
飞桨常规赛:视杯视盘分割(GAMMA挑战赛任务三) - 11月第6名方案
分数: 8.08+ 飞桨常规赛:视杯视盘分割(GAMMA挑战赛任务三) - 11月第6名方案
常规赛:视杯视盘分割(GAMMA挑战赛任务三) 11月-第六名方案
赛题简述
GAMMA挑战赛释放了两种模态的眼底影像数据对,并且有青光眼分级标签、视杯视盘分割标签、黄斑中央凹坐标标签。
青光眼是一种慢性神经退行性疾病,是世界上不可逆转但可预防的失明的主要原因之一。青光眼有许多变种,其特征是视神经盘受损,通常由高眼压引起。眼压升高是由于眼内房水异常积累的结果,是由眼排水系统的病理性缺陷引起的。当前段被这种液体饱和时,眼压逐渐升高,将玻璃体压向视网膜。如果这种情况继续不受控制,就会对神经纤维层、脉管系统和视神经盘造成损害,导致进行性和不可逆转的视力丧失,最终导致失明。

视神经盘,简称视盘,是视网膜上视觉纤维汇集穿出眼球的部位,是视神经的始端。视盘有一个生理凹陷,即视杯。视盘和视杯是眼底重要的生理结构,当视盘出现出血、盘沿变薄、血管屈膝、杯盘比扩大等体征时,极可能发生青光眼病变。除了视盘,眼底另一重要结构是黄斑。黄斑在视盘的颞侧0.35cm处并稍下方,处于人眼的光学中心区。黄斑中央的凹陷称为中央凹,是视力最敏锐的地方。
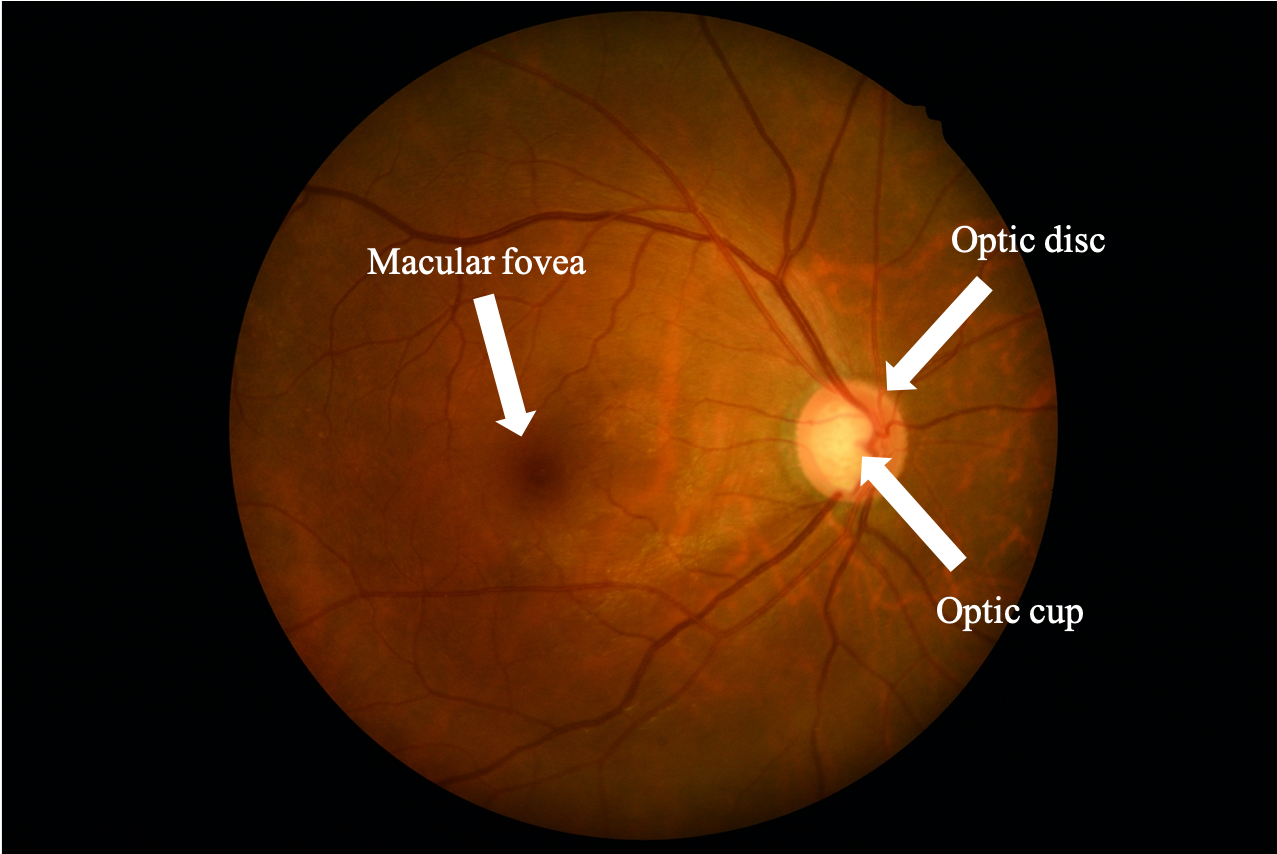
本项挑战赛的目的是促使医学图像分析社区共同开发基于多模态影像的青光眼自动分级方法,以及基于眼底图像的视盘/视杯分割、黄斑中央凹定位方法。同时,本次挑战赛给出了统一的测评框架和数据集,可对青光眼检测、黄斑中央凹定位和视盘/杯分割已有算法进行评估和比较。
训练数据集
文件名称:task3_disc_cup_segmentation中的training文件夹
training里有两个文件夹,一个是fundus color images,一个是Disc_Cup_Masks 。
训练集; 训练数据集包括100个样本0001-0100,每个样本对应一个2D眼底彩照数据,存储为0001.jpg。
视杯视盘分割金标准以bmp图像格式存储,每个样本的眼底图像对应一个视杯视盘分割结果图像。分割结果图像命名与输入的待分割眼底图像命名前缀一致。分割图像中,像素值为0代表视杯区域、像素值为128代表视盘中非视杯区域、像素值为255代表其他区域。所有样本的分割图像存储在 Disc_Cup_Masks 文件夹中。
测试数据集
文件夹名称:testing/fundus color images
压缩包里包含200张眼底彩照,命名形如0200.jpg。
提交方式*
视杯视盘分割结果存储在Disc_Cup_Segmentations文件夹中,每个样本的分割结果以bmp图像格式存储。每个样本的眼底图像对应一个视杯视盘分割结果图像。分割结果图像命名与输入的待分割眼底图像命名前缀一致。分割图像中,像素值为0代表视杯区域、像素值为128代表视盘中非视杯区域、像素值为255代表其他区域。
zip结果提交:参赛者将Disc_Cup_Segmentations文件夹以zip格式打包,将打包后的压缩包提交到AI Studio平台,平台将进行在线评分,实时排名。
毎个参赛队伍每天最多可以提交5次在线评测,提交额度用尽后,当日无法再提交;
参赛者历史提交结果将在本页下方展示,但排行榜页内仅显示该参赛者历史最佳成绩(如果新提交结果好于之前提交结果,该参赛者在排行榜中成绩将自动进行更新覆盖。反之,排行榜中成绩保持不变)。
方案内容
-
解压数据
– # 解压数据集
-
数据标签预处理与数据划分
– # 转换标签
– # 划分数据
-
利用PaddleSeg高层API加速赛题开发与测试
– # 实现数据增强
水平翻转,垂直翻转,随机扭曲,高斯模糊,随机缩放,图像标准化。因为眼底彩照尺寸较大,输入尺寸调大可以提升一点精度。
– # 实现训练流程
尝试UNet、BiSeNetV2网络。在本项目上BiSeNetV2网络收敛快,且精度不比UNet低多少,我觉得该网络在眼部影像分割上有一定优势。
学习率策略与优化器:CosineAnnealingDecay + Adamw。这是我在分割项目上的常用组合,Adamw解决了Adam L2正则化失效的问题。
– # 实现预测流程
-
完成结果提交 – 基线方案为8.08+的得分(DISC_DICE:0.93509 , CUP_DICE:0.85377 , vCDR:0.04924 ),可从训练迭代次数、损失函数、模型入手
测试记录
如果你喜欢我的测试记录,并认为这个项目和记录对你有帮助,欢迎在之后的版本中也更新并公开你的测试记录~
| Index | 版本 | score | disc | cup | vCDR | 备注 |
|---|---|---|---|---|---|---|
| 0 | 版本0 | 8.08043 | 0.9429 | 0.84968 | 0.05037 | 翻转 形变 模糊 缩放 Adam 2048*2048 |
| 1 | 版本1 | 8.08743 | 0.93509 | 0.85377 | 0.04924 | 翻转 形变 模糊 缩放 AdamW 2048*2048 |
一、解压数据
! wget https://dataset-bj.cdn.bcebos.com/%E5%8C%BB%E7%96%97%E6%AF%94%E8%B5%9B/task3_disc_cup_segmentation.zip
! unzip -oq /home/aistudio/task3_disc_cup_segmentation.zip
1.1导入依赖
!pip install paddleseg
#导入常用的库
import os
import random
import numpy as np
from random import shuffle
import cv2
import paddle
from PIL import Image
import shutil
import re
from paddle.vision.transforms import functional as F
import os.path
import paddleseg.transforms as T
from paddleseg.datasets import Dataset
from paddleseg.core import train
from paddleseg.core import evaluate
from paddleseg.core import predict
from PIL import Image
import paddleseg
二、数据标签预处理与数据划分
PaddleSeg需要使用txt文档指定训练信息,同样要求训练标签从0,1,2开始编号。
2.1数据标签预处理
# 转化训练标签到指定格式
! mkdir training/mask
for item in os.listdir('training/Disc_Cup_Mask'):
im=Image.open('training/Disc_Cup_Mask/'+item)
im=(np.array(im).astype(float)/255*2).astype(int).astype('uint8')
im = Image.fromarray(im)
im.save('training/mask/'+item)
# 观察图片尺寸
try:
os.rename('/home/aistudio/training/fundus color images/','/home/aistudio/training/fundus_color_images/')
except:
print('have renamed')
names = [item.split('.')[0] for item in os.listdir('training/fundus_color_images')]
img_dir='/home/aistudio/training/fundus_color_images/'
mask_dir='/home/aistudio/training/mask/'
for name in names:
im=Image.open(img_dir+name+'.jpg')
print(np.array(im).shape)
# 生成对应的图片-标签数据
try:
os.rename('/home/aistudio/training/fundus color images/','/home/aistudio/training/fundus_color_images/')
except:
print('have renamed')
names = [item.split('.')[0] for item in os.listdir('training/fundus_color_images')]
ori_train_list=[]
img_dir='/home/aistudio/training/fundus_color_images/'
mask_dir='/home/aistudio/training/mask/'
for name in names:
if os.path.exists(img_dir+name+'.jpg') and os.path.exists(mask_dir+name+'.png'):
ori_train_list.append(img_dir+name+'.jpg '+mask_dir+name+'.png'+'\n')
2.2 数据集划分
# 生成txt文档
cut_percent=0.1
cut_point=int(cut_percent*len(ori_train_list))
random.shuffle(ori_train_list)
with open('train.txt','w') as f:
for item in ori_train_list[cut_point:]:
f.write(item)
with open('eval.txt','w') as f:
for item in ori_train_list[:cut_point]:
f.write(item)
三、利用PaddleSeg高层API加速赛题开发与测试
这里直接使用了2048*2048的Resize大小
3.1 数据增强
# 定义transforms
import paddleseg.transforms as T
train_transforms = [
T.RandomHorizontalFlip(0.3),# 水平翻转
T.RandomVerticalFlip(0.3),# 垂直翻转
T.RandomDistort(0.6),# 随机扭曲
T.RandomBlur(0.3),# 高斯模糊
T.RandomScaleAspect(min_scale=0.8,aspect_ratio=0.5),# 随机缩放
T.Resize(target_size=(2048,2048)),
T.Normalize() # 图像标准化
]
val_transforms = [
T.Resize(target_size=(2048,2048)),
T.Normalize()
]
3.2 构建数据集
# 构建训练集
train_dataset = Dataset(
dataset_root='/home/aistudio',
train_path='/home/aistudio/train.txt',
transforms=train_transforms,
num_classes=3,
mode='train'
)
#验证集
val_dataset = Dataset(
dataset_root='/home/aistudio',
val_path='/home/aistudio/eval.txt',
transforms=val_transforms,
num_classes=3,
mode='val'
)
四、利用PaddleSeg高层API加速赛题开发与测试
4.1 实现训练流程
import paddle
from paddleseg.models import BiSeNetV2
from paddleseg.models.losses import MixedLoss,CrossEntropyLoss,DiceLoss,BCELoss,LovaszSoftmaxLoss
learning_rate =0.0125 #初始学习率
BATCH_SIZE = 4
EPOCHS = 110
decay_steps = int(len(train_dataset)/BATCH_SIZE * EPOCHS)
iters = decay_steps
model = BiSeNetV2(num_classes=3)
lr =paddle.optimizer.lr.CosineAnnealingDecay(learning_rate, T_max=(iters // 3), last_epoch=0.5) #使用余弦退火调整学习率
u_optimizer = paddle.optimizer.AdamW(lr, parameters=model.parameters())
#构建损失函数
mixtureLosses = [CrossEntropyLoss(),DiceLoss() ]
mixtureCoef = [0.7,0.3]
losses = {}
losses['types'] = [MixedLoss(mixtureCoef,mixtureLosses)]*5
losses['coef'] = [1]*5
#进行训练
train(
model = model,
train_dataset=train_dataset,
val_dataset=val_dataset,
optimizer=u_optimizer,
save_dir='output/BiSeNetV2_1',
iters=iters,
batch_size=BATCH_SIZE,
save_interval=80,
log_iters=20,
num_workers=0,
losses=losses,
use_vdl=False
)
from paddleseg.core import evaluate
from paddleseg.models import BiSeNetV2
#设置模型
model = BiSeNetV2(num_classes=3)
#模型路径
model_path = 'output/BiSeNetV2/best_model/model.pdparams'
para_state_dict = paddle.load(model_path)
model.set_dict(para_state_dict)
evaluate(model,val_dataset)
4.2 实现预测流程
test_list=["testing/fundus color images/"+item for item in os.listdir("testing/fundus color images")]
transforms = T.Compose([
T.Resize(target_size=(2048, 2048)),
T.Normalize()
])
model = paddleseg.models.BiSeNetV2(num_classes=3)
predict(
model,
#换自己保存的模型文件
model_path = 'output/BiSeNetV2/best_model/model.pdparams',
transforms=transforms,
image_list=test_list,
save_dir='Predict_result',)
五、完成结果提交
需要将预测结果转化为指定格式并打包提交
! mkdir Disc_Cup_Segmentations
for img in os.listdir('Predict_result/pseudo_color_prediction'):
img_dir='Predict_result/pseudo_color_prediction/'+img
im=Image.open(img_dir)
im=Image.fromarray((np.array(im).astype(float)*255/2).round().astype('uint8'))
img=img.split('.')[0]
im.save('Disc_Cup_Segmentations/'+img+'.bmp')
! zip -q -r result.zip Disc_Cup_Segmentations
其他
参考项目
飞桨常规赛:视杯视盘分割(GAMMA挑战赛任务三) - 10月第1名方案
by:笠雨聆月
推荐项目
基于多通道标签和极坐标变换的视杯视盘联合分割
by:Auto
该项目介绍:
在前一个项目 基于PaddleX和PaddleSeg的眼底彩照视盘分割 中,提供了基于目标检测的视盘区域裁剪方法,构建了自定义 PaddleSeg 模型 M-Net 进行视盘的 2 类别分割。
原 MNet 模型的输出通道数为 2,使用 Sigmoid 分别对每个通道做 2 类分割,如果我们想要使用 PaddleSeg 自定义组件构建 MNet,虽然可以通过 1x1 卷积将输出通道由 2 转变为 3 进行 Softmax + Argmax(本次项目的数据是 3 类别:背景,视盘,视杯。),但引文的标签构建方法独具特色(使用 3 通道 PNG),所以本项目以此为契机,手动实现全流程:项目各个模块的结构参考 PaddleSeg-API,增进对 PaddleSeg-API 代码组织和细节的了解,方便以后提交PR。

学大模型,用大模型上飞桨星河社区!每天8点V100G算力免费领!免费领取ERNIE 4.0 100w Token >>>
更多推荐



 0
0 0
0- 0



 已为社区贡献1436条内容
已为社区贡献1436条内容

所有评论(0)