
PaddleRS:利用卫星影像与数字高程模型进行滑坡识别
PaddleRS:利用卫星影像与数字高程模型进行滑坡识别
一、项目背景
我国是一个多山的国家,山区的面积占陆地面积超过一半
而在山区,频发的不良地质体会给公路、铁路、建筑等基础设施带来不可估量的损害,严重威胁人们生命和财产安全,不良地质体如下图所示
高效、精准地定位不良地质区域对风险评估有重要意义。山区地形复杂仅依靠现场勘查无法满足实际应用需求,亟需发展智能化的遥感处理手段,提升灾害识别精度
本项目将使用PaddleRS套件,基于武汉大学季顺平老师的滑坡数据集,卫星影像和数字高程模型(RGB+DEM)数据的叠加进行滑坡识别。季老师的论文《Landslide detection from an open satellite imagery and digital elevation model dataset using attention boosted convolutional neural networks》实验结果表明RGB数据引入DEM后各项指标均有提高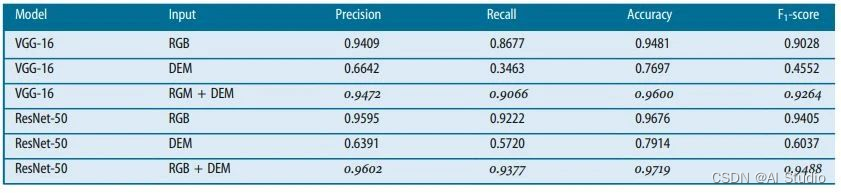
二、数据集介绍与处理
2.1 数据集介绍
该数据集包含滑坡数据和非滑坡数据两个部分,具体数量如下图所示,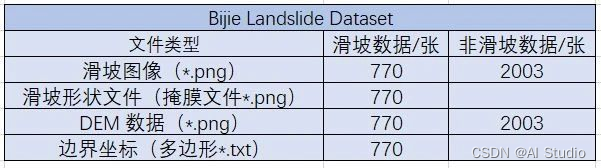
其中影像数据采用TripleSat卫星数据,其全色0.8米、多光谱3.2米,滑坡示例如下图所示:
2.2 数据集处理
由于数据集中是包含RGB以及DEM两种数据,要叠加在一起,PaddleRS目前还没有读取多种数据融合的数据类,因此在训练之前先对数据集进行处理,将RGB数据和DEM数据叠加融合,保存为.npy文件的处理
同时也要对标签数据进行处理,因为需要以0,1两个值,每个值代表一个类别
In [12]
解压文件
!unzip -qo data/data121515/Bijie_landslide_dataset.zip -d .
In [13]
查看数据集的目录结构
!tree -L 2 Bijie-landslide-dataset/
Bijie-landslide-dataset/
├── landslide
│ ├── dem
│ ├── image
│ ├── mask
│ └── polygon_coordinate
└── non-landslide
├── dem
└── image
8 directories, 0 files
可以看到数据集包含两个文件夹,一个是有滑坡的,另一个是没有滑坡的,其中没滑坡的文件夹中没有mask作为label,可以自己生成
注:DEM数据和RGB数据的分辨率不同,所以在数据合并时需要resize
In [14]
分别查看数据长什么样
import os
import cv2
import matplotlib.pyplot as plt
%matplotlib inline
tag判断文件夹下有没有mask文件夹
def show_img(root_dir, tag=True):
img_dir = os.path.join(root_dir, ‘image’)
dem_dir = os.path.join(root_dir, ‘dem’)
mask_dir = os.path.join(root_dir, ‘mask’)
img_list = [f for f in os.listdir(img_dir) if f.endswith(‘.png’)]
filename = img_list[0]
img = cv2.imread(os.path.join(img_dir, filename))
dem = cv2.imread(os.path.join(dem_dir, filename))
print(img.shape, dem.shape)
if tag:
num = 3
else:
num = 2
plt.figure(figsize=(10,5))
plt.subplot(1,num,1), plt.title(‘image’)
plt.imshow(img), plt.axis(‘off’)
plt.subplot(1,num,2), plt.title(‘dem’)
plt.imshow(dem), plt.axis(‘off’)
if tag:
mask = cv2.imread(os.path.join(mask_dir, filename))
plt.subplot(1, num, 3), plt.title(‘label’)
plt.imshow(mask), plt.axis(‘off’)
plt.show()
In [15]
滑坡数据
root_dir = r"Bijie-landslide-dataset/landslide"
show_img(root_dir, True)
(484, 487, 3) (121, 122, 3)
In [16]
非滑坡数据
root_dir = r"Bijie-landslide-dataset/non-landslide"
show_img(root_dir, False)
(441, 463, 3) (111, 116, 3)
合并数据生成.npy文件
In [17]
import cv2
import numpy as np
import os
import tqdm
def save_npy(img_dir, dem_dir, save_dir, img_list):
for filename in tqdm.tqdm(img_list):
img_rgb = cv2.imread(os.path.join(img_dir, filename), -1)
dem = cv2.imread(os.path.join(dem_dir, filename), -1)
h, w, _ = img_rgb.shape
dem = cv2.resize(dem, (w, h), cv2.INTER_CUBIC)
if (np.max(dem)!=np.min(dem)):
dem = 255*(dem-np.min(dem))/(np.max(dem)-np.min(dem)) #转为在[0,255]之间
else:
print(“the max value {} equal min value {}!”.format(np.max(dem), np.min(dem))) # 对于最大值和最小值相等的,说明是平地不用转换
image = np.zeros([h, w, 4])
image[:, :, 0:3] = img_rgb
image[:, :, -1] = dem
name, _ = os.path.splitext(filename)
np.save(os.path.join(save_dir, name+‘.npy’), image.astype(‘float32’))
scale为测试集占数据集数量的比值
def combine_data(root_dir, save_dir, scale):
img_dir = os.path.join(root_dir, ‘image’)
dem_dir = os.path.join(root_dir, ‘dem’)
if not os.path.isdir(save_dir):
os.mkdir(save_dir)
train_dir = os.path.join(save_dir, 'train')
test_dir = os.path.join(save_dir, 'test')
if not os.path.isdir(train_dir):
os.mkdir(train_dir)
if not os.path.isdir(test_dir):
os.mkdir(test_dir)
img_list = [f for f in os.listdir(img_dir) if f.endswith('.png')]
val_num = int(len(img_list) * scale)
test_list = img_list[:val_num] #测试集
train_list = img_list[val_num:] #训练集
save_npy(img_dir, dem_dir, train_dir, train_list) # 保存训练集
save_npy(img_dir, dem_dir, test_dir, test_list) # 保存测试集
In [18]
合并保存在dataset文件夹下
root_dir = r"Bijie-landslide-dataset/landslide"
save_dir = r"Bijie-landslide-dataset/dataset"
scale = 1/3
combine_data(root_dir, save_dir, scale)
100%|██████████| 514/514 [00:02<00:00, 217.21it/s]
100%|██████████| 256/256 [00:01<00:00, 240.58it/s]
In [ ]
root_dir = r"Bijie-landslide-dataset/non-landslide"
save_dir = r"Bijie-landslide-dataset/dataset"
scale = 1/3
combine_data(root_dir, save_dir, scale)
生成label数据:
对于有滑坡的部分,则把mask转为label即可
对于没滑坡的部分,则直接生成全为0的单通道图像
In [26]
有滑坡部分
import os
import cv2
from PIL import Image
import numpy as np
mask_dir = r"Bijie-landslide-dataset/landslide/mask"
label_dir = r"Bijie-landslide-dataset/label" # label所在文件夹
mask_list = [f for f in os.listdir(mask_dir) if f.endswith(‘.png’)]
if not os.path.isdir(label_dir):
os.mkdir(label_dir)
for filename in tqdm.tqdm(mask_list):
mask = np.array(Image.open(os.path.join(mask_dir, filename)))
label = np.zeros_like(mask)
label[np.where(mask>0)] = 1
cv2.imwrite(os.path.join(label_dir, filename), label)
100%|██████████| 770/770 [00:00<00:00, 1108.84it/s]
In [27]
没滑坡的部分
img_dir = r"Bijie-landslide-dataset/non-landslide/image"
label_dir = r"Bijie-landslide-dataset/label" # label所在文件夹
img_list = [f for f in os.listdir(img_dir) if f.endswith(‘.png’)]
if not os.path.isdir(label_dir):
os.mkdir(label_dir)
for filename in tqdm.tqdm(img_list):
img = np.array(Image.open(os.path.join(img_dir, filename)))
h, w, _ = img.shape
label = np.zeros([h, w])
cv2.imwrite(os.path.join(label_dir, filename), label)
100%|██████████| 2003/2003 [00:07<00:00, 259.41it/s]
In [28]
按照train与test文件夹,将label文件夹中的label数据分为train_label与test_label
import shutil
label_dir = r"Bijie-landslide-dataset/label"
train_dir = r"Bijie-landslide-dataset/dataset/train"
test_dir = r"Bijie-landslide-dataset/dataset/test"
增加label文件夹
train_label_dir = r"Bijie-landslide-dataset/dataset/train_label"
test_label_dir = r"Bijie-landslide-dataset/dataset/test_label"
if not os.path.isdir(train_label_dir):
os.mkdir(train_label_dir)
if not os.path.isdir(test_label_dir):
os.mkdir(test_label_dir)
train_list = [f for f in os.listdir(train_dir) if f.endswith(‘.npy’)]
test_list = [f for f in os.listdir(test_dir) if f.endswith(‘.npy’)]
for filename in tqdm.tqdm(test_list):
name, _ = os.path.splitext(filename)
filename = name + ‘.png’
src = os.path.join(label_dir,filename)
dst = os.path.join(test_label_dir,filename)
shutil.move(src, dst)
for filename in tqdm.tqdm(train_list):
name, _ = os.path.splitext(filename)
filename = name + ‘.png’
src = os.path.join(label_dir,filename)
dst = os.path.join(train_label_dir,filename)
shutil.move(src, dst)
100%|██████████| 923/923 [00:00<00:00, 4665.32it/s]
100%|██████████| 1850/1850 [00:00<00:00, 51688.74it/s]
三、训练准备
数据准备好之后,克隆仓库、配置环境、生成数据列表,为训练做准备
In [1]
克隆仓库,如果项目已经有了该仓库,则不用执行这句话
!git clone https://github.com/PaddleCV-SIG/PaddleRS
正克隆到 ‘PaddleRS’…
remote: Enumerating objects: 3447, done.
remote: Counting objects: 100% (248/248), done.
remote: Compressing objects: 100% (130/130), done.
remote: Total 3447 (delta 121), reused 232 (delta 116), pack-reused 3199
接收对象中: 100% (3447/3447), 6.96 MiB | 3.17 MiB/s, 完成.
处理 delta 中: 100% (1949/1949), 完成.
检查连接… 完成。
In [ ]
安装依赖配置环境
%cd PaddleRS/
!pip install -r requirements.txt
In [40]
设置txt文件
import os.path as osp
from glob import glob
DATA_DIR = ‘…/Bijie-landslide-dataset/dataset/’
def write_rel_paths(phase, names, out_dir):
“”“将文件相对路径存储在txt格式文件中”“”
with open(osp.join(out_dir, phase+‘.txt’), ‘w’) as f:
for name in names:
filename, _ = osp.splitext(name)
f.write(
’ ‘.join([
osp.join(phase, name),
osp.join(’{}_label’.format(phase), filename+‘.png’)
])
)
f.write(‘\n’)
train_names = [f for f in os.listdir(osp.join(DATA_DIR, “train”)) if f.endswith(‘.npy’)]
test_names = [f for f in os.listdir(osp.join(DATA_DIR, “test”)) if f.endswith(‘.npy’)]
write_rel_paths(“train”, train_names, DATA_DIR) # 设置训练列表
write_rel_paths(“test”, test_names, DATA_DIR) # 设置测试的列表
In [31]
设置label.txt 分为背景和滑坡两类
label_txt_path = os.path.join(DATA_DIR, ‘label.txt’)
with open(label_txt_path, ‘w’) as f:
f.write(‘background’)
f.write(‘\n’)
f.write(‘landslide’)
四、模型训练
In [2]
import sys
sys.path.append(‘/home/aistudio/PaddleRS’)
import paddlers as pdrs
from paddlers import transforms as T
In [5]
%cd /home/aistudio/PaddleRS/
根路径
DATA_DIR = ‘…/Bijie-landslide-dataset/dataset/’
训练集file_list文件路径
TRAIN_FILE_LIST_PATH = ‘…/Bijie-landslide-dataset/dataset/train.txt’
测试集file_list文件路径
TEST_FILE_LIST_PATH = ‘…/Bijie-landslide-dataset/dataset/test.txt’
数据集类别信息文件路径
LABEL_LIST_PATH = ‘…/Bijie-landslide-dataset/dataset/label.txt’
实验目录,保存输出的模型权重和结果
EXP_DIR = ‘./output/deeplabv3p/’
波段数量,RGB+DEM 所以是四通道
NUM_BANDS = 4
train_transforms = T.Compose([
# 将影像缩放到512x512大小
T.RandomCrop(
# 裁剪区域将被缩放到256x256
crop_size=224,
# 裁剪区域的横纵比在0.5-2之间变动
aspect_ratio=[1.0, 1.0],
# 裁剪区域相对原始影像长宽比例在一定范围内变动,最小不低于原始长宽的1/5
scaling=[0.8, 1.0]
),
# 以50%的概率实施随机水平翻转
T.RandomHorizontalFlip(prob=0.5),
T.RandomVerticalFlip(prob=0.5),
# 将数据归一化到[-1,1]
T.Normalize(
mean=[0.5] * NUM_BANDS, std=[0.5] * NUM_BANDS),
])
test_transforms = T.Compose([
# 验证阶段与训练阶段的数据归一化方式必须相同
T.Resize(target_size=224),
T.Normalize(
mean=[0.5] * NUM_BANDS, std=[0.5] * NUM_BANDS),
])
/home/aistudio/PaddleRS
In [6]
分别构建训练和验证所用的数据集
train_dataset = pdrs.datasets.SegDataset(
data_dir=DATA_DIR,
file_list=TRAIN_FILE_LIST_PATH,
label_list=LABEL_LIST_PATH,
transforms=train_transforms,
num_workers=4,
shuffle=True)
test_dataset = pdrs.datasets.SegDataset(
data_dir=DATA_DIR,
file_list=TEST_FILE_LIST_PATH,
label_list=LABEL_LIST_PATH,
transforms=test_transforms,
num_workers=0,
shuffle=False)
2022-06-07 21:18:47 [INFO] 1850 samples in file …/Bijie-landslide-dataset/dataset/train.txt
2022-06-07 21:18:47 [INFO] 923 samples in file …/Bijie-landslide-dataset/dataset/test.txt
In [ ]
import paddle
构建DeepLab V3+模型,使用ResNet-50作为backbone
目前已支持的模型请参考:https://github.com/PaddleCV-SIG/PaddleRS/blob/develop/docs/apis/model_zoo.md
模型输入参数请参考:https://github.com/PaddleCV-SIG/PaddleRS/blob/develop/paddlers/tasks/segmenter.py
model = pdrs.tasks.DeepLabV3P(
input_channel=NUM_BANDS,
num_classes=len(train_dataset.labels),
backbone=‘ResNet50_vd’)
设置100个epoch,大约1个小时训练完成
num_epoch = 100
train_batch_size = 32
DECAY_STEP =int(20 * train_dataset.len()/ train_batch_size)
LR = 0.001
lr_scheduler = paddle.optimizer.lr.StepDecay(
LR,
step_size=DECAY_STEP,
# 学习率衰减系数,这里指定每次减半
gamma=0.5
)
构造SGD优化器
optimizer = paddle.optimizer.Momentum(learning_rate=lr_scheduler, parameters=model.net.parameters(), weight_decay=5.0e-4)
执行模型训练
model.train(
num_epochs=num_epoch,
train_dataset=train_dataset,
train_batch_size=train_batch_size,
eval_dataset=test_dataset,
save_interval_epochs=5,
# 每多少次迭代记录一次日志
log_interval_steps=10,
save_dir=EXP_DIR,
optimizer=optimizer,
# 是否使用early stopping策略,当精度不再改善时提前终止训练
early_stop=False,
# 是否启用VisualDL日志功能
use_vdl=True,
# 指定从某个检查点继续训练
resume_checkpoint=None)
五、模型测试与预测
训练好模型之后,就可以将其用来对测试集测试
同时也可以进行滑坡的识别,记住需要输入RGB和DEM合并的数据
5.1 模型测试
In [9]
使用已经训练好的权重进行预测,如果要换成自己训练的权重,更改路径即可
model_path = r"…/work/best_model/model.pdparams"
为模型加载历史最佳权重
state_dict = paddle.load(model_path)
model.net.set_state_dict(state_dict)
执行测试
test_result = model.evaluate(test_dataset)
print(
“测试集上指标:mIoU为{:.2f},OAcc为{:.2f},Kappa系数为{:.2f}”.format(
test_result[‘miou’],
test_result[‘oacc’],
test_result[‘kappa’],
)
)
print(“各类IoU分别为:”+‘, ‘.join(’{:.2f}’.format(iou) for iou in test_result[‘category_iou’]))
print(“各类Acc分别为:”+‘, ‘.join(’{:.2f}’.format(acc) for acc in test_result[‘category_acc’]))
print(“各类F1分别为:”+‘, ‘.join(’{:.2f}’.format(f1) for f1 in test_result[‘category_F1-score’]))
2022-06-07 22:44:05 [INFO] Start to evaluate(total_samples=923, total_steps=923)…
测试集上指标:mIoU为0.80,OAcc为0.99,Kappa系数为0.75
各类IoU分别为:0.99, 0.61
各类Acc分别为:0.99, 0.75
各类F1分别为:0.99, 0.76
训练了100epoch之后,mIOU达到了80%,但是滑坡类的IOU还不是很高,为61%,后续可以自行调参
5.2 预测结果
对RGB+DEM数据生成的.npy文件进行预测
In [20]
!cp …/Bijie-landslide-dataset/dataset/test/df034.npy …/work/test/
!cp …/Bijie-landslide-dataset/dataset/test_label/df034.png …/work/test_label/
In [26]
import numpy as np
import matplotlib.pyplot as plt
from PIL import Image
%matplotlib inline
state_dict_path = r"…/work/best_model/model.pdparams" # 模型权重
npy_path = r"…/work/test/df034.npy" # npy文件
label_path = r"…/work/test_label/df034.png" # label文件
gt_label = np.array(Image.open(label_path))
transforms = T.Compose([
T.Resize(target_size=224),
T.Normalize(
mean=[0.5] * NUM_BANDS, std=[0.5] * NUM_BANDS)
# transform方式必须要相同
])
model.net_initialize(pretrain_weights = state_dict_path)
model.net.eval()
image = {‘image’: npy_path}
image = transforms(image)
input = image[“image”].transpose((2, 0, 1))
input = paddle.to_tensor(input).unsqueeze(0)
logits, *_ = model.net(input)
pred = paddle.argmax(logits[0], axis=0)
pred = pred.numpy().astype(np.uint8) # 得到预测结果
data = np.load(npy_path)
plt.figure(figsize=(15,10))
plt.subplot(2,2,1), plt.title(“RGB”)
plt.imshow(data[:, :, 0:3].astype(np.uint)), plt.axis(“off”)
plt.subplot(2,2,2), plt.title(“DEM”)
plt.imshow(data[:, :, 3]), plt.axis(“off”)
plt.subplot(2,2,3), plt.title(“Pred”)
plt.imshow(pred), plt.axis(“off”)
plt.subplot(2,2,4), plt.title(“GT”)
plt.imshow(gt_label*255), plt.axis(“off”)
plt.show()
2022-06-08 00:42:10 [INFO] Loading pretrained model from …/work/best_model/model.pdparams
2022-06-08 00:42:10 [INFO] There are 360/360 variables loaded into DeepLabV3P.
六、总结
使用PaddleRS可以进行RGB+DEM的数据的训练
利用DeepLabV3+模型进行滑坡识别,对滑坡的预测IOU效果还可以,但是没有仔细的调参,仍有提升的空间

学大模型,用大模型上飞桨星河社区!每天8点V100G算力免费领!免费领取ERNIE 4.0 100w Token >>>
更多推荐



 10
10 0
0- 0



 已为社区贡献1437条内容
已为社区贡献1437条内容

所有评论(0)