
【校园AI Day-AI workshop】自定义区域OCR识别文件重命名
【校园AI Day-AI workshop】自定义区域OCR识别文件重命名
1背景介绍
任务描述:在实际的工作中,有时候需要根据图片中的指定区域进行重命名,通过OCR技术实现可自主框选识别区,实现识别内容的精确提取。本任务提供30张交付验收单,需要通过OCR技术识别图片中的铁塔名称,并根据该字段完成对图片的重命名
2解决方案
2.1数据分析
数据情况:制式标准表单
数据量:30张扫描数据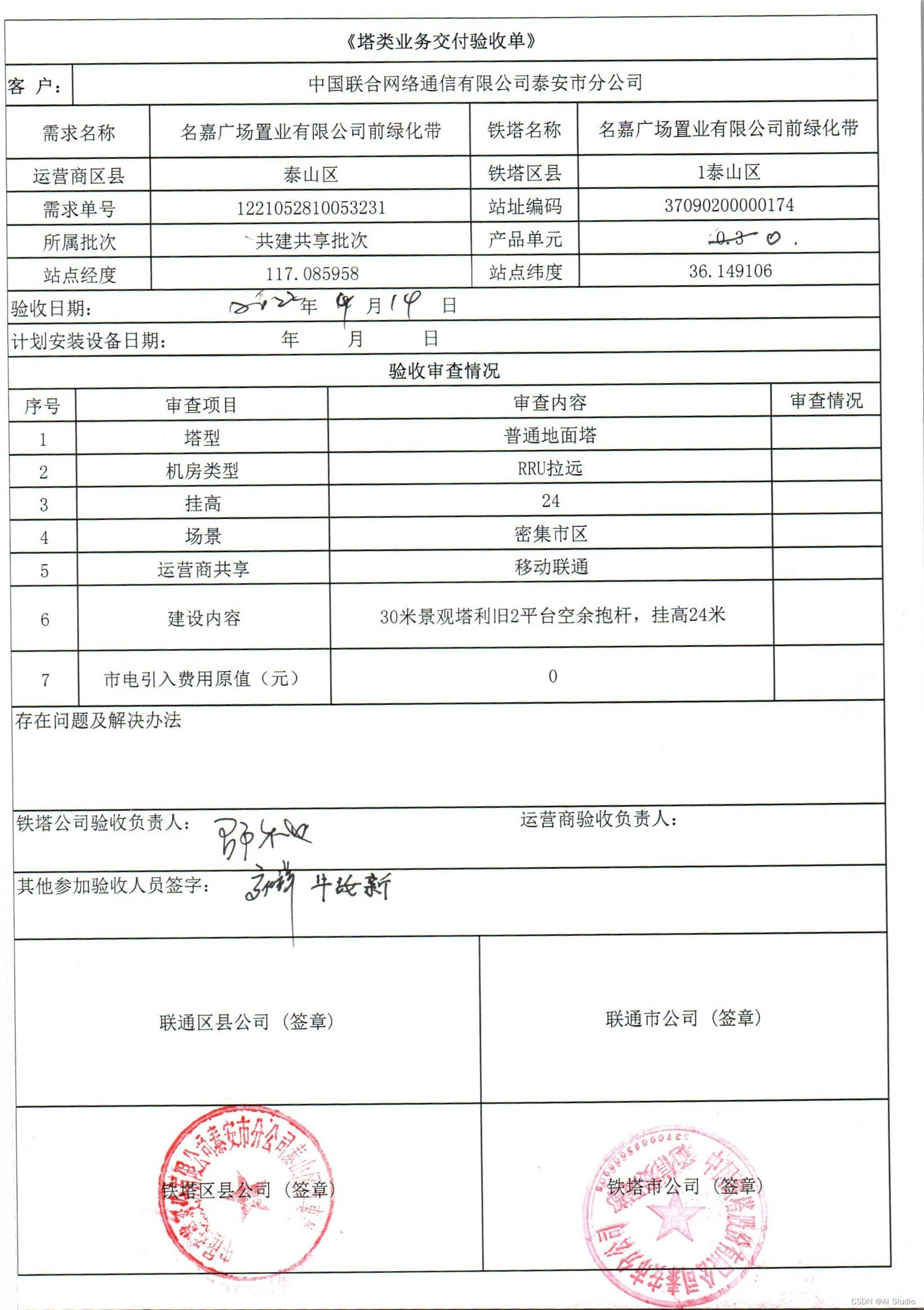
2.2表单识别介绍
参考《多模态技术在金融场景创新实践:表单识别》
表单识主流方案:单模态和多模态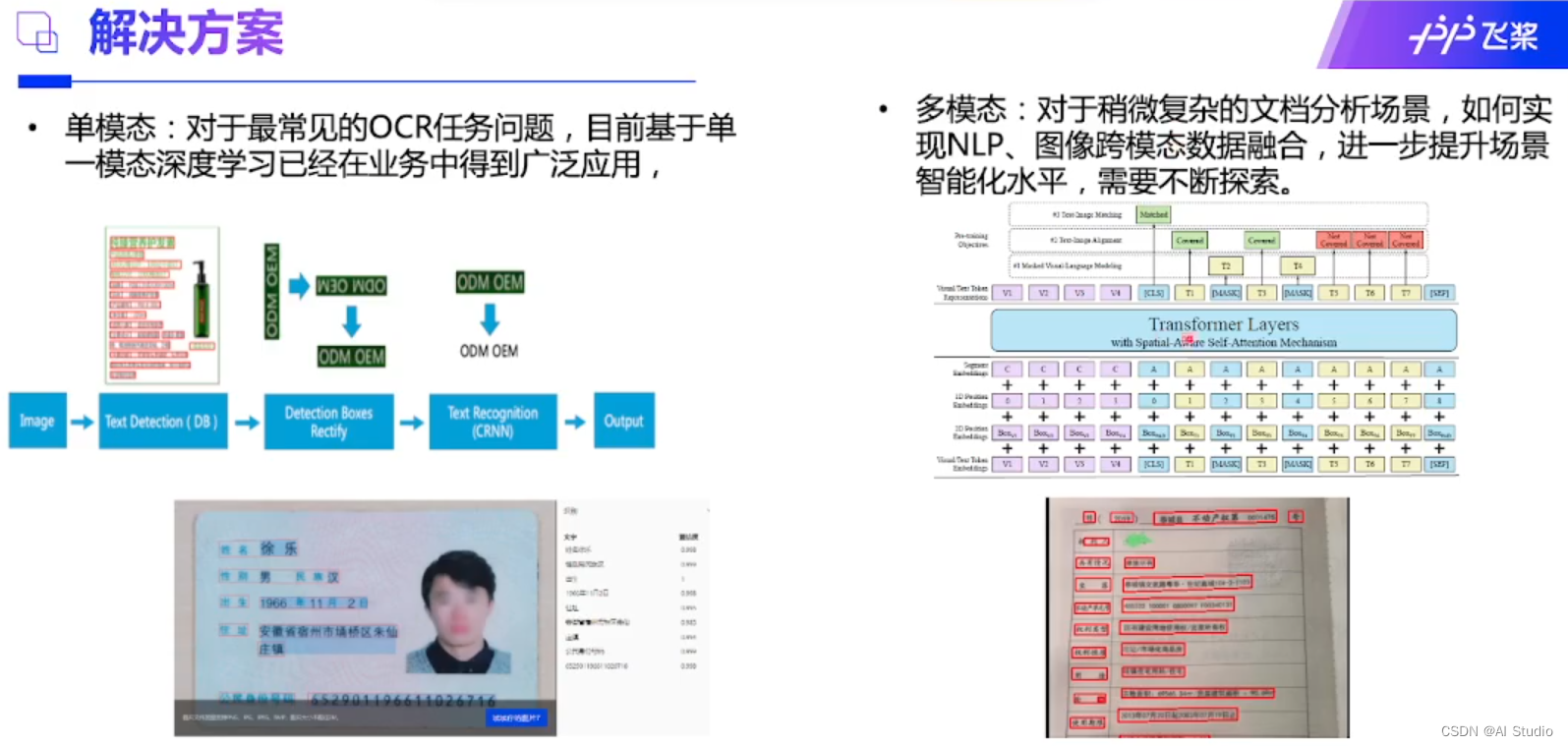

2.3本项目拟采取思路 基于PaddleHUB+后处理(低代码快速实现文本提前)
基于PaddleHUB+后处理(低代码快速实现文本提前)
准确率100%
3实施过程
3.1数据准备
本项目没有专门数据集挂载,自行从本地上传到/home/aistudio/work/data
In [ ]
#创建文件夹,上传数据
#!mkdir work/data
!tree work/data
3.2环境准备
In [ ]
#安装 paddlehub
!pip install paddlepaddle -i https://pypi.tuna.tsinghua.edu.cn/simple
!pip install paddlehub==2.1 -i https://pypi.tuna.tsinghua.edu.cn/simple
3.3执行输出
In [ ]
#定义获取名称函数
import paddlehub as hub
import cv2
ocr = hub.Module(name=“ch_pp-ocrv3”)
def get_name(fn):
img = cv2.imread(fn)
result = ocr.recognize_text(images=[img])
#1找到铁塔名称
indx = 0
r_data = result[0]['data']
for i in range(len(r_data)):
if '塔名称' in r_data[i]['text']:
#print(r_data[i]['text_box_position'])
indx = i
break
#2找到铁塔名称
#垂直方向加权,铁塔名称答案在一条直线上
weight_y = 4
#找到离铁塔名称最近的识别框
p_x = (r_data[indx]['text_box_position'][1][0] + r_data[indx]['text_box_position'][2][0])/2
p_y = (r_data[indx]['text_box_position'][1][1] + r_data[indx]['text_box_position'][2][1])/2
min_d = p_x + p_y
name_idx = 0
for i in range(len(r_data)):
#排除自己
if i == indx:
continue
x = (r_data[i]['text_box_position'][0][0] + r_data[i]['text_box_position'][3][0])/2
y = (r_data[i]['text_box_position'][0][1] + r_data[i]['text_box_position'][3][1])/2
dis = abs(p_x-x) + abs(p_y - y)*weight_y
#print('{0}:{1}'.format(dis,r_data[i]['text']))
if dis < min_d:
min_d = dis
name_idx = i
name = r_data[name_idx]['text']
#3搜索夸行问题
weight_x =1
#底部两个点中点
p_x = (r_data[name_idx]['text_box_position'][2][0] + r_data[name_idx]['text_box_position'][3][0])/2
p_y = (r_data[name_idx]['text_box_position'][2][1] + r_data[name_idx]['text_box_position'][3][1])/2
min_d = 20 # 距离小于20存在跨行
for i in range(len(r_data)):
#排除自己
if i == name_idx:
continue
x = (r_data[i]['text_box_position'][0][0] + r_data[i]['text_box_position'][1][0])/2
y = (r_data[i]['text_box_position'][0][1] + r_data[i]['text_box_position'][1][1])/2
dis = abs(p_x-x)*weight_x + abs(p_y - y)
#print('{0}:{1}'.format(dis,r_data[i]['text']))
if dis < min_d:
name += r_data[i]['text']
break
return name
In [ ]
#遍历重命名文件
!mkdir work/output
import os
img_dir = ‘work/data’
output_dir = ‘work/output’
for pic in os.listdir(img_dir):
fn = os.path.join(img_dir,pic)
name = get_name(fn)
print(‘{0}:{1}’.format(fn,name))
import shutil
shutil.copy(fn,os.path.join(output_dir,name + fn[-9:]))
4总结
本项目解决是特定制式表单,通过后处理trick堆叠使处理结果达到100%
工业实践中还需要根据图片分辨率修正参数
表单识别思路有很多,后续有空会写一下单模态其他方法、多模态方法实现
感谢飞桨提供平台,感谢项目过程导师给予知道
队伍介绍
队名:路人队
队长:yangliang1132
队员:tianxingxia
请点击此处查看本环境基本用法.
Please click here for more detailed instructions.

学大模型,用大模型上飞桨星河社区!每天8点V100G算力免费领!免费领取ERNIE 4.0 100w Token >>>
更多推荐



 0
0 0
0- 0



 已为社区贡献1437条内容
已为社区贡献1437条内容

所有评论(0)