
全流程,从零搞懂图像分割:从数据到预测
自制鸽子数据集,并分别基于Paddle2.3 API和PaddleSeg2.5套件及PaddleX2.1以U-Net网络为例完成鸽子图像的语义分割任务
1. 项目简介
本项目介绍如何从零开始完成一个图像分割任务。通过自建数据集,并分别使用基于Paddle2.3,PaddleSeg2.5和PaddleX2.1的方法完成图像分割任务。相对于原有项目有如下几点改进:
- 对Paddle和PaddleSeg的版本进行了升级,使用了最新版本。
- 增加了使用PaddleX完成图像分割的方法。
- 对数据集图片进行了缩放使其尺寸变小,训练更快;并且对标签文件进行了预处理,避免了训练时的Bug。
- 对整个项目流程的部分细节进行了优化,使其更加容易理解、减少bug、方便运行。
1.1 什么是图像分割
图像分割是一种典型的计算机视觉任务,指的是将一张图像分割成既定类别的几个区域。图像分割本质上是一种像素级别的图像分类任务。
图像分割通常分为语义分割、实例分割、全景分割,如图1所示。另外,还有基于视频的目标分割和实例分割。本项目中我们将完成一个图像语义分割任务。
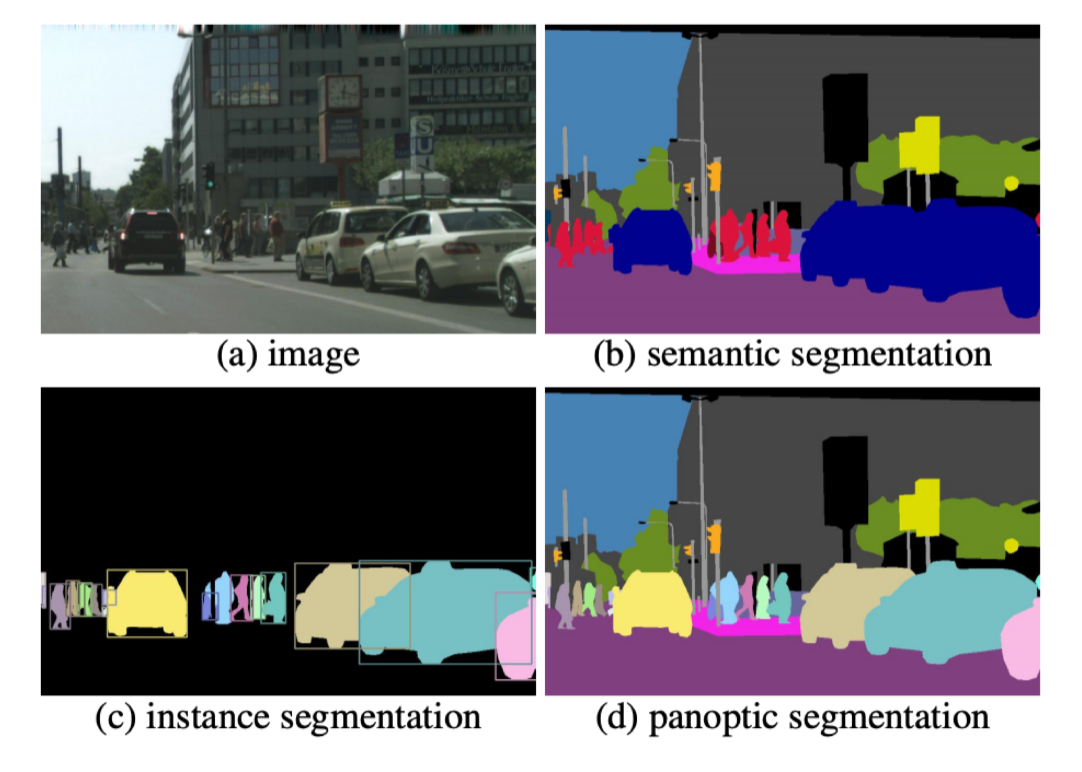
图1 图像分割任务示意图
2. 创建数据集
本项目采用自建的鸽子图片数据集。创建数据集分为如下几步:
2.1. 拍摄鸽子的照片
拍摄鸽子图片时尽量选择不同角度、不同背景进行拍摄,图片中的鸽子数量也尽量不同,以便增加图片的多样性从而提高最后模型的鲁棒性。由于本项目只是讲述流程,故这里仅采用了122张照片。
2.2. 使用labelme进行标注
严格按照labelme github仓库主页的描述来安装labelme,链接为labelme github网址
2.3. 基于标注好的图片利用json文件生成原始图片和标签图片
使用labelme完成标注任务后,需要利用保存的json文件来生成原始图片和对应的标签图片。这里要注意的是,由于labelme自带的labelme_json_to_dataset命令只能处理单个json文件,如果要批量处理所有生成的json文件可以采用并修改如下示例代码:
import os
path = PATH_TO_JSON
json_file = os.listdir(path)
#os.system("conda activate labelme")
for file in json_file:
os.system("labelme_json_to_dataset %s"%(path+"/"+file))
2.4. 使用AI Studio创建并上传标注好的图片
通常生成的数据集较大,这时可以使用AI Studio的创建数据集功能上传生成的数据,然后在项目中挂载使用。
完成以上步骤后就可以使用AI Studio进行训练、验证和预测了。
3. 训练、验证和预测
下面以U-Net网络为例,讲述两种进行训练、验证和预测的方法:基于Paddle2.3 API的方法和基于PaddleSeg2.5的方法。
3.1 基于Paddle2.3 API使用U-Net网络实现鸽子图像的语义分割任务
3.1.1 简要介绍
U-Net网络结构是一个基于FCN并改进后的深度学习网络,包含下采样(编码器,特征提取)和上采样(解码器,分辨率还原)两个阶段,因模型结构比较像U型而命名为U-Net。
3.1.2.环境设置
导入一些比较基础常用的模块,确认自己的飞桨版本。
import os
import io
import numpy as np
import matplotlib.pyplot as plt
from PIL import Image as PilImage
import paddle
from paddle.nn import functional as F
import warnings
warnings.filterwarnings('ignore')
paddle.__version__
'2.3.0'
3.1.3 解压数据集
!unzip -q 'data/data149031/imgs.zip' -d work/
## 预处理标签
!python code/process_label.py
finished processing labels
3.1.4 数据集概览
首先我们先来了解一下我们的数据集。
数据集解压后,里面放的每个文件夹中有四个文件,分别是图片文件、标签文件、标签名字文件和可视化的图片文件,如下所示。
.
├── label.png
├── img.png
├── label_names.txt
└── label_viz.png
我们来看看这个数据集给我们提供了多少个训练样本。
images_path = "work/imgs"
image_count = len([os.path.join(images_path, image_name)
for image_name in os.listdir(images_path) if not image_name.startswith('.')])
print("用于训练的图片样本数量:", image_count)
用于训练的图片样本数量: 122
3.1.5 划分训练集、验证集和测试集
def _sort_images(image_dir):
"""
对文件夹内的图像进行按照文件名排序
"""
images = []
labels = []
for image_name in os.listdir(image_dir):
if os.path.isdir(os.path.join(image_dir, image_name)):
images.append('/home/aistudio/' + os.path.join(image_dir, image_name, 'img.png'))
labels.append('/home/aistudio/' + os.path.join(image_dir, image_name, 'result.png'))
return sorted(images), sorted(labels)
"""
这里的分割符是空格,因为PaddleSeg读取文件时默认的分割符是空格。
"""
def write_file(mode, images, labels):
with open('/home/aistudio/{}.txt'.format(mode), 'w') as f:
for i in range(len(images)):
f.write('{} {}\n'.format(images[i], labels[i]))
"""
由于所有文件都是散落在文件夹中,在训练时我们需要使用的是数据集和标签对应的数据关系,
所以我们第一步是对原始的数据集进行整理,得到数据集和标签两个数组,分别一一对应。
这样可以在使用的时候能够很方便的找到原始数据和标签的对应关系,否则对于原有的文件夹图片数据无法直接应用。
"""
images, labels = _sort_images(images_path)
eval_num = int(image_count * 0.1)
"""
由于图片数量有限,这里的测试集和验证集采用相同的一组图片。
"""
write_file('train', images[:-eval_num], labels[:-eval_num])
write_file('test', images[-eval_num:], labels[-eval_num:])
write_file('eval', images[-eval_num:], labels[-eval_num:])
3.1.6 DoveDataSet数据集抽样展示
划分好数据集之后,我们来查验一下数据集是否符合预期,我们通过划分的配置文件读取图片路径后再加载图片数据来用matplotlib进行展示。
with open('/home/aistudio/train.txt', 'r') as f:
i = 0
for line in f.readlines():
image_path, label_path = line.strip().split(' ')
label_path = label_path.replace('result.png', 'label.png')
image = np.array(PilImage.open(image_path))
label = np.array(PilImage.open(label_path))
if i > 2:
break
# 进行图片的展示
plt.figure()
plt.subplot(1,2,1),
plt.title('Train Image')
plt.imshow(image.astype('uint8'))
plt.axis('off')
plt.subplot(1,2,2),
plt.title('Label')
plt.imshow(label.astype('uint8'))
plt.axis('off')
plt.show()
i = i + 1
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-fFlBsAcM-1656724406826)(output_16_0.png)]
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-gT5PoIM1-1656724406827)(output_16_1.png)]
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-54kgxdrM-1656724406828)(output_16_2.png)]
3.1.7 数据集类定义
飞桨(PaddlePaddle)数据集加载方案是统一使用Dataset(数据集定义) + DataLoader(多进程数据集加载)。
首先我们先进行数据集的定义,数据集定义主要是实现一个新的Dataset类,继承父类paddle.io.Dataset,并实现父类中以下两个抽象方法,__getitem__和__len__:
class MyDataset(Dataset):
def __init__(self):
...
# 每次迭代时返回数据和对应的标签
def __getitem__(self, idx):
return x, y
# 返回整个数据集的总数
def __len__(self):
return count(samples)
在数据集内部可以结合图像数据预处理相关API进行图像的预处理(改变大小、反转、调整格式等)。
由于加载进来的图像不一定都符合自己的需求,举个例子,已下载的这些图片里面可能会有RGBA格式的图片,这个时候图片就不符合我们所需3通道的需求,我们需要进行图片的格式转换,那么这里我们直接实现了一个通用的图片读取接口,确保读取出来的图片都是满足我们的需求。
本项目的数据集定义的代码可以参考code目录下的dove_dataset.py文件。
3.1.8 模型组网
U-Net是一个U型网络结构,可以看做两个大的阶段,图像先经过Encoder编码器进行下采样得到高级语义特征图,再经过Decoder解码器上采样将特征图恢复到原图片的分辨率。
具体的网络定义的代码可以参考code目录下的unet.py文件,具体网络结构包括如下几部分。
3.1.9 定义SeparableConv2D接口
我们为了减少卷积操作中的训练参数来提升性能,是继承paddle.nn.Layer自定义了一个SeparableConv2D Layer类,整个过程是把filter_size * filter_size * num_filters的Conv2D操作拆解为两个子Conv2D,先对输入数据的每个通道使用filter_size * filter_size * 1的卷积核进行计算,输入输出通道数目相同,之后在使用1 * 1 * num_filters的卷积核计算。
3.1.10 定义Encoder编码器
我们将网络结构中的Encoder下采样过程进行了一个Layer封装,方便后续调用,减少代码编写,下采样是有一个模型逐渐向下画曲线的一个过程,这个过程中是不断的重复一个单元结构将通道数不断增加,形状不断缩小,并且引入残差网络结构,我们将这些都抽象出来进行统一封装。
3.1.11 定义Decoder解码器
在通道数达到最大得到高级语义特征图后,网络结构会开始进行decode操作,进行上采样,通道数逐渐减小,对应图片尺寸逐步增加,直至恢复到原图像大小,那么这个过程里面也是通过不断的重复相同结构的残差网络完成,我们也是为了减少代码编写,将这个过程定义一个Layer来放到模型组网中使用。
3.1.12 训练模型组网
按照U型网络结构格式进行整体的网络结构搭建,三次下采样,四次上采样。
3.1.13 模型可视化
调用飞桨提供的summary接口对组建好的模型进行可视化,方便进行模型结构和参数信息的查看和确认。
%cd code
import paddle
from unet import DoveNet
num_classes = 2
IMAGE_SIZE = (224, 224)
network = DoveNet(num_classes)
model = paddle.Model(network)
model.summary((-1, 3,) + IMAGE_SIZE)
/home/aistudio/code
W0607 10:10:12.904951 166 gpu_context.cc:278] Please NOTE: device: 0, GPU Compute Capability: 7.0, Driver API Version: 11.2, Runtime API Version: 10.1
W0607 10:10:12.909504 166 gpu_context.cc:306] device: 0, cuDNN Version: 7.6.
-----------------------------------------------------------------------------
Layer (type) Input Shape Output Shape Param #
=============================================================================
Conv2D-1 [[1, 3, 224, 224]] [1, 32, 112, 112] 896
BatchNorm2D-1 [[1, 32, 112, 112]] [1, 32, 112, 112] 128
ReLU-1 [[1, 32, 112, 112]] [1, 32, 112, 112] 0
ReLU-2 [[1, 32, 112, 112]] [1, 32, 112, 112] 0
SeparableConv2D-1 [[1, 32, 112, 112]] [1, 64, 112, 112] 2,400
BatchNorm2D-2 [[1, 64, 112, 112]] [1, 64, 112, 112] 256
ReLU-3 [[1, 64, 112, 112]] [1, 64, 112, 112] 0
SeparableConv2D-2 [[1, 64, 112, 112]] [1, 64, 112, 112] 4,736
BatchNorm2D-3 [[1, 64, 112, 112]] [1, 64, 112, 112] 256
MaxPool2D-1 [[1, 64, 112, 112]] [1, 64, 56, 56] 0
Conv2D-2 [[1, 32, 112, 112]] [1, 64, 56, 56] 2,112
Encoder-1 [[1, 32, 112, 112]] [1, 64, 56, 56] 0
ReLU-4 [[1, 64, 56, 56]] [1, 64, 56, 56] 0
SeparableConv2D-3 [[1, 64, 56, 56]] [1, 128, 56, 56] 8,896
BatchNorm2D-4 [[1, 128, 56, 56]] [1, 128, 56, 56] 512
ReLU-5 [[1, 128, 56, 56]] [1, 128, 56, 56] 0
SeparableConv2D-4 [[1, 128, 56, 56]] [1, 128, 56, 56] 17,664
BatchNorm2D-5 [[1, 128, 56, 56]] [1, 128, 56, 56] 512
MaxPool2D-2 [[1, 128, 56, 56]] [1, 128, 28, 28] 0
Conv2D-3 [[1, 64, 56, 56]] [1, 128, 28, 28] 8,320
Encoder-2 [[1, 64, 56, 56]] [1, 128, 28, 28] 0
ReLU-6 [[1, 128, 28, 28]] [1, 128, 28, 28] 0
SeparableConv2D-5 [[1, 128, 28, 28]] [1, 256, 28, 28] 34,176
BatchNorm2D-6 [[1, 256, 28, 28]] [1, 256, 28, 28] 1,024
ReLU-7 [[1, 256, 28, 28]] [1, 256, 28, 28] 0
SeparableConv2D-6 [[1, 256, 28, 28]] [1, 256, 28, 28] 68,096
BatchNorm2D-7 [[1, 256, 28, 28]] [1, 256, 28, 28] 1,024
MaxPool2D-3 [[1, 256, 28, 28]] [1, 256, 14, 14] 0
Conv2D-4 [[1, 128, 28, 28]] [1, 256, 14, 14] 33,024
Encoder-3 [[1, 128, 28, 28]] [1, 256, 14, 14] 0
ReLU-8 [[1, 256, 14, 14]] [1, 256, 14, 14] 0
Conv2DTranspose-1 [[1, 256, 14, 14]] [1, 256, 14, 14] 590,080
BatchNorm2D-8 [[1, 256, 14, 14]] [1, 256, 14, 14] 1,024
ReLU-9 [[1, 256, 14, 14]] [1, 256, 14, 14] 0
Conv2DTranspose-2 [[1, 256, 14, 14]] [1, 256, 14, 14] 590,080
BatchNorm2D-9 [[1, 256, 14, 14]] [1, 256, 14, 14] 1,024
Upsample-1 [[1, 256, 14, 14]] [1, 256, 28, 28] 0
Upsample-2 [[1, 256, 14, 14]] [1, 256, 28, 28] 0
Conv2D-5 [[1, 256, 28, 28]] [1, 256, 28, 28] 65,792
Decoder-1 [[1, 256, 14, 14]] [1, 256, 28, 28] 0
ReLU-10 [[1, 256, 28, 28]] [1, 256, 28, 28] 0
Conv2DTranspose-3 [[1, 256, 28, 28]] [1, 128, 28, 28] 295,040
BatchNorm2D-10 [[1, 128, 28, 28]] [1, 128, 28, 28] 512
ReLU-11 [[1, 128, 28, 28]] [1, 128, 28, 28] 0
Conv2DTranspose-4 [[1, 128, 28, 28]] [1, 128, 28, 28] 147,584
BatchNorm2D-11 [[1, 128, 28, 28]] [1, 128, 28, 28] 512
Upsample-3 [[1, 128, 28, 28]] [1, 128, 56, 56] 0
Upsample-4 [[1, 256, 28, 28]] [1, 256, 56, 56] 0
Conv2D-6 [[1, 256, 56, 56]] [1, 128, 56, 56] 32,896
Decoder-2 [[1, 256, 28, 28]] [1, 128, 56, 56] 0
ReLU-12 [[1, 128, 56, 56]] [1, 128, 56, 56] 0
Conv2DTranspose-5 [[1, 128, 56, 56]] [1, 64, 56, 56] 73,792
BatchNorm2D-12 [[1, 64, 56, 56]] [1, 64, 56, 56] 256
ReLU-13 [[1, 64, 56, 56]] [1, 64, 56, 56] 0
Conv2DTranspose-6 [[1, 64, 56, 56]] [1, 64, 56, 56] 36,928
BatchNorm2D-13 [[1, 64, 56, 56]] [1, 64, 56, 56] 256
Upsample-5 [[1, 64, 56, 56]] [1, 64, 112, 112] 0
Upsample-6 [[1, 128, 56, 56]] [1, 128, 112, 112] 0
Conv2D-7 [[1, 128, 112, 112]] [1, 64, 112, 112] 8,256
Decoder-3 [[1, 128, 56, 56]] [1, 64, 112, 112] 0
ReLU-14 [[1, 64, 112, 112]] [1, 64, 112, 112] 0
Conv2DTranspose-7 [[1, 64, 112, 112]] [1, 32, 112, 112] 18,464
BatchNorm2D-14 [[1, 32, 112, 112]] [1, 32, 112, 112] 128
ReLU-15 [[1, 32, 112, 112]] [1, 32, 112, 112] 0
Conv2DTranspose-8 [[1, 32, 112, 112]] [1, 32, 112, 112] 9,248
BatchNorm2D-15 [[1, 32, 112, 112]] [1, 32, 112, 112] 128
Upsample-7 [[1, 32, 112, 112]] [1, 32, 224, 224] 0
Upsample-8 [[1, 64, 112, 112]] [1, 64, 224, 224] 0
Conv2D-8 [[1, 64, 224, 224]] [1, 32, 224, 224] 2,080
Decoder-4 [[1, 64, 112, 112]] [1, 32, 224, 224] 0
Conv2D-9 [[1, 32, 224, 224]] [1, 2, 224, 224] 578
=============================================================================
Total params: 2,058,690
Trainable params: 2,051,138
Non-trainable params: 7,552
-----------------------------------------------------------------------------
Input size (MB): 0.57
Forward/backward pass size (MB): 230.07
Params size (MB): 7.85
Estimated Total Size (MB): 238.50
-----------------------------------------------------------------------------
{'total_params': 2058690, 'trainable_params': 2051138}
3.1.14 启动模型训练
使用模型代码进行Model实例生成,使用prepare接口定义优化器、损失函数和评价指标等信息,用于后续训练使用。在所有初步配置完成后,调用fit接口开启训练执行过程,调用fit时只需要将前面定义好的训练数据集、测试数据集、训练轮次(Epoch)和批次大小(batch_size)配置好即可。
!python ../code/train.py
3.1.15 预测数据集准备和预测
继续使用DoveDataset来实例化待预测使用的数据集。
我们可以直接使用model.predict接口来对数据集进行预测操作,只需要将预测数据集传递到接口内即可。
import paddle
from unet import DoveNet
from dove_dataset import DoveDataset
num_classes = 2
network = DoveNet(num_classes)
state_dict = paddle.load('./unet.pdparams')
network.set_state_dict(state_dict)
model = paddle.Model(network)
predict_dataset = DoveDataset(mode='test')
test_loader = paddle.io.DataLoader(predict_dataset, places=paddle.CUDAPlace(0), batch_size= 32)
model.prepare(paddle.nn.CrossEntropyLoss(axis=1))
predict_results = model.predict(test_loader)
Predict begin...
step 1/1 [==============================] - 678ms/step
Predict samples: 12
3.1.16 预测结果可视化
从我们的预测数据集中抽3个图片来看看预测的效果,展示一下原图、标签图和预测结果。
import numpy as np
import matplotlib.pyplot as plt
from paddle.vision.transforms import transforms as T
from PIL import Image as PilImage
plt.figure(figsize=(10, 10))
IMAGE_SIZE = (224, 224)
i = 0
idx = 0
with open('/home/aistudio/test.txt', 'r') as f:
for line in f.readlines():
image_path, label_path = line.strip().split(' ')
label_path = label_path.replace('result.png', 'label.png')
resize_t = T.Compose([
T.Resize(IMAGE_SIZE)
])
image = resize_t(PilImage.open(image_path))
label = resize_t(PilImage.open(label_path))
image = np.array(image).astype('uint8')
label = np.array(label).astype('uint8')
if i > 8:
break
plt.subplot(3, 3, i + 1)
plt.imshow(image)
plt.title('Input Image')
plt.axis("off")
plt.subplot(3, 3, i + 2)
plt.imshow(label, cmap='gray')
plt.title('Label')
plt.axis("off")
data = predict_results[0][0][idx].transpose((1, 2, 0))
mask = np.argmax(data, axis=-1)
plt.subplot(3, 3, i + 3)
plt.imshow(mask.astype('uint8'), cmap='gray')
plt.title('Predict')
plt.axis("off")
i += 3
idx += 1
plt.show()
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-iPsIOFxZ-1656724406830)(output_35_0.png)]
3.2 基于PaddleSeg使用U-Net网络实现鸽子图像的语义分割任务
%cd
/home/aistudio
3.2.1 安装PaddleSeg
!pip install paddleseg
3.2.2 克隆或者解压缩PaddleSeg
为避免由于网络造成的下载困难问题,这里采用解压缩的方法。也可以采用克隆的方法获取最新的PaddleSeg。
!git clone https://github.com/PaddlePaddle/PaddleSeg.git
!git clone https://github.com/PaddlePaddle/PaddleSeg.git
!unzip -q data/data149927/PaddleSeg-release-2.5.zip -d ./
3.2.3 开始训练
使用PaddleSeg时的配置信息是采用yml文件描述的,这里使用的是unet.yml文件.
## 使用U-net进行训练
!python PaddleSeg-release-2.5/train.py --config unet.yml --save_interval 2000
3.2.4 开始预测
## 将测试图片拷贝到新建的文件夹中
import os
import shutil
if not os.path.exists('test_imgs'):
os.mkdir('test_imgs')
with open('test.txt', 'r') as f:
paths = f.readlines()
i = 0
for path in paths:
img, label = path.strip().split(' ')
shutil.copy(img, 'test_imgs/t'+str(i)+'.png')
i += 1
## 将标签图片拷贝到新建的文件夹中
if not os.path.exists('label_imgs'):
os.mkdir('label_imgs')
with open('test.txt', 'r') as f:
paths = f.readlines()
i = 0
for path in paths:
img, label = path.strip().split(' ')
label = label.replace('result.png', 'label.png')
shutil.copy(label, 'label_imgs/t'+str(i)+'.png')
i += 1
## 开始预测并保存预测后的图片
!python PaddleSeg-release-2.5/predict.py --image_path test_imgs \
--model_path output/iter_10000/model.pdparams \
--save_dir saved_imges \
--crop_size 512 512 \
--config unet.yml
3.2.5 结果可视化
## 创建需要可视化的图片列表
test_images = os.listdir('test_imgs')
label_images = os.listdir('label_imgs')
predicted_images = os.listdir('saved_imges/pseudo_color_prediction')
test_images = ['test_imgs/' + path for path in test_images if not path.startswith('.')]
label_images = ['label_imgs/' + path for path in label_images if not path.startswith('.')]
predicted_images = ['saved_imges/pseudo_color_prediction/' + path for path in predicted_images if not path.startswith('.')]
test_images.sort()
label_images.sort()
predicted_images.sort()
## 开始可视化
from paddle.vision.transforms import transforms as T
import matplotlib.pyplot as plt
from PIL import Image as PilImage
import numpy as np
plt.figure(figsize=(10, 10))
IMAGE_SIZE = (224, 224)
i = 0
for j in range(len(test_images)):
test_path = test_images[j]
label_path = label_images[j]
predicted_path = predicted_images[j]
resize_t = T.Compose([
T.Resize(IMAGE_SIZE)
])
image = resize_t(PilImage.open(test_path))
label = resize_t(PilImage.open(label_path))
predicted = resize_t(PilImage.open(predicted_path))
image = np.array(image).astype('uint8')
label = np.array(label).astype('uint8')
predicted = np.array(predicted).astype('uint8')
if i > 8:
break
plt.subplot(3, 3, i + 1)
plt.imshow(image)
plt.title('Input Image')
plt.axis("off")
plt.subplot(3, 3, i + 2)
plt.imshow(label, cmap='gray')
plt.title('Label')
plt.axis("off")
plt.subplot(3, 3, i + 3)
plt.imshow(predicted, cmap='gray')
plt.title('Predict')
plt.axis("off")
i += 3
j += 1
plt.show()
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-52MhjjYq-1656724406830)(output_51_0.png)]
3.3 基于PaddleX 2.1 API使用U-Net网络实现鸽子图像的语义分割任务
3.3.1 创建PaddleX需要的数据文件
PaddleX需要一些训练预测的数据文件,如labels.txt, train_list.txt,val_list.txt。我们已经创建了train.txt, eval.text和test.txt。现在只需要创建labels.txt。
with open('labels.txt', 'w') as f:
f.writelines(['background\n', 'dove'])
3.3.2 安装PaddleX
!pip install paddlex==2.1.0 -i https://mirror.baidu.com/pypi/simple
3.3.3 开始训练
import paddlex as pdx
from paddlex import transforms as T
train_transforms = T.Compose([
T.Resize(target_size=512),
T.RandomHorizontalFlip(),
T.Normalize(
mean=[0.5, 0.5, 0.5], std=[0.5, 0.5, 0.5]),
])
eval_transforms = T.Compose([
T.Resize(target_size=512),
T.Normalize(
mean=[0.5, 0.5, 0.5], std=[0.5, 0.5, 0.5]),
])
train_dataset = pdx.datasets.SegDataset(
data_dir='./',
file_list='./train.txt',
label_list='./labels.txt',
transforms=train_transforms,
shuffle=True)
eval_dataset = pdx.datasets.SegDataset(
data_dir='./',
file_list='./eval.txt',
label_list='./labels.txt',
transforms=eval_transforms,
shuffle=False)
2022-06-14 13:45:19 [INFO] 110 samples in file ./train.txt
2022-06-14 13:45:19 [INFO] 12 samples in file ./eval.txt
num_classes = len(train_dataset.labels)
model = pdx.seg.UNet(num_classes=num_classes)
W0614 13:47:08.356240 103 gpu_context.cc:278] Please NOTE: device: 0, GPU Compute Capability: 7.0, Driver API Version: 11.2, Runtime API Version: 10.1
W0614 13:47:08.361294 103 gpu_context.cc:306] device: 0, cuDNN Version: 7.6.
model.train(
num_epochs=100,
train_dataset=train_dataset,
train_batch_size=16,
eval_dataset=eval_dataset,
save_interval_epochs=10,
log_interval_steps=20,
learning_rate=0.01,
save_dir='output/unet')
3.3.4 开始预测
import os
## 创建需要预测的图片列表
test_images = os.listdir('test_imgs')
test_images = ['test_imgs/' + path for path in test_images if not path.startswith('.')]
test_images.sort()
model = pdx.load_model('output/unet/best_model')
for test_image in test_images:
result = model.predict(test_image)
pdx.seg.visualize(test_image, result, weight=0.0, save_dir='./result_imgs')
3.3.5 结果可视化
## 创建需要可视化的图片列表
label_images = os.listdir('label_imgs')
predicted_images = os.listdir('result_imgs')
label_images = ['label_imgs/' + path for path in label_images if not path.startswith('.')]
predicted_images = ['result_imgs/' + path for path in predicted_images if not path.startswith('.')]
label_images.sort()
predicted_images.sort()
%matplotlib inline
## 开始可视化
from paddle.vision.transforms import transforms as T
import matplotlib.pyplot as plt
from PIL import Image as PilImage
import numpy as np
plt.figure(figsize=(10, 10))
IMAGE_SIZE = (512, 512)
i = 0
for j in range(len(test_images)):
test_path = test_images[j]
label_path = label_images[j]
predicted_path = predicted_images[j]
resize_t = T.Compose([
T.Resize(IMAGE_SIZE)
])
image = resize_t(PilImage.open(test_path))
label = resize_t(PilImage.open(label_path))
predicted = resize_t(PilImage.open(predicted_path))
image = np.array(image).astype('uint8')
label = np.array(label).astype('uint8')
predicted = np.array(predicted).astype('uint8')
if i > 8:
break
plt.subplot(3, 3, i + 1)
plt.imshow(image)
plt.title('Input Image')
plt.axis("off")
plt.subplot(3, 3, i + 2)
plt.imshow(label, cmap='gray')
plt.title('Label')
plt.axis("off")
plt.subplot(3, 3, i + 3)
plt.imshow(predicted, cmap='gray')
plt.title('Predict')
plt.axis("off")
i += 3
j += 1
plt.show()

4. 总结
-
本项目从零开始,全流程的介绍了基于Paddle的图像分割方法。
-
在自建分割数据集的基础上,分别使用Paddle2.3,PaddleSeg2.5和PaddleX2.1完成了基于U-Net的图像分割方法。
-
针对图像分割任务,PaddleSeg2.5和PaddleX2.1相对于Paddle2.3具有使用简单、效果好等优点,建议使用。
-
采用其它网络的图像分割方法可以在本项目的基础上修改实现。
-
欢迎fork,评论,共同学习,来互粉吧,等你哦
原项目链接:https://aistudio.baidu.com/aistudio/projectdetail/4180144
break

学大模型,用大模型上飞桨星河社区!每天8点V100G算力免费领!免费领取ERNIE 4.0 100w Token >>>
更多推荐



 2
2 0
0- 0



 已为社区贡献1437条内容
已为社区贡献1437条内容

所有评论(0)