
Serf:使用Log-Softplus误差激活函数更好地训练深度神经网络
激活函数在决定训练动态和神经网络性能方面起着至关重要的作用。被广泛采用的激活函数ReLU虽然简单有效,但仍存在一些缺点,包括濒死的ReLU问题。为了解决这些问题,我们提出了一种新的自正则的非单调激活函数Serf。和Mish一样,Serf也属于Swish函数家族。在基于Serf的不同先进架构在计算机视觉(图像分类和目标检测)和自然语言处理(机器翻译、情感分类和多模态隐含)等任务的实验上,观察到Ser

摘要
激活函数在决定训练动态和神经网络性能方面起着至关重要的作用。被广泛采用的激活函数ReLU虽然简单有效,但仍存在一些缺点,包括濒死的ReLU问题。为了解决这些问题,我们提出了一种新的自正则的非单调激活函数Serf。和Mish一样,Serf也属于Swish函数家族。在基于Serf的不同先进架构在计算机视觉(图像分类和目标检测)和自然语言处理(机器翻译、情感分类和多模态隐含)等任务的实验上,观察到Serf在ReLU(基线)和其他激活功能(包括Swish和Mish)上的表现大大优于前者,在更深层次的架构上有明显更大的优势。消融研究进一步证明,基于Serf的架构在不同的场景下比Swish和Mish的架构表现更好,验证了Serf在不同深度、复杂性、优化器、学习率、批处理大小、初始化和Dropout下的有效性和兼容性。最后,我们研究了Swish和Serf之间的数学关系,从而展示了根植于Serf一阶导数中的预处理函数的影响,它提供了一种正则化效应,使梯度更平滑,优化速度更快。
1. Serf
1.1 Serf介绍
激活函数在神经网络中引入了非线性,它们对网络的整体性能起着非常重要的作用。ReLU是神经网络中应用最广泛的激活函数。然而,它有一些缺点,最明显的一个是死亡ReLU现象。这个问题源于ReLU激活函数中缺失的负数部分,该部分将负数限制为零。同时,ReLU也不是连续可微的。此外,ReLU是一个非负函数。这就产生了一个非零均值问题,即平均激活大于零。这样的问题对于网络收敛是不可取的。
为了在一定程度上解决上述问题,最近出现了几个新的激活函数,包括LeakyReLU, ELU, Swish等。Swish似乎是激活函数的理想候选函数,其属性包括非单调性和保持小负权并保持平滑轮廓的能力。与Swish类似,像GELU这样的激活函数已经获得了流行,特别是在基于Transformer的体系结构中。另一个激活函数Mish因其在最先进的分类和目标检测任务中的表现而脱颖而出,Mish起源于Swish,是通过对导致Swish效果的属性进行系统分析而开发出来的。
从Mish的开发中获得灵感,本文提出了一个名为Serf的激活函数:
f ( x ) = x erf ( ln ( 1 + e x ) ) f(x)=x \operatorname{erf}\left(\ln \left(1+e^{x}\right)\right) f(x)=xerf(ln(1+ex))
1.2 Serf属性
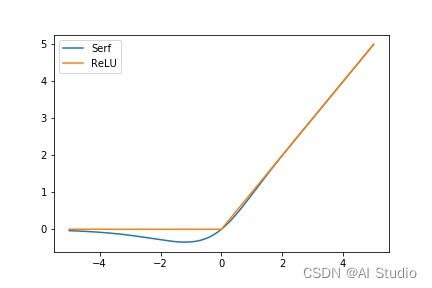
如下图所示,Serf具有如下属性:
- 无上界:避免饱和问题
- 有下界:以便提供强的正则化效果
- 可微性:避免了基于梯度的优化过程中的奇点和任何伴随的不良影响
- 预调节器:使得梯度更平滑且优化更快,如下公式所示,我们可以将Serf的一阶导数表示为swish的函数,p(x)是一个预调节器,可以使得梯度更加平滑
f ′ ( x ) = 2 π e − ln ( ( 1 + e x ) ) 2 x σ ( x ) + f ( x ) x = p ( x ) swish ( x ) + f ( x ) x f^{\prime}(x)=\frac{2}{\sqrt{\pi}} e^{-\ln \left(\left(1+e^{x}\right)\right)^{2}} x \sigma(x)+\frac{f(x)}{x}=p(x) \operatorname{swish}(x)+\frac{f(x)}{x} f′(x)=π2e−ln((1+ex))2xσ(x)+xf(x)=p(x)swish(x)+xf(x) - 平滑性:平滑的损失曲线表明更容易的优化并具有较少的局部最优。因此更好的泛化,最小化初始化和学习率的影响
2. 代码复现
2.1 下载并导入所需要的包
!pip install paddlex
%matplotlib inline
import paddle
import paddle.fluid as fluid
import numpy as np
import matplotlib.pyplot as plt
from paddle.vision.datasets import Cifar10
from paddle.vision.transforms import Transpose
from paddle.io import Dataset, DataLoader
from paddle import nn
import paddle.nn.functional as F
import paddle.vision.transforms as transforms
import os
import matplotlib.pyplot as plt
from matplotlib.pyplot import figure
import paddlex
from paddle import ParamAttr
2.2 创建数据集
train_tfm = transforms.Compose([
transforms.Resize((130, 130)),
transforms.ColorJitter(brightness=0.2,contrast=0.2, saturation=0.2),
paddlex.transforms.MixupImage(),
transforms.RandomResizedCrop(128, scale=(0.6, 1.0)),
transforms.RandomHorizontalFlip(0.5),
transforms.RandomRotation(20),
transforms.ToTensor(),
transforms.Normalize(mean=(0.485, 0.456, 0.406), std=(0.229, 0.224, 0.225)),
])
test_tfm = transforms.Compose([
transforms.Resize((128, 128)),
transforms.ToTensor(),
transforms.Normalize(mean=(0.485, 0.456, 0.406), std=(0.229, 0.224, 0.225)),
])
paddle.vision.set_image_backend('cv2')
# 使用Cifar10数据集
train_dataset = Cifar10(data_file='data/data152754/cifar-10-python.tar.gz', mode='train', transform = train_tfm)
val_dataset = Cifar10(data_file='data/data152754/cifar-10-python.tar.gz', mode='test',transform = test_tfm)
print("train_dataset: %d" % len(train_dataset))
print("val_dataset: %d" % len(val_dataset))
train_dataset: 50000
val_dataset: 10000
batch_size=128
train_loader = DataLoader(train_dataset, batch_size=batch_size, shuffle=True, drop_last=True, num_workers=4)
val_loader = DataLoader(val_dataset, batch_size=batch_size, shuffle=False, drop_last=False, num_workers=4)
2.3 标签平滑
class LabelSmoothingCrossEntropy(nn.Layer):
def __init__(self, smoothing=0.1):
super().__init__()
self.smoothing = smoothing
def forward(self, pred, target):
confidence = 1. - self.smoothing
log_probs = F.log_softmax(pred, axis=-1)
idx = paddle.stack([paddle.arange(log_probs.shape[0]), target], axis=1)
nll_loss = paddle.gather_nd(-log_probs, index=idx)
smooth_loss = paddle.mean(-log_probs, axis=-1)
loss = confidence * nll_loss + self.smoothing * smooth_loss
return loss.mean()
2.4 AlexNet-Serf
2.4.1 Serf
class Serf(nn.Layer):
def __init__(self):
super().__init__()
def forward(self, x):
out = x * paddle.erf(paddle.log(1 + paddle.exp(x)))
return out
x = paddle.linspace(-5.0, 5.0, 1000, dtype=paddle.float32)
model = Serf()
y1 = model(x)
y2 = F.relu(x)
plt.plot(x, y1, x, y2)
plt.legend(['Serf', 'ReLU'])
plt.savefig('activation.jpg')
plt.show()
W0731 19:01:06.202260 785 gpu_resources.cc:61] Please NOTE: device: 0, GPU Compute Capability: 7.0, Driver API Version: 11.2, Runtime API Version: 10.1
W0731 19:01:06.206224 785 gpu_resources.cc:91] device: 0, cuDNN Version: 7.6.
model = Serf()
paddle.summary(model, (1, 64, 224, 224))
---------------------------------------------------------------------------
Layer (type) Input Shape Output Shape Param #
===========================================================================
Serf-2 [[1, 64, 224, 224]] [1, 64, 224, 224] 0
===========================================================================
Total params: 0
Trainable params: 0
Non-trainable params: 0
---------------------------------------------------------------------------
Input size (MB): 12.25
Forward/backward pass size (MB): 24.50
Params size (MB): 0.00
Estimated Total Size (MB): 36.75
---------------------------------------------------------------------------
{'total_params': 0, 'trainable_params': 0}
2.4.2 AlexNet-Serf
class AlexNet_Serf(nn.Layer):
def __init__(self,num_classes=10):
super().__init__()
self.features=nn.Sequential(
nn.Conv2D(3,48, kernel_size=11, stride=4, padding=11//2),
Serf(),
nn.MaxPool2D(kernel_size=3,stride=2),
nn.Conv2D(48,128, kernel_size=5, padding=2),
Serf(),
nn.MaxPool2D(kernel_size=3,stride=2),
nn.Conv2D(128, 192,kernel_size=3,stride=1,padding=1),
Serf(),
nn.Conv2D(192,192,kernel_size=3,stride=1,padding=1),
Serf(),
nn.Conv2D(192,128,kernel_size=3,stride=1,padding=1),
Serf(),
nn.MaxPool2D(kernel_size=3,stride=2),
)
self.classifier=nn.Sequential(
nn.Linear(3 * 3 * 128,2048),
nn.ReLU(),
nn.Dropout(0.5),
nn.Linear(2048,2048),
nn.ReLU(),
nn.Dropout(0.5),
nn.Linear(2048,num_classes),
)
def forward(self,x):
x = self.features(x)
x = paddle.flatten(x, 1)
x=self.classifier(x)
return x
model = AlexNet_Serf(num_classes=10)
paddle.summary(model, (1, 3, 128, 128))
---------------------------------------------------------------------------
Layer (type) Input Shape Output Shape Param #
===========================================================================
Conv2D-1 [[1, 3, 128, 128]] [1, 48, 32, 32] 17,472
Serf-3 [[1, 48, 32, 32]] [1, 48, 32, 32] 0
MaxPool2D-1 [[1, 48, 32, 32]] [1, 48, 15, 15] 0
Conv2D-2 [[1, 48, 15, 15]] [1, 128, 15, 15] 153,728
Serf-4 [[1, 128, 15, 15]] [1, 128, 15, 15] 0
MaxPool2D-2 [[1, 128, 15, 15]] [1, 128, 7, 7] 0
Conv2D-3 [[1, 128, 7, 7]] [1, 192, 7, 7] 221,376
Serf-5 [[1, 192, 7, 7]] [1, 192, 7, 7] 0
Conv2D-4 [[1, 192, 7, 7]] [1, 192, 7, 7] 331,968
Serf-6 [[1, 192, 7, 7]] [1, 192, 7, 7] 0
Conv2D-5 [[1, 192, 7, 7]] [1, 128, 7, 7] 221,312
Serf-7 [[1, 128, 7, 7]] [1, 128, 7, 7] 0
MaxPool2D-3 [[1, 128, 7, 7]] [1, 128, 3, 3] 0
Linear-1 [[1, 1152]] [1, 2048] 2,361,344
ReLU-5 [[1, 2048]] [1, 2048] 0
Dropout-1 [[1, 2048]] [1, 2048] 0
Linear-2 [[1, 2048]] [1, 2048] 4,196,352
ReLU-6 [[1, 2048]] [1, 2048] 0
Dropout-2 [[1, 2048]] [1, 2048] 0
Linear-3 [[1, 2048]] [1, 10] 20,490
===========================================================================
Total params: 7,524,042
Trainable params: 7,524,042
Non-trainable params: 0
---------------------------------------------------------------------------
Input size (MB): 0.19
Forward/backward pass size (MB): 1.81
Params size (MB): 28.70
Estimated Total Size (MB): 30.69
---------------------------------------------------------------------------
{'total_params': 7524042, 'trainable_params': 7524042}
2.5 训练
learning_rate = 0.001
n_epochs = 50
paddle.seed(42)
np.random.seed(42)
work_path = 'work/model'
model = AlexNet_Serf(num_classes=10)
criterion = LabelSmoothingCrossEntropy()
scheduler = paddle.optimizer.lr.CosineAnnealingDecay(learning_rate=learning_rate, T_max=50000 // batch_size * n_epochs, verbose=False)
optimizer = paddle.optimizer.Adam(parameters=model.parameters(), learning_rate=scheduler, weight_decay=1e-5)
gate = 0.0
threshold = 0.0
best_acc = 0.0
val_acc = 0.0
loss_record = {'train': {'loss': [], 'iter': []}, 'val': {'loss': [], 'iter': []}} # for recording loss
acc_record = {'train': {'acc': [], 'iter': []}, 'val': {'acc': [], 'iter': []}} # for recording accuracy
loss_iter = 0
acc_iter = 0
for epoch in range(n_epochs):
# ---------- Training ----------
model.train()
train_num = 0.0
train_loss = 0.0
val_num = 0.0
val_loss = 0.0
accuracy_manager = paddle.metric.Accuracy()
val_accuracy_manager = paddle.metric.Accuracy()
print("#===epoch: {}, lr={:.10f}===#".format(epoch, optimizer.get_lr()))
for batch_id, data in enumerate(train_loader):
x_data, y_data = data
labels = paddle.unsqueeze(y_data, axis=1)
logits = model(x_data)
loss = criterion(logits, y_data)
acc = paddle.metric.accuracy(logits, labels)
accuracy_manager.update(acc)
if batch_id % 10 == 0:
loss_record['train']['loss'].append(loss.numpy())
loss_record['train']['iter'].append(loss_iter)
loss_iter += 1
loss.backward()
optimizer.step()
scheduler.step()
optimizer.clear_grad()
train_loss += loss
train_num += len(y_data)
total_train_loss = (train_loss / train_num) * batch_size
train_acc = accuracy_manager.accumulate()
acc_record['train']['acc'].append(train_acc)
acc_record['train']['iter'].append(acc_iter)
acc_iter += 1
# Print the information.
print("#===epoch: {}, train loss is: {}, train acc is: {:2.2f}%===#".format(epoch, total_train_loss.numpy(), train_acc*100))
# ---------- Validation ----------
model.eval()
for batch_id, data in enumerate(val_loader):
x_data, y_data = data
labels = paddle.unsqueeze(y_data, axis=1)
with paddle.no_grad():
logits = model(x_data)
loss = criterion(logits, y_data)
acc = paddle.metric.accuracy(logits, labels)
val_accuracy_manager.update(acc)
val_loss += loss
val_num += len(y_data)
total_val_loss = (val_loss / val_num) * batch_size
loss_record['val']['loss'].append(total_val_loss.numpy())
loss_record['val']['iter'].append(loss_iter)
val_acc = val_accuracy_manager.accumulate()
acc_record['val']['acc'].append(val_acc)
acc_record['val']['iter'].append(acc_iter)
print("#===epoch: {}, val loss is: {}, val acc is: {:2.2f}%===#".format(epoch, total_val_loss.numpy(), val_acc*100))
# ===================save====================
if val_acc > best_acc:
best_acc = val_acc
paddle.save(model.state_dict(), os.path.join(work_path, 'best_model.pdparams'))
paddle.save(optimizer.state_dict(), os.path.join(work_path, 'best_optimizer.pdopt'))
print(best_acc)
paddle.save(model.state_dict(), os.path.join(work_path, 'final_model.pdparams'))
paddle.save(optimizer.state_dict(), os.path.join(work_path, 'final_optimizer.pdopt'))
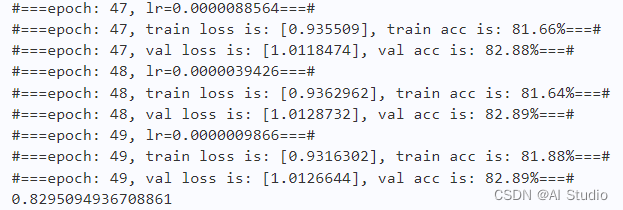
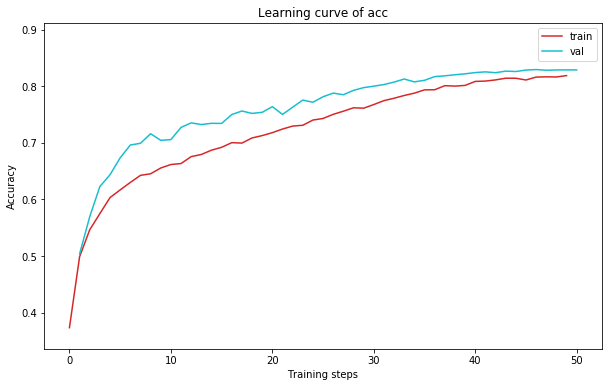
2.6 实验结果
def plot_learning_curve(record, title='loss', ylabel='CE Loss'):
''' Plot learning curve of your CNN '''
maxtrain = max(map(float, record['train'][title]))
maxval = max(map(float, record['val'][title]))
ymax = max(maxtrain, maxval) * 1.1
mintrain = min(map(float, record['train'][title]))
minval = min(map(float, record['val'][title]))
ymin = min(mintrain, minval) * 0.9
total_steps = len(record['train'][title])
x_1 = list(map(int, record['train']['iter']))
x_2 = list(map(int, record['val']['iter']))
figure(figsize=(10, 6))
plt.plot(x_1, record['train'][title], c='tab:red', label='train')
plt.plot(x_2, record['val'][title], c='tab:cyan', label='val')
plt.ylim(ymin, ymax)
plt.xlabel('Training steps')
plt.ylabel(ylabel)
plt.title('Learning curve of {}'.format(title))
plt.legend()
plt.show()
plot_learning_curve(loss_record, title='loss', ylabel='CE Loss')
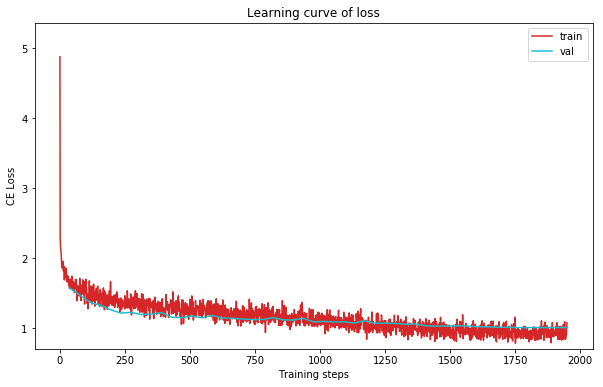
plot_learning_curve(acc_record, title='acc', ylabel='Accuracy')
import time
work_path = 'work/model'
model = AlexNet_Serf(num_classes=10)
model_state_dict = paddle.load(os.path.join(work_path, 'best_model.pdparams'))
model.set_state_dict(model_state_dict)
model.eval()
aa = time.time()
for batch_id, data in enumerate(val_loader):
x_data, y_data = data
labels = paddle.unsqueeze(y_data, axis=1)
with paddle.no_grad():
logits = model(x_data)
bb = time.time()
print("Throughout:{}".format(int(len(val_dataset)//(bb - aa))))
Throughout:2124
def get_cifar10_labels(labels):
"""返回CIFAR10数据集的文本标签。"""
text_labels = [
'airplane', 'automobile', 'bird', 'cat', 'deer', 'dog', 'frog',
'horse', 'ship', 'truck']
return [text_labels[int(i)] for i in labels]
def show_images(imgs, num_rows, num_cols, pred=None, gt=None, scale=1.5):
"""Plot a list of images."""
figsize = (num_cols * scale, num_rows * scale)
_, axes = plt.subplots(num_rows, num_cols, figsize=figsize)
axes = axes.flatten()
for i, (ax, img) in enumerate(zip(axes, imgs)):
if paddle.is_tensor(img):
ax.imshow(img.numpy())
else:
ax.imshow(img)
ax.axes.get_xaxis().set_visible(False)
ax.axes.get_yaxis().set_visible(False)
if pred or gt:
ax.set_title("pt: " + pred[i] + "\ngt: " + gt[i])
return axes
work_path = 'work/model'
X, y = next(iter(DataLoader(val_dataset, batch_size=18)))
model = AlexNet_Serf(num_classes=10)
model_state_dict = paddle.load(os.path.join(work_path, 'best_model.pdparams'))
model.set_state_dict(model_state_dict)
model.eval()
logits = model(X)
y_pred = paddle.argmax(logits, -1)
X = paddle.transpose(X, [0, 2, 3, 1])
axes = show_images(X.reshape((18, 128, 128, 3)), 1, 18, pred=get_cifar10_labels(y_pred), gt=get_cifar10_labels(y))
plt.show()
Clipping input data to the valid range for imshow with RGB data ([0..1] for floats or [0..255] for integers).
Clipping input data to the valid range for imshow with RGB data ([0..1] for floats or [0..255] for integers).
Clipping input data to the valid range for imshow with RGB data ([0..1] for floats or [0..255] for integers).
Clipping input data to the valid range for imshow with RGB data ([0..1] for floats or [0..255] for integers).
Clipping input data to the valid range for imshow with RGB data ([0..1] for floats or [0..255] for integers).
Clipping input data to the valid range for imshow with RGB data ([0..1] for floats or [0..255] for integers).
Clipping input data to the valid range for imshow with RGB data ([0..1] for floats or [0..255] for integers).
Clipping input data to the valid range for imshow with RGB data ([0..1] for floats or [0..255] for integers).
Clipping input data to the valid range for imshow with RGB data ([0..1] for floats or [0..255] for integers).
Clipping input data to the valid range for imshow with RGB data ([0..1] for floats or [0..255] for integers).
Clipping input data to the valid range for imshow with RGB data ([0..1] for floats or [0..255] for integers).
Clipping input data to the valid range for imshow with RGB data ([0..1] for floats or [0..255] for integers).
Clipping input data to the valid range for imshow with RGB data ([0..1] for floats or [0..255] for integers).
Clipping input data to the valid range for imshow with RGB data ([0..1] for floats or [0..255] for integers).
Clipping input data to the valid range for imshow with RGB data ([0..1] for floats or [0..255] for integers).
Clipping input data to the valid range for imshow with RGB data ([0..1] for floats or [0..255] for integers).
Clipping input data to the valid range for imshow with RGB data ([0..1] for floats or [0..255] for integers).
Clipping input data to the valid range for imshow with RGB data ([0..1] for floats or [0..255] for integers).

3. AlexNet
3.1 AlexNet
class AlexNet(nn.Layer):
def __init__(self,num_classes=10):
super().__init__()
self.features=nn.Sequential(
nn.Conv2D(3,48, kernel_size=11, stride=4, padding=11//2),
nn.ReLU(),
nn.MaxPool2D(kernel_size=3,stride=2),
nn.Conv2D(48,128, kernel_size=5, padding=2),
nn.ReLU(),
nn.MaxPool2D(kernel_size=3,stride=2),
nn.Conv2D(128, 192,kernel_size=3,stride=1,padding=1),
nn.ReLU(),
nn.Conv2D(192,192,kernel_size=3,stride=1,padding=1),
nn.ReLU(),
nn.Conv2D(192,128,kernel_size=3,stride=1,padding=1),
nn.ReLU(),
nn.MaxPool2D(kernel_size=3,stride=2),
)
self.classifier=nn.Sequential(
nn.Linear(3 * 3 * 128,2048),
nn.ReLU(),
nn.Dropout(0.5),
nn.Linear(2048,2048),
nn.ReLU(),
nn.Dropout(0.5),
nn.Linear(2048,num_classes),
)
def forward(self,x):
x = self.features(x)
x = paddle.flatten(x, 1)
x=self.classifier(x)
return x
model = AlexNet(num_classes=10)
paddle.summary(model, (1, 3, 128, 128))
---------------------------------------------------------------------------
Layer (type) Input Shape Output Shape Param #
===========================================================================
Conv2D-21 [[1, 3, 128, 128]] [1, 48, 32, 32] 17,472
ReLU-13 [[1, 48, 32, 32]] [1, 48, 32, 32] 0
MaxPool2D-13 [[1, 48, 32, 32]] [1, 48, 15, 15] 0
Conv2D-22 [[1, 48, 15, 15]] [1, 128, 15, 15] 153,728
ReLU-14 [[1, 128, 15, 15]] [1, 128, 15, 15] 0
MaxPool2D-14 [[1, 128, 15, 15]] [1, 128, 7, 7] 0
Conv2D-23 [[1, 128, 7, 7]] [1, 192, 7, 7] 221,376
ReLU-15 [[1, 192, 7, 7]] [1, 192, 7, 7] 0
Conv2D-24 [[1, 192, 7, 7]] [1, 192, 7, 7] 331,968
ReLU-16 [[1, 192, 7, 7]] [1, 192, 7, 7] 0
Conv2D-25 [[1, 192, 7, 7]] [1, 128, 7, 7] 221,312
ReLU-17 [[1, 128, 7, 7]] [1, 128, 7, 7] 0
MaxPool2D-15 [[1, 128, 7, 7]] [1, 128, 3, 3] 0
Linear-13 [[1, 1152]] [1, 2048] 2,361,344
ReLU-18 [[1, 2048]] [1, 2048] 0
Dropout-9 [[1, 2048]] [1, 2048] 0
Linear-14 [[1, 2048]] [1, 2048] 4,196,352
ReLU-19 [[1, 2048]] [1, 2048] 0
Dropout-10 [[1, 2048]] [1, 2048] 0
Linear-15 [[1, 2048]] [1, 10] 20,490
===========================================================================
Total params: 7,524,042
Trainable params: 7,524,042
Non-trainable params: 0
---------------------------------------------------------------------------
Input size (MB): 0.19
Forward/backward pass size (MB): 1.81
Params size (MB): 28.70
Estimated Total Size (MB): 30.69
---------------------------------------------------------------------------
{'total_params': 7524042, 'trainable_params': 7524042}
3.2 训练
learning_rate = 0.001
n_epochs = 50
paddle.seed(42)
np.random.seed(42)
work_path = 'work/model1'
model = AlexNet(num_classes=10)
criterion = LabelSmoothingCrossEntropy()
scheduler = paddle.optimizer.lr.CosineAnnealingDecay(learning_rate=learning_rate, T_max=50000 // batch_size * n_epochs, verbose=False)
optimizer = paddle.optimizer.Adam(parameters=model.parameters(), learning_rate=scheduler, weight_decay=1e-5)
gate = 0.0
threshold = 0.0
best_acc = 0.0
val_acc = 0.0
loss_record1 = {'train': {'loss': [], 'iter': []}, 'val': {'loss': [], 'iter': []}} # for recording loss
acc_record1 = {'train': {'acc': [], 'iter': []}, 'val': {'acc': [], 'iter': []}} # for recording accuracy
loss_iter = 0
acc_iter = 0
for epoch in range(n_epochs):
# ---------- Training ----------
model.train()
train_num = 0.0
train_loss = 0.0
val_num = 0.0
val_loss = 0.0
accuracy_manager = paddle.metric.Accuracy()
val_accuracy_manager = paddle.metric.Accuracy()
print("#===epoch: {}, lr={:.10f}===#".format(epoch, optimizer.get_lr()))
for batch_id, data in enumerate(train_loader):
x_data, y_data = data
labels = paddle.unsqueeze(y_data, axis=1)
logits = model(x_data)
loss = criterion(logits, y_data)
acc = paddle.metric.accuracy(logits, labels)
accuracy_manager.update(acc)
if batch_id % 10 == 0:
loss_record1['train']['loss'].append(loss.numpy())
loss_record1['train']['iter'].append(loss_iter)
loss_iter += 1
loss.backward()
optimizer.step()
scheduler.step()
optimizer.clear_grad()
train_loss += loss
train_num += len(y_data)
total_train_loss = (train_loss / train_num) * batch_size
train_acc = accuracy_manager.accumulate()
acc_record1['train']['acc'].append(train_acc)
acc_record1['train']['iter'].append(acc_iter)
acc_iter += 1
# Print the information.
print("#===epoch: {}, train loss is: {}, train acc is: {:2.2f}%===#".format(epoch, total_train_loss.numpy(), train_acc*100))
# ---------- Validation ----------
model.eval()
for batch_id, data in enumerate(val_loader):
x_data, y_data = data
labels = paddle.unsqueeze(y_data, axis=1)
with paddle.no_grad():
logits = model(x_data)
loss = criterion(logits, y_data)
acc = paddle.metric.accuracy(logits, labels)
val_accuracy_manager.update(acc)
val_loss += loss
val_num += len(y_data)
total_val_loss = (val_loss / val_num) * batch_size
loss_record1['val']['loss'].append(total_val_loss.numpy())
loss_record1['val']['iter'].append(loss_iter)
val_acc = val_accuracy_manager.accumulate()
acc_record1['val']['acc'].append(val_acc)
acc_record1['val']['iter'].append(acc_iter)
print("#===epoch: {}, val loss is: {}, val acc is: {:2.2f}%===#".format(epoch, total_val_loss.numpy(), val_acc*100))
# ===================save====================
if val_acc > best_acc:
best_acc = val_acc
paddle.save(model.state_dict(), os.path.join(work_path, 'best_model.pdparams'))
paddle.save(optimizer.state_dict(), os.path.join(work_path, 'best_optimizer.pdopt'))
print(best_acc)
paddle.save(model.state_dict(), os.path.join(work_path, 'final_model.pdparams'))
paddle.save(optimizer.state_dict(), os.path.join(work_path, 'final_optimizer.pdopt'))
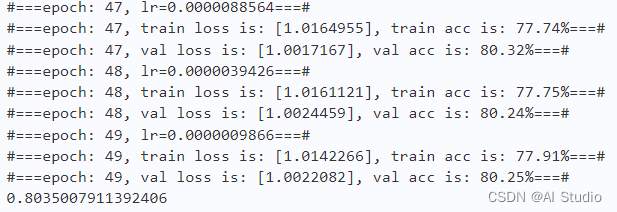
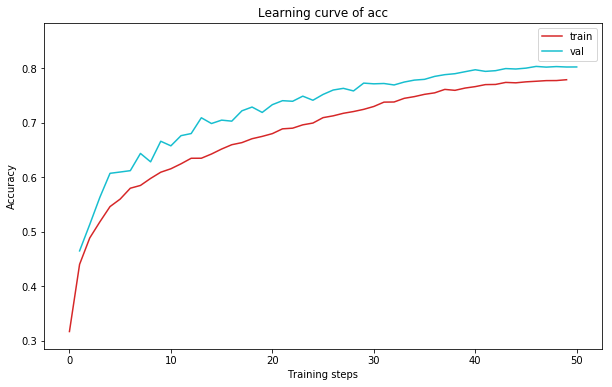
3.3 实验结果
plot_learning_curve(loss_record1, title='loss', ylabel='CE Loss')
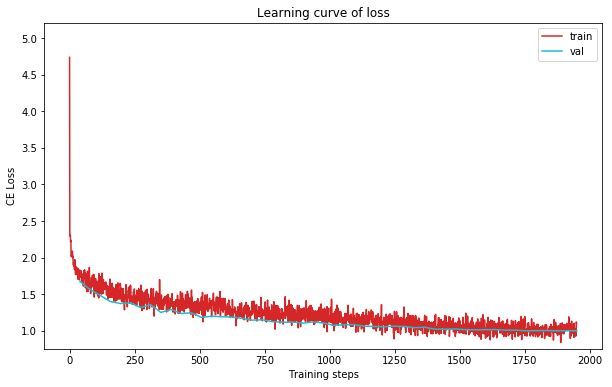
plot_learning_curve(acc_record1, title='acc', ylabel='Accuracy')
import time
work_path = 'work/model1'
model = AlexNet(num_classes=10)
model_state_dict = paddle.load(os.path.join(work_path, 'best_model.pdparams'))
model.set_state_dict(model_state_dict)
model.eval()
aa = time.time()
for batch_id, data in enumerate(val_loader):
x_data, y_data = data
labels = paddle.unsqueeze(y_data, axis=1)
with paddle.no_grad():
logits = model(x_data)
bb = time.time()
print("Throughout:{}".format(int(len(val_dataset)//(bb - aa))))
Throughout:2160
work_path = 'work/model1'
X, y = next(iter(DataLoader(val_dataset, batch_size=18)))
model = AlexNet(num_classes=10)
model_state_dict = paddle.load(os.path.join(work_path, 'best_model.pdparams'))
model.set_state_dict(model_state_dict)
model.eval()
logits = model(X)
y_pred = paddle.argmax(logits, -1)
X = paddle.transpose(X, [0, 2, 3, 1])
axes = show_images(X.reshape((18, 128, 128, 3)), 1, 18, pred=get_cifar10_labels(y_pred), gt=get_cifar10_labels(y))
plt.show()
Clipping input data to the valid range for imshow with RGB data ([0..1] for floats or [0..255] for integers).
Clipping input data to the valid range for imshow with RGB data ([0..1] for floats or [0..255] for integers).
Clipping input data to the valid range for imshow with RGB data ([0..1] for floats or [0..255] for integers).
Clipping input data to the valid range for imshow with RGB data ([0..1] for floats or [0..255] for integers).
Clipping input data to the valid range for imshow with RGB data ([0..1] for floats or [0..255] for integers).
Clipping input data to the valid range for imshow with RGB data ([0..1] for floats or [0..255] for integers).
Clipping input data to the valid range for imshow with RGB data ([0..1] for floats or [0..255] for integers).
Clipping input data to the valid range for imshow with RGB data ([0..1] for floats or [0..255] for integers).
Clipping input data to the valid range for imshow with RGB data ([0..1] for floats or [0..255] for integers).
Clipping input data to the valid range for imshow with RGB data ([0..1] for floats or [0..255] for integers).
Clipping input data to the valid range for imshow with RGB data ([0..1] for floats or [0..255] for integers).
Clipping input data to the valid range for imshow with RGB data ([0..1] for floats or [0..255] for integers).
Clipping input data to the valid range for imshow with RGB data ([0..1] for floats or [0..255] for integers).
Clipping input data to the valid range for imshow with RGB data ([0..1] for floats or [0..255] for integers).
Clipping input data to the valid range for imshow with RGB data ([0..1] for floats or [0..255] for integers).
Clipping input data to the valid range for imshow with RGB data ([0..1] for floats or [0..255] for integers).
Clipping input data to the valid range for imshow with RGB data ([0..1] for floats or [0..255] for integers).
Clipping input data to the valid range for imshow with RGB data ([0..1] for floats or [0..255] for integers).

4. 对比实验结果
| model | Train Acc | Val Acc | parameter |
|---|---|---|---|
| AlexNet w/o Serf | 0.7752 | 0.80350 | 7524042 |
| AlexNet w Serf | 0.8110 | 0.82951 | 7524042 |
总结
- Serf在不增加可训练参数的同时大大加快了收敛速度以及精度(+0.02509)
- 从Serf与ReLU的曲线可以看到Serf在 x > 0 x > 0 x>0 时可以很好地近似ReLU,继承了ReLU的优点,同时又解决了死亡ReLU等问题
转载自:https://aistudio.baidu.com/aistudio/projectdetail/4413856?forkThirdPart=1

学大模型,用大模型上飞桨星河社区!每天8点V100G算力免费领!免费领取ERNIE 4.0 100w Token >>>
更多推荐



 0
0 0
0- 0



 已为社区贡献1437条内容
已为社区贡献1437条内容

所有评论(0)