
ECCV2022:KD-SCFNet文章解读与模型使用
论文首先提出了一个轻量级的显著目标检测分割模型SCFNet,该模型在精度和效率上远优于现有的方法,然后通过知识蒸馏提升小模型的性能,最后论文还提出新的损失函数和边界学习方法PBSM。
前言
这是我之前的一个工作,从去年11月份提出到3月份投稿,7月份接收,最终三个审稿人的评分为Accept、Weak Accept、Weak Accept,也就是122的得分,论文最后评定为Poster。文章的想法启发于PaddleClas文档的知识蒸馏,所以将最经典的知识蒸馏应用在了我的领域上。本项目可能介绍文章的内容有点晦涩,需要点图像分割的知识储备,这里进行中文版本的介绍,尽可能地描述清楚。与论文不同的是,这里会进行较为基础的说明,帮助大家理解论文。大家有兴趣可以看看文章。
文章的github地址:https://github.com/zhangjinCV/KD-SCFNet (求star)
文章就放在项目里了,欢迎下载。
相关项目:
第三届中国AI+创新创业大赛:半监督学习目标定位竞赛第1名方案
显著目标检测研究方向与Paddle处理CV任务时的代码技巧分享1
显著目标检测研究方向与Paddle处理CV任务时的代码技巧分享2
显著目标检测

显着目标检测(SOD)是计算机视觉的一项基本任务。它旨在通过模仿人类视觉的注意力机制来检测图像中最吸引人的区域。作为一种高效的预处理技术,SOD 广泛用于许多计算机视觉任务,例如图像翻译、对象跟踪、语义分割、图像检索等。如上图所示,彩色图就为模型的输入,模型输出的结果要趋近于彩色图右侧的黑白分割图,不同于语义分割,SOD任务的语义指的是显著的物体,而非每个类别,因此SOD任务是不固定类别的分割任务,较难于固定类别的分割。SOD的主要任务在于分割出图像中的显著目标,“显著”一词说明了该任务数据集标注时存在一定的主观因素,同时显著一词大多表面物体多出现于图像的中心区域,所以在早期基于传统机器学习的方法中有提出例如中心先验、颜色先验等先验方法。
自2016年来,基于深度学习的方法逐渐开始应用于SOD任务,由最开始超像素判断,到基于FCN和UNet方式的编码-解码架构实现了端到端的像素级预测。许多工作提出了各种优秀的模型,但是围绕着SOD存在的棘手问题依然没有被解决,例如:
- 大多数的SOD模型都结构复杂,参数量大,导致难以应用部署。虽然有轻量级SOD模型被提出,但精心设计的轻量级结构依然难以抵消精度的缺失。
- 由于数据标注存在主观性,需要多人协同标注,这就造成了标注SOD数据集需要大量的人力物力,以至于现有的训练集数据量少,模型又因数据集的数量陷入了性能瓶颈。
- 由于是二值分割任务,所以为了达到精细的边界,越来越多的工作应用边界监督来提升模型的效果,这无疑是有效的,但是并没有考虑到不同训练阶段边界的不同效果,导致了训练前期边界监督不利于模型快速收敛。
如上所述,设计一个既快又好的SOD模型是极具挑战的,因此,面对所提到的问题,我们设计了一个轻量级的更好的更快的SOD模型。
模型设计
SOD模型类似于UNet的结构,将从骨干网络(图像分类模型)获取4或5层具有不同尺寸和通道数的特征按照不同的解码方式放入解码器,最后经过3×3卷积以及sigmoid激活函数输出单通道的结果图。SOD任务有着一个既定的规则,因为骨干网络,即图像分类模型的准确率会严重影响整个模型的效果,因此往往选择相同的骨干网络,即VGG-16或者ResNet-50。然后设计自己的解码模块、损失函数等作为创新点。但是由于轻量级模型的设计,肯定不会选择VGG或者ResNet这样的重模型,所以轻量级的模型往往自己设计骨干网络或者选择轻量级的分类模型,比如MobileNet、ShuffleNet等。
骨干网络
为了构建轻量级模型,同时考虑参数和特征提取能力,我们选择了MobileNet V3作为骨干网络,这里采用的是MobileNet V3 Large 0.5的版本。下图展示了不同模型参数量、计算量、准确率的对比。

解码网络
解码器是论文提出的核心模块,随着UNet的提出,越来越多的模型使用UNet的解码器恢复图像的分辨率并实现端到端的预测,值得注意的是,U 形编码器解码器架构会导致深层特征在转移到较低层时逐渐被稀释。一些工作通过将深层特征分别输入每个融合层来改进这个问题。刘等人对相邻层特征和最深特征进行像素级相加,以获得更多的上下文信息,而 Chen 等人采用逐像素乘法来更好地融合特征。虽然这些方法可以取得很好的效果,但由于粗鲁的融合,它们需要额外的模块来优化融合特征。这就造成了模型的结构复杂,不易运行等问题。直观地说,深层特征具有更高层次的语义信息,可以更好地引导浅层特征定位显着对象,而具有细节信息的低层次上下文特征更有利于产生具有精细边界的对象. 因此,我们设计了一个语义引导的上下文融合模块(SCFM),以有效地整合低层和深层特征的互补信息。假设输入图像的大小为 H × W × 3 H × W × 3 H×W×3,其中 H H H 和 W W W 分别为高和宽,我们可以得到大小为 [ H / 2 i , W / 2 i ] [ H/2^i , W/2^i ] [H/2i,W/2i] 来自骨干网。尺寸较大的特征 f 1 、 f 2 f^1、f^2 f1、f2 和 f 3 f^3 f3 是低级特征, f 4 f^4 f4 和 f 5 f^5 f5 是高级特征。 f 1 、 f 2 f^1、f^2 f1、f2 和 f 3 f^3 f3具有物体的细节和纹理信息, f 4 f^4 f4 和 f 5 f^5 f5由于低分辨率,图像较为粗糙,但是随着分辨率的降低,其语义信息的表达也越为突出,所以称之为高级特征, f 5 f^5 f5则是最深层特征。下图是我们的解码器和之前的一些方法的对比。
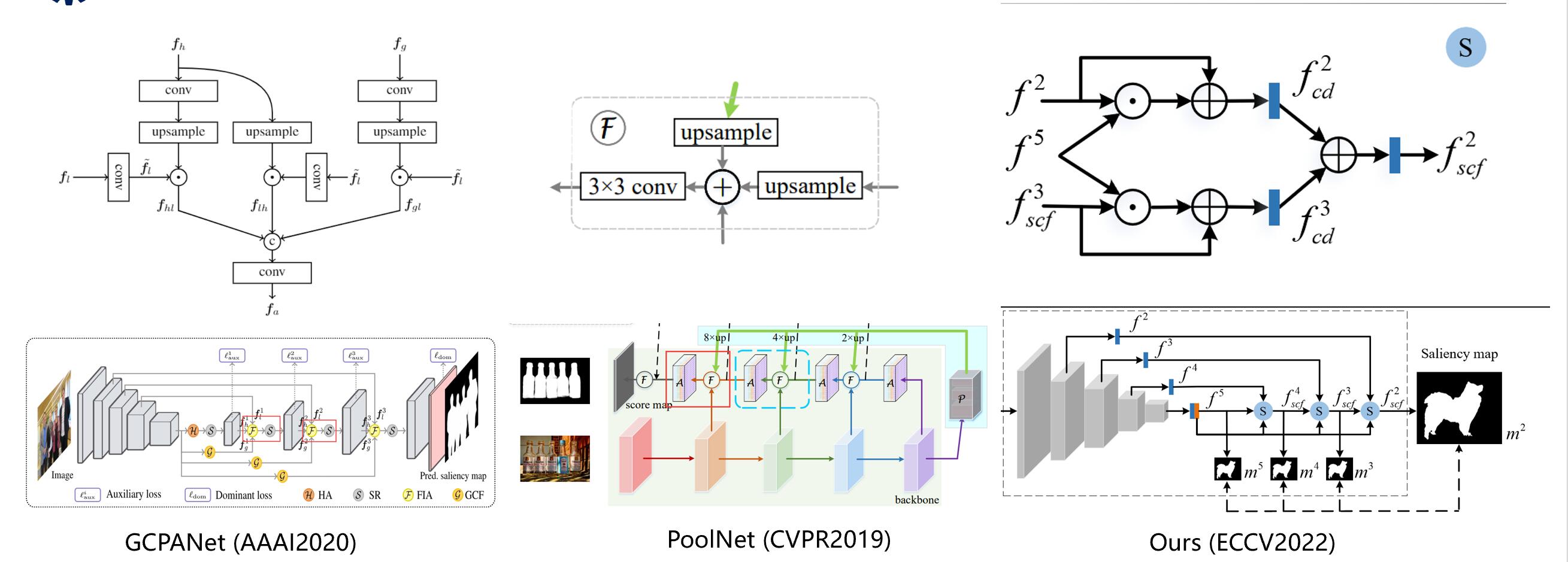
GCPANet对上下文特征与最深层特征采取直接粗暴的像素级乘积,而PoolNet是像素级相加的方法,这都需要一些后续的模块进行优化,改善合成的不利效果。而我们设计的模块语义引导的上下文融合模块(SCFM)通过将全局深层特征融合到低层上下文特征中更准确地捕获显着对象,然后通过融合低层上下文特征生成具有精细边界的显着对象。SCFM没有直接将深层特征与浅层上下文特征直接相乘或者相加,而是先用乘法的方式指导浅层特征定位目标,然后使用残差连接的方式保持浅层特征的细节。
SCFNet
因此,我们提出了一种新的轻量级 SOD 框架,名为语义引导的上下文融合网络 (SCFNet),它仅由编码器 MobileNet V3 和由 SCFM 组成的解码器组成。 由于精心设计的解码架构,SCFNet 不需要在每个 SCFM 之后添加辅助模块即可完成语义和细节分割。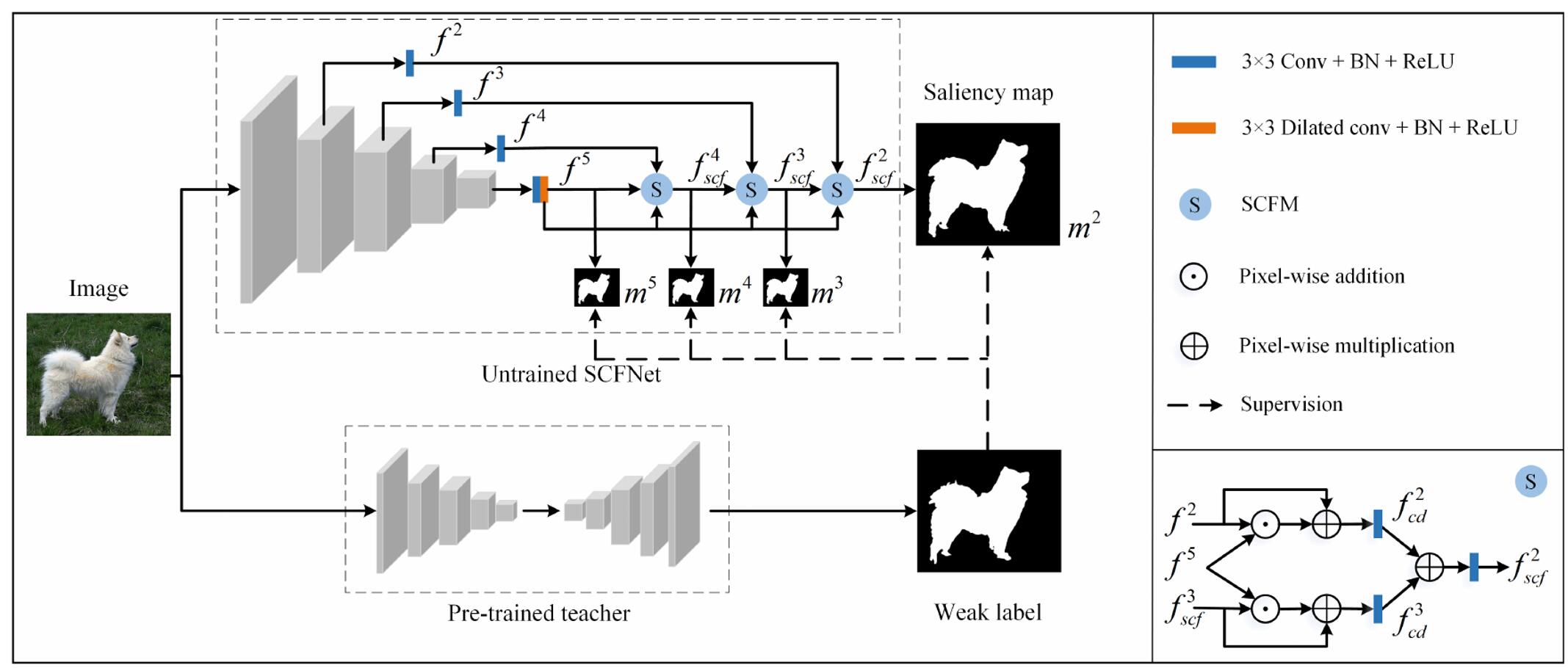
上图就是所提出的 SCFNet 的整体架构和知识蒸馏的过程。 m i , i ∈ 2 , 3 , 4 , 5 m^i, i ∈ {2, 3, 4, 5} mi,i∈2,3,4,5 是经过处理的特征 f i f^i fi 得到的显著图。 SCFM是语义引导的上下文融合模块,右下角以最后一个SCFM为例描述了特征处理流程。
知识蒸馏
之前说到,SOD任务的训练数据少,标注难度大,为了打破像素级注释图像的限制并获得性能更好的模型,我们将知识蒸馏引入 SOD 任务,并提出了一种基于知识蒸馏的 SCFNet (KD-SCFNet)。知识蒸馏是由 Hinton 等人正式提出的,它将黑暗的知识从复杂的教师传递给紧凑的学生模型,使学生能够保持作为教师的强泛化。在本文中,我们构建并训练了一个比轻量级网络具有更多表征能力的教师模型,以将暗知识转移到未经训练的学生模型中。具体来说,教师在常用的 SOD 训练数据集上进行训练,将自然图像上的预测结果视为弱标签来监督未经训练的 SCFNet。由于从教师模型中提取和转移的知识,KD-SCFNet 将学习到强大的泛化能力来检测准确的显着对象。值得一提的是,为了区别于基于知识蒸馏的 SCFNet,以全监督方式训练的 SCFNet 被命名为 FS-SCFNet。
教师模型
为了展示所提出的解码器SCFM的鲁棒性、有效性,同时为了保证重量级模型对比的公平性,我们简单地将SCFNet的骨干网络换为ResNet-50,从而构造了一个教师模型即,SCFNet R 50 _{R50} R50.
学生模型
学生模型即为上述提到的SCFNet,为了体现蒸馏的有效性,我们同时训练了全监督的SCFNet,分别叫KD-SCFNet和FS-SCFNet。KD表示知识蒸馏,FS表示全监督。
KD-SOD80K
在知识蒸馏的过程中,我们需要一个额外的自然场景图像数据库来生成弱标签来训练学生模型。 因此,我们在考虑蒸馏的增益和效率的情况下,从ImageNet数据集中选择了 80K 图像,并且每张图像至少有一个显著对象。我们将此未标记的数据集命名为 KD-SOD80K,为了进行公平比较,KD-SOD80K 不包含来自任何 SOD 数据集的图像。
蒸馏Pipeline
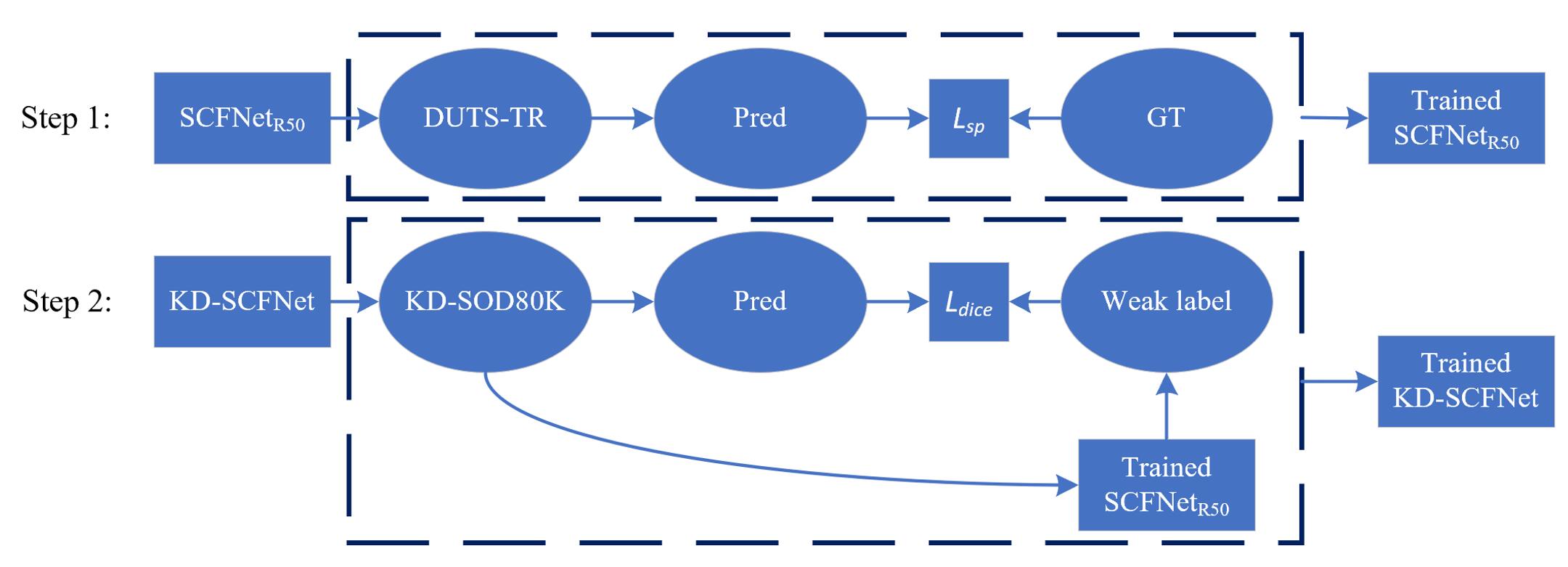
这是整个模型的训练pipeline,这里的DUTS-TR表示训练集,是一个有像素级标注的SOD任务公认的训练集,有10553对图像,KD-SOD80K是我们提供的无标签的图像数据集。 L s p L_{sp} Lsp 和 L d i c e L_{dice} Ldice 为两个损失函数,后面会介绍到。
损失函数
SP Loss
SOD任务中常用的二值交叉熵(BCE)损失函数独立计算每个像素的损失,不能很好地处理样本不平衡问题,同时不会考虑像素点之间的关系,而图像分割这种密集预测任务,一个像素周围往往是同类像素。此外,训练集中正负样本的比例约为 2:5,这导致 BCE loss 监督的模型性能不佳。一些工作应用 DICE 损失来解决图像分割中前景和背景区域之间的样本不平衡问题。 DICE 损失对结果施加全局约束,使得预测图与GT的总和相关。因此,我们引入 DICE loss 来克服尺度变化引起的样本不平衡,公式如下: L d i c e ( P , G ) = 1 − 1 + ∑ i = 1 , j = 1 H , W 2 × G i j × P i j 1 + ∑ i = 1 , j = 1 H , W G i j + P i j L_{dice}(P, G) = 1 -\frac{1 + \sum^{H, W}_{i=1, j = 1} 2 \times G_{ij} \times P_{ij}}{1 + \sum^{H, W}_{i=1, j = 1}G_{ij} + P_{ij}} Ldice(P,G)=1−1+∑i=1,j=1H,WGij+Pij1+∑i=1,j=1H,W2×Gij×Pij
P P P 为预测图, G G G为GT图。
虽然 DICE loss 可以更好地优化模型,但模型对边界区域仍然缺乏足够的约束,导致显着图中的边界模糊。为了解决这个问题,我们构造了一个边界 DICE(BD)损失来显式学习显著对象的边界,可以表示为:
L b d ( P b , G b ) = 1 − 1 + ∑ i = 1 , j = 1 H , W 2 × G i j b × P i j b 1 + ∑ i = 1 , j = 1 H , W G i j b + P i j b L_{bd}(P^b, G^b) = 1 -\frac{1 + \sum^{H, W}_{i=1, j = 1} 2 \times G_{ij}^{b} \times P_{ij}^{b}}{1 + \sum^{H, W}_{i=1, j = 1}G_{ij}^{b} + P_{ij}^{b}} Lbd(Pb,Gb)=1−1+∑i=1,j=1H,WGijb+Pijb1+∑i=1,j=1H,W2×Gijb×Pijb
我们首先应用膨胀操作和腐蚀操作来获得 G G G 和预测图 P P P的边界图 G b , t h i n G^{b,thin} Gb,thin 和 P b , t h i n P^{b,thin} Pb,thin。然后,我们使用最大池化操作来扩大边界的覆盖范围。 max ( ⋅ ) \max(\cdot) max(⋅) 表示最大池化操作, A i j A_{ij} Aij 表示围绕像素 ( i , j ) (i,j) (i,j) 的池化区域。面积越大,边界越厚。对于较薄的边界图,早期训练阶段较大的边界损失波动难以有效引导模型,较厚的边界难以准确勾勒出物体的轮廓。因此,我们提出了一种渐进式边界监督方法(PBSM)。具体来说,总训练 epoch 为 69。我们将池化区域设置为 13$\times$13,以便在训练的前 10 个 epoch 中获得更厚的边界,以帮助网络更好地定位显著对象,并每 10 个 epoch减少 2 个池化区域的边长。在最后 9 个 epoch 中,我们使用最薄的边界精细地勾勒出显著对象。我们将 DICE 损失和 BD 损失结合起来,将其命名为结构抛光(SP)损失,可以概括为:
L s p = L d i c e + λ L b d L_{sp} = L_{dice} + \lambda L_{bd} Lsp=Ldice+λLbd
其中 λ \lambda λ 是一个平衡两个损失贡献的超参数。 为简单起见,将其设置为 1。
PBSM可以简单理解为下面的图。
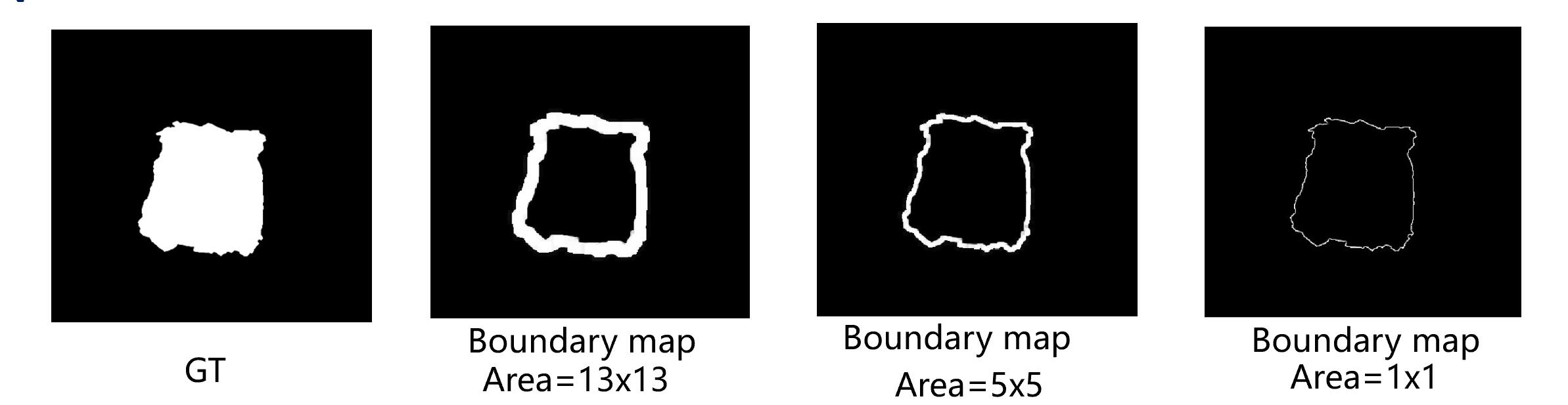
边界图由开操作和闭操作获得,不同的宽厚由不同size的最大池化操作获得,最后控制池化区域逐渐缩减厚度。
监督方式
对于 FS-SCFNet,我们使用 SP 损失来指导模型,而对于 KD-SCFNet,由于教师产生的弱标签往往没有细致的边界,我们选择 DICE 作为损失函数。多级监督策略用于指导训练模型。具体来说,训练模型的总输出是显著图 m i ( i = 2 , 3 , 4 , 5 ) m^i(i = 2, 3, 4, 5) mi(i=2,3,4,5),其取值范围为 [0-1],由特征 f i s c f , ( i = 2 , 3 , 4 ) f^iscf , (i = 2, 3, 4) fiscf,(i=2,3,4) 和 f 5 f^5 f5 经过 3×3 卷积和 sigmoid 操作。我们将损失的总和定义为总损失。此外,显着性图 m 2 m^2 m2 是模型的结果,提供了占主导地位的损失;其他显着性图提供辅助损失。并且由于辅助损失的值大于主要损失,我们为它们分配了较小的权重。总损失定义为:
L F S = ∑ i = 2 5 1 2 i − 2 L s p ( m i , G ) L K D = ∑ i = 2 5 1 2 i − 2 L d i c e ( m i , G ) L_{FS} = \sum\nolimits_{i = 2}^{5}\frac{1}{2^{i-2}}L_{sp}(m^i, G) \\ L_{KD} = \sum\nolimits_{i = 2}^{5}\frac{1}{2^{i-2}}L_{dice}(m^i, G) LFS=∑i=252i−21Lsp(mi,G)LKD=∑i=252i−21Ldice(mi,G)
对比
指标
FS-SCFNet、KD-SCFNet 和其他最先进的方法的性能通过七种不同的评估指标进行评估,包括参数(Params)、浮点运算(FLOPs)、每秒帧数(FPS)、 乘累加运算 (MACC)、平均绝对误差 ( M M M) 、Fmeasure (F β _{\beta} β) 和 E-measure ( E β E_{\beta} Eβ) 。为了公平比较,所有指标均在同一台计算机上计算,该计算机具有一个 Intel i7-11700 CPU 和一个 RTX 3080TI GPU。在计算Params、FPS、FLOPs和MACCs时,输入图像被resize到相应论文中报告的大小,其他评估指标由论文作者提供的显著图计算。
数值对比
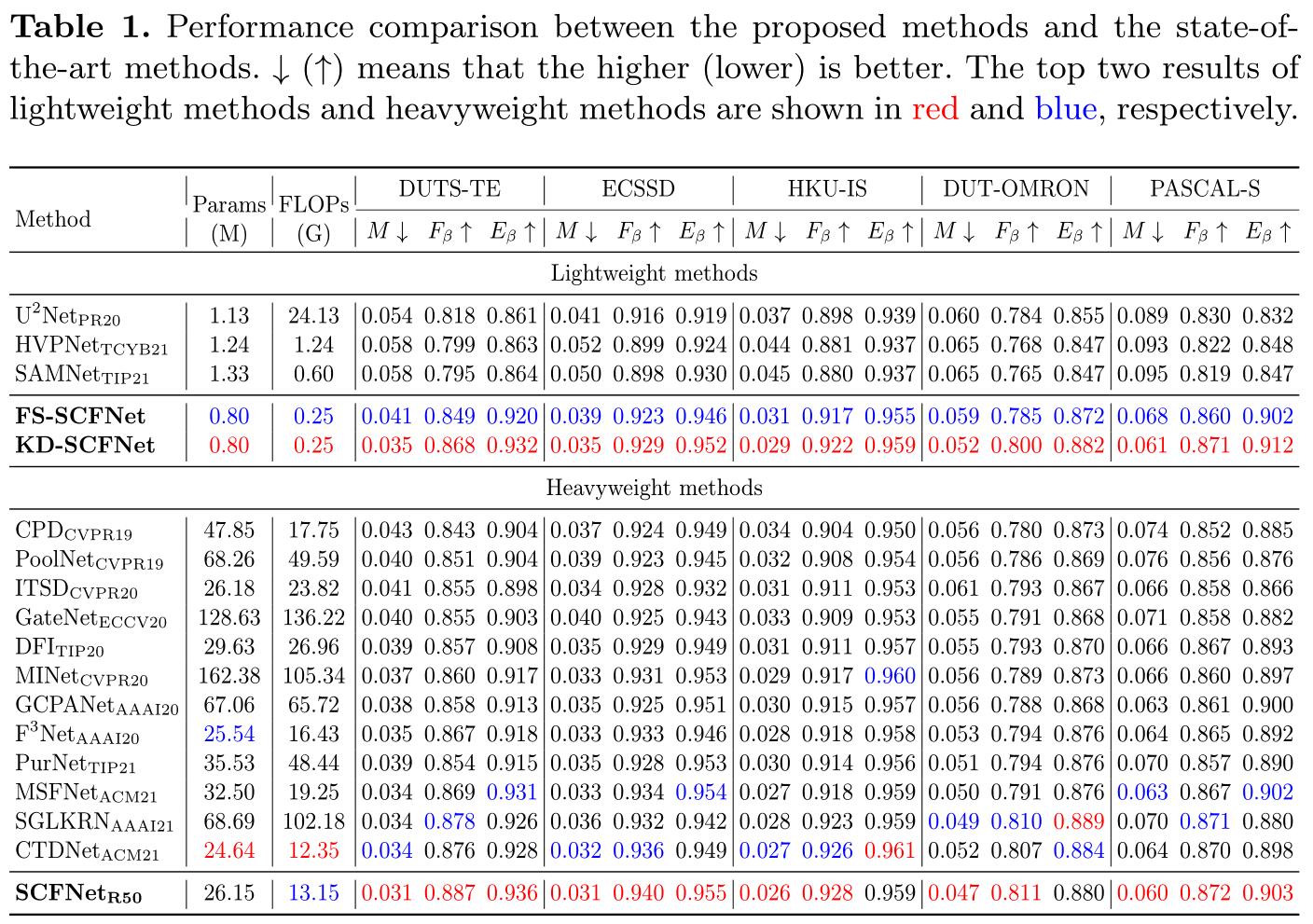
上表显示了在 Params、FLOPs、 M M M、 F β F_{\beta} Fβ 和 E β E_{\beta} Eβ 方面在五个流行数据集的定量比较。可以看出,所提出的 KD-SFNet 在五个数据集上优于所有轻量级方法。与 FS-SCFNet 相比,KD-SCFNet 在五个数据集上的平均绝对误差降低了 10.9%,证明了所提蒸馏方法的有效性。此外,KD-SCFNet 具有显着的性能 10 Zhang 等人。与其他轻量级方法相比的优势。与 SAMNet、HVPNet 和 U2Net 相比,KD-SCFNet 在五个数据集上的平均绝对误差的结果分别降低了 32.3%、32.1% 和 24.6%。 FS-SCFNet 作为一个全监督的轻量级模型,虽然不如 KD-SCFNet 优秀,但与其他现有的轻量级模型相比,它在准确性和效率上仍然具有明显的优势。与重量级方法相比,轻量级 SCFNets 仅包含 0.8M 参数和 0.25G FLOPs,但仍然取得了出色的效果。 KD-SCFNet 在五个数据集上的结果甚至优于一些重型模型产生的结果,例如 PurNet [14]、GCPANet [4] 和 DFI [17]。我们还列出了基于重量级 ResNet-50 的模型之间的比较,我们的 SCFNetR50 在效率和有效性方面取得了最好的结果。总之,KD-SCFNet 和 FS-SCFNet 以弱监督和全监督的方式为显着性检测提供了更准确和有效的解决方案。作为重量级的 SCFNet R 50 _{R50} R50,SCFNet R 50 _{R50} R50 为精确 SOD 提供了更好的选择。
显著图对比

我们在上图中选择了一些具有代表性的显著目标检测场景进行视觉比较。这些场景反映了各种场景,包括简单的情况(第 1 行)、低对比度场景中的小物体(第 2 和第 3 行)、低对比度场景中的大物体(第 4 行),具有复杂结构的多个对象(第 5 行和第 6 行)。可以看出,所提出的 FS-SCFNet 和 KD-SCFNet 可以始终如一地生成具有清晰边界和连贯细节的准确完整的显着图。
速度对比
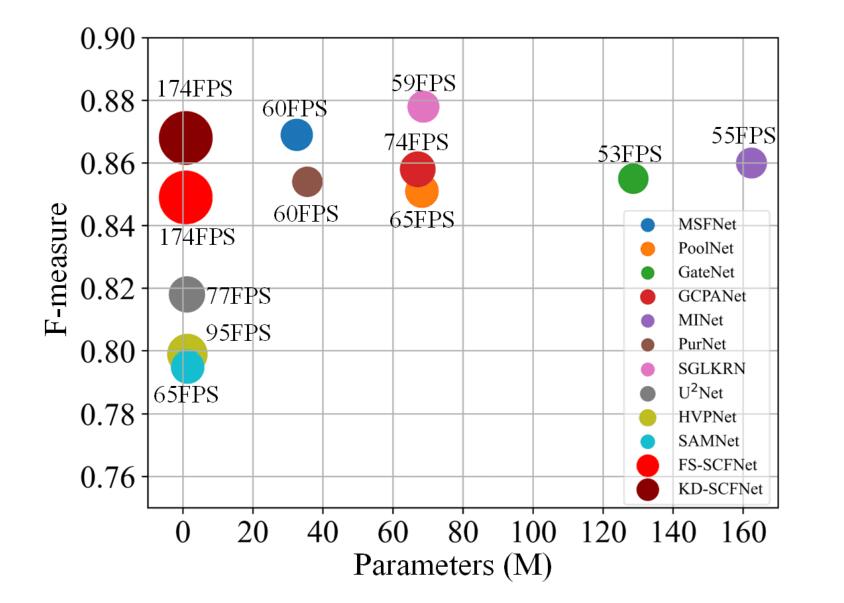
我们的方法(FS-SCFNet、KD-SCFNet)与现有方法在参数、准确性和速度方面的比较。度量 F-measure 在 DUTS-TE 数据集中计算。不同的颜色表示不同的方法,圆圈的大小代表检测的速度。
总结
碍于篇幅限制,并且由于罗里吧嗦了一堆可能晦涩难懂的内容,本项目就不展示文章关于消融实验的内容了。简单做下贡献点总结。
-
我们设计了一个语义引导的上下文融合模块(SCFM),有效地利用了深层特征的高级语义信息和低级上下文特征的详细信息,并构建了一个基于SCFM的轻量级显著对象检测模型。
-
我们将知识蒸馏引入 SOD 任务。从预训练的教师模型提取的知识被转移给学生,使其比完全监督训练的方式得到的模型更加出色。据我们所知,我们是第一个将知识蒸馏应用于 SOD 任务的。此外,我们提供了一个大型未标记数据集 KD-SOD80K 用于显著目标检测。
-
我们提出了一种结构抛光损失和渐进式边界监督方法,它更加关注边界细节,并帮助网络减轻在不同训练阶段由于边界偏差造成的不利影响。
-
我们对 6 个数据集进行了广泛的实验,并将所提出的轻量级模型与 15 种现有的最先进的 SOD 方法进行了比较。蒸馏实验和对比实验结果证明了所提方法的有效性和优越性。
体验SOD分割
import numpy as np
import paddle
from SCFNet.net import SCFNet
from paddle import nn
import cv2
import paddle
from paddle.nn import functional as F
def predict(path):
net = SCFNet(1, 'M3_0.5')
net.load_dict(paddle.load(r"SCFNet/KD-SCFNet.pdparams"))
net.eval()
img = cv2.imread(path)[:, :, ::-1]
h, w, c = img.shape
tk = img
img = img - np.array([[[124.55, 118.90, 102.94]]])
img = img / np.array([[[56.77, 55.97, 57.50]]])
img = cv2.resize(img, dsize=(352, 352))
img = img.transpose((2, 0, 1))
img = paddle.to_tensor(img, dtype=paddle.float32).unsqueeze(0)
with paddle.no_grad():
out = net(img)[0]
out = F.sigmoid(out)
out = F.interpolate(out, size=(h, w), mode='bilinear')
out = (out[0]).numpy().transpose(1, 2, 0)
out_mask = out
out = out * tk
out = out[:, :, ::-1]
out_origin = out
return tk, out_mask * 255, out_origin[:, :, ::-1]
if __name__ == '__main__':
# 可将下面的图片换为自己的图片测试玩一玩
origin, out_mask, out_origin = predict("ILSVRC2012_test_00001060.jpg")
/home/aistudio/SCFNet/backbones/SwinT.py:6: DeprecationWarning: Using or importing the ABCs from 'collections' instead of from 'collections.abc' is deprecated, and in 3.8 it will stop working
from collections import Callable
%matplotlib inline
import matplotlib.pyplot as plt
plt.figure(figsize=(16, 6.5))
plt.subplot(131)
plt.imshow(np.uint8(origin))
plt.subplot(132)
plt.imshow(out_mask[:, :, 0], cmap='gray')
plt.subplot(133)
plt.imshow(np.uint8(out_origin))
# 从左到右,依次为原图,显著图,显著图*原图的结果。
/opt/conda/envs/python35-paddle120-env/lib/python3.7/site-packages/matplotlib/__init__.py:107: DeprecationWarning: Using or importing the ABCs from 'collections' instead of from 'collections.abc' is deprecated, and in 3.8 it will stop working
from collections import MutableMapping
/opt/conda/envs/python35-paddle120-env/lib/python3.7/site-packages/matplotlib/rcsetup.py:20: DeprecationWarning: Using or importing the ABCs from 'collections' instead of from 'collections.abc' is deprecated, and in 3.8 it will stop working
from collections import Iterable, Mapping
/opt/conda/envs/python35-paddle120-env/lib/python3.7/site-packages/matplotlib/colors.py:53: DeprecationWarning: Using or importing the ABCs from 'collections' instead of from 'collections.abc' is deprecated, and in 3.8 it will stop working
from collections import Sized
/opt/conda/envs/python35-paddle120-env/lib/python3.7/site-packages/matplotlib/cbook/__init__.py:2349: DeprecationWarning: Using or importing the ABCs from 'collections' instead of from 'collections.abc' is deprecated, and in 3.8 it will stop working
if isinstance(obj, collections.Iterator):
/opt/conda/envs/python35-paddle120-env/lib/python3.7/site-packages/matplotlib/cbook/__init__.py:2366: DeprecationWarning: Using or importing the ABCs from 'collections' instead of from 'collections.abc' is deprecated, and in 3.8 it will stop working
return list(data) if isinstance(data, collections.MappingView) else data
<matplotlib.image.AxesImage at 0x7fb2c408bb90>
/opt/conda/envs/python35-paddle120-env/lib/python3.7/site-packages/matplotlib/image.py:425: DeprecationWarning: np.asscalar(a) is deprecated since NumPy v1.16, use a.item() instead
a_min = np.asscalar(a_min.astype(scaled_dtype))
/opt/conda/envs/python35-paddle120-env/lib/python3.7/site-packages/matplotlib/image.py:426: DeprecationWarning: np.asscalar(a) is deprecated since NumPy v1.16, use a.item() instead
a_max = np.asscalar(a_max.astype(scaled_dtype))

origin, out_mask, out_origin = predict("0068.jpg")
%matplotlib inline
import matplotlib.pyplot as plt
plt.figure(figsize=(16, 6.5))
plt.subplot(131)
plt.imshow(np.uint8(origin))
plt.subplot(132)
plt.imshow(out_mask[:, :, 0], cmap='gray')
plt.subplot(133)
plt.imshow(np.uint8(out_origin))
# 从左到右,依次为原图,显著图,显著图*原图的结果。
<matplotlib.image.AxesImage at 0x7fb210140a50>

origin, out_mask, out_origin = predict("danrenbudaikouzhaozhengchang.mp4_047_snapshot_001.jpg")
%matplotlib inline
import matplotlib.pyplot as plt
plt.figure(figsize=(16, 6.5))
plt.subplot(131)
plt.imshow(np.uint8(origin))
plt.subplot(132)
plt.imshow(out_mask[:, :, 0], cmap='gray')
plt.subplot(133)
plt.imshow(np.uint8(out_origin))
_origin))
# 从左到右,依次为原图,显著图,显著图*原图的结果。
<matplotlib.image.AxesImage at 0x7fb2100f5e50>

关于作者
姓名:张晋
学校:上海应用技术大学,研二
研究方向:CV,图像分割,显著目标检测
AI Stidio链接:https://aistudio.baidu.com/aistudio/personalcenter/thirdview/635490
github链接:https://github.com/zhangjinCV
个人荣誉:PPDE。CCF会员。《第三届中国AI+创新创业大赛:半监督学习目标定位竞赛》第一名。《CCF真实场景下的水表读数自动识别》第一名。一篇ECCV。3篇SCI。
如果喜欢这个项目的话,欢迎点赞关注。
论文github地址:https://github.com/zhangjinCV/KD-SCFNet 求star
此文仅为搬运,原作链接:https://aistudio.baidu.com/aistudio/projectdetail/4303214

学大模型,用大模型上飞桨星河社区!每天8点V100G算力免费领!免费领取ERNIE 4.0 100w Token >>>
更多推荐



 0
0 0
0- 0



 已为社区贡献1436条内容
已为社区贡献1436条内容

所有评论(0)