
基于PaddleDetection实现人流量统计人体检测
本项目基于PaddleDetection FairMOT实现动态场景和静态场景下的人流量统计,提供从 “模型选择→模型优化→模型部署” 的全流程指导,模型可以直接或经过少量数据微调后用于相关任务
人流量统计
1. 项目概述
在地铁站、火车站、机场、展馆、景区等公共场所,需要实时检测人流数量,当人流密度过高时及时预警,并实施导流、限流等措施,防止安全隐患。
在人流密度较高的公共场所,使用PaddleDetection多目标跟踪方案,可以实现动态场景下和静态场景下的人流数量统计,帮助场所工作人员制定智能化管理方案,模型效果如 图1 所示。

本案例提供从“模型选择→模型优化→模型部署”的全流程指导,模型可以直接或经过少量数据微调后用于相关任务中,无需耗时耗力从头训练。
学习资源
-
更多实践案例(AI识虫,基于PaddleX实现森林火灾监测,眼疾识别,智能相册分类等)、深度学习资料,请参考:awesome-DeepLearning
-
更多目标检测模型,请参考:PaddleDetection
-
更多学习资料请参阅飞桨深度学习平台
⭐ ⭐ ⭐ 欢迎点个小小的Star,开源不易,希望大家多多支持~⭐ ⭐ ⭐
2. 技术难点
- 人流密度过高时,容易造成漏检: 在人流密度较高的场合,人与人之间存在遮挡,会导致模型误检、漏检问题。
- 在动态场景下,容易造成重识别问题: 模型需要对遮挡后重新出现的行人进行准确的重识别,否则对一段时间内的人流统计会有较大的影响。
3. 解决方案
人流量统计任务需要在检测到目标的类别和位置信息的同时,识别出帧与帧间的关联信息,确保视频中的同一个人不会被多次识别并计数。本案例选取PaddleDetection目标跟踪算法中的FairMOT模型来解决人流量统计问题。
FairMOT以Anchor Free的CenterNet检测器为基础,深浅层特征融合使得检测和ReID任务各自获得所需要的特征,实现了两个任务之间的公平性,并获得了更高水平的实时多目标跟踪精度。
针对拍摄角度不同(平角或俯角)以及人员疏密程度,在本案例设计了不同的训练方法:
- 针对人员相对稀疏的场景: 基于Caltech Pedestrian、CityPersons、CHUK-SYSU、PRW、ETHZ、MOT16和MOT17数据集进行训练,对场景中的行人进行全身检测和跟踪。 如 图2 所示,模型会对场景中检测到的行人进行标识,并在左上角显示出该帧场景下的行人数量,实现人流量统计。

- 针对人员相对密集的场景: 人与人之间的遮挡问题会非常严重,这时如果选择对行人整体检测,会导致漏检率升高。因此,本场景中使用人头跟踪方法。基于HT-21数据集进行训练,对场景中的行人进行人头检测和跟踪,对人流量的统计基于检测到的人头进行计数,如 图3 所示。

使用PaddleDetection完成人流量统计任务,只需完成如 图4 所示的步骤:

5. 数据准备
数据集介绍
Caltech Pedestrian
Caltech Pedestrain 数据集由加州理工提供、由固定在在城市环境中常规行驶的车辆上的摄像头采集得到。数据集包含约10小时的 640x480 30Hz 视频,其中标注了约250,000帧(约137分钟的片段)中的350,000个边界框和2300个行人。更多信息可参考:Caltech Pedestrain Detection Benchmark

图片来源:Caltech Pedestrian Detection Benchmark
CityPersons
CityPersons 数据集是基于CityScapes数据集在行人检测领域专门建立的数据集,它选取了CityScapes 中5000张精标图片,并对其中的行人进行边界框标注。其中训练集包含2975张图片,验证集包含500张,测试集包含1575张。图片中行人的平均数量为7人,标注提供全身标注和可视区域标注。更多信息可参考:CityPersons

图片来源:CityPersons: A Diverse Dataset for Pedestrian Detection
CUHK-SYSU
CUHK-SYSU 是一个大规模的人员搜索基准数据集,包含18184张图像和8432个行人,以及99,809个标注好的边界框。根据图像来源,数据集可分为在街道场景下采集和影视剧中采集两部分。在街道场景下,图像通过手持摄像机采集,包含数百个场景,并尝试尽可能的包含不同的视角、光线、分辨率、遮挡和背景等。另一部分数据集采集自影视剧,因为它们可以提供更加多样化的场景和更具挑战性的视角。
该数据集为行人检测和人员重识别提供注释。每个查询人会出现在至少两个图像中,并且每个图像可包含多个查询人和更多的其他人员。数据集被划分为训练集和测试集。训练集包含11206张图片和5532个查询人,测试集包含6978张图片和2900个查询人。更多信息可参考:End-to-End Deep Learning for Person Search

图片来源:End-to-End Deep Learning for Person Search
PRW
PRW (Person Re-identification in the Wild) 是一个人员重识别数据集。该数据集采集于清华大学,通过六个摄像机,采集共10小时的视频。数据集被分为训练、验证和测试集。训练集包含5134帧和482个ID,验证集共570帧和482个ID,测试集则包含6112帧和450个ID。每帧中出现的所有行人都会被标注边界框,同时分配一个ID。更多信息可参考:PRW
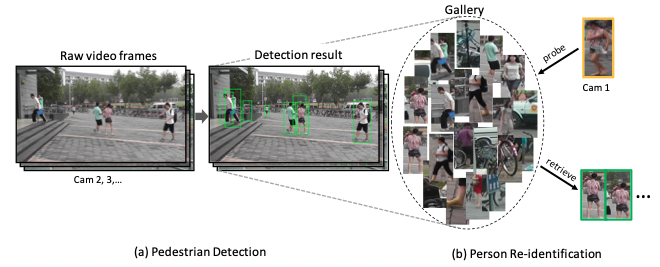
图片来源:Person Re-identification in the Wild
ETHZ
ETHZ 数据集由一对车载的AVT Marlins F033C摄像头拍摄采集,分辨率为 640x480,帧率为13-14 fps。数据集给出原始图像、标定信息和行人标注信息。更多信息可参考:ETHZ

图片来源:ETHZ数据集
MOT16
MOT16数据集是在2016年提出的用于衡量多目标跟踪检测和跟踪方法标准的数据集,专门用于行人跟踪。其主要标注目标为移动或静止的行人与行进中的车辆。MOT16基于MOT15添加了更细化的标注和更多的边界框,它拥有更加丰富的画面、不同拍摄视角及不同的天气情况。MOT16数据集共有14个视频,其中7个为带有标注的训练集,7个为测试集。它因为提供了标注好的检测结果,因此可以免去目标检测部分,更加关注在目标跟踪部分。更多信息可参考:MOT16

图片来源:MOT16: A Benchmark for Multi-Object Tracking
MOT17
MOT17与MOT16数据集相同,但标注更为准确。更多信息可参考:MOT17
训练数据集
训练数据集包含Caltech Pedestrian, CityPersons, CHUK-SYSU, PRW, ETHZ, MOT17和MOT16。训练时,我们采用前六个数据集,共 53694 张已标注好的数据集用于训练。MOT16作为评测数据集。所有的行人都有检测框标签,部分有ID标签。本项目在 data/data110591/datasets.zip 中提供了Caltech Pedestrian, CityPersons, CHUK-SYSU, PRW, ETHZ, MOT17的数据,在data/data110610/MOT16.zip 中提供了MOT16数据集。如果您想使用这些数据集,请遵循他们的License。
# 解压数据集,在第一次运行本项目时执行此步即可
!unzip -oq /home/aistudio/data/data110591/datasets.zip
!unzip -oq /home/aistudio/data/data110610/MOT16.zip
数据格式
上述数据集都遵循以下结构:
Caltech
|——————images
| └——————00001.jpg
| |—————— ...
| └——————0000N.jpg
└——————labels_with_ids
└——————00001.txt
|—————— ...
└——————0000N.txt
MOT17
|——————images
| └——————train
| └——————test
└——————labels_with_ids
└——————train
所有数据集的标注是以统一数据格式提供的。各个数据集中每张图片都有相应的标注文本。给定一个图像路径,可以通过将字符串images替换为 labels_with_ids并将 .jpg替换为.txt来生成标注文本路径。在标注文本中,每行都描述一个边界框,格式如下:
[class] [identity] [x_center] [y_center] [width] [height]
注意:
class为0,目前仅支持单类别多目标跟踪。identity是从1到num_identifies的整数(num_identifies是数据集中不同物体实例的总数),如果此框没有identity标注,则为-1。[x_center] [y_center] [width] [height]是中心点坐标和宽高,它们的值是基于图片的宽度/高度进行标准化的,因此值为从0到1的浮点数。
# 以下代码仅在第一次运行代码时执行即可
# 这里我们先对PaddleeDetection进行解压,因为AIStudio上进行git下载速度较慢,所以项目中提供了下载好的PaddleDetection
!unzip -oq /home/aistudio/PaddleDetection.zip
# 将全部数据移动到 PaddleDetection/dataset/mot 中
!mv datasets/* PaddleDetection/dataset/mot/
!mv MOT16/ PaddleDetection/dataset/mot/
数据集目录
将数据集移动到 PaddleDetection/dataset/mot中,其目录结构为:
dataset/mot
|——————image_lists
|——————caltech.10k.val
|——————caltech.all
|——————caltech.train
|——————caltech.val
|——————citypersons.train
|——————citypersons.val
|——————cuhksysu.train
|——————cuhksysu.val
|——————eth.train
|——————mot15.train
|——————mot16.train
|——————mot17.train
|——————mot20.train
|——————prw.train
|——————prw.val
|——————Caltech
|——————Cityscapes
|——————CUHKSYSU
|——————ETHZ
|——————MOT15
|——————MOT16
|——————MOT17
|——————PRW
调优数据集
在进行调优时,我们采用 Caltech Pedestrian, CityPersons, CHUK-SYSU, PRW, ETHZ和MOT17中一半的数据集,使用MOT17另一半数据集作为评测数据集。调优时和训练时使用的数据集不同,主要是因为MOT官网的测试集榜单提交流程比较复杂,这种数据集的使用方式也是学术界慢慢摸索出的做消融实验的方法。调优时使用的训练数据共 51035 张。
6. 模型选择
PaddleDetection对于多目标追踪算法主要提供了三种模型,DeepSORT、JDE和FairMOT。
- DeepSORT (Deep Cosine Metric Learning SORT) 扩展了原有的 SORT (Simple Online and Realtime Tracking) 算法,增加了一个CNN模型用于在检测器限定的人体部分图像中提取特征,在深度外观描述的基础上整合外观信息,将检出的目标分配和更新到已有的对应轨迹上即进行一个ReID重识别任务。DeepSORT所需的检测框可以由任意一个检测器来生成,然后读入保存的检测结果和视频图片即可进行跟踪预测。ReID模型此处选择 PaddleClas 提供的
PCB+Pyramid ResNet101模型。 - JDE (Joint Detection and Embedding) 是在一个单一的共享神经网络中同时学习目标检测任务和embedding任务,并同时输出检测结果和对应的外观embedding匹配的算法。JDE原论文是基于Anchor Base的YOLOv3检测器新增加一个ReID分支学习embedding,训练过程被构建为一个多任务联合学习问题,兼顾精度和速度。
- FairMOT 以Anchor Free的CenterNet检测器为基础,克服了Anchor-Based的检测框架中anchor和特征不对齐问题,深浅层特征融合使得检测和ReID任务各自获得所需要的特征,并且使用低维度ReID特征,提出了一种由两个同质分支组成的简单baseline来预测像素级目标得分和ReID特征,实现了两个任务之间的公平性,并获得了更高水平的实时多目标跟踪精度。
综合精度和速度,这里我们选择了FairMOT算法进行人流量统计/人体检测。
7. 模型训练
运行如下代码开始训练模型:(AIStudio仅支持开启一个GPU进行训练)
cd PaddleDetection/
/home/aistudio/PaddleDetection
# 训练前先对PaddleaddleDetection所需依赖进行安装
!pip install -r requirements.txt
!python -m paddle.distributed.launch --log_dir=./fairmot_dla34_30e_1088x608/ --gpus 0 tools/train.py -c configs/mot/fairmot/fairmot_dla34_30e_1088x608.yml
8. 模型评估
FairMOT使用单张GPU通过如下命令一键式启动评估:
!CUDA_VISIBLE_DEVICES=0 python tools/eval_mot.py -c configs/mot/fairmot/fairmot_dla34_30e_1088x608.yml -o weights=output/fairmot_dla34_30e_1088x608/model_final.pdparams
注意: 默认评估的是MOT-16 Train Set数据集,如需换评估数据集可参照以下代码修改configs/datasets/mot.yml,修改data_root:
EvalMOTDataset:
!MOTImageFolder
dataset_dir: dataset/mot
data_root: MOT16/images/train
keep_ori_im: False # set True if save visualization images or video
9. 模型优化(进阶)
本小节侧重展示在模型优化过程中,提升模型精度的思路。在这些思路中,有些会对精度有所提升,有些没有。在其他人流量统计/人体检测场景中,可以根据实际情况尝试如下策略,不同的场景下可能会有不同的效果。
(1) 基线模型选择
本案例采用FairMOT模型作为基线模型,其骨干网络选择是DLA34。基线模型共有三种:
1)训练基于NVIDIA Tesla V100 32G 2GPU,batch size = 6,使用Adam优化器,模型使用CrowdHuman数据集进行预训练;
2)训练基于NVIDIA Tesla V100 32G 4GPU,batch size = 8,使用Momentum优化器,模型使用CrowdHuman数据集进行预训练;
3)训练基于NVIDIA Tesla V100 32G 4GPU,batch size = 8,使用Momentum优化器,模型使用ImageNet数据集进行预训练。
模型优化时使用的数据集,参见 调优数据集。
| 模型 | MOTA | 推理速度 |
|---|---|---|
| baseline (dla34 2gpu bs6 adam lr=0.0001) | 70.9 | 15.600 |
| baseline (dla34 4gpu bs8 momentum) | 67.5 | 15.291 |
| baseline (dla34 4gpu bs8 momentum + imagenet_pretrain) | 64.3 | 15.314 |
(2) 数据增强
增加cutmix
下图中展示了三种数据增强的方式:
- Mixup: 将随机两幅图像以一定的全值叠加构成新的图像;
- Cutout:将图像中随机区域剪裁掉,用0像素值来填充;
- CutMix:将一张图像中的随机区域剪裁掉,并随机选取另一张图片,用其对应区域中的像素来填充剪裁掉的部分。

图片来源:CutMix: Regularization Strategy to Train Strong Classifiers with Localizable Features
相比于Mixup和Cutout,CutMix在图像分类和目标检测任务上都用哟欧更好的效果。因为CutMix要求模型从局部识别对象,可以进一步增强模型定位能力。
实现上,可以通过修改 configs/mot/fairmot/__base__/fairmot_reader_1088x608.yml,加入如下代码,CutMix数据增强:
TrainReader:
inputs_def:
image_shape: [3, 608, 1088]
sample_transforms:
- Decode: {}
- RGBReverse: {}
- AugmentHSV: {}
- LetterBoxResize: {target_size: [608, 1088]}
- MOTRandomAffine: {reject_outside: False}
- RandomFlip: {}
- Cutmix: {}
- BboxXYXY2XYWH: {}
- NormalizeBox: {}
- NormalizeImage: {mean: [0, 0, 0], std: [1, 1, 1]}
- RGBReverse: {}
- Permute: {}
实验结果:
| 模型 | MOTA | 推理速度 |
|---|---|---|
| dla34 4gpu bs8 momentum + cutmix | 67.7 | 15.528 |
在baseline中加入cutmix,模型MOTA提升0.2%。
(3) 可变形卷积
可变形卷积(Deformable Convolution Network, DCN)顾名思义就是卷积的位置是可变形的,并非在传统的 N × N N \times N N×N 网格上做卷积,这样的好处就是更准确地提取到我们想要的特征(传统的卷积仅仅只能提取到矩形框的特征),通过一张图我们可以更直观地了解:
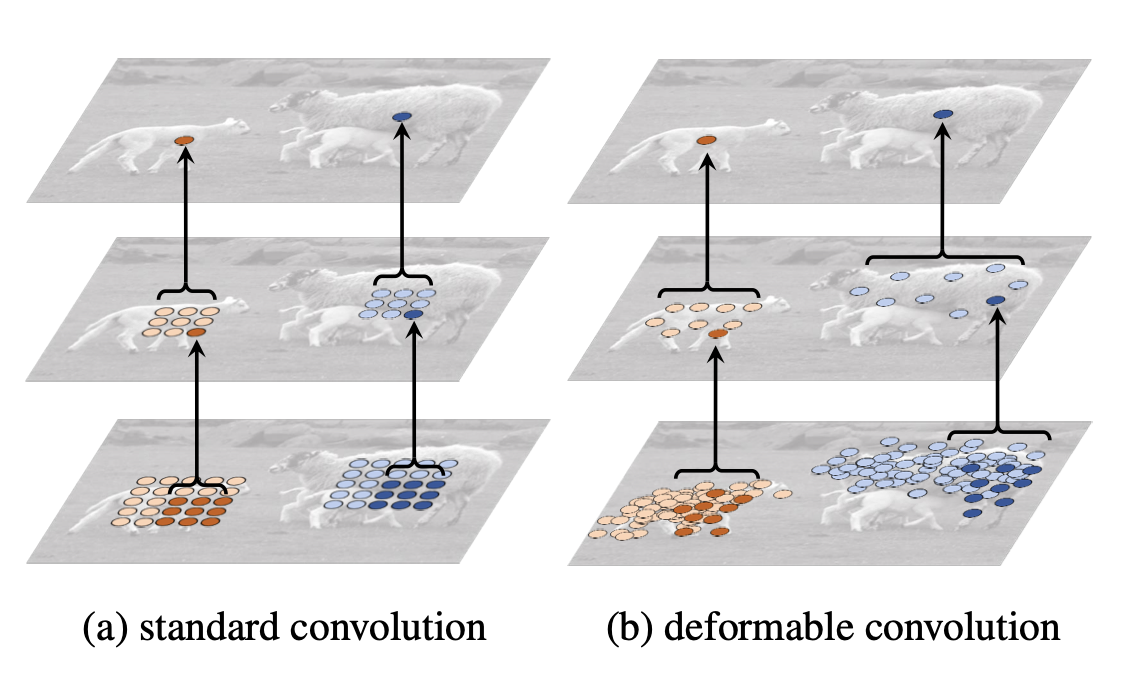
图片来源:Deformable Convolutional Networks
在上面这张图里面,左边传统的卷积显然没有提取到完整绵羊的特征,而右边的可变形卷积则提取到了完整的不规则绵羊的特征。本实验在 CenterNet head 中加入了DCN,具体实现方法为:使用 code/centernet_head_dcn.py 中的代码替换 ppdet/modeling/heads/centernet_head.py 中的代码。
实验结果:
| 模型 | MOTA | 推理速度 |
|---|---|---|
| dla34 4gpu bs8 momentum + dcn | 67.2 | 16.695 |
在baseline中加入dcn,模型MOTA降低0.3%。
(4) syncbn+ema
syncbn
默认情况下,在使用多个GPU卡训练模型的时候,Batch Normalization都是非同步的 (unsynchronized)。每次迭代时,输入被分为多等分,然后在不同的卡上进行前向后向运算,每个卡上的模型都是单独运算的,相应的Batch Normalization也是在卡内完成。因此BN所归一化的样本数量也只局限于卡内的样本数。开启跨卡同步Batch Normalization后,在前向运算时即可得到全局的均值和方差,后向运算时得到相应的全局梯度,卡与卡之间同步。
ema
在深度学习中,经常会使用EMA(指数移动平均)这个方法对模型的参数做平均,以求提高测试指标并增加模型鲁棒。指数移动平均(Exponential Moving Average)也叫权重移动平均(Weighted Moving Average),是一种给予近期数据更高权重的平均方法。在深度学习优化中,其基本假设为,模型权重在最后的n步内会在最优点附近震荡,所以我们取n步后的平均值,则能使模型更加鲁棒。
本实验中,使用synbn和ema,可以通过在 configs/mot/fairmot/_base_/fairmot_dla34.yml 中,进行如下修改:
architecture: FairMOT
pretrain_weights: https://paddledet.bj.bcebos.com/models/pretrained/fairmot_dla34_crowdhuman_pretrained.pdparams
norm_type: sync_bn
use_ema: true
ema_decay: 0.9998
实验结果:
| 模型 | MOTA | 推理速度 |
|---|---|---|
| dla34 4gpu bs8 momentum + syncbn + ema | 67.4 | 16.695 |
在baseline上开启syncbn和ema,模型MOTA降低0.1%。
(5) 优化策略
Adam使用动量和自适应学习率来加快收敛速度。对梯度的一阶矩阵估计和二阶矩阵估计进行综合考虑,以此计算更新步长。本实验中可以通过在 PaddleDetection/configs/mot/fairmot/_base_/optimizer_30e.yml 中,进行如下修改:
LearningRate:
base_lr: 0.0002
schedulers:
- !PiecewiseDecay
gamma: 0.1
milestones: [20,]
use_warmup: False
OptimizerBuilder:
optimizer:
type: Adam
regularizer: NULL
实验结果:
| 模型 | MOTA | 推理速度 |
|---|---|---|
| dla34 4gpu bs6 adam lr=0.0002 | 71.1 | 15.823 |
(6) 空间域注意力模块(Spatial Gate Module)
注意力机制的加入可以让网络更加关注重点信息并忽略无关信息。空间域注意力模块的结构如下图所示:
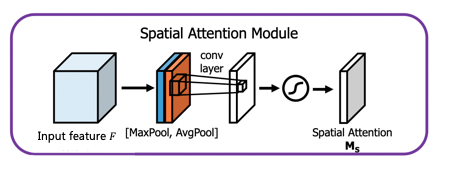
图片来源:CBAM: Convolutional Block Attention Module
模块的输入特征为F。首先会基于通道维度进行global max pooling和global average pooling,得到两个H×W×1 的特征图,然后将这两个特征图进行通道拼接。再经过一个7×7卷积操作,将通道数降维为1。然后经过sigmoid函数生成spatial attention feature,即 M s M_s Ms。该feature与输入特征相乘则得到最终的特征。
本实验中通过将 code/centernet_fpn_attention.py 中的代码替换 PaddleDetection/ppdet/modeling/necks/centernet_fpn.py 来实现Spatial Gate Module。设置 self.attention = SpatialGate()。
self.attention = SpatialGate()
# self.attention = SANN_Attention(c_state = False, s_state = True) # spatial_attention
实验结果:
| 模型 | MOTA | 推理速度 |
|---|---|---|
| dla34 4gpu bs8 momentum + attention | 67.6 | - |
| dla34 4gpu bs6 adam lr=0.0002 + syncbn + ema + attention | 71.6 | - |
| dla34 4gpu bs6 adam lr=0.0002 + syncbn + ema + attention + cutmix | 71.3 | - |
在baseline上新增了attention,模型MOTA增加0.1%。在baseline上回合使用优化策略、+syncbn+ema和spatial gate,模型MOTA增加4.1%。新增attention部分暂不支持开启TensorRT进行推理。
(7) backbone

在本实验中,我们尝试将baseline中的centernet的backbone由DLA-34更换为其他更大的模型,如DLA-46-C、DLA-60及DLA-102。因为更换的backbone都只有在ImageNet上的预训练模型,而我们实验中使用的dla34 backbone 是在CrowdHuman上做过预训练的。所以这一部分的实验结果要与 baseline (dla34 4gpu bs8 momentum + image_pretrain) 进行比较。替换backbone可以通过 code/dla_backbones中的代码来替换 PaddleDetection/ppdet/modeling/backbones/dla.py 中的代码,并通过调整 depth 来选择backbone的结构,可选择dla34、46c、60和102。
class DLA(nn.Layer):
"""
DLA, see https://arxiv.org/pdf/1707.06484.pdf
Args:
depth (int): DLA depth, should be 34.
residual_root (bool): whether use a reidual layer in the root block
"""
def __init__(self, depth=34, residual_root=False):
实验结果如下:
| 模型 | MOTA | 推理速度 |
|---|---|---|
| dla46c 4gpu bs8 momentum + imagenet_pretrain | 61.2 | 16.863 |
| dla60 4gpu bs8 momentum + imagenet_pretrain | 58.8 | 12.531 |
| dla102 4gpu bs8 momentum + imagenet_pretrain | 54.8 | 12.469 |
(8) GIoU Loss
GIoU解决了IoU Loss存在的两个问题:
- 预测框如果和真实框没有重叠,则IoU始终为0,损失函数失去可导性;
- IoU无法分辨不同方式的对齐,IoU值相同,但预测框的方向可能完全不同。
GIoU提出一种计算方式,对于两个框A和B,先计算出A、B的最小包围框C,然后根据如下公式计算出GIoU:
G I o U = I o U − C − ( A ∪ B ) C GIoU = IoU - \frac{C-(A \cup B)}{C} GIoU=IoU−CC−(A∪B)
GIoU Loss = 1 - GIoU. 如想尝试增加GIoU Loss,可用 code/centernet_head_iou_head.py 替换 ppdet/modeling/heads/centernet_head.py 中的代码,并且修改 ppdet/modeling/architectures/fairmot.py 文件,在第84行增加 'iou_loss': det_outs['iou_loss'], :
det_loss = det_outs['det_loss']
loss = self.loss(det_loss, reid_loss)
loss.update({
'heatmap_loss': det_outs['heatmap_loss'],
'size_loss': det_outs['size_loss'],
'iou_loss': det_outs['iou_loss'],
'offset_loss': det_outs['offset_loss'],
'reid_loss': reid_loss
})
return loss
实验结果如下:
| 模型 | MOTA | 推理速度 |
|---|---|---|
| dla34 4gpu bs6 adam lr=0.0002 + syncbn + ema + iou head | 71.6 | 15.723 |
全部实验结果:
全部模型优化的实验结果如下表所示,如下实验均在NVIDIA Tesla V100机器上实现,测速时开启TensorRT。从实验结果可以发现,精度最高的模型并不是推理速度最快的,推理速度最快的模型精度效果不是最好的,具体使用什么模型还需要根据需求进行分析。
| 模型 | MOTA | 推理速度(开启TensorRT) |
|---|---|---|
| baseline (dla34 2gpu bs6 adam lr=0.0001) | 70.9 | 15.600 |
| baseline (dla34 4gpu bs8 momentum) | 67.5 | 15.291 |
| baseline (dla34 4gpu bs8 momentum + imagenet_pretrain) | 64.3 | 15.314 |
| dla34 4gpu bs8 momentum + dcn | 67.2 | 16.695 |
| dla34 4gpu bs8 momentum + syncbn + ema | 67.4 | 15.528 |
| dla34 4gpu bs8 momentum + cutmix | 67.7 | 15.528 |
| dla34 4gpu bs8 momentum + attention | 67.6 | - |
| dla34 4gpu bs6 adam lr=0.0002 | 71.1 | 15.823 |
| dla34 4gpu bs6 adam lr=0.0002 + syncbn + ema | 71.7 | 15.038 |
| dla34 4gpu bs6 adam lr=0.0002 + syncbn + ema + attention | 71.6 | - |
| dla34 4gpu bs6 adam lr=0.0002 + syncbn + ema + iou head | 71.6 | 15.723 |
| dla34 4gpu bs6 adam lr=0.0002 + syncbn + ema + attention + cutmix | 71.3 | - |
| dla46c 4gpu bs8 momentum + imagenet_pretrain | 61.2 | 16.863 |
| dla60 4gpu bs8 momentum + imagenet_pretrain | 58.8 | 12.531 |
| dla102 4gpu bs8 momentum + imagenet_pretrain | 54.8 | 12.469 |
10. 模型预测
使用单个GPU通过如下命令预测一个视频,并保存为视频
# 使用自己训练的模型预测
!CUDA_VISIBLE_DEVICES=0 python tools/infer_mot.py -c configs/mot/fairmot/fairmot_dla34_30e_1088x608.yml -o weights=output/fairmot_dla34_30e_1088x608/model_final.pdparams --video_file=../example.mp4 --frame_rate=20 --save_videos
# 使用PaddleaddleDetection提供的训练好的模型预测
!CUDA_VISIBLE_DEVICES=0 python tools/infer_mot.py -c configs/mot/fairmot/fairmot_dla34_30e_1088x608.yml -o weights=https://paddledet.bj.bcebos.com/models/mot/fairmot_dla34_30e_1088x608.pdparams --video_file=../example.mp4 --frame_rate=20 --save_videos
使用单个GPU通过如下命令预测一个图片文件夹,并保存为视频
!CUDA_VISIBLE_DEVICES=0 python tools/infer_mot.py -c configs/mot/fairmot/fairmot_dla34_30e_1088x608.yml -o weights=output/fairmot_dla34_30e_1088x608/model_final.pdparams --image_dir=./dataset/mot/MOT17/images/test/MOT17-01-SDP/img1 --save_videos
注意: 请先确保已经安装了ffmpeg, Linux(Ubuntu)平台可以直接用以下命令安装:apt-get update && apt-get install -y ffmpeg。--frame_rate表示视频的帧率,表示每秒抽取多少帧,可以自行设置,默认为-1表示会使用OpenCV读取的视频帧率。
11. 模型导出
# 使用PaddleaddleDetection提供的训练好的模型导出
!CUDA_VISIBLE_DEVICES=0 python tools/export_model.py -c configs/mot/fairmot/fairmot_dla34_30e_1088x608.yml -o weights=https://paddledet.bj.bcebos.com/models/mot/fairmot_dla34_30e_1088x608.pdparams
# 使用自己训练的模型导出
!CUDA_VISIBLE_DEVICES=0 python tools/export_model.py -c configs/mot/fairmot/fairmot_dla34_30e_1088x608.yml -o weights=output/fairmot_dla34_30e_1088x608/model_final.pdparams
12. 模型部署
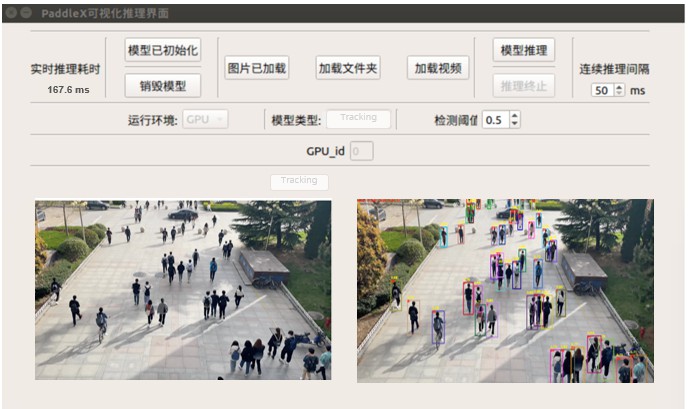
本案例为用户提供了基于Jetson NX的部署Demo方案,如下图所示。支持用户输入单张图片、文件夹文件夹或视频流进行预测。
更多深度学习资源
PaddleEdu一站式深度学习在线百科awesome-DeepLearning中还有其他的能力,大家可以敬请期待:
- 深度学习入门课

- 深度学习百问

- 特色课

- 产业实践

PaddleEdu使用过程中有任何问题欢迎在awesome-DeepLearning提issue,同时更多深度学习资料请参阅飞桨深度学习平台。
记得点个Star⭐收藏噢~~

飞桨PaddleEdu技术交流群(QQ)
目前QQ群已有2000+同学一起学习,欢迎扫码加入

数据来源
本案例数据来源于:
- Caltech Pedestrian Detection Benchmark: http://www.vision.caltech.edu/Image_Datasets/CaltechPedestrians/
- CityPersons: https://github.com/cvgroup-njust/CityPersons
- CUHK-SYSU: http://www.ee.cuhk.edu.hk/~xgwang/PS/dataset.html
- PRW: https://github.com/liangzheng06/PRW-baseline
- ETHZ: https://data.vision.ee.ethz.ch/cvl/aess/dataset/
- MOT16: https://motchallenge.net/data/MOT16/
- MOT17: https://motchallenge.net/data/MOT17/
- Head Tracking 21: https://motchallenge.net/data/Head_Tracking_21

学大模型,用大模型上飞桨星河社区!每天8点V100G算力免费领!免费领取ERNIE 4.0 100w Token >>>
更多推荐



 22
22 1
1- 0



 已为社区贡献1436条内容
已为社区贡献1436条内容

所有评论(0)