
基于SKEP预训练模型进行语句级情感分析
基于SKEP预训练模型,在chnsenticorp数据集上进行语句级别的情感分析
基于SKEP预训练模型进行情感分析
众所周知,人类自然语言中包含了丰富的情感色彩:表达人的情绪(如悲伤、快乐)、表达人的心情(如倦怠、忧郁)、表达人的喜好(如喜欢、讨厌)、表达人的个性特征和表达人的立场等等。情感分析在商品喜好、消费决策、舆情分析等场景中均有应用。利用机器自动分析这些情感倾向,不但有助于帮助企业了解消费者对其产品的感受,为产品改进提供依据;同时还有助于企业分析商业伙伴们的态度,以便更好地进行商业决策。
一般来讲,被人们所熟知的情感分析任务是语句级别的情感分析,其主要分析一段文本中整体蕴含的情感色彩。其常用于电影评论分析、网络论坛舆情分析等场景,如下面这句话所示。
15.4寸笔记本的键盘确实爽,基本跟台式机差不多了,蛮喜欢数字小键盘,输数字特方便,样子也很美观,做工也相当不错 1
为方便语句级别的情感分析任务建模,可将情感极性分为正向、负向、中性三个类别,这样将情感分析任务转变为一个分类问题,如图1所示:
- 正向: 表示正面积极的情感,如高兴,幸福,惊喜,期待等;
- 负向: 表示负面消极的情感,如难过,伤心,愤怒,惊恐等;
- 中性: 其他类型的情感;

本实践将基于预训练SKEP模型,在ChnSentiCorp
进行建模语句级别的情感分析任务。
学习资源
- 更多的深度学习资料,比如深度学习知识,论文解读,实践案例等,请参考:awesome-DeepLearning
- 更多飞桨框架相关资料,请参考:飞桨深度学习平台
⭐ ⭐ ⭐ 欢迎点个小小的Star,开源不易,希望大家多多支持~⭐ ⭐ ⭐

1. 方案设计
本实践的设计思路如图2所示,首先将文本串传入SKEP模型中,利用SKEP模型对该文本串进行语义编码后,将CLS位置的token输出向量作为最终的语义编码向量。接下来将根据该语义编码向量进行情感分类。需要注意的是:ChnSentiCorp数据集是个二分类数据集,其情感极性只包含正向和负向两个类别。
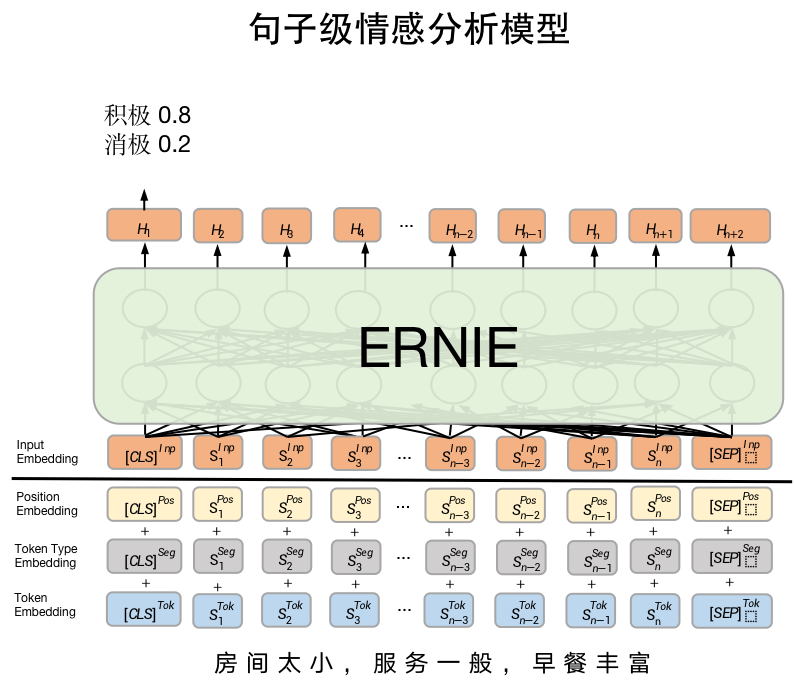
2. 数据处理
2.1 数据集介绍
本实践将在数据集ChnSentiCorp进行情感分析任务。该数据集是个语句级别的数据集,其中训练集包含9.6k训练样本,开发集和测试集均包含1.2k训练样本。下面展示了该数据集中的两条样本:
{
"text":"不错,帮朋友选的,朋友比较满意,就是USB接口少了,而且全是在左边,图片有误",
"label":1
}
{
"text":"机器背面似乎被撕了张什么标签,残胶还在。但是又看不出是什么标签不见了,该有的都在,怪",
"label":0
}
2.2 数据加载
本节我们将训练、评估和测试数据集加载到内存中。 由于ChnSentiCorp数据集属于paddlenlp的内置数据集,所以本实践我们将直接从paddlenlp里面加载数据。相关代码如下。
import os
import copy
import argparse
import numpy as np
from functools import partial
import paddle
import paddle.nn.functional as F
from paddlenlp.datasets import load_dataset
from paddlenlp.data import Pad, Stack, Tuple
from paddlenlp.metrics import AccuracyAndF1
from paddlenlp.transformers import SkepTokenizer, SkepModel, LinearDecayWithWarmup
from utils.utils import set_seed
from utils.data import convert_example_to_feature
train_ds, dev_ds = load_dataset("chnsenticorp", splits=["train", "dev"])
2.3 将数据转换成特征形式
在将数据加载完成后,接下来,我们将训练和开发集数据转换成适合输入模型的特征形式,即将文本字符串数据转换成字典id的形式。这里我们要加载paddleNLP中的SkepTokenizer,其将帮助我们完成这个字符串到字典id的转换。
model_name = "skep_ernie_1.0_large_ch"
batch_size = 16
max_seq_len = 256
tokenizer = SkepTokenizer.from_pretrained(model_name)
trans_func = partial(convert_example_to_feature, tokenizer=tokenizer, max_seq_len=max_seq_len)
train_ds = train_ds.map(trans_func, lazy=False)
dev_ds = dev_ds.map(trans_func, lazy=False)
[2021-11-10 13:53:27,418] [ INFO] - Found /home/aistudio/.paddlenlp/models/skep_ernie_1.0_large_ch/skep_ernie_1.0_large_ch.vocab.txt
2.4 构造DataLoader
接下来,我们需要根据加载至内存的数据构造DataLoader,该DataLoader将支持以batch的形式将数据进行划分,从而以batch的形式训练相应模型。
batchify_fn = lambda samples, fn=Tuple(
Pad(axis=0, pad_val=tokenizer.pad_token_id),
Pad(axis=0, pad_val=tokenizer.pad_token_type_id),
Stack(dtype="int64")
): fn(samples)
train_batch_sampler = paddle.io.BatchSampler(train_ds, batch_size=batch_size, shuffle=True)
dev_batch_sampler = paddle.io.BatchSampler(dev_ds, batch_size=batch_size, shuffle=False)
train_loader = paddle.io.DataLoader(train_ds, batch_sampler=train_batch_sampler, collate_fn=batchify_fn)
dev_loader = paddle.io.DataLoader(dev_ds, batch_sampler=dev_batch_sampler, collate_fn=batchify_fn)
3. 模型构建
本案例中,我们将基于SKEP模型实现图2所展示的情感分析功能。具体来讲,我们将处理好的文本数据输入SLEP模型中,ERNIE将会对文本的每个token进行编码,产生对应向量序列,我们任务CLS位置对应的输出向量能够代表语句的完整语义,所以将利用该向量进行情感分类。相应代码如下。
class SkepForSquenceClassification(paddle.nn.Layer):
def __init__(self, skep, num_classes=2, dropout=None):
super(SkepForSquenceClassification, self).__init__()
self.num_classes = num_classes
self.skep = skep
self.dropout = paddle.nn.Dropout(p=dropout if dropout is not None else self.skep.config["hidden_dropout_prob"])
self.classifier = paddle.nn.Linear(self.skep.config["hidden_size"], self.num_classes)
def forward(self, input_ids, token_type_ids=None, position_ids=None, attention_mask=None):
_, pooled_output = self.skep(input_ids, token_type_ids=token_type_ids, position_ids=position_ids, attention_mask=attention_mask)
pooled_output = self.dropout(pooled_output)
logits = self.classifier(pooled_output)
return logits
4. 训练配置
接下来,定义情感分析模型训练时的环境,包括:配置训练参数、配置模型参数,定义模型的实例化对象,指定模型训练迭代的优化算法等,相关代码如下。
# model hyperparameter setting
num_epoch = 1
learning_rate = 3e-5
weight_decay = 0.01
warmup_proportion = 0.1
max_grad_norm = 1.0
log_step = 50
eval_step = 200
seed = 1000
checkpoint = "./checkpoint/"
set_seed(seed)
use_gpu = True if paddle.get_device().startswith("gpu") else False
if use_gpu:
paddle.set_device("gpu:0")
if not os.path.exists(checkpoint):
os.mkdir(checkpoint)
skep = SkepModel.from_pretrained(model_name)
model = SkepForSquenceClassification(skep, num_classes=len(train_ds.label_list))
num_training_steps = len(train_loader) * num_epoch
lr_scheduler = LinearDecayWithWarmup(learning_rate=learning_rate, total_steps=num_training_steps, warmup=warmup_proportion)
decay_params = [p.name for n, p in model.named_parameters() if not any(nd in n for nd in ["bias", "norm"])]
grad_clip = paddle.nn.ClipGradByGlobalNorm(max_grad_norm)
optimizer = paddle.optimizer.AdamW(learning_rate=lr_scheduler, parameters=model.parameters(), weight_decay=weight_decay, apply_decay_param_fun=lambda x: x in decay_params, grad_clip=grad_clip)
metric = AccuracyAndF1()
[2021-11-10 13:53:34,544] [ INFO] - Already cached /home/aistudio/.paddlenlp/models/skep_ernie_1.0_large_ch/skep_ernie_1.0_large_ch.pdparams
W1110 13:53:34.549857 31931 device_context.cc:404] Please NOTE: device: 0, GPU Compute Capability: 7.0, Driver API Version: 10.1, Runtime API Version: 10.1
W1110 13:53:34.556116 31931 device_context.cc:422] device: 0, cuDNN Version: 7.6.
5. 模型训练与评估
本节我们将定义一个train函数和evaluate函数,其将分别进行训练和评估模型。在训练过程中,每隔log_steps步打印一次日志,每隔eval_steps步进行评估一次模型,并始终保存验证效果最好的模型。相关代码如下:
def evaluate(model, data_loader, metric):
model.eval()
metric.reset()
for idx, batch_data in enumerate(data_loader):
input_ids, token_type_ids, labels = batch_data
logits = model(input_ids, token_type_ids=token_type_ids)
# count metric
correct = metric.compute(logits, labels)
metric.update(correct)
accuracy, precision, recall, f1, _ = metric.accumulate()
return accuracy, precision, recall, f1
def train():
global_step, best_f1 = 1, 0.
model.train()
for epoch in range(1, num_epoch+1):
for batch_data in train_loader():
input_ids, token_type_ids, labels = batch_data
logits = model(input_ids, token_type_ids=token_type_ids)
loss = F.cross_entropy(logits, labels)
loss.backward()
lr_scheduler.step()
optimizer.step()
optimizer.clear_grad()
if global_step > 0 and global_step % log_step == 0:
print(f"epoch: {epoch} - global_step: {global_step}/{num_training_steps} - loss:{loss.numpy().item():.6f}")
if (global_step > 0 and global_step % eval_step == 0) or global_step == num_training_steps:
accuracy, precision, recall, f1 = evaluate(model, dev_loader, metric)
model.train()
if f1 > best_f1:
print(f"best F1 performence has been updated: {best_f1:.5f} --> {f1:.5f}")
best_f1 = f1
paddle.save(model.state_dict(), f"{checkpoint}/best.pdparams")
print(f'evalution result: accuracy: {accuracy:.5f}, precision: {precision:.5f}, recall: {recall:.5f}, F1: {f1:.5f}')
global_step += 1
paddle.save(model.state_dict(), f"{checkpoint}/final.pdparams")
train()
epoch: 1 - global_step: 50/600 - loss:0.456018
epoch: 1 - global_step: 100/600 - loss:0.538403
epoch: 1 - global_step: 150/600 - loss:0.390294
epoch: 1 - global_step: 200/600 - loss:0.745360
best F1 performence has been updated: 0.00000 --> 0.92969
evalution result: accuracy: 0.9291666666666667, precision: 0.91234, recall: 0.94772, F1: 0.92969
epoch: 1 - global_step: 250/600 - loss:0.035638
epoch: 1 - global_step: 300/600 - loss:0.338947
epoch: 1 - global_step: 350/600 - loss:0.255733
epoch: 1 - global_step: 400/600 - loss:0.016853
evalution result: accuracy: 0.9291666666666667, precision: 0.91234, recall: 0.94772, F1: 0.92969
epoch: 1 - global_step: 450/600 - loss:0.150336
epoch: 1 - global_step: 500/600 - loss:0.303883
epoch: 1 - global_step: 550/600 - loss:0.256591
epoch: 1 - global_step: 600/600 - loss:0.348062
evalution result: accuracy: 0.9291666666666667, precision: 0.91234, recall: 0.94772, F1: 0.92969
6. 模型推理
实现一个模型预测的函数,实现任意输入一串带有情感的文本串,如:“交通方便;环境很好;服务态度很好 房间较大”,期望能够输出这段文本描述中所蕴含的情感类别。首先我们先加载训练好的模型参数,然后进行推理。相关代码如下。
# process data related
model_name = "skep_ernie_1.0_large_ch"
model_path = os.path.join(checkpoint, "best.pdparams")
id2label = {0:"Negative", 1:"Positive"}
# load model
loaded_state_dict = paddle.load(model_path)
ernie = SkepModel.from_pretrained(model_name)
model = SkepForSquenceClassification(ernie, num_classes=len(train_ds.label_list))
model.load_dict(loaded_state_dict)
[2021-11-10 14:01:27,887] [ INFO] - Already cached /home/aistudio/.paddlenlp/models/skep_ernie_1.0_large_ch/skep_ernie_1.0_large_ch.pdparams
def predict(input_text, model, tokenizer, id2label, max_seq_len=256):
model.eval()
# processing input text
encoded_inputs = tokenizer(input_text, max_seq_len=max_seq_len)
input_ids = paddle.to_tensor([encoded_inputs["input_ids"]])
token_type_ids = paddle.to_tensor([encoded_inputs["token_type_ids"]])
# predict by model and decoding result
logits = model(input_ids, token_type_ids=token_type_ids)
label_id = paddle.argmax(logits, axis=1).numpy()[0]
# print predict result
print(f"text: {input_text} \nlabel: {id2label[label_id]}")
input_text = "交通方便;环境很好;服务态度很好 房间较大"
predict(input_text, model, tokenizer, id2label, max_seq_len=256)
text: 交通方便;环境很好;服务态度很好 房间较大
label: Positive
7. 更多深度学习资源
7.1 一站式深度学习平台awesome-DeepLearning
- 深度学习入门课
- 深度学习百问

- 特色课

- 产业实践
PaddleEdu使用过程中有任何问题欢迎在awesome-DeepLearning提issue,同时更多深度学习资料请参阅飞桨深度学习平台。
记得点个Star⭐收藏噢~~

7.2 飞桨技术交流群(QQ)
目前QQ群已有2000+同学一起学习,欢迎扫码加入

学大模型,用大模型上飞桨星河社区!每天8点V100G算力免费领!免费领取ERNIE 4.0 100w Token >>>
更多推荐


 1
1 0
0- 0



 已为社区贡献1438条内容
已为社区贡献1438条内容

所有评论(0)