/PPYOLOTiny',
image_dir='data/testing/images')
test_crop.crop(write_file=False)
加载模型,装载已经训练好的参数。
model = MNet()
params_path = 'output/MNet/best_model/model.pdparams'
model_state_dict = paddle.load(params_path)
model.set_dict(model_state_dict)
对裁剪下来的 images_patch/*.jpg 图像进行预测,保存在 output/prediction 中。
test_path_list = sorted(glob.glob('data/testing/images_patch/*.jpg'))
predict(
model=model,
transforms=val_transforms,
image_list=test_path_list,
save_dir='output/prediction')
对预测结果做一个展示,他们其实是 0-127-255 灰度图,下面用的是色调显示。
pred_path_list = [str('output/prediction/%04d.png' % (100+i)) for i in range(50, 59)]
plt.figure(figsize=(8, 4))
for i in range(8):
plt.subplot(int('24'+str(i+1)))
plt.title(pred_path_list[i].split(os.sep)[-1])
pred = cv2.imread(pred_path_list[i], cv2.IMREAD_GRAYSCALE)
plt.imshow(pred)
plt.tight_layout()
plt.show()
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-Fc38UzUC-1639096006830)(output_73_0.png)]](https://i-blog.csdnimg.cn/blog_migrate/121be8e1e267bae8d646364f91db8eec.png)
对模型预测的极坐标 Patches 进行复原,得到 output/prediction_pasted 文件夹。
test_crop.paste_origin(patch_dir='output/prediction')
部分模型预测图和复原图的效果。
test_path_list = []
for i in range(50, 53):
pred_path = 'output/prediction/%04d.png' % (100+i)
test_path_list.append(pred_path)
test_path_list.append(pred_path.replace('prediction', 'prediction_pasted'))
plt.figure(figsize=(8, 10))
grid = str(len(test_path_list) // 2)+'2'
for i in range(0, len(test_path_list), 2):
plt.subplot(int(grid+str(i+1)))
plt.title(test_path_list[i])
plt.imshow(cv2.imread(test_path_list[i], cv2.IMREAD_GRAYSCALE))
plt.subplot(int(grid+str(i+2)))
plt.title(test_path_list[i+1])
plt.imshow(cv2.imread(test_path_list[i+1], cv2.IMREAD_GRAYSCALE))
plt.tight_layout()
plt.show()
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-gYmD73EB-1639096006830)(output_77_0.png)]](https://i-blog.csdnimg.cn/blog_migrate/2255cfbe284b60d675d536c675e6ff53.png)
6 项目总结
通过本项目,对 PaddlePaddle / PaddleSeg-API 的程序细节和代码逻辑有了进一步熟悉,拓展了对语义分割任务程序设计的理解。后续的注意力模块和上下文模块也可以在此模型上进行修改测试;此外,注意到项目结构的扩展性,可尝试构建基于 PaddleSeg 的医学图像分割框架做进一步的学习研究。
项目细节部分难免存在疏漏,欢迎您提供意见或建议。
附 录:
from utils.crop_patches import DiscCrop
from transforms import train_transforms, val_transforms
from dataset import OpticDisc
from models import MNet
from losses import MultiChannelsDiceLoss
from val import evaluate
from train import train
op
from transforms import train_transforms, val_transforms
from dataset import OpticDisc
from models import MNet
from losses import MultiChannelsDiceLoss
from val import evaluate
from train import train
from predict import predict

学大模型,用大模型上飞桨星河社区!每天8点V100G算力免费领!免费领取ERNIE 4.0 100w Token >>>
更多推荐



 0
0 0
0- 0



 已为社区贡献1436条内容
已为社区贡献1436条内容

所有评论(0)