
文本样本增广(4)— 基于复杂网络随机游走的过采样
介绍了一种文本超采样技术,适用于短文本小样本数据(大数据速度不太适合)。
A network-based feature extraction model for imbalanced text data
Keping Li, Dongyang Yan,Yanyan Liu, Qiaozhen Zhu
对于文本数据的过采样技术,如之前项目所提到的那样,大多数是基于数值样本的。其思想是将文本先转换为数值向量,再通过经典的欧几里得空间中样本点的过采样技术进行采样,以增加样本的数量。这种操作简单明了,且大部分情况下能够收到一定的效果。然而,文本的向量表示方法注定了这种采样技术在数学原理上是不太合理的。文本表示可以有两种方法,其一是用词袋模型(Bag of word)的方法,忽略文本中文字的相对顺序,以热点的方式构造一个向量;其二是目前自然语言处理比较常用的词向量表示的方法。传统的文本超采样的思想仅适用于词袋模型的表示方法,因为词向量的方法最小单位是词,对词的过采样是没有意义的。当然,也有人直接将所有词向量进行聚合得到文本的向量,这种思路的效果在实际应用中可能并不显著。在项目词袋模型与复杂网络的强力结合,带你了解AEBoW模型中其作为对比方案出现过(未列出,文中有显示,结果中AE对应的内容),效果甚至弱于词袋模型。对于词袋模型来说,其向量表示是不符合过采样技术中普遍默认的高斯分布假设的,而是一种稀疏分布,即由较多的0和很少的非0数值组成。这个问题带来的直接后果是针对词袋模型的文本表示的过采样结果会与原始的向量存在很大的差距,虽然在评测过程中效果也不错,但是与原始数据这么大的差距肯定会造成之后的应用中泛化效果非常差的问题,这个问题在大多数相关论文中都没有提及。其实非高斯分布的问题可以通过LSA等降维技术进行一步降维操作缓解,这种操作到底可以带来多少提升,目前也没有人尝试,有想法的同学可以尝试一下,弄不好能发个小论文呢哈哈哈。
针对以上问题,这篇论文尝试了一种比较新颖的方式:绕开向量表示这一步,直接在文本的层面进行过采样。当然,如果直接对文本中的词进行过采样,可能会造成一个问题,采样出来的文字并不能代表原来文本的主题,因为文本的信息是非常稀疏的,随机采样会丢失掉大多数的关键信息,而得到一些无用信息。这里的思路是将文本先构造成复杂网络,其思路与词袋模型与复杂网络的强力结合,带你了解AEBoW模型相似,然后在文本复杂网络上进行随机游走,将随机游走得到的游走路径整合成新的样本。文中也针对复杂网络储存文本信息的方式对游走路径进行了处理,以更容易从中提取到有价值的信息。
相关代码链接(注:目前移植到飞桨的精度还没有对齐,很疑惑,因为核心思想不在神经网络上,而是采样的方式,竟然也会出现精度下降的情况。调整好会更新。)
2022/6/28:修改了用词,将超采样修改为过采样,英文中对应为oversampling。
本人的研究方向是基于复杂网络的文本处理方法,也在致力于探究与深度学习相结合的方法。我会不定期更新自己的工作,如果有研究方向相同的,或者感兴趣的朋友,欢迎三连支持一下。来AI Studio互粉吧等你哦
更多项目链接点击没入门的研究生的项目合集
1. 文本复杂网络的构造
这里采用动态网络的构造方式,即每个单词被视为一个节点,如果在原文中有两个单词时相邻的,那么它们之间建立一条连边。如下为示例:
原始文本:This is just a toy example. Here we show how a complex network of a text is constructed.
网络表示: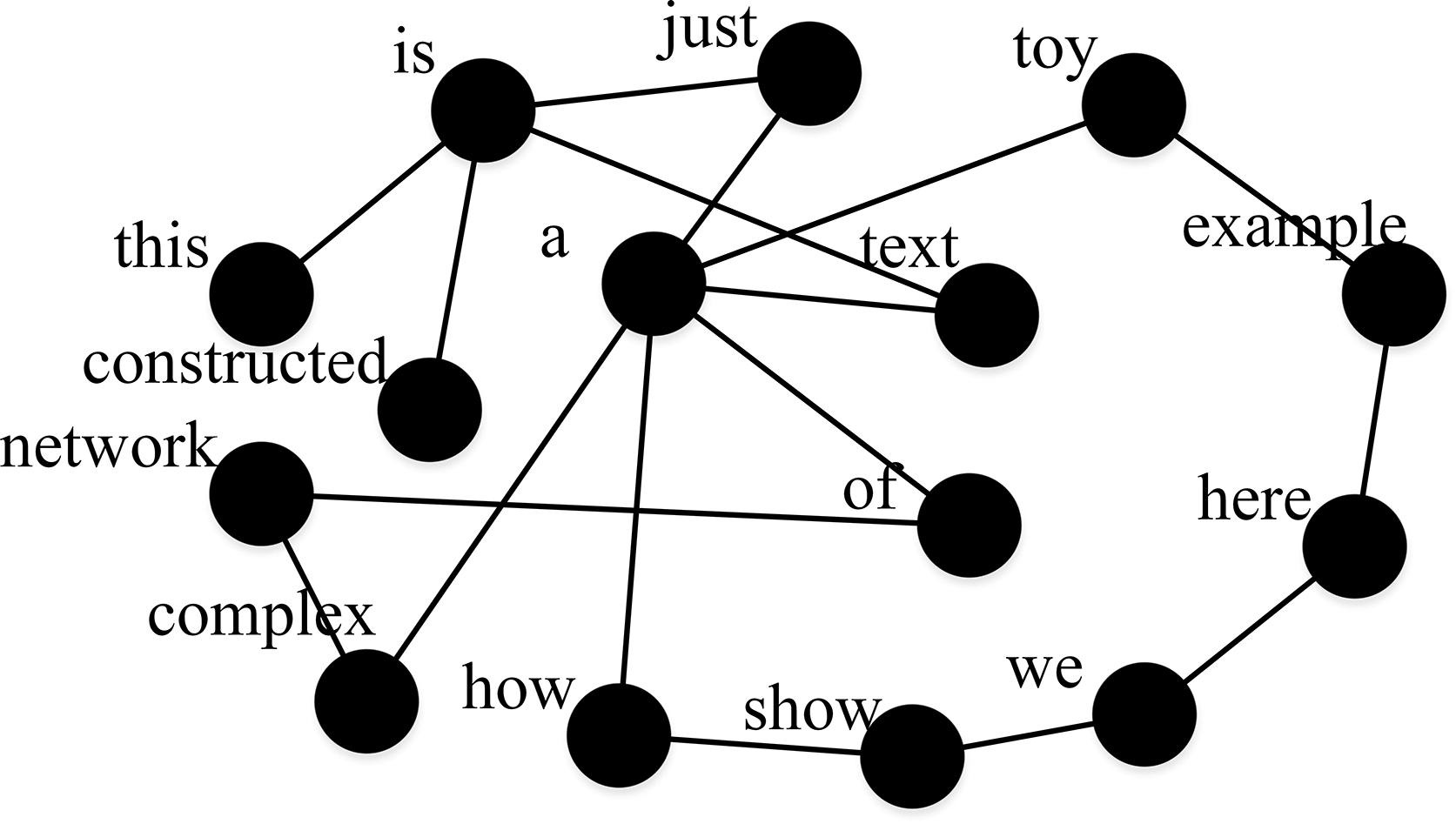
2. 复杂网络的文本信息特点
之所以用随机游走的方法,是因为文本在动态复杂网络中具有以下的特点:
- 相同的表述在网络中以最近邻的形式存在,如“source node,” “source text,” “source document”,以下图中A1B1,A1B2,A1B3的形式出现;
- 相同的语义在网络中以邻居的邻居形式存在,如 a dog and a cat all “like eating fishes,” “play with a toy ball,” and “sleep all day long,”,以下图中A1和A2加上不同颜色的多节点的形式出现。
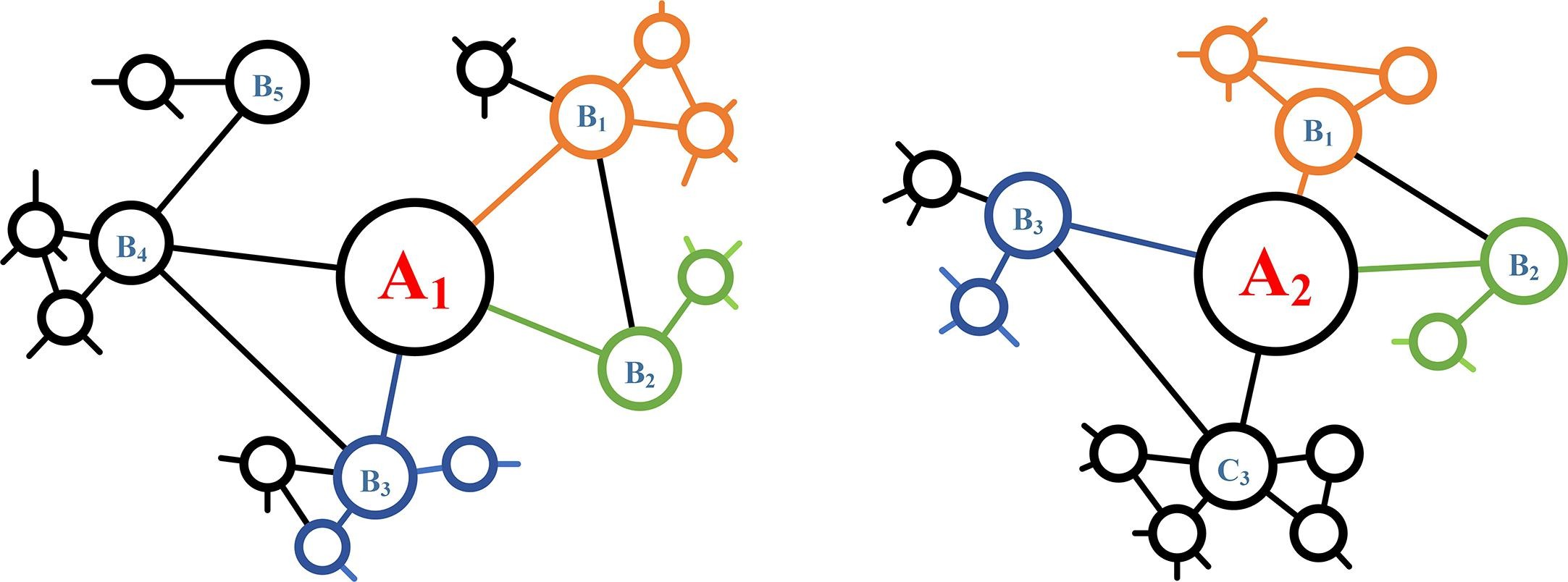
因此,文中对一个文本对应的网络(或多个文本合并的网络)进行多次短距离的随机游走,形成一个随机游走路径组成的矩阵,作为新的样本,其好处是可以通过CNN对以上分析的两种相似特征进行学习(卷积核能够很好地聚合两种相似的文本信息。)下图解释了原理:
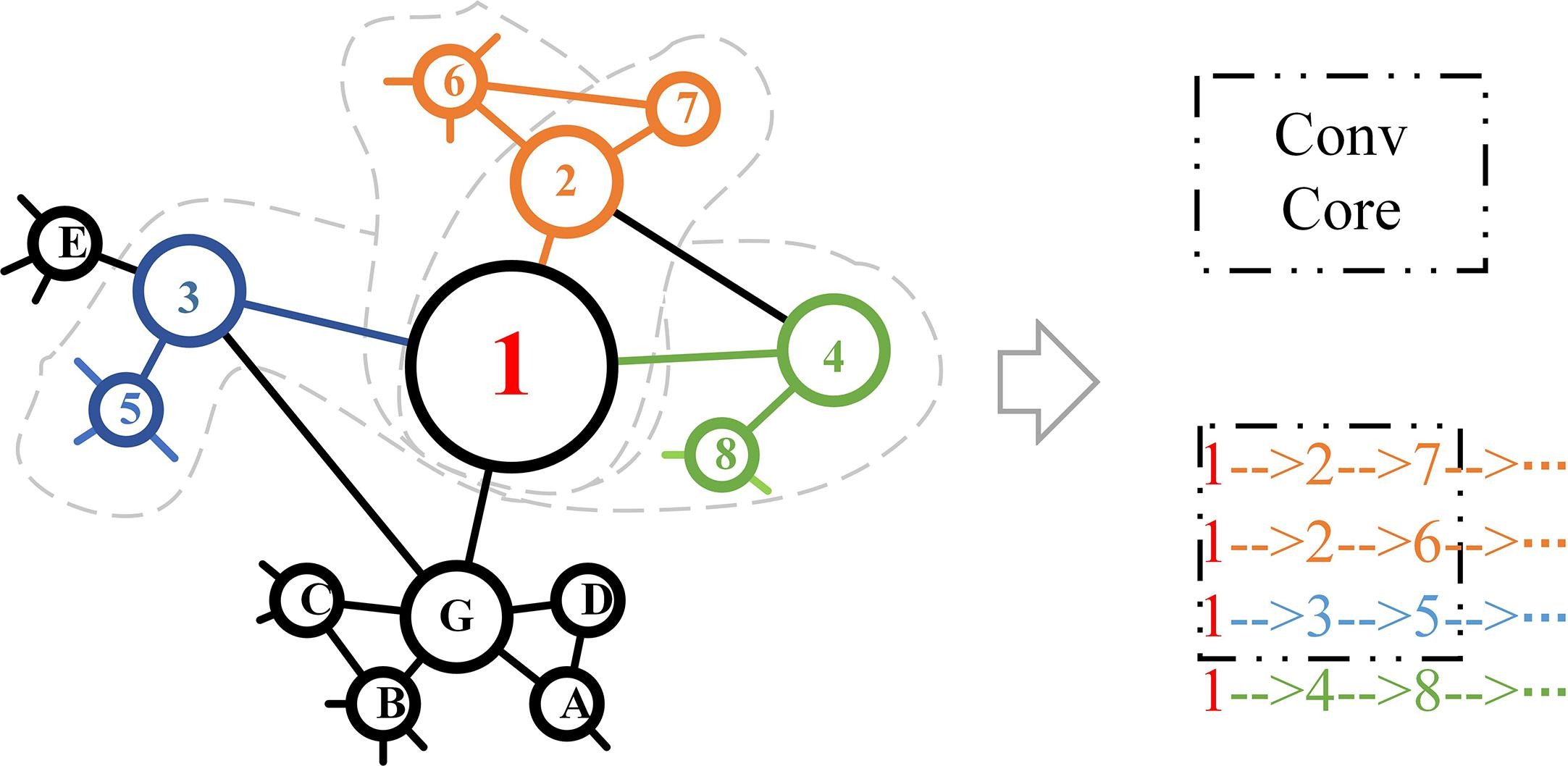
可以看到,一个卷积核可以覆盖到两种信息,有利于后续对文本信息的提取。
3. 随机游走的方式
为了灵活的调整对文本信息提取的方向,如侧重于2中所示的相似性1还是相似性2。文中引入了一个可调节游走方向的随机游走方式,该思想是图神经网络的一种经典的处理方法,在项目node2vec: 一种更加灵活的图嵌入模型中也有提到,其可以通过控制p和q的大小来调整游走的方向,具体思想可以参考此项目。
4. 随机游走的代码实现
如下为论文的核心代码,即随机游走的实现。相关参数已在代码备注中进行了解释。需要注意的是,文中的方法是walk='node2vec’的情况,设为其他参数也可以,效果有一定的差别。
# PathGen. Generate random walk pathes as the inputs of pcnn net model.
class PathGen:
"""
产生随机游走路径,作为数据预处理,输出的结果作为pcnn_net_model的输入。建立网络使用的是动态词共现网络。
/ To generate random paths of data preprocessing. The output is to be the input of pcnn_net_model. The newtork is word
co-occurrence complex network.
number: 每一个文本网络随机游走路径的生成数量 / The number of random walk paths for each sample.
length: 随机游走路径的长度 / length of random walk paths
walk: 随机游走方式:'normal', 'self_avoiding', 'weighted', 'weighted_reverse','smooth', 'smooth_reverse','node2vec',默认为self_avoiding
/ The choice method for every step during the random walk. 'normal', 'self_avoiding', 'weighted',
'weighted_reverse','smooth', 'smooth_reverse','node2vec',Default: self_avoiding
p,q: 当walk='node2vec'时需要填写的项,控制node2vec游走方式的超参数,如果p大,则游走趋向于不往回走,q大则使游走在起点周围进行。
Must be set when walk='node2vec'. The parameter to control the stepping trend for every step of random walk.
If p is larger, the trend is avoid to go back; if q is larger, the trend is to walk around the start node.
start_nodes: 随机游走的开始节点, 格式(batches,number)注意:如果start_nodes不为None,则无法使用data_expansion.
/ Start node of the random walk. Format: (batches, number). Note: If start_nodes is not None, the data_expansion
is ignored.
expansion_ratio: 数据倍增比例,=n即将数据倍增为n倍, <=1则不使用倍增 / The ratio to expansion data, just simply copy ratio times.
if =n > 1, to copy the data n times; if <= 1, do not copy.
sample_cross: 是否用两个同标签样本的拼接形成的网络模型进行倍增取样,注意:sample_cross只有在adaptive_expansion开启时才有效 / Whether
to use two samples in the same class to construct synthetic complex network and then to generate random walk paths.
Note: sample_cross only be actived if adaptive_expansion is activated.
adaptive_expansion: 是否开启自适应数据倍增,自适应数据倍增是将数据集中各类别数据的数量倍增到基本一致。默认为False,如果
为True,则数据会先按类整理,然后以数据量最多的类别为基准Cb,将其他数据的数量增至与该数据的数据量相同。其思路如下:
首先,如果Cb的数据量是Ci的n倍多m,则先将Ci的数据量倍增n倍,然后在Ci的源数据中取样m个。
注意:当adaptive_expansion为True时,expansion_ratio需要<=1. 如果expansion_ratio=n>1, 则会在adaptive_expansion操作结束后,
对数据再进行n倍的倍增
\ Whether to adopt the strategy to expand adaptive number of samples for each class to make the number of samples in
each class approximately equal. Default: False. If adaptive_expansion=True, the data will be arranged to groups, in
which samples are with the same class. The samples of each group is expanded to the number equal to the group with
the most samples.
Note: the effect of adaptive_expansion and expansion_ratio can be superimposed. So if adaptive_expansion is True, make
sure that expansion_ratio <= 1. Otherwise, after adaptive_expansion operation is completed, the data is copied n
times again.
cut_off_ratio: 截断倍率,当adaptive_expansion=True时有效,为了避免样本数量极少的类别出现过多重复数据,对小样本倍增的倍率
进行限制,n超过cut_off_ratio后,只倍增cut_off_ratio倍。默认为0,表示不做限制。当cut_off_ratio大于0的时候,该选项才会起作用
同时,规定cut_off_ratio为整数
\ (int) take effect if adaptive_expansion is True to make the samples' number of minority class to be expanded with
expanding times cutting off by a max value. Default: 0, do not do cut off operation.
cut_off_num: 截断数量,和cut_off_ratio作用相同,不同点在于,cut_off_num从数量上限制倍增,如果cut_off_num>0,则所有的倍增
样本的数量都只增加到cut_off_num
\ (int) take effect if adaptive_expansion is True to make the samples' number of minority class cut off by a max
value. Default: 0, do not do cut off operation.
注意:cut_off_num和cut_off_ratio是可以同时起作用的 / cut_off_num and cut_off_ratio can be activated simultaneously.
注意:如果训练数据有labels,labels倍增可以用self.multiple_objs操作,操作后的数据与倍增后的训练数据一一对应 / If the training data
contains labels, the labels can be expanded with self.multiple_objs, with the label mapping to the training samples
one-by-one.
fast_mode: 是否开启并行模式 / whether to take multiprocess (for cpu)
threads: 并行线程数,如果为0,表示开启cpu的最大线程数量。默认为0 / threads. If =0, take the max thread number of cpu
try_times: 有些self_avoiding的路径无法达到length的长度,需要尝试try_times次,如果try_times过后仍然未达到length的长度,则
将未达到长度的节点padding / for self_avoiding walk. Some random walk can not reach length, which has to be handled by
try many times. If length is still not reached after try_times trial, padding the last length.
except_padding: 当try_times次过后仍未达到length的长度,其余长度填充的方式,‘random’,随机选择节点填充,‘zeros’,填充0 /
If length is still not reached after try_times trial, padding the last length with this value.
undersampling: 是否对个数大于cut_off_num的类进行下采样,使其数量减少至cut_off_num, 仅当cut_off_num>0, adaptive_expansion==True
时有效 / whether to undersample for the class with the samples number larger than cut_off_num (to decease the value to
cut_off_num). Activated only if cut_off_num > 0 and adaptive_expansion==True.
"""
def __init__(self, number,
length,
walk='self_avoiding',
start_nodes=None,
expansion_ratio=1,
adaptive_expansion=False,
sample_cross=False,
cut_off_ratio=0,
cut_off_num=0,
threads=0,
try_times=10,
except_padding='zeros',
undersampling=False,
p=1,
q=1,
):
self.number = number
self.length = length
self.walk = walk
self.start_nodes = start_nodes
self.ratio = expansion_ratio
self.adaptive = adaptive_expansion
self.sample_cross = sample_cross
self.cut_ratio = cut_off_ratio
self.cut_num = cut_off_num
self.threads = threads
self.try_times = try_times
self.except_padding = except_padding
self.undersampling = undersampling
self.p = p
self.q = q
if threads == 1 or threads < 0:
self.fast_mode = False
else:
self.fast_mode = True
if self.start_nodes is not None:
for index, nodes in enumerate(self.start_nodes):
if isinstance(nodes, list):
len_ = len(nodes)
elif isinstance(nodes, np.ndarray):
len_ = nodes.shape[0]
else:
raise TypeError('Please use list or ndarray instead.')
if len_ != self.number:
raise ValueError('The number of start nodes in line {} is not equal to wanted number of paths.'
.format(index))
if self.except_padding not in ['random', 'zeros']:
raise ValueError('Only support {random, zeros} padding. Error padding: ', self.except_padding)
if self.ratio > 1:
if type(self.ratio) is not int:
raise ValueError('Type of expansion_ratio should be int but is ', type(self.ratio))
if self.start_nodes is not None:
print('\033[1;31m WARNING: When calling expansion operation, the start nodes is randomly given. '
'So the input value of start_nodes is neglected! \033[0m')
if isinstance(self.cut_ratio, float):
self.cut_ratio = int(self.cut_ratio)
print('\033[1;31m WARNING: The value of cut_off_ratio is float. It is transferred to int. \033[0m')
if isinstance(self.cut_num, float):
self.cut_num = int(self.cut_num)
print('\033[1;31m WARNING: The value of cut_off_ratio is float. It is transferred to int. \033[0m')
#print('padding: ',except_padding)
def __call__(self, inputs, labels=None, verbose=False, batch_size=256, **kwargs):
"""
:param inputs: (batches, length), list或np.array格式
:param kwargs:
:return: self.number random paths with self.length.
"""
if verbose:
print('Calling PathGen......')
t = time.time()
inputs = tf.constant(inputs)
if self.threads <= 0:
threads = cpu_count() - 1
else:
threads = self.threads
nets = [self._trans_net(line) for line in inputs]
if self.start_nodes is not None:
nets = np.array(nets)
else:
if self.adaptive is False:
nets = self.multiple_obj(nets)
nets = np.array(nets)
if labels is not None:
labels = self.multiple_obj(labels)
labels = np.array(labels)
else:
if labels is None:
raise ValueError("labels must be input if adaptive_expansion is True.")
else:
if np.ndim(labels) <= 1:
labels = self.one_hot_labeling(labels)
sum_classes = np.sum(labels, axis=0)
num_classes = sum_classes.shape[0]
max_class = np.argmax(sum_classes)
max_num = int(np.max(sum_classes))
sort_data = {i: {'data': [], 'labels': []} for i in range(num_classes)}
for index, label in enumerate(labels):
i = np.argmax(label)
sort_data[i]['data'].append(nets[index])
sort_data[i]['labels'].append(label)
if self.cut_ratio <= 0:
cut_ratio = 999999999999
else:
cut_ratio = self.cut_ratio
for i, num in enumerate(sum_classes):
num = int(num)
r = max_num % num
n = max_num // num
if self.cut_num > 0:
if self.cut_num < num:
r = 0
n = 1
else:
r = self.cut_num % num
n = self.cut_num // num
if not self.sample_cross:
if n <= cut_ratio:
indexes = [x for x in range(num)]
sample_indexes = random.sample(indexes, r)
r_data = [sort_data[i]['data'][x] for x in sample_indexes]
r_labels = [sort_data[i]['labels'][x] for x in sample_indexes]
sort_data[i]['data'] = self.multiple_obj(sort_data[i]['data'], n) + r_data
sort_data[i]['labels'] = self.multiple_obj(sort_data[i]['labels'], n) + r_labels
else:
sort_data[i]['data'] = self.multiple_obj(sort_data[i]['data'], cut_ratio)
sort_data[i]['labels'] = self.multiple_obj(sort_data[i]['labels'], cut_ratio)
else:
if n <= cut_ratio:
num_sample = (n - 1) * num + r
else:
num_sample = (cut_ratio - 1) * num
indexes = [x for x in range(num)]
merge_data = []
merge_labels = []
for count in range(num_sample):
if len(indexes) > 1:
sample_indexes = random.sample(indexes, 2)
else:
sample_indexes = [0, 0]
merge_data.append(self.net_merge([sort_data[i]['data'][x] for x in sample_indexes]))
merge_labels.append(sort_data[i]['labels'][0])
sort_data[i]['data'] = sort_data[i]['data'] + merge_data
sort_data[i]['labels'] = sort_data[i]['labels'] + merge_labels
if self.cut_num > 0 and self.adaptive and self.undersampling:
for i in sort_data.keys():
if len(sort_data[i]['data']) > self.cut_num:
us_data = random.sample(sort_data[i]['data'], self.cut_num)
sort_data[i]['data'] = us_data
sort_data[i]['labels'] = sort_data[i]['labels'][:self.cut_num]
new_nets = []
new_labels = []
for i in range(num_classes):
new_nets += sort_data[i]['data']
new_labels += sort_data[i]['labels']
# shuffles
new_nets = np.array(new_nets)
new_labels = np.array(new_labels)
new_nets = self.multiple_obj(new_nets)
new_nets = np.array(new_nets)
new_labels = self.multiple_obj(new_labels)
new_labels = np.array(new_labels)
index_new = [i for i in range(new_nets.shape[0])]
random.shuffle(index_new)
nets = np.array([new_nets[i] for i in index_new])
labels = np.array([new_labels[i] for i in index_new])
nets_size = nets.shape[0]
batch_num = int(np.ceil(nets_size / batch_size))
cumulate_len = 0
cumulate_time = 0
out = []
p = pool.Pool(threads)
for i in range(batch_num):
start = time.time()
net_batch = nets[i*batch_size:(i+1)*batch_size]
len_ = net_batch.shape[0]
if self.start_nodes is None:
starts_batch = [None for i in range(len_)]
else:
starts_batch = self.start_nodes[i*batch_size:(i+1)*batch_size]
if not self.fast_mode:
out = out + [self._pool_for_call(net, np.array(start_nodes))
for net, start_nodes in zip(net_batch, starts_batch)]
else:
out_ = p.map(self._wrap_for_pool, zip(net_batch, starts_batch))
out = out + out_
cumulate_len = cumulate_len + len_
if verbose:
if i < batch_num - 1:
cumulate_time = cumulate_time + time.time() - start
print('{}/{} - ETA: {:.0f}s.'.
format(str(cumulate_len).rjust(len(str(nets_size))), nets_size,
(nets_size - cumulate_len) * cumulate_time / cumulate_len,))
else:
cumulate_time = cumulate_time + time.time() - start
print('{}/{} - {:.0f}s.'.
format(str(cumulate_len).rjust(len(str(nets_size))), nets_size,
cumulate_time))
p.close()
p.join()
out = np.array(out)
if verbose:
print("PathGen finished. Time costs: {:.2f}s.".format(time.time() - t))
return out, labels
def one_hot_labeling(self, y):
all_label = dict()
for label in y:
if label not in all_label:
all_label[label] = len(all_label) + 1
one_hot = np.identity(len(all_label))
y = [one_hot[all_label[label] - 1] for label in y]
return y
def multiple_obj(self, objs, n=0):
"""
objs中的元素倍增后返回
:param n:
:param objs: np.array, list
:return:
"""
if n <= 0:
n = self.ratio
if not isinstance(objs, (list, np.ndarray)):
raise AttributeError('Only support {list, ndarray} type. objs" type is ', type(objs))
if not isinstance(objs, list):
objs = objs.tolist()
out = []
for i in range(n):
out = out + objs
return out
def net_merge(self, Gs):
"""
将几个网络G1和G2合并成一个网络,即整合两个网络中的所有点以及边
Gs: 存有若干网络模型的列表
"""
edges = []
for g in Gs:
edges += [e for e in g.edges]
edges = [e + (1, ) for e in edges]
G = nx.Graph()
G.add_weighted_edges_from(edges)
return G
def _pool_for_call(self, net, start_nodes):
"""
并行操作函数
:param line:
:param start: 起始点
:return:
"""
#net = self._trans_net(line)
start_nodes = np.array(start_nodes)
get_path = RandomWalk(walks=1, length=self.length, extra_walks=self.try_times)
if not start_nodes:
start_nodes = self._choose_start_nodes(net)
if self.walk == 'self_avoiding':
loop = False
weighted = False
reverse = False
smooth = False
elif self.walk == 'normal':
loop = True
weighted = False
reverse = False
smooth = False
elif self.walk == 'weighted':
loop = True
weighted = True
reverse = False
smooth = False
elif self.walk == 'weighted_reverse':
loop = True
weighted = True
reverse = True
smooth = False
elif self.walk == 'smooth':
loop = True
weighted = True
reverse = False
smooth = True
elif self.walk == 'smooth_reverse':
loop = True
weighted = True
reverse = True
smooth = True
elif self.walk == 'node2vec':
get_path = Node2VecWalk(walks=1, length=self.length, p=self.p, q=self.q)
else:
raise ValueError('Not support {} walk'.format(self.walk))
if self.walk == 'node2vec':
paths = [get_path.rand_paths(net, s) for s in start_nodes]
else:
paths = [get_path.rand_paths(net, s, loop=loop, weighted=weighted, smooth=smooth, reverse=reverse)[0] for s in start_nodes]
# 纠错
for index, path in enumerate(paths):
if len(path) < self.length:
while len(path) < self.length:
if self.except_padding == 'random':
path.append(random.sample(net.nodes, 1)[0])
else:
path.append(0)
paths[index] = path
return paths
def _wrap_for_pool(self, args):
return self._pool_for_call(*args)
def _trans_net(self, line):
line = np.array(line)
net = nx.Graph()
for index, node in enumerate(line):
if index > 0:
try:
#net.add_edge(line[index-1], node)
net.add_weighted_edges_from([(line[index-1], node, 1)])
except TypeError:
print('line', line)
return net
def _choose_start_nodes(self, net):
"""
得到line生成随机游走序列的左右开始节点
:param net:
:return:
"""
nodes = [x for x in net.nodes]
if 0 in nodes:
nodes.remove(0)
return [random.sample(nodes, 1)[0] for i in range(self.number)]
5. 将随机游走路径作为输入的后续处理
在文中,文本的嵌入层是不可训练的(在tensorflow上调为可训练会出现显存溢出的问题),嵌入向量直接用预训练向量代替。由于文本是以二维的随机游走路径路径为输入的,这里与传统的LSTM和CNN处理文本都不相同,因此文中又加了一个自定义的网络层来将数据进行转化,文中称之为PolarLayer,其原理如下图所示,就是消掉了嵌入向量的维度并保留第一层的信息,在第二层以后以传统的处理图片的CNN的方式进行下一步处理。其中x轴是随机游走路径长度,y轴是随机游走路径数量,z轴是嵌入向量的维度。
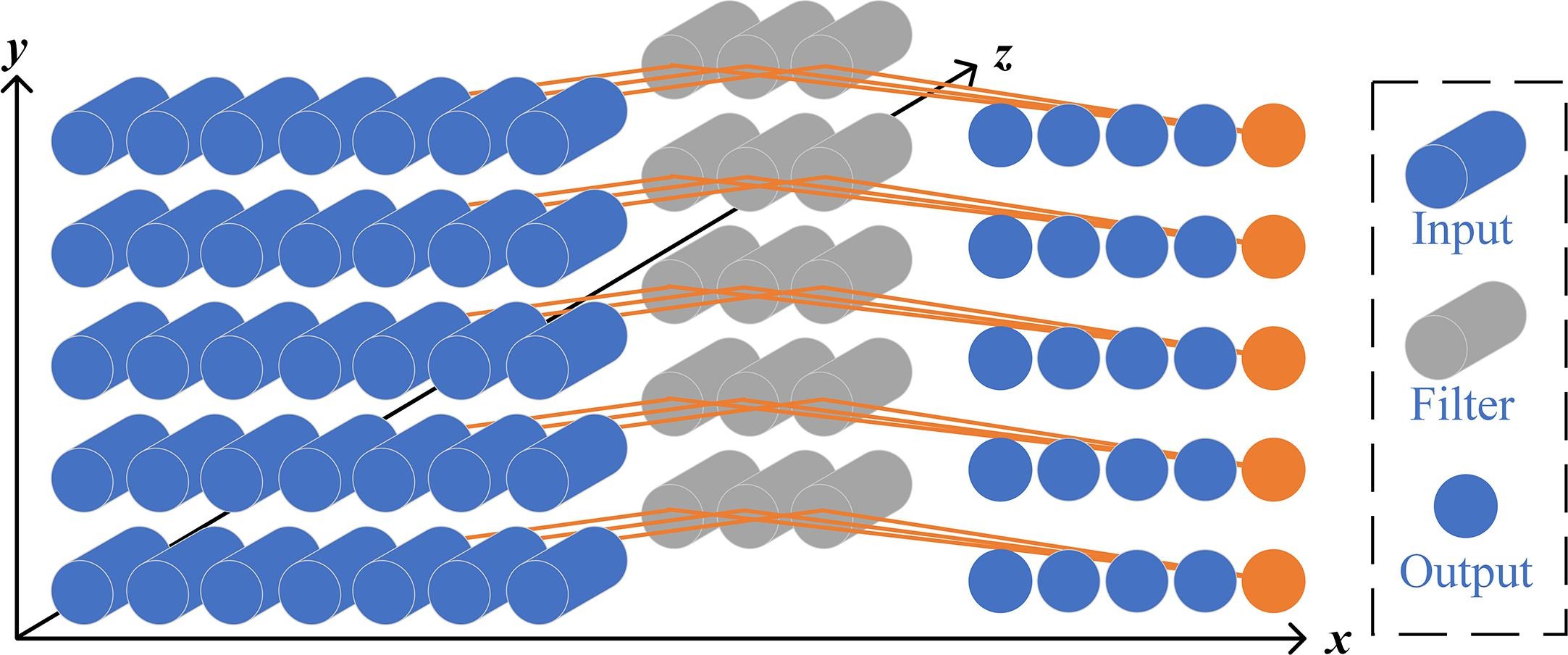
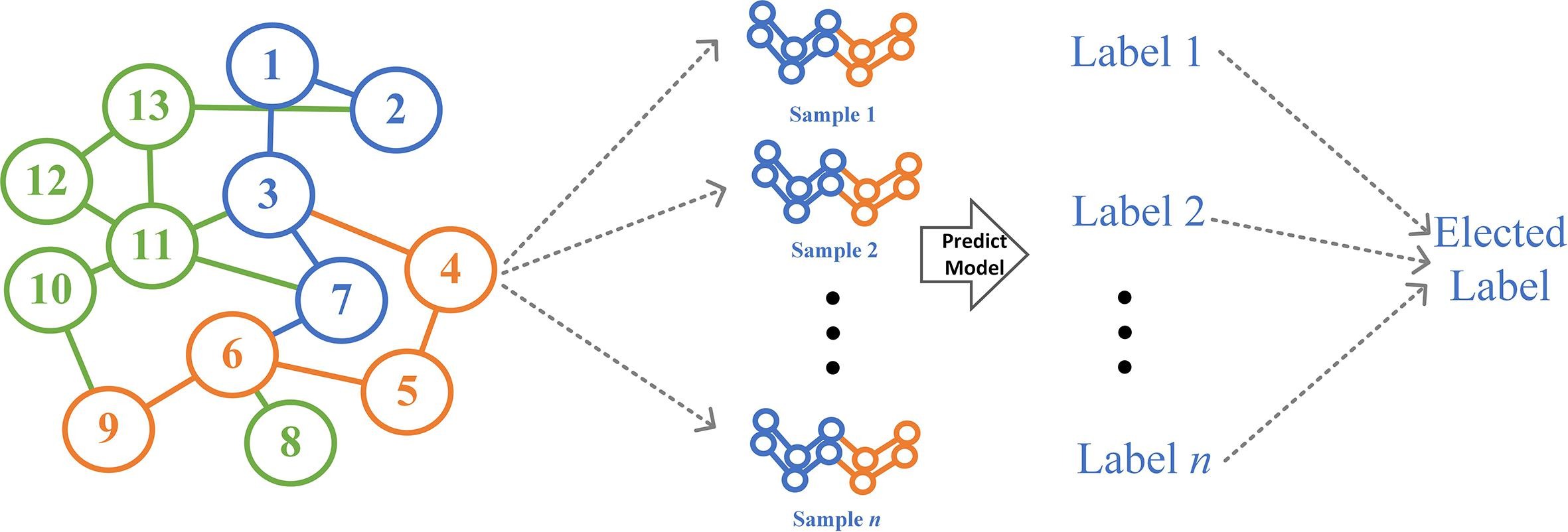
6. 由上述采样方式衍生出的结果选举策略
由于随机游走每次游走的方式均有差异,因此在训练的时候可以避免过拟合问题,在预测时也可以基于Bootstrap的方式,先生成多次随机游走路径,再进行多次预测,将多次预测的结果进行整合,选取最佳结果作为最终结果。文中称这种方式为选举策略。原理如下图所示。
7. 结果分析
文中对比了多种方法,在部分数据集上的表现实现了SOTA(当然也有部分数据集优势不是很大,结果没敢放上去)。其中,带有NCNN字样的是文中提到的方案。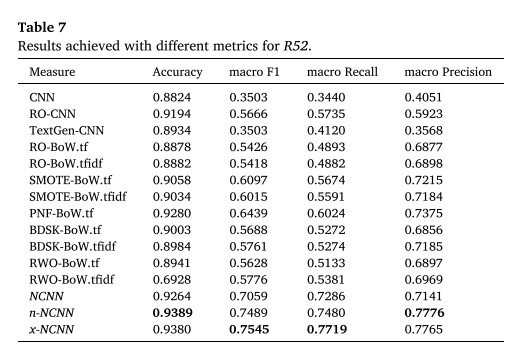
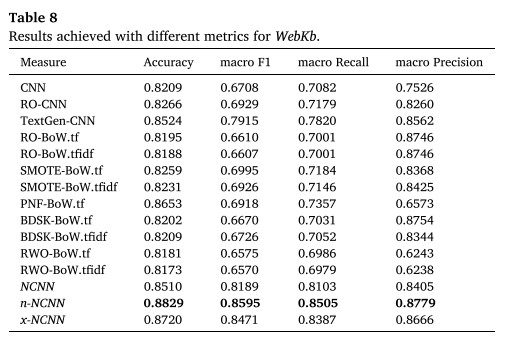
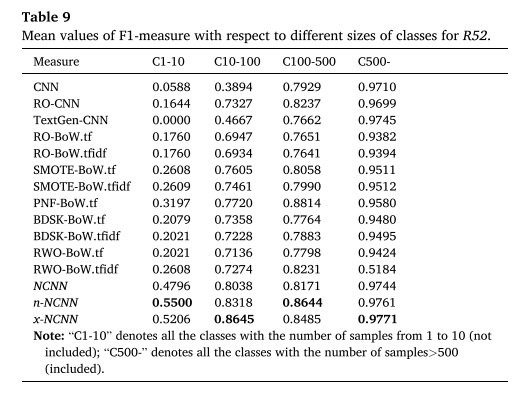
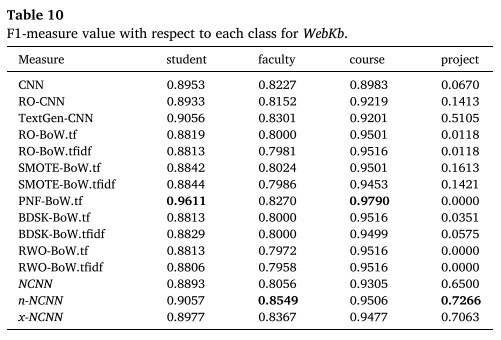
8. 总结
本文所提的方法其实并不算什么好方法,能被这个期刊接收,可能是因为对故有问题提出了挑战,并尝试了新的方法解决了部分问题。虽然随机游走可以解决一定的问题,但是同时也带来了新的问题,比如随机游走忽略了语序,面临着和词袋模型一样的问题,同时这种方法只适用于小样本,大型数据的处理效率不行,而且对内存的要求比较高。文本的不平衡问题素来是一个非常具有挑战性的问题,在纯NLP的研究中可能并不常见,但是在大部分应用中,如交通安全分析,医学诊断结果预测等等,都是普遍存在且必须考虑的一个问题。如果有研究NLP的大牛看到这个,一定要考虑一下相关问题的理论解决方法,这将造福像我这样应用领域的学子们。
开源链接
AiStudio源项目地址:https://aistudio.baidu.com/aistudio/projectdetail/4278657?contributionType=1

学大模型,用大模型上飞桨星河社区!每天8点V100G算力免费领!免费领取ERNIE 4.0 100w Token >>>
更多推荐



 1
1 0
0- 0



 已为社区贡献1437条内容
已为社区贡献1437条内容

所有评论(0)