
动漫线稿上色项目
给动漫线稿上色,基于spade论文
转载AI Studio项目链接https://aistudio.baidu.com/aistudio/projectdetail/3483236
动漫线稿上色项目
任务描述
本项目目的就是输入一个动漫线稿,然后一键给线稿上色
数据集介绍
来自这个网址https://www.kaggle.com/ktaebum/anime-sketch-colorization-pair
在这里展示一下其中一张照片:
左边就是Ground Truth,右边是input。
原来这张图片是512*1024,然后是RGB三通道,从中间分开左边和右边都是512*512.
因为输入的是线稿,只有黑白,那么这里我就把它通过one_hot处理成二分值的形式。然后我采取的仍然是基于 SPADE的模型。

然后依旧是利用vae,encoder提供mu,log_var,然后通过下面这个方法得到z,输入到decoder(生成器),mu和logvar的shape都为[batch,64*8,8,8]
def reparameterize(self,mu, logvar):
std = paddle.exp(0.5 * logvar)
eps = paddle.randn([self.batch_size,64*8,8,8])
return paddle.multiply(eps,std) + mu
为了好训练我把GT和input都resize成256*256.
效果展示
从左到有:GT,INPUT,生成的图片,然后我也测试了不同的模型参数文件检验效果

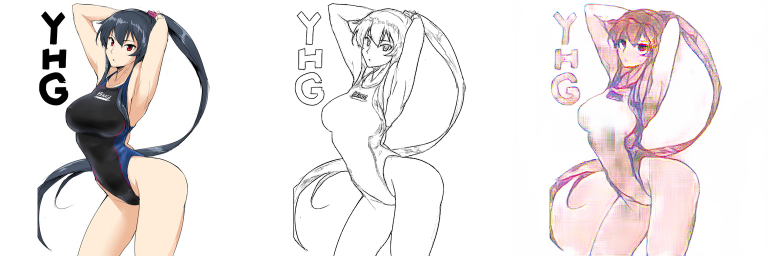



从描述问题到改进的一些想法:
-
生成的图片就是人物颜色还是不够纯,感觉像彩铅的感觉。这个我认为其中之一就是人物占整个图片只有一点点,所以算图片loss,很大程度被背景白色影响了。那么如何改进呢?
- 添加个人物蒙版这个也行,然后把Loss注重在人物蒙版上,类似权重交叉熵。但是这个人物蒙版最好有现成的机器学习方法,不建议专门继续为了这个花很多力气。
- 图像构造的时候我只用了resize,可以使用中心裁剪,设置一个随机数当大于0.3为resize,小于0.3为centercrop,因为centercrop的图片就是很大部分都是人物一部分,有鲜明颜色。
-
生成的颜色比较单一,不屌。这个是我现在能力还不够,现在正在钻研这方面。
- 多样性,目前我的改进想法是spade添加一个统一的noise,训练的时候这个noise与GT经过encoder的特征信息紧密相关,这样才方便训练,不然如果训练的时候noise就是randn就很难收敛。等我看完INADE代码具体这块怎么实现我再继续尝试。
-
训练的时候我发现输出的结果挺好,很精致,但是测试的时候不行。
- 因为我训练使用的是z是来自GT经过encoder的信息,deocder太过于依赖这部分了,但是测试的时候z是randn,所以导致这方面问题。我的策略是设置一个随机数当大于0.3为来自encoder的z,小于0.3z为randn.使decoder不过分依赖encoder.
def forward(self,img,seg):
mu, logvar = self.encoder(img)
r = random.random()
if r>0.7:
z = self.reparameterize(mu, logvar)
else:
z = paddle.randn([self.batch_size,64*8,8,8])
img_fake = self.generator(seg,z)
return img_fake,mu,logvar
-
color_loss使用可以帮我图像看上去色彩亮一点,不然其实有点黯淡。这个确实不错。
-
生成器和判别器可以预先预训练,然后再添加对抗loss.
欢迎大家提供宝贵想法。
核心文件讲解:
MODEL.py为训练的主模型文件
MODEL_test.py 是为了测试基于MODEL.py改动的,只输出img_fake,输入的只有二分值tensor
接下来就是训练代码了。
注意:
在最后我提供测试代码,解压了数据集就可以直接单独运行了。
# 解压数据集,只需执行一次
import os
# if not os.path.isdir("./data/d"):
# os.mkdir("./data/d")
d")
# ! unzip data/data128161/archive.zip -d ./data/d
from paddle.vision.transforms import CenterCrop,Resize
transform = Resize((256,256))
#构造dataset
IMG_EXTENSIONS = [
'.jpg', '.JPG', '.jpeg', '.JPEG',
'.png', '.PNG', '.ppm', '.PPM', '.bmp', '.BMP',
]
import paddle
import cv2
import os
def data_maker(dir):
images = []
assert os.path.isdir(dir), '%s is not a valid directory' % dir
for root, _, fnames in sorted(os.walk(dir)):
for fname in fnames:
if is_image_file(fname) and ("outfit" not in fname):
path = os.path.join(root, fname)
images.append(path)
return sorted(images)
def is_image_file(filename):
return any(filename.endswith(extension) for extension in IMG_EXTENSIONS)
class AnimeDataset(paddle.io.Dataset):
"""
"""
def __init__(self):
super(AnimeDataset,self).__init__()
self.anime_image_dirs =data_maker("data/d/data/train")
self.size = len(self.anime_image_dirs)
# cv2.imread直接读取为GBR,把通道换成RGB
@staticmethod
def loader(path):
return cv2.cvtColor(cv2.imread(path, flags=cv2.IMREAD_COLOR),
cv2.COLOR_BGR2RGB)
def __getitem__(self, index):
img = AnimeDataset.loader(self.anime_image_dirs[index])
img_a = img[:,:512,:]
img_a =transform(img_a)
img_b = img[:,512:,:]
img_b = transform(img_b)[:,:,0:1]/255
img_b =paddle.to_tensor(img_b).squeeze(2).astype("int32")
# print(img_b)
img_b = paddle.nn.functional.one_hot(img_b,2, name=None).numpy()
return img_a,img_b
def __len__(self):
return self.size
#构造dataloader
dataset = AnimeDataset()
for img_a,img_b in dataset:
print(img_a.shape,img_b.shape)
break
W0215 14:02:38.417768 7086 device_context.cc:447] Please NOTE: device: 0, GPU Compute Capability: 7.0, Driver API Version: 10.1, Runtime API Version: 10.1
W0215 14:02:38.422991 7086 device_context.cc:465] device: 0, cuDNN Version: 7.6.
(256, 256, 3) (256, 256, 2)
batch_size = 4
datas = AnimeDataset()
data_loader = paddle.io.DataLoader(datas,batch_size=batch_size,shuffle =True)
for input_img,masks in data_loader:
print(input_img.shape,masks.shape)
break
[4, 256, 256, 3] [4, 256, 256, 2]
# !python -u SPADEResBlock.py
# !python -u SPADE.py
# !python -u Generator.py
# !python -u MODEL.py
import paddle.nn as nn
class KLDLoss(nn.Layer):
def forward(self, mu, logvar):
return -0.5 * paddle.sum(1 + logvar - mu.pow(2) - logvar.exp())
KLD_Loss = KLDLoss()
l1loss = nn.L1Loss()
from VGG_Model import VGG19
VGG = VGG19()
import paddle
import cv2
from tqdm import tqdm
import numpy as np
import os
from visualdl import LogWriter
from MODEL import Model
import math
log_writer = LogWriter("./log/gnet")
mse_loss = paddle.nn.MSELoss()
l1loss = paddle.nn.L1Loss()
# !python -u Discriminator.py
'''
该代码块代表多尺度判别器示例
'''
from Discriminator import build_m_discriminator
import numpy as np
discriminator = build_m_discriminator()
input_nc = 3
x = np.random.uniform(-1, 1, [4, 3, 256, 256]).astype('float32')
x = paddle.to_tensor(x)
print("input tensor x.shape",x.shape)\
y = discriminator(x)
for i in range(len(y)):
for j in range(len(y[i])):
print(i, j, y[i][j].shape)
print('--------------------------------------')
input tensor x.shape [4, 3, 256, 256]
0 0 [4, 64, 128, 128]
0 1 [4, 128, 64, 64]
0 2 [4, 256, 32, 32]
0 3 [4, 512, 32, 32]
0 4 [4, 1, 32, 32]
--------------------------------------
1 0 [4, 64, 64, 64]
1 1 [4, 128, 32, 32]
1 2 [4, 256, 16, 16]
1 3 [4, 512, 16, 16]
1 4 [4, 1, 16, 16]
--------------------------------------
model = Model()
# model和discriminator参数文件导入
M_path ='model_params/Mmodel_state3.pdparams'
layer_state_dictm = paddle.load(M_path)
model.set_state_dict(layer_state_dictm)
D_path ='discriminator_params/Dmodel_state3.pdparams'
layer_state_dictD = paddle.load(D_path)
discriminator.set_state_dict(layer_state_dictD)
scheduler_G = paddle.optimizer.lr.StepDecay(learning_rate=1e-4, step_size=3, gamma=0.8, verbose=True)
scheduler_D = paddle.optimizer.lr.StepDecay(learning_rate=4e-4, step_size=3, gamma=0.8, verbose=True)
optimizer_G = paddle.optimizer.Adam(learning_rate=scheduler_G,parameters=model.parameters(),beta1=0.,beta2 =0.9)
optimizer_D = paddle.optimizer.Adam(learning_rate=scheduler_D,parameters=discriminator.parameters(),beta1=0.,beta2 =0.9)
Epoch 0: StepDecay set learning rate to 0.0001.
Epoch 0: StepDecay set learning rate to 0.0004.
EPOCHEES = 30
i = 0
#四个设计保存参数文件的文件夹
save_dir_generator = "generator_params"
save_dir_encoder = "encoder_params"
save_dir_model = "model_params"
save_dir_Discriminator = "discriminator_params"
class Train_OPT():
'''
opt格式
'''
def __init__(self):
super(Train_OPT, self).__init__()
self.no_vgg_loss = False
self.batchSize = 4
self.lambda_feat = 10.0
self.lambda_vgg = 2
opt = Train_OPT()
#单纯当个指标,实际style_loss不参与反向传播
def gram(x):
b, c, h, w = x.shape
x_tmp = x.reshape((b, c, (h * w)))
gram = paddle.matmul(x_tmp, x_tmp, transpose_y=True)
return gram / (c * h * w)
def style_loss(style, fake):
gram_loss = nn.L1Loss()(gram(style), gram(fake))
return gram_loss
# return gram_loss
from GANloss import GANLoss
def rgb2yuv(rgb):
kernel = paddle.to_tensor([[0.299, -0.14714119, 0.61497538],
[0.587, -0.28886916, -0.51496512],
[0.114, 0.43601035, -0.10001026]],
dtype='float32')
rgb = paddle.transpose(rgb, (0, 2, 3, 1))
yuv = paddle.matmul(rgb, kernel)
return yuv
def denormalize(image):
return image * 0.5 + 0.5
def color_loss( con, fake):
con = rgb2yuv(denormalize(con))
# print("con",con.shape)
fake = rgb2yuv(denormalize(fake))
# print("fake",fake.shape)
return (nn.L1Loss()(con[:, :, :, 0], fake[:, :, :, 0]) +
nn.SmoothL1Loss()(con[:, :, :, 1], fake[:, :, :, 1]) +
nn.SmoothL1Loss()(con[:, :, :, 2], fake[:, :, :, 2]))
# 训练代码
step =0
for epoch in range(EPOCHEES):
# if(step >1000):
# break
for input_img,mask in tqdm(data_loader):
try:
# if(step >1000):
# break
# print(input_img.shape,mask.shape)
input_img =paddle.transpose(x=input_img.astype("float32")/127.5-1,perm=[0,3,1,2])
mask = paddle.transpose(x=mask,perm=[0,3,1,2]).astype("float32")
seg_mask = paddle.sum(mask,axis =1,keepdim =True).astype("float32")
seg_mask = paddle.concat([seg_mask,seg_mask,seg_mask],axis =1)
b,c,h,w = input_img.shape
model_input = input_img
img_fake,_,_ = model(model_input,mask)
img_fake = img_fake.detach()
# kld_loss = KLD_Loss(mu,logvar)
# print(img_fake.shape)
fake_and_real_data = paddle.concat((img_fake, input_img,seg_mask), 0).detach()
pred = discriminator(fake_and_real_data)
df_ganloss = 0.
for i in range(len(pred)):
pred_i = pred[i][-1][:opt.batchSize]
# new_loss = -paddle.minimum(-pred_i - 1, paddle.zeros_like(pred_i)).mean() # hingle loss pred_i<-1
new_loss = (300 * 1.2 *GANLoss()(pred_i, False))/4
df_ganloss += new_loss
df_ganloss /= len(pred)
df_ganloss*=0.35
dr_ganloss = 0.
for i in range(len(pred)):
pred_i = pred[i][-1][opt.batchSize:opt.batchSize*2]
# new_loss = -paddle.minimum(pred_i - 1, paddle.zeros_like(pred_i)).mean() # hingle loss pred_i>1
new_loss = (300 * 1.2 *GANLoss()(pred_i, True))/4
dr_ganloss += new_loss
dr_ganloss /= len(pred)
dr_ganloss*=0.35
dseg_ganloss = 0.
for i in range(len(pred)):
pred_i = pred[i][-1][opt.batchSize*2:]
# new_loss = -paddle.minimum(pred_i - 1, paddle.zeros_like(pred_i)).mean() # hingle loss pred_i>1
new_loss = (300 * 1.2 *GANLoss()(pred_i, False))/4
dseg_ganloss += new_loss
dseg_ganloss /= len(pred)
dseg_ganloss*=0.35
d_loss = df_ganloss + dr_ganloss + dseg_ganloss
d_loss.backward()
optimizer_D.step()
optimizer_D.clear_grad()
discriminator.eval()
# encoder.eval()
# set_requires_grad(discriminator,False)
# mu, logvar = encoder(input_img)
# kld_loss = KLD_Loss(mu,logvar)
# z = reparameterize(mu, logvar)
# img_fake = generator(mask,z)
# print(img_fake.shape)
img_fake,mu,logvar = model(model_input,mask)
kldloss = KLD_Loss(mu,logvar)/600
# loss_mask = paddle.sum(mask,axis = 1,keepdim = True).astype("bool").astype("float32").detach()
g_vggloss = paddle.to_tensor(0.)
g_styleloss= paddle.to_tensor(0.)
if not opt.no_vgg_loss:
rates = [1.0 / 32, 1.0 / 16, 1.0 / 8, 1.0 / 4, 1.0]
# _, fake_features = VGG( paddle.multiply (img_fake,loss_mask))
# _, real_features = VGG(paddle.multiply (input_img,loss_mask))
_, fake_features = VGG(img_fake)
_, real_features = VGG(input_img)
for i in range(len(fake_features)):
a,b = fake_features[i], real_features[i]
# if i ==len(fake_features)-1:
# a = paddle.multiply( a,F.interpolate(loss_mask,a.shape[-2:]))
# b = paddle.multiply( b,F.interpolate(loss_mask,b.shape[-2:]))
g_vggloss += rates[i] * l1loss(a,b)
# print(a.shape,b.shape)
# g_vggloss += paddle.mean(rates[i] *paddle.square(a-b))
if i ==len(fake_features)-1:
style_a,style_b = fake_features[i], real_features[i]
# style_a = paddle.multiply( style_a,F.interpolate(loss_mask,style_a.shape[-2:]))
# style_b = paddle.multiply( style_b,F.interpolate(loss_mask,style_b.shape[-2:]))
g_styleloss += rates[i] * style_loss(style_b,style_a)
g_vggloss *= opt.lambda_vgg
g_vggloss /=30
g_styleloss/=10
# loss_mask8 = paddle.concat([loss_mask,loss_mask],axis=0)
fake_and_real_data = paddle.concat((img_fake, input_img), 0)
# fake_and_real_data = paddle.multiply (fake_and_real_data,loss_mask8)
pred = discriminator(fake_and_real_data)
# 关闭真图片 tensor 的梯度计算
for i in range(len(pred)):
for j in range(len(pred[i])):
pred[i][j][opt.batchSize:].stop_gradient = True
g_ganloss = paddle.to_tensor(0.)
for i in range(len(pred)):
pred_i_f = pred[i][-1][:opt.batchSize]
# loss_mask0 = F.interpolate(loss_mask,pred_i_f.shape[-2:])
# pred_i_f = paddle.multiply(pred_i_f,loss_mask0)
pred_i_r = pred[i][-1][opt.batchSize:].detach()
# pred_i_r = paddle.multiply(pred_i_r,loss_mask0)
_,c,h,w = pred_i_f.shape
# new_loss = -1*pred_i_f.mean() # hinge loss
new_loss = paddle.sum(paddle.square(pred_i_r -pred_i_f))/math.sqrt(c*h*w)
g_ganloss += new_loss
g_ganloss /= len(pred)
g_ganloss*=2
g_featloss = paddle.to_tensor(0.)
for i in range(len(pred)):
for j in range(len(pred[i]) - 1): # 除去最后一层的中间层featuremap
pred_i_f = pred[i][j][:opt.batchSize]
# loss_mask0 = F.interpolate(loss_mask,pred_i_f.shape[-2:])
# pred_i_f = paddle.multiply(pred_i_f,loss_mask0)
pred_i_r = pred[i][j][opt.batchSize:].detach()
# pred_i_r = paddle.multiply(pred_i_r,loss_mask0)
unweighted_loss = (pred_i_r -pred_i_f).abs().mean() # L1 loss
g_featloss += unweighted_loss * opt.lambda_feat / len(pred)
# g_featloss*=3
col_loss = color_loss(input_img,img_fake)*200
g_loss = g_ganloss + g_vggloss +g_featloss +kldloss+col_loss+g_styleloss
# g_loss = g_vggloss +kldloss+col_loss+g_styleloss
g_loss.backward()
optimizer_G.step()
optimizer_G.clear_grad()
# optimizer_E.step()
# optimizer_E.clear_grad()
discriminator.train()
if step%2==0:
log_writer.add_scalar(tag='train/d_real_loss', step=step, value=dr_ganloss.numpy()[0])
log_writer.add_scalar(tag='train/d_fake_loss', step=step, value=df_ganloss.numpy()[0])
dseg_ganloss
log_writer.add_scalar(tag='train/dseg_ganloss', step=step, value=dseg_ganloss.numpy()[0])
log_writer.add_scalar(tag='train/d_all_loss', step=step, value=d_loss.numpy()[0])
log_writer.add_scalar(tag='train/col_loss', step=step, value=col_loss.numpy()[0])
log_writer.add_scalar(tag='train/g_ganloss', step=step, value=g_ganloss.numpy()[0])
log_writer.add_scalar(tag='train/g_featloss', step=step, value=g_featloss.numpy()[0])
log_writer.add_scalar(tag='train/g_vggloss', step=step, value=g_vggloss.numpy()[0])
log_writer.add_scalar(tag='train/g_loss', step=step, value=g_loss.numpy()[0])
log_writer.add_scalar(tag='train/g_styleloss', step=step, value=g_styleloss.numpy()[0])
log_writer.add_scalar(tag='train/kldloss', step=step, value=kldloss.numpy()[0])
step+=1
# print(i)
if step%100 == 3:
print(step,"g_ganloss",g_ganloss.numpy()[0],"g_featloss",g_featloss.numpy()[0],"col_loss",col_loss.numpy()[0],"g_vggloss",g_vggloss.numpy()[0],"g_styleloss",g_styleloss.numpy()[0],"kldloss",kldloss.numpy()[0],"g_loss",g_loss.numpy()[0])
print(step,"dreal_loss",dr_ganloss.numpy()[0],"dfake_loss",df_ganloss.numpy()[0],"dseg_ganloss",dseg_ganloss.numpy()[0],"d_all_loss",d_loss.numpy()[0])
# img_fake = paddle.multiply (img_fake,loss_mask)
seg_mask =seg_mask*255
input_img = (input_img+1)*127.5
img_fake = (img_fake+1)*127.5
g_output = paddle.concat([img_fake,input_img,seg_mask],axis = 3).detach().numpy() # tensor -> numpy
g_output = g_output.transpose(0, 2, 3, 1)[0] # NCHW -> NHWC
# g_output = (g_output+1) *127.5 # 反归一化
g_output = g_output.astype(np.uint8)
cv2.imwrite(os.path.join("./kl_result", 'epoch'+str(step).zfill(3)+'.png'),cv2.cvtColor(g_output,cv2.COLOR_RGB2BGR))
# generator.train()
if step%100 == 3:
# save_param_path_g = os.path.join(save_dir_generator, 'Gmodel_state'+str(step)+'.pdparams')
# paddle.save(model.generator.state_dict(), save_param_path_g)
save_param_path_d = os.path.join(save_dir_Discriminator, 'Dmodel_state'+str(3)+'.pdparams')
paddle.save(discriminator.state_dict(), save_param_path_d)
# save_param_path_e = os.path.join(save_dir_encoder, 'Emodel_state'+str(1)+'.pdparams')
# paddle.save(model.encoder.state_dict(), save_param_path_e)
save_param_path_m = os.path.join(save_dir_model, 'Mmodel_state'+str(3)+'.pdparams')
paddle.save(model.state_dict(), save_param_path_m)
# break
except:
pass
# break
scheduler_G.step()
scheduler_D.step()
#测试代码 效果保存至test文件
from MODEL_test import Model
import paddle
import numpy as np
import cv2
import os
model = Model(1)
M_path ='model_params/Mmodel_state3.pdparams'
layer_state_dictm = paddle.load(M_path)
model.set_state_dict(layer_state_dictm)
# z = paddle.randn([1,64*8,8,8])
path1 ="data/d/data/train/2970114.png"
img = cv2.cvtColor(cv2.imread(path1, flags=cv2.IMREAD_COLOR),cv2.COLOR_BGR2RGB)
from paddle.vision.transforms import CenterCrop,Resize
transform = Resize((256,256))
img_a = img[:,:512,:]
img_a =transform(img_a)
img_b = img[:,512:,:]
img_b = transform(img_b)
b = img_b[:,:,0:1]/255
b =paddle.to_tensor(b).squeeze(2).astype("int32")
# print(img_b)
b = paddle.nn.functional.one_hot(b,2, name=None).unsqueeze(0).transpose([0,3,1,2])
# test/2967110.png
img_fake= model(b)
print('img_fake',img_fake.shape)
# print(img_fake.shape)
# g_output = paddle.concat([img_fake,g_input1,g_input2],axis = 3).detach() # tensor -> numpy
img_fake = img_fake.transpose([0, 2, 3, 1])[0].numpy() # NCHW -> NHWC
print(img_fake.shape)
img_fake = (img_fake+1) *127.5
g_output = np.concatenate((img_a,img_b,img_fake),axis =1)
g_output = g_output.astype(np.uint8)
cv2.imwrite(os.path.join("./test", "2970114.png"), cv2.cvtColor(g_output,cv2.COLOR_RGB2BGR))
img_fake [1, 3, 256, 256]
(256, 256, 3)
True

学大模型,用大模型上飞桨星河社区!每天8点V100G算力免费领!免费领取ERNIE 4.0 100w Token >>>
更多推荐



 0
0 0
0- 0



 已为社区贡献1437条内容
已为社区贡献1437条内容

所有评论(0)