
【第十七智能车完全模型组竞速赛】线上赛推理代码撰写及结果提交教程
根据比赛要求撰写推理代码并整理结果文件
转载自AI Studio 项目链接https://aistudio.baidu.com/aistudio/projectdetail/3489163
线上赛推理代码撰写及结果提交教程
手把手教你根据比赛要求撰写推理代码并整理结果文件。
参考资料:
一、赛题介绍与数据说明
参赛者需要利用提供的训练数据,在统一的计算资源下,实现一个能够识别虚车道线、实车道线和斑马线具体位置和类别的深度学习模型,不限制深度学习任务。
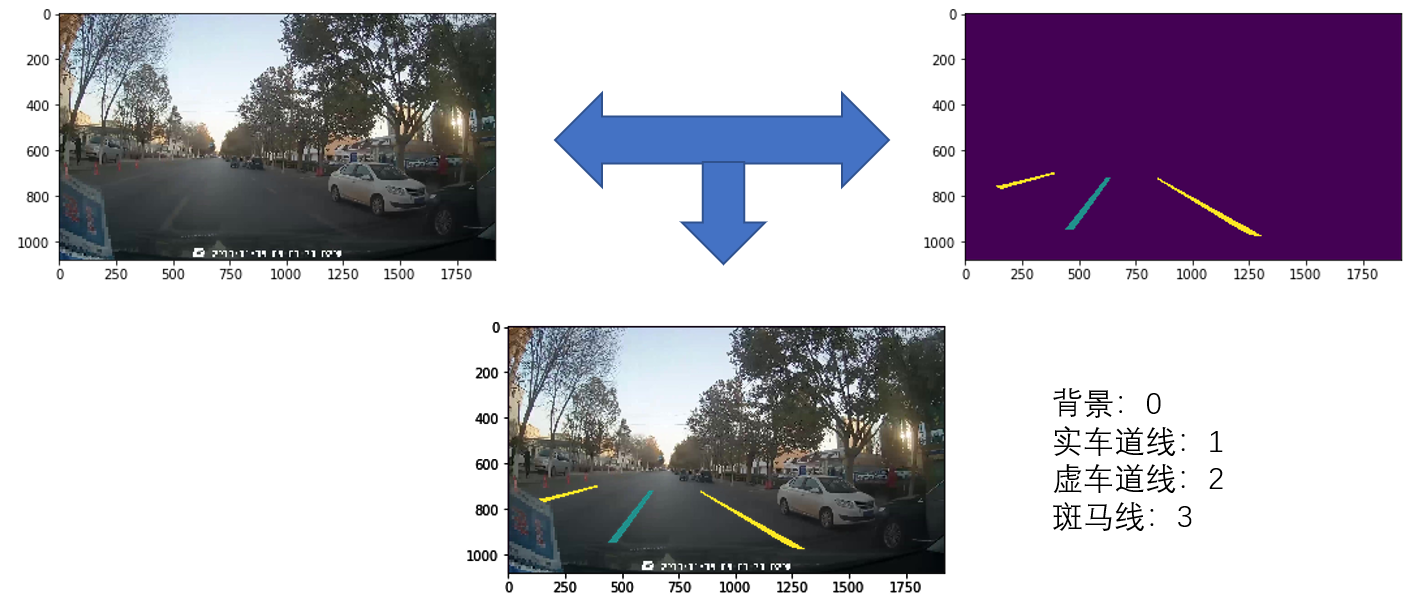
赛题数据集包括16000张可以直接用于训练的车载影像数据,官方采用分割连通域标注方法,对这些图片数据标注了虚车道线、实车道线和斑马线的区域和类别,其中标注数据以灰度图的方式存储。 标注数据是与原图尺寸相同的单通道灰度图,其中背景像素的灰度值为0,不同类别的目标像素分别为不同的灰度值。实车道线、虚车道线和斑马线类别编号分别为1、2和3。
报名后即可下载比赛数据集,竞赛官网传送门:
二、测评系统与提交思路
在正式整理结果文件前,我们有必要了解一下测评系统是如何工作的。
注意:
predict.py文件需要自己撰写!
平台评测配置环境
-
预测框架:平台默认配置paddle(v2.2)框架;
-
代码环境:平台仅配置python3.7执行环境;
-
环境库(可选):选手如需使用超出平台的代码依赖库或框架,即要求定义好env目录,确保predict.py在平台能正常执行。
平台测评流程与代码思路
AI Studio平台提供统一的预测机器资源(V100),并运行predict.py输出预测结果,具体执行命令如下:
predict.py data.txt result.json
划重点:提交的预测代码,其命名及文件夹位置应该与要求保持一致,否则测评系统无法找到你的预测代码
1.执行推理程序
predict.py的第一个参数data.txt是输入的图像路径索引文件,示例内容如下:
xx\xx\08001.jpg
…
xx\xx\10000.jpg
这时,你撰写的predict.py应该开始读取data.txt里的图片,并将其送入推理程序中,获取输出结果。
2.获取输出结果
predict.py的第二个参数result.json是输出的预测结果提交文件,格式要求如下:
{
"result": [{
"image_id": int
"type": int,
"segmentation": [polygon] },
...]
}
推理程序运行结束后,每一张图像应该会得到一个对应结果,你可以先用字典保存中间结果,最后再转成JSON文件即输出提交结果result.json。
到此为止,你撰写的predict.py文件运行完毕。测评系统会根据运行predict.py所消耗的时间以及data.txt包含的图片数量,得到FPS值(越高越好,越高说明推理速度越快)。
3.根据输出结果计算得分
最后,平台会把输出结果与真实结果进行对比,通过计算mIoU来评估结果,整个过程是平台自动完成的。
三、代码实现
我们将上面的思路用代码实现。代码参考PaddleSeg/deploy/python/infer.py
1.读取图像
我们需要把data.txt里的图像路径读取出来。
为了便于大家运行,这里只用10张图像给大家做示例,示例图像位于car/文件夹下。
我们可以写一段程序获取这个文件夹下的所有图片路径,并保存成data.txt文件,用来模拟提交时的输入文件。
import os
path = '/home/aistudio/car'
list_name = []
for file_name in os.listdir(path):
file_path = os.path.join(path, file_name)
if file_path[-3:] == "jpg":
list_name.append(file_path)
print(list_name)
with open('./data.txt','w') as f:
write=''
for i in list_name:
write=write+str(i)+'\n'
f.write(write)
['/home/aistudio/car/00010.jpg', '/home/aistudio/car/00008.jpg', '/home/aistudio/car/00004.jpg', '/home/aistudio/car/00002.jpg', '/home/aistudio/car/00003.jpg', '/home/aistudio/car/00001.jpg', '/home/aistudio/car/00007.jpg', '/home/aistudio/car/00009.jpg', '/home/aistudio/car/00005.jpg', '/home/aistudio/car/00006.jpg']
我们也可以读取一下刚刚生成的data.txt:
def get_test_images(file_path):
images = set()
f = open(file_path)
line = f.readline()
while line:
line = line.strip('\n')
images.add(str(line))
line = f.readline()
f.close()
images = list(images)
return images
images_list = get_test_images(file_path='data.txt')
print(images_list)
['/home/aistudio/car/00002.jpg', '/home/aistudio/car/00008.jpg', '/home/aistudio/car/00006.jpg', '/home/aistudio/car/00010.jpg', '/home/aistudio/car/00004.jpg', '/home/aistudio/car/00001.jpg', '/home/aistudio/car/00007.jpg', '/home/aistudio/car/00009.jpg', '/home/aistudio/car/00003.jpg', '/home/aistudio/car/00005.jpg']
2.模型推理
推理程序可参考PaddleSeg/deploy/python/infer.py。
PaddleSeg完整代码传送门:https://github.com/PaddlePaddle/PaddleSeg
模型推理可以分为3个部分:
- 数据预处理:图像尺寸、归一化
- 准备模型:模型加载
- 获取输出:将掩码图转成分割连通域
数据预处理
数据预处理的配置在deploy.yaml里,一般来说,模型输入的图像尺寸应该保持一致,并且图像需要归一化:
transforms:
- type: Resize
target_size: [480, 480]
interp: 'LINEAR'
- type: Normalize
关于图像尺寸的说明:数据集中,图像的宽高是1920x1080,如果用原尺寸输入,模型推理的速度会变慢;另一方面,预测时的模型输入与训练时的模型输入保持一致时,其效果较好。因此,图像的尺寸要Resize到480x480的大小
import numpy as np
import codecs
import yaml
import paddleseg.transforms as T
from paddleseg.cvlibs import manager
class DeployConfig:
def __init__(self, path="submit/model/deploy.yaml"):
with codecs.open(path, 'r', 'utf-8') as file:
self.dic = yaml.load(file, Loader=yaml.FullLoader)
self._transforms = self._load_transforms(
self.dic['Deploy']['transforms'])
self._dir = os.path.dirname(path)
@property
def transforms(self):
return self._transforms
def _load_transforms(self, t_list):
com = manager.TRANSFORMS
transforms = []
for t in t_list:
ctype = t.pop('type')
transforms.append(com[ctype](**t))
return T.Compose(transforms)
cfg = DeployConfig()
data = cfg.transforms(images_list[0])[0]
print("输入模型的图像尺寸:{}".format(data.shape))
# print(data)
输入模型的图像尺寸:(3, 480, 480)
准备模型
这里我们使用PaddleInference来实现模型推理。首先导入必要的资源库:
from paddle.inference import create_predictor, PrecisionType
from paddle.inference import Config as PredictConfig
在正式地做推理之前,你需要准备好模型,并且把正确的网络参数加载进去。
from paddle.inference import create_predictor, PrecisionType
from paddle.inference import Config as PredictConfig
# 配置模型路径
model_path = "submit/model/model.pdmodel" # 模型结构
params_path = "submit/model/model.pdiparams" # 模型参数
pred_cfg = PredictConfig(model_path, params_path)
pred_cfg.enable_use_gpu(2000, 0)
predictor = create_predictor(pred_cfg)
[1m[35m--- Running analysis [ir_graph_build_pass][0m
[1m[35m--- Running analysis [ir_graph_clean_pass][0m
[1m[35m--- Running analysis [ir_analysis_pass][0m
[32m--- Running IR pass [is_test_pass][0m
[32m--- Running IR pass [simplify_with_basic_ops_pass][0m
[32m--- Running IR pass [conv_affine_channel_fuse_pass][0m
[32m--- Running IR pass [conv_eltwiseadd_affine_channel_fuse_pass][0m
[32m--- Running IR pass [conv_bn_fuse_pass][0m
[32m--- Running IR pass [conv_eltwiseadd_bn_fuse_pass][0m
I0225 23:12:14.951006 383 fuse_pass_base.cc:57] --- detected 36 subgraphs
[32m--- Running IR pass [embedding_eltwise_layernorm_fuse_pass][0m
[32m--- Running IR pass [multihead_matmul_fuse_pass_v2][0m
[32m--- Running IR pass [squeeze2_matmul_fuse_pass][0m
[32m--- Running IR pass [reshape2_matmul_fuse_pass][0m
[32m--- Running IR pass [flatten2_matmul_fuse_pass][0m
[32m--- Running IR pass [map_matmul_v2_to_mul_pass][0m
[32m--- Running IR pass [map_matmul_v2_to_matmul_pass][0m
[32m--- Running IR pass [map_matmul_to_mul_pass][0m
[32m--- Running IR pass [fc_fuse_pass][0m
[32m--- Running IR pass [fc_elementwise_layernorm_fuse_pass][0m
[32m--- Running IR pass [conv_elementwise_add_act_fuse_pass][0m
[32m--- Running IR pass [conv_elementwise_add2_act_fuse_pass][0m
[32m--- Running IR pass [conv_elementwise_add_fuse_pass][0m
[32m--- Running IR pass [transpose_flatten_concat_fuse_pass][0m
[32m--- Running IR pass [runtime_context_cache_pass][0m
[1m[35m--- Running analysis [ir_params_sync_among_devices_pass][0m
I0225 23:12:14.993126 383 ir_params_sync_among_devices_pass.cc:45] Sync params from CPU to GPU
[1m[35m--- Running analysis [adjust_cudnn_workspace_size_pass][0m
[1m[35m--- Running analysis [inference_op_replace_pass][0m
[1m[35m--- Running analysis [ir_graph_to_program_pass][0m
I0225 23:12:15.085718 383 analysis_predictor.cc:714] ======= optimize end =======
I0225 23:12:15.092967 383 naive_executor.cc:98] --- skip [feed], feed -> x
I0225 23:12:15.095815 383 naive_executor.cc:98] --- skip [argmax_0.tmp_0], fetch -> fetch
获取输出
我们先实现预测一张图像的代码,然后你可以写一个for循环来预测所有图像。
# 准备输入数据
input_names = predictor.get_input_names()
input_handle = predictor.get_input_handle(input_names[0])
input_data = np.array([data])
input_handle.reshape(input_data.shape)
input_handle.copy_from_cpu(input_data)
# 模型预测
predictor.run()
# 获取输出结果
output_names = predictor.get_output_names()
output_handle = predictor.get_output_handle(output_names[0])
print("输出掩码图的尺寸为:{}".format(output_handle.copy_to_cpu().shape))
输出掩码图的尺寸为:(1, 480, 480)
可视化输出
为了直观地检验模型的好坏,我们可以可视化输出结果。
%matplotlib inline
import numpy as np
import matplotlib.pyplot as plt
from paddleseg.utils.visualize import get_pseudo_color_map
seg_result = np.squeeze(output_handle.copy_to_cpu())
result = get_pseudo_color_map(seg_result)
plt.imshow(result)
plt.show()
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-DCL9d59d-1646532740348)(output_16_0.png)]](https://i-blog.csdnimg.cn/blog_migrate/f4b90fa91c497080370bfe0df8098629.png)
3.保存结果
掩码图转分割连通域
模型的输出结果是上面所展示的掩码图,比赛要求的提交格式是分割连通域,因此,我们还需要对上面的结果进行转换。
我们可以使用cv2.findContours()函数来查找物体的轮廓,即分割连通域。
import cv2
contours, hierarchy = cv2.findContours(seg_result.astype('uint8'), cv2.RETR_TREE, cv2.CHAIN_APPROX_SIMPLE)
print("一共找到{}个轮廓,其中,第一个轮廓由{}个点组成".format(len(contours), len(contours[0])))
一共找到7个轮廓,其中,第一个轮廓由8个点组成
由于输出图像的尺寸是480x480的大小,而实际图像的尺寸是1920x1080,所以我们需要把坐标点映射到原尺寸。
# 查看轮廓点的坐标
coordinate = contours[0][0][0]
print("480x480对应的坐标点为({}, {})".format(coordinate[0], coordinate[1]))
# 计算一下分割图需要还原的比例
w_ratio = float(1920 / 480)
h_ratio = float(1080 / 480)
print("1920x1080对应的坐标点为({}, {})".format(coordinate[0]*w_ratio, coordinate[1]*h_ratio))
480x480对应的坐标点为(298, 282)
1920x1080对应的坐标点为(1192.0, 634.5)
获取分割连通域所属类别
得到分割连通域后,我们还需要确定分割连通域的类别。本教程的方法是通过位置索引获取类别。

如上图所示,我们的分割连通域是由坐标点组成的,那么,我们可以把坐标点当作索引,获取该分割连通域内具体的数值,这个数值其实就是我们的类别标签。
x, y = coordinate[0], coordinate[1]
category = int(seg_result[y][x])
print("该分割连通域的类别为id:{}".format(category))
该分割连通域的类别为id:2
4.多线程/多进程加速
线上赛提交结果时有FPS的要求,如果FPS小于30,那么得分为0。我们可以使用多线程/多进程的方法加速。
这里使用 multiprocessing.dummy 模块执行多线程任务的方法。
multiprocessing.dummy 模块与 multiprocessing 模块的区别:
dummy模块是多线程,而 multiprocessing 是多进程, api 都是通用的。 所以可以很方便将代码在多线程和多进程之间切换。
下面是示例代码:
# from multiprocessing import Pool
from multiprocessing.dummy import Pool as ThreadPool
import time
def main(data):
for item in range(100):
pass
data = [1] * 100
start = time.time()
results = map(main, data)
print('Normal:', time.time() - start)
start2 = time.time()
# 开8个 worker,没有参数时默认是 cpu 的核心数
pool = ThreadPool(processes=8)
# 在线程中执行 main(data) 并返回执行结果
results2 = pool.map(main, data)
pool.close()
pool.join()
print('Thread Pool:', time.time() - start2)
Normal: 4.935264587402344e-05
Thread Pool: 0.10247254371643066
5.完整代码
我们将上面的代码串起来,写成一个完整的predict.py,并试着测试一下。
%cd /home/aistudio/submit/
!python predict.py data.txt result.json
/home/aistudio/submit
FPS:3.78446874204859
输出的结果文件保存在submit/result.json里。
四、异常解决
在提交结果文件时,可能会遇到如下报错,下面是我的解决思路。
[OOMKilled] job failed because of Insufficient memory
该报错是内存不足导致的,而内存不足有两种情况:
- 推理模型时,模型较大,占用内存较大导致报错
- 保存结果文件时,内容过多导致保存失败
the predict.py script failed to run
出现此报错的原因是提交的文件里多了一些影响代码运行的文件。
在本教程里,为了方便测试,在submit文件夹中加入了data.txt,并且运行后会生成一个result.json文件,正式提交时,这两个文件应该被删除,如下所示:
├── model
│ ├── deploy.yaml
│ ├── model.pdiparams
│ ├── model.pdiparams.info
│ └── model.pdmodel
├── paddleseg
│ ├── core
│ ├── cvlibs
│ ├── datasets
│ ├── __init__.py
│ ├── models
│ ├── __pycache__
│ ├── transforms
│ └── utils
├── predict.py
└── train.py
V1.5.0版本以前,提交的分数只有零头
1.image_id不匹配
V1.5.0版本以前(包括V1.5.0版本)的image_id只有4位,但是实际的image_id有5位,因为id不匹配,所以得分低,这是最根本的原因
2.图像尺寸不匹配
V1.5.0版本以前(包括V1.5.0版本)的图像尺寸被写死了,测评系统里的图像尺寸不一,所以分数较低
3.图像读取格式
在paddleseg/transforms/transforms.py的第56行里,数据的读取方式默认是float32,改成uint8会使FPS提高大概10,但是分数会降低(可忽略不计)
在V1.6.0版本中,已修复以上问题,最新得分为:
五、总结与升华
注意:本项目中使用的模型源自官方基线系统的BiSeNet,但是没有完全训练,只是训练了几个iter就保存了模型,只作为测试使用。因此,想要获取更高的分数,你需要:
- 将
submit/model里的模型更换为你自己训练的模型,同时需要注意修改参数配置文件的内容; - 尽可能优化
predict.py里的代码,使得代码运行速度更快,效率更高; - 文件格式上,
submit文件夹下的data.txt是测试用的输入,result.json是测试的输出结果,当你正式提交时,应该把这两个文件删除; - 代码里还存在着不够好的地方需要优化,掩码图转分割连通域的代码比较复杂,有很大的提升空间;
- 可在数据读取上尝试进行优化,opencv读取图像是默认是
float32,如果使用uint8,速度会快不少; - 可尝试对模型进行裁剪,或使用模型蒸馏,从而进一步加快运行速度。
作者简介
北京联合大学 机器人学院 自动化专业 2018级 本科生 郑博培
中国科学院自动化研究所复杂系统管理与控制国家重点实验室实习生
百度飞桨开发者技术专家 PPDE
百度飞桨北京领航团团长
百度飞桨官方帮帮团、答疑团成员
深圳柴火创客空间 认证会员
百度大脑 智能对话训练师
阿里云人工智能、DevOps助理工程师
我在AI Studio上获得至尊等级,点亮10个徽章,来互关呀!!!
https://aistudio.baidu.com/aistudio/personalcenter/thirdview/147378


学大模型,用大模型上飞桨星河社区!每天8点V100G算力免费领!免费领取ERNIE 4.0 100w Token >>>
更多推荐



 3
3 0
0- 0



 已为社区贡献1436条内容
已为社区贡献1436条内容

所有评论(0)