
基于飞桨的中文多领域任务型对话系统
项目基于NEZHA-base预训练模型和CrossWOZ数据集,采用意图识别模块、二分类slot识别模块和NER识别模块做DST,基于规则生成回复。
完整代码链接:https://github.com/cyberfish1120/PaddleTDS
Colab链接:https://drive.google.com/drive/folders/1xaW472DaLdA7OjwXQzUnm0qs-M9FEqo
视频链接:https://www.bilibili.com/video/BV1Yb4y1r7JV
项目背景
互联网的发展给人们的生活带来了诸多便利,随之而来的是人工智能技术逐渐应用于人们生活中的方方面面,对话系统作为人工智能技术的一大体现,在人们生活中,传统的机械式对话系统已经不能满足人类自然交互的要求,因此大规模的自然人机交互需求被极大的激发出来,微软首席执行官萨提亚纳德拉在微软的Build2016开发者大会上提出“对话即平台”的概念,认为对话是给人工智能带来颠覆性的下一代革命,更是推动人工智能领域改革的一剂兴奋剂,手机助手,问答系统,智能聊天机器人等对话系统如雨后春笋一般涌现出来,人机对话系统产业的蓬勃发展展现了人机对话广泛的应用价值。
环境要求
- python=3.6
- paddlepaddle-gpu=2.1.1post101
- paddlnlp=2.0
预训练权重下载地址
-
百度网盘链接:https://pan.baidu.com/s/17fCpfkQodHvQEOLinrkG-Q
-
提取码:hg3r
-
备用权重
- 百度网盘:https://pan.baidu.com/s/1zqM70hUM8TaLDW0q0-pZ9w
- 提取码:57sp
模块与框架
整个任务型对话系统主要由五个模块组成:对话状态追踪模块、对话状态决策模块、数据库查询模块、对话回复模块、网页前端模块
对话状态追踪模块
对话状态追踪模块由三个子模块组成:意图识别模块、二分类Slot识别模块、Span Slot抽取模块
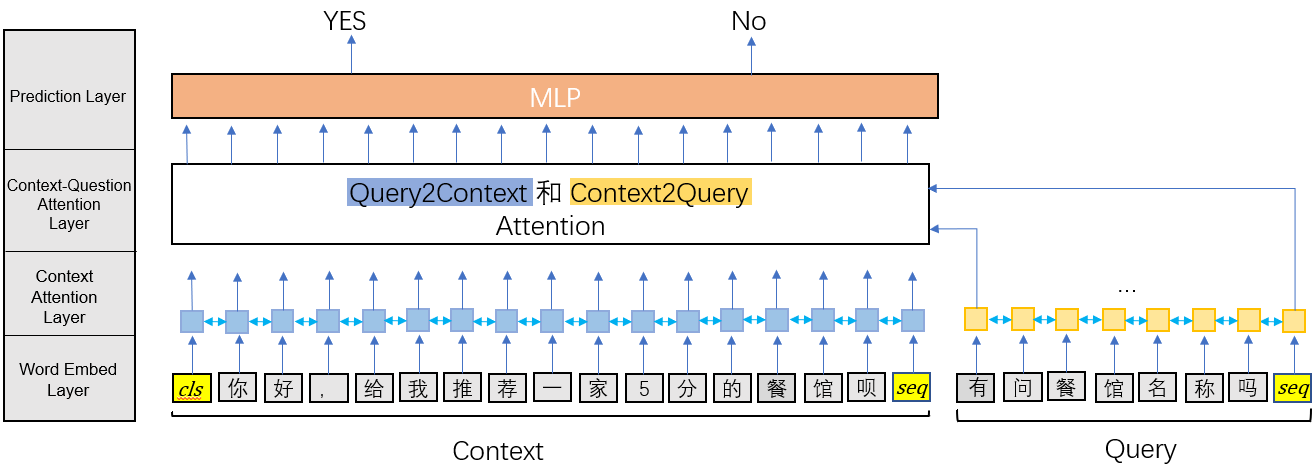
意图识别模块
# --- coding:utf-8 ---
# author: Cyberfish time:2021/7/22
import paddle
from paddle import set_device, get_device
from intent_code.intent_utils import model, utils_fn
from paddlenlp.transformers import NeZhaTokenizer
ner_label2id, ner_id2label, bi_label2id, id2bi_label, slots2id, id2slots, slots = utils_fn.label_process('data/slots.txt')
class IntentPredict():
def __init__(self):
self.intent_model = model.IntentModel()
self.intent_model.to(set_device(get_device()))
intent_state_dict = paddle.load('weight/intent_model.state')
self.intent_model.set_state_dict(intent_state_dict)
self.tokenizer = NeZhaTokenizer.from_pretrained('nezha-base-wwm-chinese')
def intent_predict(self, content):
contents = []
for slot in slots:
contents.append([content, '有在问' + slot + '吗?'])
embedding = self.tokenizer.batch_encode(contents,
max_seq_len=128,
pad_to_max_seq_len=True
)
input_ids, token_type_ids = paddle.to_tensor([i['input_ids'] for i in embedding]), \
paddle.to_tensor([i['token_type_ids'] for i in embedding])
intent_pred = self.intent_model(input_ids, token_type_ids)
y_pred = paddle.argmax(intent_pred, 1).numpy()
intents = []
for i, label in enumerate(y_pred):
if label == 1:
intents.append(id2slots[i])
return intents
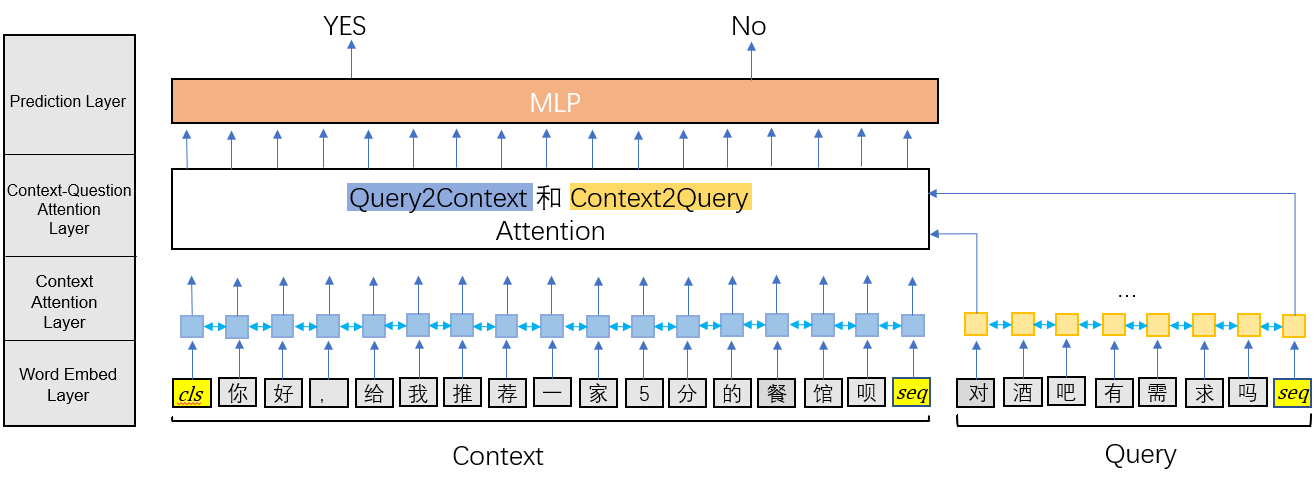
二分类Slot识别模块
# --- coding:utf-8 ---
# author: Cyberfish time:2021/7/22
import paddle
from paddle import set_device, get_device
from biclass_code.bi_utils import model, utils_fn
from paddlenlp.transformers import NeZhaTokenizer
ner_label2id, ner_id2label, bi_label2id, id2bi_label, slots2id, id2slots, slots = utils_fn.label_process('data/slots.txt')
class BiPredict():
def __init__(self):
self.bi_model = model.BiModel()
self.bi_model.to(set_device(get_device()))
bi_state_dict = paddle.load('weight/bi_model.state')
self.bi_model.set_state_dict(bi_state_dict)
self.tokenizer = NeZhaTokenizer.from_pretrained('nezha-base-wwm-chinese')
def bi_predict(self, content):
contents = []
for slot in bi_label2id:
contents.append([content, '对' + slot + '有要求吗?'])
embedding = self.tokenizer.batch_encode(contents,
max_seq_len=128,
pad_to_max_seq_len=True
)
input_ids, token_type_ids = paddle.to_tensor([i['input_ids'] for i in embedding]), \
paddle.to_tensor([i['token_type_ids'] for i in embedding])
bi_pred = self.bi_model(input_ids, token_type_ids)
y_pred = paddle.argmax(bi_pred, 1).numpy()
bis = []
for i, label in enumerate(y_pred):
if label == 1:
bis.append(id2bi_label[i])
return bis
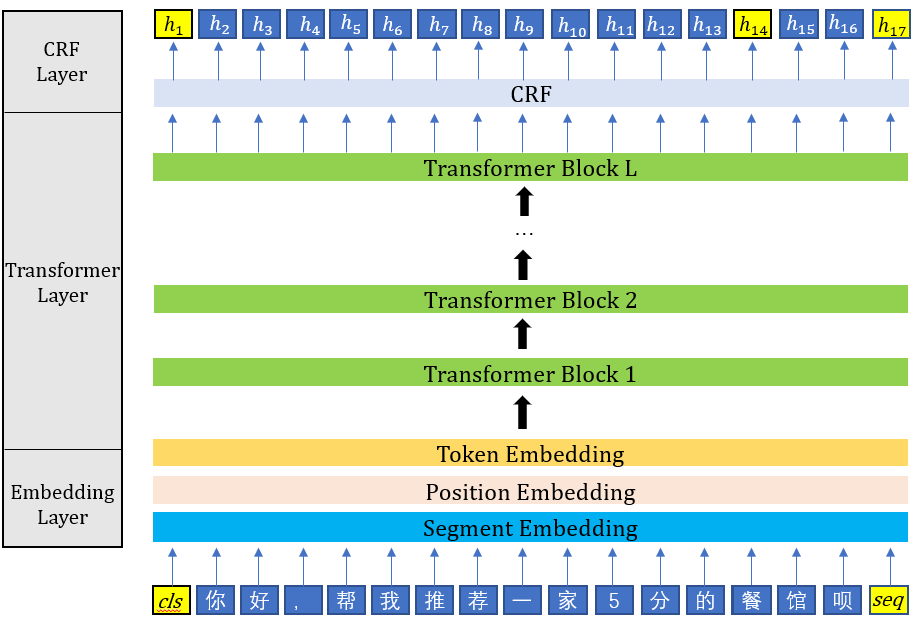
Span Slot抽取模块
# --- coding:utf-8 ---
# author: Cyberfish time:2021/7/22
import paddle
from paddle import set_device, get_device
from ner_code.ner_utils import model, utils_fn
from paddlenlp.transformers import NeZhaTokenizer
ner_label2id, ner_id2label, bi_label2id, id2bi_label, slots2id, id2slots, slots = utils_fn.label_process('data/slots.txt')
class NerPredict():
def __init__(self):
self.ner_model = model.NerModel()
self.ner_model.to(set_device(get_device()))
ner_state_dict = paddle.load('weight/ner_model.state')
self.ner_model.set_state_dict(ner_state_dict)
self.tokenizer = NeZhaTokenizer.from_pretrained('nezha-base-wwm-chinese')
def ner_predict(self, content):
content = [c for c in content]
input_ids = paddle.to_tensor([self.tokenizer(content, is_split_into_words=True)['input_ids']])
lens = paddle.to_tensor(len(content))
_, pred = self.ner_model(input_ids, lens)
entities = []
entity = ''
for content, label in zip(content, pred[0]):
label = int(label)
if label == 0:
if entity:
entities.append(entity)
entity = ''
else:
continue
else:
if label % 2 == 1:
if entity:
entities.append(entity)
entity = ner_id2label[label].split('_')[1] + '\t' + content
else:
if entity:
entity += content
else:
continue
return entities
对话回复模块
# --- coding:utf-8 ---
# author: Cyberfish time:2021/7/23
def rule_response(content, intents, database, DST):
greet, thank, bye = '', '', ''
responds = set()
if len(intents) == 0:
return '实在是不好意思,我没听懂您想问啥,抱歉!', DST
for intent in intents:
if intent == 'greet-none':
greet = '你好!'
elif intent == 'thank-none':
thank = '不用客气!'
elif intent == 'bye-none':
bye = '再见!'
else:
responds.add(database.database_return(content, intent, DST))
if responds:
sequence = greet + thank + ';'.join(responds) + bye + '。'
if sequence[-2] == '?':
sequence = sequence[:-1]
else:
sequence = greet + thank + bye
return sequence, DST
整体思路
在得到用户的输入对话(如:你好,可以帮我安排一个人均消费100-150元,评分4.5分以上的餐馆吗?)后,意图识别模块和二分类slot识别模块将识别任务转为QA任务。将用户输入看作文档信息,构造“有在问{intent}吗?”或“对{bi_slot}有要求吗?”当作问题,然后将文档信息和问题做embedding和Attention进行二分类。这样做的一个好处就是当用户的输入对话包含多个意图或者多个二分类slot时,QA模型是有能力全部识别出来的,而分类模型则做不到这一点。
对话span slot识别模块采用命名实体识别(NER)技术,模型架构为Transformer+CRF,不仅在测试集上取得98.56%的不错F1,将span类型的slot识别时间复杂度从O(n)下降至O(1),大幅降低了模型的推理时间,而且还能处理OOV情形。
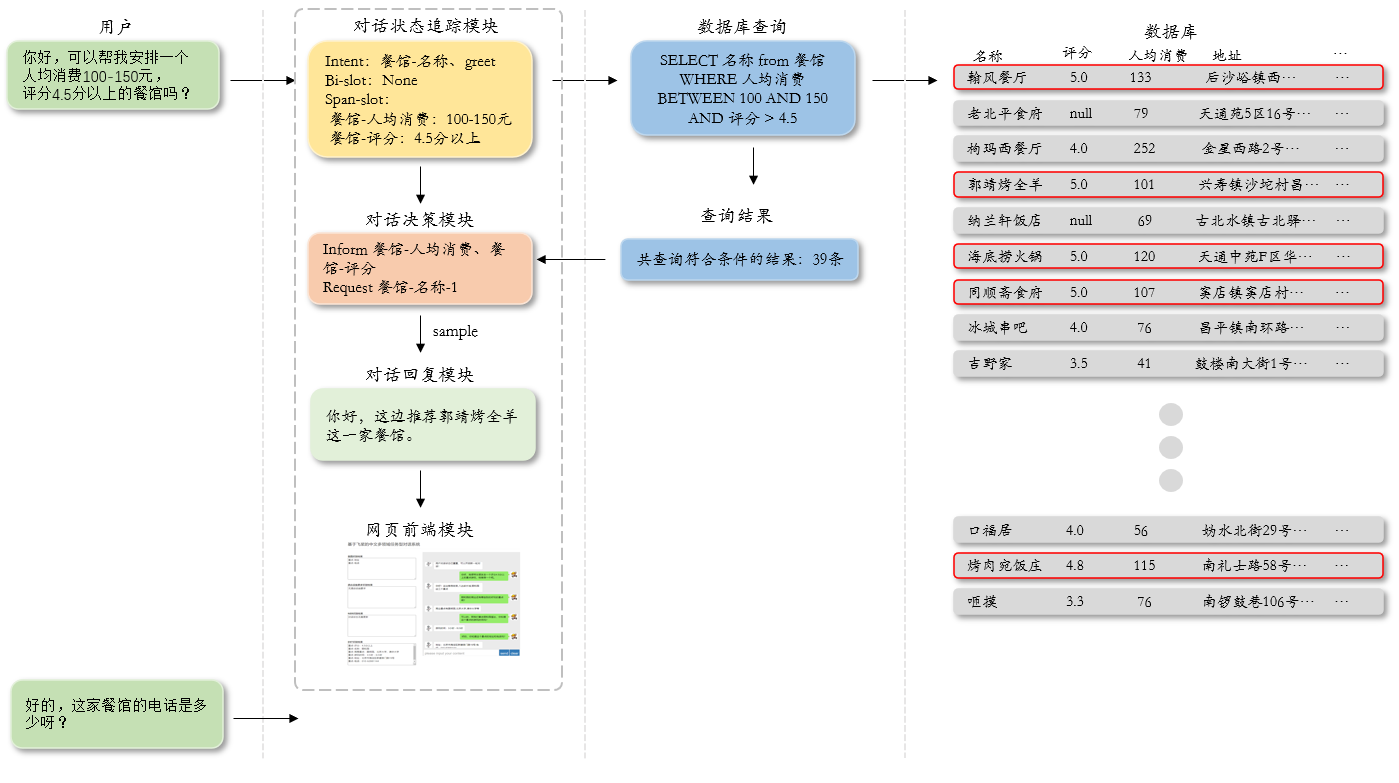
在得到意图识别结果和对话状态后,系统会将这些约束信息传给数据库模块来查询符合条件的结果,最后将查询结果传给决策模块和回复模块来生成用户回复。下图为系统的整体框架图:
运行系统
# --- coding:utf-8 ---
# author: Cyberfish time:2021/7/23
from ner_code.predict import NerPredict
from intent_code.predict import IntentPredict
from biclass_code.predict import BiPredict
from database_code.database_main import DataBase
from agent import Agent
from collections import defaultdict
intent_predict = IntentPredict()
bi_predict = BiPredict()
ner_predict = NerPredict()
database = DataBase()
agent = Agent(intent_predict, bi_predict, ner_predict, database)
while True:
content = input('请输入内容: ')
if content == 'clear':
agent.DST = defaultdict(set)
print('已重置用户对话状态')
else:
agent.response(content)
e:
content = input('请输入内容: ')
if content == 'clear':
agent.DST = defaultdict(set)
print('已重置用户对话状态')
else:
agent.response(content)
最终效果
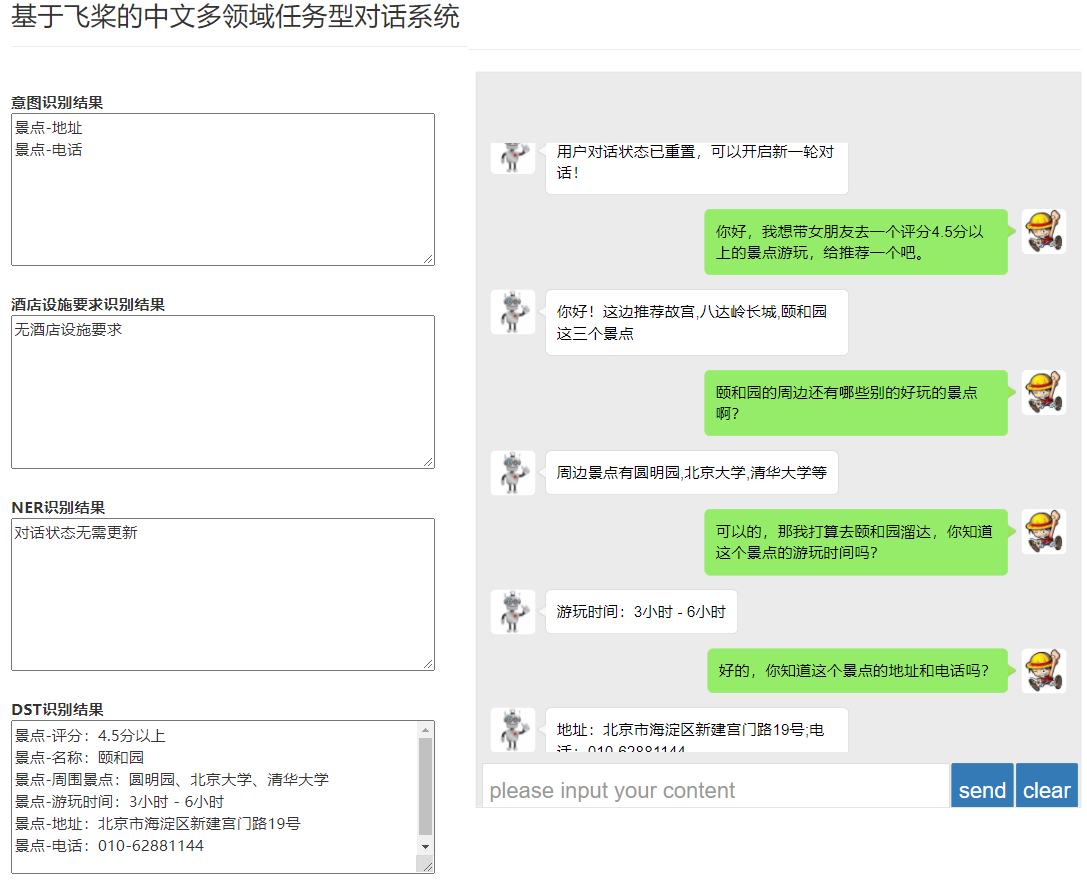
总结
基于飞桨的中文多领域任务型对话系统PaddleTDS将自然语言理解模块和对话状态追踪模块合并成一个模块以较少传播误差。在对话状态追踪模块中将Slot的预测分为分类Slot和Span Slot,不仅使得大部分Slot的预测时间从O(n)降至O(1),大附降低了对话状态追踪(DST)的时间与算力消耗,而且能处理Out of Values(OOV)的情形,增强了整个模型的鲁棒性。

学大模型,用大模型上飞桨星河社区!每天8点V100G算力免费领!免费领取ERNIE 4.0 100w Token >>>
更多推荐



 1
1 0
0- 0



 已为社区贡献1436条内容
已为社区贡献1436条内容

所有评论(0)