
【视觉 Transformer】超详细解读 T2T-ViT 模型
给 ViT 加个 Token to Token(T2T) 来引入局部先验,解决 ViT 训练依赖大数据(JFT-300M)问题 ~
T2T-ViT

paper:https://arxiv.org/abs/2101.11986
浅谈 T2T-ViT
Hi guy!我们又见面了,这次解析一篇来自新加坡国立大学的视觉 Transformer 相关工作 T2T-ViT

在 NLP 领域,Transformer 可谓是大杀四方,常见如 BERT、GPT-3 等,不少学者开始研究如何在 CV 领域去复制 NLP 领域的成功。最近Google 的论文 ViT: An Image is Worth 16x16 Words: Transformers for Image Recognition at Scale 可以说引爆了CV 圈,从此拉开了视觉 Transformer 的大航海时代

直观来看一波 ViT 的性能
| Arch | Data | ImNet Top-1 | Params |
|---|---|---|---|
| ViT-B/16 | JFT-300M | 84.15 | 86M |
| ViT-L/16 | JFT-300M | 87.12 | 307M |
| ViT-H/14 | JFT-300M | 88.04 | 632M |
尽管 ViT(Vision Transformer) 取得了不俗的成绩,但是其存在这很多弊端,其中最明显的是 Train from scratch 问题,即在中型数据集 ImageNet 上从头开始训练,ViT 的性能打不过 ConvNet 的网络
我们来分析一波,主要是因为:
- ViT 将图像分为多个 token,然后用多个 Transformer 来对全局进行建模以进行分类,但是这样会失去局部性,实际上图像的局部信息如边缘、线条和纹理等信息对视觉理解是很重要的
- ViT 的注意力骨干含有冗余,特征丰富度有限,模型训练困难
作者做了一个实验帮我们更直观理解,如下所示
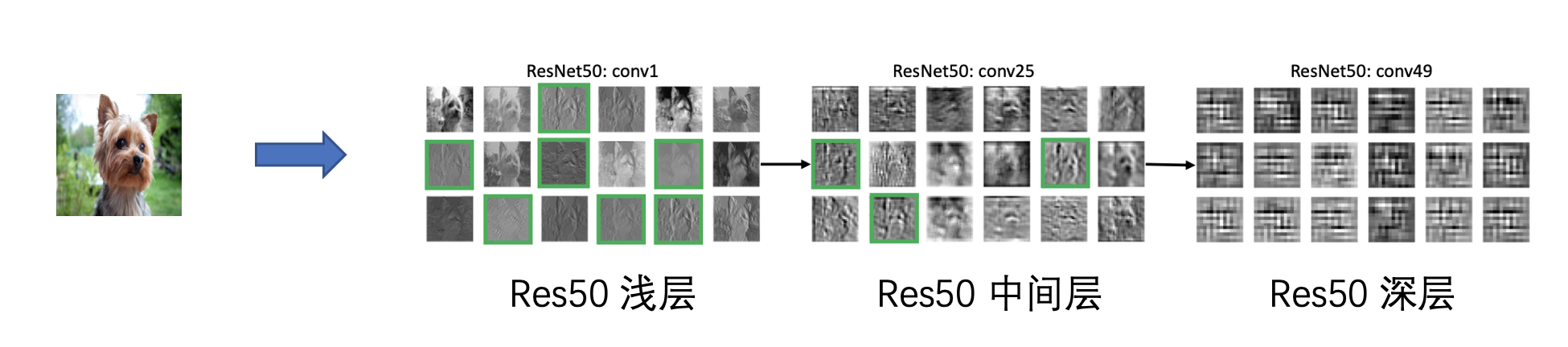
输入一张待预测的图片,如上图可爱的小狗为例子,在 ResNet50 网络里浅层和中间层都很好捕获了小狗的局部信息(边缘线条),如绿色的框所示,那么在 ViT 下情况是什么样呢?
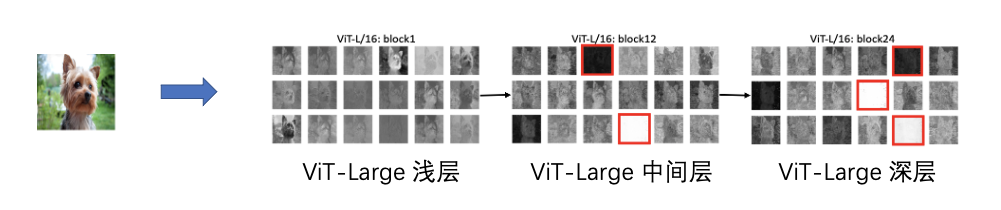
我们可以看到,经过 ViT-Large/16 网络,浅层看起来似乎没有很好捕获局部的信息,同时在中间层和深层出现了冗余特征(数值为零或过大的无效的特征图),如红色框所示,这进一步说明 ViT 网络对数据利用率存在一定的冗余,这也侧面解释了为什么视觉 Transformer 需要很多的数据量来填补这个冗余。
基于以上,作者提出了两个改进点
- 添加局部性
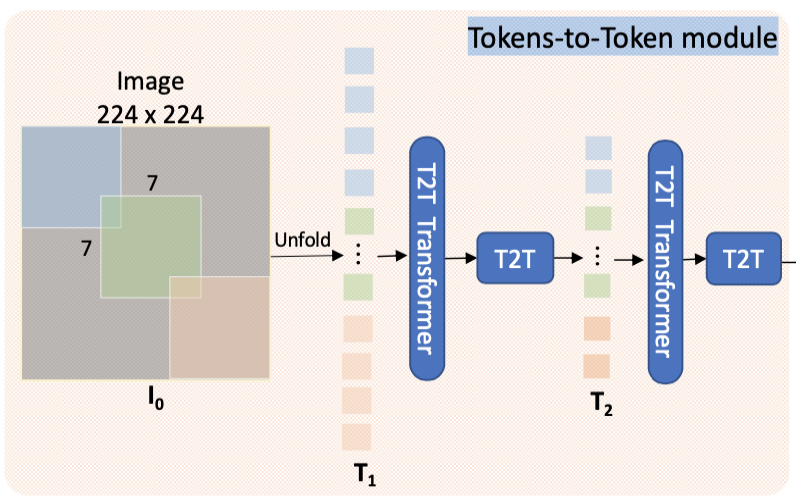
取代 ViT 的 tokenization,提出 Tokens-to-Token module,将相邻的 Tokens 聚合为一个Token(命名为Tokens-to-Token模块),它可以模拟周围 Tokens 的局部结构信息,迭代地减少 Tokens 的长度。具体来说,在每个Token-to-Token(T2T)步骤中,由 Transformer 输出的 Tokens 被重建为一个图像(re- structurization),然后通过软分割(soft spilt)将周围的 Token 分割平铺聚集在一起生成新的 Token。因此,周围的局部结构被嵌入到生成的 Token 中,并被输入到下一个Transformer 层。通过迭代进行T2T,引入了局部先验性
- 采用深窄结构
为了给 T2T-ViT 找到一个有效的骨架,我们探索借用 CNN 的一些架构设计来建立 Transformer Layer,以提高特征的丰富性,我们发现 ViT 中通道较少但层数较多的 "深-窄 "架构设计在比较模型大小和 MAC(Multi-Adds)时带来更好的性能
通过精心设计的 Transformer 架构(T2T模块和高效骨干),T2T-ViT 可以在 ImageNet 上的不同复杂度上胜过 CNN,而无需在 JFT-300M 上进行预训练。
流程解析
我们先看看整个流程图是什么样的,T2T-ViT 的流程图如下所示
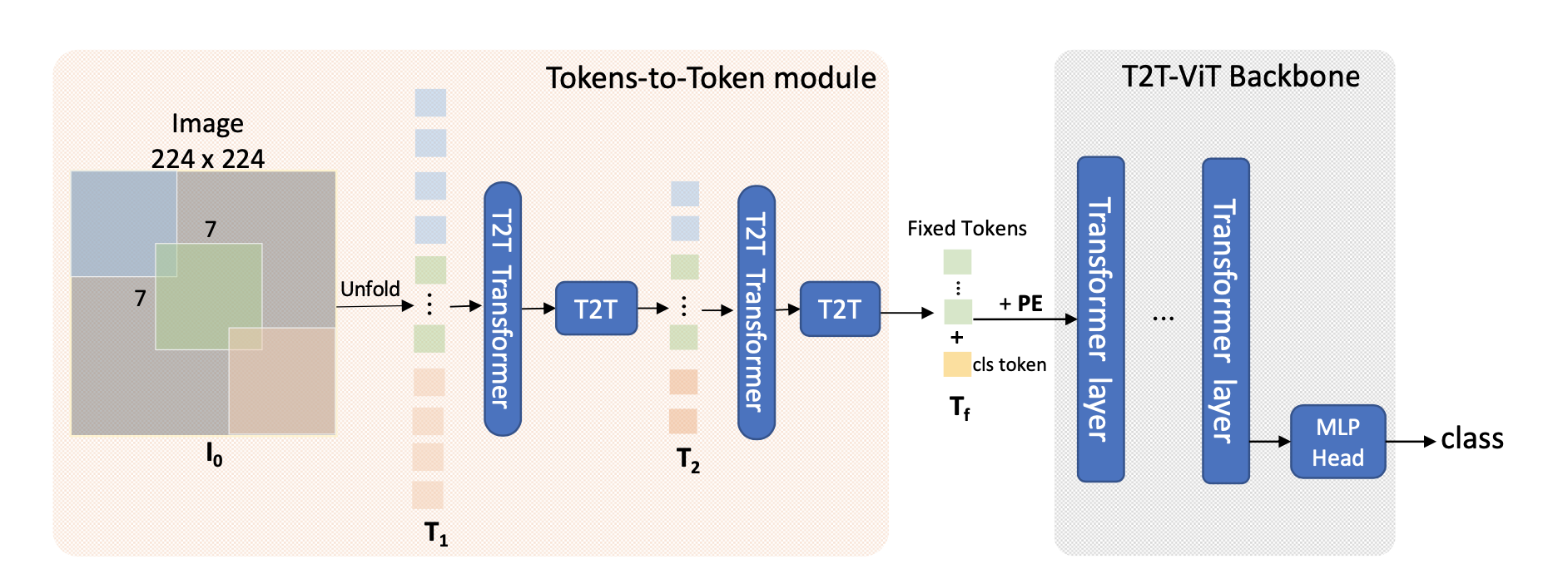
其中 Tokens-to-Token module 是本文的亮点,了解这个就等于了解 T2T-ViT 了,那么 Tokens-to-Token module 到底做了什么?为了方便大家理解,本文将手把手细推 Tokens-to-Token module 的流程,我们先看一下 forward 部分的代码
# from https://github.com/PaddlePaddle/PASSL/blob/main/passl/modeling/backbones/t2t_vit.py
class T2T_module(nn.Layer):
"""
Tokens-to-Token encoding module
"""
def __init__(self,
img_size=224,
tokens_type='performer',
in_chans=3,
embed_dim=768,
token_dim=64):
super().__init__()
def forward(self, x):
# step0: soft split
x = self.soft_split0(x).transpose([0, 2, 1])
# iteration1: re-structurization/reconstruction
x = self.attention1(x)
B, new_HW, C = x.shape
x = x.transpose([0, 2, 1]).reshape(
[B, C, int(np.sqrt(new_HW)),
int(np.sqrt(new_HW))])
# iteration1: soft split
x = self.soft_split1(x).transpose([0, 2, 1])
# iteration2: re-structurization/reconstruction
x = self.attention2(x)
B, new_HW, C = x.shape
x = x.transpose([0, 2, 1]).reshape(
[B, C, int(np.sqrt(new_HW)),
int(np.sqrt(new_HW))])
# iteration2: soft split
x = self.soft_split2(x).transpose([0, 2, 1])
# final tokens
x = self.project(x)
return x
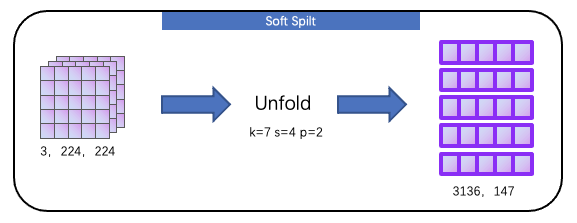
为了方便理解流程,这里不考虑 batch size,定义输入尺寸为 3, 224, 224,首先经过一次 soft split,将图像转为二维张量,这个过程利用 nn.Unfold 函数,如下所示
然后我们通过 T2T Transformer 来提取 Token 的全局信息,T2T Transformer 和 ViT 的 MSA 极其相似,都采用了 Self-Attention 结构
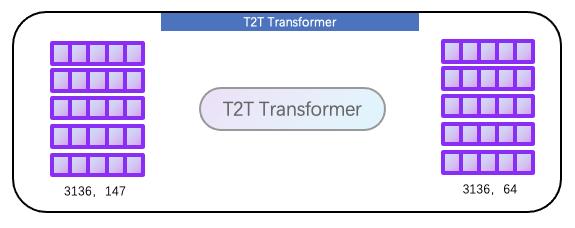
接下来就是 T2T process 部分,论文给出的流程图如下所示,其中我们目前得到的数据(size=3136, 64)对应下图的 Ti’,我们可以看见 T2T process 操作流程为Reshape+Unfold
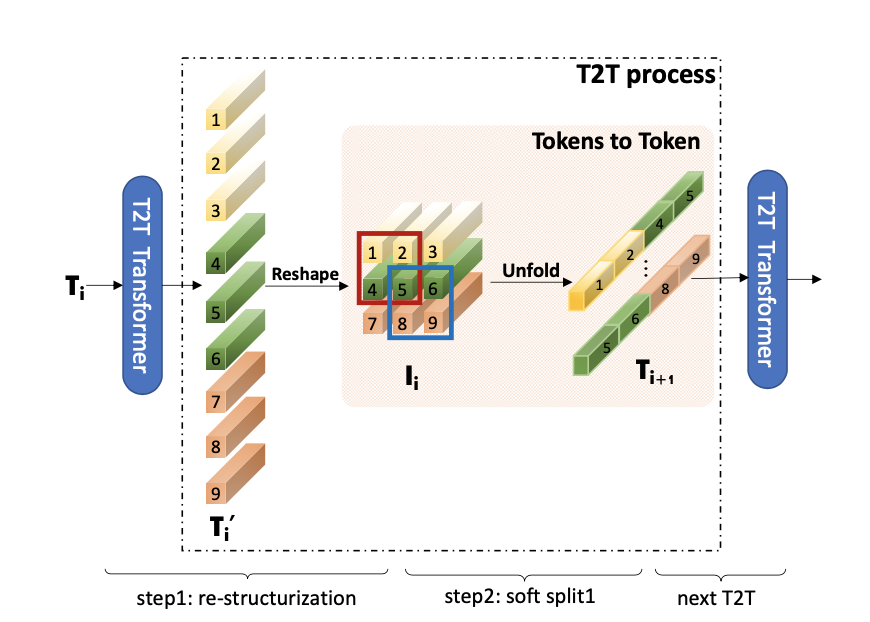
为什么要这样做呢?怎么理解上图的 Tokens to Token?
实际上 soft split 操作是用来模拟局部结构信息,作者希望建立一个先验,即周围的 Token 之间应该有更强的关联性,如上图所示,token1、token2、token4、token5 这4个 token 局部相邻,将它们通过 Unfold(soft split 操作)来融合成新的 token,如上图 Ti+1[0] 所示
T2T process 详细输出变化如下所示
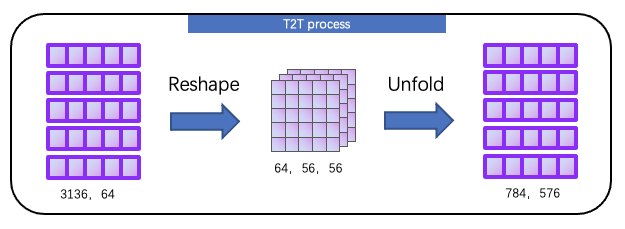
就这样,我们得到了size 为784,576的输出,再进行一次 T2T Transformer 和 T2T proccess,整体结构如下所示
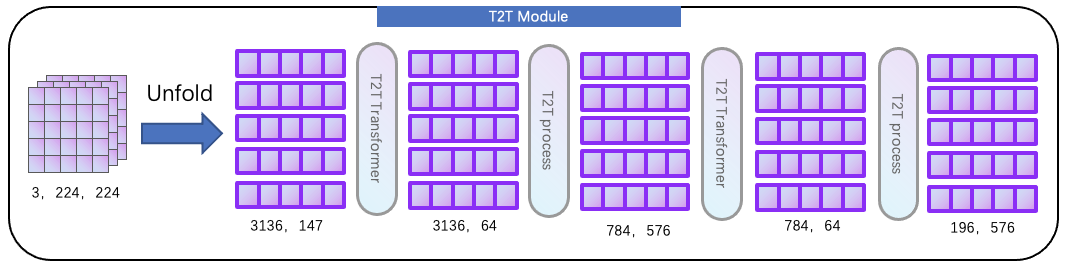
其中 T2T Transformer 用于提取全局表征,T2T process 用于引入局部先验,这两个模块交替进行特征提取,得到输出为196, 576,然后通过 Linear 得到 final token(196,576 --Linear--> 196,786)。以上步骤都是 Tokens-to-Token module 部分
接下来的操作就是和 ViT 的操作差不多了,添加 clas token 以及 pos token 进入 ViT Transformer Layer,然后提取 clas token 做分类
针对 T2T-ViT 的 Backbone 怎么设计,作者研究了Wide-ResNets(浅宽与深窄结构),DenseNet(密集连接),ResneXt结构,Ghost操作和通道衰减。发现 Deep-Narrow 结构最有效,可以大大减小参数和 MACs,而性能几乎没有下降
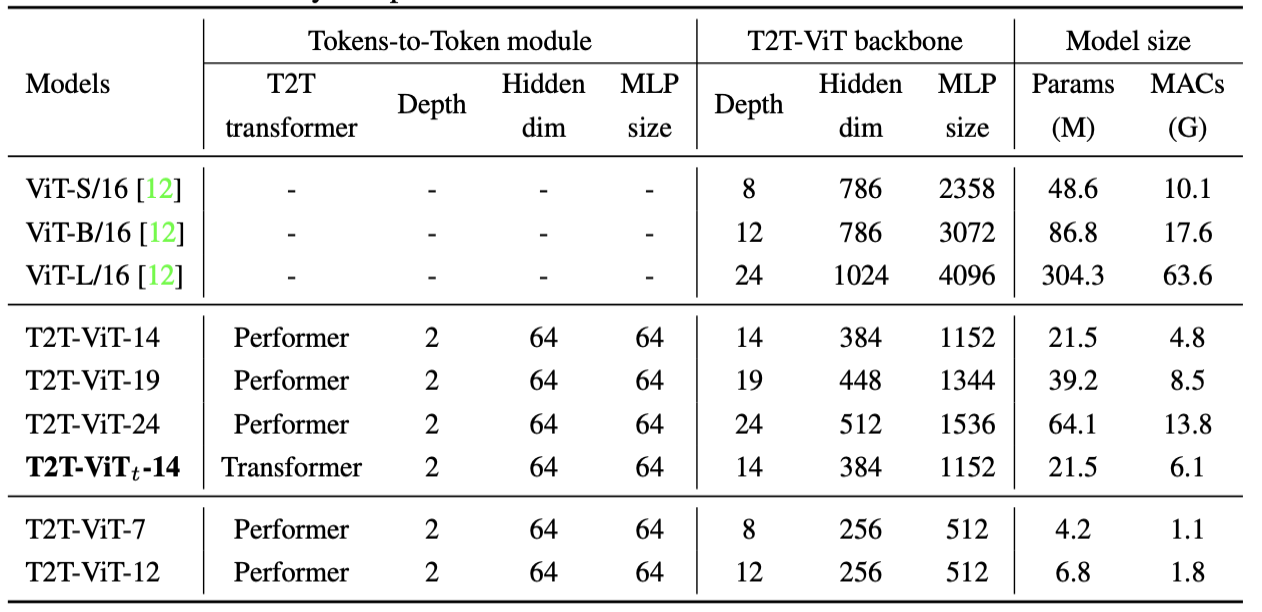
我们看一下 T2T-ViT 的性能如何
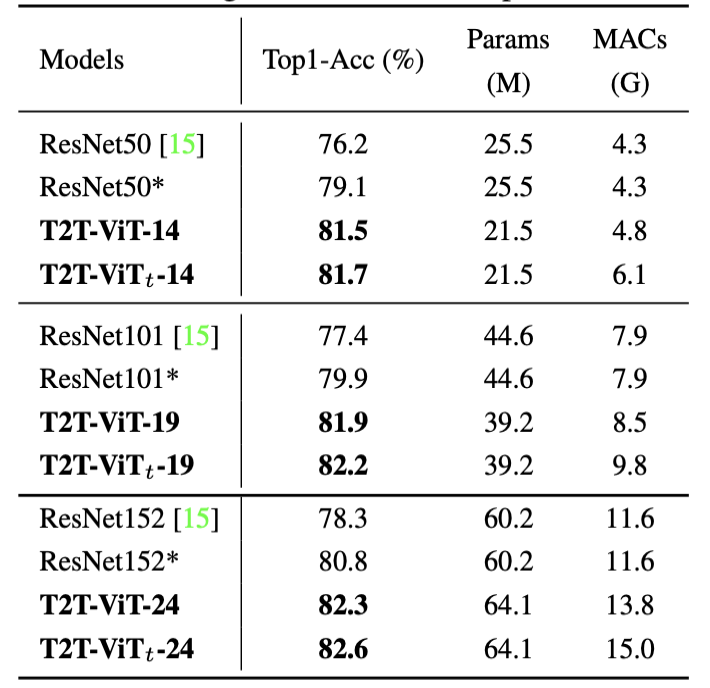
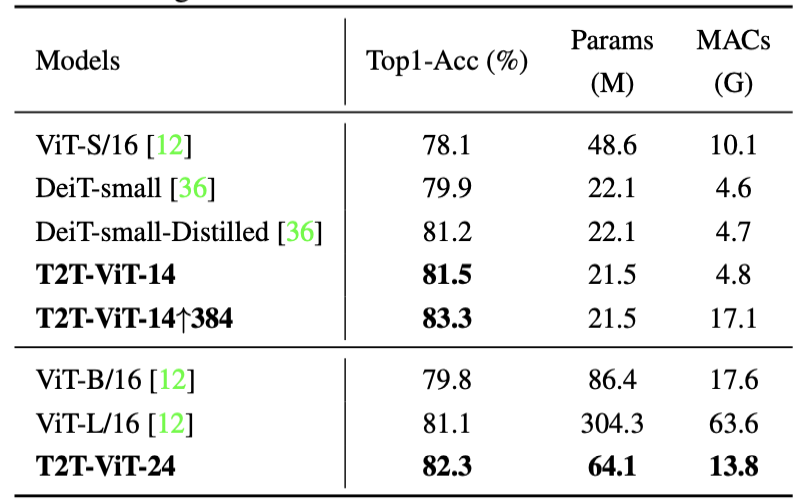
可以看见,T2T-ViT 通过引入局部先验,在 ImageNet-1K 下取得了相比 ResNet 以及 ViT、DeiT 更具竞争力的水准,更详细的细节具体看论文 Tokens-to-Token ViT: Training Vision Transformers from Scratch on ImageNet
PASSL 已支持 T2T-ViT
PASSL 包含 SimCLR、MoCo v1/v2、BYOL、CLIP 等基于对比学习的图像自监督算法以及 Vision Transformer、Swin Transformer、BEiT、CvT、T2T-ViT、MLP-Mixer 等视觉 Transformer 及相关算法,欢迎 star ~
PASSL github:https://github.com/PaddlePaddle/PASSL
T2T-ViT 性能
The results are evaluated on ImageNet2012 validation set
| Arch | Weight | Top-1 Acc | Top-5 Acc | Crop ratio | # Params |
|---|---|---|---|---|---|
| t2t_vit_14 | pretrain 1k | 81.50 | 95.67 | 0.9 | 21.5M |
| t2t_vit_19 | pretrain 1k | 81.93 | 95.74 | 0.9 | 39.1M |
| t2t_vit_24 | pretrain 1k | 82.28 | 95.89 | 0.9 | 64.0M |
| t2t_vit_t_14 | pretrain 1k | 81.69 | 95.85 | 0.9 | 21.5M |
| t2t_vit_t_19 | pretrain 1k | 82.44 | 96.08 | 0.9 | 39.1M |
| t2t_vit_t_24 | pretrain 1k | 82.55 | 96.07 | 0.9 | 64.0M |
更详细内容可见:https://github.com/PaddlePaddle/PASSL/tree/main/configs/t2t_vit
!git clone https://github.com/PaddlePaddle/PASSL.git # 克隆 PASSL,连不上多试几次
!pip install ftfy # 安装依赖
!pip install regex # 安装依赖
%cd PASSL
import paddle
from passl.modeling.backbones import build_backbone
from passl.modeling.heads import build_head
from passl.utils.config import get_config
class Model(paddle.nn.Layer):
def __init__(self, cfg_file):
super().__init__()
cfg = get_config(cfg_file)
self.backbone = build_backbone(cfg.model.architecture)
self.head = build_head(cfg.model.head)
def forward(self, x):
x = self.backbone(x)
x = self.head(x)
return x
cfg_file = 'configs/t2t_vit/t2t_vit_14.yaml' # T2T-ViT 配置文件
m = Model(cfg_file) # 模型组网
x = paddle.randn([2, 3, 224, 224]) # test
out = m(x)
loss = out.sum()
loss.backward()
print('Single iteration completed successfully')
总结
ViT 架构一定完美吗?
相比经过不少研究者精心雕琢的 CNN 网络来说,ViT 的架构更像是一个大力出奇迹的结构,因为缺少归纳偏置以及各种先验,只要上大量数据和算力就能跑出很好的结果,简单粗暴。但是在数据量不充足的条件下,ViT进一步限制了其性能,需要从 CNN 网络中学习一些经验来帮助提升其下限。

学大模型,用大模型上飞桨星河社区!每天8点V100G算力免费领!免费领取ERNIE 4.0 100w Token >>>
更多推荐


 5
5 0
0- 0



 已为社区贡献1438条内容
已为社区贡献1438条内容

所有评论(0)