
『NLP打卡营』实践课6:机器阅读理解
基于预训练模型结合DuReader数据集训练阅读理解模型。
基于预训练模型的机器阅读理解
阅读理解是检索问答系统中的重要组成部分,最常见的数据集是单篇章、抽取式阅读理解数据集。
该示例展示了如何使用PaddleNLP快速实现基于预训练模型的机器阅读理解任务。
本示例使用的数据集是Dureaderrobust数据集。对于一个给定的问题q和一个篇章p,根据篇章内容,给出该问题的答案a。数据集中的每个样本,是一个三元组<q, p, a>,例如:
问题 q: 乔丹打了多少个赛季
篇章 p: 迈克尔.乔丹在NBA打了15个赛季。他在84年进入nba,期间在1993年10月6日第一次退役改打棒球,95年3月18日重新回归,在99年1月13日第二次退役,后于2001年10月31日复出,在03年最终退役…
参考答案 a: [‘15个’,‘15个赛季’]
阅读理解模型的鲁棒性是衡量该技术能否在实际应用中大规模落地的重要指标之一。随着当前技术的进步,模型虽然能够在一些阅读理解测试集上取得较好的性能,但在实际应用中,这些模型所表现出的鲁棒性仍然难以令人满意。

本示例使用的Dureaderrobust数据集作为首个关注阅读理解模型鲁棒性的中文数据集,旨在考察模型在真实应用场景中的过敏感性、过稳定性以及泛化能力等问题。
安装说明
-
PaddlePaddle 安装
本项目依赖于 PaddlePaddle 2.0 及以上版本,请参考 安装指南 进行安装
-
PaddleNLP 安装
pip install --upgrade paddlenlp -i https://pypi.org/simple -
环境依赖
Python的版本要求 3.6+
AI Studio平台默认安装了Paddle和PaddleNLP,并定期更新版本。
如需手动更新Paddle,可参考飞桨安装说明,安装相应环境下最新版飞桨框架。
使用如下命令确保安装最新版PaddleNLP:
!pip install --upgrade paddlenlp -i https://pypi.org/simple
Collecting paddlenlp
[?25l Downloading https://files.pythonhosted.org/packages/b0/7d/6c24cda54d018d350ee342f715523ade7871660444ed95f3d3e753d6f388/paddlenlp-2.0.8-py3-none-any.whl (571kB)
[K |████████████████████████████████| 573kB 59kB/s eta 0:00:011
[?25hRequirement already satisfied, skipping upgrade: colorama in /opt/conda/envs/python35-paddle120-env/lib/python3.7/site-packages (from paddlenlp) (0.4.4)
Requirement already satisfied, skipping upgrade: colorlog in /opt/conda/envs/python35-paddle120-env/lib/python3.7/site-packages (from paddlenlp) (4.1.0)
Requirement already satisfied, skipping upgrade: jieba in /opt/conda/envs/python35-paddle120-env/lib/python3.7/site-packages (from paddlenlp) (0.42.1)
Requirement already satisfied, skipping upgrade: multiprocess in /opt/conda/envs/python35-paddle120-env/lib/python3.7/site-packages (from paddlenlp) (0.70.11.1)
Requirement already satisfied, skipping upgrade: h5py in /opt/conda/envs/python35-paddle120-env/lib/python3.7/site-packages (from paddlenlp) (2.9.0)
Requirement already satisfied, skipping upgrade: seqeval in /opt/conda/envs/python35-paddle120-env/lib/python3.7/site-packages (from paddlenlp) (1.2.2)
Requirement already satisfied, skipping upgrade: dill>=0.3.3 in /opt/conda/envs/python35-paddle120-env/lib/python3.7/site-packages (from multiprocess->paddlenlp) (0.3.3)
Requirement already satisfied, skipping upgrade: numpy>=1.7 in /opt/conda/envs/python35-paddle120-env/lib/python3.7/site-packages (from h5py->paddlenlp) (1.20.3)
Requirement already satisfied, skipping upgrade: six in /opt/conda/envs/python35-paddle120-env/lib/python3.7/site-packages (from h5py->paddlenlp) (1.15.0)
Requirement already satisfied, skipping upgrade: scikit-learn>=0.21.3 in /opt/conda/envs/python35-paddle120-env/lib/python3.7/site-packages (from seqeval->paddlenlp) (0.24.2)
Requirement already satisfied, skipping upgrade: joblib>=0.11 in /opt/conda/envs/python35-paddle120-env/lib/python3.7/site-packages (from scikit-learn>=0.21.3->seqeval->paddlenlp) (0.14.1)
Requirement already satisfied, skipping upgrade: scipy>=0.19.1 in /opt/conda/envs/python35-paddle120-env/lib/python3.7/site-packages (from scikit-learn>=0.21.3->seqeval->paddlenlp) (1.6.3)
Requirement already satisfied, skipping upgrade: threadpoolctl>=2.0.0 in /opt/conda/envs/python35-paddle120-env/lib/python3.7/site-packages (from scikit-learn>=0.21.3->seqeval->paddlenlp) (2.1.0)
Installing collected packages: paddlenlp
Found existing installation: paddlenlp 2.0.7
Uninstalling paddlenlp-2.0.7:
Successfully uninstalled paddlenlp-2.0.7
Successfully installed paddlenlp-2.0.8
示例流程
与大多数NLP任务相同,本次机器阅读理解任务的示例展示分为以下四步:
首先我们从数据准备开始。

数据准备
数据准备流程如下:

1. 加载PaddleNLP内置数据集
使用PaddleNLP提供的load_datasetAPI,即可一键完成数据集加载。
from paddlenlp.datasets import load_dataset
train_ds, dev_ds, test_ds = load_dataset('dureader_robust', splits=('train', 'dev', 'test'))
for idx in range(2):
print(train_ds[idx]['question'])
print(train_ds[idx]['context'])
print(train_ds[idx]['answers'])
print(train_ds[idx]['answer_starts'])
print()
100%|██████████| 20038/20038 [00:00<00:00, 65482.39it/s]
仙剑奇侠传3第几集上天界
第35集雪见缓缓张开眼睛,景天又惊又喜之际,长卿和紫萱的仙船驶至,见众人无恙,也十分高兴。众人登船,用尽合力把自身的真气和水分输给她。雪见终于醒过来了,但却一脸木然,全无反应。众人向常胤求助,却发现人世界竟没有雪见的身世纪录。长卿询问清微的身世,清微语带双关说一切上了天界便有答案。长卿驾驶仙船,众人决定立马动身,往天界而去。众人来到一荒山,长卿指出,魔界和天界相连。由魔界进入通过神魔之井,便可登天。众人至魔界入口,仿若一黑色的蝙蝠洞,但始终无法进入。后来花楹发现只要有翅膀便能飞入。于是景天等人打下许多乌鸦,模仿重楼的翅膀,制作数对翅膀状巨物。刚佩戴在身,便被吸入洞口。众人摔落在地,抬头发现魔界守卫。景天和众魔套交情,自称和魔尊重楼相熟,众魔不理,打了起来。
['第35集']
[0]
燃气热水器哪个牌子好
选择燃气热水器时,一定要关注这几个问题:1、出水稳定性要好,不能出现忽热忽冷的现象2、快速到达设定的需求水温3、操作要智能、方便4、安全性要好,要装有安全报警装置 市场上燃气热水器品牌众多,购买时还需多加对比和仔细鉴别。方太今年主打的磁化恒温热水器在使用体验方面做了全面升级:9秒速热,可快速进入洗浴模式;水温持久稳定,不会出现忽热忽冷的现象,并通过水量伺服技术将出水温度精确控制在±0.5℃,可满足家里宝贝敏感肌肤洗护需求;配备CO和CH4双气体报警装置更安全(市场上一般多为CO单气体报警)。另外,这款热水器还有智能WIFI互联功能,只需下载个手机APP即可用手机远程操作热水器,实现精准调节水温,满足家人多样化的洗浴需求。当然方太的磁化恒温系列主要的是增加磁化功能,可以有效吸附水中的铁锈、铁屑等微小杂质,防止细菌滋生,使沐浴水质更洁净,长期使用磁化水沐浴更利于身体健康。
['方太']
[110]
关于更多PaddleNLP数据集,请参考数据集列表
如果你想使用自己的数据集文件构建数据集,请参考以内置数据集格式读取本地数据集和自定义数据集
2. 加载 paddlenlp.transformers.ErnieTokenizer用于数据处理
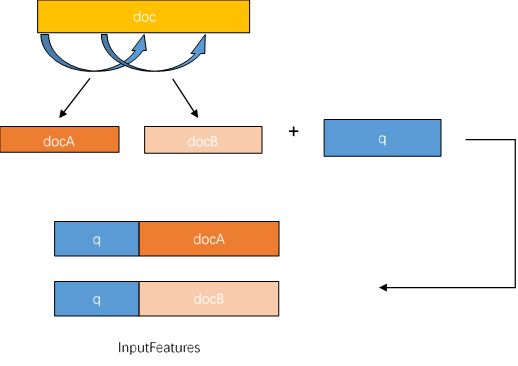
DuReaderrubust数据集采用SQuAD数据格式,InputFeature使用滑动窗口的方法生成,即一个example可能对应多个InputFeature。
由于文章加问题的文本长度可能大于max_seq_length,答案出现的位置有可能出现在文章最后,所以不能简单的对文章进行截断。
那么对于过长的文章,则采用滑动窗口将文章分成多段,分别与问题组合。再用对应的tokenizer转化为模型可接受的feature。doc_stride参数就是每次滑动的距离。滑动窗口生成InputFeature的过程如下图:
本基线中,我们使用的预训练模型是ERNIE,ERNIE对中文数据的处理是以字为单位。PaddleNLP对于各种预训练模型已经内置了相应的tokenizer,指定想要使用的模型名字即可加载对应的tokenizer。
tokenizer的作用是将原始输入文本转化成模型可以接受的输入数据形式。
import paddlenlp
# 设置模型名称
MODEL_NAME = 'ernie-1.0'
tokenizer = paddlenlp.transformers.ErnieTokenizer.from_pretrained(MODEL_NAME)
[2021-08-25 10:55:15,847] [ INFO] - Downloading https://paddlenlp.bj.bcebos.com/models/transformers/ernie/vocab.txt and saved to /home/aistudio/.paddlenlp/models/ernie-1.0
[2021-08-25 10:55:15,850] [ INFO] - Downloading vocab.txt from https://paddlenlp.bj.bcebos.com/models/transformers/ernie/vocab.txt
100%|██████████| 90/90 [00:00<00:00, 3321.34it/s]
3. 调用map()方法批量处理数据
由于我们传入了lazy=False,所以我们使用load_dataset()自定义的数据集是MapDataset对象。MapDataset是paddle.io.Dataset的功能增强版本。其内置的map()方法适合用来进行批量数据集处理。
map()方法接受的主要参数是一个用于数据处理的function。正好可以与tokenizer相配合。
以下是本示例中的用法:
from utils import prepare_train_features, prepare_validation_features
from functools import partial
max_seq_length = 512
doc_stride = 128
train_trans_func = partial(prepare_train_features,
max_seq_length=max_seq_length,
doc_stride=doc_stride,
tokenizer=tokenizer)
train_ds.map(train_trans_func, batched=True, num_workers=4)
dev_trans_func = partial(prepare_validation_features,
max_seq_length=max_seq_length,
doc_stride=doc_stride,
tokenizer=tokenizer)
dev_ds.map(dev_trans_func, batched=True, num_workers=4)
test_ds.map(dev_trans_func, batched=True, num_workers=4)
<paddlenlp.datasets.dataset.MapDataset at 0x7fb1b6e50290>
for idx in range(2):
print(train_ds[idx]['input_ids'])
print(train_ds[idx]['token_type_ids'])
print(train_ds[idx]['overflow_to_sample'])
print(train_ds[idx]['offset_mapping'])
print(train_ds[idx]['start_positions'])
print(train_ds[idx]['end_positions'])
print()
[1, 1034, 1189, 734, 2003, 241, 284, 131, 553, 271, 28, 125, 280, 2, 131, 1773, 271, 1097, 373, 1427, 1427, 501, 88, 662, 1906, 4, 561, 125, 311, 1168, 311, 692, 46, 430, 4, 84, 2073, 14, 1264, 3967, 5, 1034, 1020, 1829, 268, 4, 373, 539, 8, 154, 5210, 4, 105, 167, 59, 69, 685, 12043, 539, 8, 883, 1020, 4, 29, 720, 95, 90, 427, 67, 262, 5, 384, 266, 14, 101, 59, 789, 416, 237, 12043, 1097, 373, 616, 37, 1519, 93, 61, 15, 4, 255, 535, 7, 1529, 619, 187, 4, 62, 154, 451, 149, 12043, 539, 8, 253, 223, 3679, 323, 523, 4, 535, 34, 87, 8, 203, 280, 1186, 340, 9, 1097, 373, 5, 262, 203, 623, 704, 12043, 84, 2073, 1137, 358, 334, 702, 5, 262, 203, 4, 334, 702, 405, 360, 653, 129, 178, 7, 568, 28, 15, 125, 280, 518, 9, 1179, 487, 12043, 84, 2073, 1621, 1829, 1034, 1020, 4, 539, 8, 448, 91, 202, 466, 70, 262, 4, 638, 125, 280, 83, 299, 12043, 539, 8, 61, 45, 7, 1537, 176, 4, 84, 2073, 288, 39, 4, 889, 280, 14, 125, 280, 156, 538, 12043, 190, 889, 280, 71, 109, 124, 93, 292, 889, 46, 1248, 4, 518, 48, 883, 125, 12043, 539, 8, 268, 889, 280, 109, 270, 4, 1586, 845, 7, 669, 199, 5, 3964, 3740, 1084, 4, 255, 440, 616, 154, 72, 71, 109, 12043, 49, 61, 283, 3591, 34, 87, 297, 41, 9, 1993, 2602, 518, 52, 706, 109, 12043, 37, 10, 561, 125, 43, 8, 445, 86, 576, 65, 1448, 2969, 4, 469, 1586, 118, 776, 5, 1993, 2602, 4, 108, 25, 179, 51, 1993, 2602, 498, 1052, 122, 12043, 1082, 1994, 1616, 11, 262, 4, 518, 171, 813, 109, 1084, 270, 12043, 539, 8, 3006, 580, 11, 31, 4, 2473, 306, 34, 87, 889, 280, 846, 573, 12043, 561, 125, 14, 539, 889, 810, 276, 182, 4, 67, 351, 14, 889, 1182, 118, 776, 156, 952, 4, 539, 889, 16, 38, 4, 445, 15, 200, 61, 12043, 2]
[0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1]
0
[(0, 0), (0, 1), (1, 2), (2, 3), (3, 4), (4, 5), (5, 6), (6, 7), (7, 8), (8, 9), (9, 10), (10, 11), (11, 12), (0, 0), (0, 1), (1, 3), (3, 4), (4, 5), (5, 6), (6, 7), (7, 8), (8, 9), (9, 10), (10, 11), (11, 12), (12, 13), (13, 14), (14, 15), (15, 16), (16, 17), (17, 18), (18, 19), (19, 20), (20, 21), (21, 22), (22, 23), (23, 24), (24, 25), (25, 26), (26, 27), (27, 28), (28, 29), (29, 30), (30, 31), (31, 32), (32, 33), (33, 34), (34, 35), (35, 36), (36, 37), (37, 38), (38, 39), (39, 40), (40, 41), (41, 42), (42, 43), (43, 44), (44, 45), (45, 46), (46, 47), (47, 48), (48, 49), (49, 50), (50, 51), (51, 52), (52, 53), (53, 54), (54, 55), (55, 56), (56, 57), (57, 58), (58, 59), (59, 60), (60, 61), (61, 62), (62, 63), (63, 64), (64, 65), (65, 66), (66, 67), (67, 68), (68, 69), (69, 70), (70, 71), (71, 72), (72, 73), (73, 74), (74, 75), (75, 76), (76, 77), (77, 78), (78, 79), (79, 80), (80, 81), (81, 82), (82, 83), (83, 84), (84, 85), (85, 86), (86, 87), (87, 88), (88, 89), (89, 90), (90, 91), (91, 92), (92, 93), (93, 94), (94, 95), (95, 96), (96, 97), (97, 98), (98, 99), (99, 100), (100, 101), (101, 102), (102, 103), (103, 104), (104, 105), (105, 106), (106, 107), (107, 108), (108, 109), (109, 110), (110, 111), (111, 112), (112, 113), (113, 114), (114, 115), (115, 116), (116, 117), (117, 118), (118, 119), (119, 120), (120, 121), (121, 122), (122, 123), (123, 124), (124, 125), (125, 126), (126, 127), (127, 128), (128, 129), (129, 130), (130, 131), (131, 132), (132, 133), (133, 134), (134, 135), (135, 136), (136, 137), (137, 138), (138, 139), (139, 140), (140, 141), (141, 142), (142, 143), (143, 144), (144, 145), (145, 146), (146, 147), (147, 148), (148, 149), (149, 150), (150, 151), (151, 152), (152, 153), (153, 154), (154, 155), (155, 156), (156, 157), (157, 158), (158, 159), (159, 160), (160, 161), (161, 162), (162, 163), (163, 164), (164, 165), (165, 166), (166, 167), (167, 168), (168, 169), (169, 170), (170, 171), (171, 172), (172, 173), (173, 174), (174, 175), (175, 176), (176, 177), (177, 178), (178, 179), (179, 180), (180, 181), (181, 182), (182, 183), (183, 184), (184, 185), (185, 186), (186, 187), (187, 188), (188, 189), (189, 190), (190, 191), (191, 192), (192, 193), (193, 194), (194, 195), (195, 196), (196, 197), (197, 198), (198, 199), (199, 200), (200, 201), (201, 202), (202, 203), (203, 204), (204, 205), (205, 206), (206, 207), (207, 208), (208, 209), (209, 210), (210, 211), (211, 212), (212, 213), (213, 214), (214, 215), (215, 216), (216, 217), (217, 218), (218, 219), (219, 220), (220, 221), (221, 222), (222, 223), (223, 224), (224, 225), (225, 226), (226, 227), (227, 228), (228, 229), (229, 230), (230, 231), (231, 232), (232, 233), (233, 234), (234, 235), (235, 236), (236, 237), (237, 238), (238, 239), (239, 240), (240, 241), (241, 242), (242, 243), (243, 244), (244, 245), (245, 246), (246, 247), (247, 248), (248, 249), (249, 250), (250, 251), (251, 252), (252, 253), (253, 254), (254, 255), (255, 256), (256, 257), (257, 258), (258, 259), (259, 260), (260, 261), (261, 262), (262, 263), (263, 264), (264, 265), (265, 266), (266, 267), (267, 268), (268, 269), (269, 270), (270, 271), (271, 272), (272, 273), (273, 274), (274, 275), (275, 276), (276, 277), (277, 278), (278, 279), (279, 280), (280, 281), (281, 282), (282, 283), (283, 284), (284, 285), (285, 286), (286, 287), (287, 288), (288, 289), (289, 290), (290, 291), (291, 292), (292, 293), (293, 294), (294, 295), (295, 296), (296, 297), (297, 298), (298, 299), (299, 300), (300, 301), (301, 302), (302, 303), (303, 304), (304, 305), (305, 306), (306, 307), (307, 308), (308, 309), (309, 310), (310, 311), (311, 312), (312, 313), (313, 314), (314, 315), (315, 316), (316, 317), (317, 318), (318, 319), (319, 320), (320, 321), (321, 322), (322, 323), (323, 324), (324, 325), (325, 326), (326, 327), (327, 328), (328, 329), (329, 330), (330, 331), (331, 332), (0, 0)]
14
16
[1, 1404, 266, 506, 101, 361, 1256, 27, 664, 85, 170, 2, 352, 790, 1404, 266, 506, 101, 361, 36, 4, 7, 91, 41, 129, 490, 47, 553, 27, 358, 281, 74, 208, 6, 39, 101, 862, 91, 92, 41, 170, 4, 16, 52, 39, 87, 1745, 506, 1745, 888, 5, 87, 528, 249, 6, 532, 537, 45, 302, 94, 91, 5, 413, 323, 101, 565, 284, 6, 868, 25, 41, 826, 52, 6, 58, 518, 397, 6, 204, 62, 92, 41, 170, 4, 41, 371, 9, 204, 62, 337, 1023, 371, 521, 99, 191, 28, 1404, 266, 506, 101, 361, 100, 664, 539, 65, 4, 817, 1042, 36, 201, 413, 65, 120, 51, 277, 14, 2081, 541, 1190, 348, 12043, 58, 512, 508, 17, 57, 445, 5, 1512, 73, 1664, 565, 506, 101, 361, 11, 175, 29, 82, 412, 58, 76, 388, 15, 62, 76, 658, 222, 74, 701, 1866, 537, 506, 4, 48, 532, 537, 71, 109, 1123, 1600, 469, 220, 12048, 101, 565, 303, 876, 862, 91, 4, 16, 32, 39, 87, 1745, 506, 1745, 888, 5, 87, 528, 4, 145, 124, 93, 101, 150, 3466, 231, 164, 133, 174, 39, 101, 565, 130, 326, 524, 586, 108, 11, 17963, 42, 17963, 4, 48, 596, 581, 50, 155, 707, 1358, 1443, 345, 1455, 1411, 1123, 455, 413, 323, 12048, 483, 366, 4850, 14, 6215, 9488, 653, 266, 82, 337, 1023, 371, 521, 263, 204, 62, 78, 99, 191, 28, 7, 689, 65, 13, 4850, 269, 266, 82, 337, 1023, 77, 12043, 770, 137, 4, 47, 699, 506, 101, 361, 201, 9, 826, 52, 4177, 756, 387, 369, 52, 4, 297, 413, 86, 763, 27, 247, 98, 3887, 444, 48, 29, 247, 98, 629, 163, 868, 25, 506, 101, 361, 4, 79, 87, 326, 378, 290, 377, 101, 565, 4, 596, 581, 50, 8, 65, 314, 73, 5, 1123, 1600, 413, 323, 12043, 153, 187, 58, 512, 5, 1512, 73, 1664, 565, 135, 517, 57, 41, 5, 10, 385, 120, 1512, 73, 369, 52, 4, 48, 22, 9, 344, 813, 912, 101, 12, 5, 754, 2337, 6, 754, 2880, 43, 702, 96, 792, 207, 4, 510, 735, 541, 1101, 1989, 21, 4, 175, 2873, 1600, 101, 207, 263, 1308, 1158, 4, 84, 195, 175, 29, 1512, 73, 101, 2873, 1600, 263, 217, 37, 262, 82, 691, 736, 12043, 2]
[0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1]
1
[(0, 0), (0, 1), (1, 2), (2, 3), (3, 4), (4, 5), (5, 6), (6, 7), (7, 8), (8, 9), (9, 10), (0, 0), (0, 1), (1, 2), (2, 3), (3, 4), (4, 5), (5, 6), (6, 7), (7, 8), (8, 9), (9, 10), (10, 11), (11, 12), (12, 13), (13, 14), (14, 15), (15, 16), (16, 17), (17, 18), (18, 19), (19, 20), (20, 21), (21, 22), (22, 23), (23, 24), (24, 25), (25, 26), (26, 27), (27, 28), (28, 29), (29, 30), (30, 31), (31, 32), (32, 33), (33, 34), (34, 35), (35, 36), (36, 37), (37, 38), (38, 39), (39, 40), (40, 41), (41, 42), (42, 43), (43, 44), (44, 45), (45, 46), (46, 47), (47, 48), (48, 49), (49, 50), (50, 51), (51, 52), (52, 53), (53, 54), (54, 55), (55, 56), (56, 57), (57, 58), (58, 59), (59, 60), (60, 61), (61, 62), (62, 63), (63, 64), (64, 65), (65, 66), (66, 67), (67, 68), (68, 69), (69, 70), (70, 71), (71, 72), (72, 73), (73, 74), (74, 75), (75, 76), (76, 77), (77, 78), (78, 79), (79, 80), (80, 81), (82, 83), (83, 84), (84, 85), (85, 86), (86, 87), (87, 88), (88, 89), (89, 90), (90, 91), (91, 92), (92, 93), (93, 94), (94, 95), (95, 96), (96, 97), (97, 98), (98, 99), (99, 100), (100, 101), (101, 102), (102, 103), (103, 104), (104, 105), (105, 106), (106, 107), (107, 108), (108, 109), (109, 110), (110, 111), (111, 112), (112, 113), (113, 114), (114, 115), (115, 116), (116, 117), (117, 118), (118, 119), (119, 120), (120, 121), (121, 122), (122, 123), (123, 124), (124, 125), (125, 126), (126, 127), (127, 128), (128, 129), (129, 130), (130, 131), (131, 132), (132, 133), (133, 134), (134, 135), (135, 136), (136, 137), (137, 138), (138, 139), (139, 140), (140, 141), (141, 142), (142, 143), (143, 144), (144, 145), (145, 146), (146, 147), (147, 148), (148, 149), (149, 150), (150, 151), (151, 152), (152, 153), (153, 154), (154, 155), (155, 156), (156, 157), (157, 158), (158, 159), (159, 160), (160, 161), (161, 162), (162, 163), (163, 164), (164, 165), (165, 166), (166, 167), (167, 168), (168, 169), (169, 170), (170, 171), (171, 172), (172, 173), (173, 174), (174, 175), (175, 176), (176, 177), (177, 178), (178, 179), (179, 180), (180, 181), (181, 182), (182, 183), (183, 184), (184, 185), (185, 186), (186, 187), (187, 188), (188, 189), (189, 190), (190, 191), (191, 193), (193, 194), (194, 196), (196, 197), (197, 198), (198, 199), (199, 200), (200, 201), (201, 202), (202, 203), (203, 204), (204, 205), (205, 206), (206, 207), (207, 208), (208, 209), (209, 210), (210, 211), (211, 212), (212, 213), (213, 214), (214, 215), (215, 217), (217, 218), (218, 220), (220, 221), (221, 222), (222, 223), (223, 224), (224, 225), (225, 226), (226, 227), (227, 228), (228, 229), (229, 230), (230, 231), (231, 232), (232, 233), (233, 234), (234, 235), (235, 236), (236, 237), (237, 238), (238, 239), (239, 241), (241, 242), (242, 243), (243, 244), (244, 245), (245, 246), (246, 247), (247, 248), (248, 249), (249, 250), (250, 251), (251, 252), (252, 253), (253, 254), (254, 255), (255, 256), (256, 257), (257, 258), (258, 259), (259, 260), (260, 264), (264, 265), (265, 266), (266, 267), (267, 268), (268, 269), (269, 270), (270, 271), (271, 272), (272, 273), (273, 274), (274, 275), (275, 276), (276, 279), (279, 280), (280, 281), (281, 282), (282, 283), (283, 284), (284, 285), (285, 286), (286, 287), (287, 288), (288, 289), (289, 290), (290, 291), (291, 292), (292, 293), (293, 294), (294, 295), (295, 296), (296, 297), (297, 298), (298, 299), (299, 300), (300, 301), (301, 302), (302, 303), (303, 304), (304, 305), (305, 306), (306, 307), (307, 308), (308, 309), (309, 310), (310, 311), (311, 312), (312, 313), (313, 314), (314, 315), (315, 316), (316, 317), (317, 318), (318, 319), (319, 320), (320, 321), (321, 322), (322, 323), (323, 324), (324, 325), (325, 326), (326, 327), (327, 328), (328, 329), (329, 330), (330, 331), (331, 332), (332, 333), (333, 334), (334, 335), (335, 336), (336, 337), (337, 338), (338, 339), (339, 340), (340, 341), (341, 342), (342, 343), (343, 344), (344, 345), (345, 346), (346, 347), (347, 348), (348, 349), (349, 350), (350, 351), (351, 352), (352, 353), (353, 354), (354, 355), (355, 356), (356, 357), (357, 358), (358, 359), (359, 360), (360, 361), (361, 362), (362, 363), (363, 364), (364, 365), (365, 366), (366, 367), (367, 368), (368, 369), (369, 370), (370, 371), (371, 372), (372, 373), (373, 374), (374, 375), (375, 376), (376, 377), (377, 378), (378, 379), (379, 380), (380, 381), (381, 382), (382, 383), (383, 384), (384, 385), (385, 386), (386, 387), (387, 388), (388, 389), (0, 0)]
121
122
从以上结果可以看出,数据集中的example已经被转换成了模型可以接收的feature,包括input_ids、token_type_ids、答案的起始位置等信息。
其中:
input_ids: 表示输入文本的token ID。token_type_ids: 表示对应的token属于输入的问题还是答案。(Transformer类预训练模型支持单句以及句对输入)。overflow_to_sample: feature对应的example的编号。offset_mapping: 每个token的起始字符和结束字符在原文中对应的index(用于生成答案文本)。start_positions: 答案在这个feature中的开始位置。end_positions: 答案在这个feature中的结束位置。
数据处理的详细过程请参见utils.py。
更多有关数据处理的内容,请参考数据处理。
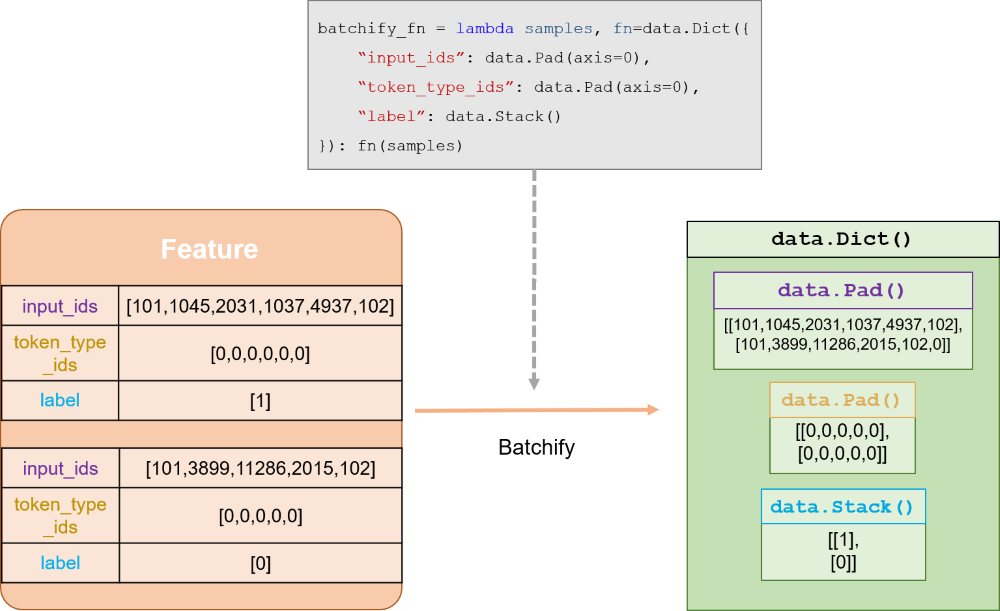
4. Batchify和数据读入
使用paddle.io.BatchSampler和paddlenlp.data中提供的方法把数据组成batch。
然后使用paddle.io.DataLoader接口多线程异步加载数据。
batchify_fn详解:
import paddle
from paddlenlp.data import Stack, Dict, Pad
batch_size = 12
# 定义BatchSampler
train_batch_sampler = paddle.io.DistributedBatchSampler(
train_ds, batch_size=batch_size, shuffle=True)
dev_batch_sampler = paddle.io.BatchSampler(
dev_ds, batch_size=batch_size, shuffle=False)
test_batch_sampler = paddle.io.BatchSampler(
test_ds, batch_size=batch_size, shuffle=False)
# 定义batchify_fn
train_batchify_fn = lambda samples, fn=Dict({
"input_ids": Pad(axis=0, pad_val=tokenizer.pad_token_id),
"token_type_ids": Pad(axis=0, pad_val=tokenizer.pad_token_type_id),
"start_positions": Stack(dtype="int64"),
"end_positions": Stack(dtype="int64")
}): fn(samples)
dev_batchify_fn = lambda samples, fn=Dict({
"input_ids": Pad(axis=0, pad_val=tokenizer.pad_token_id),
"token_type_ids": Pad(axis=0, pad_val=tokenizer.pad_token_type_id)
}): fn(samples)
# 构造DataLoader
train_data_loader = paddle.io.DataLoader(
dataset=train_ds,
batch_sampler=train_batch_sampler,
collate_fn=train_batchify_fn,
return_list=True)
dev_data_loader = paddle.io.DataLoader(
dataset=dev_ds,
batch_sampler=dev_batch_sampler,
collate_fn=dev_batchify_fn,
return_list=True)
test_data_loader = paddle.io.DataLoader(
dataset=test_ds,
batch_sampler=test_batch_sampler,
collate_fn=dev_batchify_fn,
return_list=True)
更多PaddleNLP内置的batchify相关API,请参考collate。
到这里数据集准备就全部完成了,下一步我们需要组网并设计loss function。

模型结构
使用PaddleNLP一键加载预训练模型
以下项目以ERNIE为例,介绍如何将预训练模型Fine-tune完成DuReaderrobust阅读理解任务。
DuReaderrobust阅读理解任务的本质是答案抽取任务。根据输入的问题和文章,从预训练模型的sequence_output中预测答案在文章中的起始位置和结束位置。原理如下图所示:
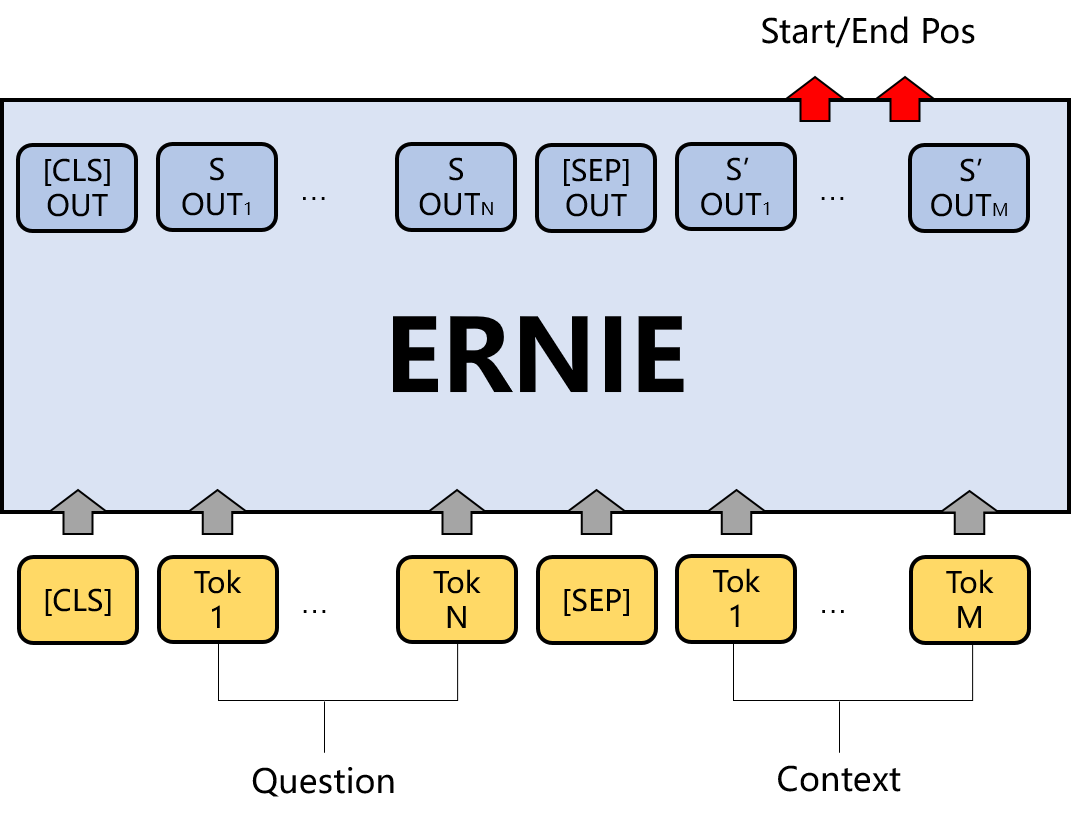
目前PaddleNLP已经内置了包括ERNIE在内的多种基于预训练模型的常用任务的下游网络,包括机器阅读理解。
这些网络在paddlenlp.transformers下,均可实现一键调用。
from paddlenlp.transformers import ErnieForQuestionAnswering
model = ErnieForQuestionAnswering.from_pretrained(MODEL_NAME)
[2021-08-25 10:59:19,803] [ INFO] - Downloading https://paddlenlp.bj.bcebos.com/models/transformers/ernie/ernie_v1_chn_base.pdparams and saved to /home/aistudio/.paddlenlp/models/ernie-1.0
[2021-08-25 10:59:19,806] [ INFO] - Downloading ernie_v1_chn_base.pdparams from https://paddlenlp.bj.bcebos.com/models/transformers/ernie/ernie_v1_chn_base.pdparams
100%|██████████| 392507/392507 [00:05<00:00, 69764.95it/s]
设计loss function
模型的网络结构确定后我们就可以设计loss function了。
ErineForQuestionAnswering模型对将ErnieModel的sequence_output拆开成start_logits和end_logits输出,所以DuReaderrobust的loss由start_loss和end_loss两部分组成,我们需要自己定义loss function。
对于答案起始位置和结束位置的预测可以分别看成两个分类任务。所以设计的loss function如下:
class CrossEntropyLossForRobust(paddle.nn.Layer):
def __init__(self):
super(CrossEntropyLossForRobust, self).__init__()
def forward(self, y, label):
start_logits, end_logits = y
start_position, end_position = label
start_position = paddle.unsqueeze(start_position, axis=-1)
end_position = paddle.unsqueeze(end_position, axis=-1)
start_loss = paddle.nn.functional.cross_entropy(
input=start_logits, label=start_position)
end_loss = paddle.nn.functional.cross_entropy(
input=end_logits, label=end_position)
loss = (start_loss + end_loss) / 2
return loss
选择网络结构后,我们需要设置Fine-Tune优化策略。

设置Fine-Tune优化策略
适用于ERNIE/BERT这类Transformer模型的学习率为warmup的动态学习率。

# 训练过程中的最大学习率
learning_rate = 3e-5
# 训练轮次
epochs = 2
# 学习率预热比例
warmup_proportion = 0.1
# 权重衰减系数,类似模型正则项策略,避免模型过拟合
weight_decay = 0.01
num_training_steps = len(train_data_loader) * epochs
# 学习率衰减策略
lr_scheduler = paddlenlp.transformers.LinearDecayWithWarmup(learning_rate, num_training_steps, warmup_proportion)
decay_params = [
p.name for n, p in model.named_parameters()
if not any(nd in n for nd in ["bias", "norm"])
]
optimizer = paddle.optimizer.AdamW(
learning_rate=lr_scheduler,
parameters=model.parameters(),
weight_decay=weight_decay,
apply_decay_param_fun=lambda x: x in decay_params)
现在万事俱备,我们可以开始训练阅读理解模型啦。

模型训练与评估
模型训练的过程通常有以下步骤:
- 从dataloader中取出一个batch data。
- 将batch data喂给model,做前向计算。
- 将前向计算结果传给损失函数,计算loss。
- loss反向回传,更新梯度。重复以上步骤。
每训练一个epoch时,程序通过evaluate()调用paddlenlp.metric.squad中的squad_evaluate(), compute_predictions()评估当前模型训练的效果,其中:
-
compute_predictions()用于生成可提交的答案;
-
squad_evaluate()用于返回评价指标。
二者适用于所有符合squad数据格式的答案抽取任务。这类任务使用F1和exact来评估预测的答案和真实答案的相似程度。
from utils import evaluate
criterion = CrossEntropyLossForRobust()
global_step = 0
for epoch in range(1, epochs + 1):
for step, batch in enumerate(train_data_loader, start=1):
global_step += 1
input_ids, segment_ids, start_positions, end_positions = batch
logits = model(input_ids=input_ids, token_type_ids=segment_ids)
loss = criterion(logits, (start_positions, end_positions))
if global_step % 100 == 0 :
print("global step %d, epoch: %d, batch: %d, loss: %.5f" % (global_step, epoch, step, loss))
loss.backward()
optimizer.step()
lr_scheduler.step()
optimizer.clear_grad()
evaluate(model=model, data_loader=dev_data_loader)
global step 100, epoch: 1, batch: 100, loss: 4.74704
global step 200, epoch: 1, batch: 200, loss: 1.81868
global step 300, epoch: 1, batch: 300, loss: 1.15884
global step 400, epoch: 1, batch: 400, loss: 1.60474
global step 500, epoch: 1, batch: 500, loss: 1.21233
global step 600, epoch: 1, batch: 600, loss: 1.64146
global step 700, epoch: 1, batch: 700, loss: 1.63286
global step 800, epoch: 1, batch: 800, loss: 1.33980
global step 900, epoch: 1, batch: 900, loss: 1.03344
global step 1000, epoch: 1, batch: 1000, loss: 1.06277
global step 1100, epoch: 1, batch: 1100, loss: 1.07185
global step 1200, epoch: 1, batch: 1200, loss: 1.47855
global step 1300, epoch: 1, batch: 1300, loss: 0.90132
global step 1400, epoch: 1, batch: 1400, loss: 0.84292
global step 1500, epoch: 2, batch: 28, loss: 0.61762
global step 1600, epoch: 2, batch: 128, loss: 0.77899
global step 1700, epoch: 2, batch: 228, loss: 0.97447
global step 1800, epoch: 2, batch: 328, loss: 0.58711
global step 1900, epoch: 2, batch: 428, loss: 0.53401
global step 2000, epoch: 2, batch: 528, loss: 0.50683
global step 2100, epoch: 2, batch: 628, loss: 1.62025
global step 2200, epoch: 2, batch: 728, loss: 0.24940
global step 2300, epoch: 2, batch: 828, loss: 0.63583
global step 2400, epoch: 2, batch: 928, loss: 1.13538
global step 2500, epoch: 2, batch: 1028, loss: 1.31787
global step 2600, epoch: 2, batch: 1128, loss: 1.21098
global step 2700, epoch: 2, batch: 1228, loss: 0.51721
global step 2800, epoch: 2, batch: 1328, loss: 0.75630
global step 2900, epoch: 2, batch: 1428, loss: 0.71678
Processing example: 1000
time per 1000: 10.412069320678711
{
"exact": 71.84191954834156,
"f1": 85.9847378130661,
"total": 1417,
"HasAns_exact": 71.84191954834156,
"HasAns_f1": 85.9847378130661,
"HasAns_total": 1417
}
问题: 爬行垫什么材质的好
原文: 爬行垫根据中间材料的不同可以分为:XPE爬行垫、EPE爬行垫、EVA爬行垫、PVC爬行垫;其中XPE爬行垫、EPE爬行垫都属于PE材料加保鲜膜复合而成,都是无异味的环保材料,但是XPE爬行垫是品质较好的爬行垫,韩国进口爬行垫都是这种爬行垫,而EPE爬行垫是国内厂家为了减低成本,使用EPE(珍珠棉)作为原料生产的一款爬行垫,该材料弹性差,易碎,开孔发泡防水性弱。EVA爬行垫、PVC爬行垫是用EVA或PVC作为原材料与保鲜膜复合的而成的爬行垫,或者把图案转印在原材料上,这两款爬行垫通常有异味,如果是图案转印的爬行垫,油墨外露容易脱落。 当时我儿子爬的时候,我们也买了垫子,但是始终有味。最后就没用了,铺的就的薄毯子让他爬。
答案: XPE
问题: 范冰冰多高真实身高
原文: 真实情况是160-162。她平时谎报的168是因为不离脚穿高水台恨天高(15厘米) 图1她穿着高水台恨天高和刘亦菲一样高,(刘亦菲对外报身高172)范冰冰礼服下厚厚的高水台暴露了她的心机,对比一下两者的鞋子吧 图2 穿着高水台恨天高才和刘德华谢霆锋持平,如果她真的有168,那么加上鞋高,刘和谢都要有180?明显是不可能的。所以刘德华对外报的身高174减去10-15厘米才是范冰冰的真实身高 图3,范冰冰有一次脱鞋上场,这个最说明问题了,看看她的身体比例吧。还有目测一下她手上鞋子的鞋跟有多高多厚吧,至少超过10厘米。
答案: 160-162
问题: 小米6防水等级
原文: 防水作为目前高端手机的标配,特别是苹果也支持防水之后,国产大多数高端旗舰手机都已经支持防水。虽然我们真的不会故意把手机放入水中,但是有了防水之后,用户心里会多一重安全感。那么近日最为火热的小米6防水吗?小米6的防水级别又是多少呢? 小编查询了很多资料发现,小米6确实是防水的,但是为了保持低调,同时为了不被别人说防水等级不够,很多资料都没有标注小米是否防水。根据评测资料显示,小米6是支持IP68级的防水,是绝对能够满足日常生活中的防水需求的。
答案: IP68级
问题: 怀孕多久会有反应
原文: 这位朋友你好,女性出现妊娠反应一般是从6-12周左右,也就是女性怀孕1个多月就会开始出现反应,第3个月的时候,妊辰反应基本结束。 而大部分女性怀孕初期都会出现恶心、呕吐的感觉,这些症状都是因人而异的,除非恶心、呕吐的非常厉害,才需要就医,否则这些都是刚怀孕的的正常症状。1-3个月的时候可以观察一下自己的皮肤,一般女性怀孕初期可能会产生皮肤色素沉淀或是腹壁产生妊娠纹,特别是在怀孕的后期更加明显。 还有很多女性怀孕初期会出现疲倦、嗜睡的情况。怀孕三个月的时候,膀胱会受到日益胀大的子宫的压迫,容量会变小,所以怀孕期间也会有尿频的现象出现。月经停止也是刚怀孕最容易出现的症状,只要是平时月经正常的女性,在性行为后超过正常经期两周,就有可能是怀孕了。 如果你想判断自己是否怀孕,可以看看自己有没有这些反应。当然这也只是多数人的怀孕表现,也有部分女性怀孕表现并不完全是这样,如果你无法确定自己是否怀孕,最好去医院检查一下。
答案: 6-12周左右,也就是女性怀孕1个多月
问题: 研发费用加计扣除比例
原文: 【东奥会计在线——中级会计职称频道推荐】根据《关于提高科技型中小企业研究开发费用税前加计扣除比例的通知》的规定,研发费加计扣除比例提高到75%。|财政部、国家税务总局、科技部发布《关于提高科技型中小企业研究开发费用税前加计扣除比例的通知》。|通知称,为进一步激励中小企业加大研发投入,支持科技创新,就提高科技型中小企业研究开发费用(以下简称研发费用)税前加计扣除比例有关问题发布通知。|通知明确,科技型中小企业开展研发活动中实际发生的研发费用,未形成无形资产计入当期损益的,在按规定据实扣除的基础上,在2017年1月1日至2019年12月31日期间,再按照实际发生额的75%在税前加计扣除;形成无形资产的,在上述期间按照无形资产成本的175%在税前摊销。|科技型中小企业享受研发费用税前加计扣除政策的其他政策口径按照《财政部国家税务总局科技部关于完善研究开发费用税前加计扣除政策的通知》(财税〔2015〕119号)规定执行。|科技型中小企业条件和管理办法由科技部、财政部和国家税务总局另行发布。科技、财政和税务部门应建立信息共享机制,及时共享科技型中小企业的相关信息,加强协调配合,保障优惠政策落实到位。|上一篇文章:关于2016年度企业研究开发费用税前加计扣除政策企业所得税纳税申报问题的公告 下一篇文章:关于提高科技型中小企业研究开发费用税前加计扣除比例的通知
答案: 75%
# 传入test_data_loader,并将is_test参数设为True,即可生成千言比赛可提交的结果。
计扣除政策企业所得税纳税申报问题的公告 下一篇文章:关于提高科技型中小企业研究开发费用税前加计扣除比例的通知
答案: 75%
```python
# 传入test_data_loader,并将is_test参数设为True,即可生成千言比赛可提交的结果。
evaluate(model=model, data_loader=test_data_loader, is_test=True)
以上基线实现基于PaddleNLP,开源不易,希望大家多多支持~
记得给PaddleNLP点个小小的Star⭐
GitHub地址:https://github.com/PaddlePaddle/PaddleNLP
更多使用方法可参考PaddleNLP教程
- 使用seq2vec模块进行句子情感分类
- 使用预训练模型ERNIE优化情感分析
- 使用BiGRU-CRF模型完成快递单信息抽取
- 使用预训练模型ERNIE优化快递单信息抽取
- 使用Seq2Seq模型完成自动对联
- 使用预训练模型ERNIE-GEN自动写诗
- 使用TCN网络完成新冠疫情病例数预测
- 自定义数据集实现文本多分类任务
加入交流群,一起学习吧
现在就加入PaddleNLP的QQ技术交流群,一起交流NLP技术吧!


学大模型,用大模型上飞桨星河社区!每天8点V100G算力免费领!免费领取ERNIE 4.0 100w Token >>>
更多推荐



 0
0 0
0- 0



 已为社区贡献1437条内容
已为社区贡献1437条内容

所有评论(0)