
【AI达人特训营】强化学习优化离散制造系统
【AI达人特训营】强化学习优化离散制造系统0.简介在制造系统中,产线工位设置、工艺流程的组织直接影响车间生产效率、产量及成本,关系到企业盈利情况。“中国制造2025”国家行动纲领规划了我国制造业三步走战略,明确指出加快推动新一代信息技术与制造技术融合发展,把智能制造作为两化深度融合的主攻方向;着力发展智能装备和智能产品,推进生产过程智能化,培育新型生产方式,全面提升企业研发、生产、管理和服务的智能
【AI达人特训营】强化学习优化离散制造系统
0.简介
在制造系统中,产线工位设置、工艺流程的组织直接影响车间生产效率、产量及成本,关系到企业盈利情况。“中国制造2025”国家行动纲领规划了我国制造业三步走战略,明确指出加快推动新一代信息技术与制造技术融合发展,把智能制造作为两化深度融合的主攻方向;着力发展智能装备和智能产品,推进生产过程智能化,培育新型生产方式,全面提升企业研发、生产、管理和服务的智能化水平。因此将人工智能引入到企业制造系统的工艺规划中具有极其重要的现实意义。
不同企业生产线因其生产产品、企业技术路线的不同而存在较大差异,传统企业一般不具备保存大量生产信息数据的意识。另外由于柔性制造需要,产线生产计划调整也更加频繁,即便积累了大量前期生产数据,也很难符合调整后的产线情况。所以依赖大量样本的机器学习系统难以直接应用于企业产线的智能化升级中。
强化学习不依赖样本,构建合理的交互环境即可开展学习训练,为产线的智能优化提供了合适的解决途径。本项目旨在通过简单例程,实现强化学习优化离散制造系统的流程框架的搭建,为企业类似项目的落地提供一个思路。
本项目依托百度飞桨【AI达人特训营】,在陆平导师指导下完成。
项目使用simpy仿真库进行离散制造系统的环境建模;使用parl库,通过DQN强化学习方法,优化系统中上料机械臂的原料分配策略,进行制造系统流程优化。
- 库导入
simpy 仿真库
parl 强化学习库
In [ ]
!pip install simpy
!pip install parl==2.0.4
In [2]
同时添加如下代码, 这样每次环境(kernel)启动的时候只要运行下方代码即可:
Also add the following code,
so that every time the environment (kernel) starts,
just run the following code:
import sys
sys.path.append(‘/home/aistudio/external-libraries’)
In [3]
#导入simpy模块
from simpy.core import Environment #环境,所有的事件都在环境中
from simpy.resources.store import Store #存储,用它可以模拟队列、仓库
from simpy.resources.resource import Resource #资源,用它可以模拟资源占用
2. 制造系统环境构建
本项目制造系统构成如下:
2个加工工位,1个搬运机械臂,1个质检工位
2个加工工位执行同一工序共同生产,每个加工工位各有一个进料区。
加工工位1,生产效率高(10),良品率低(0.7)
加工工位2,生产效率低(20),良品率高(0.9)
机械臂由料库向2个加工工位进料区搬运原料
质检工位检测产品质量,合格进入成品库,不合格需要重新加工。
通过DQN算法训练机械臂向2个工位供料策略,以优化系统生产工时,并减小2个加工工位进料区的原料堆积。
在生产系统类中定义了强化学习交互环境相关函数。
本项目制造系统搭建参考自陆平导师“多阶段离散制造系统的数字化仿真(简易版)”项目 https://aistudio.baidu.com/aistudio/projectdetail/1691625?channelType=0&channel=0
2.1 零件类定义
In [4]
#零部件类–调用它可以生成零部件实例
class Part:
#初始化方法
def init(self, env, name):
self.env = env
self.name = name
self.finished = “待加工”
self.check=“未检测”
self.action = self.env.process(self.run())
def run(self):
yield self.env.timeout(0) #设置延迟时间为0
2.2 加工工位1工艺流程定义
加工工位1由该工位进料区获得原料进行加工,其生产效率为每隔10个单位时间加工1个零件,良品率70%(由随机数生成,确定所生产零件质量)。
In [5]
import random
‘’’
加工工位1
‘’’
def process_unit1(env, in_store, out_store):
while True:
p = yield in_store.get() #从输入队列中获取待加工的零部件
yield env.timeout(10) #加工零部件时间流逝,加工工位1的生产效率为每隔10个单位时间,加工1个零件
p.finished = “已加工” #设置为已加工
if random.random() < 0.7: #如果生成的随机数小于0.7,则为良品
p.check = “合格” #设置为合格
else:
p.check = “不合格” #设置为不合格
if not train:
print(‘%s 在时刻%d加工完毕, 加工设备1’ % (p.name, env.now))
out_store.put§ #把已经加工后的零部件放入输出队列
2.3 加工工位2工艺流程定义
加工工位2由该工位进料区获得原料进行加工,其生产效率为每隔20个单位时间加工1个零件,良品率90%(由随机数生成,确定所生产零件质量)。
In [6]
‘’’
加工工位2
‘’’
def process_unit2(env, in_store, out_store):
while True:
p = yield in_store.get() #从输入队列中获取待加工的零部件
yield env.timeout(20) #加工零部件时间流逝,加工工位2的生产效率为每隔20个单位时间,加工1个零部件
p.finished = “已加工” #设置为已加工
if random.random() < 0.9: #如果生成的随机数小于0.9,则为良品
p.check = “合格” #设置为合格
else:
p.check = “不合格” #设置为不合格
if not train:
print(‘%s 在时刻%d加工完毕, 加工设备2’ % (p.name, env.now))
out_store.put§ #把已经加工后的零部件放入输出队列
2.4 质检工位工艺流程定义
质检工位检测产品质量,合格进入成品库,不合格需要重新加工。质检每个零件消耗2个工时。
In [7]
‘’’
质检工位
‘’’
def test_unit(env, in_store, out_store1, out_store2):
while True:
p = yield in_store.get() #从输入仓库中获取待检测的零部件
yield env.timeout(2) #检测时间流逝,每隔2个单位时间,检测1个零部件
if p.check == “合格”:
if not train:
print(‘%s 在时刻%d检测合格, 检测设备1’ % (p.name, env.now))
out_store1.put§ #把已经检测后的零部件放入输出仓库
else:
if not train:
print(‘%s 在时刻%d检测不合格, 检测设备1’ % (p.name, env.now))
out_store2.put§
2.5 生产系统环境及待优化机械臂工艺流程构建
生产系统环境由生产系统类定义,该类由构造函数、环境重置函数、搬运机械臂工艺流程函数和生产过程步进函数构成。
构造函数初始化生产计划,即生产产品数量和生产工时上限(超时)。
环境重置函数定义了不同工位进出队列,并定义各工位间的流程关系。
搬运机械臂工艺流程函数定义了机械3个不同动作即搬运至加工工位1,搬运至加工工位2以及暂停操作。搬运操作分别消耗8个和5个工时,在训练过程中不向终端输出,仿真时向终端输出操作行为。为了优化每个加工工位进料区原料堆积,设计了机械臂暂停操作的动作。
生产过程步进函数 定义了强化学习智能体对生产环境的观察,即2各加工工位各自进料区的原料数量。定义了强化学习智能体的回报,为了减小加工工时,每个工时消耗回报为-1,为了减小2各尽量去堆积,原料堆积回报为原料总数量×(-0.01),完成产品回报为新增产品书×10,总步进回报为工时消耗回报和原料堆积回报二者相加。如果总生产时间超时,则给出较大惩罚的回报。
In [8]
‘’’
生产系统类
‘’’
class test_ground():
def init(self, num_product, timeout):
self.products = num_product
self.timeOut = timeout
self.action = 0
self.finished = 0
self.reset()
def reset(self):
self.env_plant = Environment(); #生成环境实例
self.store0 = Store(self.env_plant) #生成原料库,待加工零部件的储存队列
self.store1_in = Store(self.env_plant) #生成设备1,加工前的零部件的储存队列
self.store2_in = Store(self.env_plant) #生成设备2,加工前的零部件的储存队列
self.store_out = Store(self.env_plant) ##生成设备2,加工后的零部件的储存队列
self.store3 = Store(self.env_plant) #生成仓库3,检测后的零部件的储存队列
#假设输入仓库中有20个待加工的零部件
for i in range(self.products):
p = Part(self.env_plant, 'part %d' % i) #创建一个待加工零部件实例
self.store0.put(p) #把待加工零部件放入输入仓库
self.env_plant.process(self.manipulator(self.env_plant, self.store0, self.store1_in, self.store2_in))
self.env_plant.process(process_unit1(self.env_plant, self.store1_in, self.store_out))
self.env_plant.process(process_unit2(self.env_plant, self.store2_in, self.store_out))
self.env_plant.process(test_unit(self.env_plant, self.store_out, self.store3, self.store0))
return [len(self.store1_in.items), len(self.store2_in.items), len(self.store_out.items)]
'''
搬运机械臂工位
'''
def manipulator(self, env, in_store, unit1_store, unit2_store):
p = yield in_store.get() #从输入队列中获取待转移的零部件
while True:
if self.action == 2:
yield env.timeout(8) #转移零部件时间流逝,转移效率为每隔5个单位时间,加工1个零部件
p.finished = "已转移至设备1" #设置为已加工
if not train:
print('%s 在时刻%d转移完毕, %s, 搬运臂' % (p.name, env.now, p.finished))
unit1_store.put(p) #把已经加工后的零部件放入输出队列
p = yield in_store.get() #从输入队列中获取待转移的零部件
elif self.action == 1:
yield env.timeout(5) #转移零部件时间流逝,转移效率为每隔5个单位时间,加工1个零部件
p.finished = "已转移至设备2" #设置为已加工
if not train:
print('%s 在时刻%d转移完毕, %s, 搬运臂' % (p.name, env.now, p.finished))
unit2_store.put(p) #把已经加工后的零部件放入输出队列
p = yield in_store.get() #从输入队列中获取待转移的零部件
else:
yield env.timeout(1)
def step(self, action):
self.action = action
self.env_plant.step()
obs = [len(self.store1_in.items), len(self.store2_in.items), len(self.store_out.items)]
reward = -1.0-0.01*(len(self.store1_in.items)+len(self.store2_in.items))+(len(self.store3.items)-self.finished)*10
self.finished = len(self.store3.items)
#生产订单完成或超时,生产结束
if len(self.store3.items) == self.products or self.env_plant.now > self.timeOut:
done = True
if self.env_plant.now > self.timeOut:
reward = -self.env_plant.now #生产超时获得较大惩罚
else:
done = False
return obs, reward, done
3.强化学习系统构建
本项目采用Parl强化学习库,Parl将强化学习系统拆解为模型、算法、智能体三个不同模块,方便了强化学习系统的构建。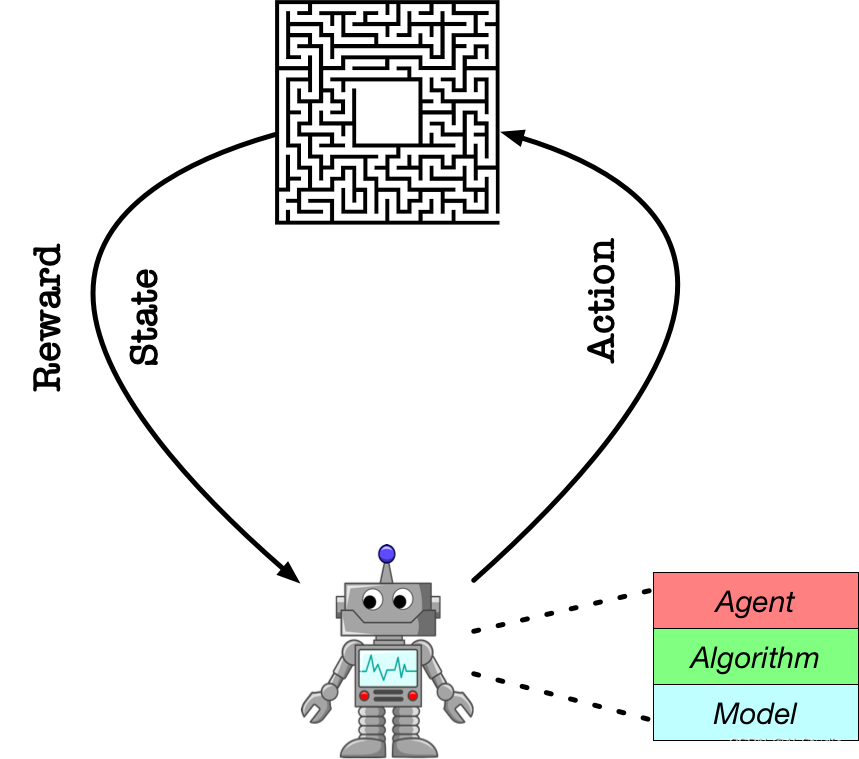
本项目DQN强化学习部分参考自“强化学习7日打卡营-世界冠军带你从零实践”系列课程。 https://aistudio.baidu.com/aistudio/education/group/info/1335
3.1 构建DQN网络模型
主要定义前向网络,这通常是一个策略网络(Policy Network)或者一个值函数网络(Value Function),输入是当前环境状态(State)。
首先,构建一个包含3个全连接层的前向网络。
定义前向网络的主要三个步骤:
继承 parl.Model 类
构造函数 init 中声明要用到的中间层
在 forward 函数中搭建网络
先在构造函数中声明了两个全连接层,然后在 forward 函数中定义了网络的前向计算方式:输入一个状态,然后经过第一层FC和ReLU激活函数,第二层FC和tanh激活函数,第三层FC和softmax激活函数,得到了每个action的概率分布预测。
In [16]
import parl
import paddle.nn as nn
import paddle.nn.functional as F
class Model(parl.Model):
def init(self, obs_dim, act_dim):
super(Model, self).init()
hid1_size = obs_dim10
hid2_size = act_dim10
# 3层全连接网络
self.fc1 = nn.Linear(obs_dim, hid1_size)
self.fc2 = nn.Linear(hid1_size, hid2_size)
self.fc3 = nn.Linear(hid2_size, act_dim)
def forward(self, obs):
h1 = F.relu(self.fc1(obs))
h2 = F.tanh(self.fc2(h1))
Q = F.softmax(self.fc3(h2), axis=-1)
return Q
3.2 经验回放模块
由于强化学习没有供神经网络训练的样本,经验回放模块设置经验池作为训练神经网络的样本。
经验池:用于存储多条经验,实现经验回放。
In [17]
import random
import collections
import numpy as np
class ReplayMemory(object):
def init(self, max_size):
self.buffer = collections.deque(maxlen=max_size)
def append(self, exp):
self.buffer.append(exp)
def sample(self, batch_size):
mini_batch = random.sample(self.buffer, batch_size)
obs_batch, action_batch, reward_batch, next_obs_batch, done_batch = [], [], [], [], []
for experience in mini_batch:
s, a, r, s_p, done = experience
obs_batch.append(s)
action_batch.append(a)
reward_batch.append(r)
next_obs_batch.append(s_p)
done_batch.append(done)
return np.array(obs_batch).astype('float32'), \
np.array(action_batch).astype('float32'), np.array(reward_batch).astype('float32'),\
np.array(next_obs_batch).astype('float32'), np.array(done_batch).astype('float32')
def __len__(self):
return len(self.buffer)
3.3 算法模块
算法模块用于定义神经网络更新、损失函数、Q-Learning更新等训练过程等相关算法。 Algorithm 定义了具体的算法来更新前向网络(Model),也就是通过定义损失函数来更新Model,和算法相关的计算都放在algorithm中。构建算法,需要继承类 parl.Algorithm,并实现两个基本函数: predict 和 learn
learn : 根据训练数据(观测量和输入的reward),定义损失函数,用于更新 Model 中的参数。
predict : 根据当前的观测量,给出动作概率分布或者Q函数的预估值。
本项目采用DQN算法。
在构造函数__init__(self, model, act_dim=None, gamma=None, lr=None)中定义 DQN的 self.model 和 self.target_model , 同时,在该函数中定义超参数 gamma 以及 lr 。 这些超参数在 learn 函数中会被用到 。
predict(self, obs) 中直接使用输入该函数的环境状态,并将该状态传输入 self.model 中,self.model 会输出预测的action value function
sync_target(self)函数同步 self.target_model 和 self.model 中的参数
In [18]
import copy
import paddle
import parl
from parl.utils.utils import check_model_method
all = [‘DQN’]
class DQN(parl.Algorithm):
def init(self, model, act_dim=None, gamma=None, lr=None):
“”" DQN algorithm
Args:
model (parl.Model): 定义Q函数的前向网络结构
act_dim (int): action空间的维度,即有几个action
gamma (float): reward的衰减因子
lr (float): learning_rate,学习率.
"""
self.model = model
self.target_model = copy.deepcopy(model)
check_model_method(model, 'forward', self.__class__.__name__)
assert isinstance(act_dim, int)
assert isinstance(gamma, float)
assert isinstance(lr, float)
self.act_dim = act_dim
self.gamma = gamma
self.lr = lr
self.mse_loss = paddle.nn.MSELoss(reduction='mean')
self.optimizer = paddle.optimizer.Adam(
learning_rate=lr, parameters=self.model.parameters())
def predict(self, obs):
""" 使用self.model的value网络来获取 [Q(s,a1),Q(s,a2),...]
"""
return self.model(obs)
def learn(self, obs, action, reward, next_obs, terminal):
""" 使用DQN算法更新self.model的value网络
"""
pred_values = self.model(obs) # 获取Q预测值
# 将action转onehot向量,比如:3 => [0,0,0,1,0]
action = paddle.squeeze(action, axis=-1)
action_onehot = paddle.nn.functional.one_hot(
action, num_classes=self.act_dim)
# 下面一行是逐元素相乘,拿到action对应的 Q(s,a)
# 比如:pred_value = [[2.3, 5.7, 1.2, 3.9, 1.4]], action_onehot = [[0,0,0,1,0]]
# ==> pred_action_value = [[3.9]]
pred_value = pred_values * action_onehot
pred_value = paddle.sum(pred_value, axis=1, keepdim=True)
# 从target_model中获取 max Q' 的值,用于计算target_Q
with paddle.no_grad(): # 阻止梯度传递
max_v = self.target_model(next_obs).max(1, keepdim=True)
target = reward + (1 - terminal) * self.gamma * max_v
# 计算 Q(s,a) 与 target_Q的均方差,得到loss
loss = self.mse_loss(pred_value, target)
self.optimizer.clear_grad()
loss.backward()
self.optimizer.step()
return loss
def sync_target(self):
""" 把 self.model 的模型参数值同步到 self.target_model
"""
self.model.sync_weights_to(self.target_model)
3.4 智能体模块
智能体 (Agent )负责算法与环境的交互,在交互过程中把生成的数据提供给算法模块(Algorithm)来更新模型(Model),数据的预处理流程也一般定义在这里。
init :把前面定义好的algorithm传进来,作为agent的一个成员变量,用于后续的数据交互。需要注意的是,这里必须得要初始化父类:super(CartpoleAgent, self).init(algorithm) 。
predict :根据环境状态返回预测动作(action),一般用于评估和部署agent。
sample :根据环境状态返回动作(action),一般用于训练时候采样action进行探索。
learn : 根据训练数据(观测量和输入的reward),定义损失函数,用于更新 Model 中的参数。
In [19]
import numpy as np
import parl
import paddle
class Agent(parl.Agent):
def init(self,
algorithm,
obs_dim,
act_dim,
e_greed=0.1,
e_greed_decrement=0):
assert isinstance(obs_dim, int)
assert isinstance(act_dim, int)
self.obs_dim = obs_dim
self.act_dim = act_dim
super(Agent, self).init(algorithm)
self.global_step = 0
self.update_target_steps = 200 # 每隔200个training steps再把model的参数复制到target_model中
self.e_greed = e_greed # 有一定概率随机选取动作,探索
self.e_greed_decrement = e_greed_decrement # 随着训练逐步收敛,探索的程度慢慢降低
def sample(self, obs):
sample = np.random.rand() # 产生0~1之间的小数
if sample < self.e_greed:
act = np.random.randint(self.act_dim) # 探索:每个动作都有概率被选择
else:
act = self.predict(obs) # 选择最优动作
self.e_greed = max(
0.01, self.e_greed - self.e_greed_decrement) # 随着训练逐步收敛,探索的程度慢慢降低
return act
def predict(self, obs): # 选择最优动作
obs = paddle.to_tensor(obs, dtype='float32')
pred_q = self.alg.predict(obs)
act = pred_q.argmax().numpy()[0] # 选择Q最大的下标,即对应的动作
return act
def learn(self, obs, act, reward, next_obs, terminal):
# 每隔200个training steps同步一次model和target_model的参数
if self.global_step % self.update_target_steps == 0:
self.alg.sync_target()
self.global_step += 1
act = np.expand_dims(act, axis=-1)
reward = np.expand_dims(reward, axis=-1)
terminal = np.expand_dims(terminal, axis=-1)
obs = paddle.to_tensor(obs, dtype='float32')
act = paddle.to_tensor(act, dtype='int32')
reward = paddle.to_tensor(reward, dtype='float32')
next_obs = paddle.to_tensor(next_obs, dtype='float32')
terminal = paddle.to_tensor(terminal, dtype='float32')
loss = self.alg.learn(obs, act, reward, next_obs, terminal) # 训练一次网络
return loss.numpy()[0]
4 强化学习训练及验证
4.1 训练
创建环境和Agent,创建经验池,启动训练,保存模型
In [25]
import os
import numpy as np
import parl
from parl.utils import logger # 日志打印工具
LEARN_FREQ = 5 # 训练频率,不需要每一个step都learn,攒一些新增经验后再learn,提高效率
MEMORY_SIZE = 2000 # replay memory的大小,越大越占用内存
MEMORY_WARMUP_SIZE = 200 # replay_memory 里需要预存一些经验数据,再从里面sample一个batch的经验让agent去learn
BATCH_SIZE = 32 # 每次给agent learn的数据数量,从replay memory随机里sample一批数据出来
LEARNING_RATE = 0.001 # 学习率
GAMMA = 0.99 # reward 的衰减因子,一般取 0.9 到 0.999 不等
train = True
训练一个episode
def run_episode(env, agent, rpm):
total_reward = 0
obs = env.reset()
step = 0
while True:
step += 1
action = agent.sample(obs) # 采样动作,所有动作都有概率被尝试到
next_obs, reward, done = env.step(action)
rpm.append((obs, action, reward, next_obs, done))
# train model
if (len(rpm) > MEMORY_WARMUP_SIZE) and (step % LEARN_FREQ == 0):
(batch_obs, batch_action, batch_reward, batch_next_obs,
batch_done) = rpm.sample(BATCH_SIZE)
train_loss = agent.learn(batch_obs, batch_action, batch_reward,
batch_next_obs,
batch_done) # s,a,r,s',done
total_reward += reward
obs = next_obs
if done:
break
return total_reward
评估 agent, 跑 10 个episode,总reward求平均
def evaluate(env, agent, render=False):
eval_reward = []
for i in range(10):
obs = env.reset()
episode_reward = 0
while True:
action = agent.predict(obs) # 预测动作,只选最优动作
obs, reward, done = env.step(action)
episode_reward += reward
if done:
break
eval_reward.append(episode_reward)
return np.mean(eval_reward)
def main():
env = test_ground(num_product = 20, timeout = 1000) # 生产100件产品订单的生产环境
obs_Dim = 3
action_dim = 3
rpm = ReplayMemory(MEMORY_SIZE) # DQN的经验回放池
# 根据parl框架构建agent
model = Model(obs_dim=obs_Dim, act_dim=action_dim)
algorithm = DQN(model, act_dim=action_dim, gamma=GAMMA, lr=LEARNING_RATE)
agent = Agent(
algorithm,
obs_dim=obs_Dim,
act_dim=action_dim,
e_greed=0.5, # 有一定概率随机选取动作,探索
e_greed_decrement=1e-6) # 随着训练逐步收敛,探索的程度慢慢降低
# #加载模型
save_path = './dqn_model.ckpt'
agent.restore(save_path)
# 先往经验池里存一些数据,避免最开始训练的时候样本丰富度不够
while len(rpm) < MEMORY_WARMUP_SIZE:
run_episode(env, agent, rpm)
max_episode = 2000
# start train
episode = 0
best = -10000
while episode < max_episode: # 训练max_episode个回合,test部分不计算入episode数量
# train part
for i in range(0, 50):
total_reward = run_episode(env, agent, rpm)
episode += 1
# test part
eval_reward = evaluate(env, agent)
logger.info('episode:{} e_greed:{} Test reward:{}'.format(
episode, agent.e_greed, eval_reward))
# 保存最好模型
if eval_reward>best:
save_path = './dqn_model.ckpt'
agent.save(save_path)
best = eval_reward
if name == ‘main’:
main()
[06-23 12:09:49 MainThread @2114402826.py:100] episode:50 e_greed:0.4833050000004467 Test reward:-299.716999999999
[06-23 12:10:12 MainThread @2114402826.py:100] episode:100 e_greed:0.4674040000008721 Test reward:-2106.0
[06-23 12:10:29 MainThread @2114402826.py:100] episode:150 e_greed:0.4513970000013004 Test reward:-290.008999999999
[06-23 12:10:51 MainThread @2114402826.py:100] episode:200 e_greed:0.43503200000173825 Test reward:-2106.0
[06-23 12:11:14 MainThread @2114402826.py:100] episode:250 e_greed:0.4190180000021667 Test reward:-2106.0
[06-23 12:11:32 MainThread @2114402826.py:100] episode:300 e_greed:0.402712000002603 Test reward:-336.04199999999855
[06-23 12:11:50 MainThread @2114402826.py:100] episode:350 e_greed:0.3861580000030459 Test reward:-304.8039999999972
[06-23 12:12:09 MainThread @2114402826.py:100] episode:400 e_greed:0.37009600000347564 Test reward:-325.25499999999965
[06-23 12:12:28 MainThread @2114402826.py:100] episode:450 e_greed:0.353786000003912 Test reward:-329.1619999999988
[06-23 12:12:46 MainThread @2114402826.py:100] episode:500 e_greed:0.3373980000043505 Test reward:-302.79199999999895
[06-23 12:13:04 MainThread @2114402826.py:100] episode:550 e_greed:0.32095800000479036 Test reward:-298.3449999999991
[06-23 12:13:22 MainThread @2114402826.py:100] episode:600 e_greed:0.3052170000052115 Test reward:-353.94699999999847
[06-23 12:13:43 MainThread @2114402826.py:100] episode:650 e_greed:0.2884740000056595 Test reward:-360.5589999999984
[06-23 12:14:02 MainThread @2114402826.py:100] episode:700 e_greed:0.2720620000060986 Test reward:-302.21099999999757
[06-23 12:14:22 MainThread @2114402826.py:100] episode:750 e_greed:0.2555500000065404 Test reward:-338.88699999999847
[06-23 12:14:43 MainThread @2114402826.py:100] episode:800 e_greed:0.23928100000667815 Test reward:-336.1169999999985
[06-23 12:15:04 MainThread @2114402826.py:100] episode:850 e_greed:0.22236000000666123 Test reward:-389.468999999999
[06-23 12:15:25 MainThread @2114402826.py:100] episode:900 e_greed:0.20556600000664443 Test reward:-349.14099999999854
[06-23 12:15:44 MainThread @2114402826.py:100] episode:950 e_greed:0.18960500000662847 Test reward:-297.5409999999997
[06-23 12:16:07 MainThread @2114402826.py:100] episode:1000 e_greed:0.17231600000661118 Test reward:-348.1919999999985
[06-23 12:16:28 MainThread @2114402826.py:100] episode:1050 e_greed:0.15585200000659472 Test reward:-387.349999999999
[06-23 12:16:49 MainThread @2114402826.py:100] episode:1100 e_greed:0.13888600000657775 Test reward:-291.6479999999991
[06-23 12:17:17 MainThread @2114402826.py:100] episode:1150 e_greed:0.12127600000656014 Test reward:-2106.0
[06-23 12:17:39 MainThread @2114402826.py:100] episode:1200 e_greed:0.10401900000654288 Test reward:-363.9729999999984
[06-23 12:18:01 MainThread @2114402826.py:100] episode:1250 e_greed:0.086143000006525 Test reward:-334.81299999999953
[06-23 12:18:25 MainThread @2114402826.py:100] episode:1300 e_greed:0.06840500000650726 Test reward:-339.90399999999846
[06-23 12:18:49 MainThread @2114402826.py:100] episode:1350 e_greed:0.04972800000648858 Test reward:-297.81899999999894
[06-23 12:19:16 MainThread @2114402826.py:100] episode:1400 e_greed:0.029612000006468464 Test reward:-299.933999999999
[06-23 12:19:42 MainThread @2114402826.py:100] episode:1450 e_greed:0.011230000006457705 Test reward:-336.3489999999987
[06-23 12:20:08 MainThread @2114402826.py:100] episode:1500 e_greed:0.01 Test reward:-293.95299999999907
[06-23 12:20:35 MainThread @2114402826.py:100] episode:1550 e_greed:0.01 Test reward:-296.00599999999895
[06-23 12:21:03 MainThread @2114402826.py:100] episode:1600 e_greed:0.01 Test reward:-360.6399999999986
[06-23 12:21:32 MainThread @2114402826.py:100] episode:1650 e_greed:0.01 Test reward:-346.1389999999984
[06-23 12:22:00 MainThread @2114402826.py:100] episode:1700 e_greed:0.01 Test reward:-294.03699999999907
[06-23 12:22:25 MainThread @2114402826.py:100] episode:1750 e_greed:0.01 Test reward:-296.876999999999
[06-23 12:22:52 MainThread @2114402826.py:100] episode:1800 e_greed:0.01 Test reward:-392.0649999999992
[06-23 12:23:24 MainThread @2114402826.py:100] episode:1850 e_greed:0.01 Test reward:-2106.0
[06-23 12:23:49 MainThread @2114402826.py:100] episode:1900 e_greed:0.01 Test reward:-351.9779999999984
[06-23 12:24:20 MainThread @2114402826.py:100] episode:1950 e_greed:0.01 Test reward:-335.3259999999964
[06-23 12:24:46 MainThread @2114402826.py:100] episode:2000 e_greed:0.01 Test reward:-349.9309999999988
4.2 生产仿真验证
加载训练后DQN模型,进行生产仿真。
In [26]
obs_dim = 3
action_dim = 3
rpm = ReplayMemory(MEMORY_SIZE) # DQN的经验回放池
根据parl框架构建agent
model = Model(obs_dim=obs_dim, act_dim=action_dim)
algorithm = DQN(model, act_dim=action_dim, gamma=GAMMA, lr=LEARNING_RATE)
agent = Agent(
algorithm,
obs_dim=obs_dim,
act_dim=action_dim,
e_greed=0.1, # 有一定概率随机选取动作,探索
e_greed_decrement=1e-6) # 随着训练逐步收敛,探索的程度慢慢降低
#加载模型
save_path = ‘./dqn_model.ckpt’
agent.restore(save_path)
env = test_ground(num_product = 10, timeout = 10000) # 生产10件产品订单的生产环境
obs = env.reset()
train = False
while True:
action = agent.predict(obs) # 预测动作,只选最优动作
obs, reward, done = env.step(action)
if done:
break
part 0 在时刻5转移完毕, 已转移至设备2, 搬运臂
part 1 在时刻10转移完毕, 已转移至设备2, 搬运臂
part 2 在时刻15转移完毕, 已转移至设备2, 搬运臂
part 3 在时刻20转移完毕, 已转移至设备2, 搬运臂
part 0 在时刻25加工完毕, 加工设备2
part 4 在时刻25转移完毕, 已转移至设备2, 搬运臂
part 0 在时刻27检测合格, 检测设备1
part 5 在时刻30转移完毕, 已转移至设备2, 搬运臂
part 6 在时刻35转移完毕, 已转移至设备2, 搬运臂
part 7 在时刻40转移完毕, 已转移至设备2, 搬运臂
part 1 在时刻45加工完毕, 加工设备2
part 8 在时刻45转移完毕, 已转移至设备2, 搬运臂
part 1 在时刻47检测合格, 检测设备1
part 9 在时刻50转移完毕, 已转移至设备2, 搬运臂
part 2 在时刻65加工完毕, 加工设备2
part 2 在时刻67检测合格, 检测设备1
part 3 在时刻85加工完毕, 加工设备2
part 3 在时刻87检测合格, 检测设备1
part 4 在时刻105加工完毕, 加工设备2
part 4 在时刻107检测合格, 检测设备1
part 5 在时刻125加工完毕, 加工设备2
part 5 在时刻127检测合格, 检测设备1
part 6 在时刻145加工完毕, 加工设备2
part 6 在时刻147检测不合格, 检测设备1
part 6 在时刻152转移完毕, 已转移至设备2, 搬运臂
part 7 在时刻165加工完毕, 加工设备2
part 7 在时刻167检测不合格, 检测设备1
part 7 在时刻172转移完毕, 已转移至设备2, 搬运臂
part 8 在时刻185加工完毕, 加工设备2
part 8 在时刻187检测合格, 检测设备1
part 9 在时刻205加工完毕, 加工设备2
part 9 在时刻207检测合格, 检测设备1
part 6 在时刻225加工完毕, 加工设备2
part 6 在时刻227检测合格, 检测设备1
part 7 在时刻245加工完毕, 加工设备2
part 7 在时刻247检测合格, 检测设备1
5. 项目总结
本项目通过simpy库构建了简单的离散制造生产系统,通过Parl库以DQN强化学习方法对该生产系统中搬运机械臂的工艺流程进行了优化,初步实现了应用强化学习优化制造系统生产流程。由于时间匆忙智能体与环境交互的观测信息、回报函数的定义仍有进一步优化空间,DQN训练的参数设置也有不足。望抛砖引玉,为强化学习应用于制造业提供一定参考。
学员与导师简介
学员:董绪斌 工学博士 北华大学机械工程学院 智能制造专业教师
导师:陆平 个人主页:https://aistudio.baidu.com/aistudio/personalcenter/thirdview/379381
感谢陆平老师在项目实现中提供的指导意见!

学大模型,用大模型上飞桨星河社区!每天8点V100G算力免费领!免费领取ERNIE 4.0 100w Token >>>
更多推荐



 0
0 0
0- 0



 已为社区贡献1437条内容
已为社区贡献1437条内容

所有评论(0)